DeepSeek实战--图像识别
本文介绍了利用多模态大模型实现数学题目识别与解答的解决方案。文章对比了传统OCR技术的局限性,详细展示了基于Dify平台和Qwen-VL模型搭建解题助手的实践步骤:1)配置API密钥;2)搭建支持图片上传的工作流;3)设计提示词模板;4)测试验证效果。同时提供了2025年主流图像识别模型的对比分析,重点推荐了Qwen-VL等开源模型。该方案能有效帮助家长辅导孩子作业,但需注意处理速度和模型选择等问
1. 背景
以往我们要识别图片内容,常规技术是OCR 比如:车牌识别、文字识别等,既然有了OCR还有必要研究大模型的图像识别能力 ?答案是:很有必要。 OCR能够识别固定的内容,但一些抽象的内容 就识别不出,比如:从一堆图片中,找出帅气的我。自恋了,哈哈哈!!!今天我来拯救一下,各位家长,做一个功能,识别数学题,并给出解题思路和答案,方便家长们辅导家里的“小怪兽”。
2.环境准备
python 版本:3.12.5
LLM: deepseek-chat、Qwen-VL
Dify:账号、地址
3.实战
Step1: 开通 “阿里云百炼” 权限、配置API key
https://dashi.aliyun.com/activity/ydsbl?userCode=ps9j51zi&clubBiz=subTask…12101002…10239…
Step2: Dify 配置Qwen API key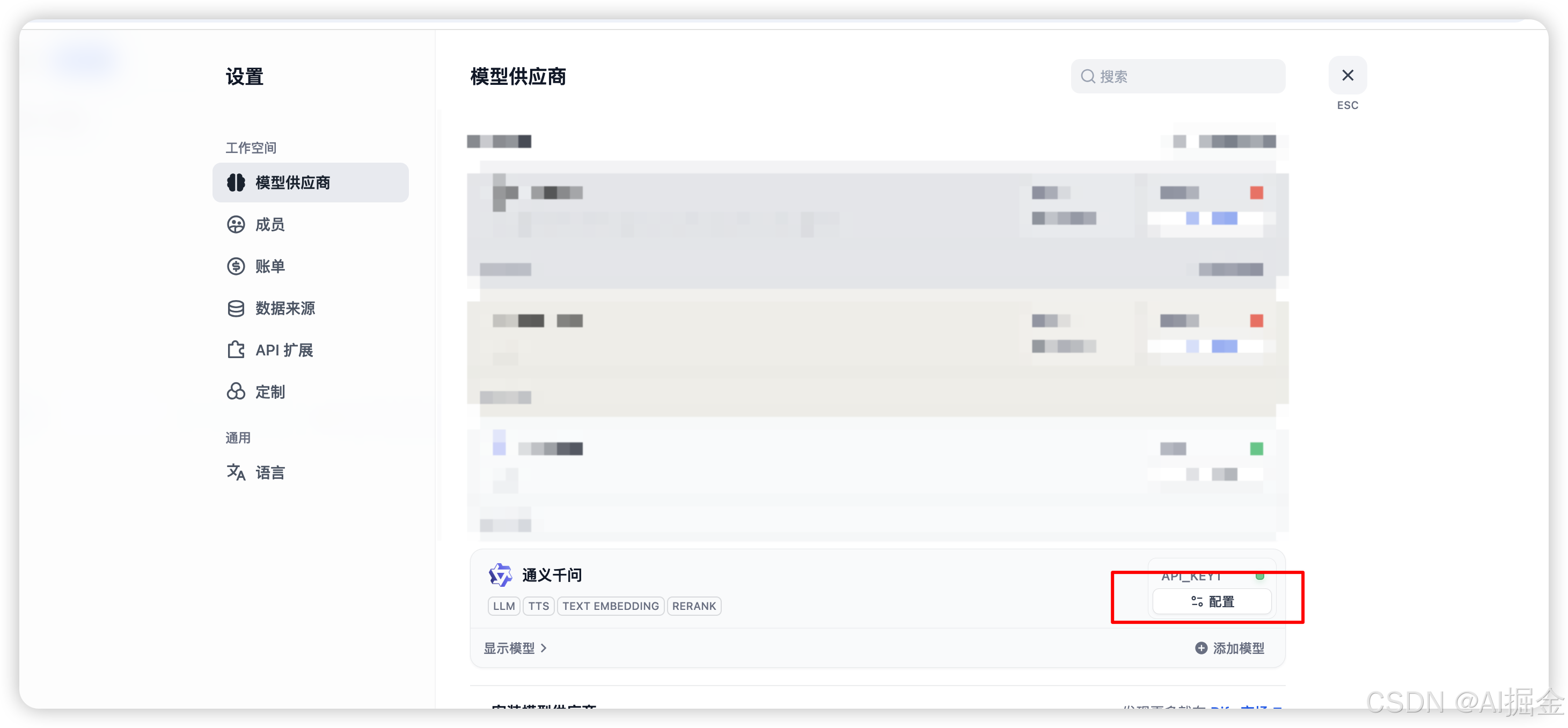
Step3: Dify 流程支持文本上传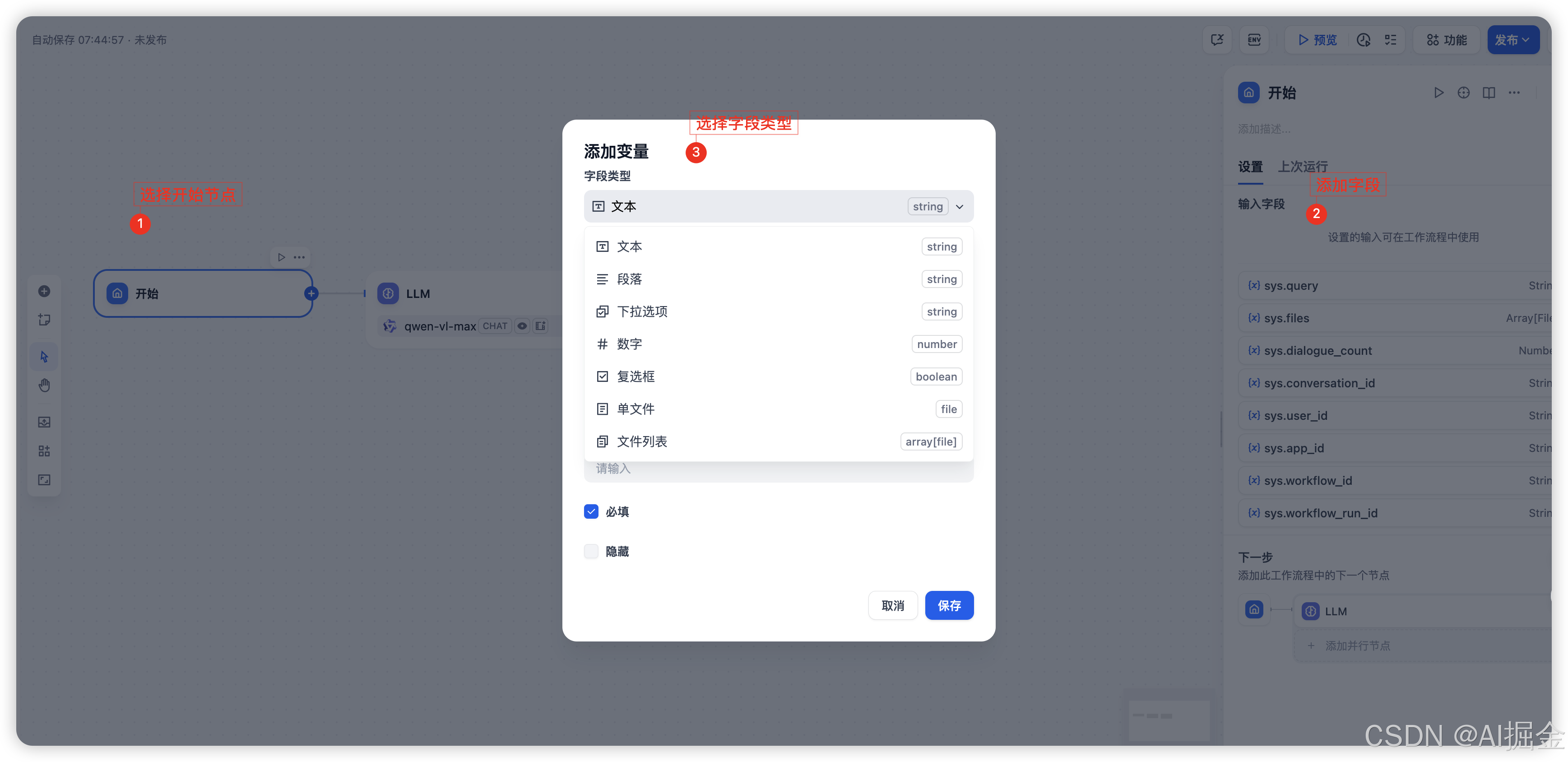
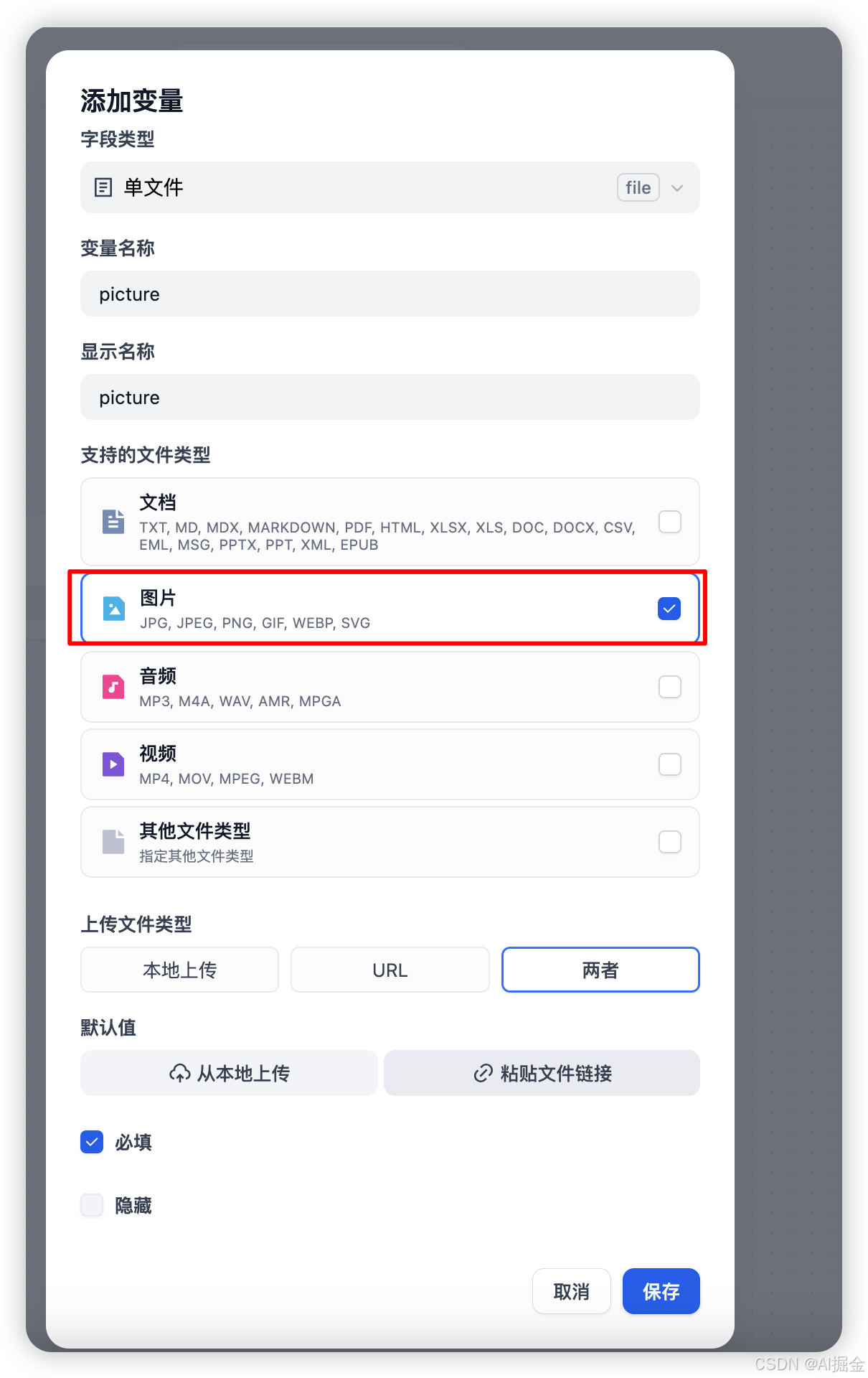
Step4: 配置多模态模型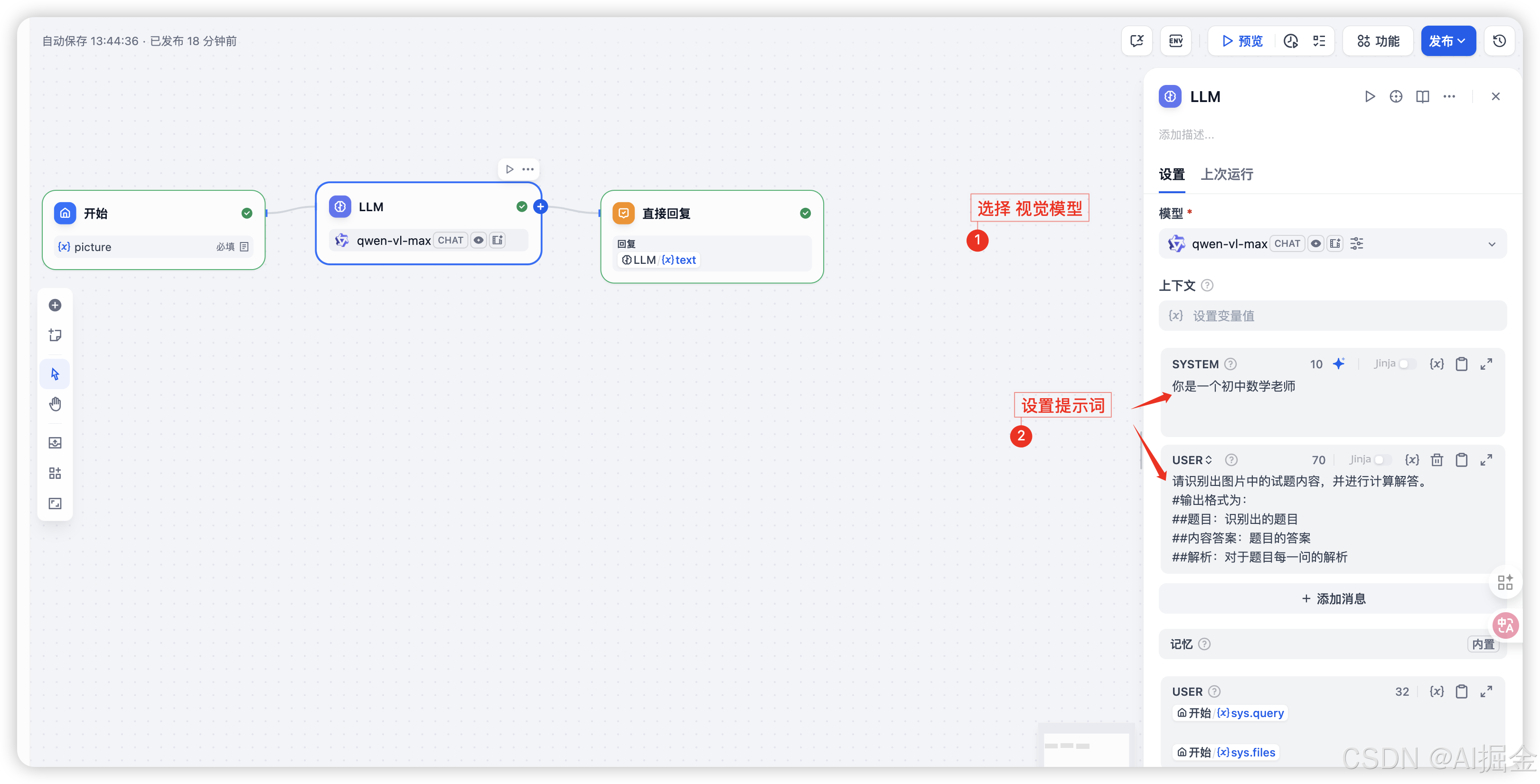
选用的多模态模型是:Qwen-VL
SYSTEM提示词
你是一个初中数学老师
USER提示词
请识别出{{#1757763771530.picture#}}图片中的试题内容,并进行计算解答。
#输出格式为:
##题目:识别出的题目
##内容答案:题目的答案
##解析:对于题目每一问的解析
Step5: 检阅结果
1)上传数学题目照片
2)与Agent对话,让其帮助解数学题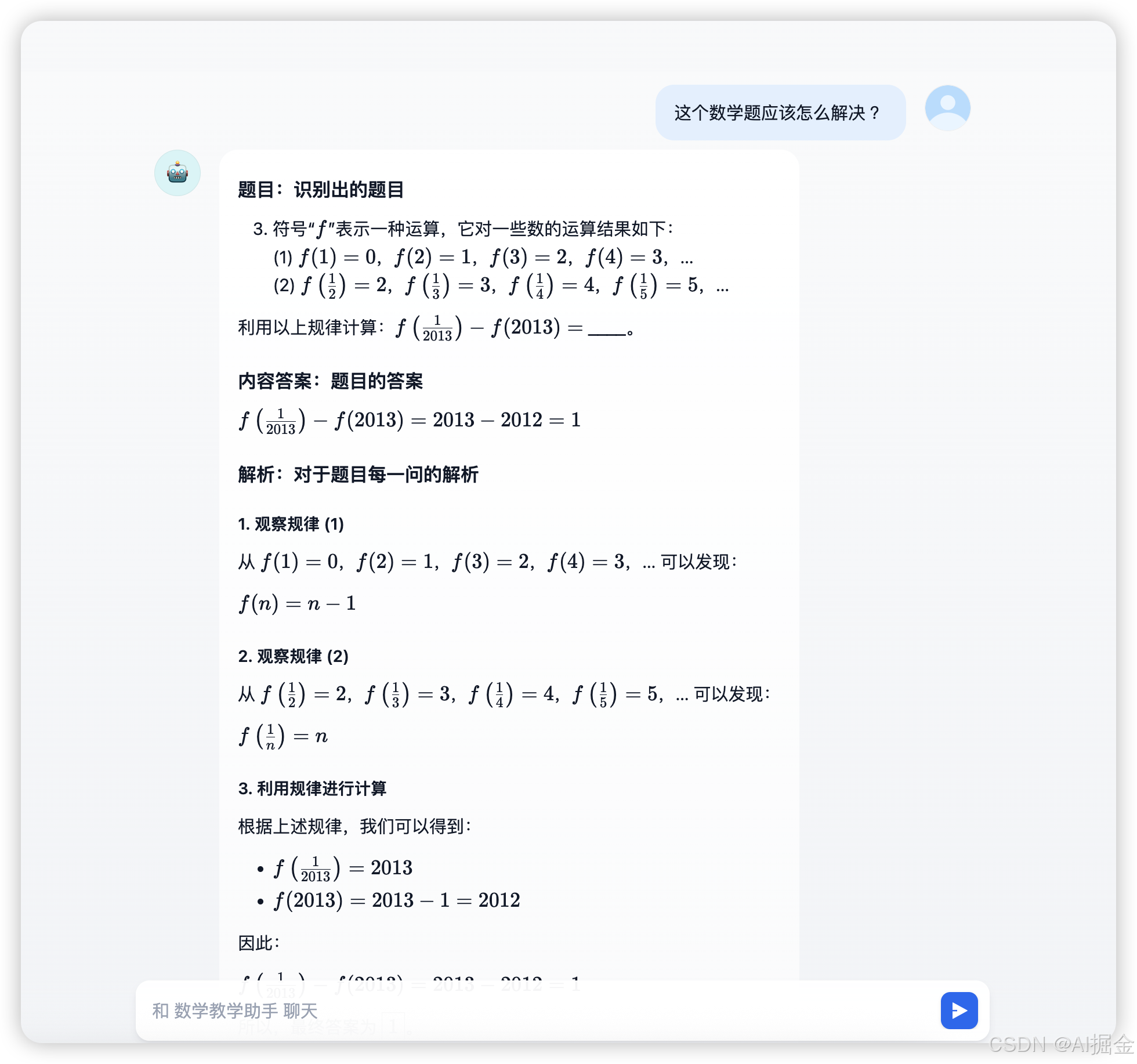
4.总结
1)需要将上传文件节点的变量写到 LLM节点,提示词中,不然大模型没法读取到
2)多模态模型,要慢些一下,所以在生产环境使用时,注意耗时
5.加餐:图像识别模型对比
| 应用场景 | 推荐模型 | 核心优势 | 备注 |
|---|---|---|---|
| 多模态理解与推理 | 商汤日日新 SenseNova | 多模态图像理解能力国内领先,在文字识别、物体定位、图像风格识别等方面表现优异 | - |
| 多模态理解与推理 | 阿里通义千问 Qwen-VL | 视觉理解能力全面,OCR能力强,支持长视频理解 | 开源,提供 3B、7B、72B 等多个版本 |
| 多模态理解与推理 | 百度文心 ERNIE-4.5-Turbo-VL | 在中文多模态视觉语言模型测评中成绩领先 | - |
| 工业质检、垂直领域 | 华为盘古 CV | 工业质检(如电路板缺陷检测)准确率高 | 参数规模达 300B |
| 视频理解 | 快手 Keye-VL-1.5 | 在视频时序理解、场景推理方面有优势 | 开源,8B 参数 |
| 通用与国际模型 | GPT-5 (OpenAI) | 多模态能力支持图像、视频、音频的复杂理解与生成 | 闭源,私有化部署成本高昂 |
| 通用与国际模型 | Gemini 2.5 Pro (Google) | 跨模态对齐误差率较低,在工业设计 3D 建模方面准确率高 | 闭源,对中文文化语境的理解误差率较高 |
| 轻量化与边缘部署 | Qwen2.5-Omni-7B (阿里) | 开源,支持手机部署 | 70 亿参数实现全球最强性能,实时处理语音/图像/文本 |
| 轻量化与边缘部署 | Gemini Nano 2.5 (Google) | 支持离线运行,移动端实时交互,功耗低 | 闭源,集成于移动设备 |
时间:2025.9.13,模型迭代太快了,备注一下,以免误导大家

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)