AI热点周报(9.7~9.13):阿里Qwen3-Next震撼发布、Claude 增强记忆与服务抖动、OpenAI 聚焦模型规范化...
在本周,阿里Qwen3-Next下一代模型震撼发布、Claude 增强记忆与服务抖动、OpenAI 聚焦模型规范化,AI的发展透露了哪些信息?一起来看看!
名人说:博观而约取,厚积而薄发。——苏轼《稼说送张琥》
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)很高兴你打开了这篇博客,更多AI知识,请关注我、订阅专栏《AI知识图谱》,内容持续更新中…
大家好,我是流苏👋,今天我们一起了解一下本周的一些AI热点。
- 如果你想看简单版,下面笔者整理了3分钟速览版,请看下方
一、3分钟速览版:一张表看懂本周AI大事
| 日期 | 国家/地区 | 机构/产品 | 事件要点 |
|---|---|---|---|
| 9/10 | 中国 | 阿里通义 | 宣布即将发布 Qwen3-Next-80B-A3B 系列模型 |
| 9/10 | 美国 | Anthropic | 承认 Claude降智问题,表示正在调查和优化 |
| 9/10 | 中国 | 腾讯 | 开源 HunyuanImage-2.1,推出AI CLI工具 CodeBuddy Code |
| 9/10 | 中国 | 字节跳动 | 豆包Seedream 4.0 全量上线,图像生成能力升级 |
| 9/11 | 美国 | Anthropic / Claude | 推出面向团队/企业的记忆(memory)功能与隐身(incognito)选项;同周出现一次影响 API 与控制台的服务中断。 |
| 9/12 | 中国 | Qwen(通义) | 发布/宣称新变体 Qwen3-Next(宣传方向:训练与推理更高效,成本显著下降、响应更快)。 |
| 9/12 | 美国 | OpenAI | 更新 Model Spec / 模型行为说明,强调 agent 级别原则与可配置安全优先级;并发布关于“为什么模型会幻觉”的重要研究与讨论。 |
| 9/7–9/13 | 全球 | Google / Gemini(延续) | 关于 Gemini 使用/配额与家庭场景落地的讨论持续,Google 也在调整定价/使用策略。 |
二、国内:阿里Qwen3-Next引领架构创新
1. 阿里通义发布革命性Qwen3-Next架构
9月12日,阿里巴巴通义千问发布下一代基础模型架构Qwen3-Next,并开源了基于该架构的Qwen3-Next-80B-A3B系列模型。这是本周AI领域最重要的技术突破之一。

a.核心技术创新
架构革新:
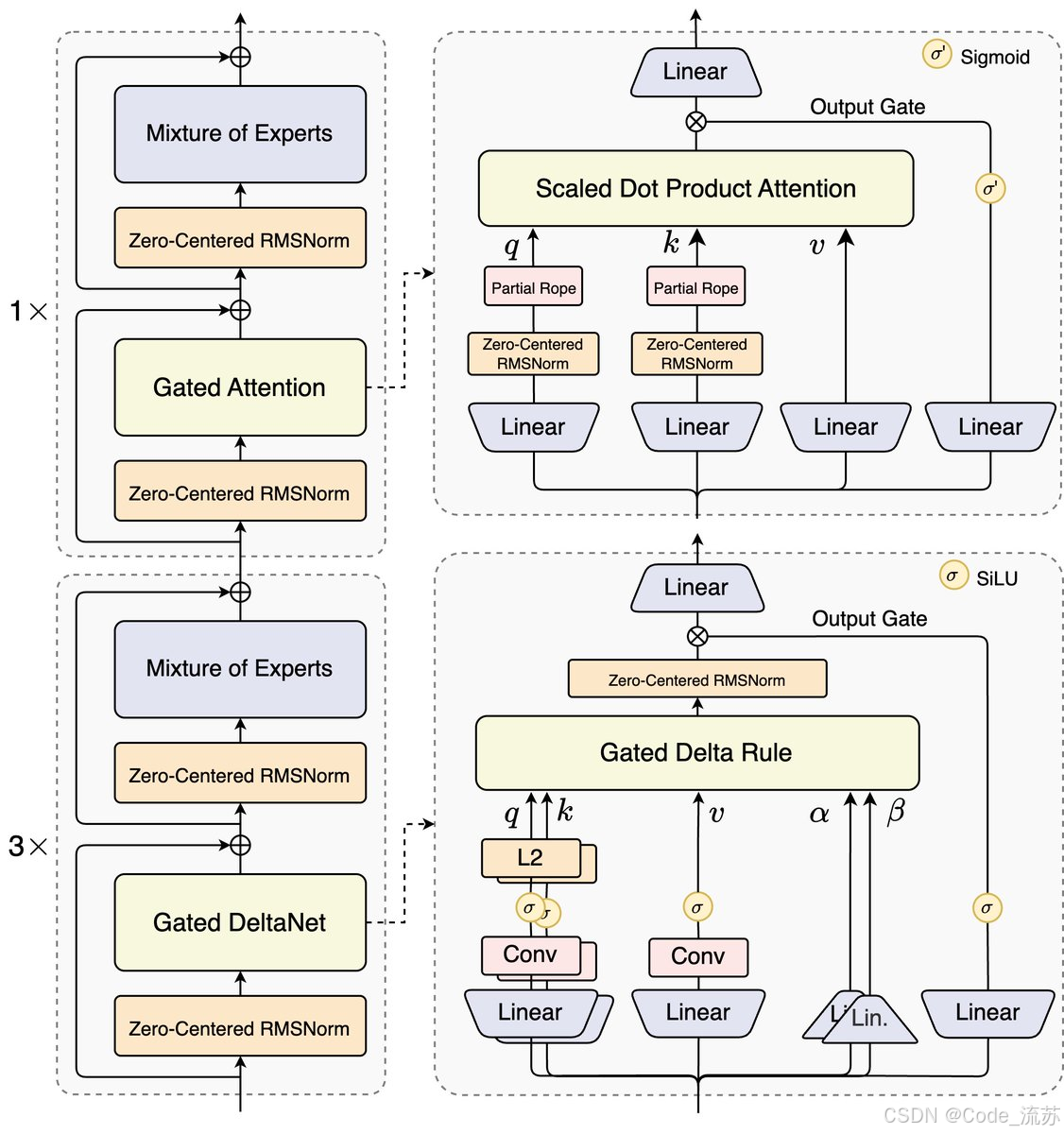
该结构相比Qwen3的MoE模型结构,进行了以下核心改进:混合注意力机制、高稀疏度MoE结构、一系列训练稳定友好的优化,以及提升推理效率的多token预测机制。

创新亮点:
- 模型用全球首创的Gated DeltaNet和Gated Attention混合架构,实现更快的处理速度、更强的效果和更省的资源消耗
- 80B 总参数(80B-A3B)与稀疏激活(每次仅激活约 3B 参数)为核心设计思路,显著提升在长上下文、高并发与低延迟场景下的性价比
b.性能突破
成本与效率革命:
Qwen3-Next针对大模型在上下文长度和总参数两方面不断扩展(Scaling)的未来趋势而设计,采用全新的高稀疏MoE架构,并对经典Transformer核心组件进行了重构,创新采用线性注意力和自研门控注意力结合的混合注意力机制,实现了模型训练和推理的双重性价比突破。
预训练效率与推理速度:
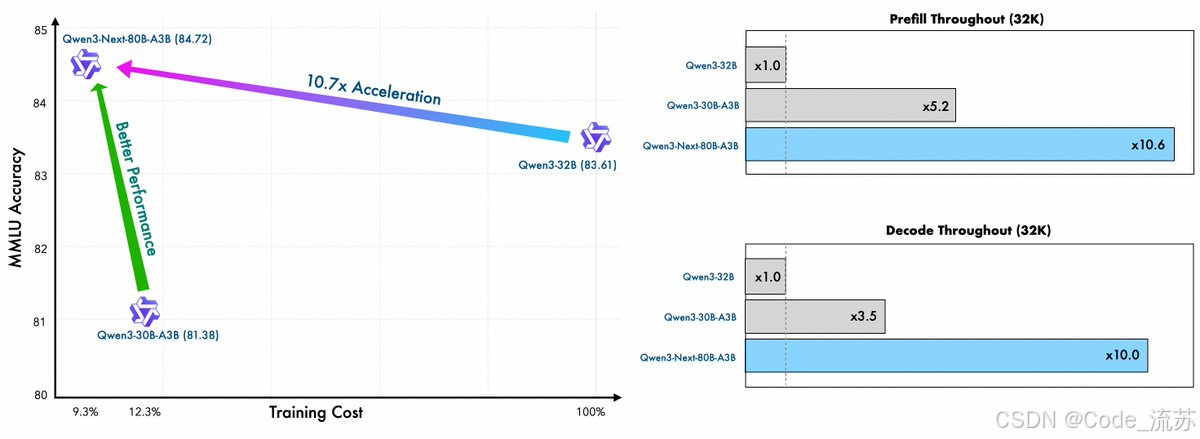
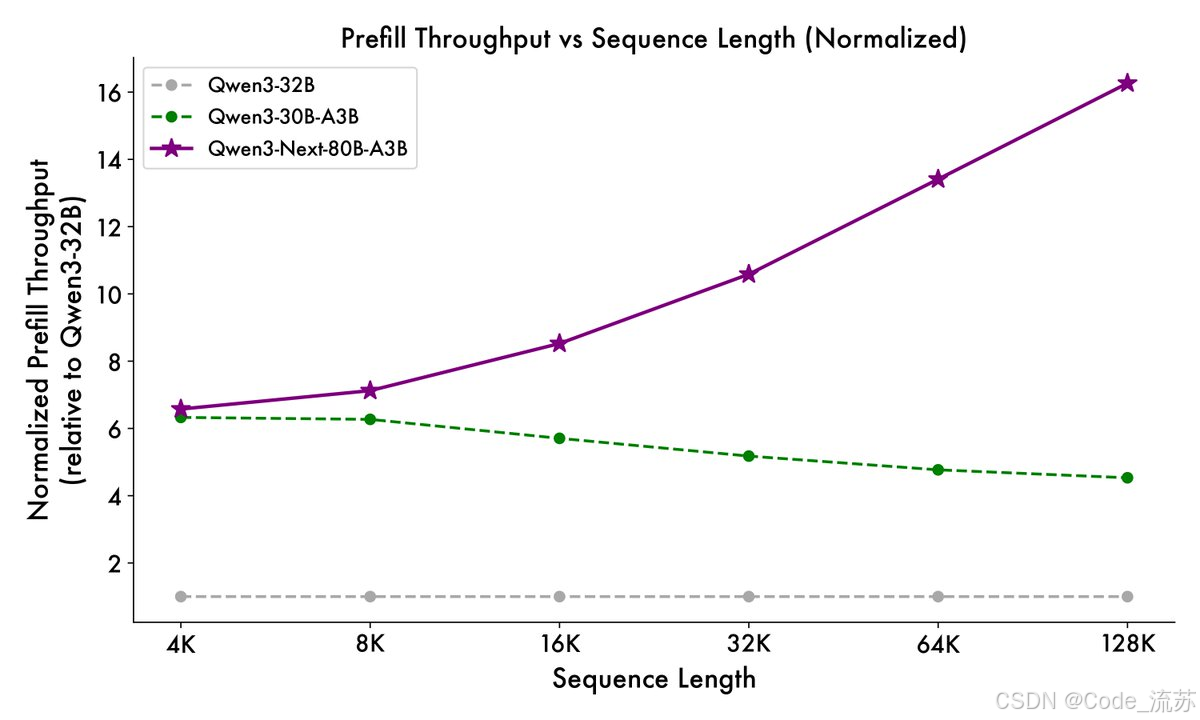
预填充阶段:在 4K 上下文长度时,吞吐量比 Qwen3-32B 高近 7 倍。超过 32K 时,速度提高 10 倍以上。
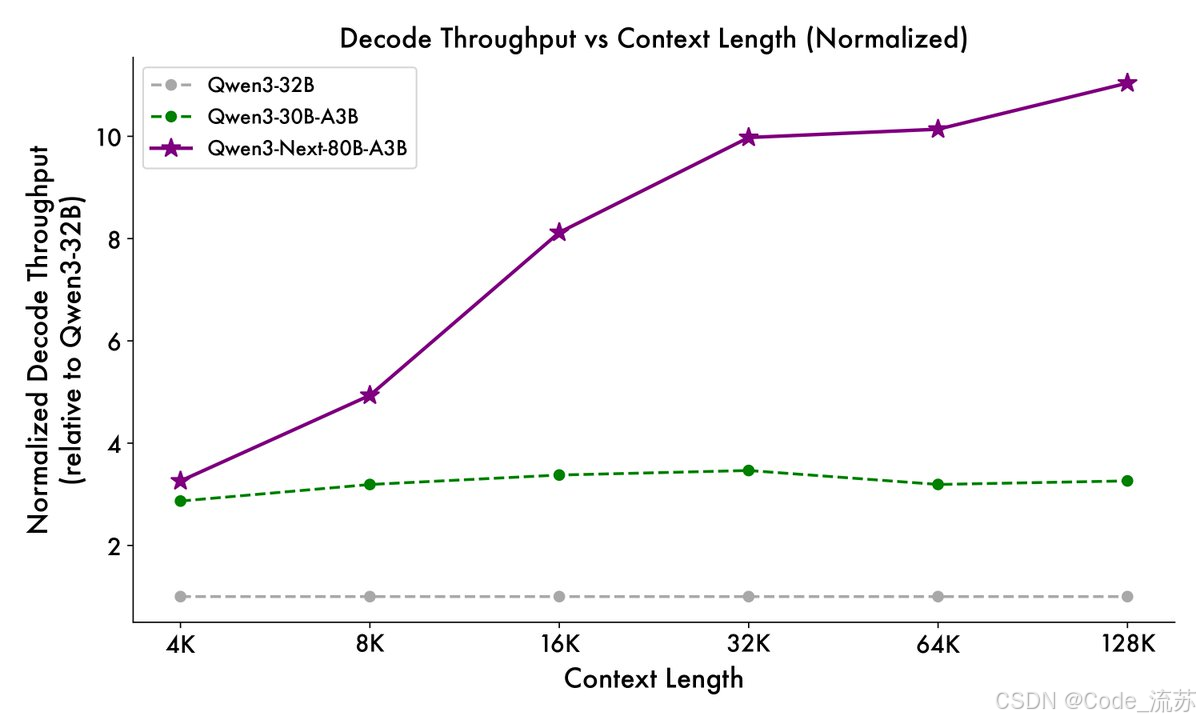
解码阶段:在 4K 上下文中,吞吐量高出近 4 倍。即使超过 32K,它仍能保持 10 倍以上的速度优势。
根据官方数据:
- 训练成本降低90%
- 长文本推理吞吐提升10倍
- 256K超长上下文支持
c.两大版本定位
本系列包含两个主打方向:
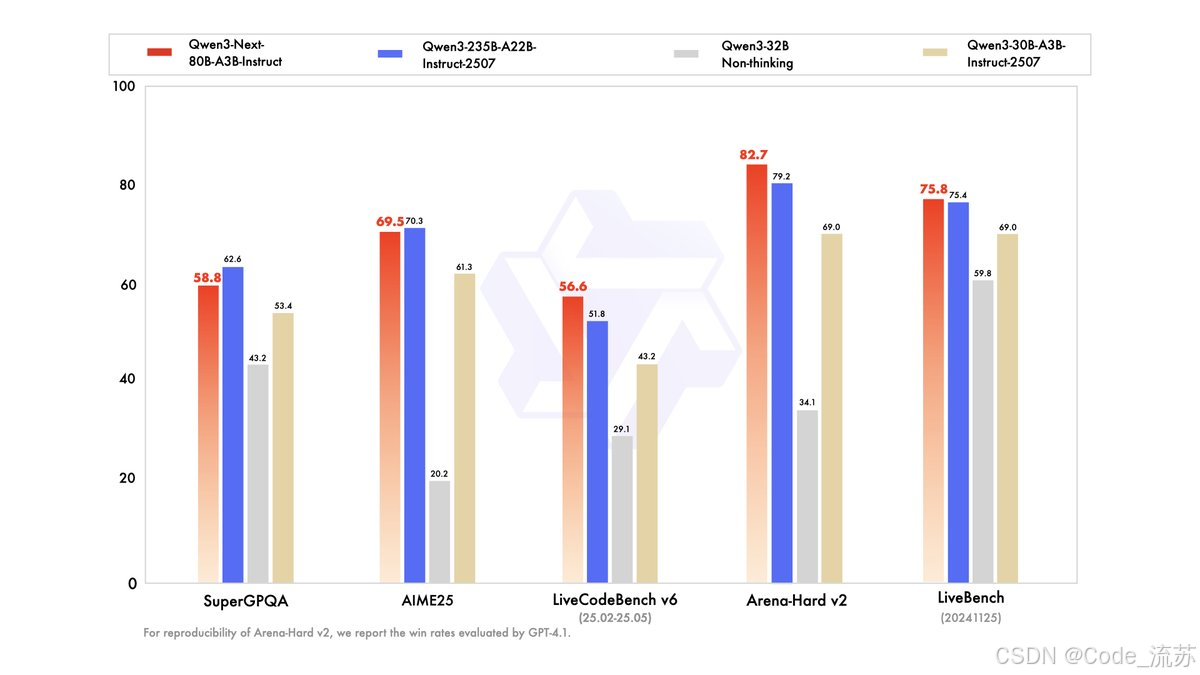
Qwen3-Next-80B-A3B-Instruct(指令版)
- Instruct版本的性能与阿里巴巴的旗舰模型Qwen3-235B-A22B-Instruct-2507相当,并在需要长达256,000个令牌的超长上下文任务中显示出优势
- 适用于通用对话、文本生成、长文本理解等场景
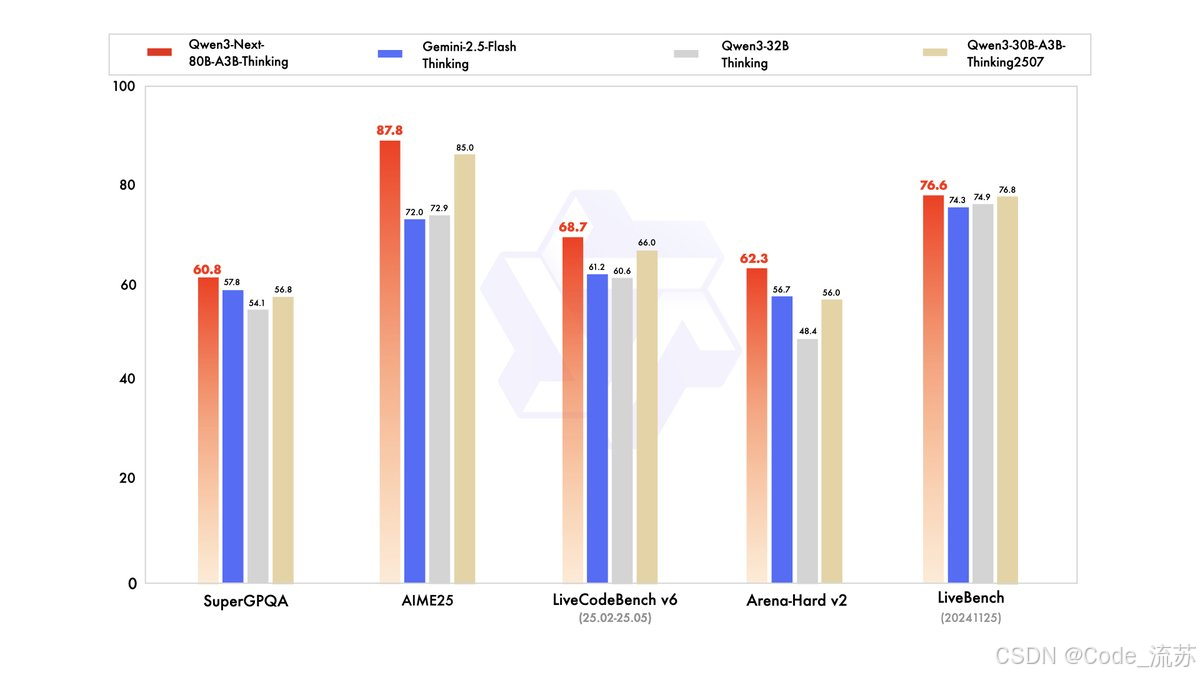
Qwen3-Next-80B-A3B-Thinking(思维版)
- Thinking版本在复杂推理任务中表现出色,据报道其性能优于成本更高的模型,如Qwen3-30B-A3B-Thinking-2507和Qwen3-32B-Thinking
- 专攻数学推理、代码生成、逻辑分析等复杂任务
d.开放生态布局
阿里已在Hugging Face和ModelScope上提供Qwen3-Next。用户可以通过阿里云Model Studio和英伟达API目录访问Qwen3-Next服务。
1️⃣Huggingface: https://huggingface.co/collections/Qwen/qwen3-next
2️⃣ModelScope: https://modelscope.cn/models/Qwen/Qwen3-Next
模型现已上线阿里云百炼支持API调用和Qwen网页版支持在线体验。
Qwen网页版:https://chat.qwen.ai/
2. 腾讯AI生态持续发力
根据官推发布,腾讯在本周推出多项AI更新:
- 腾讯混元开源HunyuanImage-2.1:图像生成模型进一步优化
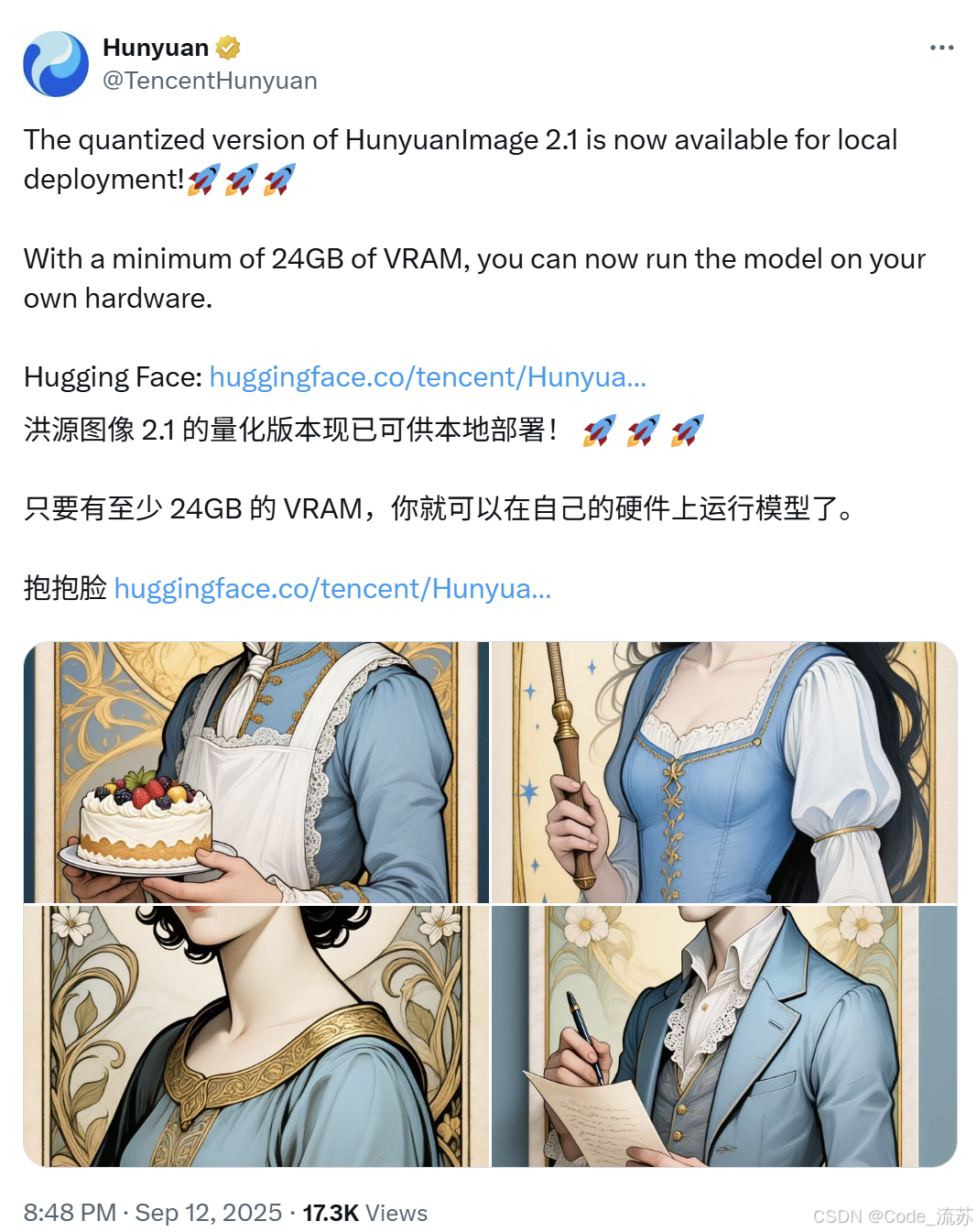
混元AI生图示例:


- 腾讯发布AI CLI:CodeBuddy Code:面向开发者的命令行AI工具
- 持续强化在多模态AI领域的布局
3. 字节跳动豆包升级
豆包Seedream 4.0全量上线,在图像生成质量、速度和多样性方面都有显著提升。

三、国外:模型优化与反思
1. Anthropic承认Claude降智问题
Anthropic承认Claude降智,这是业界罕见的公开承认模型性能下降的案例。Anthropic表示正在调查原因并进行优化,现在已解决部分问题,体现了对用户反馈的重视和技术透明度。
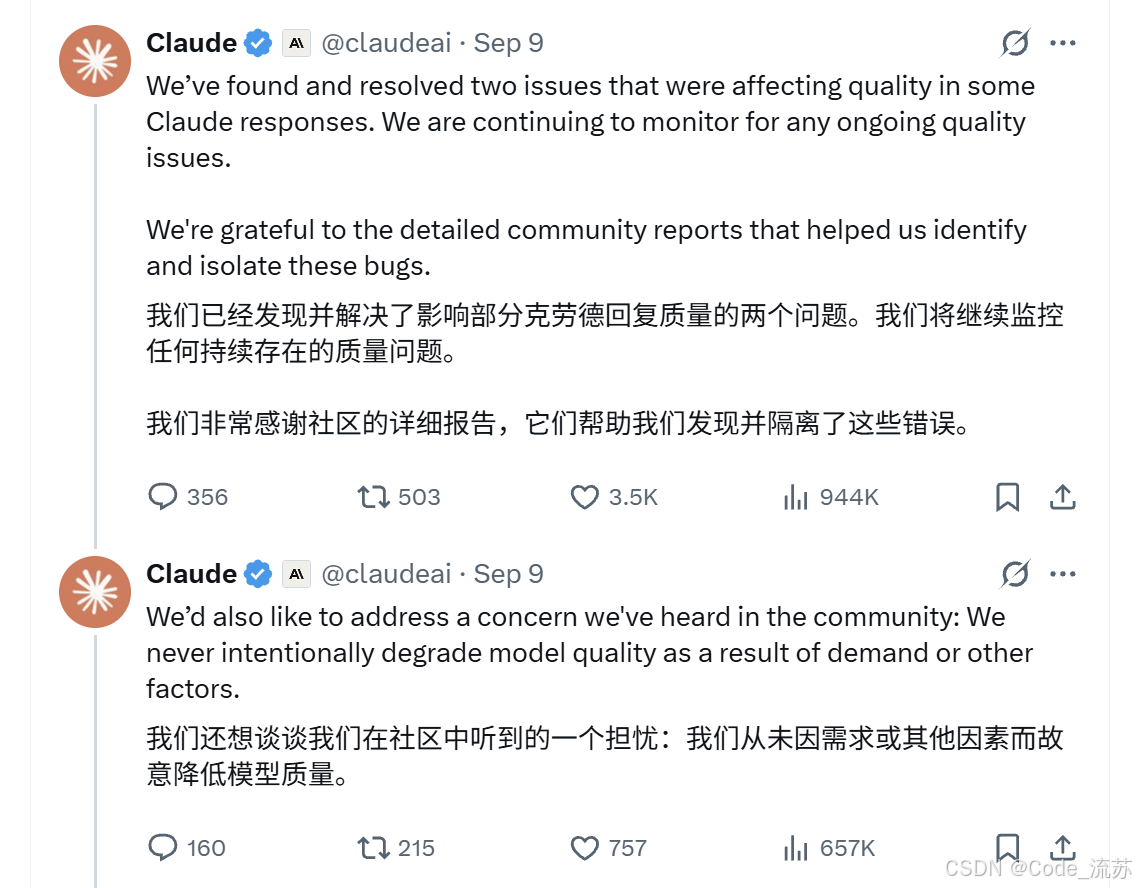
影响分析:
- 短期内可能影响用户信任
- 长期看有助于建立更诚实的AI发展文化
- 推动业界更关注模型稳定性而非单纯追求参数规模
2. Claude新增文件创建分析功能
Claude上线文件创建分析功能,进一步增强了其作为编程助手的实用性。

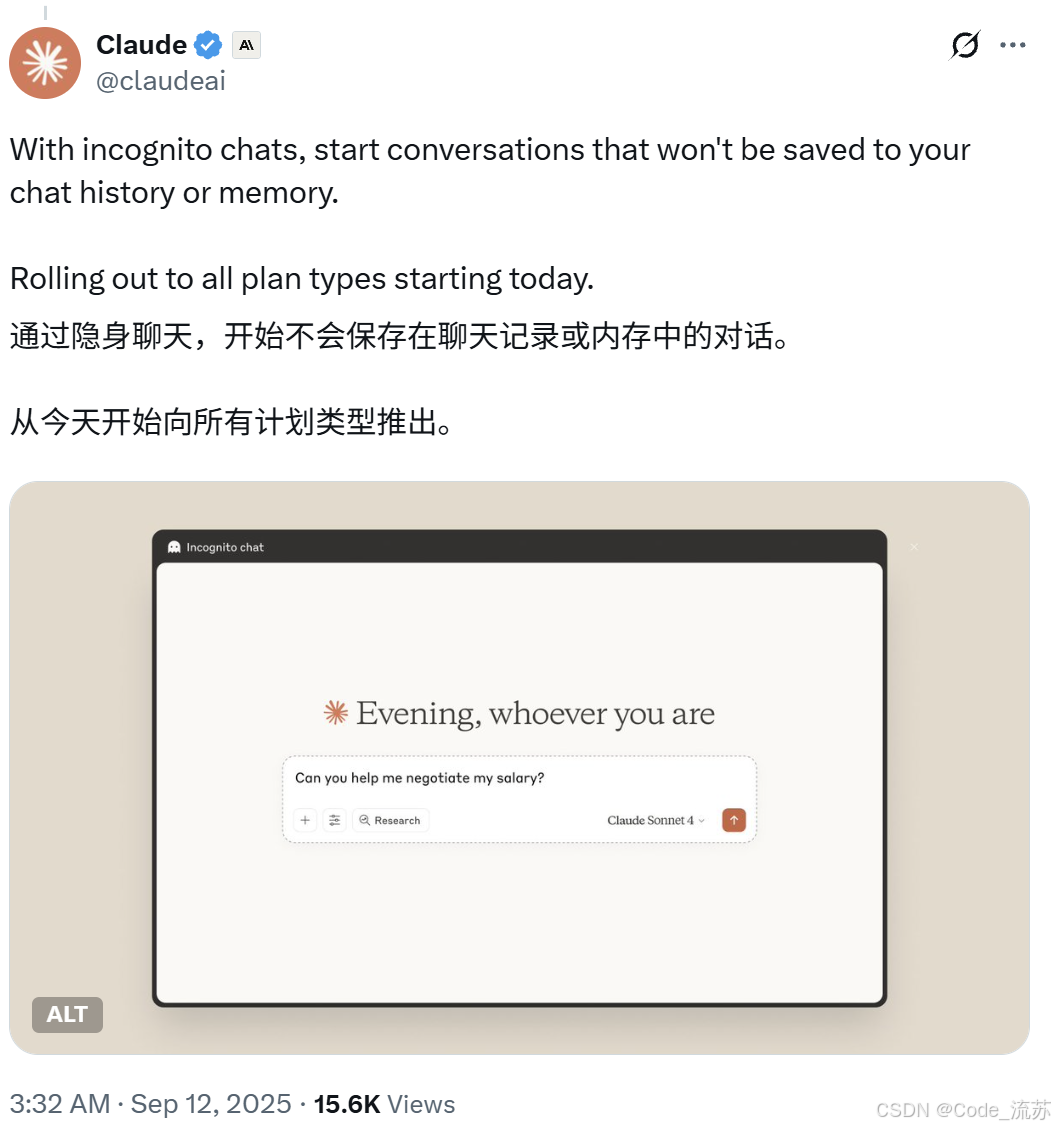
3. Anthropic:记忆功能、隐私模式与服务可用性
- Anthropic 本周在 Claude(Team / Enterprise) 上增加了记忆(memory)功能以提升团队协作的连续性,并提供隐身/Incognito 模式用于更细粒度的隐私控制,这对企业級应用(例如内部知识库接入、长会话场景)是个实用特性。 (Venturebeat)
- 同周,Anthropic 报告了影响控制台与 API 的短时中断(outage)。服务可用性事件提醒:企业级用户部署云端大模型时,必须把冗余、降级策略与本地缓存/批量处理设计好。 (TechCrunch)

4. OpenAI:更新 Model Spec 与“幻觉”研究
- Model Spec 更新:OpenAI 对其公开的 Model Spec 做了重要更新,强化了对“agent”(能执行动作的模型)行为的原则、权限层级(如 Root / System / Developer / User 等)及安全优先级说明。这代表着向更可控的“可编排智能体”方向迈进一步,对于构建自治型应用(自动化 agent、业务流程机器人)很重要。 (OpenAI Help Center)

- 为什么模型会幻觉?(研究/论文):OpenAI 与学术圈的研究指出,训练与评价机制往往“奖励猜测”而非承认不确定性,这是导致模型“自信地说错话(hallucinate)”的统计学根源。论文给出了一些评估与训练上的应对措施(例如更合理的标注/评估机制、对不确定性做 explicit 表达等)。对于需要高可信度输出(医疗、法律、金融)的应用,这一议题仍是核心工程问题。 (arXiv)
5. Google / Gemini:配额与家庭场景的商业化调整
- 与 Gemini 在家庭场景(Gemini for Home)推广同步,Google 本周围绕 使用限制/计费分层等进行了讨论与调整,这说明大型云厂商在平衡“免费可试用体验”与“成本回收/滥用防范”之间持续微调。对开发者意味着:要关注模型使用的定价与速率限制(rate limits),并在产品中内建优雅的降级或计费告警逻辑。 (Yahoo Tech)
四、技术趋势分析:架构创新成为新战场
1. 从参数竞赛到架构创新
本周的事件(Qwen3-Next 的工程优化主张、Anthropic 的记忆/隐私功能、OpenAI 的 Model Spec 更新)共同传递了一个信号:厂商开始把竞争话语权从“谁更大更强”逐渐往“谁更便捷、更可靠、更合规”倾斜。这对产品化落地更友好,也会推动更多垂直行业的试点上云。
其中,Qwen3-Next的发布也标志着大模型竞争进入新阶段:
- 不再单纯追求参数规模:80B总参数但仅激活3B,效果媲美235B模型
- 架构创新成为核心:混合注意力、高稀疏MoE等新技术
- 性价比成为关键指标:训练成本降90%,推理效率提升10倍
2. 专用模型分化趋势明显
本周发布显示出明显的模型专业化趋势:
- 指令模型 vs 思维模型:针对不同任务优化
- 长文本 vs 高并发:场景化设计
- 效果 vs 效率:根据需求平衡
3. 开源生态加速发展
国内厂商持续加大开源力度:
- 阿里Qwen3-Next全系列开源
- 腾讯HunyuanImage开源
- 形成与闭源模型互补的生态格局
4. 幻觉(hallucination)仍是难题
- 本周 OpenAI/学术圈对“为什么模型会幻觉”做了明确的机制性分析(见上文),并建议在训练/评测环节引入“不确定性容许”与更现实的评估任务。
- 工程实践来说,短期可行的对策包括:答案溯源(source attribution)+ 可解释检索(RAG)+ 不确定性提示(calibration / confidence)。 (arXiv)
无、小结
本周AI领域最大亮点是阿里巴巴通义千问发布下一代基础模型架构Qwen3-Next,通过革命性的架构创新实现了训练成本降低90%、推理吞吐提升10倍的突破。这标志着大模型竞争从"参数竞赛"转向"架构创新竞赛"。
国内AI生态展现出强劲的创新活力,阿里的Qwen3-Next、腾讯的混元、字节的豆包等产品持续迭代,形成了完整的AI技术栈。特别是在成本控制和效率优化方面,国产模型已经走在世界前列。
国际方面,Anthropic公开承认Claude降智问题,虽然短期内可能影响用户信任,但这种透明态度有助于建立更健康的AI发展生态。
展望未来,架构创新、成本优化、场景专用化将成为大模型发展的三大主线。开发者需要更加关注模型的实际应用效果和成本效益,而非单纯追求参数规模。
参考(部分权威来源)
- 阿里通义Qwen3-Next架构发布(财联社、新浪科技,9月12日)
- Qwen3-Next技术详解(QWQ AI、AI工具集,9月12日)
- 阿里开源新架构Qwen3-Next分析(每日经济新闻,9月12日)
- Qwen3-Next系列模型全解析(Stable Learn,9月12日)
- AI早报:Qwen即将发布、Claude降智、腾讯混元更新(知乎,9月10日)
- Qwen3-Next在Hugging Face和ModelScope开源(阿里官方,9月12日)
- Qwen 官方博客 / 新进展(Qwen3-Next 宣称与技术博文)。(Qwen)
- South China Morning Post:关于 Qwen3-Next / 通义新变体的报道(2025-09-12)。(South China Morning Post)
- VentureBeat:Anthropic 为 Team/Enterprise 增加记忆与隐身功能(2025-09-11)。(Venturebeat)
- TechCrunch:Anthropic 报告 API / 控制台中断(2025-09-10)。(TechCrunch)
- OpenAI:Model Spec 更新(2025-09-12)与“Why language models hallucinate”研究(ArXiv / OpenAI 论文,2025-09)。(OpenAI Help Center)
- 额外阅读:关于 Gemini 使用/配额与家庭场景的新闻与技术博客。(Yahoo Tech)
声明:本文所有时间均以 2025年9月7日—9月13日期间的公开报道与官方文档为准;技术参数以官方发布为准。
创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊)
专栏:AI知识图谱|面向零基础读者的每周情报与深度解读

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)