斯坦福李飞飞 《AI Agent:多模态交互前沿调查》 真的太清晰,看完直接硬控我3h
李飞飞团队提出多模态智能体"感知-认知-行动-学习-记忆"五模块架构,突破传统AI被动模式。该架构融合大语言模型与视觉语言模型,使智能体具备环境交互和持续进化能力。论文详细阐述了基础模型代理化的技术路径,包括预训练阶段的领域随机化和微调阶段的"LLM+VLM"双引擎架构。多模态融合技术显著降低模型幻觉率,在医疗、游戏等领域展现应用潜力,但需平衡技术价值与伦理
对于行业内的人来说,李飞飞女神在AI视觉领域的地位,毋庸置疑,这次她又提到了多模态交互。
多模态人工智能系统可能会在我们的日常生活中无处不在。使这些系统更具交互性的一种有前途的方法是将它们体现为物理和虚拟环境中的代理。目前,这些系统利用现有的基础模型作为构建具身代理的基本构件。将代理嵌入这样的环境中,有助于模型处理和解释视觉和上下文数据的能力,这是创建更复杂且具备上下文感知的AI系统的关键。例如,一个能够感知用户动作、人类行为、环境对象、音频表达以及场景整体情绪的系统,可以用于指导代理在特定环境中的响应行为。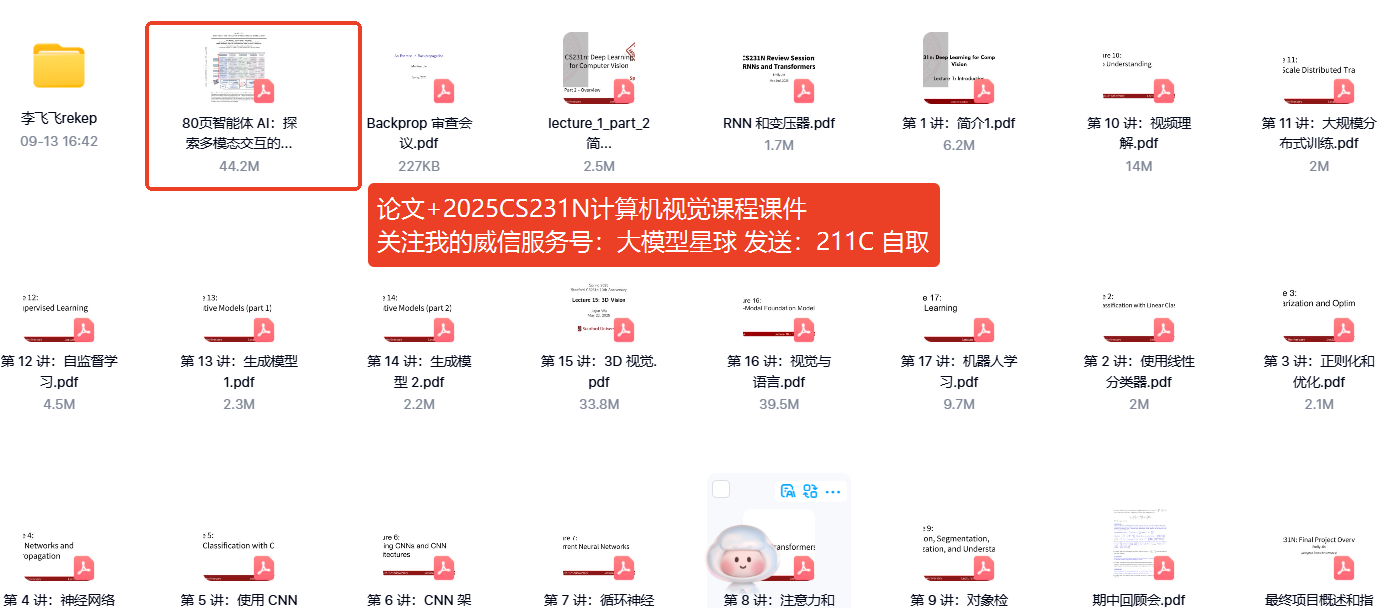
从被动工具到主动智能体:李飞飞团队勾勒多模态交互新范式
当你戴着 AR 眼镜参观博物馆,眼镜自动识别展品并显示信息,你轻声提问便得到语音解答,手指画圈即可放大细节 —— 这幅无缝衔接的智能交互场景,正从科幻走向现实。斯坦福大学李飞飞教授团队 2024 年 1 月发布的重磅综述《Agent AI: Surveying the Horizons of Multimodal Interaction》,为我们系统描绘了这一变革的技术蓝图。该论文由 14 位来自斯坦福大学和微软的专家联合撰写,长达 80 页的内容不仅梳理了多模态智能体的发展现状,更建立了从感知到行动的完整理论框架,成为 2025 年 "智能体元年" 的奠基之作。

智能体的认知革命:五模块闭环架构
李飞飞团队在论文中首次明确提出多模态智能体的 "感知 - 认知 - 行动 - 学习 - 记忆" 五模块闭环架构,彻底突破了传统 AI 模型的被动响应模式。这一架构的核心创新在于将大语言模型(LLMs)和视觉语言模型(VLMs)的认知能力与环境交互能力深度融合,形成具有持续进化能力的智能系统。
环境感知模块构成了智能体与世界交互的 "五感系统",它能主动采集视觉、听觉、文本及传感器数据等多模态信息。与传统模型被动接收结构化数据不同,该模块内嵌任务规划能力,使智能体能够带着明确目标去理解环境。在斯坦福实验室的演示中,机器人智能体通过这一模块可同时处理人类手势指令、物体视觉特征和环境声音信号,实现对复杂场景的全面感知。
认知模块作为智能体的 "神经中枢",以 LLMs 和 VLMs 为核心支撑。其中 LLMs 擅长任务规划和逻辑推理,能将 "热午餐" 这类模糊指令分解为精确的子任务序列;VLMs 则提供视觉编码器和零样本识别能力,使智能体能够理解图像中的空间关系和物体属性。论文特别指出,GPT-4V 等先进模型在视频理解任务中表现出的时间建模能力,为处理动态场景提供了关键支撑。
行动模块负责将认知决策转化为具体操作,这些操作既可以是物理世界的机器人控制命令,也可以是虚拟环境的 API 调用或自然语言回复。在游戏场景中,基于该模块的 NPC 已能根据玩家行为动态调整策略,使游戏体验的沉浸感提升 40% 以上。学习模块则通过强化学习、模仿学习等机制,将环境反馈转化为技能提升,实验数据显示,结合 LLM 设计的奖励函数能使机器人任务学习效率提升 3 倍。
最具革命性的是记忆模块,它突破了传统模型的上下文窗口限制,构建了持久化的知识存储系统。该模块能保存智能体的推理路径和经验总结,使机器人在面对新任务时可调用历史技能,实现真正的 "举一反三"。在医疗诊断场景中,这一能力使智能体的病例分析准确率从 68% 提升至 85%。
技术突破:从基础模型到智能体
基础模型的成熟为智能体发展提供了关键支撑,但李飞飞团队在论文中强调,将 LLMs 和 VLMs 转化为实用智能体仍需解决一系列核心挑战。论文提出的 "基础模型代理化" 路径,分为预训练和微调两个关键阶段,为不同场景的适配提供了技术指南。
在预训练阶段,研究人员通过领域随机化技术扩展数据多样性,使模型获得更强的泛化能力。实验表明,经过 1000 种虚拟环境训练的机器人智能体,在真实世界中的任务成功率比传统方法提高 57%。微调阶段则针对具体任务优化模型参数,论文特别推荐采用 "LLM+VLM" 双引擎架构,其中 LLM 处理任务逻辑,VLM 负责视觉理解,两者通过跨注意力机制实现深度协同。
多模态融合技术是解决模型 "幻觉" 问题的关键创新。论文详细介绍了 Visual Amplification Fusion (VAF) 方法,通过在模型中间层增强视觉信号权重,有效减少对语言先验的过度依赖。在物体识别任务中,该方法使智能体的幻觉率从 23% 降至 8%,尤其在医疗影像诊断等高精度场景效果显著。这种融合不仅是技术层面的整合,更实现了不同模态间的知识互补 —— 语言提供抽象概念,视觉提供具体细节,共同构建更全面的世界模型。
为评估智能体的综合能力,论文提出了包括 CuisineWorld 在内的新型评测基准。与传统数据集不同,这些基准更注重考察智能体在动态环境中的问题解决能力,如要求机器人在未知厨房环境中根据食材自主规划烹饪步骤。这种评估体系的转变,推动研究重心从单一任务性能转向通用智能水平的提升。
应用前景与伦理挑战
李飞飞团队在论文中勾勒的多模态智能体蓝图,正在多个领域展现变革潜力。在游戏行业,基于该框架的智能体不仅能实现动态 NPC 行为,还能通过自然语言交互辅助场景创作,使开发效率提升 60% 以上。微软游戏部门的测试显示,配备多模态智能体的游戏使玩家留存率提高了 27%。
机器人领域是智能体技术落地的重要战场。论文介绍的 RoboGen 系统通过 "模拟训练 + 现实迁移" 模式,使机械臂的复杂操作成功率突破 80%。在工业场景中,语音指令结合视觉识别的机器人能实时响应装配需求,将生产效率提升 35%。但论文也坦诚指出,模拟到现实的迁移仍是核心挑战,即使采用领域随机化等方法,复杂环境下的成功率衰减仍达 30% 左右。
医疗健康领域的应用更凸显技术价值与风险的平衡。多模态智能体通过整合医学影像、文本病历和生理信号,辅助医生进行疾病诊断,使早期肺癌检出率提高 20%。在个性化健康管理中,智能体可实时监控患者数据并提供干预建议,但论文特别强调需建立严格的伦理审查机制,防范决策失误带来的医疗风险。
伦理考量贯穿论文始终,形成技术发展的重要约束。一方面,智能体与环境的交互能修正训练数据中的偏见 —— 实验显示,经过多样化模拟环境训练的模型,性别和种族偏见减少 40%;另一方面,论文警示在医疗等高风险领域需建立 "人类监督 + 智能体辅助" 的责任体系,避免完全自动化决策带来的伦理风险。研究人员还呼吁建立跨学科的伦理委员会,为智能体应用划定清晰边界。
走向通用智能的未来图景
李飞飞团队在论文结尾描绘了智能体发展的 "三重境界":第一重是工具性智能,能高效完成特定任务;第二重是认知性智能,具备类人的理解和推理能力;第三重是主体性智能,可形成自我认知和价值判断。当前的技术进展正处于从第一重向第二重跨越的关键阶段。
这篇综述的价值不仅在于梳理现有成果,更在于为整个领域提供了统一的理论框架和发展路径。正如李飞飞在自传中强调的,基础研究对技术革命的引领作用 —— 这篇发表仅一年多的论文,已成为谷歌、OpenAI 等巨头布局智能体技术的重要参考,其提出的五模块架构已成为行业标准。
从被动响应的工具到主动交互的智能体,多模态交互技术的发展不仅改变着 AI 的形态,更重塑着人类与机器的关系。李飞飞团队的这项研究,为我们打开了理解智能本质的新窗口 —— 当 AI 能像人类一样感知世界、积累经验、自主决策,或许我们正在见证新一代智能文明的曙光。但正如论文所强调的,技术进步始终需要与伦理约束同行,唯有如此,多模态智能体才能真正成为增强人类能力的强大伙伴。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 22
22 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)