「大模型学习」(13) DeepSeek-GRPO原理
GRPO是一种改进的强化学习算法,其目标函数结合了PPO的思想并引入组内归一化奖励。该算法还保留了PPO的策略比率裁剪机制和KL散度正则项,以控制策略更新幅度。相较于PPO,GRPO无需额外训练奖励模型,直接利用组内相对评分构建优势函数,更具实用性和部署便利性。优化流程包括采样、组内评分归一化、策略比率计算和带裁剪的目标函数优化等步骤。
一、GRPO 的目标函数:完整数学表达式
GRPO 的目标函数参考 PPO 的思想,但使用组内归一化奖励Group-Relative Advantage代替绝对奖励,同时加入策略变动的限制项。
我们回顾一下PPO的reward: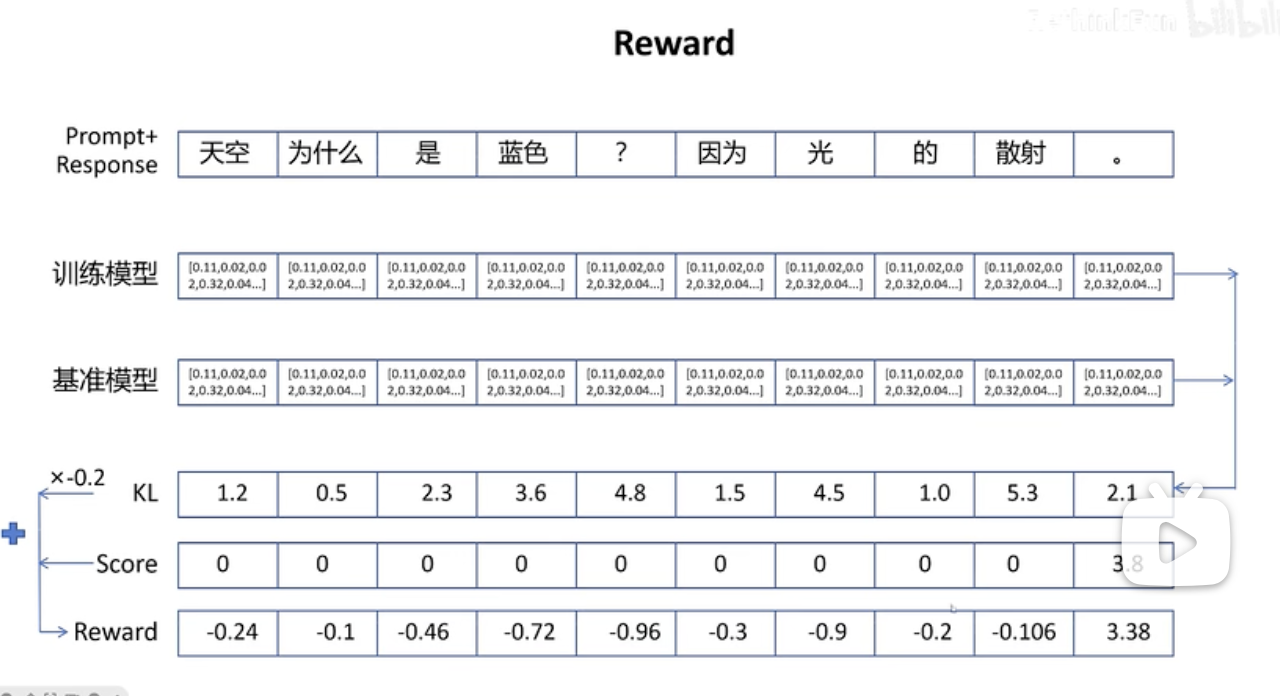
下面是GRPO算法: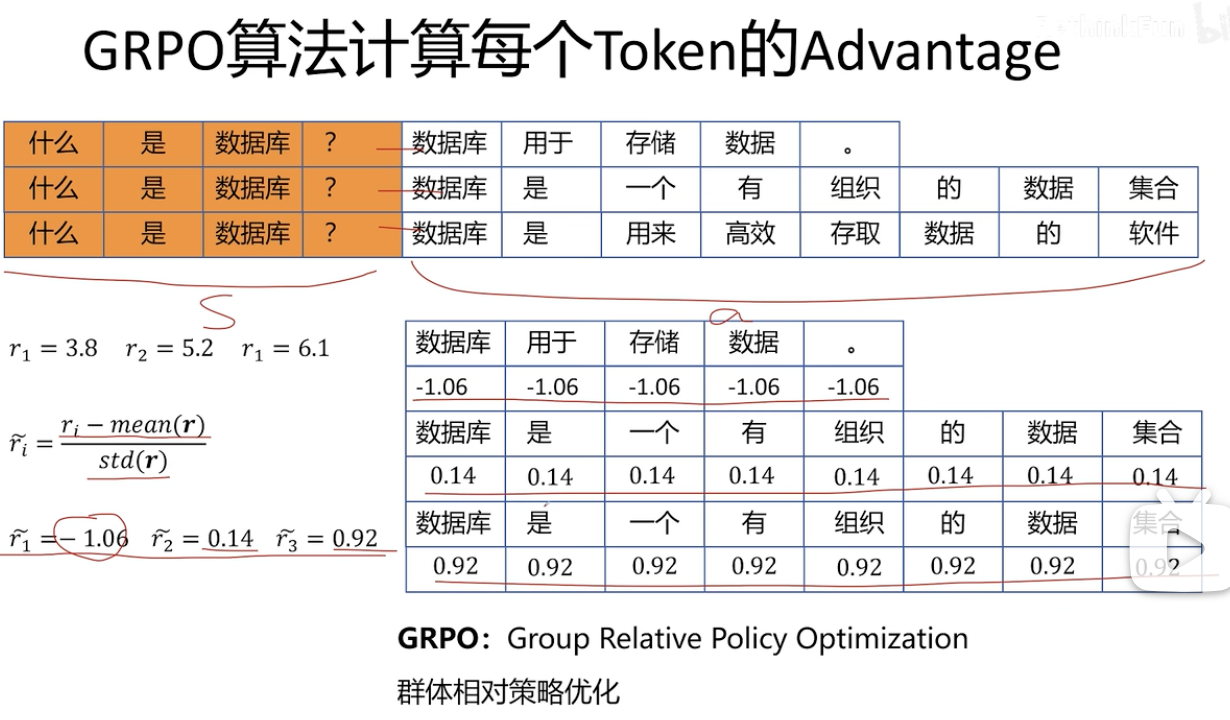
目标函数如下:
L(θ)=Ex∼πθ[min(r(x)⋅Arel(x), clip(r(x),1−ε,1+ε)⋅Arel(x))]−β⋅KL[πθ∥πold] \mathcal{L}(\theta) = \mathbb{E}_{x \sim \pi_\theta} \left[ \min \left( r(x) \cdot A^{\text{rel}}(x), \, \text{clip}(r(x), 1 - \varepsilon, 1 + \varepsilon) \cdot A^{\text{rel}}(x) \right) \right] - \beta \cdot \mathrm{KL}[\pi_\theta \| \pi_{\text{old}}] L(θ)=Ex∼πθ[min(r(x)⋅Arel(x),clip(r(x),1−ε,1+ε)⋅Arel(x))]−β⋅KL[πθ∥πold]
其中:
- r(x)=πθ(x)πold(x)r(x) = \frac{\pi_\theta(x)}{\pi_{\text{old}}(x)}r(x)=πold(x)πθ(x):策略比率(policy ratio)
- Arel(x)=rx−μrσr+δA^{\text{rel}}(x) = \frac{r_x - \mu_r}{\sigma_r + \delta}Arel(x)=σr+δrx−μr:组内相对优势(group-relative advantage)
- KL[πθ∥πold]\mathrm{KL}[\pi_\theta \| \pi_{\text{old}}]KL[πθ∥πold]:KL 散度正则项
- ε\varepsilonε:裁剪阈值,通常为 0.1 或 0.2
- β\betaβ:KL 散度惩罚强度
- δ\deltaδ:小数平滑项,防止除以零
二、各组成部分详细解析
2.1 相对优势 Arel(x)A^{\text{rel}}(x)Arel(x)
对于一个输入 prompt qqq,模型生成 NNN 个样本输出 {x1,x2,…,xN}\{x_1, x_2, \dots, x_N\}{x1,x2,…,xN},并为每个输出打分得奖励 {r1,r2,…,rN}\{r_1, r_2, \dots, r_N\}{r1,r2,…,rN}。
则组内归一化优势计算为:
Arel(xi)=ri−μrσr+δ,其中μr=1N∑j=1Nrj,σr=1N∑j=1N(rj−μr)2 A^{\text{rel}}(x_i) = \frac{r_i - \mu_r}{\sigma_r + \delta}, \quad \text{其中} \quad \mu_r = \frac{1}{N} \sum_{j=1}^N r_j, \quad \sigma_r = \sqrt{\frac{1}{N} \sum_{j=1}^N (r_j - \mu_r)^2} Arel(xi)=σr+δri−μr,其中μr=N1j=1∑Nrj,σr=N1j=1∑N(rj−μr)2
✅ 作用:不依赖外部奖励模型,而是仅在组内对表现做排序,抵抗评分偏移与缩放干扰。
2.2 策略比率 r(x)r(x)r(x)
表示新策略生成该输出的概率相较于旧策略的变化:
r(x)=πθ(x)πold(x)=exp(logπθ(x)−logπold(x)) r(x) = \frac{\pi_\theta(x)}{\pi_{\text{old}}(x)} = \exp\left( \log \pi_\theta(x) - \log \pi_{\text{old}}(x) \right) r(x)=πold(x)πθ(x)=exp(logπθ(x)−logπold(x))
✅ 作用:衡量当前策略对该输出的支持程度变化。
2.3 裁剪函数(Clipping)
裁剪策略比率的变化范围,避免策略剧烈变化,公式:
min(r(x)⋅Arel(x), clip(r(x),1−ε,1+ε)⋅Arel(x)) \min \left( r(x) \cdot A^{\text{rel}}(x), \, \text{clip}(r(x), 1 - \varepsilon, 1 + \varepsilon) \cdot A^{\text{rel}}(x) \right) min(r(x)⋅Arel(x),clip(r(x),1−ε,1+ε)⋅Arel(x))
- 如果 r(x)r(x)r(x) 变化不大于 ε\varepsilonε,使用原始项
- 如果变化过大,使用裁剪项来限制更新
✅ 作用:提高训练稳定性,防止策略崩溃(即新策略偏离旧策略过远)。
2.4 KL 散度正则项
为了进一步防止策略崩坏,引入 KL 散度:
KL[πθ∥πold]=∑xπθ(x)⋅log(πθ(x)πold(x)) \mathrm{KL}[\pi_\theta \| \pi_{\text{old}}] = \sum_{x} \pi_\theta(x) \cdot \log \left( \frac{\pi_\theta(x)}{\pi_{\text{old}}(x)} \right) KL[πθ∥πold]=x∑πθ(x)⋅log(πold(x)πθ(x))
惩罚策略更新过快的行为,β 控制强度:
最终目标=clipped PPO 目标−β⋅KL 散度 \text{最终目标} = \text{clipped PPO 目标} - \beta \cdot \text{KL 散度} 最终目标=clipped PPO 目标−β⋅KL 散度
✅ 作用:鼓励保守更新,控制策略漂移。
三、优化过程解析
总结一轮优化流程如下:
- 采样输出:对每个 prompt,采样多个输出 xi∼πθx_i \sim \pi_\thetaxi∼πθ
- 打分奖励:基于规则或运行测试,获得 rir_iri
- 归一化奖励:计算组内均值/方差,获得 Arel(xi)A^{\text{rel}}(x_i)Arel(xi)
- 计算策略比率:对每个样本计算新旧概率比 r(xi)r(x_i)r(xi)
- 裁剪 + KL 正则:带入 GRPO 目标函数,求解梯度
- 更新策略参数:使用优化器(如 Adam)更新参数 θ
🔍 四、GRPO 与 PPO 的对比简述

PPO: 策略模型 + 奖励模型 + 价值模型+基准模型
GRPO: 策略模型 + 奖励模型(基线用组平均替代,不需要 Value Model)+基准模型
| 方面 | PPO | GRPO |
|---|---|---|
| 奖励来源 | 通常需要训练的奖励模型 | 组内相对评分,无需额外模型 |
| 优势函数 | 通常需要 baseline(如 value 网络) | 组内标准化后奖励,直接构造优势 |
| 稳定性控制 | 剪裁策略比率 + KL 散度 | 相同机制,剪裁 + KL 控制偏移 |
| 实用性 | 更灵活但训练复杂 | 简洁高效,易于部署 |
举个栗子🌰
第一阶段:数据构造与策略初始化
1.1 模型初始化
- 使用预训练模型作为初始策略,例如
DeepSeek-V3-Base或LLaMA-2-13B。 - 用有监督微调(SFT)方式,提前教模型如何按照模板回答数学问题:
<think>这里写推理过程</think><answer>最终答案</answer>
👉 目的:初始化模型时已经能学会“格式感知”式的推理方式。
1.2 Prompt 设定
给定数学题目:
User: 小明用5元钱买了3支铅笔,每支铅笔多少钱?
此时模型作为策略 πθ\pi_{\theta}πθ,会生成多个答案。
第二阶段:采样与评分
✅ 2.1 多样性采样
对每个 Prompt(数学题),采样 K=8∼16K = 8 \sim 16K=8∼16 个推理路径,用温度采样(temperature > 1)或 top-k / nucleus sampling 增强多样性。
✅ 2.2 采样输出示例(共 4 个)
| 输出编号 | 模型生成内容 |
|---|---|
| Output 1 | 5 / 3 = 1.671.67 |
| Output 2 | 5元买3支,平均每支 1.67 元1.67 |
| Output 3 | 用除法:5÷3 = 1.671.67 |
| Output 4 | 3元每支3 |
✅ 2.3 定义奖励函数(基于规则,无需奖励模型)
我们可以设置如下奖励:
| 奖励项目 | 定义 | 分值规则 |
|---|---|---|
| 准确性奖励 | <answer> 是否是 1.67 |
1(正确) / 0(错误) |
| 格式奖励 | 是否同时有 <think> 和 <answer> |
1(完整) / 0(缺失) |
| 推理合理性奖励(可选) | <think> 是否使用除法 |
1 / 0 |
例如:
| 输出编号 | 准确性奖励 | 格式奖励 | 合计 r 值 |
|---|---|---|---|
| 1 | 1 | 1 | 2 |
| 2 | 1 | 1 | 2 |
| 3 | 1 | 1 | 2 |
| 4 | 0 | 1 | 1 |
第三阶段:计算组内相对优势(核心公式)
✅ 3.1 奖励向量
r=[2,2,2,1] \mathbf{r} = [2, 2, 2, 1] r=[2,2,2,1]
计算均值和标准差:
- μr=2+2+2+14=1.75\mu_r = \frac{2 + 2 + 2 + 1}{4} = 1.75μr=42+2+2+1=1.75
- σr=(2−1.75)2×3+(1−1.75)24=0.18751≈0.43\sigma_r = \sqrt{\frac{(2 - 1.75)^2 \times 3 + (1 - 1.75)^2}{4}} = \sqrt{\frac{0.1875}{1}} \approx 0.43σr=4(2−1.75)2×3+(1−1.75)2=10.1875≈0.43
✅ 3.2 计算相对优势(归一化奖励)
Airel=ri−μrσr A_i^{\text{rel}} = \frac{r_i - \mu_r}{\sigma_r} Airel=σrri−μr
| 输出编号 | r | AirelA_i^{\text{rel}}Airel |
|---|---|---|
| 1 | 2 | (2−1.75)/0.43≈0.58(2 - 1.75)/0.43 ≈ 0.58(2−1.75)/0.43≈0.58 |
| 2 | 2 | ≈ 0.58 |
| 3 | 2 | ≈ 0.58 |
| 4 | 1 | (1−1.75)/0.43≈−1.74(1 - 1.75)/0.43 ≈ -1.74(1−1.75)/0.43≈−1.74 |
第四阶段:策略优化(GRPO核心目标函数)
我们用 GRPO 的目标函数优化策略:
✅ 4.1 策略比率计算
假设某个输出 xix_ixi 的新旧策略概率分别为:
- πθ(xi)=0.01\pi_\theta(x_i) = 0.01πθ(xi)=0.01
- πold(xi)=0.005\pi_{\text{old}}(x_i) = 0.005πold(xi)=0.005
策略比率:
ri=πθ(xi)πold(xi)=2.0 r_i = \frac{\pi_\theta(x_i)}{\pi_{\text{old}}(x_i)} = 2.0 ri=πold(xi)πθ(xi)=2.0
✅ 4.2 裁剪函数(Clipped Ratio)
clip(ri,1−ε,1+ε),ε=0.2 \text{clip}(r_i, 1-\varepsilon, 1+\varepsilon),\quad \varepsilon = 0.2 clip(ri,1−ε,1+ε),ε=0.2
若 ri=2.0r_i = 2.0ri=2.0,则被裁剪为 1.21.21.2
✅ 4.3 GRPO 目标函数(单个样本)
Li=min(ri⋅Airel,clip(ri)⋅Airel)−β⋅DKL[πθ∣∣πold] \mathcal{L}_i = \min(r_i \cdot A_i^{\text{rel}}, \text{clip}(r_i) \cdot A_i^{\text{rel}}) - \beta \cdot D_{\text{KL}}[\pi_\theta || \pi_{\text{old}}] Li=min(ri⋅Airel,clip(ri)⋅Airel)−β⋅DKL[πθ∣∣πold]
其中:
- 优势越大、奖励越高的输出,其 loss 趋于负(表示增加该样本概率)
- 优势小的样本 loss 趋于正(抑制其概率)
🔁 第五阶段:循环迭代训练
每轮训练流程如下:
- 采样 N 个 Prompt,每个采样 8~16 个输出;
- 计算规则奖励,得出组内优势;
- 计算策略比率并裁剪;
- 优化策略模型(如使用 AdamW);
- 每若干轮评估模型能力是否进步(准确率/格式合规率)。
PPO与GRPO对比
1. PPO
✅ 核心依赖:
- 策略模型(Policy):LLM
- 奖励模型(Reward Model):通常用人类反馈训练
- 状态价值模型(Value Model / Critic):单独训练的模型,用于估计某个“Prompt”在当前策略下的预期总奖励 V(s)V(s)V(s)
PPO 中 Advantage(优势)的计算:
At=rt−V(st) A_t = r_t - V(s_t) At=rt−V(st)
也可以是 GAE 形式:At=A^t=∑l=0∞(γλ)lδt+lA_t = \hat{A}_t = \sum_{l=0}^{\infty} (\gamma \lambda)^l \delta_{t+l}At=A^t=∑l=0∞(γλ)lδt+l
-GRPO(Group Relative Policy Optimization):不使用价值模型
2.GRPO
不再需要 Value Function:
- 不再拟合 V(s);
- 不再计算 TD 误差;
- 不再依赖 bootstrapping;
- 优化目标只基于当前批次中各输出的相对排名。
两者Advantage 计算方式对比
| 项目 | PPO | GRPO |
|---|---|---|
| 优势估计 | At=rt−V(st)A_t = r_t - V(s_t)At=rt−V(st) | Ai=ri−μσA_i = \frac{r_i - \mu}{\sigma}Ai=σri−μ |
| 是否使用 Critic 模型 | ✅ 是 | ❌ 否 |
| 需要拟合状态值 V(s) | ✅ 需要 | ❌ 不需要 |
| 是否可用于长期奖励估计 | ✅ 是 | ❌ 否,偏向短期任务(如文本生成) |
| 优势依赖于状态 | ✅(V depends on state) | ❌(仅与组内 reward 相对关系有关) |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)