Dify 2.0.0 beta.2 发布,4 大提升,AI 开发效率飞升!
第二步,文字部分送到文本理解模块;不过,一个由我们中国团队主导的开源项目Dify,最近发布了一个新版本,叫Dify 2.0.0 beta.2,它就像是给AI应用开发领域带来了一套全新的、高效的施工方案,让原来复杂的事情变得简单了许多。现在,具备了多模态能力的AI可以直接“看”懂整张发票的布局,它能准确地知道哪个是抬头,哪个是总金额,中间的表格里又有哪些具体的消费项目。但是,大家可能不太了解的是,在
最近,人工智能这个词可以说是无处不在,从我们手机里的智能助手,到各种能写文章、会画画的应用,我们每天都在享受着它带来的便利。
但是,大家可能不太了解的是,在这些光鲜亮丽的应用背后,开发它们的过程其实相当复杂和繁琐,对很多公司和开发者来说都是一个不小的挑战。
就像盖一座房子,你需要打地基、砌墙、接水电,每个环节都不能出错,而且成本还很高。
不过,一个由我们中国团队主导的开源项目Dify,最近发布了一个新版本,叫Dify 2.0.0 beta.2,它就像是给AI应用开发领域带来了一套全新的、高效的施工方案,让原来复杂的事情变得简单了许多。

这次更新主要有四个方面的重大提升,我们来用大白话一件一件地聊清楚,看看它到底解决了哪些实际问题。
首先,我们来谈谈第一个大提升,它解决的是AI“学习资料”的问题。
我们都知道,要想让AI变聪明,就得给它“喂”大量的资料去学习,这个过程在技术上叫做RAG,也就是检索增强生成。
简单来说,就是你给AI一堆文件,然后问它问题,它会从这些文件里找答案再告诉你。
这个想法很好,但在实际操作中却遇到了一个大麻烦。
比如,我们平时工作中最常见的PDF文件,里面不光有文字,还有很多重要的图表、图片和表格。
以前的AI在处理这种复杂文件时,往往会“犯迷糊”,它可能只认识文字,却把图表和图片当成不存在,或者因为格式太乱而读不懂。
这就好比你让一个学生看一篇图文并茂的科学报告,却蒙上他的眼睛只让他听文字,那他肯定无法完全理解报告里的核心信息。
这样一来,很多有价值的数据就白白浪费了,AI给出的答案自然也就不够准确和全面。
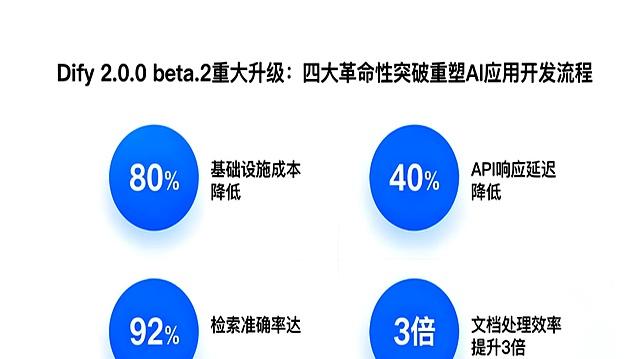
为了解决这个难题,Dify这次推出了一个叫做“知识管道”的新功能。
你可以把它理解成一个为信息处理量身定制的“精加工流水线”。
以前处理文件是一条路走到底,不管什么都用同一种方法,效果当然不好。
现在,Dify提供了七种不同的处理模板,就像工具箱里有锤子、螺丝刀、扳手一样,你可以根据文件的具体情况,自由组合这些工具来搭建一条最合适的处理流程。
比如说,一家金融公司需要处理大量的贷款合同PDF,这些合同里既有文字条款,也有关键的利率数据表格,还有客户的签名图片。
利用知识管道,他们可以这样设置流程:第一步,先用专门处理复杂PDF的模块把整个文件拆解开;第二步,文字部分送到文本理解模块;第三步,调用表格提取模块,把利率、还款期限这些关键数据精准地抓取出来,变成结构化的信息;第四步,再用图像识别模块去检查签名图片是否清晰有效。
整个过程分工明确,各司其职,就像一个配合默契的团队。
根据实际应用的数据来看,有金融企业用了这个功能后,查询和审核合同的效率直接提升了40%,这就是技术带来的实实在在的改变。
说完了AI如何更好地“读书”,我们再来看看第二个提升,它解决的是AI“干活”的效率和稳定性问题。
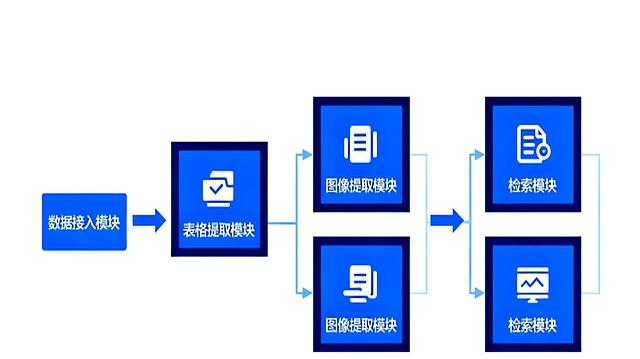
一个AI应用的工作流程,通常是由好几个步骤串联起来的。
比如一个电商网站的自动处理订单系统,它可能需要先查询商品库存,然后验证顾客的收货地址,接着计算运费,最后再生成订单。
这个流程就像一串多米诺骨牌,如果中间任何一个环节出了问题,比如验证地址的网络突然卡了一下,整个任务就可能失败了。
尤其是在购物节这种订单量暴增的时候,系统很容易因为处理不过来而变得非常缓慢,甚至崩溃,用户体验会非常糟糕。
Dify推出的“队列式图引擎”就是来解决这个问题的。
它引入了一种叫做“任务队列”的机制,听起来有点专业,但原理很简单,就像我们在银行排队办业务一样。
当大量的订单请求涌进来时,系统不会乱作一团,而是把每个订单处理任务拆分成一个个小步骤,然后让它们在一个虚拟的队列里排好队。
系统会根据自己的处理能力,一个一个地、有条不紊地从队列里取出任务来执行。
这样做最大的好处就是稳定。
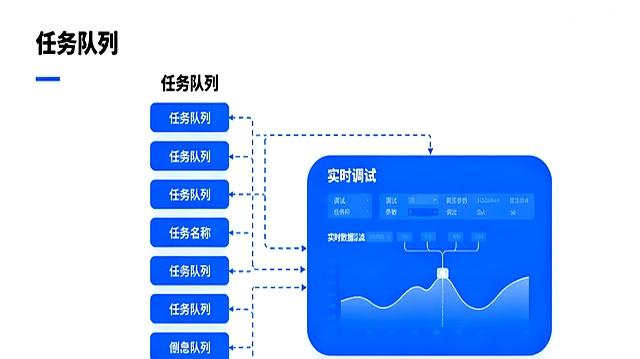
即使中间某个步骤失败了,比如地址验证不成功,它也不会影响到后面的其他任务。
系统会把这个失败的任务先放在一边,并做好标记,让开发者可以回过头来专门处理这个问题,甚至可以从失败的地方继续执行,而不需要整个流程重来一遍。
这大大增强了系统的可靠性。
同时,因为任务调度更加合理,系统的资源得到了充分利用,处理效率也大大提高。
官方数据显示,这个新引擎让应用的响应延迟降低了40%,而在电商订单处理这样的场景下,效率更是提升了三倍。
这意味着,系统在同样的时间内能处理比以前多三倍的订单,而且还不容易出错了。
第三个重大提升,是关于AI应用后台的“地基”——数据库架构。
一个功能完善的AI应用,背后往往需要不止一种数据库来支撑。
比如,用户的账号信息、交易记录这些格式规整的数据,通常存放在关系型数据库里;而为了让AI能理解语言文字的深层含义,还需要一种专门存放词语之间关联信息的向量数据库。

这就好`比一个大型超市,需要有存放蔬菜水果的冷藏库,也需要有存放零食饼干的常温库,管理起来很麻烦,成本也很高,而且不同仓库之间调配货物也很不方便。
Dify这次做了一个非常聪明的改变,它选择使用我们国家自主研发的一款非常优秀的数据库产品——TiDB,来统一管理所有数据。
TiDB的厉害之处在于,它像一个“全能型仓库”,既能很好地管理传统的关系型数据,又能高效地处理AI所需的向量数据。
这样一来,原来需要好几个不同系统才能完成的工作,现在一个系统就全搞定了。
最直接的好处就是大大简化了系统的复杂性,让维护变得更容易。
更重要的是,它极大地降低了成本。
根据Dify公布的数据,这次架构升级,让基础设施的成本降低了惊人的80%。
这对于很多预算有限的初创公司和中小企业来说,无疑是一个巨大的福音。
这不仅是一次技术上的优化,也体现了我们国产基础软件的强大实力。
最后,第四个提升是让AI拥有了“眼睛”,也就是多模态能力的增强。
在过去很长一段时间里,我们和AI的交流主要依赖于文字。
但我们生活的世界是丰富多彩的,充满了图片、图表和视频。
一个只会“读”不会“看”的AI,它的能力边界是显而易见的。
这次更新,Dify加强了对视觉语言模型的支持,比如能够兼容像阿里通义千问这样先进的模型。
这意味着,基于Dify开发的应用,不仅能听懂你说的话,还能看懂你发的图片。
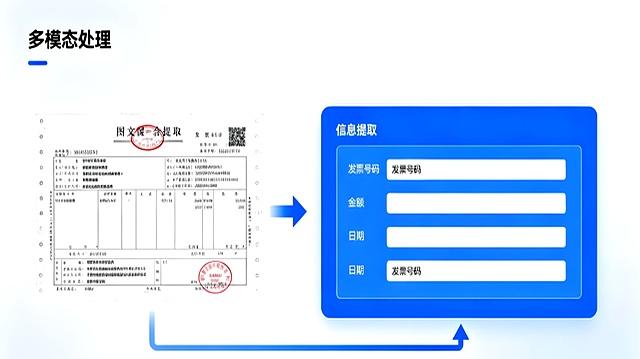
一个非常典型的例子就是智能发票识别。
一张发票上,有公司名称、开票日期、项目列表、金额、公章等各种信息。
以前的技术可能只能把上面的文字识别出来,但分不清哪个是哪个。
现在,具备了多模态能力的AI可以直接“看”懂整张发票的布局,它能准确地知道哪个是抬头,哪个是总金额,中间的表格里又有哪些具体的消费项目。
这项能力带来的效果是惊人的:一家公司的财务处理效率因此提升了300%,也就是原来需要三个人干的活现在一个人就能轻松搞定,而且机器识别的错误率降到了0.5%以下,比人工核对还要准确。
这种看图识意的能力,让AI的应用场景一下子被拓宽了,从金融、医疗到日常生活的方方面面,都能发挥出更大的价值。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)