系统架构设计师——【2025年上半年案例题】真题分享(一)
本文分享了2025年上半年系统架构设计师考试的两道案例题及详细解析。第一题针对在线大模型训练平台,分析了12个需求对应的质量属性,补充了解释器风格架构图,并解释了该架构的适用性。第二题关于医药领域智能问答系统,完善了基于知识图谱的系统架构图,补充了Scrapy框架组件,并建议采用图数据库存储知识图谱。文章为备考者提供了典型案例分析思路和专业知识解答,帮助理解系统架构设计中的关键概念和方法。
系统架构设计师——【2025年上半年案例题】真题分享(一)
这是 2025 年上半年系统架构设计师下午案例题的部分真题及详尽解析,希望能帮助你备考。
试题一:在线大模型训练平台的质量属性与架构风格
题目背景:
某公司开发一个在线大模型训练平台,支持 Python 代码编写、模型训练和部署。用户通过 Python 编写模型代码,将代码交给系统进行解析,最终由系统匹配相应的计算机资源进行输出,用户无需关心底层硬件。架构师李工认为该平台适合采用解释器风格架构。系统分析师调研的需求描述如下:
a. 系统发生错误时,异常请求能够不影响用户正常工作,并发送消息通知系统管理员。(可用性)
b. 平台应保护用户隐私,防止未授权访问。(安全性)
c. 系统界面能调整屏幕,适配用户提供的屏幕尺寸比例。(易用性)
d. 用户提交训练任务时应在一分钟内提供硬件和资源,启动训练。(性能)
e. 支持远程修改,供远程用户进行连接操作,仅提供给系统注册用户使用。(安全性)
f. 在训练时,应对请求 5 秒钟内提供队列信息。(性能)
g. 支持多语言界面,操作指南和文档。(易用性)
h. 发生故障时应在 15 秒钟内定位故障,解决故障。(可用性)
i. 系统发生故障时,要能提供操作日志。(可测试性)
j. 具备扩展能力,能够 3 天内完成新功能部署。(可修改性)
k. 数据库发生故障后,自动切换到备用数据库,保证训练不中断。(可用性)
l. 符合用户习惯的默认快捷键设置。(易用性)
问题 1:题干中列举了所有需求列表,请填写对应的质量属性。(12 分)
参考答案与解析:
软件质量属性是系统架构设计的核心考量点,用于评估软件在特定环境下满足预期需求的程度。
| 需求编号 | 质量属性 | 解析 |
|---|---|---|
| a | 可用性 | 系统发生错误时不影响正常用户工作,并能通知管理员,这体现了系统在故障时维持服务并快速恢复的能力,属于可用性范畴。 |
| b | 安全性 | 保护用户隐私和防止未授权访问直接关系到系统的安全防护和数据机密性。 |
| c | 易用性 | 系统界面适配不同屏幕尺寸,旨在提升用户交互体验,属于易用性。 |
| d | 性能 | 要求在一分钟内分配资源并启动训练,是对系统响应时间和效率的要求,属于性能属性。 |
| e | 安全性 | 支持远程修改但仅限注册用户,强调了对用户身份的认证和授权,核心是安全性。 |
| f | 性能 | 5 秒钟内提供队列信息,是对系统响应速度的明确性能指标。 |
| g | 易用性 | 支持多语言界面和文档,是为了让不同地区的用户更容易使用系统,提升了易用性。 |
| h | 可用性 | 要求快速定位和解决故障(15 秒内),旨在最大限度地减少系统中断时间,提高可用性。 |
| i | 可测试性 | 故障时提供操作日志,有助于开发或运维人员追踪和诊断问题根源,极大地提升了系统的可测试性。 |
| j | 可修改性 | 要求系统能快速(3 天内)扩展新功能,体现了系统应以较低成本、较高效率进行变更的能力,即可修改性。 |
| k | 可用性 | 数据库故障自动切换,是为了保证服务的连续性,是保障可用性的典型手段。 |
| l | 易用性 | 符合用户习惯的快捷键,旨在让用户更高效、便捷地操作软件,属于易用性。 |
问题 2:请补充完整下列解释器风格架构图。(6 分)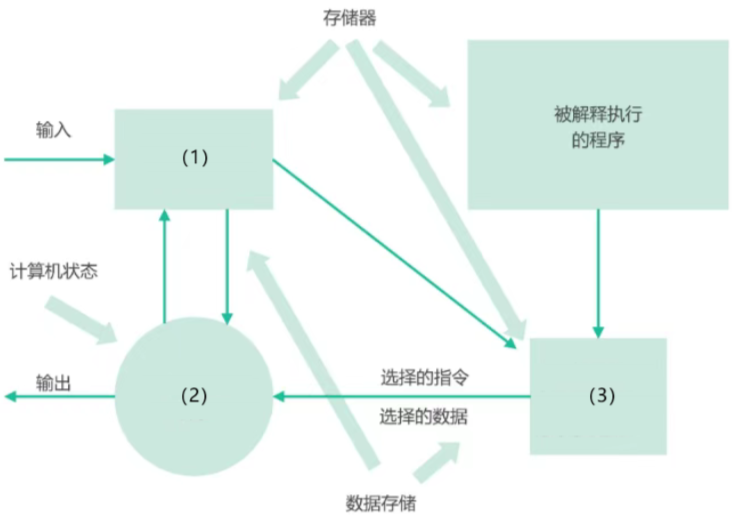
参考答案:
解释器风格是虚拟机架构风格的一种,其核心在于解释执行用户定义的指令或程序。
- 程序执行的当前状态 (或 “解释器引擎的内部状态”)
- 解释器引擎的内部状态 (或 “程序执行的当前状态”。这两个空位顺序可互换,共同构成解释器的上下文环境。)
- 解释器引擎 (或 “解释器”)
解析:
解释器风格架构通常包含以下几个核心部件:
- 解释器引擎 (Interpreter Engine):这是架构的核心,负责解析和执行输入的程序或脚本。
- 程序/脚本 (Program/Script):用户编写的代码,即需要被解释执行的指令集合。
- 程序状态/上下文 (Context):维护程序执行过程中的当前状态和信息(如变量、环境等)。
- 内部状态 (Internal State):解释器引擎自身运行所需的状态信息。
其工作流程通常是:解释器引擎读取用户程序,根据其内部状态和程序的当前执行状态,解释并执行每条指令,同时更新状态。
问题 3:请解释为什么该模型平台适合解释器风格。(7 分)
参考答案:
- 动态代码解析与执行:该平台的核心功能是接收用户提交的 Python 代码并动态执行。解释器风格无需预先编译,可直接解析和执行用户代码,完美契合了这一需求。用户无需关心底层硬件,正如解释器屏蔽了机器语言的细节。
- 灵活的资源动态匹配:解释器架构易于集成资源管理模块(如 Kubernetes)。在解析用户代码后,系统可以根据代码需求和当前资源状况,动态地分配和调度 GPU、CPU 等计算资源。这种动态性避免了静态绑定,提高了资源利用率。
- 良好的可扩展性:平台需要不断支持新的机器学习框架或算法。解释器风格通常支持插件或模块化扩展,新功能可以作为独立的解释模块添加到系统中,而无需修改核心解释引擎,这使得在 3 天内完成新功能部署成为可能。
试题二:医药领域智能问答系统与知识图谱
题目背景:
公司欲建设一个医院的智能问答系统,建立医院知识图谱。某工认为互联网的关键字检索无法满足需求,建议采用爬虫技术构建知识图谱。
问题 1:完善基于知识图谱的医药领域智能问答系统架构图。(10 分)
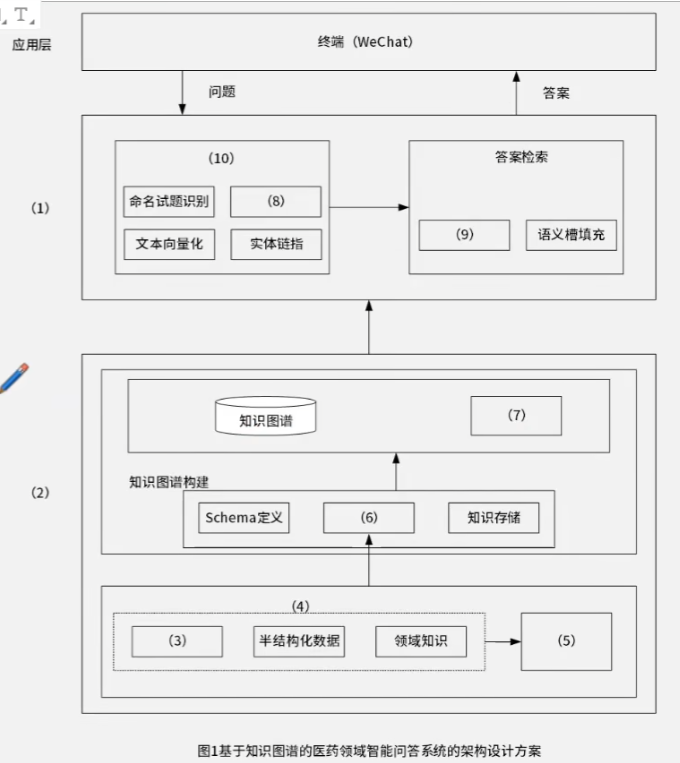
图中空白处需从选项中选择填写:(a)网络层、(b)数据层、©业务层、(d)知识层、(e)网页数据、(f)结构化数据、(g)数据采集、(h)知识获取、(i)知识清洗、(j)数据清洗、(k)知识管理、(l)实体获取、(m)关系获取、(n)意图识别、(o)语句解析、§知识检索。
参考答案与解析:
(1)c;(2)b;(3)f;(4)g;(5)j;(6)h;(7)k;(8)l;(9)p;(10)n
该架构通常分为三层,下图清晰地展示了各模块的归属和流程: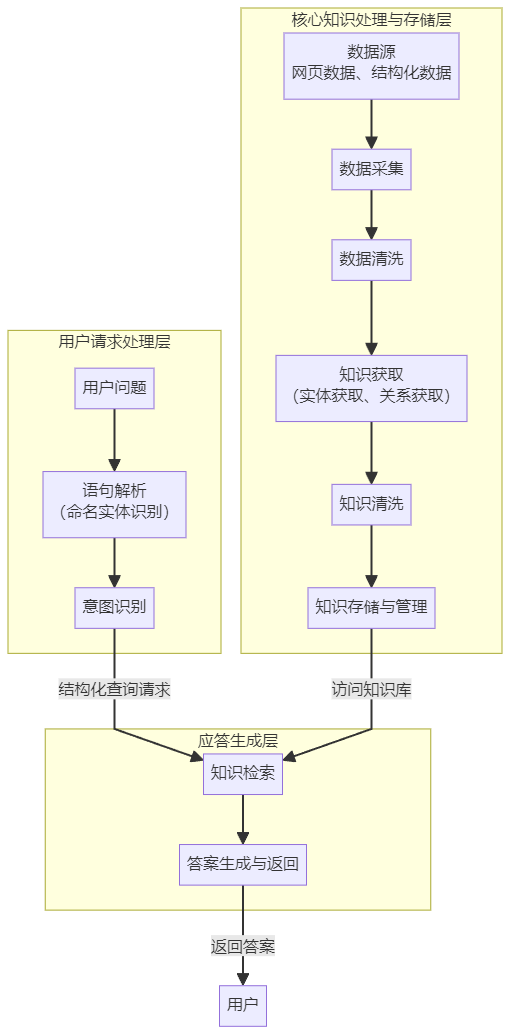
其核心流程是:数据处理管线(左下)持续从多源数据中抽取、清洗知识,并存入知识库;用户问答管线(上行)解析用户问题,检索知识库并生成答案。
问题 2:完善 Scrapy 框架架构图内容并用 200 字以内文字简要说明什么是异步 I/O。(6 分)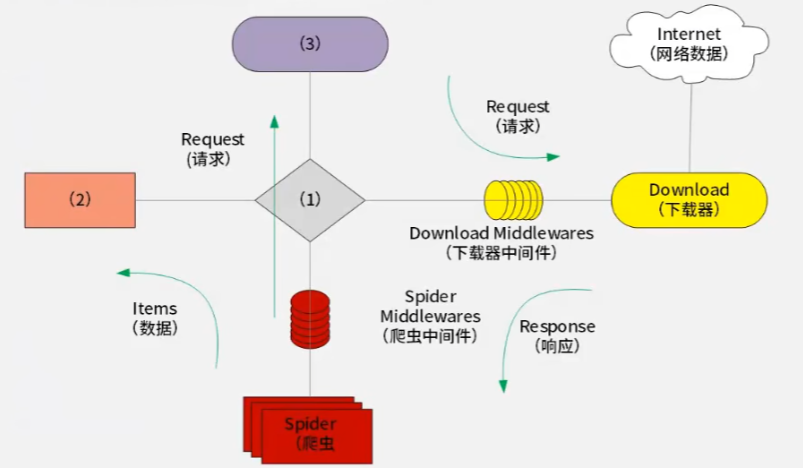
参考答案:
Scrapy 框架空白处补充:
(1) Scrapy 引擎 (Scrapy Engine):框架的核心,控制数据流,协调所有组件。
(2) 实体管道 (Item Pipeline):负责处理 Spider 提取的数据(即 Item),进行持久化、清洗、验证等操作。
(3) 调度器 (Scheduler):接收 Engine 的请求,并将其入队,等待下载。
异步 I/O 简要说明:
异步 I/O 是一种非阻塞的输入输出处理方式。程序发起 I/O 操作(如网络请求)后,无需等待其完成,可立即继续执行其他任务。当 I/O 操作完成后,系统通过回调、事件或通知机制告知程序获取结果。这种方式能充分利用 CPU 资源,避免线程空等阻塞,显著提升高并发场景下的吞吐量和响应速度。
问题 3:医药领域信息繁杂、数据量大,请用 300 字以内的文字简要说明该系统构建的医药领域知识图谱应采用何种方式进行知识存储,并说明原因。(9 分)
参考答案:
推荐采用图数据库(如 Neo4j、Nebula Graph)进行存储。
原因:
- 天然契合知识图谱的图结构:知识图谱本质上是包含实体(节点)和关系(边)的图模型。图数据库专门为存储和查询图结构数据而设计,能直接、直观地表示这种关联关系,无需像关系型数据库那样进行多表连接。
- 高效的关系查询能力:医药问答涉及大量的关系查询(如“某药物的副作用有哪些?”“某疾病与哪些基因有关?”)。图数据库基于图遍历的查询方式在处理多跳、深层次关系查询时,性能远优于传统关系数据库的多表 JOIN 操作。
- 良好的可扩展性:图数据库通常易于水平扩展,能够应对医药领域海量、持续增长的数据量。
- 灵活性:图数据库的 schema 相对灵活,易于适应医药领域知识的不断演进和变化。
希望这些详细的真题和解析能对你的备考有所帮助。系统架构设计师考试注重对知识点的理解和应用,祝你下半年考试顺利!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)