项目实战:LangExtract知识图谱构建和混合RAG在工业故障诊断中的应用(一)
本文介绍了如何利用生成式AI技术构建工业故障诊断知识图谱与智能问答系统。文章首先分析了工业领域存在的"非结构化知识困境",提出通过Google开源的LangExtract工具实现Schema驱动的知识抽取,将维修手册、故障报告等转化为结构化数据。随后详细阐述了构建工业知识图谱的全流程,包括本体设计、知识抽取与融合、Neo4j图数据库存储等关键技术。在实现层面,创新性地提出混合检
目录
- 第一部分:工业知识的“非结构化”困境与生成式AI的破局
- 第二部分:构建工业故障诊断知识图谱
- 第三部分:混合检索(Hybrid RAG)的实现与超越
- 第四部分:项目实践 —— 端到端工业故障诊断问答机器人
- 第五部分:企业级部署的挑战与远景
- 结语:开启工业智能的新篇章
想象一下这个场景:深夜,一座大型化工厂的核心压缩机突然发出异响,压力读数异常。值班工程师焦急地翻阅着数百页的PDF维修手册,同时在杂乱的电子表格中搜索相似的故障记录。每一分钟的停机都意味着巨大的经济损失。如果,此时他能像与一位资深专家对话一样,直接向系统提问:“C-101压缩机振动超标并伴有尖锐噪音,可能是什么原因?需要哪些备件?”系统不仅能秒级响应,还能给出详细的排查步骤、历史案例和备件清单。这听起来像是科幻电影,但今天,我们将亲手把这个梦想变为现实。
本文是一篇深度实践指南,我们将以“工业设备故障诊断与维修”这一极具挑战性的企业场景为核心,一步步带你构建一个真正的“工业大脑”。我们将利用 Google 最新开源的利器 LangExtract,将海量、非结构化的维修文档、故障报告转化为结构化的知识图谱。然后,通过构建一种先进的**混合检索增强生成(Hybrid RAG)**架构,融合向量检索的语义理解能力和图检索的逻辑推理能力,最终打造一个性能卓越、能够深度理解工业知识的智能问答系统。这不仅仅是一篇技术文章,更是一份完整的、可部署的实战蓝图。
第一部分:工业知识的“非结构化”困境与生成式AI的破局
1.1 维修手册与故障报告中的宝藏
在任何一个成熟的工业企业中,都积累了海量的知识财富。这些知识以各种形式存在:设备制造商提供的PDF操作手册、工程师填写的Word格式故障报告、Excel表格中的备件清单、老师傅们口耳相传的维修经验……它们共同构成了一个庞大的、但极度混乱的知识库。这种“非结构化”的特性,使得知识的检索、复用和传承变得异常困难,形成了所谓的“知识孤岛”。
传统的关键词搜索在这种场景下显得力不从心。当你搜索“轴承损坏”,你可能会得到上百个文档,但无法知道哪个与你当前面对的“高温、高振动”工况相关。我们需要一种能“理解”文本内容的技术,不仅知道“轴承”是一个实体,还能理解它与“过热”、“润滑不足”之间的因果关系。这正是信息抽取(Information Extraction, IE)技术的目标。然而,传统的IE方法往往依赖于复杂的规则和大量的标注数据,成本高昂且难以适应多变的工业场景。
1.2 LangExtract:不止于API封装的“Schema驱动”信息抽取利器
大语言模型(LLM)的出现为信息抽取带来了革命性的变化。它们强大的文本理解和生成能力,使得我们可以通过“提问”的方式从文本中获取结构化信息。然而,如何确保LLM稳定、可靠地按照我们想要的格式输出,并能追溯信息来源,是将其应用于严肃的企业场景的关键。
Google于2025年7月开源的Python库 LangExtract,正是为解决这一痛点而生。它并非简单的API封装,其核心思想是“Schema驱动”和“Few-Shot示例引导”。
- Schema驱动 (Schema-Driven): 你可以像定义一个Python数据类(如Pydantic模型)一样,精确地定义你想要抽取的信息结构(实体、属性、关系)。这为LLM提供了清晰的输出“模板”,极大地提升了输出的稳定性和可用性。
- Few-Shot示例引导 (Few-Shot Prompting): 你只需提供一两个高质量的标注示例,LangExtract就能“领会”你的意图,并将其泛化到新的文本上。这大大降低了对大量标注数据的依赖。
- 精确的源定位 (Source Grounding): LangExtract能够将抽取的每个信息点精确地关联回原文中的具体位置(span-level grounding),这对于需要审计和验证的企业应用至关重要。
- 长文本优化 (Optimized for Long Contexts): 它内置了分块(chunking)、并行处理和多遍抽取策略,能有效处理大型文档。
这些特性使得LangExtract成为构建企业级知识图谱的理想工具。它在灵活性、准确性和可追溯性之间取得了绝佳的平衡。
1.3 用LangExtract解析一份故障报告
让我们通过一个简单的例子,感受一下LangExtract的威力。假设我们有一份简短的故障报告文本。我们的目标是从中抽取出设备、故障现象、原因和解决方案。
首先,安装LangExtract库:
pip install langextract
接下来,我们用Python代码来定义抽取任务并执行:
import langextract as lx
import textwrap
from dataclasses import dataclass, field
from typing import List, Optional
# 步骤1: 定义我们想要抽取的数据结构 (Schema)
@dataclass
class FaultInfo:
"""描述一次设备故障的详细信息。"""
equipment_name: Optional[str] = field(default=None, metadata={"description": "发生故障的设备名称,例如 'P-101 离心泵'"})
phenomenon: Optional[str] = field(default=None, metadata={"description": "观察到的具体故障现象,例如 '出口压力下降20%'"})
cause: Optional[str] = field(default=None, metadata={"description": "分析得出的根本原因,例如 '密封环磨损'"})
solution: Optional[str] = field(default=None, metadata={"description": "采取的维修或解决方案,例如 '更换O型密封环'"})
@dataclass
class FaultReport:
"""从一份报告中抽取的故障信息列表。"""
faults: List[FaultInfo]
# 步骤2: 编写一个清晰的提示词 (Prompt)
prompt_desc = textwrap.dedent("""\
从工业设备故障报告中,按出现顺序抽取出故障信息。
请精确使用原文中的文本进行抽取,不要转述或概括。
为每个实体提供有意义的属性。""")
# 步骤3: 提供一个高质量的示例 (Few-Shot Example)
example = lx.data.ExampleData(
text="记录编号:20250910-01。巡检发现,P-101离心泵出口压力下降20%,伴随异常振动。初步判断为叶轮堵塞。处理措施:停机并清理叶轮异物。",
extractions=[
lx.data.Extraction(
extraction_class="FaultInfo",
extraction_text="P-101离心泵出口压力下降20%,伴随异常振动。初步判断为叶轮堵塞。处理措施:停机并清理叶轮异物。",
attributes={
"equipment_name": "P-101离心泵",
"phenomenon": "出口压力下降20%,伴随异常振动",
"cause": "叶轮堵塞",
"solution": "停机并清理叶轮异物"
}
)
]
)
# 步骤4: 在新的文本上运行抽取
input_text = "2025年9月11日,当班操作员报告,V-201反应釜的机械密封出现泄漏,现场有明显物料滴落。经检查,确认为法兰连接螺栓松动导致。已派维修工紧固所有螺栓,泄漏停止。"
# 注意:运行此代码需要配置你的LLM API Key (例如 Google Gemini)
# result = lx.extract(
# text_or_documents=input_text,
# prompt_description=prompt_desc,
# examples=[example],
# target_schemas=[FaultInfo], # 指定目标Schema
# model_id="gemini-1.5-pro-latest" # 使用支持的LLM模型
# )
# 模拟的输出结果
# 实际使用时,请取消上面代码的注释并配置好API Key
@dataclass
class MockExtraction:
extraction_class: str
extraction_text: str
attributes: dict
@dataclass
class MockResult:
text: str
extractions: List[MockExtraction]
result = MockResult(
text=input_text,
extractions=[
MockExtraction(
extraction_class='FaultInfo',
extraction_text='V-201反应釜的机械密封出现泄漏,现场有明显物料滴落。经检查,确认为法兰连接螺栓松动导致。已派维修工紧固所有螺栓,泄漏停止。',
attributes={
'equipment_name': 'V-201反应釜',
'phenomenon': '机械密封出现泄漏,现场有明显物料滴落',
'cause': '法兰连接螺栓松动',
'solution': '紧固所有螺栓'
}
)
]
)
# 打印结果
for extraction in result.extractions:
if extraction.extraction_class == 'FaultInfo':
info = FaultInfo(**extraction.attributes)
print(f"抽取的故障信息:")
print(f" - 设备名称: {info.equipment_name}")
print(f" - 故障现象: {info.phenomenon}")
print(f" - 根本原因: {info.cause}")
print(f" - 解决方案: {info.solution}")
正如你所见,仅通过一个简单的例子,LangExtract就能准确地从新文本中抽取出我们定义的结构化信息。这为我们自动化构建知识图谱奠定了坚实的基础。
第二部分:构建工业故障诊断知识图谱
零散的、结构化的信息虽然有用,但它们的真正威力在于被连接起来,形成一张巨大的知识网络——知识图谱(Knowledge Graph, KG)。在故障诊断领域,知识图谱可以将设备、故障、原因、解决方案、所需备件等实体连接起来,从而实现复杂的推理,例如“哪些原因都可能导致‘压力波动’?”或者“更换‘XX型号轴承’这个操作,通常与哪些设备的哪种故障相关?”
构建知识图谱通常遵循“自顶向下”和“自底向上”相结合的方法。我们首先“自顶向下”地设计图谱的顶层结构(即Schema或Ontology),然后“自底向上”地从数据中抽取实体和关系来填充这个图谱。
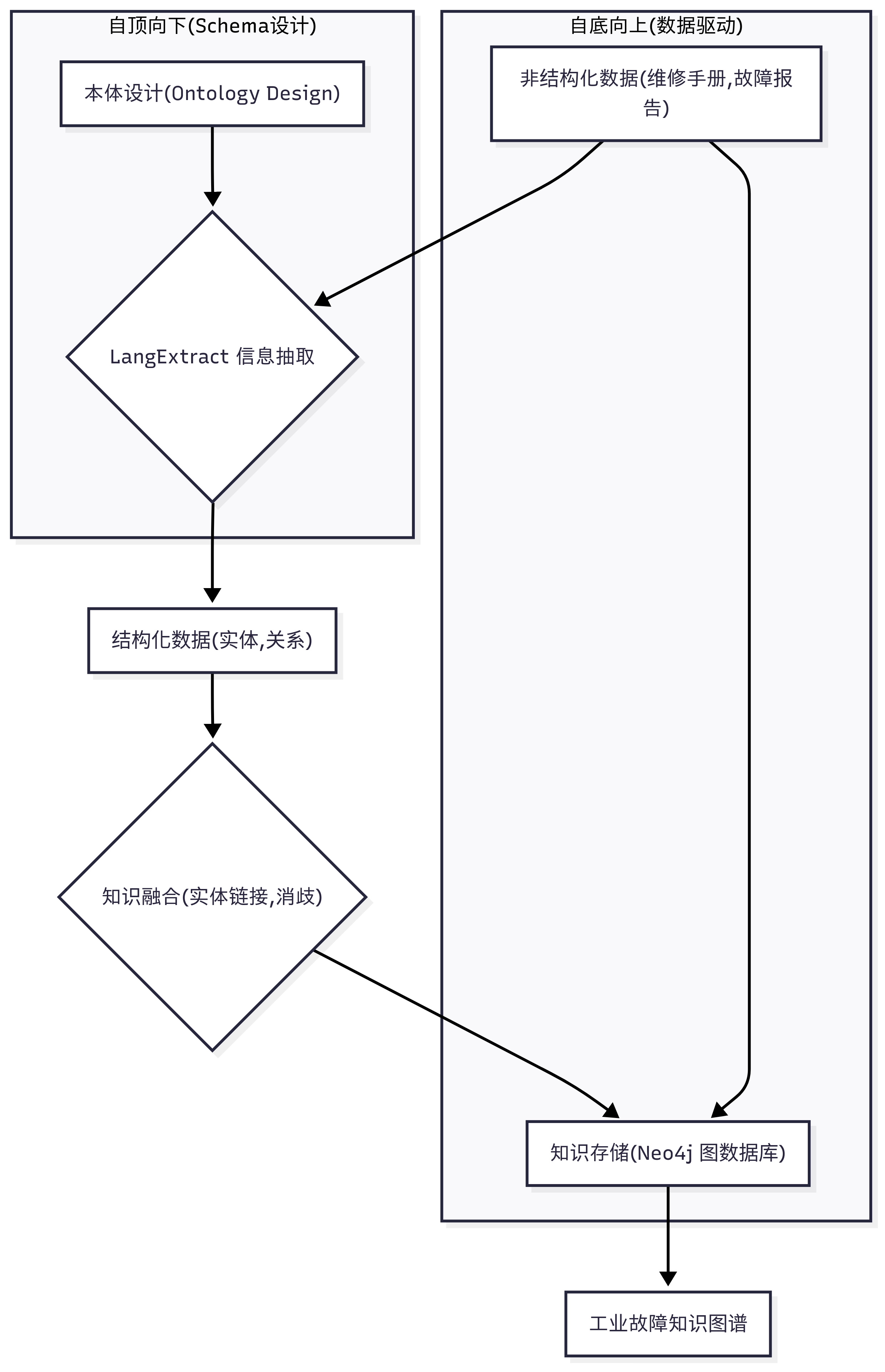
知识图谱构建流程
2.1 设计知识图谱的“本体”(Ontology)
“本体”是知识图谱的骨架,它定义了我们关心哪些类型的实体(节点)以及它们之间可能存在哪些类型的关系(边)。一个清晰的本体设计是知识图谱成功的关键。
对于工业故障诊断场景,我们可以设计如下的本体:
- 节点 (Labels):
- Equipment: 设备 (e.g., ‘C-101压缩机’, ‘P-205泵’)
- Component: 部件 (e.g., ‘轴承’, ‘密封’, ‘叶轮’)
- Fault: 故障事件 (e.g., ‘20250911_C101_Vibration’)
- Symptom: 症状/现象 (e.g., ‘振动超标’, ‘温度过高’)
- Cause: 原因 (e.g., ‘润滑油污染’, ‘转子不平衡’)
- Solution: 解决方案 (e.g., ‘更换润滑油’, ‘进行动平衡校正’)
- Document: 文档来源 (e.g., ‘C-101维修手册.pdf’)
- 关系 (Relationships):
- (Fault) -[:OCCURS_ON]-> (Equipment)
- (Fault) -[:HAS_SYMPTOM]-> (Symptom)
- (Fault) -[:HAS_CAUSE]-> (Cause)
- (Fault) -[:HAS_SOLUTION]-> (Solution)
- (Equipment) -[:HAS_COMPONENT]-> (Component)
- (Solution) -[:REQUIRES]-> (Component)
- (Fault) -[:MENTIONED_IN]-> (Document)
我们可以用Mermaid图来可视化这个本体结构:
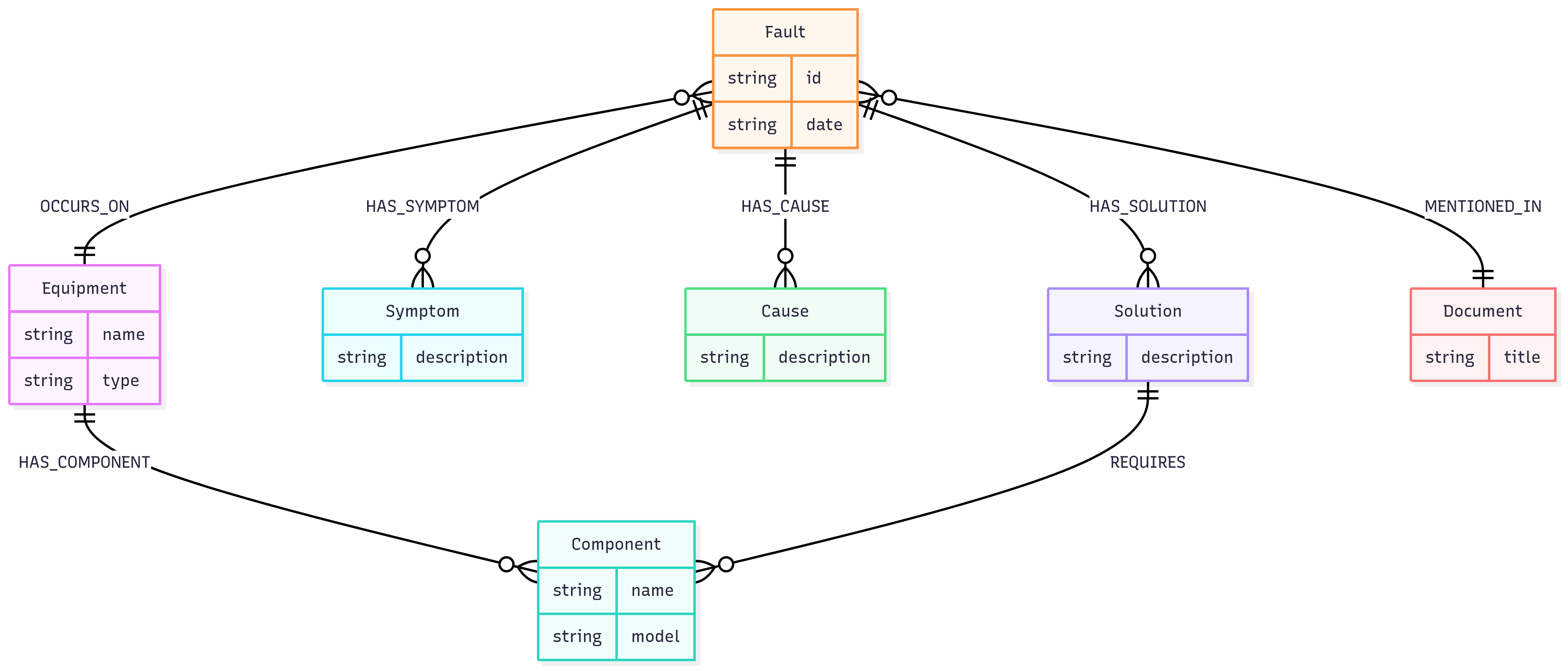
工业故障诊断知识图谱本体(Schema)
2.2 用LangExtract实现规模化知识抽取
有了清晰的蓝图,我们就可以利用LangExtract来自动化地从成百上千的文档中抽取知识了。这里的关键是设计一个更全面的Schema,使其能够覆盖我们本体中定义的多种实体和关系。
我们将扩展之前的FaultInfo,并增加对关系的抽取。LangExtract本身更侧重于实体及其属性的抽取,对于关系的抽取,我们可以设计一个巧妙的Schema,将关系作为一种特殊的“实体”来抽取,或者在抽取实体后,通过分析其上下文来推断关系。
一个更实用的策略是分两步走:首先,用LangExtract大规模抽取所有相关的实体(设备、症状、原因、方案);然后,再次利用LLM(或更传统的NLP方法)来识别这些已抽取实体之间的关系。
下面是使用LangExtract进行实体抽取的代码框架。在实际项目中,你需要遍历所有文档,并将抽取结果汇总。
# 扩展我们的Schema以包含更多实体类型
@dataclass
class ExtractedEntity:
"""从文本中抽取的单个实体。"""
entity_type: str = field(metadata={"description": "实体类型,必须是 ['Equipment', 'Component', 'Symptom', 'Cause', 'Solution'] 中的一个"})
entity_text: str = field(metadata={"description": "从原文中抽取的实体文本"})
@dataclass
class DocumentExtractions:
"""一份文档中所有抽取的实体。"""
source_document: str
entities: List[ExtractedEntity]
# 提示词和示例也需要相应更新,以指导模型抽取多种类型的实体
# ... 此处省略更新后的prompt和example的详细代码,原理同上 ...
def process_documents(documents: List[str]) -> List[DocumentExtractions]:
"""
批量处理文档,使用LangExtract抽取实体。
"""
all_results = []
# 伪代码:在实际应用中,这里会是一个循环,并调用lx.extract
for doc_content in documents:
# result = lx.extract(...)
# 假设我们得到了类似下面的模拟结果
mock_extractions = DocumentExtractions(
source_document="fault_report_001.txt",
entities=[
ExtractedEntity(entity_type='Equipment', entity_text='V-201反应釜'),
ExtractedEntity(entity_type='Component', entity_text='机械密封'),
ExtractedEntity(entity_type='Symptom', entity_text='泄漏'),
ExtractedEntity(entity_type='Cause', entity_text='法兰连接螺栓松动'),
ExtractedEntity(entity_type='Solution', entity_text='紧固所有螺栓'),
]
)
all_results.append(mock_extractions)
return all_results
# 假设我们有一批文档
docs_to_process = [
"2025年9月11日,当班操作员报告,V-201反应釜的机械密封出现泄漏,现场有明显物料滴落。经检查,确认为法兰连接螺栓松动导致。已派维修工紧固所有螺栓,泄漏停止。",
# ... 更多文档
]
extracted_data = process_documents(docs_to_process)
print(extracted_data)
2.3 知识的融合与持久化:从DataFrame到Neo4j图数据库
抽取出的实体往往存在冗余和别名问题,例如“C-101压缩机”和“一号压缩机”可能指向同一个设备。这个过程称为实体链接(Entity Linking)或实体解析(Entity Resolution)。在简单的场景中,我们可以通过字符串归一化和字典匹配来解决。在复杂场景中,可能需要更高级的向量相似度匹配或训练专门的模型。
在完成实体链接后,我们就可以将这些知识存入图数据库了。Neo4j是目前最流行的图数据库之一,它使用Cypher查询语言,非常直观。我们将使用官方的neo4j Python驱动来完成这个过程。
首先,安装驱动:
pip install neo4j pandas
然后,我们可以编写一个Python脚本,将抽取并处理好的数据写入Neo4j。为了方便处理,我们先将数据整理到Pandas DataFrame中。
import pandas as pd
from neo4j import GraphDatabase
# 假设这是经过实体链接和关系构建后的数据
# 在实际项目中,这一步需要精心设计,比如通过LLM判断实体间关系
data = {
'fault_id': ['F001'],
'equipment_name': ['V-201反应釜'],
'symptom': ['机械密封泄漏'],
'cause': ['法兰连接螺栓松动'],
'solution': ['紧固所有螺栓'],
'document': ['fault_report_002.txt']
}
df = pd.DataFrame(data)
class Neo4jUploader:
def __init__(self, uri, user, password):
self.driver = GraphDatabase.driver(uri, auth=(user, password))
def close(self):
self.driver.close()
def upload_fault_data(self, record):
with self.driver.session() as session:
session.execute_write(self._create_and_link, record)
@staticmethod
def _create_and_link(tx, record):
# 使用MERGE确保节点和关系的唯一性,避免重复创建
query = (
"MERGE (d:Document {title: $document}) "
"MERGE (e:Equipment {name: $equipment_name}) "
"MERGE (sy:Symptom {description: $symptom}) "
"MERGE (c:Cause {description: $cause}) "
"MERGE (so:Solution {description: $solution}) "
"MERGE (f:Fault {id: $fault_id}) "
"MERGE (f)-[:OCCURS_ON]->(e) "
"MERGE (f)-[:HAS_SYMPTOM]->(sy) "
"MERGE (f)-[:HAS_CAUSE]->(c) "
"MERGE (f)-[:HAS_SOLUTION]->(so) "
"MERGE (f)-[:MENTIONED_IN]->(d)"
)
tx.run(query,
document=record['document'],
equipment_name=record['equipment_name'],
symptom=record['symptom'],
cause=record['cause'],
solution=record['solution'],
fault_id=record['fault_id'])
# --- 主程序 ---
# 注意:请确保你的Neo4j数据库已启动
NEO4J_URI = "bolt://localhost:7687"
NEO4J_USER = "neo4j"
NEO4J_PASSWORD = "your_password" # 替换为你的密码
uploader = Neo4jUploader(NEO4J_URI, NEO4J_USER, NEO4J_PASSWORD)
for index, row in df.iterrows():
uploader.upload_fault_data(row)
print(f"Uploaded fault {row['fault_id']}")
uploader.close()
执行完毕后,你就可以在Neo4j Browser中看到一个由故障报告转化而来的知识图谱了!这个图谱就是我们“工业大脑”的记忆核心。
第三部分:混合检索(Hybrid RAG)的实现与超越
有了知识图谱,我们如何利用它来回答问题呢?这就是检索增强生成(RAG)技术大显身手的舞台。RAG的核心思想是:当LLM被提问时,先从外部知识库中检索相关信息,然后将这些信息作为上下文(Context)连同原始问题一起交给LLM,让它基于给定的信息来生成答案。这能有效减少LLM的“幻觉”问题,并使其能利用私有或实时更新的知识。
3.1 向量检索 vs. 图检索
在RAG中,“检索”是关键。目前主流的检索方式有两种:
向量检索 (Vector Search): 这是最常见的RAG形式。它将文本(如故障描述)转换成高维向量(Embedding),存储在向量数据库中(如FAISS, Milvus, 或Neo4j的向量索引)。当用户提问时,将问题也转换成向量,然后通过计算向量间的相似度(如余弦相似度)来找到最相关的文本片段。
- 优点: 擅长处理语义模糊的查询。用户不需要知道精确的术语,比如搜索“设备抖得厉害”,它能匹配到包含“振动异常”的文档。
- 缺点: 它返回的是独立的文本块,缺乏对实体间深层、多跳关系的理解。它不知道“轴承A”和“润滑油B”共同导致了“故障C”。
图检索 (Graph Search): 它直接在知识图谱上进行查询。通过Cypher等图查询语言,可以精确地遍历节点和关系,进行多跳推理。
- 优点: 能够揭示实体间的复杂关系和隐藏模式。非常适合回答需要逻辑推理的问题,如“找出所有因‘润滑失效’导致,且需要更换‘密封件’的故障案例”。
- 缺点: 对用户的提问要求较高,需要将自然语言准确地翻译成图查询语句(Text2Cypher),这本身就是一个难题。而且对于开放性的语义查询,它无能为力。
简单来说,向量检索回答了“什么内容与我的问题相似?”,而图检索回答了“实体之间如何连接?”
3.2 混合RAG架构解析
既然两种检索方式各有优劣,一个自然的想法就是将它们结合起来,形成混合检索(Hybrid RAG)。这种架构旨在同时利用向量的语义匹配能力和图的逻辑推理能力,提供更全面、更精准的上下文。
我们的混合检索流程如下:
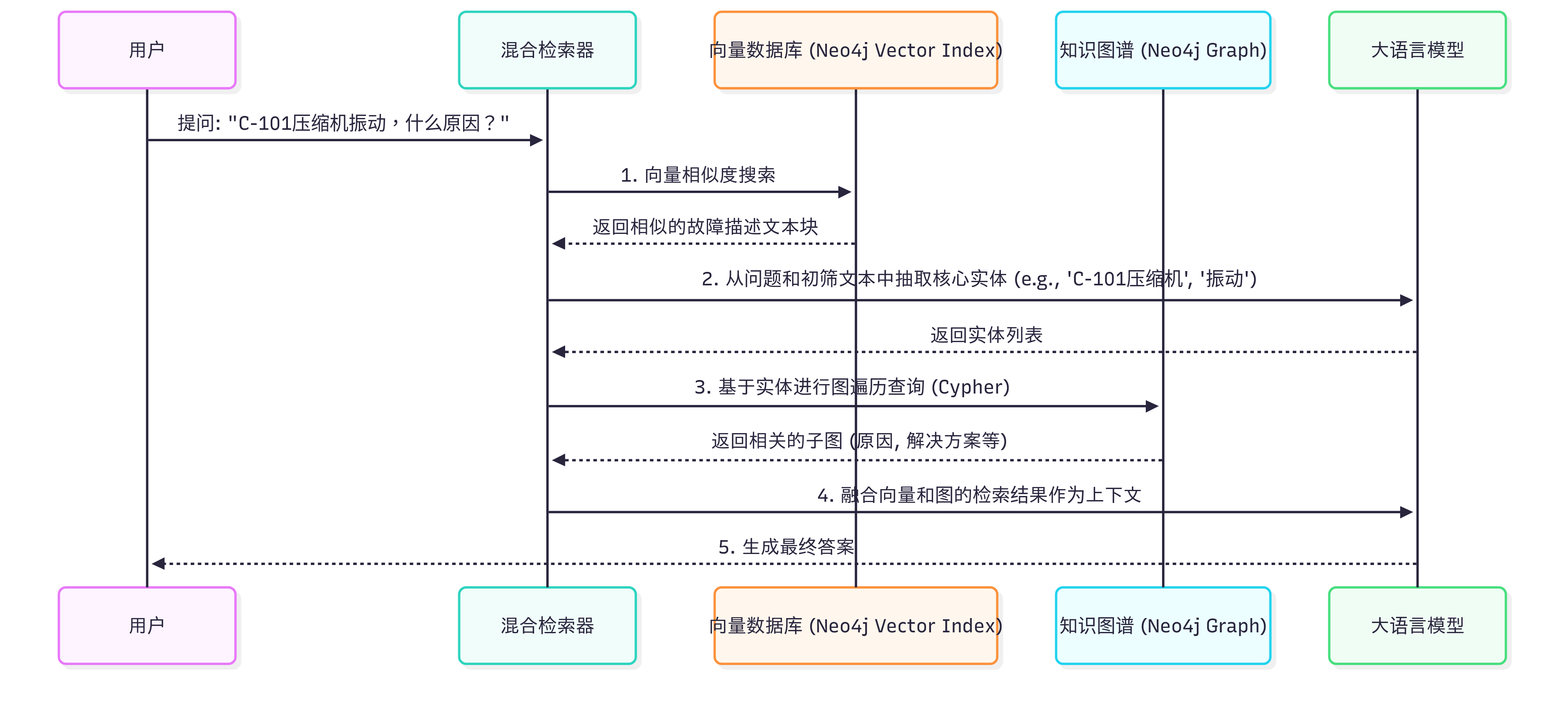
混合RAG(Hybrid RAG)工作流程
这个流程的核心在于:首先用向量检索进行一个“粗筛”,快速定位到语义相关的文档或故障记录。然后,从这些粗筛结果和用户问题中识别出关键实体。最后,将这些实体作为“锚点”,在知识图谱中进行深度、精准的图检索,挖掘出因果链、解决方案等结构化知识。最终,将两部分检索结果共同提供给LLM,生成答案。
3.3 核心引擎:在LangChain中构建自定义混合检索器
LangChain为我们提供了强大的抽象和工具链,让构建复杂的RAG系统变得简单。我们可以通过继承BaseRetriever类来创建自己的混合检索器。
首先,确保你已安装LangChain及相关依赖:
pip install langchain langchain-openai langchain-neo4j
接下来,我们来实现这个HybridRetriever。这里我们假设向量索引和知识图谱都存储在同一个Neo4j实例中,这简化了架构。
from langchain_core.retrievers import BaseRetriever
from langchain_core.callbacks import CallbackManagerForRetrieverRun
from langchain_core.documents import Document
from langchain_neo4j import Neo4jVector
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from neo4j import GraphDatabase
from typing import List
class HybridRetriever(BaseRetriever):
def __init__(self, neo4j_vector_store: Neo4jVector, neo4j_driver, llm, k: int = 4):
super().__init__()
self.vector_store = neo4j_vector_store
self.driver = neo4j_driver
self.llm = llm
self.k = k
def _get_relevant_documents(
self, query: str, *, run_manager: CallbackManagerForRetrieverRun
) -> List[Document]:
# --- 步骤1: 向量检索 ---
vector_results = self.vector_store.similarity_search(query, k=self.k)
# --- 步骤2: 从问题中抽取实体 ---
# 使用LLM从查询中提取实体
entity_extraction_prompt = f"""
从以下问题中抽取出设备名称或组件名称。
问题: "{query}"
只返回实体名称,用逗号分隔。例如:C-101压缩机,轴承
"""
response = self.llm.invoke(entity_extraction_prompt)
entities = [e.strip() for e in response.content.split(',') if e.strip()]
graph_docs = []
if entities:
# --- 步骤3: 图检索 ---
# 对每个实体,在知识图谱中查找相关的故障信息
with self.driver.session() as session:
for entity in entities:
# Cypher查询:查找与实体相关的故障,并返回其原因和解决方案
cypher_query = """
MATCH (e) WHERE e.name CONTAINS $entity
MATCH (f:Fault)-[:OCCURS_ON|HAS_COMPONENT]->(e)
MATCH (f)-[:HAS_CAUSE]->(c:Cause)
MATCH (f)-[:HAS_SOLUTION]->(s:Solution)
RETURN "设备 '" + e.name + "' 的一个相关故障原因是 '" + c.description + "',建议的解决方案是 '" + s.description + "'。" AS text
LIMIT 2
"""
result = session.run(cypher_query, entity=entity)
for record in result:
graph_docs.append(Document(page_content=record["text"]))
# --- 步骤4: 融合结果 ---
# 将向量检索的文本和图检索的结构化信息合并
combined_docs = vector_results + graph_docs
# 去重
unique_contents = set()
final_docs = []
for doc in combined_docs:
if doc.page_content not in unique_contents:
final_docs.append(doc)
unique_contents.add(doc.page_content)
return final_docs
# --- 初始化 ---
OPENAI_API_KEY = "sk-..."
NEO4J_URI = "bolt://localhost:7687"
NEO4J_USER = "neo4j"
NEO4J_PASSWORD = "your_password"
llm = ChatOpenAI(model="gpt-4o", temperature=0, api_key=OPENAI_API_KEY)
embeddings = OpenAIEmbeddings(api_key=OPENAI_API_KEY)
neo4j_driver = GraphDatabase.driver(NEO4J_URI, auth=(NEO4J_USER, NEO4J_PASSWORD))
# # 假设我们已经在Neo4j中创建了名为 'fault_vector_index' 的向量索引
vector_index = Neo4jVector.from_existing_index(
embedding=embeddings,
url=NEO4J_URI,
username=NEO4J_USER,
password=NEO4J_PASSWORD,
index_name="fault_vector_index",
)
hybrid_retriever = HybridRetriever(
neo4j_vector_store=vector_index,
neo4j_driver=neo4j_driver,
llm=llm
)
# # --- 测试检索器 ---
test_query = "V-201反应釜的机械密封好像坏了,怎么办?"
relevant_documents = hybrid_retriever.invoke(test_query)
for doc in relevant_documents:
print("--- Retrieved Document ---")
print(doc.page_content)
这个自定义的HybridRetriever完美地实现了我们的设计思路。它首先进行快速的语义匹配,然后进行精准的图谱深挖,最后将两方面的信息融合,为LLM提供了最丰富、最相关的“思考素材”。
(后文请待续)
请访问我的微信公众号“大模型RAG和Agent技术实践”,有更丰富的内容

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 41
41 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)