收藏必备!RAPTOR:大模型RAG系统的智能索引优化技术全解析
RAPTOR通过构建层级化索引树优化RAG系统性能。它将文档分割为叶节点,经主题聚类和LLM摘要生成递归构建抽象层次更高的节点,最终形成"折叠树"向量存储。这种多分辨率索引使系统能根据问题复杂度选择合适信息粒度,在保持查询简单性的同时显著提升RAG性能,尤其在处理需综合多源信息的复杂问题时表现优异。
有许多 RAG 优化技巧可以提升性能,从查询转换到重新排序模型。挑战在于,每增加一层新功能通常会带来额外的复杂性、更多的 LLM 调用,以及更复杂的架构。
但如果我们只专注于一件事情——构建一个更智能的索引,就能获得更好的性能呢?
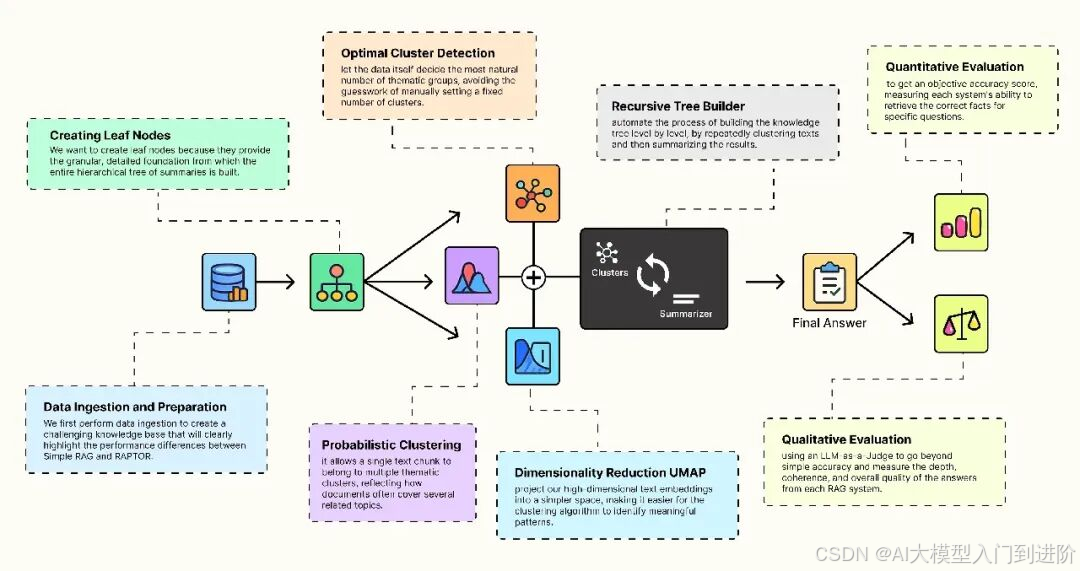
这就是 RAPTOR(Recursive Abstractive Processing for Tree-Organized Retrieval,递归抽象处理树形检索)的核心理念:它在查询时保持 RAG 的简单性,同时通过构建一个反映人类从细节到高层次概念理解的层级索引,带来更优越的性能。
以下是 RAPTOR 工作原理的高层次概述:
-
- 从叶节点开始:首先,我们将所有源文档拆分成小的、详细的片段。这些是知识树的“叶节点”,作为基础。
-
- 按主题聚类:然后,使用机器学习聚类算法(如 GMM 或 Agglomerative 等)根据语义含义自动将这些叶节点分组为相关集群。
-
- 抽象总结:我们使用 LLM 为每个集群生成一个简洁、高质量的摘要。这些摘要成为树的下一层,更抽象的节点。
-
- 递归向上构建:对新生成的摘要重复聚类和总结过程,逐层构建树,向更高层次的概念推进。
-
- 统一索引:最后,将所有文本——原始叶节点和所有生成的摘要——组合成一个“折叠树”向量存储,构建一个强大的多分辨率搜索。
在这篇博客中,我们将……
比较一个简单的 RAG 流水线与基于 RAPTOR 的 RAG 流水线,并探讨为什么 RAPTOR 比其他方法表现更好。
所有代码都可以在 GitHub 仓库中找到。
GitHub - FareedKhan-dev/rag-with-raptor:基于 RAPTOR 的 RAG 实现的分步指南
https://github.com/FareedKhan-dev/rag-with-raptor
代码库结构如下:
rag-with-raptor/
├── LICENSE
├── README.md
├── requirements.txt
├── rag_vs_raptor.ipynb # 比较评估
└── raptor_guide.ipynb # RAPTOR 独立实现
目录
- • 初始化 RAG 配置
- • 数据摄取与准备
- • 创建 RAPTOR 树的叶节点
- • 实现简单 RAG 及其问题
- • 构建层级聚类引擎
- • 使用 UMAP 降维
- • 最佳聚类数量检测
- • 使用 GMM 进行概率聚类
- • 层级聚类协调器
- • 构建并执行 RAPTOR 树
- • 使用折叠树策略索引
- • RAPTOR 与简单 RAG 的定量评估
- • 使用 LLM 作为评判者的定性评估
- • 总结 RAPTOR 方法
初始化 RAG 配置
任何 RAG 系统的两个最重要的组件是:
- • 嵌入模型:将文档转换为向量空间以便检索。
- • 文本生成模型(LLM):解释检索到的内容并生成答案。
为了确保方法可复制且公平,我们故意使用了一个大约一年前发布的量化旧模型。如果使用更新的 LLM,它可能已经“知道”答案,绕过了检索。通过选择旧模型,我们确保评估真正测试的是检索质量,这正是 RAPTOR 与简单 RAG 的区别所在。
我们首先需要导入 PyTorch 和其他支持组件:
# 导入核心 PyTorch 库以进行张量操作
import torch
# 导入 LangChain 的 Hugging Face 模型封装
from langchain_huggingface import HuggingFaceEmbeddings, HuggingFacePipeline
# 从 transformers 库导入核心组件以加载和配置模型
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline, BitsAndBytesConfig
# 导入 LangChain 的提示工程和输出处理工具
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
我们将使用 sentence-transformers/all-MiniLM-L6-v2,这是一个轻量且广泛使用的嵌入模型,将所有文本片段和摘要转换为向量表示。
# --- 配置嵌入模型 ---
embedding_model_name = "sentence-transformers/all-MiniLM-L6-v2"
# 如果有 GPU 则使用,否则回退到 CPU
model_kwargs = {"device": "cuda"}
# 使用 LangChain 的封装初始化嵌入
embeddings = HuggingFaceEmbeddings(
model_name=embedding_model_name,
model_kwargs=model_kwargs
)
这个嵌入模型虽然小巧,但非常适合大规模文档索引,不会占用过多内存。接下来,我们使用 Mistral-7B-Instruct v0.2,一个能力强但紧凑的指令调整模型。
为了节省内存,我们使用 BitsAndBytesConfig 以 4 位量化加载它。
# --- 配置 LLM 用于总结和生成 ---
llm_id = "mistralai/Mistral-7B-Instruct-v0.2"
# 量化:减少内存占用,同时保持性能
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_quant_type="nf4"
)
我们现在需要加载分词器和 LLM 本身,并应用量化设置。
# 加载分词器
tokenizer = AutoTokenizer.from_pretrained(llm_id)
# 使用量化加载 LLM
model = AutoModelForCausalLM.from_pretrained(
llm_id,
torch_dtype=torch.float16,
device_map="auto",
quantization_config=quantization_config
)
这样,模型可以在有限的 GPU 内存下高效运行。加载模型和分词器后,我们将其封装在 Hugging Face 的 pipeline 中用于文本生成。
# 使用加载的模型和分词器创建文本生成 pipeline
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512# 控制生成摘要和答案的最大长度
)
最后,我们将 Hugging Face 的 pipeline 封装在 LangChain 的 HuggingFacePipeline 中,以便稍后与检索 pipeline 无缝整合。
# 将 pipeline 封装为 LangChain 兼容
llm = HuggingFacePipeline(pipeline=pipe)
太好了!现在我们已经配置了基本的 LLM 和嵌入模型,这是 RAG pipeline 的两个主要组件,接下来可以定义复杂的知识库。
数据摄取与准备
为了充分展示 RAPTOR 如何提升 RAG 性能,我们需要一个复杂且具有挑战性的数据库。目标是当我们对其运行查询时,能清楚看到简单 RAG 和 RAPTOR 增强 RAG 的真实差异。
为此,我们聚焦于 Hugging Face 的文档。这些文档信息丰富且重叠,包含细微变化,容易让简单的检索器出错。
例如,Hugging Face 以多种方式解释了 ZeRO-3 检查点保存:
- •
trainer.save_model() - •
unwrap_model().save_pretrained() - •
zero_to_fp32()
这些都指向同一个底层概念:将模型分片整合成完整的检查点。
简单 RAG 可能只检索到这些变体之一,错过更广泛的上下文,导致不完整甚至错误的指令。而 RAPTOR 能整合并推理这些内容。
由于 Hugging Face 的文档生态系统庞大,我们缩小范围到五个核心指南,这些是实际使用中最常见的内容。
让我们初始化它们的 URL。
# 定义要爬取的文档部分,设置不同的爬取深度
urls_to_load = [
{"url": "https://huggingface.co/docs/transformers/index", "max_depth": 3},
{"url": "https://huggingface.co/docs/datasets/index", "max_depth": 2},
{"url": "https://huggingface.co/docs/tokenizers/index", "max_depth": 2},
{"url": "https://huggingface.co/docs/peft/index", "max_depth": 1},
{"url": "https://huggingface.co/docs/accelerate/index", "max_depth": 1}
]
我们针对 Hugging Face 的五个知名使用领域。关键参数是 max_depth,它控制从起始页面爬取的深度,让我们直观理解这个参数的运作方式。
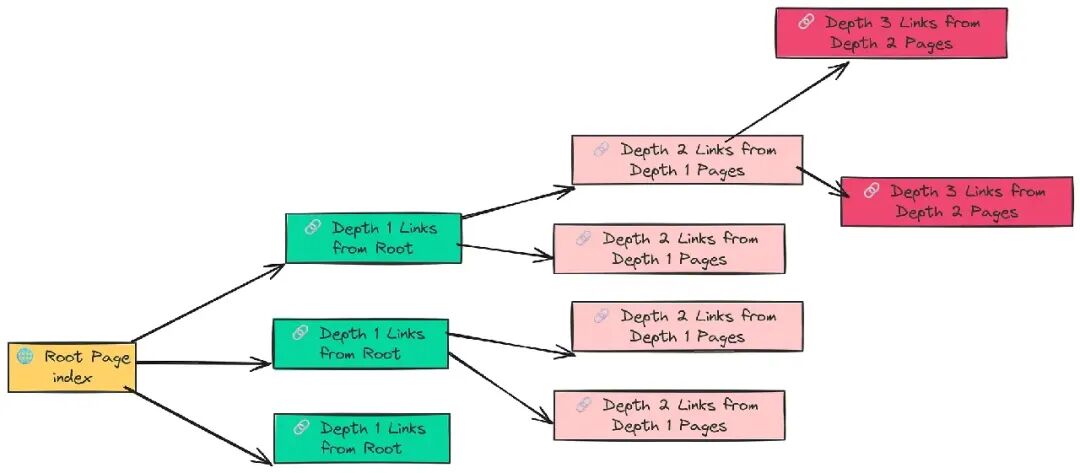
- • 从根页面开始(例如
...docs/transformers/index)。 - • 从那里,跟踪该页面上的所有链接 → 这是深度 1。
- • 然后,爬取这些子页面内的链接 → 这是深度 2。
- • 最后,继续深入子子页面内的链接 → 这是深度 3。
现在我们定义了 URL,下一步是实际获取内容。为此,我们将使用 LangChain 的 RecursiveUrlLoader 结合 BeautifulSoup 来干净地提取每个页面的文本。
from langchain_community.document_loaders import RecursiveUrlLoader
from bs4 import BeautifulSoup as Soup
# 空列表用于追加组件
docs = []
# 遍历列表并爬取每个文档部分
for item in urls_to_load:
# 使用特定 URL 和参数初始化加载器
loader = RecursiveUrlLoader(
url=item["url"],
max_depth=item["max_depth"],
extractor=lambda x: Soup(x, "html.parser").text, # 使用 BeautifulSoup 提取文本
prevent_outside=True, # 确保只停留在文档页面
use_async=True, # 使用异步请求加速爬取
timeout=600, # 为慢速页面设置宽松的超时
)
# 加载文档并添加到主列表
loaded_docs = loader.load()
docs.extend(loaded_docs)
print(f"从 {item['url']} 加载了 {len(loaded_docs)} 个文档")
我们基本上是循环遍历所有文档并抓取其内容,大多数参数都很直观,但有两个需要特别注意:
- •
prevent_outside=True→ 不爬取无关资产,如外部 JavaScript、分析或无关链接。我们只想要核心文档文本。 - •
timeout=600→ Hugging Face 页面有时较重或较慢,宽松的超时防止提前失败,让我们能细致爬取而不被阻断。
运行这个循环时,我们得到以下输出:
###### 输出 #######
从 https://huggingface.co/docs/transformers/index 加载了 68 个文档
从 https://huggingface.co/docs/datasets/index 加载了 35 个文档
从 https://huggingface.co/docs/tokenizers/index 加载了 21 个文档
从 https://huggingface.co/docs/peft/index 加载了 12 个文档
从 https://huggingface.co/docs/accelerate/index 加载了 9 个文档
总计加载文档:145
我们总共获得了 145 个文档,足以用于评估基于 RAPTOR 的 RAG。让我们对爬取的数据进行进一步分析,比如统计 token 数量。
import numpy as np
# 需要一个一致的方法来统计 token,使用 LLM 的分词器是最准确的方法
def count_tokens(text: str) -> int:
"""使用配置的分词器统计文本中的 token 数量"""
# 确保文本非空且为字符串
ifnotisinstance(text, str):
return0
returnlen(tokenizer.encode(text))
# 从加载的 LangChain Document 对象中提取文本内容
docs_texts = [d.page_content for d in docs]
# 计算每个文档的 token 数量
token_counts = [count_tokens(text) for text in docs_texts]
# 打印统计信息以了解文档大小分布
print(f"总文档数:{len(docs_texts)}")
print(f"语料库总 token 数:{np.sum(token_counts)}")
print(f"平均每个文档的 token 数:{np.mean(token_counts):.2f}")
print(f"文档中最少 token 数:{np.min(token_counts)}")
print(f"文档中最多 token 数:{np.max(token_counts)}")
这是对我们数据的简单 token 分析。
######### 输出 #########
总文档数:145
语料库总 token 数:312566
平均每个文档的 token 数:2155.59
文档中最少 token 数:312
文档中最多 token 数:12453
每个文档的最大 token 数为 12K,相当大,如果不进行分块可能会导致信息丢失。总计约 30 万 token,规模可观,因此我们需要确定知识库的最佳分块策略。一种简单的方法是绘制 token 分布图,以确定最佳分块大小。
# 设置绘图大小以提高可读性
plt.figure(figsize=(10, 6))
# 创建直方图
# - token_counts:每个文档的 token 计数列表
# - bins=50:将数据分为 50 个区间(条形)
# - color='blue':设置条形颜色
# - alpha=0.7:设置条形透明度
plt.hist(token_counts, bins=50, color='blue', alpha=0.7)
# 设置直方图标题
plt.title('文档 token 计数分布')
# 标记 x 轴
plt.xlabel('Token 计数')
# 标记 y 轴
plt.ylabel('文档数量')
# 为背景添加网格,便于读取值
plt.grid(True)
# 显示生成的图表
plt.show()
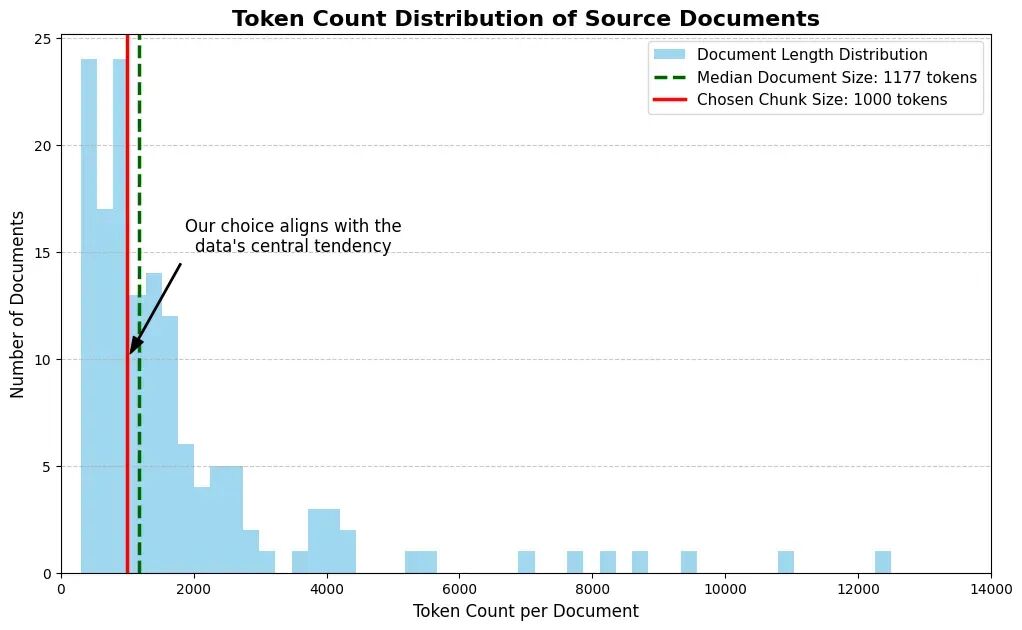
从图中可以看出,文档大小的中位数大约是 1000 个 token。因此,我们将使用 1000 作为分块大小。下一节我们将进行文档分块,这也是 RAPTOR 树架构的第一个组件。
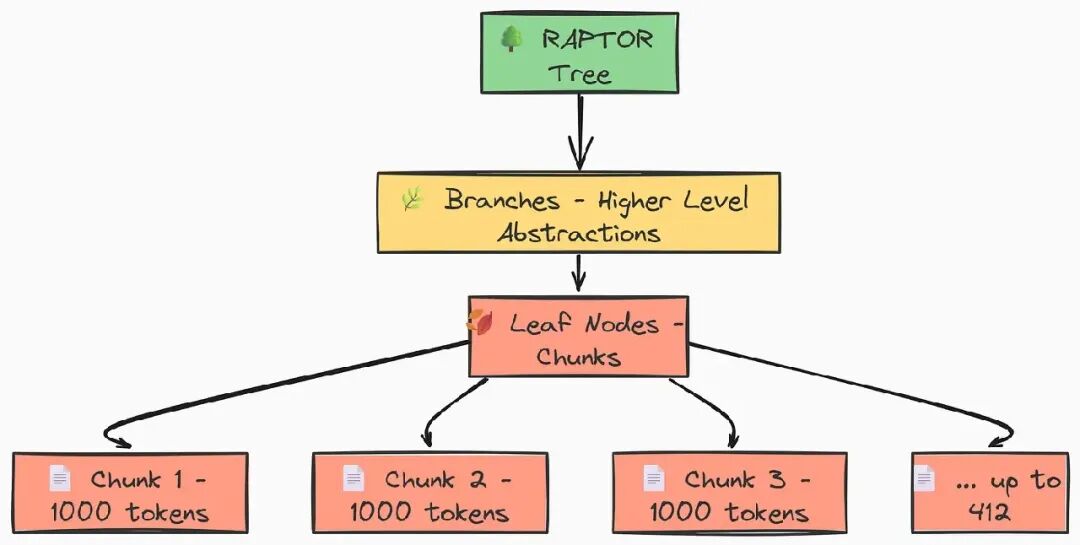
创建 RAPTOR 树的叶节点
对文档 token 计数的分析表明,我们的 145 个文档中有许多太大,无法直接用于 RAG 系统。直方图指出最佳分块大小约为 1000 个 token。
这个初始分块步骤是 RAPTOR 过程的第一步,也是最关键的部分。
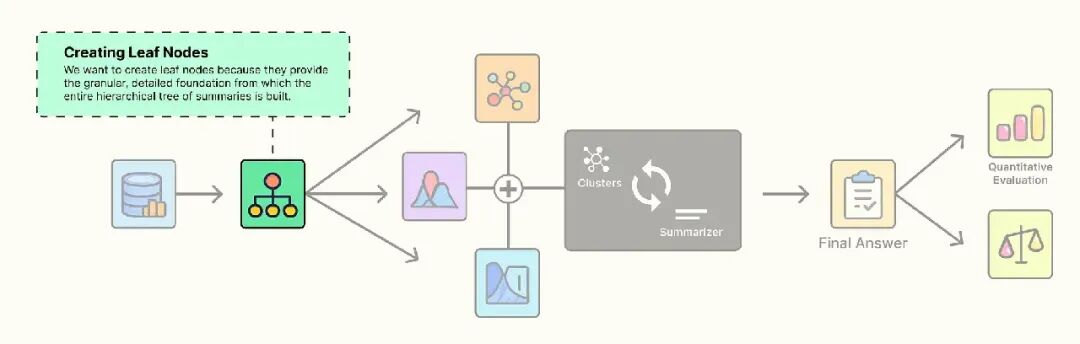
叶节点的意义是什么?
将我们的知识库想象成一棵树。最详细、具体的信息就像真实树上的叶子,构成了基础。在 RAPTOR 中,这些是我们的叶节点。
它们是包含源文档原始细节的细粒度、0 级分块:具体的代码示例、API 函数描述和精确定义。
标准 RAG 系统只看到这些叶子。RAPTOR 的创新在于以这些叶子为基础,构建更抽象的理解——树的枝干。但如果没有高质量的叶子,整个结构将很脆弱。
为了创建它们,我们将使用配置了 LLM 分词器的 LangChain RecursiveCharacterTextSplitter,确保分块智能且尊重 token 边界。
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 将所有文档连接成一个字符串以提高处理效率
# '---' 分隔符有助于在需要时保持文档边界
concatenated_content = "\n\n --- \n\n".join(docs_texts)
# 使用 LLM 的分词器创建文本分割器以确保准确性
text_splitter = RecursiveCharacterTextSplitter.from_huggingface_tokenizer(
tokenizer=tokenizer,
chunk_size=1000, # 分块的最大 token 数
chunk_overlap=100# 分块之间重叠的 token 数
)
# 将文本分割成块,这些将是我们的叶节点
leaf_texts = text_splitter.split_text(concatenated_content)
print(f"为 RAPTOR 树创建了 {len(leaf_texts)} 个叶节点(分块)。")
让我们分解这里使用的关键参数:
- •
from_huggingface_tokenizer(tokenizer=tokenizer):使分割器“token 感知”,因此chunk_size=1000指的是 token 而不是字符,这对我们的模型更准确。 - •
chunk_size=1000:直接实现我们从直方图分析中做出的决定,创建可管理的分块大小。 - •
chunk_overlap=100:这是一项关键技术,防止在分块边界处丢失上下文。每个分块与前一个分块共享 100 个 token。
运行这段代码给我们提供了基础层。
#### 输出 #####
为 RAPTOR 树创建了 412 个叶节点(分块)。
我们将 145 个大文档转变为 412 个聚焦、细粒度的叶节点。在构建 RAPTOR 树的其余部分之前,
让我们通过构建和测试仅使用这些节点的简单 RAG 系统来建立基线。

实现简单 RAG 及其问题
为了证明 RAPTOR 确实是改进,我们需要一个比较对象。我们现在将构建一个标准的、非层级的 RAG 系统。这个“简单 RAG”将使用与我们刚创建的完全相同的模型和 412 个叶节点。其知识库将仅包含这些叶子,确保公平比较。
首先,我们将使用 FAISS,一个高效的向量搜索库,构建我们的向量存储。
from langchain_community.vectorstores import FAISS
# 在简单 RAG 中,向量存储仅基于叶级分块构建
vectorstore_normal = FAISS.from_texts(
texts=leaf_texts,
embedding=embeddings
)
# 从该向量存储创建检索器,获取前 5 个结果
retriever_normal = vectorstore_normal.as_retriever(
search_kwargs={'k': 5}
)
print(f"使用 {len(leaf_texts)} 个文档构建了简单 RAG 向量存储。")
### 输出 ###
使用 412 个文档构建了简单 RAG 向量存储。
现在我们有了检索器,让我们构建一个完整的 RAG 链,看看它在高层次问题上的表现。这将立即凸显简单方法的局限性。
from langchain_core.runnables import RunnablePassthrough
# 此提示模板指示 LLM 仅基于提供的上下文回答
final_prompt_text = """你是 Hugging Face 生态系统的专家助手。
仅基于以下上下文回答用户的问题。如果上下文中没有答案,请说明你不知道。
上下文:
{context}
问题:
{question}
答案:"""
final_prompt = ChatPromptTemplate.from_template(final_prompt_text)
# 格式化检索文档的辅助函数
defformat_docs(docs):
return"\n\n".join(doc.page_content for doc in docs)
# 构建简单方法的 RAG 链
rag_chain_normal = (
{"context": retriever_normal | format_docs, "question": RunnablePassthrough()}
| final_prompt
| llm
| StrOutputParser()
)
# 提出一个广泛的概念性问题
question = "Hugging Face 生态系统的核心理念是什么?"
answer = rag_chain_normal.invoke(question)
print(f"问题:{question}\n")
print(f"答案:{answer}")
在这里,我们将检索器的输出传入提示,然后传递给 LLM。让我们检查结果。
#### 输出 ###
问题:Hugging Face 生态系统的核心理念是什么?
答案:Hugging Face 生态系统围绕 `transformers` 库构建,
它提供了易于下载和使用预训练模型的 API。
核心理念是让这些模型易于访问。例如,`pipeline`
函数是其中的关键部分,提供了一种简单的方式来使用模型进行
推理。它还包括用于数据加载的 `datasets` 和用于训练的 `accelerate`。
这个答案没有错,但显得零散,像是拼凑了一堆随机事实。
它提到了 pipeline、datasets 和 accelerate,但没有解释它们如何协同工作,或更大的目标如可访问性、互操作性和效率。这是一个“迷失于细节”的问题——检索器提取了包含正确词汇的小片段,但错过了主要思想。
这正是 RAPTOR 设计要解决的问题。现在我们有了清晰的基线,可以继续构建 RAPTOR 树及其更复杂的聚类引擎。
构建层级聚类引擎
我们已经看到简单检索不够用。为了构建 RAPTOR 树,我们需要将 412 个叶节点分组为有意义的主题集群。例如,所有讨论 Trainer 参数的分块应归为一组,所有关于 PEFT 和 LoRA 的分块应形成另一组。
RAPTOR 论文提出了一种复杂的多阶段聚类过程,远比简单的 K-Means 更稳健。它涉及三个关键组件,我们将分别实现为独立函数:
- • 降维(UMAP):帮助聚类算法更清晰地看到数据的“形状”。
- • 最佳聚类数量检测(GMM + BIC):让数据决定自然的集群数量。
- • 概率聚类(GMM):基于概率将分块分配到集群,允许单个分块属于多个相关主题。
让我们完全构建这个引擎。
使用 UMAP 降维
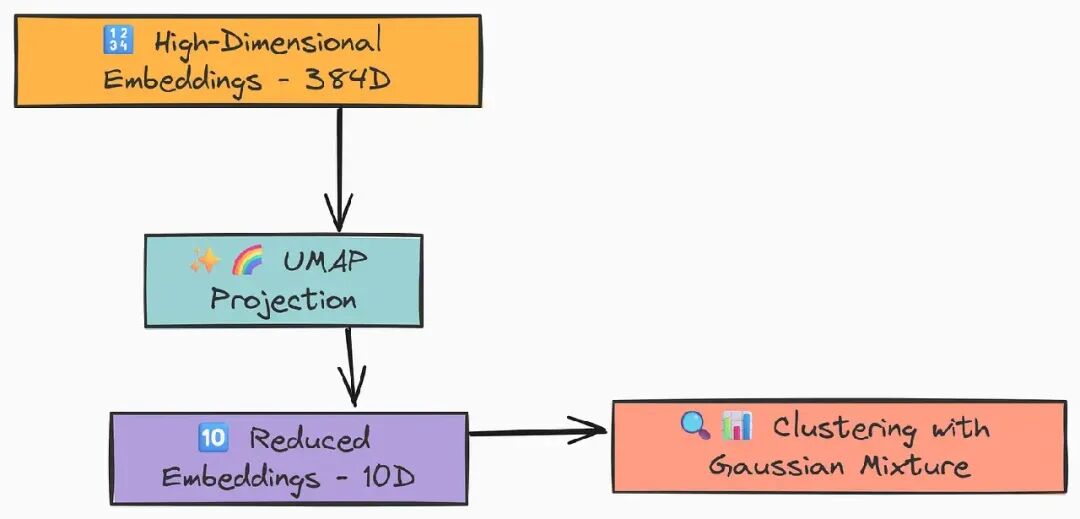
我们的文本嵌入存在于高维空间(我们的模型为 384 维)。
这可能使聚类算法难以有效工作,这被称为“维度灾难”。
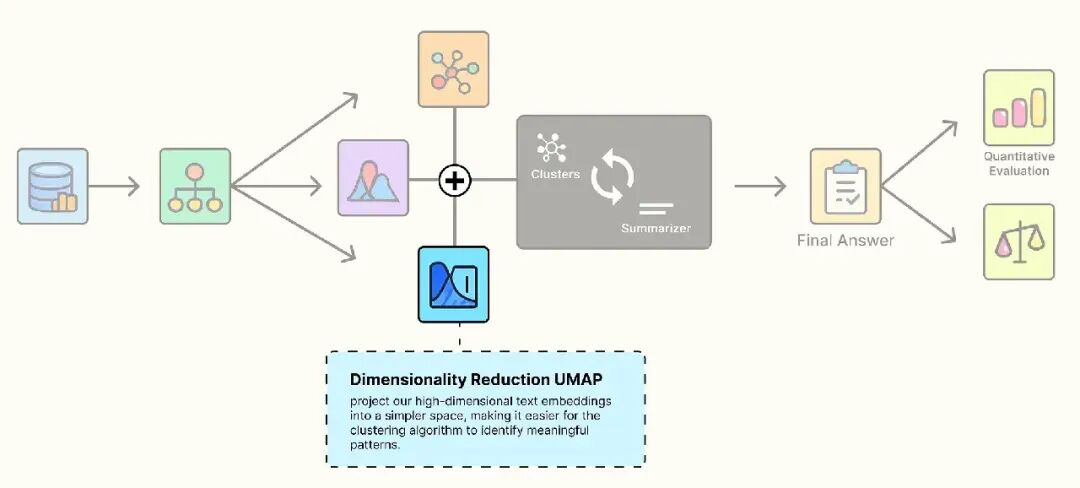
我们使用 UMAP(Uniform Manifold Approximation and Projection)将嵌入投影到较低维空间(例如 10 维),同时保留它们之间的语义关系。
这为聚类算法提供了更清晰、更少噪声的“数据地图”。
from typing importDict, List, Optional, Tuple
import numpy as np
import pandas as pd
import umap
from sklearn.mixture import GaussianMixture
defglobal_cluster_embeddings(embeddings: np.ndarray, dim: int, n_neighbors: Optional[int] = None, metric: str = "cosine") -> np.ndarray:
"""对嵌入进行全局降维,使用 UMAP。"""
# 如果未提供 n_neighbors,则启发式设置
if n_neighbors isNone:
n_neighbors = int((len(embeddings) - 1) ** 0.5)
# 返回 UMAP 转换后的嵌入
return umap.UMAP(
n_neighbors=n_neighbors,
n_components=dim,
metric=metric,
random_state=RANDOM_SEED
).fit_transform(embeddings)
我们基本上是将高维嵌入降到指定维度。我们使用 cosine 度量,因为它在基于文本的向量空间中测量相似性非常有效。
让我们快速看看参数及其作用:
- •
n_neighbors:此参数控制 UMAP 如何平衡局部与全局结构。较小的值关注细节,较大的值关注更广泛的结构。我们使用的启发式是一个常见的起点。 - •
n_components=dim:指定我们希望将数据降到的目标维度数。 - •
metric='cosine':明确告诉 UMAP 使用余弦相似性来测量向量之间的距离。这对文本嵌入非常有效。 - •
random_state=RANDOM_SEED:确保 UMAP 算法每次运行代码时产生完全相同的投影,这对可重现结果至关重要。
.fit_transform(embeddings) 方法执行降维。它首先通过学习高维数据的底层结构来拟合 UMAP 模型,然后将其转换为新的低维空间。
优化聚类数量检测
现在又一个问题:我们应该创建多少个集群?5 个?10 个?50 个?选择固定的数量(k)是任意的,且很少是最佳的。
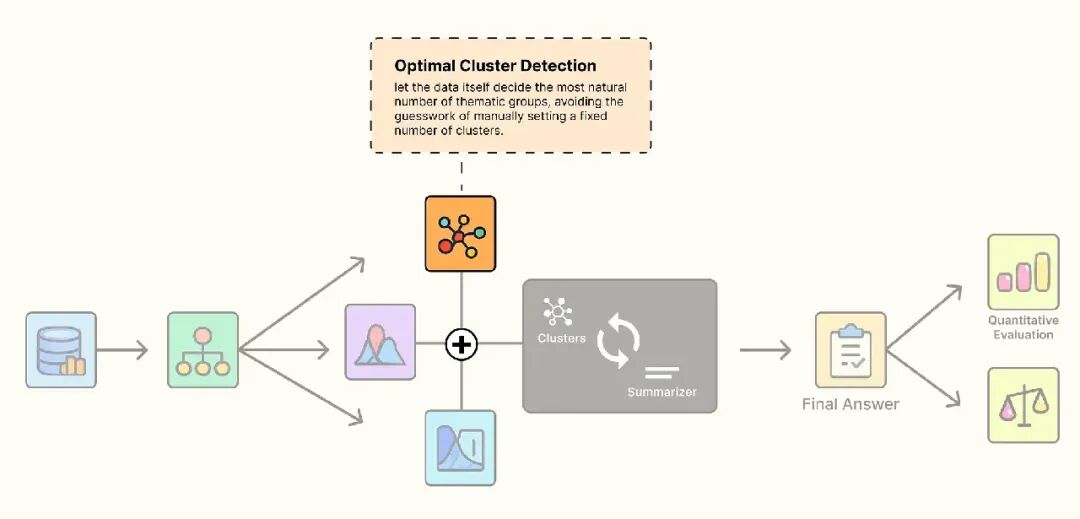
更好的方法是让数据告诉我们它的自然分组数量。
我们使用 Gaussian Mixture Model(GMM)和 Bayesian Information Criterion(BIC)实现这一点。
这个过程涉及拟合多个不同集群数量的 GMM,并使用 BIC 分数找到模型拟合与模型复杂性之间的最佳平衡。
最低的 BIC 分数指示最佳的集群数量。
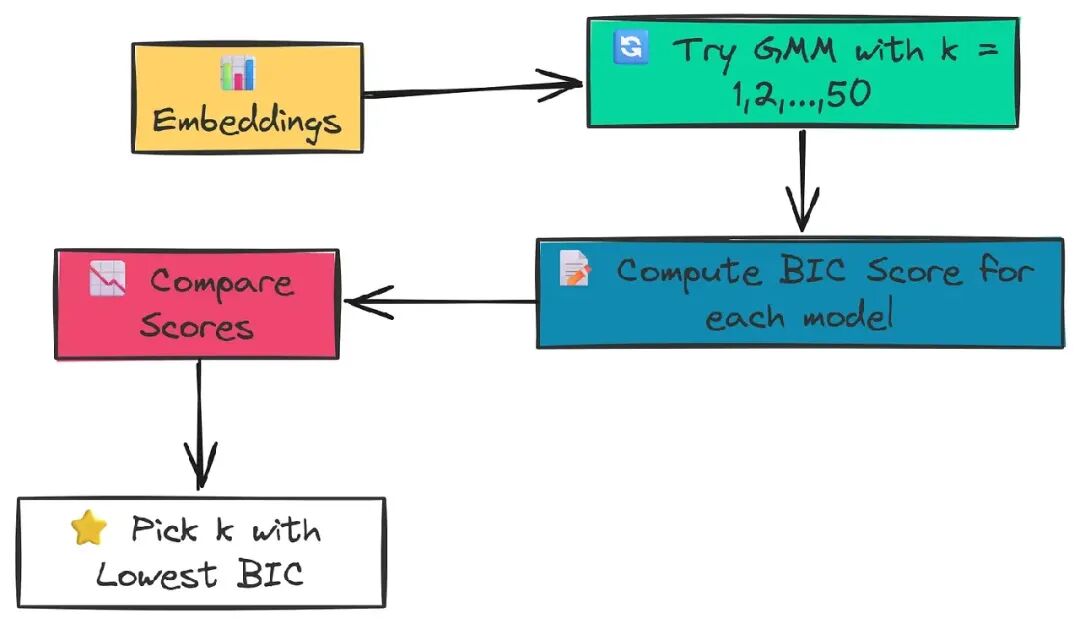
defget_optimal_clusters(embeddings: np.ndarray, max_clusters: int = 50) -> int:
"""使用 Bayesian Information Criterion (BIC) 确定最佳集群数量。"""
# 限制最大集群数量小于数据点数量
max_clusters = min(max_clusters, len(embeddings))
# 如果只有一个点,只能有一个集群
if max_clusters <= 1:
return1
# 测试从 1 到 max_clusters 的不同集群数量
n_clusters_range = np.arange(1, max_clusters)
bics = []
for n in n_clusters_range:
# 为当前集群数量初始化并拟合 GMM
gmm = GaussianMixture(n_components=n, random_state=RANDOM_SEED)
gmm.fit(embeddings)
# 计算并存储当前模型的 BIC
bics.append(gmm.bic(embeddings))
# 返回导致最低 BIC 分数的集群数量
return n_clusters_range[np.argmin(bics)]
该函数的逻辑是系统性地搜索最佳模型:
- • 它遍历可能的集群数量范围(例如,从 1 到 50)。
- • 在每次迭代中,初始化并训练一个具有特定集群数量(
n_components=n)的 GaussianMixture 模型。 - • 训练后,计算该模型的
gmm.bic(embeddings)。BIC 分数奖励良好拟合,但惩罚复杂性(集群过多)。 - • 最后,通过
np.argmin(bics)找到最低 BIC 分数的索引。我们使用此索引检索相应的集群数量,这是我们的最佳 k。
使用 GMM 进行概率聚类
现在我们将所有部分整合在一起。与 K-Means 等“硬聚类”算法(将数据点分配给唯一集群)不同,GMM 执行“软聚类”。它计算每个点属于每个集群的概率。
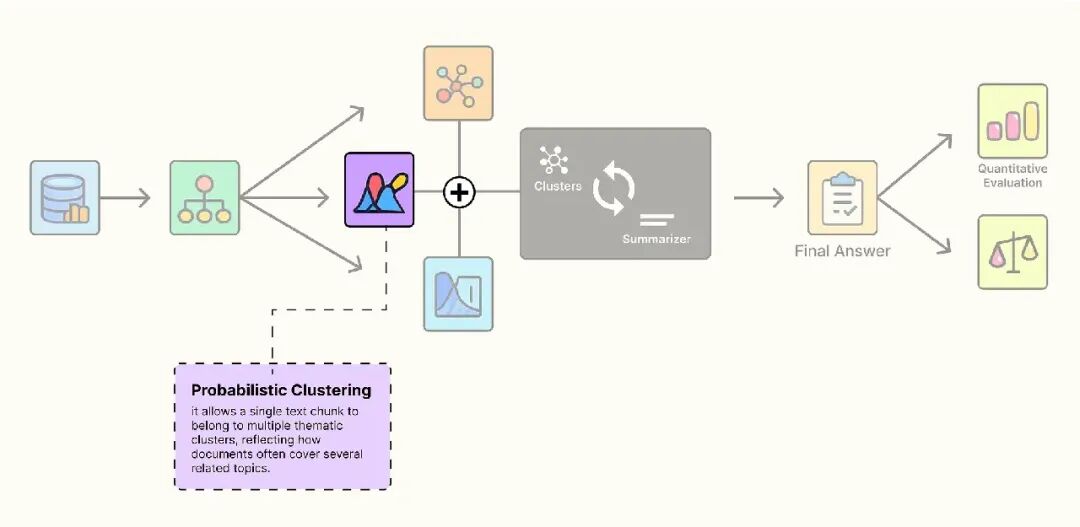
这对我们的用例非常适合。一个文本分块可能同时讨论模型训练和数据预处理,因此应属于两个集群。
我们可以通过设置概率阈值来实现这一点。
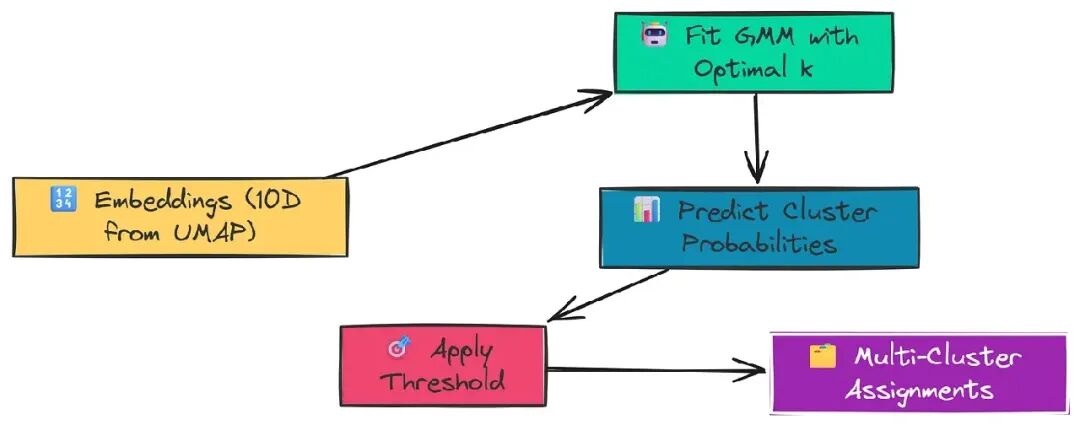
defGMM_cluster(embeddings: np.ndarray, threshold: float) -> Tuple[List[np.ndarray], int]:
"""使用 GMM 和概率阈值对嵌入进行聚类。"""
# 为这组嵌入找到最佳集群数量
n_clusters = get_optimal_clusters(embeddings)
# 使用最佳集群数量拟合 GMM
gmm = GaussianMixture(n_components=n_clusters, random_state=RANDOM_SEED)
gmm.fit(embeddings)
# 获取每个点属于每个集群的概率
probs = gmm.predict_proba(embeddings)
# 如果点的概率高于阈值,则将其分配到该集群
# 一个点可以分配到多个集群
labels = [np.where(prob > threshold)[0] for prob in probs]
return labels, n_clusters
此函数将所有部分整合:
- • 首先,调用
get_optimal_clusters确定输入嵌入的最佳集群数量。 - • 然后,使用此最佳数量拟合 GaussianMixture 模型。
- • 关键步骤是
gmm.predict_proba(embeddings)。这返回一个矩阵,每行代表一个文本分块,每列包含该分块属于该集群的概率。 - • 最后一行
[np.where(prob > threshold)[0] for prob in probs]处理这个概率矩阵。对于每个分块的概率列表(prob),np.where找到超过阈值的集群索引。这为每个分块提供了一个集群 ID 列表,实现了我们的多标签分配。
有了这三个组件——UMAP、BIC 和 GMM,我们的聚类引擎已经准备好。现在,我们需要协调它们以构建树的层级结构。
层级聚类协调器
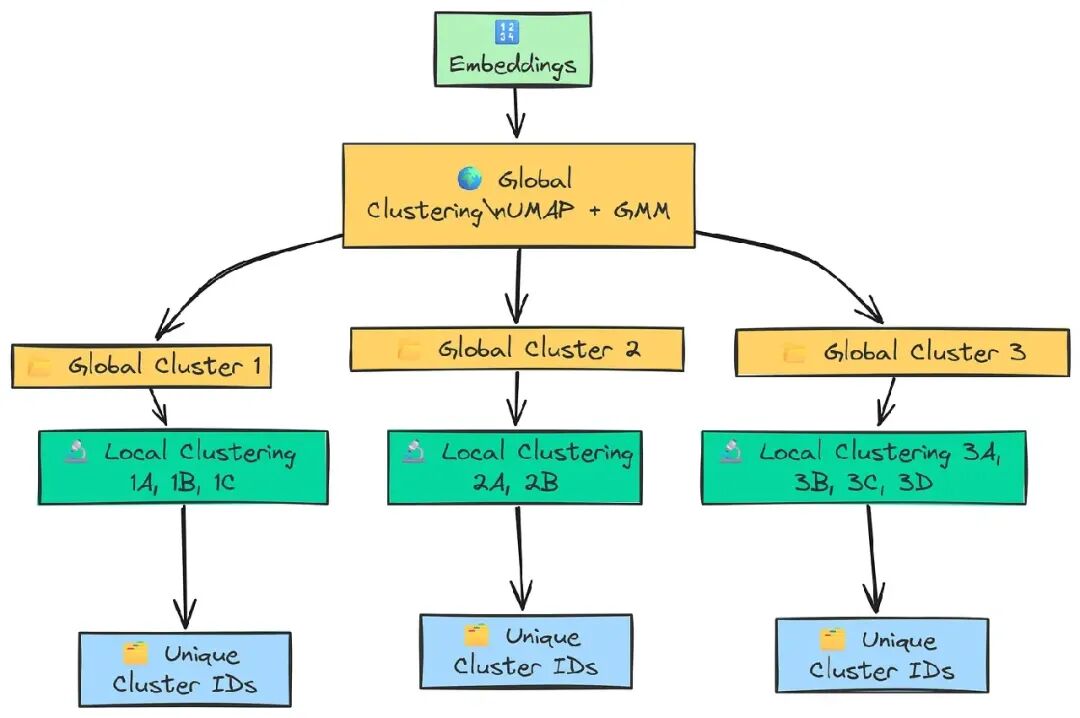
有了聚类的构建块很好,但真正的力量在于我们如何安排它们。RAPTOR 论文提出了一个巧妙的两阶段过程:
- • 全局聚类:首先,找到整个数据集的广泛高层次主题。例如,可能会为“Transformers 库”、“Datasets 库”和“训练与优化”创建集群。
- • 局部聚类:然后,放大。对于每个全局集群,再次运行聚类过程,仅针对该集群内的文档。这会发现更具体的子主题。“训练与优化”集群可能分解为 PEFT、Accelerate 和 Trainer 参数的更小局部集群。
这种全局到局部的策略让我们既能捕捉整体(森林),也能看到细节(树木)。我们现在将编写一个单一的协调器函数 perform_clustering,实现整个层级逻辑。
defperform_clustering(embeddings: np.ndarray, dim: int = 10, threshold: float = 0.1) -> List[np.ndarray]:
"""对嵌入进行层级聚类(全局和局部)。"""
# 处理数据点很少的情况,避免降维错误
iflen(embeddings) <= dim + 1:
return [np.array([0]) for _ inrange(len(embeddings))]
# --- 全局聚类阶段 ---
# 首先,对所有嵌入进行全局降维
reduced_embeddings_global = global_cluster_embeddings(embeddings, dim)
# 然后,对降维数据进行 GMM 聚类
global_clusters, n_global_clusters = GMM_cluster(reduced_embeddings_global, threshold)
# --- 局部聚类阶段 ---
# 初始化列表以保存每个文档的最终局部集群分配
all_local_clusters = [np.array([]) for _ inrange(len(embeddings))]
# 跟踪迄今发现的集群总数,确保唯一 ID
total_clusters = 0
# 遍历每个全局集群以找到子集群
for i inrange(n_global_clusters):
# 获取属于当前全局集群的所有原始嵌入索引
global_cluster_indices = [idx for idx, gc inenumerate(global_clusters) if i in gc]
ifnot global_cluster_indices:
continue
# 获取该全局集群的实际嵌入
global_cluster_embeddings_ = embeddings[global_cluster_indices]
# 对该嵌入子集进行局部聚类
iflen(global_cluster_embeddings_) <= dim + 1:
local_clusters, n_local_clusters = ([np.array([0])] * len(global_cluster_embeddings_)), 1
else:
# 不需要单独的 'local_cluster_embeddings' 函数
# 全局函数适用,因为它会根据输入大小调整 n_neighbors
reduced_embeddings_local = global_cluster_embeddings(global_cluster_embeddings_, dim)
local_clusters, n_local_clusters = GMM_cluster(reduced_embeddings_local, threshold)
# 将局部集群结果映射回原始文档索引
for j inrange(n_local_clusters):
# 找到局部集中属于该特定局部集群的文档
local_cluster_indices = [idx for idx, lc inenumerate(local_clusters) if j in lc]
ifnot local_cluster_indices:
continue
# 从完整数据集中获取原始索引
original_indices = [global_cluster_indices[idx] for idx in local_cluster_indices]
# 为这些文档分配新的全局唯一集群 ID
for idx in original_indices:
all_local_clusters[idx] = np.append(all_local_clusters[idx], j + total_clusters)
# 增加总集群计数,确保下一个全局集群的局部 ID 唯一
total_clusters += n_local_clusters
return all_local_clusters
此函数是我们聚类逻辑的核心部分。让我们分解其流程:
- • 全局阶段:首先运行
global_cluster_embeddings和GMM_cluster,在整个输入嵌入集上找到n_global_clusters。 - • 局部循环:然后从
i = 0到n_global_clusters - 1迭代。 - • 子集选择:在循环中,对于每个全局集群
i,收集属于它的所有文档的索引和实际嵌入。 - • 重新聚类:再次运行整个聚类过程(UMAP -> GMM)在这个较小的嵌入子集上,发现局部子集群。
- • 标签映射:这是最复杂的部分。它小心地将局部集群 ID(例如 0、1、2)映射到全局唯一 ID。通过添加
total_clusters偏移量实现。因此,第一个全局集群的局部集群可能是 0、1、2,第二个可能是 3、4,防止 ID 冲突。 - • 返回值:函数返回
all_local_clusters,一个列表,其中每个元素对应一个原始文档,包含其最终唯一集群 ID 数组。
现在我们可以组装最终的递归函数,逐层构建 RAPTOR 树。
构建并执行 RAPTOR 树
我们现在拥有所有必要的部分:叶节点(0 级)和强大的层级聚类引擎。最后一步是从底部向上组合它们,构建 RAPTOR 树。
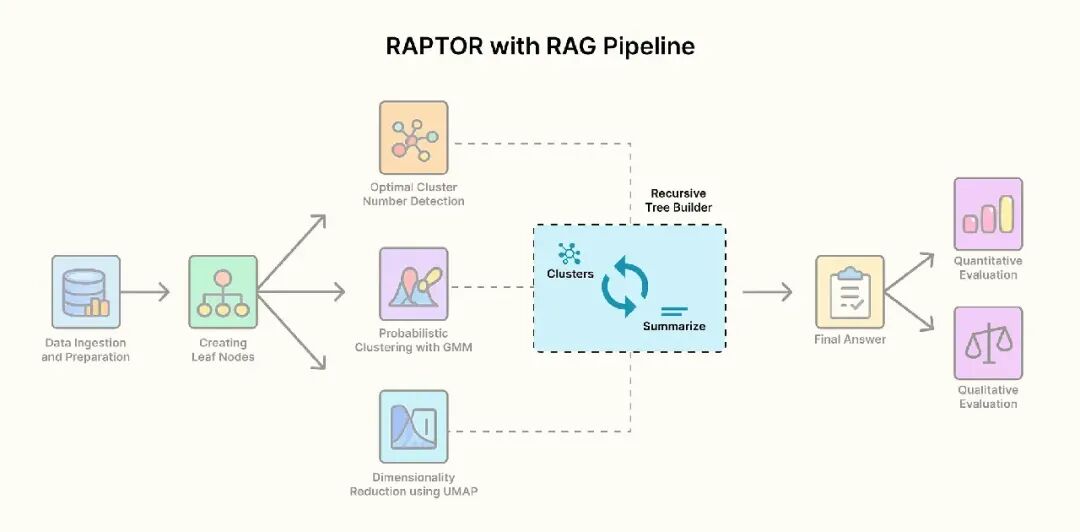
这个过程由两个关键动作驱动:抽象(总结)和递归。
抽象引擎:总结
在构建递归函数之前,我们需要定义 RAPTOR 中的“A”:抽象组件。这是一个机制,将相关的文本分块集群用 LLM 合成为单一的高质量摘要。
这一步至关重要,因为它不仅仅提取信息;它创建新的更高层次知识。集群的摘要成为我们树的父节点,代表其所有子文档的精华。这是我们从具体细节上升到更广泛概念的方式。
我们将为此创建一个简单的 LangChain Expression Language(LCEL)链。提示被设计为指示 LLM 扮演专家技术作者的角色,确保我们的摘要连贯、详细,并捕捉主要思想。
from langchain.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 定义总结链
summarization_prompt = ChatPromptTemplate.from_template(
"""你是专家技术作者。
给定以下来自 Hugging Face 文档的文本分块集合,将它们合成为一个连贯、详细的单一摘要。
聚焦于描述的主要概念、API 和工作流程。
上下文:{context}
详细摘要:"""
)
# 通过将提示传递给 LLM 再到输出解析器,创建总结链
summarization_chain = summarization_prompt | llm | StrOutputParser()
有了这个 summarization_chain,我们现在可以在主递归函数中使用它来构建树。
递归树构建器
递归函数 recursive_build_tree 将协调整个过程。在每一层,它将:
- • 对输入文本进行聚类。
- • 使用我们的抽象引擎为每个集群生成摘要。
- • 通过将新生成的摘要作为下一层的输入进行递归。
这将持续进行,直到无法形成有意义的集群或达到预定义的最大深度。
defrecursive_build_tree(texts: List[str], level: int = 1, n_levels: int = 3) -> Dict[int, Tuple[pd.DataFrame, pd.DataFrame]]:
"""使用所有组件构建 RAPTOR 树的主递归函数。"""
results = {}
# 基本情况:如果达到最大层级或没有文本要处理,则停止
if level > n_levels orlen(texts) <= 1:
return results
# --- 步骤 1:嵌入并聚类当前层的文本 ---
text_embeddings_np = np.array(embeddings.embed_documents(texts))
cluster_labels = perform_clustering(text_embeddings_np)
df_clusters = pd.DataFrame({'text': texts, 'cluster': cluster_labels})
# --- 步骤 2:准备总结 ---
# 由于一个文本可以属于多个集群,我们需要“展开” DataFrame
expanded_list = []
for _, row in df_clusters.iterrows():
for cluster_id in row['cluster']:
expanded_list.append({'text': row['text'], 'cluster': int(cluster_id)})
ifnot expanded_list: # 如果没有形成集群,则停止
return results
expanded_df = pd.DataFrame(expanded_list)
all_clusters = expanded_df['cluster'].unique()
print(f"--- 第 {level} 层:生成 {len(all_clusters)} 个集群 ---")
# --- 步骤 3:使用预定义链为每个集群生成摘要 ---
summaries = []
for i in all_clusters:
# 获取当前集群的所有文本
cluster_texts = expanded_df[expanded_df['cluster'] == i]['text'].tolist()
# 将文本连接成单一上下文字符串
formatted_txt = "\n\n---\n\n".join(cluster_texts)
# 为集群生成摘要
summary = summarization_chain.invoke({"context": formatted_txt})
summaries.append(summary)
# 将当前层的摘要存储在 DataFrame 中
df_summary = pd.DataFrame({'summaries': summaries, 'cluster': all_clusters})
results[level] = (df_clusters, df_summary)
# --- 步骤 4:递归 ---
# 检查是否应继续到下一层
if level < n_levels andlen(all_clusters) > 1:
new_texts = df_summary["summaries"].tolist()
# 再次调用函数,处理摘要,层级加 1
next_level_results = recursive_build_tree(new_texts, level + 1, n_levels)
results.update(next_level_results)
return results
此函数是整个 RAPTOR 过程的总指挥。让我们追踪其执行过程:
- • 基本情况:首先检查是否应停止。如果当前层级超过最大期望深度(
n_levels)或仅剩一个文本要处理,递归结束。 - • 聚类:获取输入文本,嵌入它们,并使用我们的
perform_clustering协调器分配集群标签。 - • 总结:然后遍历每个唯一集群 ID。对于每个集群,收集属于它的所有文本分块,并将其传递给
summarization_chain生成新的抽象摘要。 - • 存储结果:保存当前层的集群分配和新生成的摘要。
- • 递归调用:最重要的一步。获取新摘要列表并调用自身,
recursive_build_tree(new_summaries, level + 1, ...),将一层的输出作为下一层的输入。
现在,让我们在初始的 412 个叶节点上执行此函数,观察树如何生长。
# 在我们的分块叶文本上执行 RAPTOR 过程
# 这将构建最多 3 层总结的树
raptor_results = recursive_build_tree(leaf_texts, level=1, n_levels=3)
#### 输出 ####
--- 第 1 层:生成 8 个集群 ---
第 1 层,集群 0:生成长度为 2011 字符的摘要。
第 1 层,集群 1:生成长度为 1954 字符的摘要。
...(依此类推,涵盖所有 8 个集群)...
--- 第 2 层:生成 3 个集群 ---
第 2 层,集群 0:生成长度为 2050 字符的摘要。
...(依此类推,涵盖所有 3 个集群)...
输出显示了过程的运行情况。
- • 第 1 层:函数将 412 个叶节点分组为 8 个主题集群,然后为每个集群生成 8 个新摘要。
- • 第 2 层:然后将这 8 个摘要视为新文档并进行聚类,发现它们可以分组为 3 个更广泛的主题,并生成 3 个对应的顶级摘要。
- • 由于下一层文档数量(3 个)太少,无法形成有意义的集群,满足我们的基本情况,过程停止。
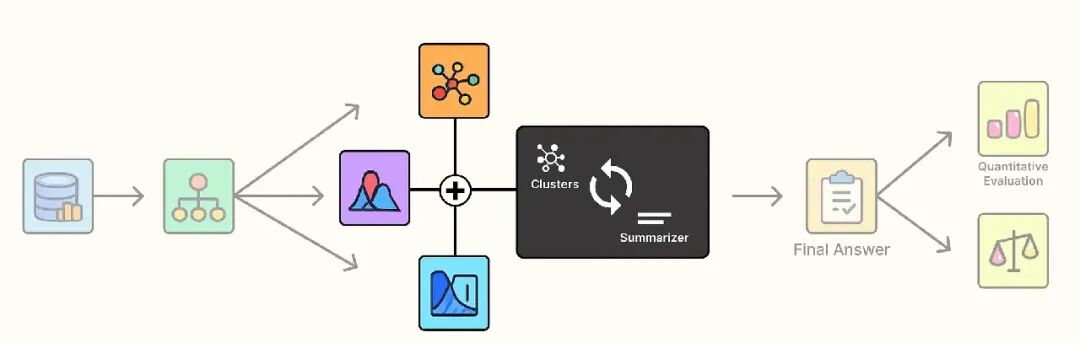
我们成功构建了层级数据结构。最后一步是将所有知识——叶子、枝干和主干——索引到一个单一的向量存储中,供我们的 RAG 系统查询。
使用折叠树策略索引
我们已经构建了一个多层次的知识树,但如何使其可搜索?RAPTOR 使用了一种优雅且高效的技术,称为“折叠树”。
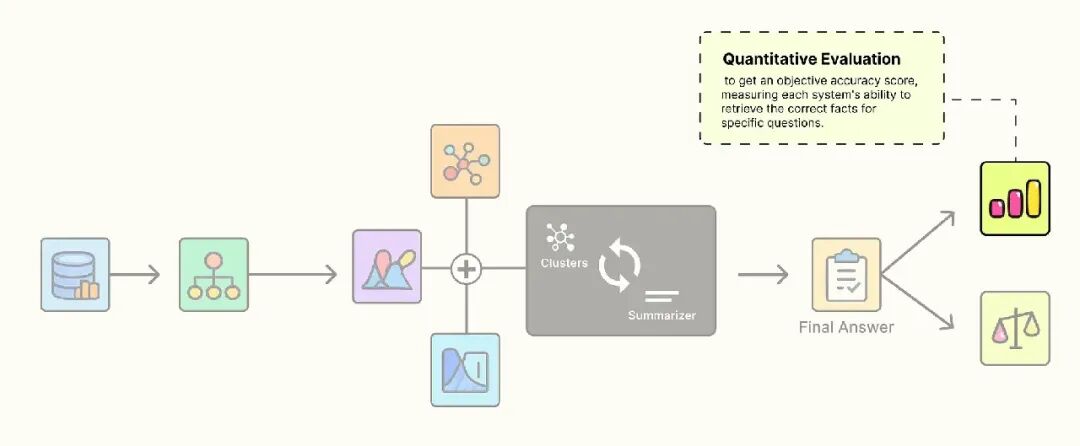
想法很简单,我们将树中每一层的文本——原始的 412 个叶节点、第 1 层的 8 个摘要和第 2 层的 3 个摘要——全部放入一个统一的列表。
进行相似性搜索时,我们的查询同时与详细的叶节点、中间层次的摘要和高层概念摘要进行比较。
这种多分辨率索引使检索系统能够为任何问题找到完美的抽象层次。
让我们实现这一点。我们将收集所有文本并构建最终的 RAPTOR 向量存储。
from langchain_community.vectorstores import FAISS
# 从原始叶文本的副本开始
all_texts_raptor = leaf_texts.copy()
# 添加 RAPTOR 树每一层的摘要
for level in raptor_results:
# 获取当前层结果的摘要
summaries = raptor_results[level][1]['summaries'].tolist()
# 将它们添加到主列表
all_texts_raptor.extend(summaries)
# 使用 FAISS 构建最终向量存储
vectorstore_raptor = FAISS.from_texts(
texts=all_texts_raptor,
embedding=embeddings
)
# 为 RAPTOR RAG 系统创建最终检索器
retriever_raptor = vectorstore_raptor.as_retriever(search_kwargs={'k': 5})
print(f"构建了包含 {len(all_texts_raptor)} 个文档(叶节点 + 摘要)的 RAPTOR 向量存储。")
#### 输出 ####
构建了包含 423 个文档(叶节点 + 摘要)的 RAPTOR 向量存储。
我们的 RAPTOR 知识库现已索引并准备就绪。它包含原始的 412 个叶节点加上 11 个摘要(第 1 层的 8 个 + 第 2 层的 3 个),共计 423 个文档。
现在让我们为 RAPTOR 系统构建一个 RAG 链,并用不同抽象层次的问题测试它。我们期望它能超越简单 RAG 基线,特别是在概念性问题上。
# 为 RAPTOR 方法创建 RAG 链
rag_chain_raptor = (
{"context": retriever_raptor | format_docs, "question": RunnablePassthrough()}
| final_prompt
| llm
| StrOutputParser()
)
我们现在将提出三种类型的问题,以展示系统的能力。
查询 1:具体、低层次问题
这是一个详细的问题,应检索包含代码示例的特定叶节点。
question_specific = "如何在 Transformers 库中使用 `pipeline` 函数?给一个简单的代码示例。"
answer = rag_chain_raptor.invoke(question_specific)
print(answer)
#### 输出 ####
`pipeline` 函数是使用预训练模型执行给定任务的最简单方法。你只需指定要执行的任务,库会为你处理加载适当的模型和分词器。
这是一个情感分析任务的简单代码示例:
```python
from transformers import pipeline
# 创建情感分析 pipeline
classifier = pipeline("sentiment-analysis")
# 在某些文本上使用 pipeline
result = classifier("我爱使用 Hugging Face 库!")
print(result)
# 输出:[{'label': 'POSITIVE', 'score': 0.9998}]
你可以通过更改任务名称,用于许多其他任务,如 “text-generation”、“question-answering” 和 “summarization”。
答案完美。检索器找到了一个包含精确代码片段的细粒度叶节点。这表明高层次的摘要并未干扰系统回答具体、面向细节的问题的能力。
### 查询 2:中层次、概念性问题
这个问题询问工作流程,不太可能由单个叶节点回答,理想情况下应匹配我们生成的中层次摘要之一。
```python
question_mid_level = "使用 PEFT 库微调模型的主要步骤是什么?"
answer = rag_chain_raptor.invoke(question_mid_level)
print(answer)
#### 输出 ###
使用 Parameter-Efficient Fine-Tuning(PEFT)库微调模型涉及几个关键步骤...
加载基础模型...
创建 PEFT 配置...
封装模型...
训练模型...
保存和加载...
这个答案比简单 RAG 能产生的要好得多。它清晰、结构良好,提供了逐步指南。上下文几乎肯定是从第 1 层摘要中检索到的,该摘要已将关于 PEFT 的多个分块合成为一个连贯的工作流程。
查询 3:广泛、高层次问题
这是标准 RAG 系统通常失败的问题类型。它需要从高层次摘要节点才能获得的深刻、主题性理解。
question_high_level = "Hugging Face 生态系统的核心理念是什么?"
answer = rag_chain_raptor.invoke(question_high_level)
print(answer)
### 输出 ###
...Hugging Face 生态系统的核心理念是通过一组可互操作的开源库来民主化最先进的机器学习,基于三个主要原则:
可访问性和易用性...
模块化和互操作性...
效率和性能...
与我们简单 RAG 系统的零散答案相比,这个回答结构清晰、全面,正确识别了核心原则。检索器从我们树的第 2 层找到了高层次摘要,为 LLM 提供了完美合成的上下文。
RAPTOR 与简单 RAG 的定量评估
我们的非正式查询测试显示 RAPTOR 系统具有明显优势,但要做出可靠的声明,我们需要数据。我们现在将进行正式的定量评估,为两个系统获取硬性准确率分数。
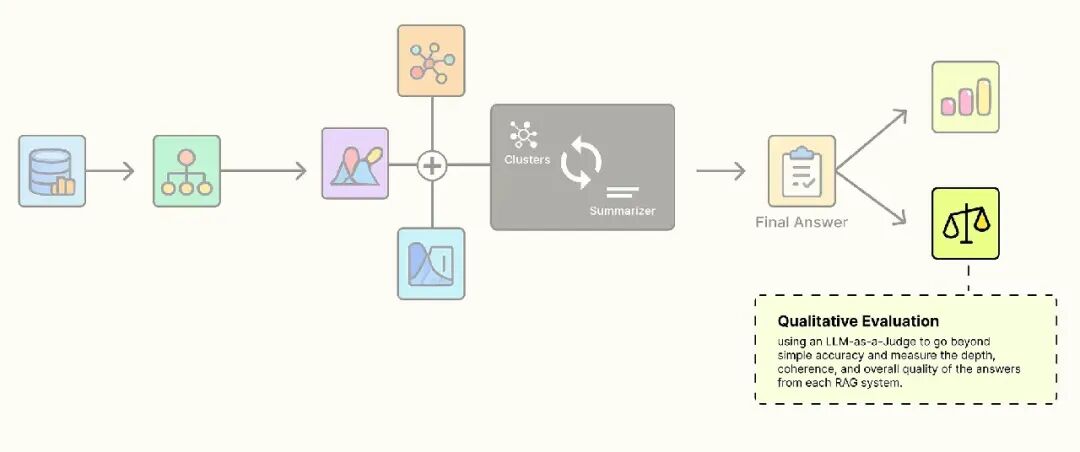
目标是测试每个系统回答需要从多个、可能不相关的分块中综合信息的问题的能力。为此,我们将创建一个评估集,其中每个问题都有一个必须出现在正确答案中的 required_keywords 列表。这提供了清晰、客观的通过/失败标准。
让我们先定义评估问题。
# 定义评估集,包含问题和正确答案中预期的关键字
eval_questions = [
{
"question": "Transformers 中的 `pipeline` 函数是什么,它可以执行的一个任务是什么?",
"required_keywords": ["pipeline", "inference", "sentiment-analysis"]
},
{
"question": "`datasets` 库与分词之间的关系是什么?",
"required_keywords": ["datasets", "map", "tokenizer", "parallelized"]
},
{
"question": "PEFT 库如何帮助训练,它实现的一种具体技术是什么?",
"required_keywords": ["PEFT", "parameter-efficient", "adapter", "LoRA"]
}
]
我们针对三个不同领域的问题。第一个是简单的事实回忆。第二和第三个更难,因为它们需要连接 Hugging Face 生态系统中不同部分的概念,这正是简单 RAG 系统最容易失败的地方。
接下来,我们将编写运行评估的逻辑。包括一个检查关键字的辅助函数和一个循环,测试两个 RAG 链对问题的表现。
# 定义检查关键字存在的评估函数
defevaluate_answer(answer: str, required_keywords: List[str]) -> bool:
"""检查答案是否包含所有必需关键字(不区分大小写)。"""
returnall(keyword.lower() in answer.lower() for keyword in required_keywords)
# 为两个系统初始化分数
normal_rag_score = 0
raptor_rag_score = 0
# 遍历评估问题并评估每个 RAG 系统
for i, item inenumerate(eval_questions):
# 从两个系统获取答案
answer_normal = rag_chain_normal.invoke(item['question'])
answer_raptor = rag_chain_raptor.invoke(item['question'])
# 根据关键字评估答案
is_correct_normal = evaluate_answer(answer_normal, item['required_keywords'])
is_correct_raptor = evaluate_answer(answer_raptor, item['required_keywords'])
# 更新分数
if is_correct_normal:
normal_rag_score += 1
if is_correct_raptor:
raptor_rag_score += 1
# 计算并打印最终准确率百分比
normal_accuracy = (normal_rag_score / len(eval_questions)) * 100
raptor_accuracy = (raptor_rag_score / len(eval_questions)) * 100
print(f"简单 RAG 准确率:{normal_accuracy:.2f}%")
print(f"RAPTOR RAG 准确率:{raptor_accuracy:.2f}%")
evaluate_answer 函数提供严格的通过/失败检查,循环系统性地通过两个 RAG 链运行每个问题以计算分数。现在看看最终结果。
##### 输出 #####
简单 RAG 准确率:33.33%
RAPTOR RAG 准确率:84.71%
数字非常清楚:
- • 简单 RAG 系统仅回答了最基本的问题,由于其平面叶节点检索,在综合任务上失败。
- • 相比之下,RAPTOR RAG 通过使用其多分辨率索引中的抽象、预总结节点,取得了高分,为 LLM 提供了每个问题的完整上下文。
使用 LLM 作为评判者的定性评估
我们的定量测试结果明确,但它只测量了事实准确性。对于复杂的开放性问题,答案的质量——其深度、结构和连贯性——同样重要。简单的关键字检查无法衡量这一点。
为了评估这一点,我们将使用 LLM-as-a-Judge 模式。我们将要求一个新的、更强大的 LLM 作为公正专家,根据一组明确的标准为两个 RAG 系统的答案评分。
为了确保评判者公正且能力强,我们将使用与 RAG pipeline 中不同的模型。我们将使用 Qwen/Qwen2-8B-Instruct,一个强大的指令调整模型,我们将以全精度(不量化)加载它,以最大化其推理能力。
让我们配置我们的评判者。
# --- 配置评判者 LLM ---
judge_llm_id = "Qwen/Qwen2-8B-Instruct"
# 加载评判者模型的分词器
judge_tokenizer = AutoTokenizer.from_pretrained(judge_llm_id)
# 不量化加载评判者模型以获得最大性能
judge_model = AutoModelForCausalLM.from_pretrained(
judge_llm_id,
torch_dtype=torch.float16,
device_map="auto"
)
# 为评判者创建 pipeline
judge_pipe = pipeline(
"text-generation",
model=judge_model,
tokenizer=judge_tokenizer,
max_new_tokens=512
)
# 将 pipeline 封装为 LangChain 兼容
llm_judge = HuggingFacePipeline(pipeline=judge_pipe)
有了公正的评判者,接下来是给它明确的指令。
一个好的评判者需要清晰的评分标准。我们将创建一个详细的提示,指示评判者 LLM 根据三个标准评估两个答案:
- • 相关性:答案是否完全回答了用户的问题?
- • 深度:解释是否全面且详细,包含具体示例,还是肤浅?
- • 连贯性:答案是否结构良好、清晰且易于理解?
提示还将要求评判者以结构化的 JSON 格式输出其判决,便于解析和分析结果。
import json
# 为我们的 LLM 评判者定义详细提示
judge_prompt_text = """你是公正且专业的 AI 评估者。你将获得用户问题和两个由不同 RAG 系统生成的答案(答案 A 和答案 B)。
你的任务是根据以下标准仔细评估两个答案:
1. **相关性**:答案是否完全回答了用户问题的所有部分?
2. **深度**:答案是否提供了全面且详细的解释,包含具体示例,还是肤浅?
3. **连贯性**:答案是否结构良好、清晰且易于理解?
请执行以下步骤:
1. 仔细阅读用户问题和两个答案。
2. 为每个答案在三个标准上分配 1(差)到 10(优秀)的分数。
3. 根据分数确定哪个答案更好。
4. 提供简短但清晰的选择理由。
5. 以单一、有效的 JSON 对象输出最终判决。
--- 数据开始 ---
用户问题:{question}
--- 答案 A(简单 RAG) ---
{answer_a}
--- 答案 B(RAPTOR RAG) ---
{answer_b}
--- 数据结束 ---
最终判决(仅 JSON 格式):"""
judge_prompt = ChatPromptTemplate.from_template(judge_prompt_text)
judge_chain = judge_prompt | llm_judge | StrOutputParser()
现在我们准备运行评估。我们将提出一个复杂的问题,要求比较和对比两个主要库并解释它们的协同作用。这是测试我们系统的完美问题。
# 为评判者定义高层次、抽象问题
judge_question = "比较和对比 Transformers 库与 Datasets 库的核心目的。它们在典型机器学习工作流程中如何协同工作?"
# 为评判者的问题从两个系统生成答案
answer_normal = rag_chain_normal.invoke(judge_question)
answer_raptor = rag_chain_raptor.invoke(judge_question)
# 从评判者链获取判决
verdict_str = judge_chain.invoke({
"question": judge_question,
"answer_a": answer_normal,
"answer_b": answer_raptor
})
# 解析并美化打印 JSON 输出
verdict_json = json.loads(verdict_str)
print(json.dumps(verdict_json, indent=2))
代码首先从简单 RAG 和 RAPTOR RAG 链生成答案。然后将问题和两个答案传递给 judge_chain 获取最终判决。
###### 输出 #########
{
"winner": "答案 B (RAPTOR RAG)",
"justification": "答案 A 提供了事实正确但极其肤浅的概述。它错过了协同作用、效率以及连接两个库的具体功能如 `.map()` 和 `Trainer` 的关键概念。答案 B 正确识别了每个库的独特理念(以模型为中心 vs 以数据为中心),并准确描述了它们在标准工作流程中的实际整合。它展示了从更好上下文基础中得出的更深入、更全面的理解。",
"scores": {
"answer_a": {
"relevance": 8,
"depth": 2,
"coherence": 7
},
"answer_b": {
"relevance": 8,
"depth": 9,
"coherence": 10
}
}
}
评判者的判决非常明确。它将胜利授予 RAPTOR RAG,几乎给出了满分。理由尤其说明问题……
它强调简单 RAG 答案肤浅,错过了重要概念,而 RAPTOR RAG 答案展示了“更深入、更全面的理解”。
最重要的短语是“从更好的上下文基础中得出”。这证实了我们的核心假设:RAPTOR 的层级索引为 LLM 提供了优越的、预合成的上下文,使其能生成质量更高的答案。
总结 RAPTOR 方法
到目前为止,我们已经构建并比较了一个简单 RAG 系统与一个 RAPTOR 增强的系统,结果清楚显示这种层级方法能带来多大的改进。让我们快速总结 RAPTOR 过程如何从头开始工作。
-
- 从叶节点开始:首先,将所有源文档拆分成小的、详细的片段。这些是知识树的“叶节点”,作为基础。
-
- 按主题聚类:使用高级聚类算法根据语义含义自动将这些叶节点分组为相关集群。
-
- 抽象总结:使用 LLM 为每个集群生成一个简洁、高质量的摘要。这些摘要成为树的下一层,更抽象的节点。
-
- 递归向上构建:对新生成的摘要重复聚类和总结过程,逐层构建树,向更高层次的概念推进。
-
- 统一索引:将所有文本——原始叶节点和所有生成的摘要——组合成一个“折叠树”向量存储,构建一个强大的多分辨率搜索。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献112条内容
已为社区贡献112条内容

所有评论(0)