必收藏!大模型长期记忆五大框架全解析:从TIM到HippoRAG,让你的AI实现自我进化
本文详解五种大模型长期记忆框架:TiM通过记忆内思考避免重复推理;CoPS结合认知记忆机制实现个性化搜索;MaLP采用双过程增强记忆与参数高效微调提升医疗助手个性化;MemoryBank引入艾宾浩斯遗忘曲线实现动态记忆更新;HippoRAG受海马体启发,通过知识图谱整合知识。这些框架旨在解决大模型长期交互中的记忆衰退问题,推动AI实现自我进化与持续学习。
基于海量数据训练的大语言模型(如GPT系列)在语言理解、推理和规划方面展现出令人瞩目的能力,在各种具有挑战性的任务中达到与人类相当的水平。当前大多数研究聚焦于通过更大规模的数据训练来进一步提升模型性能,致力于构建更强大的基座模型。然而,在持续增强基座模型的同时,探索如何使模型在推理阶段实现自我进化(即AI自我进化)对人工智能发展同样至关重要。 相较于依赖海量数据训练的方式,自我进化可能仅需有限的数据或交互即可实现。
受人类大脑皮层柱状组织结构的启发,学者们提出假设:AI模型可以通过与环境的迭代交互,逐步发展出涌现的认知能力并构建内在的表征模型。为实现这一目标,学者们主张模型必须配备长期记忆(Long-Term Memory, LTM)系统,用于存储和管理经过处理的真实世界交互数据。LTM不仅能在统计模型中表征长尾个性化数据,还能通过支持跨环境、跨智能体的多样化经验积累推动自我进化。本文将对这些具有代表性的算法框架进行详细介绍。
1 TIM框架
Think-in-Memory: Recalling and Post-thinking Enable LLMs with Long-Term Memory
论文地址:https://arxiv.org/pdf/2311.08719
作者单位:蚂蚁集团
记忆增强型大语言模型(LLMs)在长期人机交互中展现出卓越性能,其核心依赖于对历史信息的迭代检索与推理以生成高质量响应。然而,这种重复的“检索-推理”步骤容易引发思考偏差问题——即针对不同问题检索相同历史时,推理结果会出现不一致性。相比之下,人类能够将思考结果存储于记忆中,无需反复推理即可直接调用。受人类认知能力启发,论文提出一种新型记忆机制 TiM(记忆内思考),使LLMs能够维护一个随对话流不断演进的记忆库,用于存储历史思考痕迹。TiM框架包含两个关键阶段:(1) 响应生成前:LLM智能体从记忆库中检索相关思考;(2) 响应生成后:LLM智能体通过事后反思(post-think),将历史与新生成思考整合以更新记忆库。
通过将事后反思内容作为新历史存储,TiM有效消除了重复推理问题。此外,论文基于常规操作(插入、遗忘与合并操作)来组织记忆库中的历史思考信息,支持对思考内容的动态更新与演进。
记忆增强型大语言模型的核心建立在其对外部记忆缓存区历史信息进行迭代式召回与多轮次推理的复合能力之上。具体而言,在第𝑛轮对话场景下,模型需对第1至(𝑛−1)轮历史交互序列进行重新理解和重新推理。如**下图(左)**所示,当处理第2、3轮提问时,系统会对第1轮对话内容执行两次独立的检索与推理过程。但是这种范式存在着诸多问题,并且在实际应用中也会导致一些性能瓶颈:
-
【推理路径发散缺陷】
现有研究表明,针对同一个Query,大语言模型易产生推理路径发散问题。如**下图(左)**所示,模型因上下文推理路径的不一致性(contextual reasoning inconsistency)导致生成错误响应。
-
【记忆检索效率瓶颈】
传统记忆增强架构为实现历史对话相关性检索,需要计算Query与每一轮历史对话的相似度,这种基于稠密向量空间检索的机制在长程对话场景下面临O(n²)计算复杂度挑战,具体表现为:当对话轮次𝑛呈指数增长时,检索延迟将形成实时响应瓶颈。
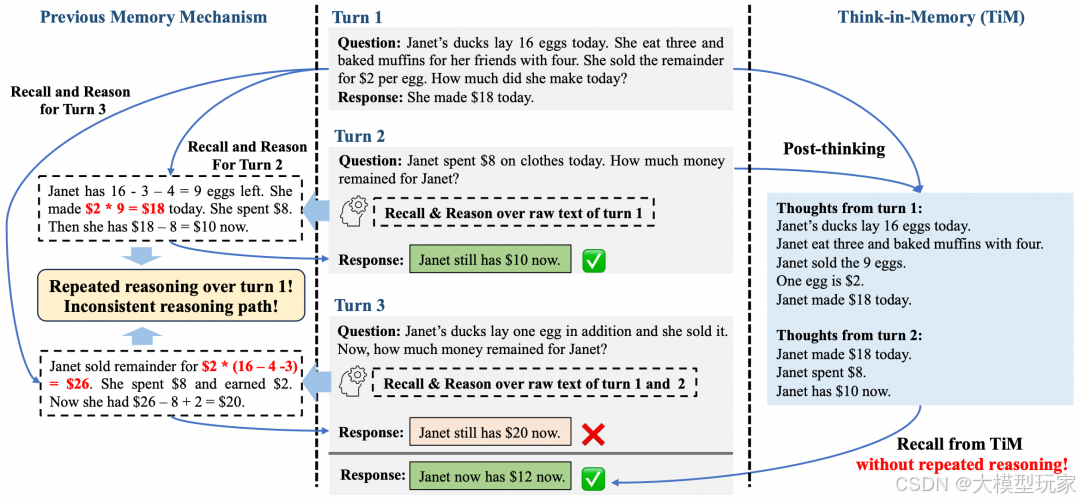
上图对比了传统记忆机制与本文提出了思维轨迹记忆(TiM)架构。(左图)现有记忆机制主要存储历史对话轮次的原始文本,需要重复执行相同历史内容的推理过程。这种设计容易导致推理路径偏移(如图左红色部分)并生成错误响应。(右图)TiM创新性地记录大语言模型在各对话阶段的思维轨迹,通过直接调用历史思维单元,无需重复推理即可规避此类偏差(如右图红色部分所示)。
针对这些问题:
- 论文提出了一种名为TiM的新型类人长期记忆机制,使大语言模型能够记忆并有选择地回忆思维。TiM可以让大语言模型直接在记忆中进行思考,而无需对长期历史进行重复推理。
- 基于成熟的认知处理方式,**制定了一系列基本操作来组织记忆中的思维,模拟了人类认知过程,使得记忆中的思维能够实现动态更新与演进。**此外,还引入了基于哈希的检索机制以实现对TiM的高效利用。
- 在多轮对话数据集上开展了大量实验。结果表明,该方法能在多个维度显著提升大语言模型的性能:(1)支持从开放领域到特定领域的多样化主题;(2)兼容中英双语环境;(3)提了升回答的正确性和连贯性。
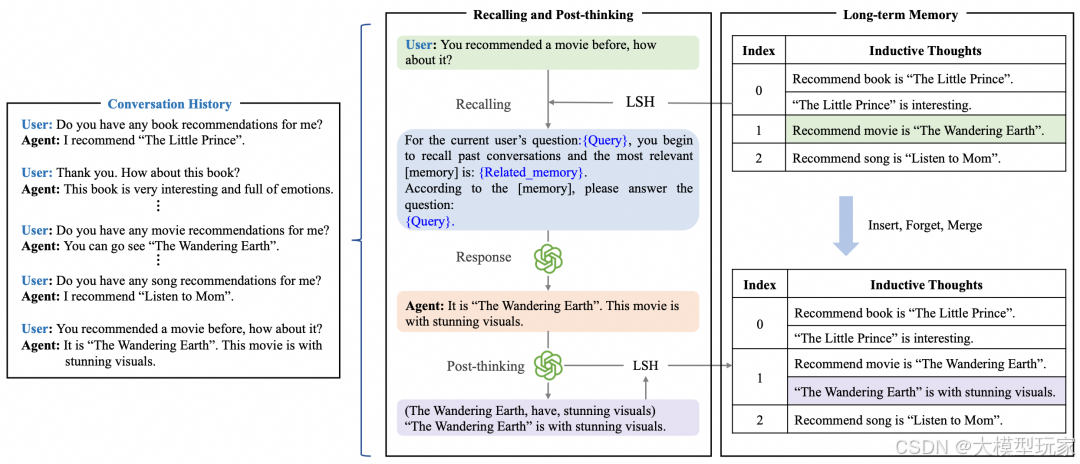
*上图是TiM框架的整体流程。大语言模型首先通过历史信息召回对问题进行初步响应生成,随后通过后置思考步骤(post-thinking)产生新的思维片段。*这些新的思维片段将作为记忆进行存储,从而有效避免对历史信息进行重复推理,实现长文本处理中的认知效率优化和计算资源集约化应用。
整体框架分为两个阶段:
- 阶段一:召回与生成:当用户提出新问题时,大模型Agent会检索相关思维以生成精准回答。由于我们将生成的推理思维保存为外部记忆,该阶段可直接基于记忆内容召回并回答问题,无需对原始历史对话文本进行重复推理。
- 阶段二:后思考与更新:在回答问题后,会让大语言模型Agent对Query-Response对(Q-R)进行后思考,并将新生成的推理思维插入记忆缓存M中。
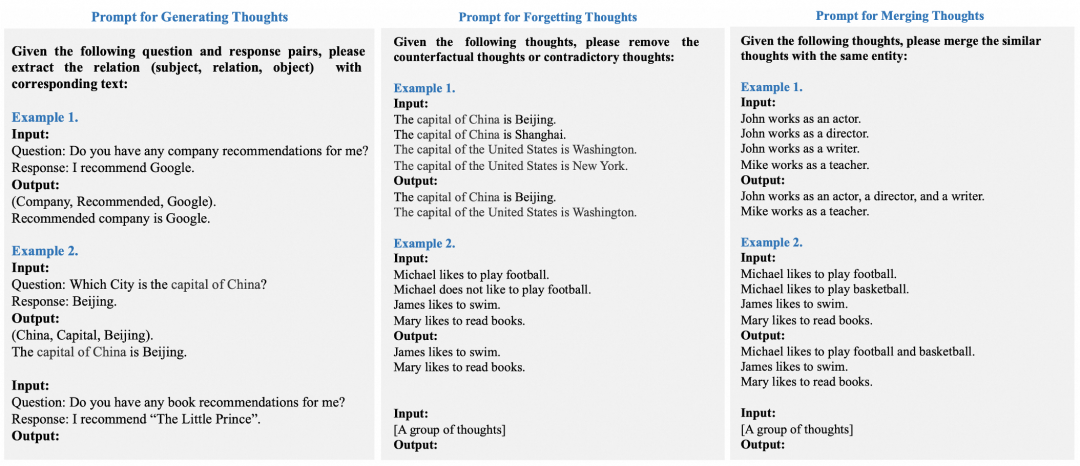
图:思维生成、遗忘与合并操作的Prompt样例
通过TiM系统应用,让大模型在每次回答问题之前,都对外部的存储空间进行一定处理,包括插入、遗忘和合并(如上图所示)。这样,大模型在应对多轮对话或问题时,可以更有效地处理并回忆上下文信息,准确检索出所需信息。类似的方式还包括递归式生成场景记忆,该方法可视作让大模型在每一轮回答完问题后,总结前一轮问题包含的上下文,将其放入外置记忆中,从而避免大模型在多轮对话时忘记前几次谈话中的内容。
论文可以借鉴的思路有:(1)在post-thinking阶段生成针对当前会话的思维,并将其进行存储来避免针对历史信息的重复推理。(2)提出了一种针对长期记忆的管理(插入、遗忘、合并等操作)方法。(3)以key-value的方式保存历史思维信息,利用一种基于哈希的检索机制(即局部敏感哈希算法)来从Memory中快速保存和检索相关思维。
2 CoPS框架
Cognitive Personalized Search Integrating Large Language Models with an Efficient Memory Mechanism
论文地址:https://arxiv.org/pdf/2402.10548
作者单位:人民大学、北京师范大学
传统搜索引擎通常为所有用户提供相同的搜索结果,忽略了个人偏好。为了解决这一局限性,个性化搜索应运而生,它根据从查询日志中提取的用户偏好对搜索结果进行重新排序。基于深度学习的个性化搜索方法展现出了潜力,但它们严重依赖大量的训练数据,因此容易受到数据稀疏性问题的影响。**本文提出了一种认知个性化搜索(CoPS)模型,该模型将大型语言模型(LLMs)与受人类认知启发的认知记忆机制相结合。CoPS利用LLMs来增强用户建模和用户搜索体验。认知记忆机制包括用于快速感官响应的感官记忆、用于复杂认知响应的工作记忆以及用于存储历史交互的长期记忆。**CoPS通过三步法处理新查询:对Query进行识别再查找操作、利用相关历史信息构建用户画像,以及基于个性化意图对文档进行排序。实验表明,在零样本场景下,CoPS的表现优于基线模型。
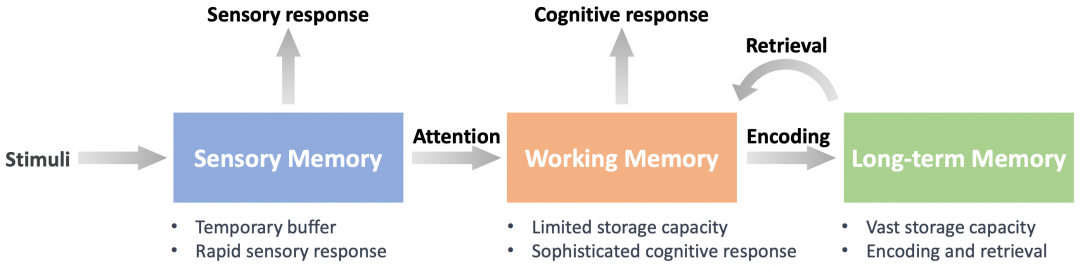
图:人类大脑的记忆机制
认知心理学的最新研究将人类大脑的记忆机制划分为不同的组成部分:感官记忆单元(Sensory Memory)、工作记忆单元(Working Memory)和长期记忆单元(Long-term Memory),如上图所示。感官记忆是记忆的最初阶段,负责存储感官信息并促进对刺激的快速反应。一旦信息通过感觉记忆,它就会进入工作记忆,工作记忆会将新信息与从长期记忆中提取的现有知识相结合。最后,来自工作记忆的信息被编码到长期记忆中,并在需要时可以从中检索。长期记忆存储持久的信息,包括知识和经验。这些模块共同构成了一个高效处理、存储和检索信息的系统。
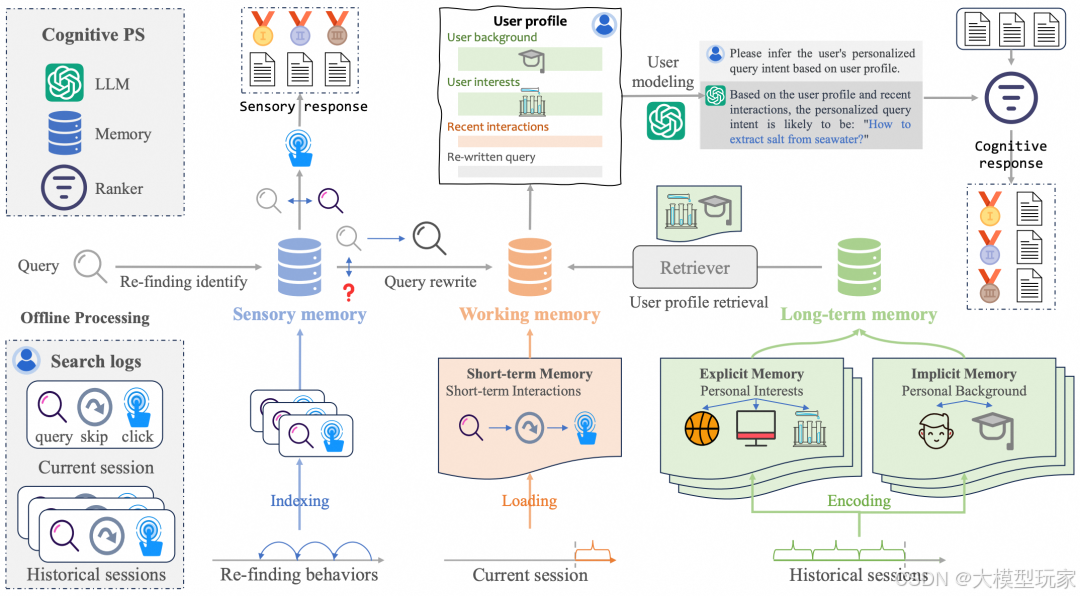
上图是CoPS的总体架构。系统首先利用感知记忆来识别再查找行为,如果识别到相关行为,则生成感官响应。否则,工作记忆将与大型语言模型(LLM)协作,积累与查询相关的个性化线索。在完成用户建模后,使用排序器根据用户兴趣对结果进行重新排序。
论文借鉴了人类认知记忆机制,为CoPS构建了具有类似结构的外部记忆单元。感官记忆单元旨在实现快速查询处理,用于识别查询是否与再查找行为相关——即重新访问之前看过的内容。被识别为[再查找]的查询会立即进行排序,而其他查询则被发送到工作记忆单元进行更深入的分析。工作记忆单元根据用户近期历史评估查询,并与长期记忆协作,整合用户过去的兴趣。这些数据形成一个用户画像,供大型语言模型(LLM)用来建模用户意图。
长期记忆单元作为用户偏好的庞大存储库,通过提供用户长期兴趣和习惯的洞察,辅助工作记忆单元的工作。
关于感官记忆单元(Sensory Memory)、工作记忆单元(Working Memory)和长期记忆单元(Long-term Memory)的定义功能如下:
Sensory Memory:感官记忆的关键作用是为外部刺激提供即时反馈。在个性化搜索的背景下,有一种被称为“再查找”的用户行为模式。用户查找以前遇到过的信息时即产生了“再查找”模式,这种模式有助于以一种简单有效的方式预测用户的下一次点击行为。受此观察的启发,论文提出在感官记忆中存储用户再查找行为的信息。这种方法能够快速识别再查找行为,并促进即时感官响应的生成。
Working Memory:工作记忆是一个关键的认知系统,负责与当前任务相关的信息的临时存储和整合。在个性化搜索的背景下,通过考虑信息的三个关键维度,可以有效捕捉用户的个性化查询意图。
- Relevant interactions:用户的历史搜索记录中通常包含对个性化无用的噪声和不相关信息。因此,历史记录中与当前查询直接相关的信息对于定制搜索结果更为重要。
- Contextual interactions:用户通常会在一个会话中输入一系列查询,以满足特定的信息需求。这些查询结合当前会话 𝐻 中相应的“跳过”和“点击”行为,提供了丰富的上下文线索。利用这些信息可以显著增强模型推断用户当前意图的能力。
- Re-written Query:用户查询通常较为简短,可能包含拼写错误或其他不一致的地方,这可能会阻碍对潜在意图的准确理解。因此,对这些查询进行优化或重写是更好地理解和满足用户特定信息需求的关键步骤。
Long-term Memory:长期记忆在记忆系统中发挥着关键作用,其核心功能在于支持用户个性化信息在长时间跨度下的持续留存。在个性化搜索场景中,该模块专为保存用户的长期交互记录而设计。鉴于用户历史数据规模庞大且包含大量噪声信息,**论文采取对长期历史H进行分段编码的策略,重点保留最具显著性的个性化信息。具体实现上,通过将用户历史划分为固定长度的时间窗口,各时段内的交互数据被分配至特定记忆槽位。**为全面捕捉用户个性化特征,论文从显式记忆和隐式记忆两个维度对用户交互进行了编码建模。
- Explicit Memory:**显式记忆模块的核心功能在于提取用户在特定主题下的兴趣偏好特征,为个性化文档推荐构建精准匹配依据。**该模块采用键值对编码存储机制:键向量表征主题语义,值向量记录该主题下用户关注的具体内容项。具体实现层面,通过提示工程策略驱动大语言模型,采用"[示例] [用户交互记录] 请根据用户历史查询日志,将其兴趣偏好归纳为多个主题"的指令模板,完成交互数据的结构化编码。
- Implicit Memory:**隐式记忆模块专注于存储用户职业属性、性别特征等潜在特征因子,通过多维度用户画像构建实现个性化查询意图的深度解析。**典型应用场景如:当查询中出现"python"等术语时,该模块可有效推断用户潜在的程序员职业特征。与显式记忆模块类似,论文采用大语言模型(LLM)作为编码器实现特征提取。在此需要特别说明的是,该编码过程可灵活替换为文档摘要模型或向量编码模型等替代方案。
论文提出了一种认知个性化搜索模型(CoPS),该模型结合了大型语言模型(LLM)的优势与认知记忆机制,以优化搜索过程中的用户建模。CoPS包含三个关键组件:(1) 认知记忆机制作为核心存储单元,(2) 大型语言模型(LLM)作为核心认知单元,以及(3) 排序器作为核心评分单元。具体而言,CoPS采用三步法来有效处理新查询。首先,CoPS利用其感官记忆评估新查询是否对应于再查找行为。如果识别为再查找操作,CoPS会立即利用感官反应对文档进行排序;否则,查询将被转发至工作记忆进行进一步分析。在第二步中,工作记忆整合相关的历史信息,包括用户的短期历史记录以及从长期记忆中提取的与查询相关的用户兴趣,从而构建一个基础用户画像,供LLM进行用户建模。最后,CoPS使用排序组件根据用户画像对候选文档进行优先级排序。实验结果表明,在零样本场景下,论文提出的模型优于基线模型。
论文可以借鉴的思路有:利用一种模仿人类大脑记忆机制的架构来组织记忆单元,从而确保模型在处理大量数据时的可扩展性和性能。
3 MaLP框架
LLM-based Medical Assistant Personalization with Short- and Long-Term Memory Coordination
论文地址:https://arxiv.org/pdf/2309.11696
作者单位:伍斯特理工学院、阿里巴巴
大型语言模型(如GPT4)在自然语言理解与生成领域展现出卓越能力,**但基于其构建的个性化医疗助手探索仍存在显著空白。医疗助手的核心价值在于通过差异化交互实现精准服务,然而患者因背景与需求不同导致的对话模式差异,对构建以用户为中心的医疗助手提出挑战。**传统全参数训练方案虽可实现目标,但面临难以承受的计算资源消耗。现有研究多采用对话记忆增强方法,通过记录历史错误实现新查询的改进响应,但单一记忆模块存在表达力局限,而全量训练则成本过高。为此,**本研究提出融合参数高效微调(PEFT)范式的计算仿生记忆机制:通过构建生物神经元启发的动态记忆单元,实现医疗知识图谱与用户个性化特征的协同建模;**为推动该领域研究,论文还开源了基于开放医疗语料库构建的全新对话数据集及完整实现代码。该方案为突破大语言模型长文本处理瓶颈提供了兼具计算效率与个性化服务能力的技术框架。
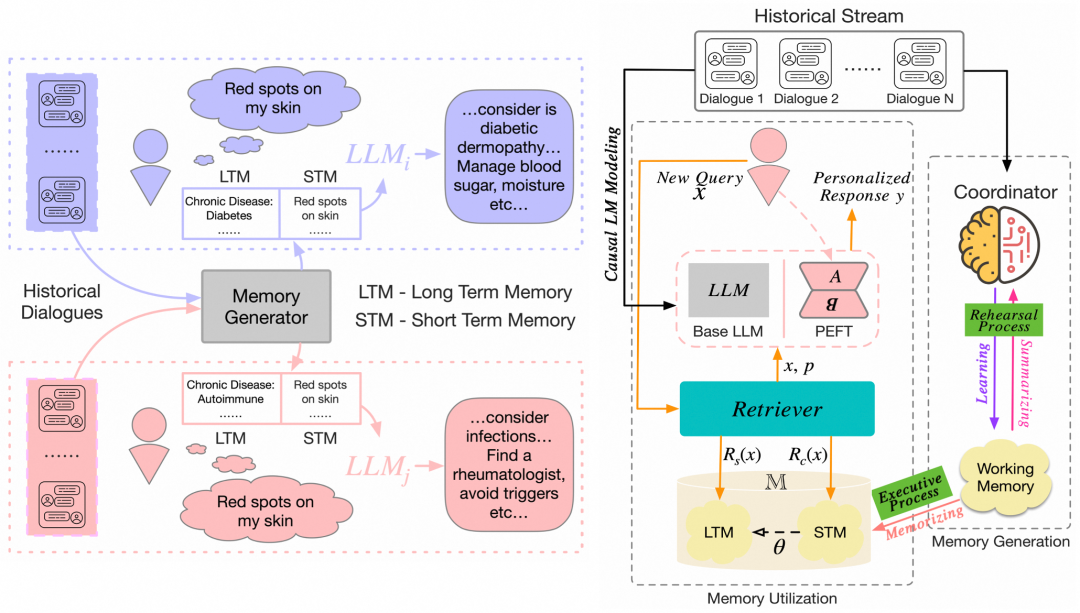
图:MALP整体结构
图(左):个性化响应*:医疗从业者能够通过持续性的诊断对话识别患者关键信息。因此,即使面对相同的医疗询问,由于患者个体差异的原因,得到回复也可能截然不同,这突显了借助大语言模型(LLM)开发个性化医疗助理的必要性。因此需要探究如何对大语言模型(LLMs)进行定制化开发以向患者提供个性化医疗建议,使其能够获得最贴合个体需求的针对性答案。*
图(右):MaLP框架*:用户的对话历史首先会被输入至协调器C(coordinator C)和一个具备参数高效微调(PEFT)技术的可训练大语言模型(LLM)中,分别进行记忆生成与因果语言建模。随后,记忆生成模块将基于双过程增强记忆机制(DPeM)形成记忆,其中双过程(dual-process)由绿色方框标注,三个具体步骤则由彩色线条分别表示。*迭代完成后,用户的新查询将被传递至检索器进行相关记忆匹配,最终由微调后的LLM结合检索到的知识及历史对话生成个性化响应。
论文的主要工作如下:
- 提出了一种新颖的双过程增强记忆(Dual-Process enhanced Memory, DPeM)机制,其运作机制高度模拟现实世界的记忆形成过程,相较于现有记忆结构,该机制实现了7%的性能提升。
- 设计了基于DPeM与参数高效微调技术(PEFT)的统一框架MaLP,通过深度适配用户个性化需求显著提升响应质量。
- 构建了一个融合用户偏好与历史记录的新型医疗对话数据集,该数据集为探索个性化医疗助手提供了独特的研究视角。
关于DPeM机制
与先前研究的核心区别在于:论文的工作转向探索复杂记忆结构的改进,而非局限于检索器(retriever)的单一优化。论文着重于设计一种高度贴合现实世界记忆过程的记忆机制,提出了由双过程(预演过程、执行过程)增强的三阶段流程——学习(Learning)、总结(Summarizing)、记忆(Memorizing)。
预演过程(Rehearsal Process):包含从数据D中学习信息并存储至工作记忆(working memory)。基于当前轮次对话内容,工作记忆通过总结步骤进行迭代更新。此双阶段预演过程由具备强大自然语言理解能力的协调器(coordinator)驱动。
执行过程(Executive Process):根据信息被访问的频率,评估工作记忆中的内容以决定将其存入短期记忆(Short-Term Memory, STM)还是长期记忆(Long-Term Memory, LTM)。
关于MaLP框架
记忆生成(Memory Generation):记忆能够提供来自个人历史对话的潜在知识,这些知识可作为提示词,以协助大语言模型(LLM)针对新查询生成所需响应,得益于论文前面提到的DPeM机制,记忆生成模块可生成结构化的记忆系统。
记忆利用(Memory Utilization):单纯依赖记忆机制实现个性化大语言模型(LLMs)仍面临挑战——即使采用了记忆增强型提示(memory-augmented prompts)与预注入知识(pre-injected knowledge),生成响应的质量最终仍取决于LLM自身的理解与生成能力。因此,通过微调LLM以满足用户个性化需求,自然成为增强模型个性化能力的潜在选项。但传统微调方法通常需要大量计算与数据资源,论文的目标是通过利用历史对话以用户友好的方式优化LLM的响应生成。在这一背景下,参数高效微调(PEFT)方法为实现这一目标提供了低资源消耗的解决方案。
其他模块
在 MaLP框架 中,多个关键组件参与记忆生成与利用过程,确保系统内各模块的高效协作:
协调器C(Coordinator C):协调器C在学习与总结阶段(涉及从对话上下文中提取信息,并对习得信息进行知识提纯)发挥核心作用。因此,论文采用具备长文本理解能力、可执行总结与判断的强大模型实现该模块功能。
检索器R(Retriever R):检索是访问已存储知识的过程。然而,短期记忆(STM)与长期记忆(LTM)中存储的知识存在差异,其检索过程亦不同。STM按存储顺序进行检索,而LTM通过关联性检索,因此论文设计了两种检索器:
- 最邻近匹配检索器Rc:用于STM检索,基于Levenshtein距离寻找与查询最接近的STM知识(该距离指将字符串s转换为字符串t所需的最少删除、插入或替换操作次数)。
- 语义匹配检索器Rs:用于LTM检索。由于LTM检索过程快速且无意识,论文选择训练编码器获取语义嵌入表示,并基于余弦相似度从LTM中检索知识。
论文可以借鉴的思路有:
提出了一种新颖的双过程增强记忆(Dual-Process enhanced Memory, DPeM)机制,其运作机制高度模拟现实世界的记忆形成过程。
设计了基于DPeM与参数高效微调技术(PEFT)的统一框架MaLP,通过深度适配用户个性化需求显著提升响应质量。
4 MemoryBank框架
MemoryBank: Enhancing Large Language Models with Long-Term Memory
论文地址:https://arxiv.org/pdf/2305.10250
作者单位:中山大学、哈尔滨工业大学、皇家理工学院
大语言模型(LLMs)的革命性进展已深度重构人机交互范式,但其长期记忆机制的缺失成为制约技术演进的关键瓶颈——尤其在需要持续交互的智能伴侣、心理咨询、秘书辅助等场景中存在明显局限。
为此,论文提出面向LLMs的认知记忆框架MemoryBank,突破现有模型在长期交互中的记忆衰退难题。该机制实现三大突破性能力:基于历史对话的动态记忆索引、持续进化的记忆更新机制、基于长期交互的人格画像构建。创新性地引入艾宾浩斯遗忘曲线理论(Ebbinghaus’ forgetting curve theory),设计记忆强度衰减与强化算法:通过时间衰减因子与语义显著性权重,智能调节记忆存储密度,实现近似人类记忆的"选择性遗忘"特性,高价值记忆通过强化机制得以持久保留,而低关联度信息则按指数衰减规律自然遗忘。
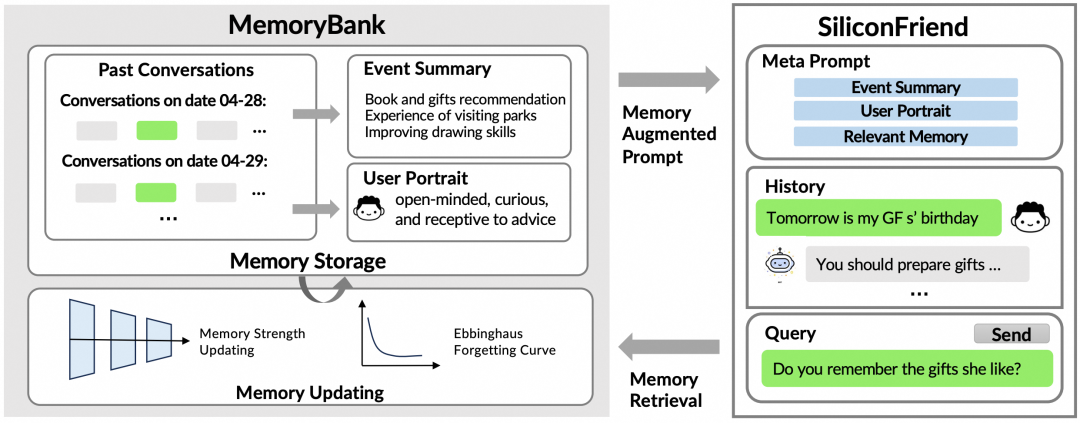
MemoryBank架构如上图所示:其中,记忆存储库持久化保存历史对话记录、摘要化事件及用户人格画像;记忆更新机制通过动态演化持续优化存储内容;记忆检索模块实现关联记忆召回。
关于MemoryBank
MemoryBank记忆机制采用三位一体的架构设计,由三大核心组件构成:(1)作为核心数据存储单元的记忆存储库;(2)支持上下文感知的记忆检索器;(3)基于艾宾浩斯遗忘曲线理论构建的记忆更新器。这种结构化设计实现了从记忆存储、情境化提取到动态更新的全链路闭环管理。
记忆存储:
记忆存储(Memory storage),即MemoryBank的仓库,是一个强大的数据存储库,它存储每日对话记录、过去事件的摘要以及用户个性的持续评估,从而构建了一个动态且多层次的记忆体系。
- 深度记忆存储**:**MemoryBank的存储系统通过以详细的时间顺序记录多轮对话,全面捕捉AI与用户互动的丰富性。每段对话均附带时间戳存储,构建出有序的历史互动叙事。这种精细化的记录机制不仅支持精准的记忆检索,还能有效促进后续的记忆更新流程,为对话历史提供了详尽的索引体系。
- 层次事件摘要**:**MemoryBank不仅进行对话细节存储。还通过对对话进行加工提炼,构建类似人类记忆核心体验的高层次事件摘要,将冗长的对话内容浓缩为精炼的每日事件摘要,进而整合生成全局概要,最终形成层次化记忆结构,实现对历史互动和重要事件的概括。具体而言,以每日对话/事件为输入,通过提示词"总结内容中的事件和关键信息 [对话/事件]"指示大语言模型进行每日事件摘要和全局事件摘要的生成。
- 动态个性理解**:**MemoryBank致力于用户画像的深度解析。系统通过长期交互持续评估并更新用户理解信息,构建每日个性洞察报告。这些洞察数据经聚合分析形成全局用户画像,最终通过多层次分析架构实现AI伴侣的持续学习与响应优化,使其能够根据用户个性特征进行精准交互适配。具体实现中,以日常对话或个性分析数据为输入,通过"请基于以下对话总结用户个性特征与情感状态[对话内容]"或"以下是用户多日表现出的个性特征与情感,请给出高度凝练的通用性人格总结[每日画像]"等提示词,引导大语言模型完成个性特征的推导与整合。
记忆检索:
记忆检索机制类似于知识检索任务。论文使用了双塔稠密检索模型,在该模型中,每轮对话及事件摘要均被视为独立记忆片段,这些记忆通过编码器模型被预先编码为上下文表征形式。由此,整个记忆库被预编码为₁₂,其中每个均为某一记忆片段的向量表示形式。这些向量表征通过FAISS建立索引来实现高效检索。与此同时,当前对话上下文通过模型编码为查询向量,该向量用于在记忆库M中检索最相关记忆片段。
记忆更新:
基于持久化记忆存储机制与记忆检索技术,大语言模型的记忆能力可获得显著提升。但对于需要实现拟人化记忆行为的应用场景(如AI伴侣、虚拟IP等),则需引入记忆更新机制——通过选择性遗忘时间久远且调用频率较低的非重要记忆片段,可使AI伴侣的交互表现更趋自然。
MemoryBank的记忆遗忘机制灵感来源于艾宾浩斯遗忘曲线理论,并遵循下面的基本规则:
- 遗忘速率**:**艾宾浩斯研究发现记忆保持率随时间推移递减,其通过遗忘曲线量化这一规律:新获得的信息若未经主动复习,将呈现指数级遗忘特征。数据显示,未经强化的记忆在20分钟后仅留存58%,24小时后骤降至33%。
- 时间与记忆衰减**:**曲线初始阶段呈现陡峭下降趋势,揭示学习行为发生后数小时至数日内将快速遗忘约70%内容(临界点在"记忆黄金48小时")。此后衰减速率趋缓,形成长期记忆基底。
- 间隔强化效应**:**艾宾浩斯发现,重新学习信息比初次学习更容易。定期回顾和重复所学内容可以重置遗忘曲线,使其变得平缓,从而提高记忆的保留效果。
艾宾浩斯遗忘曲线通过指数衰减模型来描述:,其中表示记忆留存率,即有百分之多少的记忆可以被保留。 表示获得信息后所经过的时间。约等于2.71828。表示记忆强度,其值会根据学习深度、重复次数等因素发生变化。为了简化记忆更新过程,论文将建模为一个离散值,当某条信息(记忆片段)在对话中首次被提及时将其初始化为1。当某个记忆片段在对话中被召回时,其在记忆中留存更久,此时会将的值增加1,并将时间重置为0,从而降低其被遗忘的概率。
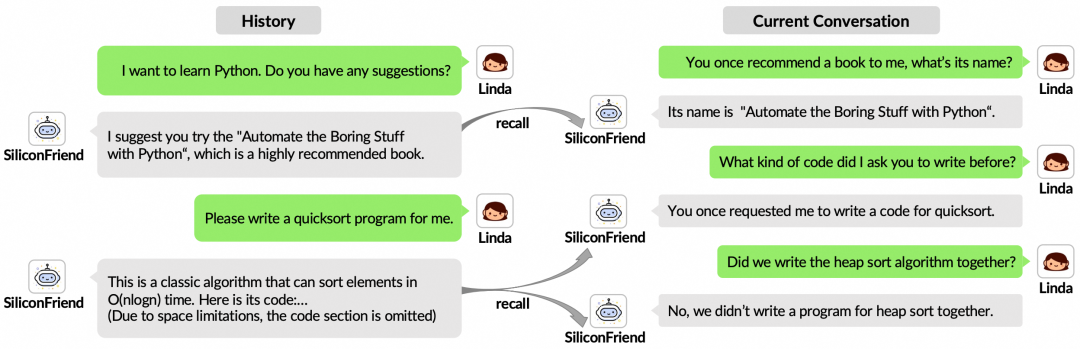
图:关于Memory Recall样例

图:关于“个性化”样例
在记忆检索时,一系列信息被组织成对话提示,包括相关记忆、全局用户画像和全局事件摘要。因此,大模型在生成响应时能够参考过往的记忆,并提供针对用户画像量身定制的互动形式。
论文可以借鉴的思路有:(1)引入艾宾浩斯遗忘曲线理论(Ebbinghaus’ forgetting curve theory),通过时间衰减因子与语义显著性权重,智能调节记忆存储密度,实现近似人类记忆的"选择性遗忘"特性。(2)系统通过长期交互持续评估并更新用户理解信息,构建每日个性洞察报告。这些洞察数据经聚合分析形成全局用户画像。
5 HippoRAG框架
HippoRAG: Neurobiologically Inspired Long-Term Memory for Large Language Models
论文地址:https://arxiv.org/pdf/2405.14831
作者单位:俄亥俄州立大学、斯坦福大学
为了在充满挑战且不断变化的自然环境中生存和发展,哺乳动物大脑进化出了存储大量世界知识并持续整合新信息的能力,同时避免了灾难性遗忘。尽管大语言模型(LLMs)已取得令人瞩目的成就,但即使在引入检索增强生成(RAG)技术后,它们仍难以在预训练后高效整合大量新经验。论文提出HippoRAG——一个受人类长期记忆的海马体记忆索引理论启发的新型检索框架,**HippoRAG通过协同整合大语言模型、知识图谱和个性化PageRank算法,来模拟人类记忆中的新皮层与海马体的的不同角色,实现对新的知识和经验进行深度高效地整合。**在多跳问答(QA)任务中将HippoRAG与现有RAG方法进行对比,结果表明:HippoRAG显著优于SOTA方法,提升幅度最高达20%。HippoRAG的单步检索性能与IRCoT等迭代检索相当甚至更优,同时成本降低10-20倍,速度提升6-13倍。将HippoRAG融入IRCoT可带来显著的增益。
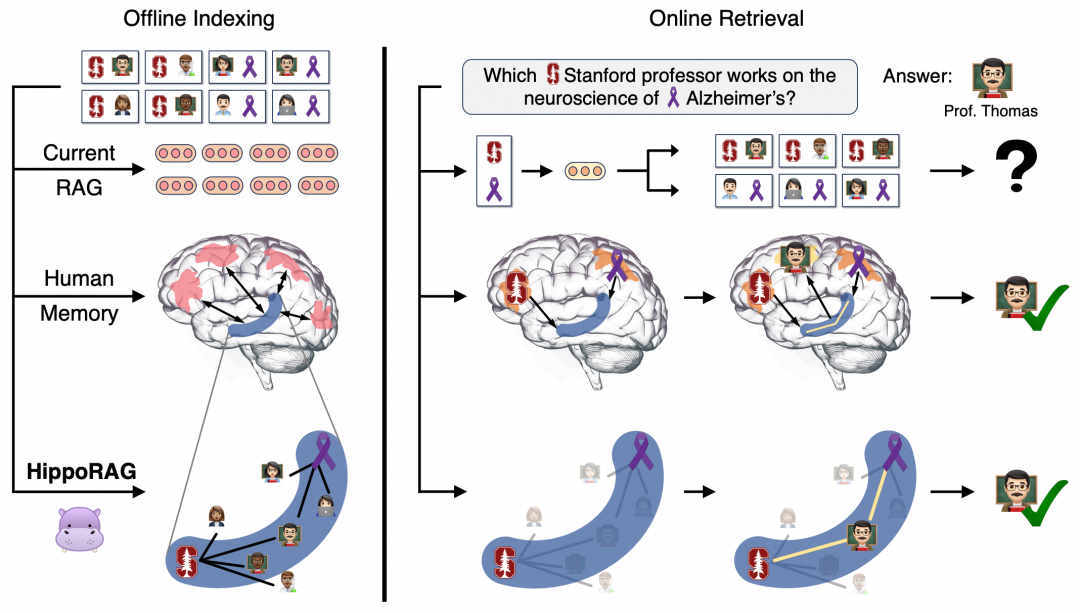
图1:知识集成与RAG:对于当前的RAG系统而言,很难处理一些需要知识整合的任务。以上述例子为例,我们需要从描述可能涉及数千名斯坦福教授和阿尔茨海默病研究人员的段落集合中,找到一位从事阿尔茨海默病研究的斯坦福教授。由于现有方法对段落进行孤立编码,除非某个段落同时提及这两个特征(斯坦福教授身份和阿尔茨海默病研究),否则现有方法难以识别托马斯教授。相比之下,熟悉该教授的人可以凭借人脑的联想记忆能力快速地回想起他(即受到上图中蓝色部分的C形海马体的索引结构驱动)。受此机制启发,HippoRAG使大语言模型能够构建并利用类似的关联图谱来处理知识整合任务。
标准多跳问答(QA)任务同样需要整合检索语料库中不同段落的信息。为解决此类任务,现有RAG系统采用将多步检索与LLM迭代生成相结合的方式关联离散段落。然而,即便完美执行多步RAG流程,在应对知识整合的诸多场景时仍显不足——如图1所示的"路径发现型多跳问题"即为典型的例证。
相比之下,人类大脑却能相对轻松地完成这类高难度知识整合任务。源于人类长期记忆研究的经典理论——海马体索引理论,为这种强大的能力提供了合理解释。Teyler与Discenna提出:人类强大的情境化持续更新记忆能力,依赖于新皮层(负责处理与存储实际记忆表征)与C形海马体(承载海马体索引,即一组互相关联的索引系统,指向新皮层记忆单元并存储其关联关系)之间的协同作用。
论文提出的HippoRAG框架是一种通过模拟人类记忆模型为大型语言模型(LLMs)提供长期记忆能力的RAG系统。**其创新性地模拟大脑新皮层(neocortex)处理感知输入的机制:通过大语言模型将文本语料库转化为动态结构的知识图谱,作为人工海马体索引(artificial hippocampal index)。****当处理新查询时,HippoRAG首先识别query中的核心概念,随后以这些概念为种子节点(seeds),在知识图谱上运行个性化PageRank(PPR)算法,实现跨文本片段的信息整合与检索。**PPR算法使HippoRAG能够探索知识图谱中的关联路径并识别相关子图,本质上在单次检索步骤中完成了多跳推理(multi-hop reasoning)。这种机制模拟了人类海马体整合分布式记忆片段的生物过程,使系统能够在知识图谱中高效追踪跨节点的语义关联,从而为问答任务提供更深层的上下文理解能力。
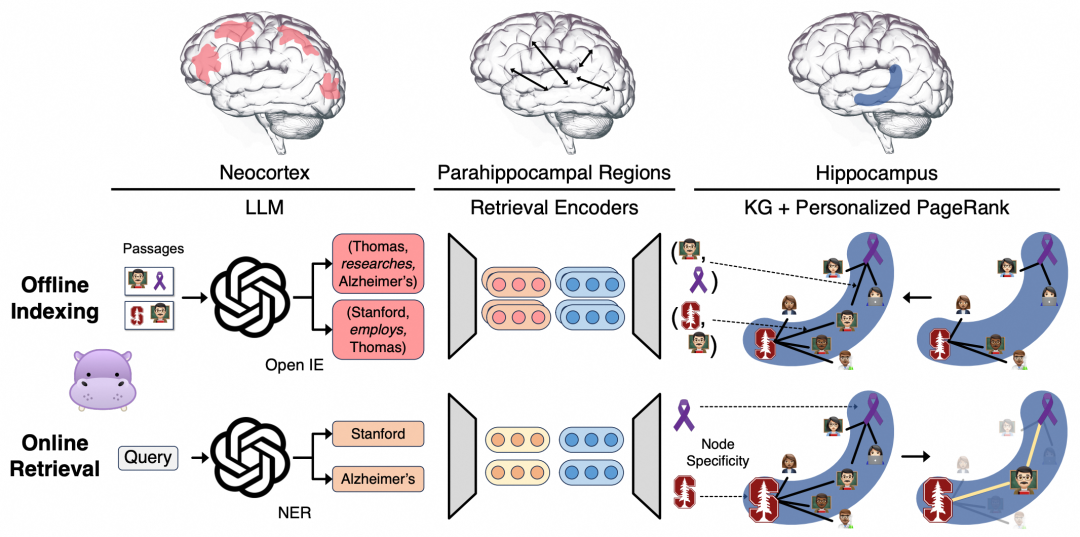
图2*:HippoRAG方法详解。论文通过建模人类长期记忆的三个组成部分来模拟其模式分离(pattern separation)和模式补全(completion)功能。在离线索引阶段(中间部分),利用大语言模型将文本片段转化为开放知识图谱(open KG)的三元组,并将其添加至人工海马体索引(artificial hippocampal index),同时,人工海马旁回区域(海马旁区 PHR)可检测同义词关系。例如图中所示,有关Thomas教授的三元组被提取并整合到知识图谱中。在线检索阶段(底部部分),大语言模型模拟的新皮层(neocortex)负责从查询中提取命名实体,而海马体检索编码器(parahippocampal retrieval encoders)则将这些实体与人工海马体索引关联。最后,通过个性化PageRank算法实现基于上下文的检索,成功提取出Thomas教授的相关信息。这一过程模拟了人类记忆系统中海马体与新皮层的协同工作:海马体负责精确检索分布式记忆痕迹,新皮层则进行语义整合与最终输出。*
该理论认为模式分离主要形成于记忆编码过程:该过程始于新皮层将接收到的感知刺激处理为更易操作更高层次的特征表征,再传输至海马旁回区域(PHR)进行路径标记,最终由海马体完成索引构建。当信号抵达海马体时,其中显著信号将被纳入海马索引系统,并在系统内建立关联关系。
记忆编码完成后,每当海马体从海马旁回区域(PHR)的传导通路接收到部分感知信号时,模式补全机制便会启动记忆提取过程。海马体利用其上下文依赖性记忆系统(学界认为此系统由CA3亚区密集连接的神经元网络实现),在海马索引中识别出完整且相关的记忆内容,随后通过PHR通路将其传回新皮层进行信息重构。因此,这种复杂的神经机制使得新信息的整合无需更新新皮层表征,仅通过调整海马索引即可实现。
Teyler和Discenna研究发现,人类长期记忆依赖于三个关键部位的协作:(1). 新皮层:存储具体信息;(2). 海马旁区域:负责信息中转;(3). 海马体:作为记忆索引器;它们一起协作赋予大脑两大能力:模式分离(pattern separation):保证了不同知觉体验在表征上的唯一性。模式补全(pattern completion):通过部分刺激检索到完整记忆。HippoRAG用这三个模块模拟人脑记忆系统:
- 新皮层 → 大语言模型(LLM):解析文本,提取关键概念(如人名、机构名)
- 海马旁区域 → 检索编码器:建立概念间的联系(如"Stanford"和"斯坦福大学"的映射)
- 海马体 → 知识图谱+PPR算法:构建关联网络,通过个性化PageRank快速定位相关节点
离线索引(Offline Indexing):离线索引阶段使用大语言模型和一个检索编码器(retrieval encoder 来处理一系列文本段落。如上图所示:首先使用,通过 OpenIE从中的每个段落提取一组名词短语节点和关系边。此过程通过对 LLM 进行1-shot提示词完成。
具体来说,首先从每个段落中提取一组命名实体,然后将这些命名实体添加到OpenIE提示词中,以提取最终的三元组(triples),这些三元组同时也包含了除命名实体之外的一些概念(名词短语)。最后,当中两个实体的表征向量之间的余弦相似度超过阈值 时,使用为这些实体添加额外同义关系集 (synonymy relations),这种方法为海马体索引(hippocampal index)引入了更多的边,从而实现更有效的模式补全(pattern completion)。
在线检索(Online Retrieval):在检索过程中,使用one-shot提示词对大语言模型进行提示,以从查询中提取一组命名实体,记作查询命名实体(query named entities)。随后,query中的这些命名实体会由检索编码器(retrieval encoder)进行编码。接着,对于查询中的每个命名实体,在节点集合中找到节点编码与查询实体编码之间相似度最高的那个节点,并将其作为对应的查询节点,得到查询节点集合。
在找到查询节点后,在海马体索引(hippocampal index)(即一个包含个节点和条边(基于三元组的边和基于同义关系的边)的知识图谱)上运行个性化PageRank算法(PPR algorithm)。该算法使用一个在节点集合上定义的个性化概率分布。在此分布中,每个查询节点具有相等的概率,所有其他节点的概率为零。这种初始化方式使得概率团能够(通过随机游走)传播到查询节点的邻居节点上,这些节点将对最终检索结果做出贡献。运行PPR算法后可以得到一个在节点集合上的更新的概率分布。最后,为了获得各个段落的评分,将更新后的概率分布向量与之前定义的矩阵(维)进行相乘运算(),得到一个表示每个段落排序评分的向量。我们使用这个评分来进行检索。
论文可以借鉴的思路有:受人类长期记忆的海马体记忆索引理论启发,提出了一种新型检索框架HippoRAG,在知识图谱上运行个性化PageRank(PPR)算法,实现跨文本片段的信息整合与检索。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。
随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:
人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:
04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)
05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!
06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献263条内容
已为社区贡献263条内容

所有评论(0)