Qwen3-Next:迈向更极致的训练推理性价比
Qwen团队发布新一代大模型Qwen3-Next,采用混合注意力机制与高稀疏度MoE架构,显著提升训练和推理效率。其80B参数模型仅激活3B参数,训练成本不到Qwen3-32B的10%,在长上下文任务中推理吞吐提升10倍以上。新模型在基准测试中表现优异,部分指标接近旗舰模型Qwen3-235B,并支持256K超长上下文处理。团队同时开源了相关代码和最佳实践,包括Transformers、SGLan
来了来了又来了,通义千问Qwen团队又在深夜(其实是凌晨)带来了最新的开源工作 Qwen3-Next。针对长上下文与大参数规模优化,创新融合混合注意力机制、高稀疏度MoE及多token预测,显著提升训练与推理效率。
模型合集:
https://modelscope.cn/collections/Qwen3-Next-c314f23bd0264a
免费体验:
https://chat.qwen.ai/
在官方Blog里,Qwen团队提出 Context Length Scaling和Total Parameter Scaling是未来大模型发展的两大趋势,为了进一步提升模型在长上下文和大规模总参数下的训练和推理效率,设计了全新的Qwen3-Next的模型结构。 该结构相比Qwen3的MoE模型结构,进行了以下改进。
核心改进:混合注意力机制、高稀疏度 MoE 结构、一系列训练稳定友好的优化,以及提升推理效率的多 token 预测机制。
基于Qwen3-Next的模型结构,Qwen团队训练了Qwen3-Next-80B-A3B-Base模型,该模型拥有800亿参数仅激活30亿参数。 该Base模型实现了与Qwen3-32B dense模型相近甚至略好的性能,而它的训练成本(GPU hours) 仅为Qwen3-32B的十分之一不到,在32k以上的上下文下的推理吞吐则是Qwen3-32B的十倍以上,实现了极致的训练和推理性价比。
基于 Qwen3-Next-80B-A3B-Base 模型,同步开发并发布了Qwen3-Next-80B-A3B-Instruct与 Qwen3-Next-80B-A3B-Thinking,解决了混合注意力机制 + 高稀疏度 MoE 架构在强化学习训练中长期存在的稳定性与效率难题,实现了 RL 训练效率与最终效果的双重提升。Qwen3-Next-80B-A3B-Instruct 与旗舰模型 Qwen3-235B-A22B-Instruct-2507 表现相当,同时在 256K 超长上下文处理 任务中展现出显著优势。
Qwen3-Next-80B-A3B-Thinking 在复杂推理任务上表现卓越,不仅优于预训练成本更高的 Qwen3-30B-A3B-Thinking-2507 与 Qwen3-32B-Thinking, 更在多项基准测试中超越闭源模型 Gemini-2.5-Flash-Thinking,部分关键指标已逼近Qwen3-235B-A22B-Thinking-2507。
01 模型结构
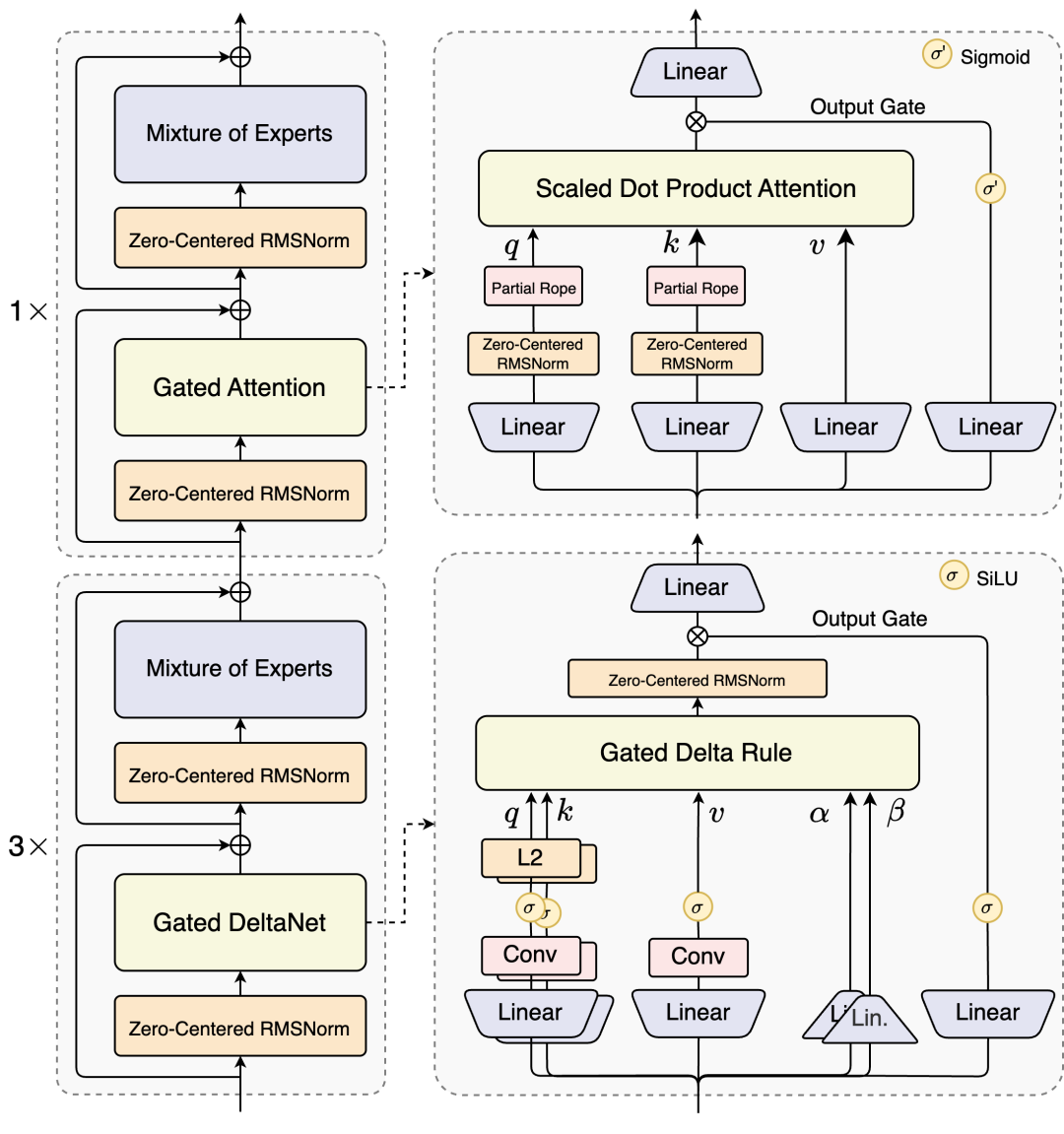
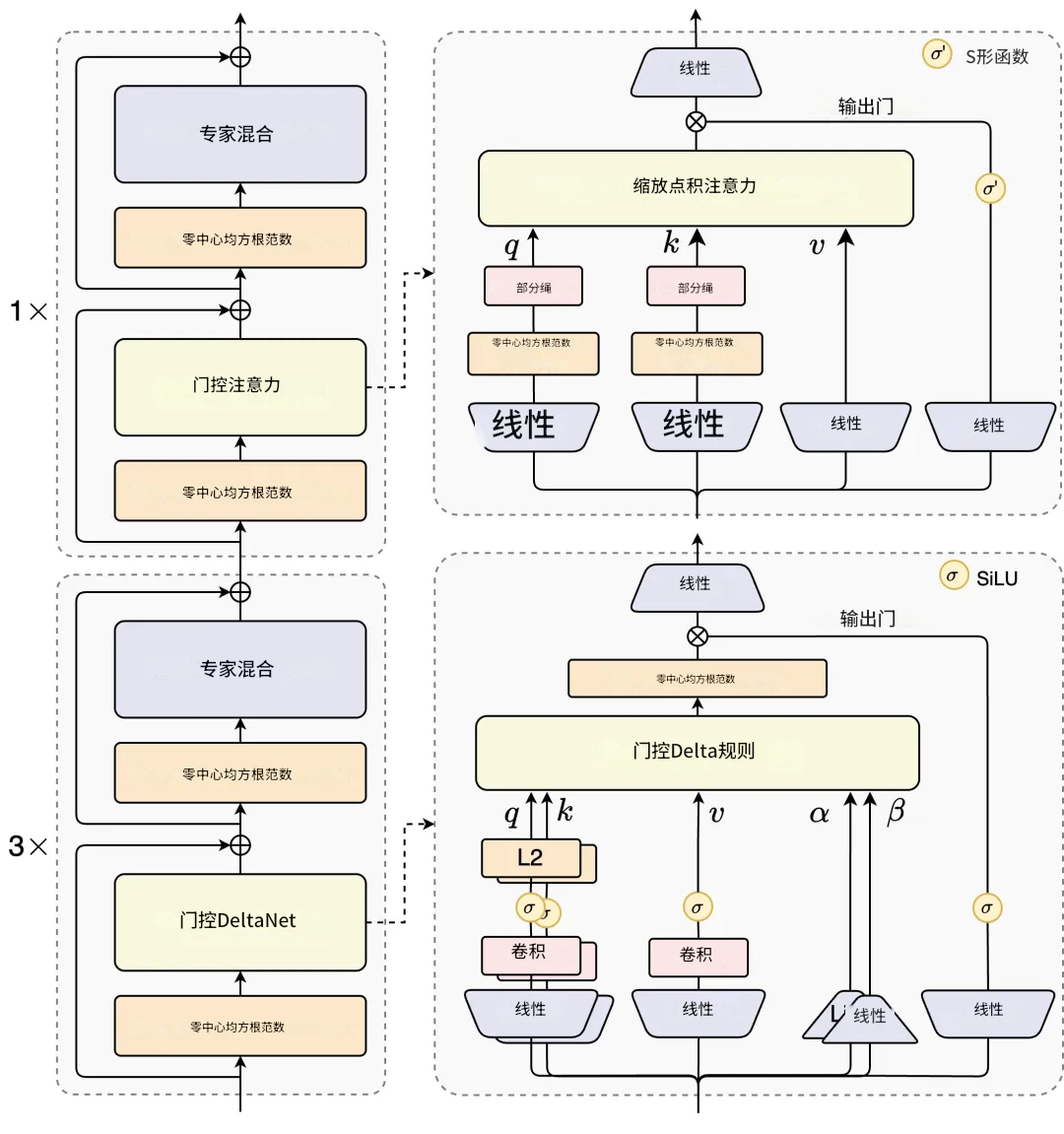
Qwen3-Next的核心架构设计在效率与性能间取得突破性平衡。
针对线性注意力高效但召回能力弱、标准注意力计算开销大的局限,采用75% Gated DeltaNet与25%标准注意力的混合架构:Gated DeltaNet在长序列建模中显著优于滑动窗口注意力和Mamba2;
标准注意力层通过输出门控机制缓解低秩问题,单头维度扩展至256,仅对前25%位置添加旋转位置编码(RoPE),有效提升长程外推能力。系统实验表明,该配置在多个基准测试中一致超越单一架构,实现性能与效率的双重优化。
MoE架构总参数量80B,推理时仅激活约3.7%(3B)参数。相比Qwen3的128总专家和8路由专家,Qwen3-Next扩展至512总专家(10路由+1共享),通过全局负载均衡机制,持续增加专家数量仍能稳定降低训练损失,最大化资源利用率。
训练稳定性方面,输出门控机制有效消除注意力池化与极大激活现象;采用Zero-Centered RMSNorm并施加weight decay,解决QK-Norm中norm weight异常膨胀问题;MoE router参数初始化归一化,确保训练早期各专家被公平采样,提升小规模实验可靠性及大规模训练稳定性。
原生Multi-Token Prediction(MTP)机制深度融入主干训练,不仅提升Speculative Decoding接受率,更通过多步训练一致性优化推理效率,显著增强实际场景中的生成流畅度与响应速度。这一系列设计共同构建了高效、稳定且高性能的下一代大模型架构。
02 模型效果
训练效率及推理效率
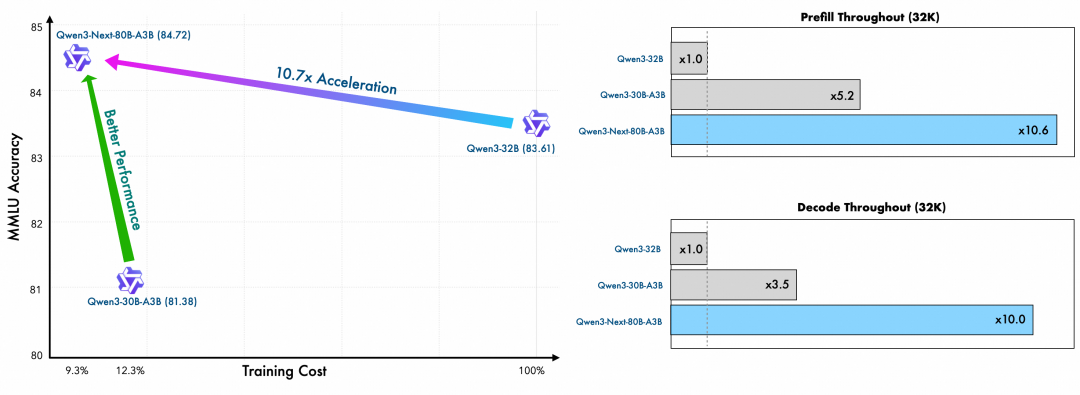
Qwen3-Next 采用的是 Qwen3 36T 预训练语料的一个均匀采样子集,仅包含 15T tokens。其训练所消耗的 GPU Hours 不到 Qwen3-30A-3B 的 80%;而与 Qwen3-32B 相比,仅需 9.3% 的 GPU 计算资源,即可实现更优的模型性能,展现出极高的训练效率与性价比。
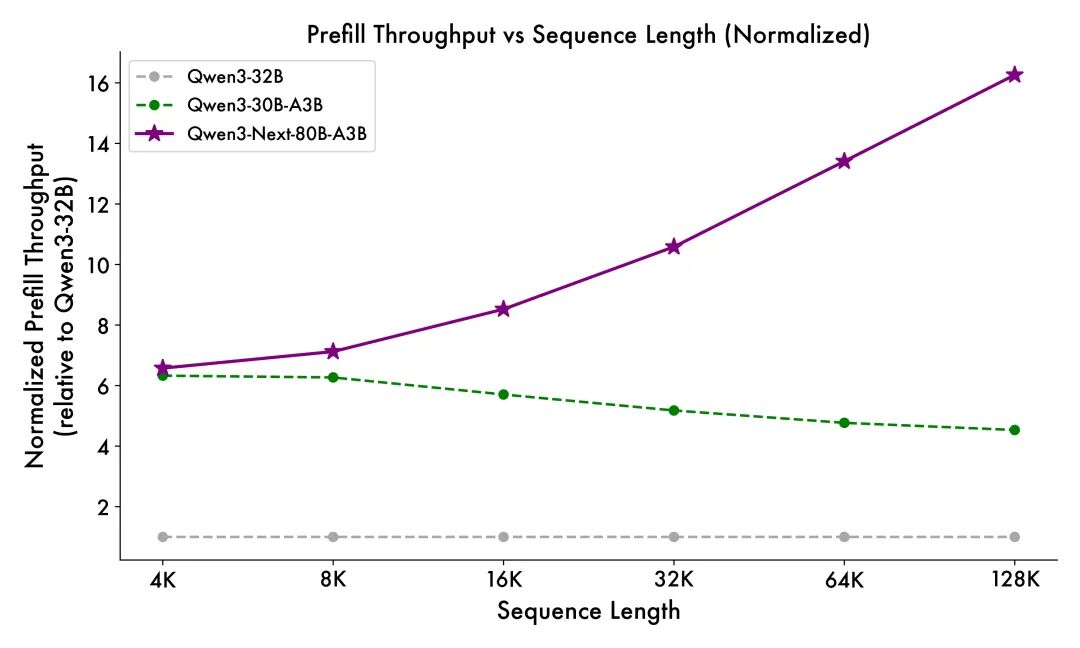
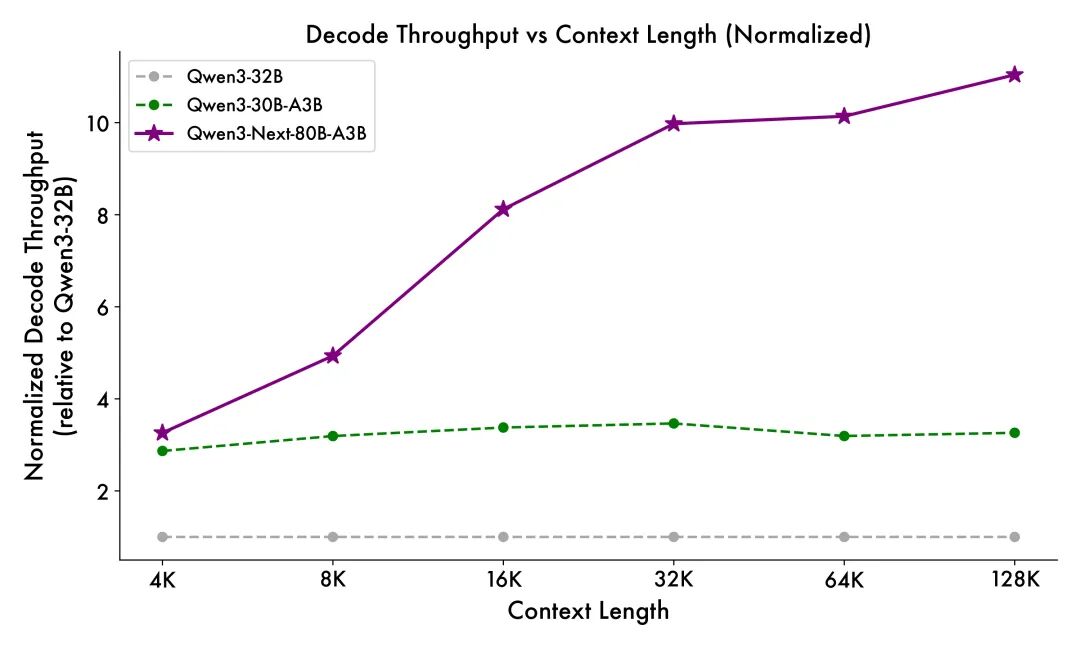
得益于创新的混合模型架构,Qwen3-Next 在推理效率方面表现出显著优势。与 Qwen3-32B 相比,Qwen3-Next-80B-A3B 在预填充(prefill)阶段展现出卓越的吞吐能力:在 4k tokens 的上下文长度下,吞吐量接近前者的七倍;当上下文长度超过 32k 时,吞吐提升更是达到十倍以上。 在解码(decode)阶段,该模型同样表现优异——在 4k 上下文下实现近四倍的吞吐提升,而在超过 32k 的长上下文场景中,仍能保持十倍以上的吞吐优势。
Base模型表现
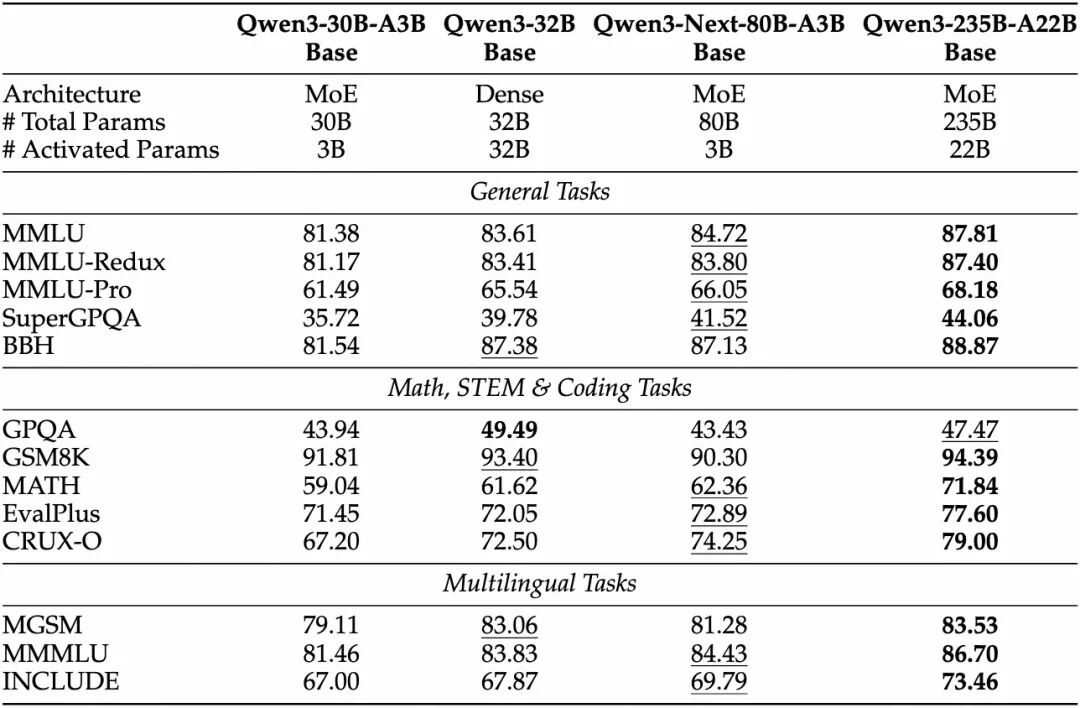
Qwen3-Next-80B-A3B-Base 仅使用十分之一的 Non-Embedding 激活参数,在大多数基准测试中便已超越 Qwen3-32B-Base,且显著优于 Qwen3-30B-A3B,展现出卓越的模型效率与性能优势。
Instruct模型表现
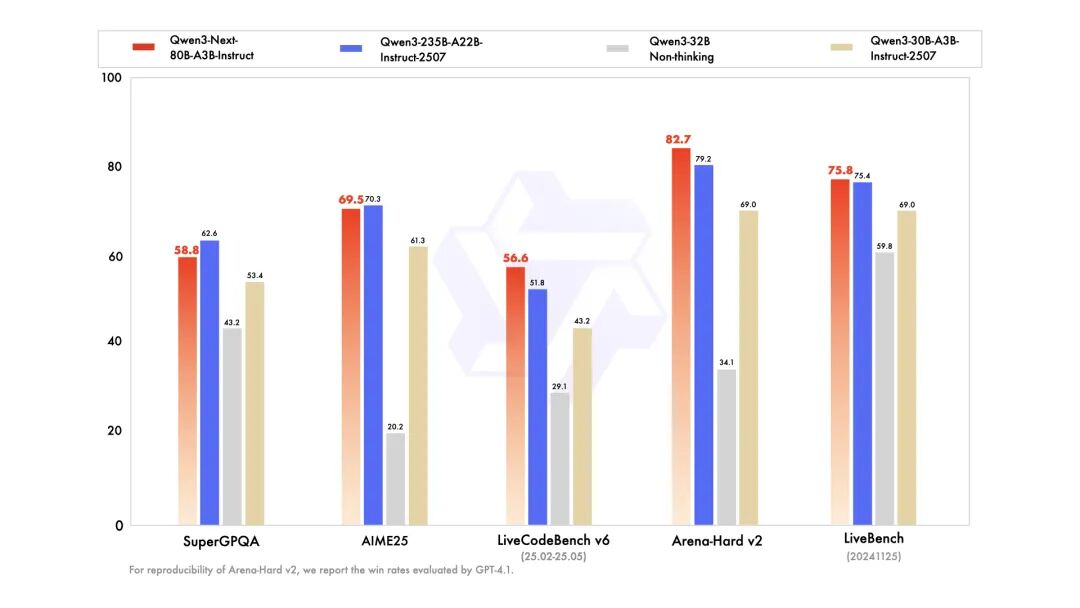
Qwen3-Next-80B-A3B-Instruct 显著优于 Qwen3-30B-A3B-Instruct-2507 和 Qwen3-32B-Non-thinking,并取得了几乎与 Qwen3-235B-A22B-Instruct-2507 相近的结果。
Qwen3-Next-80B-A3B-Instruct 在RULER上所有长度的表现明显优于层数相同、注意力层数更多的 Qwen3-30B-A3B-Instruct-2507,甚至在 256k 范围内都超过了层数更多的 Qwen3-235B-A22B-Instruct-2507,这展示了 Gated DeltaNet 与 Gated Attention 混合模型在长文本情景下的优越性。

Thinking模型表现
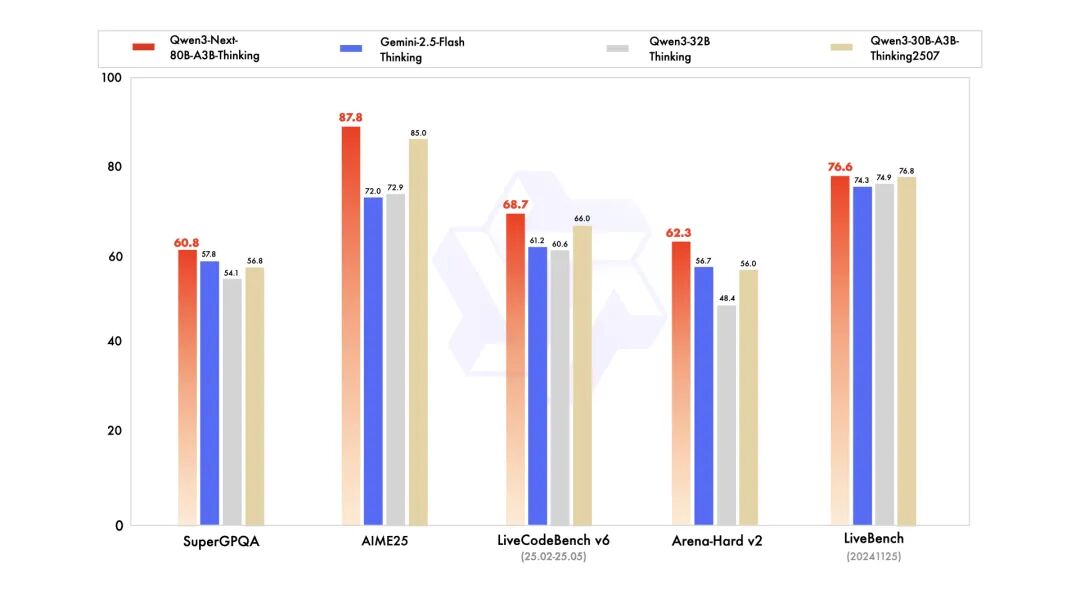
Qwen3-Next-80B-A3B-Thinking 优于预训练成本更高的 Qwen3-30B-A3B-Thinking-2507 和 Qwen3-32B-thinking,超过了闭源的模型 Gemini-2.5-Flash-Thinking,并在部分指标上接近了Qwen系列的最新的旗舰模型 Qwen3-235B-A22B-Thinking-2507。
03 最佳实践
以下示例均基于 Qwen3-Next-80B-A3B-Instruct 版本给出
Transformers
Qwen3-Next 的代码已合并至 Hugging Face transformers 的主分支。
pip install git+https://github.com/huggingface/transformers.git@main若使用较早版本,您将遇到以下错误:
KeyError: 'qwen3_next'下方代码片段演示了如何基于给定输入使用模型生成内容:
from modelscope import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-Next-80B-A3B-Instruct"
# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
dtype="auto",
device_map="auto",
)
# 准备模型输入
prompt = "请给我一个关于大语言模型的简短介绍。"
messages = [
{"role": "user", "content": prompt},
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# 执行文本生成
generated_ids = model.generate(
**model_inputs,
max_new_tokens=16384,
)
# 提取生成的输出
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
content = tokenizer.decode(output_ids, skip_special_tokens=True)
print("content:", content)Hugging Face Transformers 目前尚未普遍支持 Multi-Token Prediction (MTP)。
效率或吞吐量提升高度依赖具体实现。 建议采用专用推理框架(如 SGLang 和 vLLM)执行推理任务。
根据推理设置,您可能通过安装 flash-linear-attention 和 causal-conv1d 获得更佳效率。 请参阅上述链接获取详细安装说明和依赖要求。
部署时,可以使用最新的 sglang 或 vllm 创建兼容 OpenAI 的 API 接口。
SGLang
SGLang 已在其 main 分支中支持 Qwen3-Next,可通过源码安装:
pip install 'sglang[all] @ git+https://github.com/sgl-project/sglang.git@main#subdirectory=python'以下命令可在 4 个 GPU 上使用张量并行,创建最大上下文长度为 256K token 的 API 接口(地址:http://localhost:30000/v1):
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Instruct --port 30000 --tp-size 4 --context-length 262144 --mem-fraction-static 0.8若要启用 MTP(其余设置同上),推荐使用以下命令:
SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1 python -m sglang.launch_server --model-path Qwen/Qwen3-Next-80B-A3B-Instruct --port 30000 --tp-size 4 --context-length 262144 --mem-fraction-static 0.8 --speculative-algo NEXTN --speculative-num-steps 3 --speculative-eagle-topk 1 --speculative-num-draft-tokens 4当前必须设置环境变量 SGLANG_ALLOW_OVERWRITE_LONGER_CONTEXT_LEN=1。
默认上下文长度为 256K。若服务启动失败,建议将上下文长度减小至更小值,例如 32768。
vLLM
vLLM 已在其 main 分支中支持 Qwen3-Next,可通过源码安装:
pip install git+https://github.com/vllm-project/vllm.git以下命令可在 4 个 GPU 上使用张量并行,创建最大上下文长度为 256K token 的 API 端点(地址:http://localhost:8000/v1):
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct --port 8000 --tensor-parallel-size 4 --max-model-len 262144若要启用 MTP(其余设置同上),推荐使用以下命令:
VLLM_ALLOW_LONG_MAX_MODEL_LEN=1 vllm serve Qwen/Qwen3-Next-80B-A3B-Instruct --port 8000 --tensor-parallel-size 4 --max-model-len 262144 --speculative-config '{"method":"qwen3_next_mtp","num_speculative_tokens":2}'当前必须设置环境变量 VLLM_ALLOW_LONG_MAX_MODEL_LEN=1。
默认上下文长度为 256K。若服务启动失败,建议将上下文长度减小至更小值,例如 32768。
04 模型微调
我们介绍使用ms-swift对Qwen3-Next进行自我认知训练。ms-swift是魔搭社区官方提供的大模型与多模态大模型训练部署框架。
ms-swift开源地址:https://github.com/modelscope/ms-swift
在开始微调之前,请确保您的环境已准备妥当。
# pip install git+https://github.com/modelscope/ms-swift.gitgit clone https://github.com/modelscope/ms-swift.gitcd ms-swiftpip install -e .
如果您需要自定义数据集微调模型,你可以将数据准备成以下格式。
{"messages": [{"role": "user", "content": "浙江的省会在哪?"}, {"role": "assistant", "content": "浙江的省会在杭州。"}]}使用transformers后端微调:
-
注意:transformers微调MoE模型速度较慢。使用Megatron对Qwen3-Next的支持正在进行中,进度查看此PR:https://github.com/modelscope/ms-swift/pull/5764
CUDA_VISIBLE_DEVICES=0,1,2,3 \ # 指定使用的 GPU(这里是 0,1,2,3 四张卡)
swift sft \ # 使用 swift 工具进行有监督微调 (Supervised Fine-Tuning, SFT)
--model Qwen/Qwen3-Next-80B-A3B-Instruct \ # 基础模型名称(Qwen3 80B 指令微调版)
--train_type lora \ # 训练方式:LoRA(低秩适配)
--dataset 'swift/Chinese-Qwen3-235B-2507-Distill-data-110k-SFT#2000' \ # 第一个数据集(蒸馏数据,采样2000条)
'swift/self-cognition#1000' \ # 第二个数据集(自我认知,采样1000条)
--torch_dtype bfloat16 \ # 使用 bfloat16 精度训练,节省显存
--num_train_epochs 1 \ # 训练轮数为 1
--per_device_train_batch_size 1 \ # 每个设备上的训练 batch size = 1
--per_device_eval_batch_size 1 \ # 每个设备上的验证 batch size = 1
--learning_rate 1e-4 \ # 学习率 = 1e-4
--lora_rank 8 \ # LoRA 秩(rank),通常越大效果越好,但显存开销更大
--lora_alpha 32 \ # LoRA α 超参数(影响权重缩放)
--target_modules all-linear \ # 指定 LoRA 注入的目标模块,这里是所有线性层
--router_aux_loss_coef 1e-3 \ # 路由器辅助损失系数(MoE 或多路机制时用)
--gradient_accumulation_steps 16 \ # 梯度累积步数(等效于 batch_size * 16)
--eval_steps 50 \ # 每 50 步进行一次评估
--save_steps 50 \ # 每 50 步保存一次 checkpoint
--save_total_limit 2 \ # 最多保留 2 个 checkpoint,旧的会被删除
--logging_steps 5 \ # 每 5 步打印一次日志
--max_length 2048 \ # 输入序列最大长度(上下文长度)
--output_dir output \ # 输出目录(保存模型与日志)
--warmup_ratio 0.05 \ # 学习率预热比例(前 5% 训练步数用于 warmup)
--dataloader_num_workers 4 \ # DataLoader 的 worker 数量,加速数据加载
--model_author swift \ # 训练后模型的作者信息
--model_name swift-robot # 训练后模型的名称(可自定义)训练显存占用:4 * 60GiB
训练完成后,使用以下命令进行推理:
CUDA_VISIBLE_DEVICES=0,1,2,3 \swift infer \--adapters output/vx-xxx/checkpoint-xxx \--stream true \--max_new_tokens 2048
推送模型到ModelScope:
swift export \--adapters output/vx-xxx/checkpoint-xxx \--push_to_hub true \--hub_model_id '<your-model-id>' \--hub_token '<your-sdk-token>'
05 总结
Qwen3-Next 在模型架构上实现了重大突破,引入了注意力机制方面的多项创新,包括线性注意力和注意力门控机制,并在其 MoE 设计中进一步提升了稀疏性。Qwen3-Next-80B-A3B 在“思考模式”和“非思考模式”下的性能均与规模更大的 Qwen3-235B-A22B-2507 相当,同时在推理速度上显著提升,尤其在长上下文场景中表现更为突出。通过此次发布,我们旨在赋能开源社区,使其能够与前沿架构创新同步演进。展望未来,我们将持续优化这一架构,开发 Qwen3.5,致力于实现更高的智能水平与生产力。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献41条内容
已为社区贡献41条内容

所有评论(0)