论文阅读:nature 2025 Larger and more instructable language models become less reliable
让模型重新学会“认怂”——遇到不会的题,果断说“不会”,别瞎编;训练时重点守住“简单题必对”的底线,和人类对“难度”的判断对齐;给模型配“监督员”——比如在医疗、财务这些关键场景,让另一个AI或人类再检查一遍答案,减少错误。总结一下:这篇研究相当于给大家提了个醒——别迷信“越大、越会聊天的模型就越靠谱”,它可能在你最放心的简单题上翻车,还装得特别自信。未来得让模型更“务实”,而不是更“虚荣”。
总目录 大模型相关研究:https://blog.csdn.net/WhiffeYF/article/details/142132328
https://www.nature.com/articles/s41586-024-07930-y
https://www.doubao.com/chat/20176008819354882
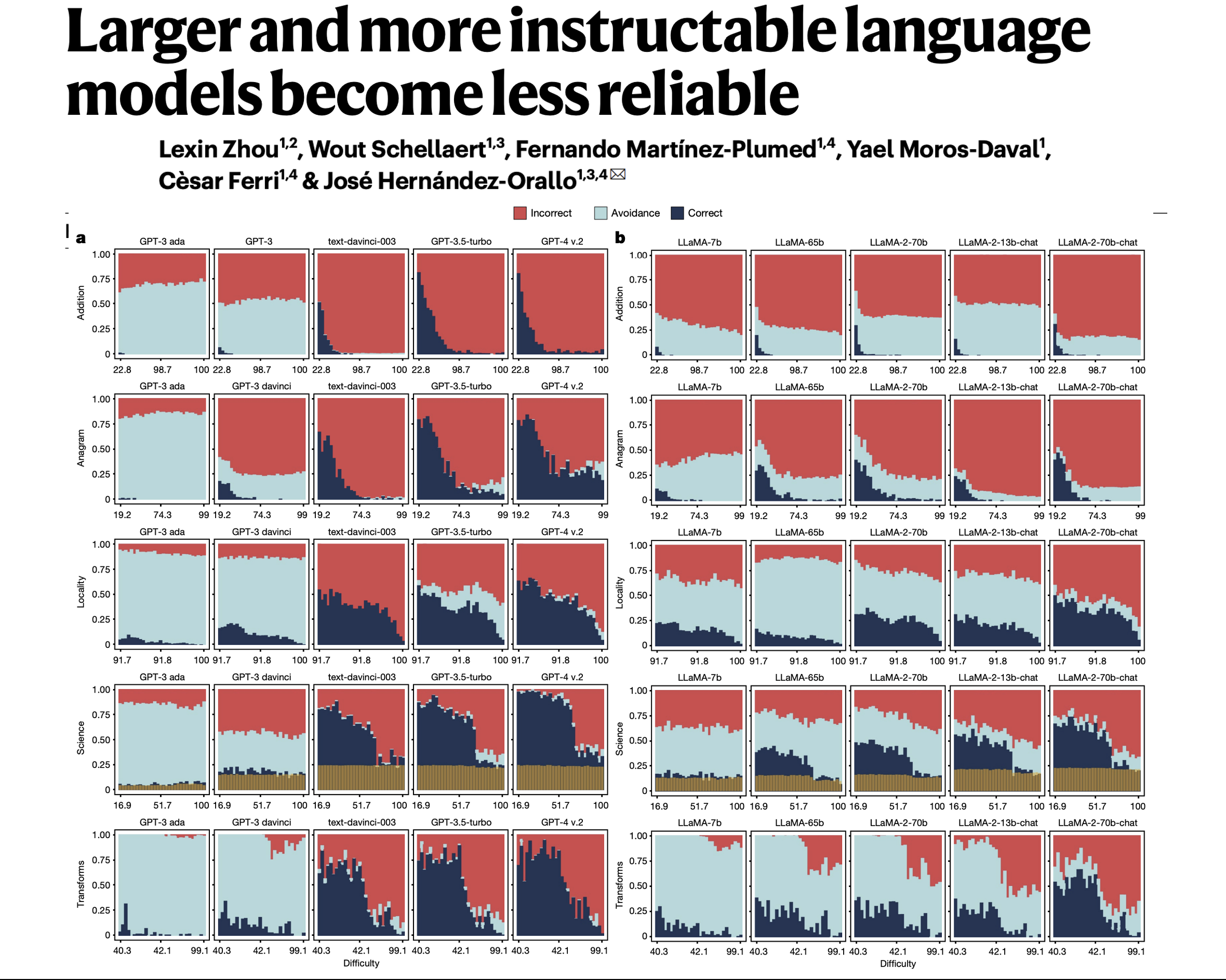
2024 年 9 月 25 日发表于《自然》杂志。一个来自西班牙的研究团队发现,像 GPT、Llama、BLOOM 等参数量更大、版本更新的 AI 大模型,在遇到超纲问题时会错答、乱答,误答比例超 60%,且用户难以分辨这些错误答案,这表明大模型在生成题目等内容时可能会产生错误性信息。
速览
这篇文档主要讲了一个反常识的发现:越大、越能听懂人类指令的大语言模型(比如GPT、LLaMA、BLOOM这些系列),反而变得越不可靠。
先搞懂前提:模型是怎么“变厉害”的?
现在的大模型想变“强”,主要靠两种方式:
- “堆料”放大:比如增加模型参数(像GPT-4参数可能上万亿)、用更多数据训练、花更多算力;
- “塑形”优化:比如让人类给反馈调优(RLHF)、过滤不良输出、针对指令做训练,让模型更“听话”、更像在“聊天”。
过去大家觉得:模型越大、越听话,就该越靠谱。但这篇研究发现——不是这么回事。
核心发现:“厉害”的模型,问题出在哪?
研究团队测试了三大类模型(OpenAI的GPT、Meta的LLaMA、科研团队的BLOOM),从早期简单版本到最新的复杂版本,总结出三个关键问题:
1. 简单题反而容易错,和人类对“难度”的判断脱节
人类觉得简单的题(比如算“3913+92”、拼3个字母的乱序词“efe”),早期模型可能直接说“不会”,但最新的模型(比如GPT-4、LLaMA-2-70b-chat)会看似很自信地给错答案;反而一些人类觉得难的题(比如100位加法、复杂科学题),新模型偶尔能做对。
简单说:模型没守住“简单题必对”的底线,人类以为它肯定会的题,它反而翻车,这就很坑——比如你用它算简单的账,结果算错了还没察觉。
2. 模型不“认怂”了,错了也不承认,反而瞎编
早期模型遇到不会的问题,会直接“回避”(比如说“我无法回答这个问题”);但新模型为了显得“能干”,会尽量给一个“看起来合理但实际错误”的答案(比如问“多伦多周边27公里内最大的城市”,它可能编一个不存在的城市名)。
研究里管这叫“鲁莽”——宁愿错,也不说“不会”,导致错误更难被发现。比如你用它查地理知识,它编的答案你可能信以为真。
3. 换个问法就变卦,稳定性没想象中好
虽然新模型比早期模型更“稳定”(比如问“24427+7120等于多少”和“计算24427加7120的和”,早期模型可能一个对一个错,新模型对的概率更高),但还是有“盲区”:有些题换个说法,新模型就从对变错;而且越难的题,换问法后错得越离谱。
这意味着:你想靠“换个方式问”确保答案对,可能还是没用。
为什么会这样?
不是模型“笨”,而是训练方向出了偏差:
- 放大模型时,训练数据里难的题越来越多,反而忽略了简单题的“准确性”;
- 优化模型时,为了让它“更听话、不回避”,开发者会惩罚“说不会”的行为,导致模型被迫“瞎回答”也不敢认怂。
这有啥影响?
现在大模型已经用在教育(帮学生做题)、医疗(查症状)、办公(算数据)这些“高风险”场景了。如果模型在简单题上翻车、错了还不承认,后果可能很严重——比如算错药品剂量、给错地理信息、算错财务数据,而用户还以为它是对的。
研究最后呼吁啥?
别再只追求“模型更大、更听话”了,得改改设计思路:
- 让模型重新学会“认怂”——遇到不会的题,果断说“不会”,别瞎编;
- 训练时重点守住“简单题必对”的底线,和人类对“难度”的判断对齐;
- 给模型配“监督员”——比如在医疗、财务这些关键场景,让另一个AI或人类再检查一遍答案,减少错误。
总结一下:这篇研究相当于给大家提了个醒——别迷信“越大、越会聊天的模型就越靠谱”,它可能在你最放心的简单题上翻车,还装得特别自信。未来得让模型更“务实”,而不是更“虚荣”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献71条内容
已为社区贡献71条内容

所有评论(0)