字节一面-大模型
这份面经非常典型,涵盖了现代大模型面试的核心考点:项目深挖:考察你的工程和研究能力。微调技术:LoRA是当前PEFT的绝对核心。模型基础:Transformer是一切的基础,必须倒背如流。对齐前沿:DPO是RLHF之后最重要的对齐方法之一,必须掌握。编码能力:常规的算法题考察。祝你面试顺利!
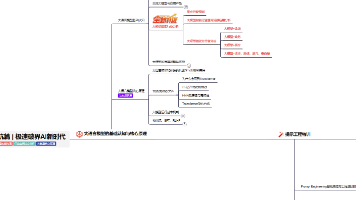
字节一面
📍面试公司:字节
💻面试岗位:大模型
❓面试问题:
1. 拷打实习
2. 简单拷打论文
3. lora的含义以及初始化
4. transformer的结构,encoder和decoder是怎么交互的,二者的mha有什么区别
5. 问dpo有什么优劣
6. dpo具体是怎么学习的
7. 手撕 lc200
字节大模型一面
📍面试公司:抖音
💻面试岗位:大模型算法
❓面试问题:
1. 拷打实习,问了很多很详细的数据和做强化学习的motivation
2. 八股拷打(好久没看基础机器学习了都忘了)
介绍一下优化器的发展
现在大模型的优化器是什么
ln和bn的区别
encoder-only和decoder-only区别以及应用场景
qkv具体是什么
为什么是多头注意力
上下文长度是什么,有什么作用
lora和全参区别
欠拟合和过拟合具体要怎么办
3. 手撕一个复杂度o(1)的插入删除和随机等概率返回(最近怎么遇不到hot100了)
🙌面试感想:
面试官人很好业务也很好玩,可惜了我手撕写了好久好久还磕磕巴巴
好的,这是一份针对您提供的字节大模型一面真题的详细解析和回答。这份回答旨在帮助您理解问题背后的知识点,并能够组织出高质量的面试答案。
真题解析与参考答案
1. & 2. 拷打实习和论文
-
解析:这两项是面试中深入了解你过去项目经验和研究深度的必备环节,无法提供标准答案,但可以给你准备思路。
-
准备建议:
-
实习项目:使用STAR法则(Situation, Task, Action, Result) 来梳理你的项目。
-
背景:项目要解决什么问题?业务目标是什么?
-
你的任务:你具体负责哪一部分?(例如:负责搭建一个基于BERT的文本分类模型并部署上线)
-
行动:你具体做了什么?为什么这么做?(这是考察重点)
-
数据是如何处理和增强的?
-
模型选型?为什么选这个模型?(例如:为什么用RoBERTa而不是BERT?)
-
遇到了什么挑战?(例如:类别不平衡、线上推理速度慢)如何解决的?(例如:采用Focal Loss、模型蒸馏或量化)
-
是否做了A/B测试?结果如何?
-
-
结果:项目的最终成果是什么?(例如:准确率提升了5%,QPS达到100)
-
-
论文:
-
用一两句话清晰概括论文的核心创新点。
-
详细阐述论文的动机:为什么现有方法不好?你的方法为什么能解决?
-
清晰地解释你的方法细节(最好能画图说明)。
-
准备好对比实验的分析:为什么你的方法比基线模型好?消融实验证明了什么?
-
思考一下工作的局限性以及未来的改进方向。
-
-
3. LoRA的含义以及初始化
-
含义:LoRA(Low-Rank Adaptation)是一种参数高效微调(PEFT) 方法。其核心思想是:大语言模型在适配下游任务时,其权重更新(ΔW)其实是一个低秩(Low-Rank)矩阵。
-
因此,它不需要微调整个模型的巨量参数,而是冻结原始权重(W),并注入一个低秩分解的旁路矩阵(A和B)来模拟权重更新(ΔW = B*A)。其中,A是随机高斯初始化,B是零初始化。
-
-
初始化:
-
矩阵A:通常采用随机高斯初始化(Kaiming初始化或Xavier初始化)。这相当于在训练开始时,给模型注入一个随机的、小的噪声。
-
矩阵B:通常采用零初始化。这是非常关键的一步。
-
原因:这样在训练开始时,B*A = 0,因此ΔW = 0。这意味着注入的LoRA模块不会影响原始模型的输出,保证了模型初始性能与预训练模型完全一致,训练过程会非常稳定。然后模型通过梯度下降,逐步学习到有效的A和B。
-
-
4. Transformer的结构,encoder和decoder是怎么交互的,二者的MHA有什么区别
-
Transformer结构:主要由Encoder和Decoder两部分组成。
-
Encoder:负责理解和编码输入序列(如一句话)。它由N个相同的层堆叠而成,每层包含一个自注意力机制(MHA) 和一个前馈神经网络(FFN)。
-
Decoder:负责根据Encoder的编码信息和之前已生成的输出,自回归地生成目标序列(如翻译后的句子)。它也由N个相同的层堆叠而成,每层包含三个子层:掩码自注意力机制(Masked MHA)、交叉注意力机制(Cross MHA) 和前馈神经网络(FFN)。
-
-
Encoder和Decoder的交互:
-
交互发生在Decoder的交叉注意力机制(Cross-Attention) 层。
-
具体过程:
-
Encoder处理完输入序列后,将其最终的输出(一组Key和Value向量)传递给Decoder。
-
在Decoder的每一层中,Cross-Attention模块会接收两个输入:
-
Query(Q):来自Decoder上一层Masked Self-Attention的输出。
-
Key(K)和 Value(V):来自Encoder的输出。
-
-
Cross-Attention会根据当前的Query(即当前要生成的词)去Encoder输出的信息(K, V)中寻找最相关的部分(计算注意力分数),并聚合这些信息来帮助生成下一个词。
-
-
-
Encoder的MHA和Decoder的MHA的区别:
-
Encoder的MHA:是自注意力(Self-Attention)。它的Q, K, V全部来自同一个源(即Encoder的输入或上一层的输出)。目的是让输入序列中的每个词都能充分注意到其他所有词,从而更好地理解上下文。
-
Decoder的MHA:
-
第一层(Masked MHA):也是自注意力,但它是掩码的(Masked)。为了防止在训练时“偷看”到未来的信息,它会将一个位置之后的所有位置都掩码掉(设为负无穷,softmax后为0),确保当前位置只能注意到它之前的位置。
-
第二层(Cross MHA):是交叉注意力(Cross-Attention)。它的Q来自Decoder本身,而K和V来自Encoder的最终输出。目的是让Decoder在生成每一个词时,都能有选择地去关注输入序列中最相关的部分。
-
-
5. 问DPO有什么优劣
-
优势(Advantages):
-
无需奖励模型:DPO最大的优点是绕过了奖励模型(RM)的显式训练阶段。RLHF需要先训练一个Reward Model,再用PPO等强化学习算法微调模型,过程复杂且不稳定。DPO直接将偏好学习问题转化为一个简单的二元分类损失函数,训练更稳定。
-
简化训练流程:只需要一个偏好数据集(即对于同一个提示,有“好回答”和“坏回答”),直接优化策略模型,大大简化了训练 pipeline。
-
性能更好:在许多实验中,DPO展现出了比传统RLHF(PPO)更好的性能,能更有效地拟合人类偏好,同时避免了PPO训练中的“奖励黑客”(Reward Hacking)问题。
-
-
劣势(Disadvantages):
-
缺乏显式奖励信号:由于没有显式的奖励模型,我们无法像RLHF那样得到一个可以量化衡量回答好坏的奖励值,这给模型迭代和评估带来了一定的困难。
-
对偏好数据质量要求高:DPO的效果极度依赖于偏好数据的质量。如果数据中存在噪声或偏见,会直接且显著地影响最终模型的表现。
-
理论上的灵活性:RLHF框架下,奖励模型可以独立更换和改进(例如,从 general reward 换成 safety reward),而DPO将偏好直接编码到模型参数中,这种灵活性较差。
-
6. DPO具体是怎么学习的
DPO的学习过程基于一个关键的理论洞察:对于满足Bradley-Terry模型的偏好,可以通过一个闭式解(closed-form solution)将最优策略模型(π)和奖励函数(r)关联起来:r(x, y) = β * log(π(y|x) / π_ref(y|x))。
基于这个关系,DPO直接优化策略模型π_θ,其损失函数如下:
L_DPO(π_θ; π_ref) = - E_(x, y_w, y_l) ~ D [ log σ( β * log (π_θ(y_w | x) / π_ref(y_w | x)) - β * log (π_θ(y_l | x) / π_ref(y_l | x)) ) ]
-
(x, y_w, y_l):来自偏好数据集,其中对于提示x,
y_w是获胜(优选)回答,y_l是失败(劣选)回答。 -
π_ref:参考模型,通常是SFT后的初始模型,在整个DPO训练过程中被冻结。
-
π_θ:我们要训练的策略模型(初始状态等于π_ref)。
-
β:控制偏离参考模型程度的超参数。β越大,越倾向于拟合偏好数据,但可能过度偏离π_ref导致模型遗忘原有知识。
学习过程:通过最小化上述损失函数,模型实际上是在拉高优选回答y_w相对于参考模型的对数概率,同时压低劣选回答y_l相对于参考模型的对数概率。σ(sigmoid函数)确保我们将偏好概率拟合到0和1之间。整个过程不需要显式地定义或训练奖励模型。
7. 手撕 LC200. 岛屿数量
这是一道经典的DFS/BFS应用题。
题目大意:给你一个由 '1'(陆地)和 '0'(水)组成的二维网格,请你计算网格中岛屿的数量。岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
方法一:深度优先搜索(DFS)
class Solution:
def numIslands(self, grid: List[List[str]]) -> int:
if not grid:
return 0
count = 0
rows, cols = len(grid), len(grid[0])
def dfs(i, j):
# 递归终止条件:越界或遇到水
if i < 0 or j < 0 or i >= rows or j >= cols or grid[i][j] != '1':
return
# 将访问过的陆地标记为‘0’(即沉没这座岛),避免重复访问
grid[i][j] = '0'
# 向四个方向递归搜索
dfs(i+1, j)
dfs(i-1, j)
dfs(i, j+1)
dfs(i, j-1)
for i in range(rows):
for j in range(cols):
# 发现一块新陆地,岛屿数量+1
if grid[i][j] == '1':
count += 1
# 然后通过DFS把属于这座岛的所有相连陆地全部“沉没”
dfs(i, j)
return count方法二:广度优先搜索(BFS)
class Solution:
def numIslands(self, grid: List[List[str]]) -> int:
if not grid:
return 0
count = 0
rows, cols = len(grid), len(grid[0])
for i in range(rows):
for j in range(cols):
if grid[i][j] == '1':
count += 1
grid[i][j] = '0' # 标记为已访问
queue = collections.deque()
queue.append((i, j))
while queue:
x, y = queue.popleft()
for dx, dy in [(1, 0), (-1, 0), (0, 1), (0, -1)]:
nx, ny = x + dx, y + dy
if 0 <= nx < rows and 0 <= ny < cols and grid[nx][ny] == '1':
grid[nx][ny] = '0'
queue.append((nx, ny))
return count面试官期待:
-
能迅速认出这是DFS/BFS问题。
-
能解释思路:遍历网格,遇到一块陆地(‘1’),计数器就加一,然后用DFS/BFS把与它相连的所有陆地都标记为已访问(例如改成‘0’),这样后续遍历就不会重复计数。
-
能流畅地写出代码,注意边界条件。
-
能分析时间复杂度为O(M*N),因为每个点最多被访问一次。
总结与面试建议
这份面经非常典型,涵盖了现代大模型面试的核心考点:
-
项目深挖:考察你的工程和研究能力。
-
微调技术:LoRA是当前PEFT的绝对核心。
-
模型基础:Transformer是一切的基础,必须倒背如流。
-
对齐前沿:DPO是RLHF之后最重要的对齐方法之一,必须掌握。
-
编码能力:常规的算法题考察。
祝你面试顺利!
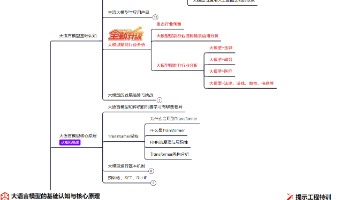
字节大模型一面
📍面试公司:抖音
💻面试岗位:大模型算法
❓面试问题:
1. 拷打实习,问了很多很详细的数据和做强化学习的motivation
2. 八股拷打(好久没看基础机器学习了都忘了)
介绍一下优化器的发展
现在大模型的优化器是什么
ln和bn的区别
encoder-only和decoder-only区别以及应用场景
qkv具体是什么
为什么是多头注意力
上下文长度是什么,有什么作用
lora和全参区别
欠拟合和过拟合具体要怎么办
3. 手撕一个复杂度o(1)的插入删除和随机等概率返回(最近怎么遇不到hot100了)
🙌面试感想:
面试官人很好业务也很好玩,可惜了我手撕写了好久好久还磕磕巴巴
好的,这是对“字节大模型一面”面试问题的解析和参考答案整理。这场面试非常典型,涵盖了项目深挖、基础知识和代码能力,对大模型算法岗的考察很全面。
面试问题解析与参考答案
1. 项目/实习深挖(强化学习方向)
面试官会深入询问实习细节,考察你是否真正理解并主导了工作,而不是简单参与。
-
考察点:
-
项目背景与动机: 为什么要在这个项目里引入强化学习(RL)?相比传统方法(如监督学习)能解决什么核心问题?(例如:优化不可微的目标、与人类偏好对齐等)。
-
细节把握: 对使用的数据(规模、来源、构造方式、清洗过程)、模型(具体架构、RL算法选择如PPO/DPO、奖励模型设计)、评估指标(自动指标如BLEU/ROUGE,人工评估方案)是否了如指掌。
-
思考深度: 遇到了什么挑战?如何解决的?如果重新做一次,会有什么改进?
-
-
建议: 准备项目时,使用STAR法则(Situation, Task, Action, Result)梳理,并确保能清晰地解释每一个技术选择背后的“为什么”。
2. 基础知识(“八股文”)
1. 介绍一下优化器的发展
-
参考答案:
-
SGD: 最基础,但容易陷入局部最优且收敛慢,对学习率敏感。
-
SGD with Momentum: 引入动量概念,加速收敛并减少震荡。它积累了之前梯度的指数加权平均,使更新方向更加稳定。
-
AdaGrad: 为每个参数自适应地调整学习率,适合稀疏数据。但学习率会单调下降至过小,可能导致提前停止学习。
-
RMSProp: 解决了AdaGrad学习率急剧下降的问题,通过引入衰减因子只关注最近一段时间的梯度平方。
-
Adam: 结合了Momentum(一阶矩估计)和RMSProp(二阶矩估计)的优点,并进行了偏差校正。通常是默认的、效果很好的选择。
-
AdamW: 在Adam的基础上,解耦了权重衰减和梯度更新。实验表明,这能带来更好的泛化性能和最终的收敛效果。这是当前训练大模型最主流的优化器。
-
2. 现在大模型的优化器是什么?
-
参考答案: 目前绝大多数大型Transformer模型(如LLaMA, GPT系列)都使用 AdamW 优化器。一些研究也开始尝试使用 Lion 等新优化器,但AdamW仍是业界主流和黄金标准。
3. LN和BN的区别
-
参考答案:
-
Batch Normalization: 对一个Batch内所有样本的同一特征维度进行归一化。依赖Batch Size,小批量时效果差。不适合RNN/Transformer等动态网络和NLP任务。
-
Layer Normalization: 对单个样本的所有特征维度进行归一化。不依赖Batch Size,非常适用于NLP序列数据、RNN和Transformer架构。Transformer中的Add & Norm里的Norm就是LN。
-
核心区别: 归一化的维度不同。BN是“竖着”归一化(跨样本),LN是“横着”归一化(跨特征)。
-
4. Encoder-only和Decoder-only区别以及应用场景
-
参考答案:
-
Encoder-only (e.g., BERT):
-
结构: 仅使用编码器,双向注意力机制,能同时看到整个序列的上下文。
-
应用: 擅长理解任务,如文本分类、情感分析、命名实体识别(NER)、自然语言推理(NLI)。通常通过添加任务特定头进行微调。
-
-
Decoder-only (e.g., GPT, LLaMA):
-
结构: 仅使用解码器,采用掩码自注意力,只能看到当前词之前的上下文(因果建模)。
-
应用: 擅长生成任务,如文本生成、代码生成、对话、续写。通过Next Token Prediction预训练,具有很强的零样本/少样本泛化能力。
-
-
补充: Encoder-Decoder (e.g., T5) 结构用于序列到序列任务,如翻译、摘要。
-
5. QKV具体是什么
-
参考答案: 来自注意力机制公式
Attention(Q, K, V) = softmax(QK^T/√d_k)V。-
Q (Query): 查询向量。代表“当前需要关注什么”,可以理解为当前需要被表征的位置。
-
K (Key): 键向量。代表“我有什么内容”,可以理解为序列中所有位置提供的标识。
-
V (Value): 值向量。代表“我实际的特征信息”,是真正用于加权求和的信息本身。
-
通俗理解: 将Q与所有K进行相似度比较(
QK^T),得到一个注意力权重分布(softmax),然后用这个权重对所有的V进行加权求和,最终得到融合了全局信息的新表征。
-
6. 为什么是多头注意力
-
参考答案: 使用多头注意力(Multiple Head)而不是一个大的单头注意力,主要有两个原因:
-
扩展模型的能力: 允许模型同时关注来自不同表示子空间的信息。不同的头可以学习到不同的模式(例如,一个头关注语法关系,另一个头关注语义关系,再一个头关注长程依赖)。
-
提升计算效率: 将维度拆分成多个头进行并行计算,在总参数量相近的情况下,比单一大头计算更高效。
-
7. 上下文长度是什么,有什么作用
-
参考答案:
-
是什么: 上下文长度(Context Length)是指模型在生成下一个词时,能看到和利用的前面token的最大数量。例如,GPT-4的上下文长度是32k,意味着它最多能处理32000个token的输入。
-
作用:
-
决定信息容量: 直接限制了模型一次性能处理的信息量,直接影响处理长文档、长对话、代码文件等任务的能力。
-
影响性能: 更长的上下文通常能让模型做出更准确、更连贯的响应,因为它拥有更丰富的背景信息。
-
-
补充: 扩展上下文长度是当前大模型研究的重点和难点(如FlashAttention, MQA, GQA等技术都是为了优化长上下文下的计算和内存开销)。
-
8. LoRA和全参微调的区别
-
参考答案:
-
全参微调: 更新预训练模型的所有参数。效果通常最好,但计算成本和内存开销极大,需要存储和优化整个模型的梯度。
-
LoRA: 一种参数高效微调方法。其核心思想是冻结原模型权重,只在原始层(如Attention的QKV矩阵)旁注入可训练的“低秩分解”适配器(Adapter)。训练时只更新这些适配器的参数。
-
区别/优势:
-
极大幅降低显存需求: 只需存储和优化极少的参数(通常<1%),可以在消费级显卡上微调大模型。
-
便于切换任务: 只需切换不同的适配器,基座模型不变,可以快速部署多个微调版本。
-
减轻灾难性遗忘: 由于原始模型大部分参数不动,能更好地保留预训练阶段学到的通用知识。
-
-
9. 欠拟合和过拟合具体要怎么办
-
参考答案:
-
欠拟合: 模型在训练集上表现就差。
-
应对措施: 增加模型复杂度(更多层/参数)、添加更多特征、减少正则化强度(如减小权重衰减系数)、延长训练时间、使用更强大的模型架构。
-
-
过拟合: 模型在训练集上表现好,在测试集上表现差。
-
应对措施: 获取更多训练数据、数据增强、降低模型复杂度、增加正则化(L1/L2权重衰减、Dropout)、早停(Early Stopping)。
-
-
3. 手撕代码
题目: 设计一个数据结构,支持平均时间复杂度为 O(1) 的 插入、删除和 随机返回一个元素操作。假设所有元素是整数且唯一。
-
思路分析:
-
哈希表(
dict)可以实现O(1)的插入和删除,但无法实现O(1)的随机返回(需要先转成列表,不是O(1))。 -
动态数组(
list)可以实现O(1)的插入(摊销时间)和O(1)的随机访问,但删除特定值需要查找,是O(n)。 -
结合两者: 用
列表存储元素,用字典记录每个元素值到其在列表中索引的映射。 -
关键操作:
-
插入: 追加到列表末尾,并在字典中记录
元素:最后一个索引。 -
删除: 通过字典找到要删除元素的索引。将该索引的元素与列表最后一个元素交换。更新字典中最后一个元素对应的索引为新的位置。删除列表最后一个元素,并从字典中删除目标元素的记录。
-
随机返回: 在列表的当前索引范围内(
0到len(list)-1)随机选择一个索引,返回该处的元素。
-
-
-
Python代码实现:
import random class RandomizedSet: def __init__(self): self.list = [] # 存储元素 self.dict = {} # 元素 -> 在list中的索引 def insert(self, val: int) -> bool: if val in self.dict: return False # 插入到列表末尾,记录索引 self.dict[val] = len(self.list) self.list.append(val) return True def remove(self, val: int) -> bool: if val not in self.dict: return False # 找到要删除元素的索引 idx_to_remove = self.dict[val] # 找到列表最后一个元素 last_element = self.list[-1] # 将最后一个元素放到要删除的位置 self.list[idx_to_remove] = last_element # 更新字典中最后一个元素的索引 self.dict[last_element] = idx_to_remove # 删除列表最后一个元素(现在val已经被覆盖了) self.list.pop() # 从字典中删除val的记录 del self.dict[val] return True def getRandom(self) -> int: # 等概率随机返回列表中的一个元素 return random.choice(self.list)
4. 开放性问题(来自评论区)
1. 人生中目前遭遇的最大的挫折
-
考察点: 抗压能力、复盘总结能力、成长型思维。
-
回答建议: 采用STAR法则描述一个有难度但最终克服了的具体事例。重点突出你如何分析问题、采取行动、从中学到了什么,而不是单纯抱怨困难。
2. 为面试刻意做了哪些准备
-
考察点: 你的准备方法、对岗位的重视程度、自我认知。
-
回答建议: 诚实且结构化地回答。例如:“我主要做了三方面准备:1. 项目复盘: 深入梳理了过往项目,确保能讲清楚每个细节和背后的思考。2. 基础知识巩固: 系统复习了机器学习、深度学习和Transformer的核心知识。3. 算法刷题: 在LeetCode上练习了常见的数据结构和算法题,可惜手撕代码还是我的弱项,需要持续加强。” 这个回答既展示了你的努力,也体现了诚实和自我认知。
总结与建议
-
面试评价: 这是一场非常标准和高质量的大模型算法面试。面试官通过项目深挖考察工程和研究能力,通过八股文考察知识扎实程度,通过手撕代码考察编程基本功。
-
给你的建议:
-
深耕项目: 对自己的简历项目了如指掌,每一个数字、每一个选择都要能解释清楚。
-
系统复习: 建立自己的知识体系,特别是Transformer、优化、微调技术等核心概念。
-
保持手感: 坚持刷题,尤其是高频题和这种经典的数据结构设计题。即使没遇到原题,思路和手感也是共通的。
-
准备行为面: 像“最大挫折”这类问题越来越常见,提前准备1-2个故事,会让你在面试中更从容。
-
祝你接下来面试顺利!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 22
22 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)