大模型测盲问题
摘要:测试显示不同AI模型在处理时间序列数据shift操作时的表现差异显著。在测试的8个模型中,仅Qwen3-235B-A22B、腾讯混元Hunyuan-TurboS和gpt-4-1-mini能正确输出结果,通义千问逻辑正确但输出有误,而Grok-3-beta、gemini-2.5-flash、豆包、智谱清言和文心一言4.5Turbo则完全失败。测试使用pd.date_range创建5天时间序列,
本文纯属写来玩,不严谨
难道没有人觉得开启深度思考效率很慢吗,而且很浪费时间
本帖子手机一些平时AI容易给出的错误答案的问题,每次新开对话测试有误差,有时对有时错
import torch
import torch.nn as nn
# 模拟输入:批次2,序列长度4,3分类任务
input = torch.randn(2, 4, 3) # [batch, seq_len, num_classes]
# 模拟目标:每个序列位置的类别索引(0-2)
target = torch.tensor([[0,1,2,0], [1,0,1,2]]) # [batch, seq_len]
ce_loss = nn.CrossEntropyLoss()
loss = ce_loss(input, target)
print(f"输入维度: {input.shape}, 目标维度: {target.shape}")
这段代码输出结果是多少
这个问题是真的牛,问豆包,DeepSeek,都会给出错误答案,不会思考,一本正经输出结果
正确答案:这个代码运行不会输出结果,会报RuntimeError: Expected target size [2, 3], got [2, 4]
不开启深度思考的
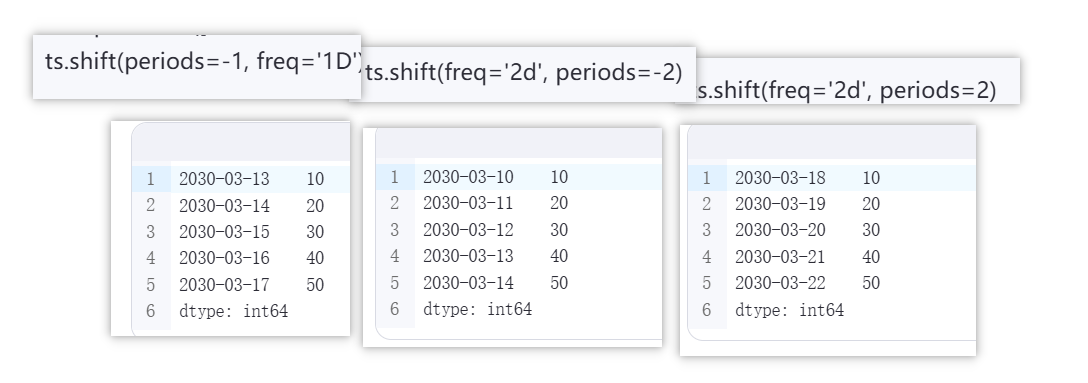
1.ts.shift
# 创建示例时间序列
index = pd.date_range('2030-3-14', periods=5, freq='D')
ts = pd.Series([10, 20, 30, 40, 50], index=index)
ts.shift(periods=-1, freq='1D')ts.shift(freq='2d', periods=-2)
ts.shift(freq='2d', periods=2)
分析上面三个shift代码输出结果
正确答案:
 目前测试了部分模型,每个模型重复新开对话测试多次,感兴趣的可以自己去官网测试,
目前测试了部分模型,每个模型重复新开对话测试多次,感兴趣的可以自己去官网测试,
| 模型名称 | 输出结果 | 网址 |
|---|---|---|
| Qwen3-235B-A22B | 正确 | Qwen Chat |
| 腾讯混元Hunyuan-TurboS | 正确 | 腾讯混元 |
| gpt-4o | 正确 | https://chatgpt.com/ |
| gpt-4.1-mini | 正确 | https://chatgpt.com/ |
| llama-3.1-405b(Meta) | 正确 | |
| 通义千问 | 正确 | 通义 - 你的实用AI助手 |
| Deepseek | 失败 | DeepSeek - 探索未至之境 |
| Grok-3 | 失败 | |
| gemini-2.5-flash-preview-05-20 | 失败 | |
| gemini-2.0-flash | 失败 | |
| 腾讯元宝 | 失败 | 腾讯元宝 - 轻松工作 多点生活 |
| 豆包 | 失败 | 豆包 - 字节跳动旗下 AI 智能助手 |
| 智谱清言 | 失败 | 智谱清言 |
| 文心一言(文心4.5 Turbo) | 失败 | 文心一言 |
2.matplotlib的plt.imshow()的colorizer参数
在imshow中使用colorizer参数,在最新版的Matplotlib3.10.3中,举例子
在最新版3.10.3的Matplotlib中有这个参数,但是对于大模型,除非开启联网搜索,否则就算是深度思考也没有这个知识点,知识库滞后
3.roc曲线
import numpy as np
from sklearn.metrics import roc_curve
import matplotlib.pyplot as plt# 真实标签
y_true = [0, 1, 0, 1, 0, 1]# 模型预测的概率(每个样本对正类的预测概率)
y_score = [0.1, 0.9, 0.3, 0.8, 0.4, 0.7]# 计算 FPR, TPR, 和 thresholds
fpr, tpr, thresholds = roc_curve(y_true, y_score)# 绘制 ROC 曲线
# 输出 FPR, TPR, thresholds
print("False Positive Rate (FPR):", fpr)
print("True Positive Rate (TPR):", tpr)
print("Thresholds:", thresholds)你解释上面代码运行 FPR, TPR, thresholds后三个数组长度是多少,
正确答案,三个数组长度都是4,然后每一个模型答出这个答案,大部分为7,错误
4.
# torch_setprecison torch.set_printoptions(precision=8, suppress=True) 取消科学计数,8位小数
豆包,DeepSeek开启深度思考都错了,一本正经胡说八道,说这个代码正确
Qwen深度思考下能看出,suppress参数错误,这是numpy的参数,不是pytorch的,应该使用sci_mode指定科学计数法是否开启
就算开启深度思考也没用
1.对 torch.optim.SGD函数的differentiable参数举例代码
大模型举例的代码必定报错
2.当池化时使用了 ceil_mode=True 参数时,PyTorch 是否可以自动推断原始输入形状 ?
正确答案是不会保错,因为反推池化时形状是由公式决定的,
形状:
- 输入:(N,C,Hin,Win) 或 (C,Hin,Win)。
- 输出:(N,C,Hout,Wout) 或 (C,Hout,Wout),其中
但是大模型给出的答案都是认为会报错,必须指定参数output_size才行
3.python语法问题
代码代码有错误,我问了DeepSeek,豆包,qwen,只有qwen第一次给出正确错误解答,
import numpy as np
# 创建一个3x5的数组
arr = np.array([[1, 2, 3, 4, 5],
[6, 7, 8, 9, 10],
[11, 12, 13, 14, 15]])
print("原始数组:")
print(arr)
print(f"数组形状: {arr.shape}")
# 定义一个需要额外参数的一维处理函数
def custom_range_1d(vector, min_val, max_val):
"""将一维向量缩放到指定范围[min_val, max_val]"""
v_min, v_max = np.min(vector), np.max(vector)
# 避免除以零
if v_max == v_min:
return np.full_like(vector, (min_val + max_val) / 2)
return min_val + (vector - v_min) * (max_val - min_val) / (v_max - v_min)
print("\n*args参数示例:")
print("将每行数据缩放到不同范围")
# 对第一行缩放到[0, 1]范围
print("\n1. 对第一行缩放到[0, 1]范围:")
row0_result = custom_range_1d(arr[0], 0, 1)
print(f"原始第一行: {arr[0]}")
print(f"缩放到[0,1]: {row0_result}")
# 使用apply_along_axis传递额外参数
print("\n2. 使用apply_along_axis对所有行缩放到[0, 100]范围:")
result = np.apply_along_axis(custom_range_1d, axis=1, arr=arr, 0, 100)
print("结果数组:")
print(result)
print(f"结果形状: {result.shape}")
这一行
result = np.apply_along_axis(custom_range_1d, axis=1, arr=arr, 0, 100)改正为
result = np.apply_along_axis(custom_range_1d, 1, arr, 0, 100)
# 参数顺序:函数名, axis, arr, *args答案是:
所有位置参数必须放在关键字参数之前。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)