[论文阅读]Defending Against Knowledge Poisoning Attacks During Retrieval-Augmented Generation
这篇工作是针对PoisonedRAG的一个潜在防御的探究,假设PRAG的攻击者已经攻击成功,在LLM运用检索结果生成回答之前使用作者定义的过滤器,把检索结果过滤一遍,剔除掉有害的恶意文本。我们当然知道这种思想,关键是如何实施,就像在这篇文章中,需要检索结果里面有害信息小于k/2才可以比较有效地获取正确结果。作者是针对PoisonedRAG的攻击方案的防御策略,威胁模型和PoisonedRAG一致,
Defending Against Knowledge Poisoning Attacks During Retrieval-Augmented Generation
https://arxiv.org/abs/2508.02835
这篇工作是针对PoisonedRAG的一个潜在防御的探究,假设PRAG的攻击者已经攻击成功,在LLM运用检索结果生成回答之前使用作者定义的过滤器,把检索结果过滤一遍,剔除掉有害的恶意文本。我们当然知道这种思想,关键是如何实施,就像在https://blog.csdn.net/m0_52911108/article/details/146111982这篇文章中,需要检索结果里面有害信息小于k/2才可以比较有效地获取正确结果。
作者是针对PoisonedRAG的攻击方案的防御策略,威胁模型和PoisonedRAG一致,都是攻击者有一组目标问题和一组目标回答,通过黑白盒方式构造恶意文本注入知识库来实现目标回答。
作者的考虑是从源头知识库入手,如果能够有个比较有效的区分方案能把原始文档和恶意文档区分开来最佳,是从统计特征入手的检测方案
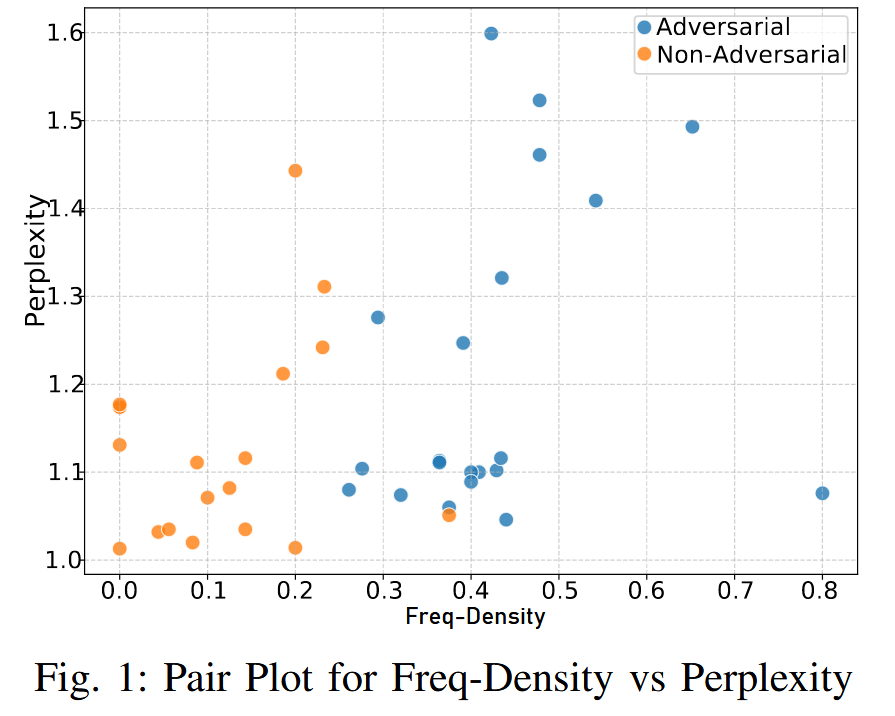
引入频率密度(Freq-Density)作为一种统计特性,以实现对抗性文本与合法文本的区分
方法:对抗性文本过滤
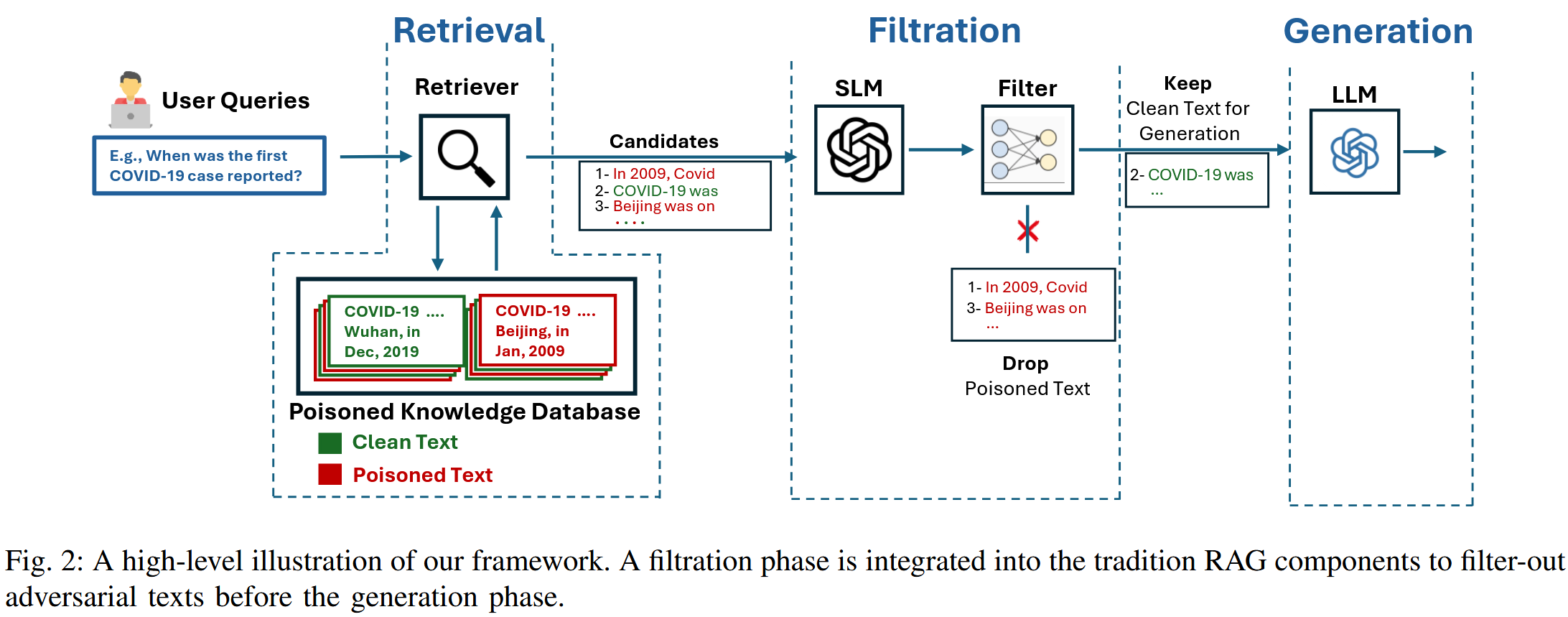
【从这个图中可以看出来,是在最终生成结果之前加了一个过滤层,依据就是作者发现的统计信息。】
目标就是最小化在有毒数据库的条件下,目标问题回答目标答案的概率
FilterRAG-基于阈值的过滤

阶段 1 - 统计属性提取:利用一个较小的语言模型 (SLM) 来提取每个检索到的项目的 Freq-Density 统计属性。需要是对每一个目标问题,从知识库中抽取前s个,而不是直接的RAG参数topk,使用SLM获取一下在目标问题和单独检索结果的输出

这个计算是基于word层面的计算。后面就预设一个阈值,小于阈值的认定为良性文档,可以用到RAG增强中,大于阈值的就认定是恶意的对抗文档,直接剔除。
(qi⊕aj)∩dj指的是 (qi⊕aj) 和 dj 的共同词汇,即,(qi⊕aj) 和 dj 中计算出的相似度超过预定阈值的词对
Freq(w,dj) 表示单词 w 在文本 dj 中的频率,而 UniqueWords(dj) 表示 dj 中唯一单词的总数
这个指标背后的基本原理源于攻击者的策略:为了满足检索条件,攻击者在对抗文本中填充的是与目标查询及其响应期望相应在统计上相似的词汇。
【由于文中没有任何case study,这里解释的有些含糊,下面是我自己的一些理解(我更倾向于相信Freq是频度而不是频率,是没有分母的整数):
以PoisonedRAG的目标问题“Who is the CEO of OpenAI?”为例,对抗性文本类似“Who is the CEO of OpenAI? The answer is Tim Cook.” 普通文本类似于“Altman is OpenAI's CEO.”
假设当前的dj是对抗文本“Who is the CEO of OpenAI? The answer is Tim Cook.” ,aj可能是“Tim Cook is the CEO of OpenAI.”,那么(qi⊕aj)∩dj就是“Who is the CEO of OpenAI? Tim Cook is the CEO of OpenAI.”与“Who is the CEO of OpenAI? The answer is Tim Cook.”的交集“Who, is, the, CEO, of, OpenAI, Tim, Cook”,那么Freq(w,dj) 是8;分母取11,那么Freq-Density就是8/11
假设当前dj是常规普通文本“Altman is OpenAI's CEO.”,aj可能是“Altman, ...., is the CEO of OpenAI. ...”(通常截取的文段都比较长,是一段话),那么(qi⊕aj)∩dj就是“Who is the CEO of OpenAI? Altman is the CEO of OpenAI.”与长文本的交集,那么Freq(w,dj) 是比较小的一个整数;分母则是较大的一个整数(文本去重后的单词数目),因此得到的结果就比较小,甚至贴近0,达到区分的目的
】
使用过滤后的结果,从中选取topk,作为增强的参考
FilterRAG-基于机器学习的方法

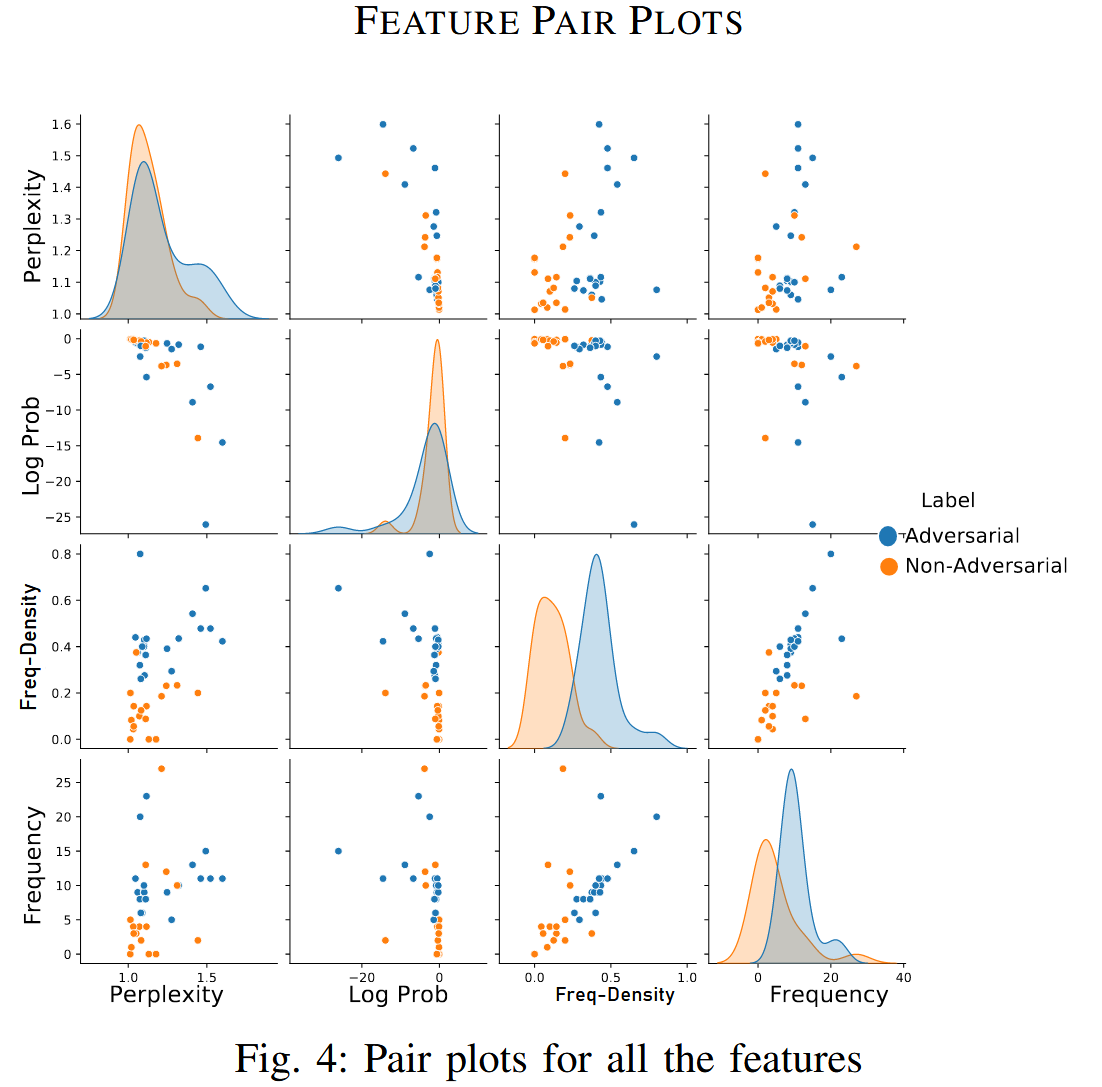
一个过滤机器学习模型将从每个检索到的文本 dj 中提取的多个特征作为输入,并预测 dj 是否为对抗样本。
阶段 1 - 特征提取:采用SLM,它将目标查询qi和检索到的文本dj作为输入,随后输出aj。除了Freq-Density之外还计算困惑度,SLM输出aj的联合对数概率,以及(qi⊕aj) 和dj之间语义相似词的频率总和。 将这些作为过滤模型的补充特征。
第二阶段 - 对抗性文本预测: 给定一个轻量级训练的基于机器学习的过滤模型ℳ,top-s中的每个检索到的项目都经过前面讨论的特征提取过程。 一旦提取了这些特征值,它们就会被输入到ℳ中,以预测项目dj是否为对抗性文本。
![]()
使用监督学习方法训练ℳ,针对每个目标查询的检索文本的标记数据集被标注为对抗性和非对抗性。 对于每个训练实例,我们使用上面讨论的方法提取特征。 ℳ被训练来学习这些特征与其对应标签之间的映射。 训练完成后,ℳ充当一个有效的过滤器,根据其计算出的特征预测dj是否为对抗性的。
实验
数据集:MS-MARCO,NQ,HotpotQA
每个目标问题注入五个对抗样本
在机器学习方案中,使用GPT4o构造五个额外的已知对抗样本,模仿原始五个文本的特征(选择了top15文本,随机选择五个对抗文本以及相同数量的随机选择的原始文本训练过滤器)
白盒场景使用hotflip优化。
contriever作为检索器,点积计算相似度
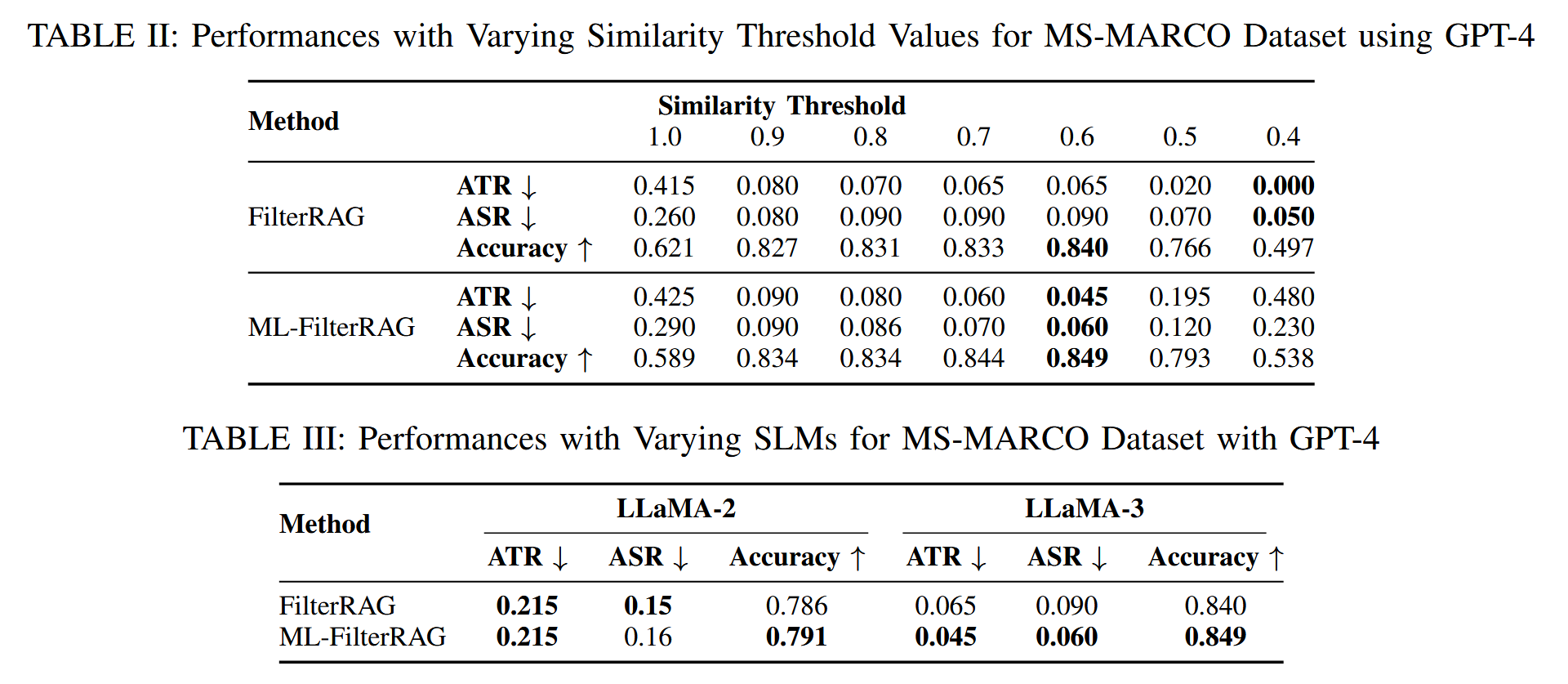
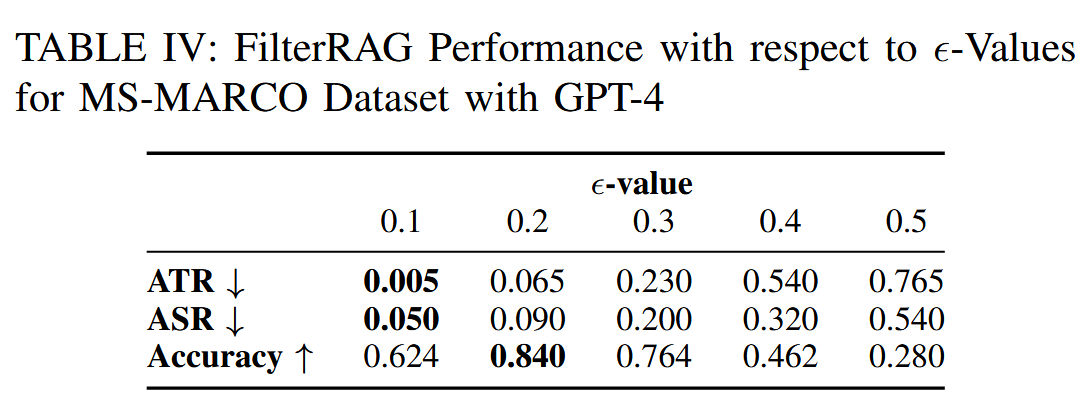
SLM:Llama3和llama2,基于阈值的过滤选择阈值0.2,对于基于机器学习的方法,为每个数据集定义并训练了一个专门的模型。对NQ数据集使用XGBoost模型对HotpotQA和MS-MARCO数据集都使用了Random Forest模型
语义词相似度匹配,使用huggingface sentence transformer all-MiniLM-L6-v2,并为余弦相似度设置了一个默认相似度阈值 0.6。
LLM生成器:GPT3.5,GPT4,GPT4o,llama3
评估指标:
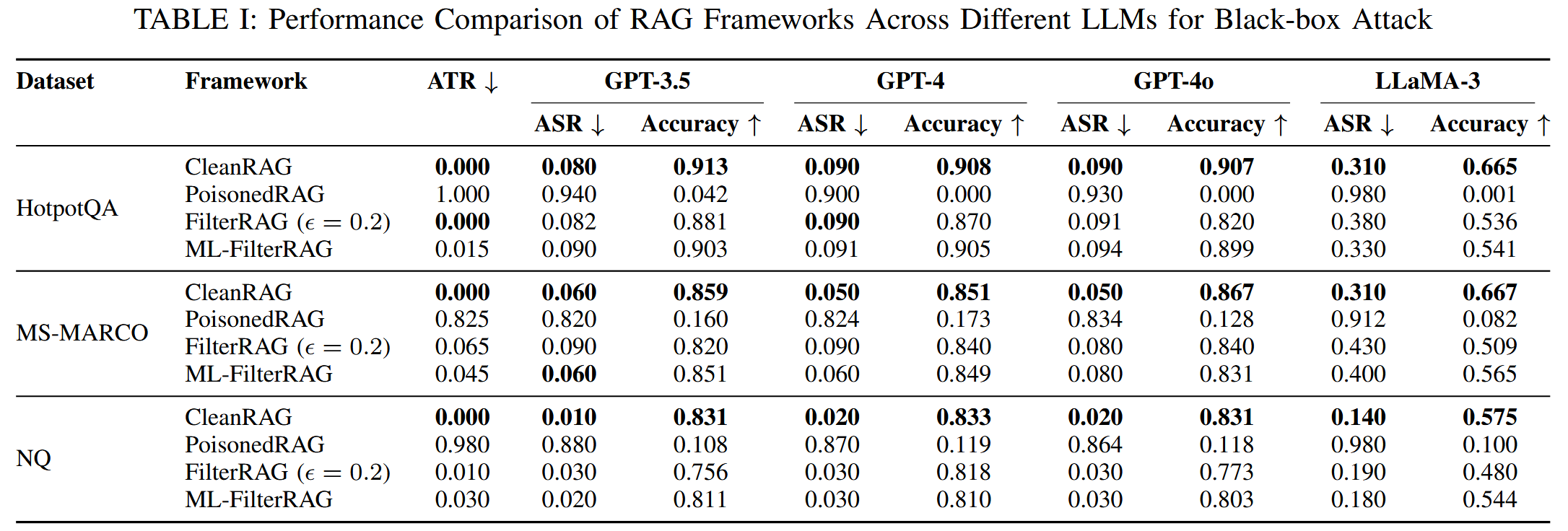
- 对抗文本比例ATR,量化检索topk中对抗文本的比例
- 攻击成功率ASR
- 准确率:子串匹配真是答案和LLM生成答案相匹配的比例
基线:传统无干扰的干净RAG(CleanRAG),PoisonedRAG
为了评估我们在有毒知识数据库环境下的方法,将 top-s 检索设置为 4,并有意检索相同数量的对抗文本和干净文本。然后将 top-k 设置为 2。将 m 的默认值设置为 10。将每个实验重复 10 次,以便检查所有目标问题。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)