YOLOv5实战:破解滑块验证码
本文详细介绍使用YOLOv5训练深度学习模型,精准识别滑块验证码位置,并结合Selenium实现自动拖动破解。包含环境配置、数据标注、模型训练、代码实战及常见问题解决,适合Python和AI初学者实战入门。
·
基于深度学习的滑块验证码识别技术研究
免责声明:本文内容仅用于学习和研究目的,旨在分享计算机视觉和深度学习技术的应用。请勿将本文所介绍的技术用于任何非法或未经授权的活动。对于任何滥用本文技术的行为,作者不承担任何责任。
引言
滑块验证码是现代网络应用中常见的安全验证机制,它通过要求用户完成滑动拼图来区分人类用户和自动化程序。本文探讨如何使用深度学习技术,特别是YOLOv5目标检测算法,来识别滑块验证码中的缺口位置,并分享一套完整的实现方案。
深度学习训练模型
目录结构
--yolov5-master
--data
--VOC2028
--Annotations:标注好的xml文件
--ImageSets:训练集
--Main
--test.txt
--train.txt
--trainval.txt
--val.txt
--说明.txt
--JPEGImages:未标注的png图片
--Labels:图片进行归一化之后的标签文件
--Safety_Helmet_Train_dataset
--score
--images:区分训练集、测试集、验证集的图片文件
--labels:区分训练集、测试集、验证集的标签文件
--custom_data.yaml:小型配置文件
--runs
--train
--exp3等
--weights:训练完的模型
--best.pt:效果最好的模型
--last.pt:最后一轮训练完的模型
--weights:yolov5初始模型(yolov5s.pt)
--滑块测试.py:拖动滑块测试
--运行命令.txt:运行train.py的命令
解释:
运行NO1.py:生成test.txt、train.txt、trainval.txt、val.txt
运行NO2.py:生成images、labels
运行train.py:生成exp3等
模型训练步骤
- 下载yolov5模型
- 安装基本环境
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
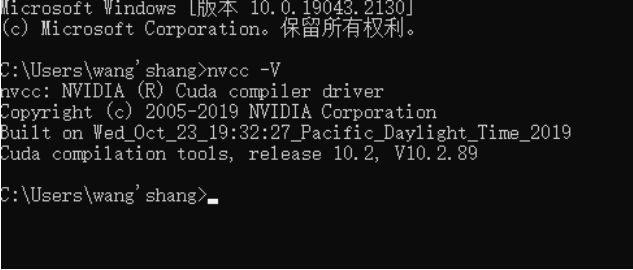
- 安装CUDA:GPU编程的并行计算平台CUDA Toolkit 10.2 Download | NVIDIA Developer
- 安装cuDNN Archive:cuDNN Archive | NVIDIA Developer
 下载完之后解压 将cudnn里面所有的东西都复制到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2里面
下载完之后解压 将cudnn里面所有的东西都复制到 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2里面 - 上面2个东西安装好之后,可以检查一下
- torch 安装 下载网址: download.pytorch.org/whl/torch_stable.html 说明: torch-2.0.0%2Bcu118-cp311-cp311-win_amd64.whl
就是给CUDA11.8,Python 3.11,Windows平台准备的torch-2.0.0 安装:
a. 下载好三个文件后,你就可以安装它了。使用pip安装这些文件,首先你要把它们放在一个文件夹里面。 Linux
cd path_to_torch/
pip install ./torch*
Windwos
cd path_to_torch\
pip install .\torch*
b.
pip install torch==1.9.1+cu102 torchvision==0.11.2+cu102 torchaudio==0.10.1 -f https://download.pytorch.org/whl/torch_stable.html
- 测试
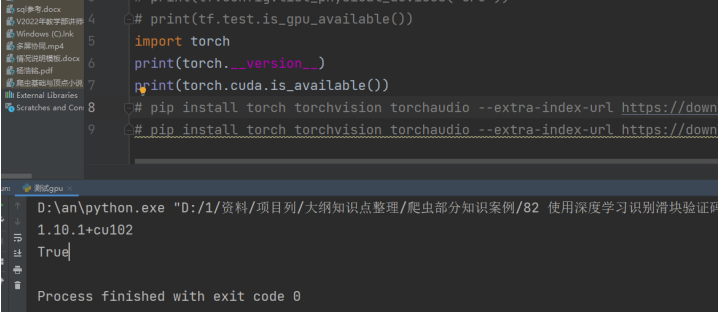
- 安装标注软件
pip install labelImg
python要求3.7
- 运行标注软件 C:\Users\l1853\anaconda3\envs\python37\Scripts
python labelImg.exe
- 标注完毕运行NO1,NO2NO2需要修改一下标签名和图片格式
- 在data下创建custom_data.yaml配置文件
- 设置训练参数:train.py
# 指定训练集的配置文件
parser.add_argument('--data', type=str, default='data/custom_data.yaml', help='(optional) dataset.yaml path')
# 指定训练集的训练模型:预训练模型
# parser.add_argument('--weights', type=str, default='yolov5s.pt', help='initial weights path')
parser.add_argument('--weights', type=str, default='runs/train/exp34/weights/best.pt', help='initial weights path')
# parser.add_argument('--weights', type=str, default=ROOT / 'runs/train/exp12/weights/best.pt', help='initial weights path')
# 指定训练轮数
parser.add_argument('--epochs', type=int, default=100, help='total training epochs')
# 指定一次训练多少张图片,一般看显存,一张图大概占0.2G
parser.add_argument('--batch-size', type=int, default=5, help='total batch size for all GPUs, -1 for autobatch')
- 运行命令开始训练
python train.py --batch-size 5 --epochs 50 --data ./data/custom_data.yaml --weights ./weights/yolov5s.pt
-batch 16 一次喂多少数据,我这内存就能给16,所以可以不传按默认16
(如果内存比较小的,建议改为8,或者4)
(但是也需要根据实际情况,看自身内存的)
--epochs 50 代表迭代五十次,可自行修改
--data ./data/custom_data.yaml 代表数据集配置文件
--weights 代表预训练模型
- 训练结果
- 训练结束模型:runs/train/exp5
- 测试图片:data/images
- 测试结果:runs/detect/exp5
- 滑块测试.py
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
"""
Run YOLOv5 detection inference on images, videos, directories, globs, YouTube, webcam, streams, etc.
Usage - sources:
$ python detect.py --weights yolov5s.pt --source 0 # webcam
img.jpg # image
vid.mp4 # video
path/ # directory
'path/*.jpg' # glob
'https://youtu.be/Zgi9g1ksQHc' # YouTube
'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream
Usage - formats:
$ python detect.py --weights yolov5s.pt # PyTorch
yolov5s.torchscript # TorchScript
yolov5s.onnx # ONNX Runtime or OpenCV DNN with --dnn
yolov5s.xml # OpenVINO
yolov5s.engine # TensorRT
yolov5s.mlmodel # CoreML (macOS-only)
yolov5s_saved_model # TensorFlow SavedModel
yolov5s.pb # TensorFlow GraphDef
yolov5s.tflite # TensorFlow Lite
yolov5s_edgetpu.tflite # TensorFlow Edge TPU
yolov5s_paddle_model # PaddlePaddle
"""
# from __future__ import division
import argparse
import os
import platform
import sys
from pathlib import Path
import torch
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver import ActionChains
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
import time
from models import *
# from utils.utils import *
# from utils.datasets import *
import random
from os.path import dirname, join
import os
import sys
import time
import datetime
import argparse
from PIL import Image
import torch
from torch.utils.data import DataLoader
from torchvision import datasets
from torch.autograd import Variable
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from matplotlib.ticker import NullLocator
FILE = Path(__file__).resolve()
ROOT = FILE.parents[0] # YOLOv5 root directory
if str(ROOT) not in sys.path:
sys.path.append(str(ROOT)) # add ROOT to PATH
ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
from models.common import DetectMultiBackend
from utils.dataloaders import IMG_FORMATS, VID_FORMATS, LoadImages, LoadScreenshots, LoadStreams
from utils.general import (LOGGER, Profile, check_file, check_img_size, check_imshow, check_requirements, colorstr, cv2,
increment_path, non_max_suppression, print_args, scale_boxes, strip_optimizer, xyxy2xywh)
from utils.plots import Annotator, colors, save_one_box
from utils.torch_utils import select_device, smart_inference_mode
@smart_inference_mode()
def run(
weights=ROOT / 'yolov5s.pt', # model path or triton URL
source=ROOT / 'data/images', # file/dir/URL/glob/screen/0(webcam)
data=ROOT / 'data/coco128.yaml', # dataset.yaml path
imgsz=(640, 640), # inference size (height, width)
conf_thres=0.25, # confidence threshold
iou_thres=0.45, # NMS IOU threshold
max_det=1000, # maximum detections per image
device='', # cuda device, i.e. 0 or 0,1,2,3 or cpu
view_img=False, # show results
save_txt=False, # save results to *.txt
save_conf=False, # save confidences in --save-txt labels
save_crop=False, # save cropped prediction boxes
nosave=False, # do not save images/videos
classes=None, # filter by class: --class 0, or --class 0 2 3
agnostic_nms=False, # class-agnostic NMS
augment=False, # augmented inference
visualize=False, # visualize features
update=False, # update all models
project=ROOT / 'runs/detect', # save results to project/name
name='exp', # save results to project/name
exist_ok=False, # existing project/name ok, do not increment
line_thickness=3, # bounding box thickness (pixels)
hide_labels=False, # hide labels
hide_conf=False, # hide confidences
half=False, # use FP16 half-precision inference
dnn=False, # use OpenCV DNN for ONNX inference
vid_stride=1, # video frame-rate stride
):
source = str(source)
save_img = not nosave and not source.endswith('.txt') # save inference images
is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))
webcam = source.isnumeric() or source.endswith('.txt') or (is_url and not is_file)
screenshot = source.lower().startswith('screen')
if is_url and is_file:
source = check_file(source) # download
# Directories
save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
(save_dir / 'labels' if save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Load model
device = select_device(device)
model = DetectMultiBackend(weights, device=device, dnn=dnn, data=data, fp16=half)
stride, names, pt = model.stride, model.names, model.pt
imgsz = check_img_size(imgsz, s=stride) # check image size
# Dataloader
bs = 1 # batch_size
if webcam:
view_img = check_imshow()
dataset = LoadStreams(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride)
bs = len(dataset)
elif screenshot:
dataset = LoadScreenshots(source, img_size=imgsz, stride=stride, auto=pt)
else:
dataset = LoadImages(source, img_size=imgsz, stride=stride, auto=pt, vid_stride=vid_stride)
vid_path, vid_writer = [None] * bs, [None] * bs
# Run inference
model.warmup(imgsz=(1 if pt or model.triton else bs, 3, *imgsz)) # warmup
seen, windows, dt = 0, [], (Profile(), Profile(), Profile())
for path, im, im0s, vid_cap, s in dataset:
with dt[0]:
im = torch.from_numpy(im).to(model.device)
im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
im /= 255 # 0 - 255 to 0.0 - 1.0
if len(im.shape) == 3:
im = im[None] # expand for batch dim
# Inference
with dt[1]:
visualize = increment_path(save_dir / Path(path).stem, mkdir=True) if visualize else False
pred = model(im, augment=augment, visualize=visualize)
# NMS
with dt[2]:
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
# Second-stage classifier (optional)
# pred = utils.general.apply_classifier(pred, classifier_model, im, im0s)
# Process predictions
for i, det in enumerate(pred): # per image
seen += 1
if webcam: # batch_size >= 1
p, im0, frame = path[i], im0s[i].copy(), dataset.count
s += f'{i}: '
else:
p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # im.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt
s += '%gx%g ' % im.shape[2:] # print string
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]] # normalization gain whwh
imc = im0.copy() if save_crop else im0 # for save_crop
annotator = Annotator(im0, line_width=line_thickness, example=str(names))
if len(det):
# Rescale boxes from img_size to im0 size
det[:, :4] = scale_boxes(im.shape[2:], det[:, :4], im0.shape).round()
# Print results
for c in det[:, 5].unique():
n = (det[:, 5] == c).sum() # detections per class
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, " # add to string
# Write results
for *xyxy, conf, cls in reversed(det):
# 前2个貌似是左上角那个点的x,y,后面2个是宽和高
global distance
distance = int(xyxy[0].item()) - 3
print(distance)
# print(66666666666666666666,int(xyxy[0].item()),xyxy,int(xyxy[0].item())+int(xyxy[2].item())/2)
#
#
# if save_txt: # Write to file
# xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist() # normalized xywh
# line = (cls, *xywh, conf) if save_conf else (cls, *xywh) # label format
# with open(f'{txt_path}.txt', 'a') as f:
# f.write(('%g ' * len(line)).rstrip() % line + '\n')
#
# if save_img or save_crop or view_img: # Add bbox to image
# c = int(cls) # integer class
# label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
# annotator.box_label(xyxy, label, color=colors(c, True))
# if save_crop:
# save_one_box(xyxy, imc, file=save_dir / 'crops' / names[c] / f'{p.stem}.jpg', BGR=True)
#
# # Stream results
# im0 = annotator.result()
# if view_img:
# if platform.system() == 'Linux' and p not in windows:
# windows.append(p)
# cv2.namedWindow(str(p), cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO) # allow window resize (Linux)
# cv2.resizeWindow(str(p), im0.shape[1], im0.shape[0])
# cv2.imshow(str(p), im0)
# cv2.waitKey(1) # 1 millisecond
#
# # Save results (image with detections)
# if save_img:
# if dataset.mode == 'image':
# cv2.imwrite(save_path, im0)
# else: # 'video' or 'stream'
# if vid_path[i] != save_path: # new video
# vid_path[i] = save_path
# if isinstance(vid_writer[i], cv2.VideoWriter):
# vid_writer[i].release() # release previous video writer
# if vid_cap: # video
# fps = vid_cap.get(cv2.CAP_PROP_FPS)
# w = int(vid_cap.get(cv2.CAP_PROP_FRAME_WIDTH))
# h = int(vid_cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
# else: # stream
# fps, w, h = 30, im0.shape[1], im0.shape[0]
# save_path = str(Path(save_path).with_suffix('.mp4')) # force *.mp4 suffix on results videos
# vid_writer[i] = cv2.VideoWriter(save_path, cv2.VideoWriter_fourcc(*'mp4v'), fps, (w, h))
# vid_writer[i].write(im0)
#
# # Print time (inference-only)
# LOGGER.info(f"{s}{'' if len(det) else '(no detections), '}{dt[1].dt * 1E3:.1f}ms")
#
# # Print results
# t = tuple(x.t / seen * 1E3 for x in dt) # speeds per image
# LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms NMS per image at shape {(1, 3, *imgsz)}' % t)
# if save_txt or save_img:
# s = f"\n{len(list(save_dir.glob('labels/*.txt')))} labels saved to {save_dir / 'labels'}" if save_txt else ''
# LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}{s}")
# if update:
# strip_optimizer(weights[0]) # update model (to fix SourceChangeWarning)
def parse_opt():
parser = argparse.ArgumentParser()
# 训练好的深度学习模型
# parser.add_argument('--weights', nargs='+', type=str, default=ROOT / 'yolov5s.pt', help='model path or triton URL')
parser.add_argument('--weights', nargs='+', type=str, default='runs/train/exp57/weights/best.pt',
help='model path or triton URL')
# parser.add_argument('--source', type=str, default=ROOT / 'data/images', help='file/dir/URL/glob/screen/0(webcam)')
parser.add_argument('--source', type=str, default='data/images', help='file/dir/URL/glob/screen/0(webcam)')
# parser.add_argument('--data', type=str, default=ROOT / 'data/coco128.yaml', help='(optional) dataset.yaml path')
parser.add_argument('--data', type=str, default='data/custom_data.yaml', help='(optional) dataset.yaml path')
# parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640], help='inference size h,w')
parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[416], help='inference size h,w')
parser.add_argument('--conf-thres', type=float, default=0.25, help='confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='NMS IoU threshold')
parser.add_argument('--max-det', type=int, default=1000, help='maximum detections per image')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--view-img', action='store_true', help='show results')
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt')
parser.add_argument('--save-conf', action='store_true', help='save confidences in --save-txt labels')
parser.add_argument('--save-crop', action='store_true', help='save cropped prediction boxes')
parser.add_argument('--nosave', action='store_true', help='do not save images/videos')
parser.add_argument('--classes', nargs='+', type=int, help='filter by class: --classes 0, or --classes 0 2 3')
parser.add_argument('--agnostic-nms', action='store_true', help='class-agnostic NMS')
parser.add_argument('--augment', action='store_true', help='augmented inference')
parser.add_argument('--visualize', action='store_true', help='visualize features')
parser.add_argument('--update', action='store_true', help='update all models')
parser.add_argument('--project', default=ROOT / 'runs/detect', help='save results to project/name')
parser.add_argument('--name', default='exp', help='save results to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--line-thickness', default=3, type=int, help='bounding box thickness (pixels)')
parser.add_argument('--hide-labels', default=False, action='store_true', help='hide labels')
parser.add_argument('--hide-conf', default=False, action='store_true', help='hide confidences')
parser.add_argument('--half', action='store_true', help='use FP16 half-precision inference')
parser.add_argument('--dnn', action='store_true', help='use OpenCV DNN for ONNX inference')
parser.add_argument('--vid-stride', type=int, default=1, help='video frame-rate stride')
opt = parser.parse_args()
opt.imgsz *= 2 if len(opt.imgsz) == 1 else 1 # expand
print_args(vars(opt))
return opt
def main(opt):
check_requirements(exclude=('tensorboard', 'thop'))
return run(**vars(opt))
def simulateDragX(driver, source, targetOffsetX):
"""
模仿人的拖拽动作:快速沿着X轴拖动(存在误差),再暂停,然后修正误差
防止被检测为机器人,出现“图片被怪物吃掉了”等验证失败的情况
:param source:要拖拽的html元素
:param targetOffsetX: 拖拽目标x轴距离
:return: None
"""
action_chains = webdriver.ActionChains(driver)
# 点击,准备拖拽
action_chains.click_and_hold(source)
# 拖动次数,二到三次
dragCount = random.randint(2, 3)
if dragCount == 2:
# 总误差值
# sumOffsetx = random.randint(-15, 15)
sumOffsetx = 0
action_chains.move_by_offset(targetOffsetX + sumOffsetx, 0)
# 暂停一会
action_chains.pause(0.8)
# 修正误差,防止被检测为机器人,出现图片被怪物吃掉了等验证失败的情况
action_chains.move_by_offset(-sumOffsetx, 0)
elif dragCount == 3:
# 总误差值
# sumOffsetx = random.randint(-15, 15)
sumOffsetx = 0
action_chains.move_by_offset(targetOffsetX + sumOffsetx, 0)
# 暂停一会
action_chains.pause(0.6)
# 已修正误差的和
fixedOffsetX = 0
# 第一次修正误差
if sumOffsetx < 0:
offsetx = random.randint(sumOffsetx, 0)
else:
offsetx = random.randint(0, sumOffsetx)
fixedOffsetX = fixedOffsetX + offsetx
action_chains.move_by_offset(-offsetx, 0)
action_chains.pause(0.6)
# 最后一次修正误差
action_chains.move_by_offset(-sumOffsetx + fixedOffsetX, 0)
action_chains.pause(0.8)
else:
raise Exception("莫不是系统出现了问题?!")
action_chains.release().perform()
class SeleniumLogin():
def __init__(self, timeout=20):
self.timeout = timeout
# self.browser = webdriver.Chrome('D:\\an\envs\python3\Lib\site-packages\\chromedriver.exe')
self.browser = webdriver.Chrome('C:\\Users\\l1853\\anaconda3\\Scripts\\chromedriver.exe')
self.browser.maximize_window()
self.wait = WebDriverWait(self.browser, self.timeout)
def move_to_gap(self, slider, tracks):
"""
拖动滑块
:param slider: 滑块
:param tracks: 轨迹
:return:
"""
# 模拟滑动滑块
action = ActionChains(self.browser)
action.click_and_hold(slider).perform()
# action.reset_actions() # 清除之前的action
for i in tracks:
action.move_by_offset(xoffset=i, yoffset=0).perform()
time.sleep(0.5)
action.release().perform()
def login(self):
wait = WebDriverWait(self.browser, 10)
self.browser.get('https://captcha1.scrape.center/')
while True:
while True:
button = wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, '.el-button')))
button.click()
try:
captcha = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR, '.geetest_slicebg.geetest_absolute')))
break
time.sleep(1)
except:
print(f'点击失败重洗点击')
while True:
time.sleep(1)
captcha.screenshot(
f'D:\大纲\上课知识\爬虫\爬虫视频\20230412crwlab部署和深度学习破解滑块验证\yolov5-maste11r\yolov5-master\data\images\\captcha_0.png')
time.sleep(1)
opt = parse_opt()
main(opt)
# get_distance()
# print(111111111111111111111111111,distance)
if distance and distance > 0:
break
else:
refresh = wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, '.geetest_refresh_1')))
refresh.click()
time.sleep(1)
slide_button = self.wait.until(
EC.element_to_be_clickable((By.XPATH,
'//div[@class="geetest_slider_button"]'))
)
# 滑动滑块进行验证
# self.move_to_gap(slide_button, tracks)
simulateDragX(self.browser, slide_button, distance)
time.sleep(2)
try:
refresh = wait.until(EC.element_to_be_clickable(
(By.CSS_SELECTOR, '.geetest_refresh_1')))
refresh.click()
print(111111111111111111)
except:
# try:
self.browser.refresh()
# except:
# print('ok')
# break
time.sleep(2)
# if flag==1:
# print('ok')
# break
if __name__ == "__main__":
a = SeleniumLogin()
a.login()
a. 将parse_opt()里面的模型改成训练好的深度学习模型即可
b. 然后运行两行代码:
opt = parse_opt()
main(opt)
c. 就可以获得distance值(global全局变量)
d. 根据distance调用滑块拖动函数即可:模拟人为加速度拖动不好,一卡一卡的会被网站识别出。用快速拖动即可
解决问题
解决YOLOV5出现全为nan和0的问题
就记得cuda不能用最新版本,用10.2版本就行,太新的版本有毒
可以参考https://blog.csdn.net/weixin_45707277/article/details/125382624
解决如下错误
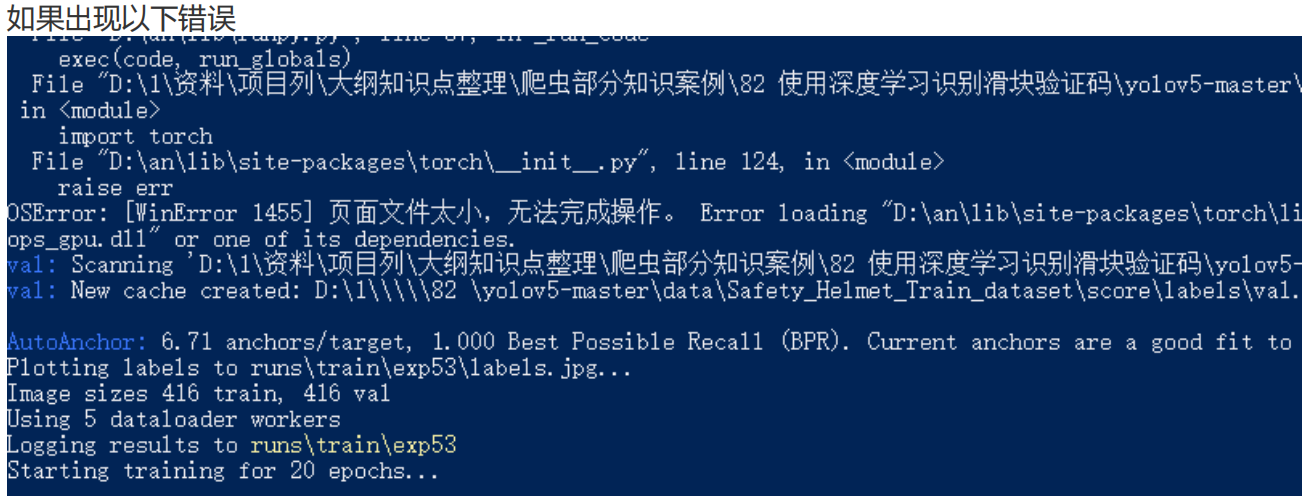
则是资源不够用
- 1是减少单次训练图片的数量
- 2 是加大内存
每个epoch使用的是同样的数据,重复同样的过程,为什么模型的性能还会发生变化?
每个epoch使用的是同样的数据,重复同样的过程,为什么模型的性能还会发生变化?_模型推理同样的数据重复推理为什么会快很多-CSDN博客
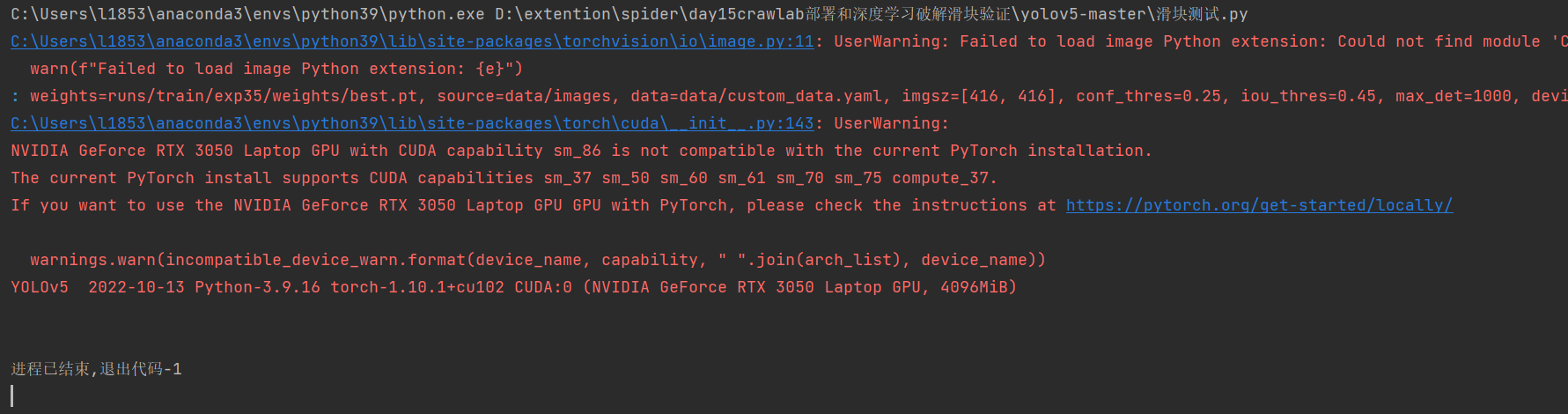
滑块测试报错如下
更多编程学习资源
编程学习公众号【程序员论周】

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 27
27 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)