分享一篇非常有意思的文章:是否有必要训练大模型?
模型不再是智能的衡量标准,而是生产力的要素。我们应该用TFP来衡量,同时考虑产出率、推理定价等因素。我们正在看软件吃掉世界,模型开始蚕食劳动力市场。能活下来的公司将是那些能以最高ROI把Token高效转化成劳动力的公司。
现在,大部分AI创业公司都是调用大厂的API来做产品。这样做目前没问题,但是按照历史规律,每家有野心的AI公司最后都会训练自己的模型——哪怕一开始只是做个简单封装的公司也不例外。为什么?因为训练模型的门槛正在快速下降。模型蒸馏、微调、后训练这些技术每个月都在变简单。等到超级AI公司把所有资金和人才都吸走的时候,想要保持竞争力,唯一的办法就是拥有自己的模型。
我们是怎么走到今天的
一开始,只有研究实验室在训练大语言模型。后来基于扩散模型的研究,出现了Midjourney和Stable Diffusion。接着整个AI行业爆发,各大实验室在2022年底到2023年初开始认真做商业化。
到了2024年,只要有几台GPU服务器,任何人都能开始训练模型。到2025年,DeepSeek花了600万美元就做出了一个前沿模型,推理能力达到了OpenAI的o1水平——这距离OpenAI发布o1才4个月,距离正式上线才2个月。
重点是:API背后的技术,已经不再是什么秘密了。
复制模型没那么神秘
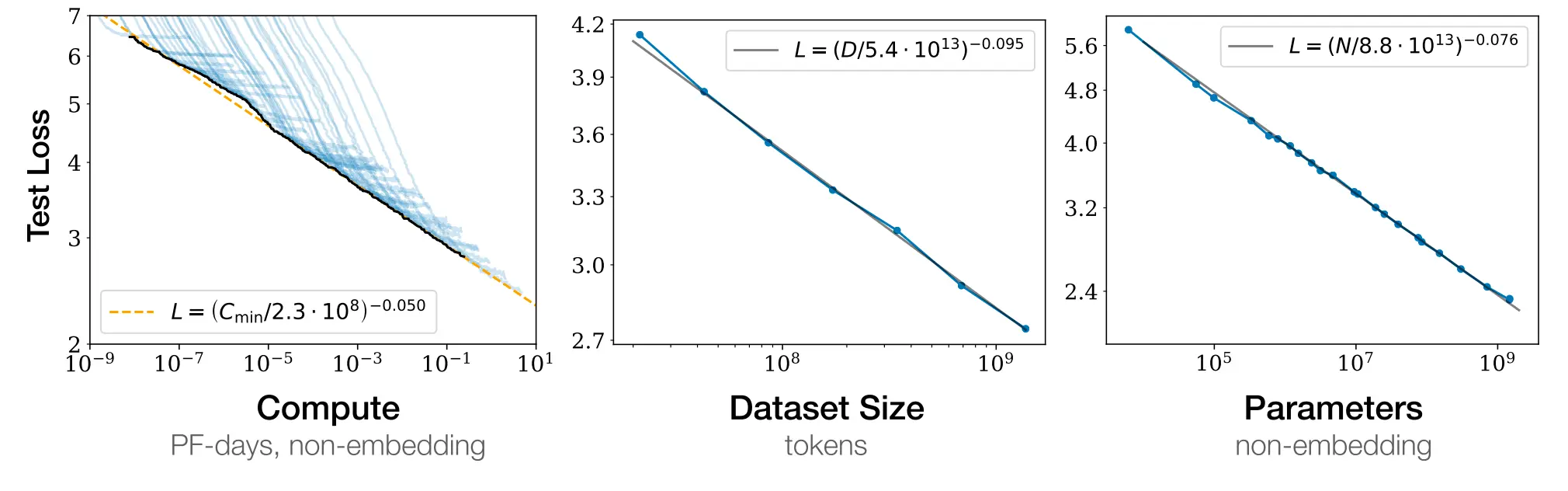
训练模型需要的东西很简单:数据、算力、架构。
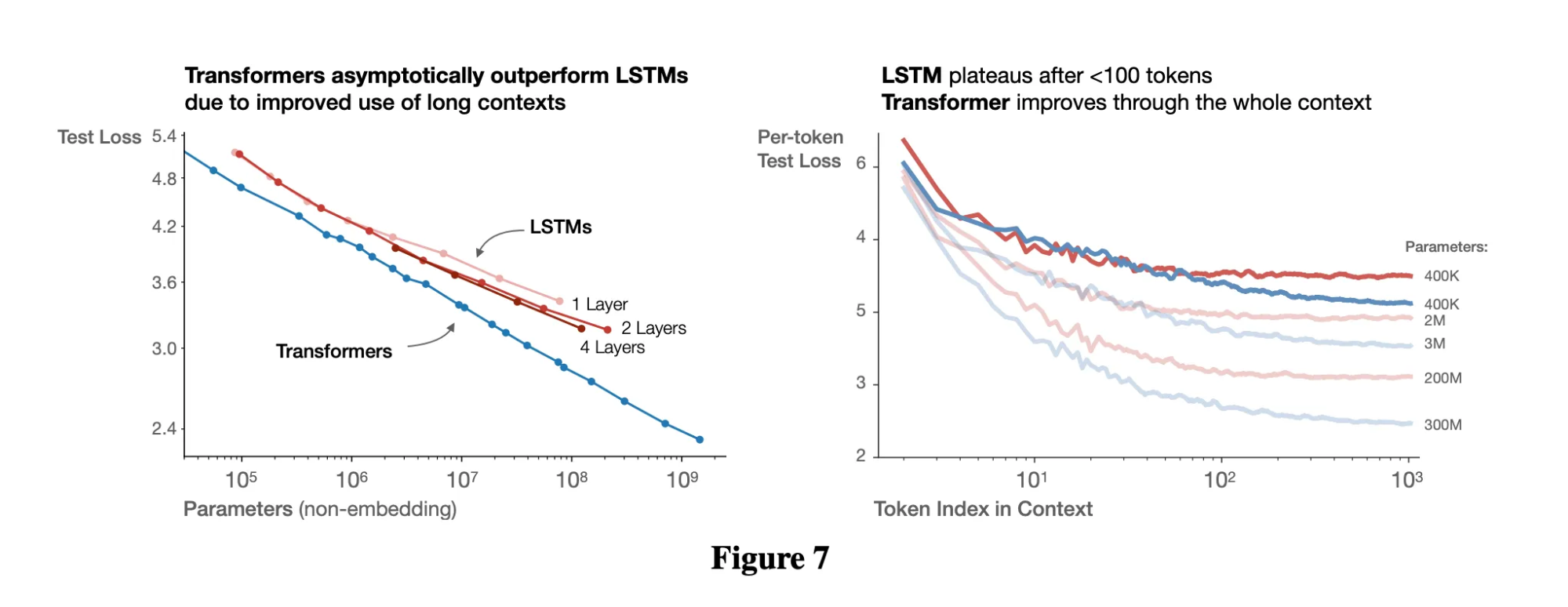
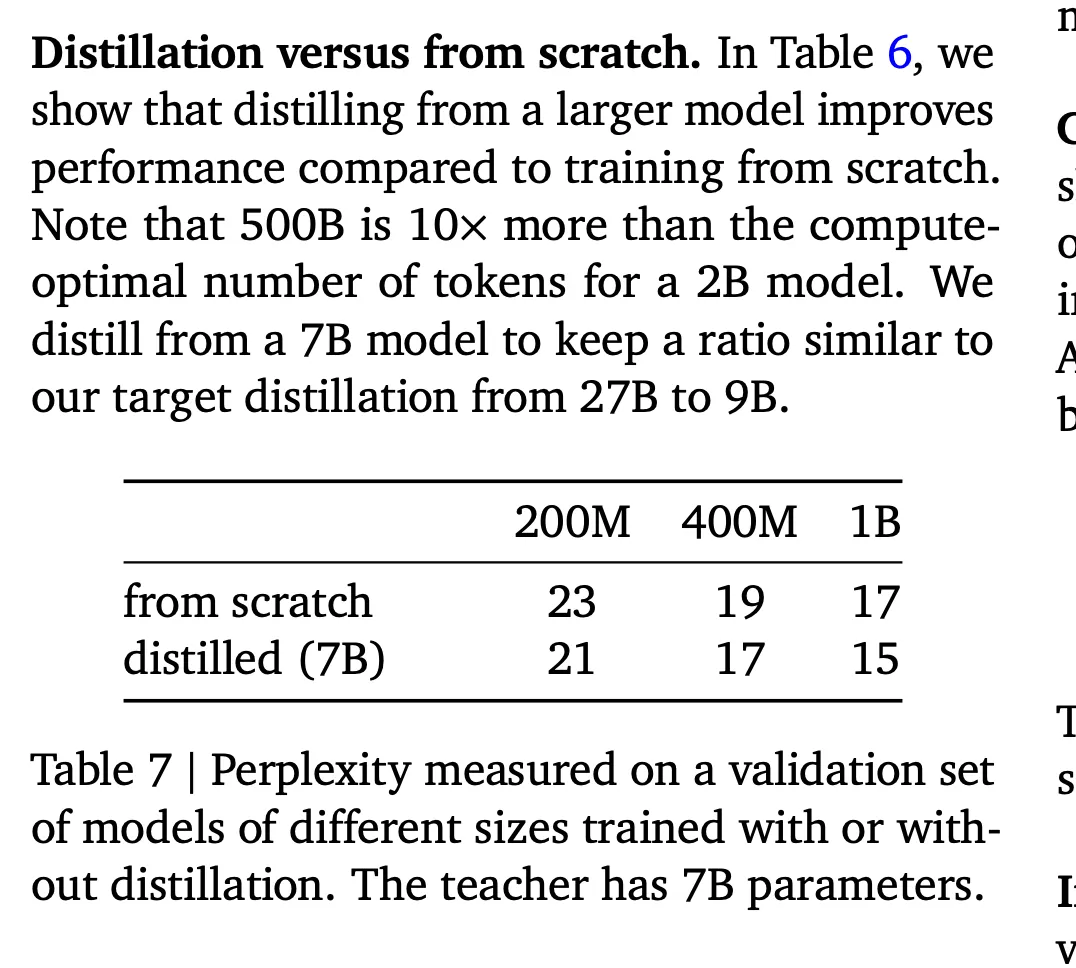
Transformer架构已经证明了自己比LSTM更强。现在预训练、后训练、推理这些知识都是公开的,基本没什么不能复制的,或者不能用Claude和Codex这些工具"照着感觉写代码"搞出来的。算力问题说白了就是找钱的问题。获取数据也可以通过蒸馏技术解决,最近有论文显示,蒸馏出来的10亿参数模型能达到从头训练的70亿参数模型的效果,Phi-4和Gemma就是这种数据高效利用的例子。
还记得2000年代做软件有多"难"吗?需要服务器、版本管理、光盘,还得有厉害的工程师。但一旦有人找到新玩法,就能称霸一个领域,比如亚马逊搞定了电商,谷歌搞定了搜索。现在训练模型的感觉跟那时候一样。难,但不是不可能。
突破点不在于发明新架构,而在于提高数据利用效率和强化学习。扩散模型也许还有潜力,但考虑到算力和数据都有限,效率是关键。
经济账
那应用公司为什么要费劲去训练模型呢?
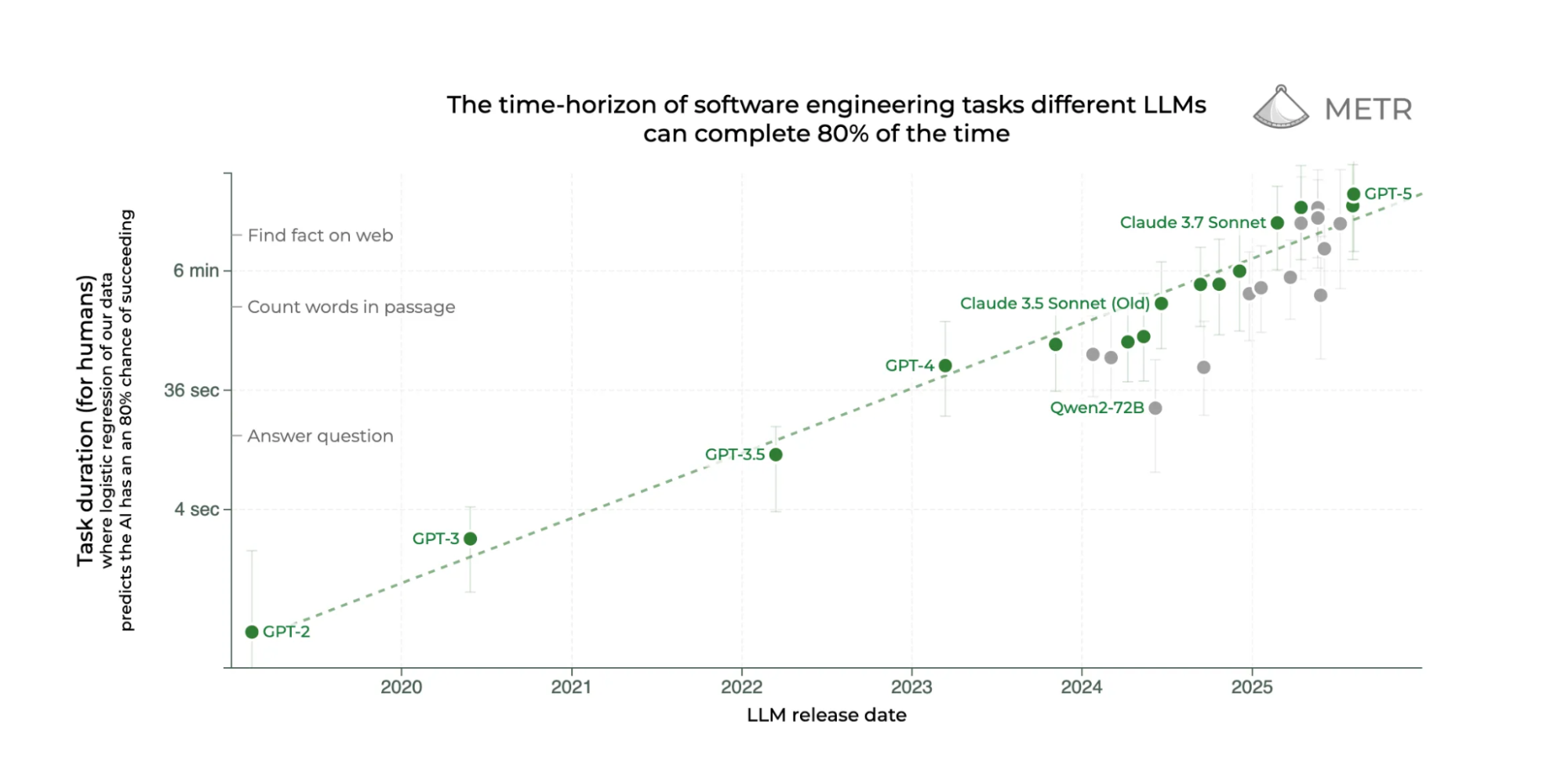
因为等到今年底,30分钟以内能完成的编程任务基本都会被自动化。到时候,软件本身就更像是一个直接卖给用户的品牌。渠道分发才是(一直都是)最重要的。
Cursor一开始就是VSCode和GPT-4的包装。现在它也在跑自己的专属模型。官方说是为了"快速应用"这样的功能。但有了数十亿条用户操作记录,Cursor完全可以训练出一个能处理几小时软件开发工作的模型。到那时候,具体用哪个底层模型就不重要了。重要的是Cursor能控制它。
这个套路是固定的:
- 先用API包装找到产品和市场的契合点,同时收集数据
- 为特定功能微调小的专业模型
- 用自己的数据护城河训练自己的模型
- 提高每个Token的生产效率,也就是给用户提供更多价值,留住用户
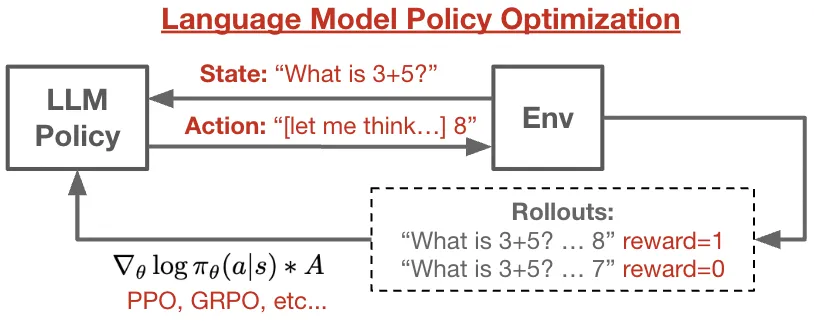
你的应用实际上就变成了一个强化学习的环境。或者你把这些宝贵的用户行为数据卖给大厂。
数据是瓶颈
OpenAI收购Statsig就是为了获取他们"会话重放"产品里记录的数十亿条用户屏幕操作。萨顿和西尔弗把这叫做"经验时代"——下个阶段的关键是智能体和环境互动产生的数据。
这就是为什么我认为电脑操作是通向AGI的重要路径。每个软件界面都变成了环境,每次操作都变成了经验数据。专业人士大部分时间都在电脑前工作。想想我们错过了多少没标记、没记录的数据。
一旦模型成为产品,积累的输入就是经验。谁能收集到这些重放数据,谁就有了优势。
Token生产效率
我每月花200美元买Claude Pro。但我从中得到的价值每年值五六位数。也就是说,我花1美元大概能得到42美元的价值。这么高的回报率下,理智的选择就是训练自己的模型。Claude这么做了,Cursor可能也得这么做。
我们应该开始衡量生产力指标,而不只是使用量:
- 每单位工作需要多少Token
- 每个Token的经济价值
- Token生产效率(TFP)
TFP指标最简单的算法:
TFP = (产出的经济价值) / (消耗的Token数量)
其中:
- 产出的经济价值 = 模型完成的工作值多少钱
- 消耗的Token数量 = 过程中用掉的Token数(输入+输出,或者你定义的范围)
就像经济学里的全要素生产率一样,TFP衡量每个Token能产生多少价值。
以我自己为例,我生成的Token里,只有不到1%-10%的代码最后真正用到了生产环境。所以按API定价,我每月花大约2000美元,用了17亿个Token(Opus和Sonnet混用,大量缓存)。其中大约200美元的部分对我真正有用,理论上我愿意为此每年付10万美元。所以实际上,我每花1美元Token就得到42美元价值。假设推理零成本,Claude给我创造了42倍的TFP!如果我只是做个Claude代码包装服务,除非我也做推理,否则长期看这根本不可能。我更愿意处在Devin的位置。
随着AI在经济中普及,这个指标会越来越受欢迎。考虑到输入Token的成本和用户愿意为最终产品付的钱,一个"凭感觉编程"的强化学习环境值多少钱?为了培训医生、住院医师、学生而付费值多少?让整个组织符合SOX法规你愿意花多少钱?
总结
模型不再是智能的衡量标准,而是生产力的要素。我们应该用TFP来衡量,同时考虑产出率、推理定价等因素。
我们正在看软件吃掉世界,模型开始蚕食劳动力市场。能活下来的公司将是那些能以最高ROI把Token高效转化成劳动力的公司。
参考资料:
- 扩散强化学习/效率讨论 — https://arxiv.org/abs/2507.15857
- 自动化的经济价值 — https://epoch.ai/gradient-updates/most-ai-value-will-come-from-broad-automation-not-from-r-d
- 不同领域的时间跨度 — https://metr.org/blog/2025-07-14-how-does-time-horizon-vary-across-domains/
- LMPO: 用强化学习做语言模型后训练 — https://github.com/kvfrans/lmpo
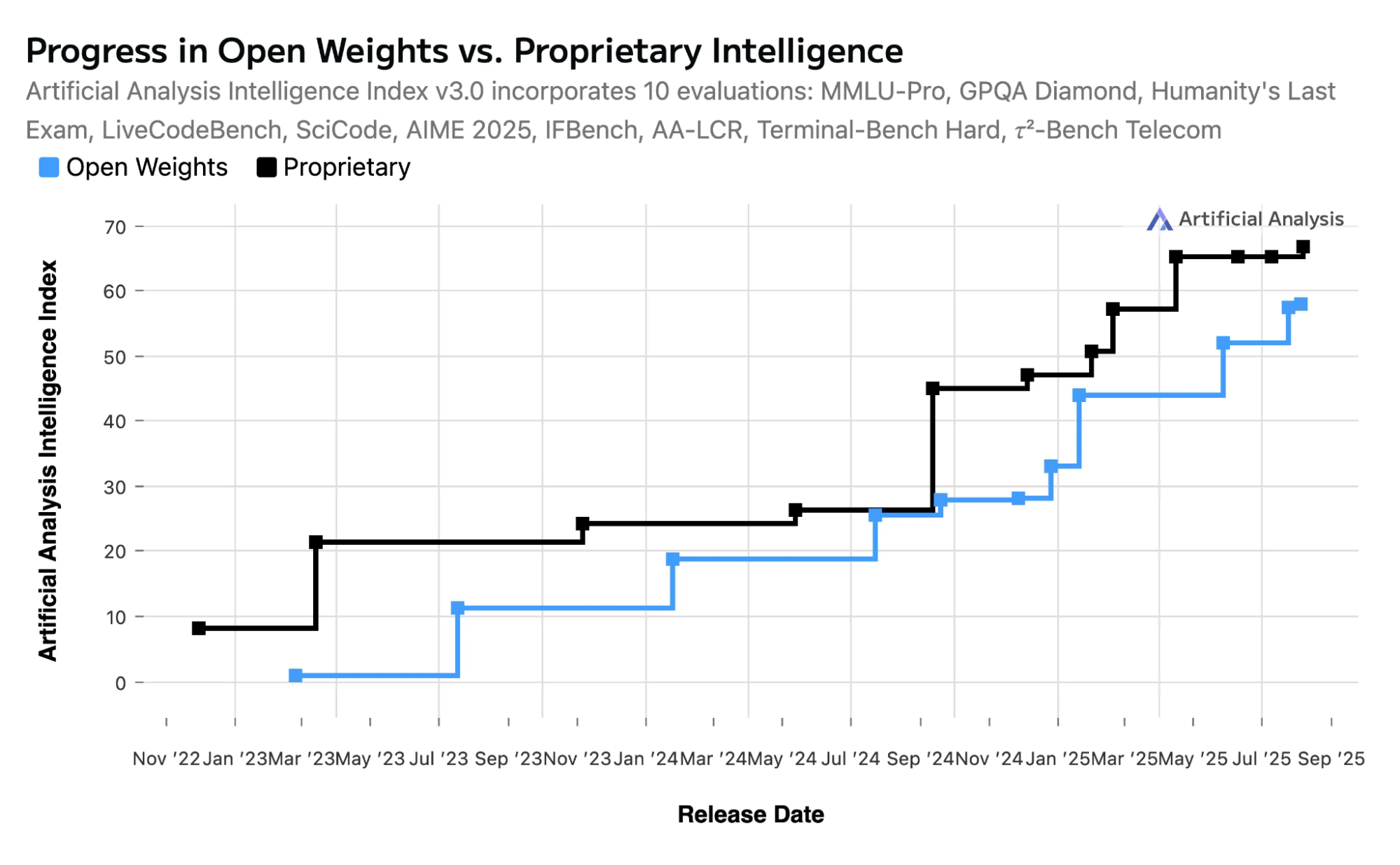
- AI模型定价和性能趋势 — https://artificialanalysis.ai/trends
- https://sdan.io/blog/training-imperative

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)