AI生成测试用例的痛点问题及解决方案
目前市面上太多所谓企业级落地的AI测试产品,事实上绝大多数是Demo玩具,而且纯靠系统支撑,也无法真正在企业落地。比如AI能够快速生成大量测试用例,在实际落地过程中仍面临质量不稳定、领域知识缺失、多模态解析不准确、工程化效率低等核心痛点。
📝 面试求职: 「面试试题小程序」 ,内容涵盖 测试基础、Linux操作系统、MySQL数据库、Web功能测试、接口测试、APPium移动端测试、Python知识、Selenium自动化测试相关、性能测试、性能测试、计算机网络知识、Jmeter、HR面试,命中率杠杠的。(大家刷起来…)
📝 职场经验干货:
目前市面上太多所谓企业级落地的AI测试产品,事实上绝大多数是Demo玩具,而且纯靠系统支撑,也无法真正在企业落地。
比如AI能够快速生成大量测试用例,在实际落地过程中仍面临质量不稳定、领域知识缺失、多模态解析不准确、工程化效率低等核心痛点。
结合已经落地的一些项目案例,聊聊这些痛点问题和目前的解决策略。
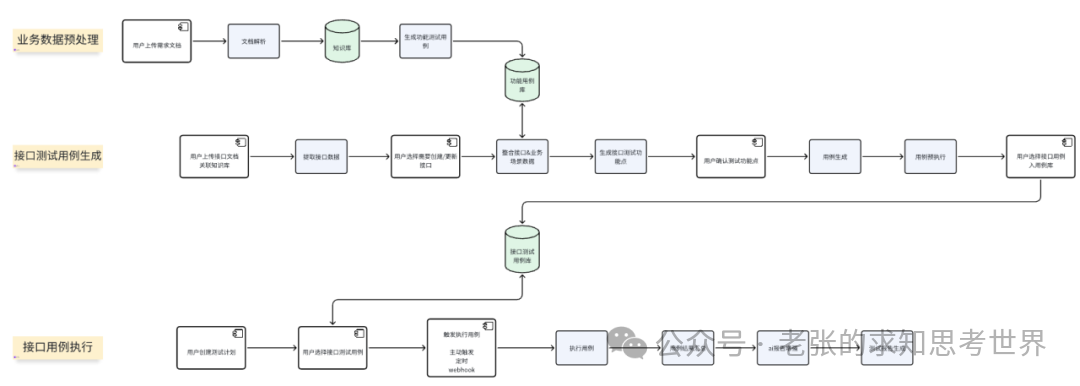
痛点问题及根源分析
1、生成质量不稳定:逻辑混乱与格式散乱
-
步骤与预期结果割裂:生成的用例中操作步骤描述点击按钮,但预期结果仅描述“功能正常”,未明确界面状态变化(如弹窗出现、数据刷新)。
-
粒度失控:同一功能点下,部分用例包含10余个冗余步骤(如重复登录),而关键场景(如支付超时)仅用1步概括。
-
术语错位:证券业务中“回转交易”被错误关联到“债券逆回购”,导致用例无法执行。
问题根源:模型缺乏测试方法论结构化引导,且未约束输出格式。
2、领域知识缺失:业务规则理解偏差
-
金融资损漏洞:优惠券叠加规则(如“满100减20”与“8折券”能否同用)未被识别,导致资损用例遗漏。
-
证券合规盲区:未覆盖“非交易时段撤单自动失效”等监管规则,生成用例允许盘后撤单。
-
行业术语混淆:医疗系统中“PRN医嘱”(按需执行)被误为常规每日执行,生成错误用药频率用例。
问题根源:通用模型未注入垂直领域知识库与业务规则库。
3、多模态解析失效:图文信息割裂
-
UI设计稿遗漏:需求文档中的按钮位置标注(如“购物车图标位于右下角”)未被解析,导致分辨率兼容性用例缺失。
-
流程图分支忽略:用户注册流程图中“实名认证失败”分支未生成对应异常用例。
-
跨文档关联断裂:接口文档中的错误码(如“5001=余额不足”)未与前端操作步骤关联。
问题根源:纯文本模型无法理解图像/表格的语义信息。
可参考的几种落地方案
一、生成后的用例处理流程
AI生成的测试用例通常需要经过质量校验、格式标准化、业务适配性优化等步骤,才能直接用于测试执行。以下是详细的处理流程:
1、质量校验:过滤无效用例
-
步骤完整性检查:如确保每个用例包含前置条件、操作步骤、预期结果,且逻辑连贯。
-
预期结果合理性:避免模糊描述(如“功能正常”),要求明确状态变化(如“订单状态变更为‘已支付’”)。
-
冗余用例剔除:合并重复用例(如多个相同边界值测试)。
-
业务规则校验
-
-
合规性检查:金融/医疗等行业需验证是否符合监管要求(如“不允许未授权访问”)。
-
资损风险检查:支付、优惠券等场景需确保用例不会导致资金损失(如“退款金额≤支付金额”)。
-
2、格式标准化:适配测试管理系统
-
用例结构转换
-
XMind脑图适配:将生成的用例按功能模块分层(如“登录→密码错误→提示‘密码错误’”)。
-
Excel/系融化适配:转换为标准表格格式(用例ID、步骤、预期结果、优先级)。
-
-
命名规范化:用例标题采用“功能点_测试场景_预期结果”格式(如“登录_错误密码_提示错误信息”)。
3、业务适配性优化:增强用例可执行性
-
补充测试数据
-
为用例提供测试账号、测试商品ID、API参数示例(如“测试用户:test_user_001”)。
-
边界值补充:如“金额输入:0.01、999999、1000000(超限)”。
-
-
异常场景增强:补充网络异常、服务降级等场景(如“支付时断网,检查本地订单状态”)。
4、UI设计稿解析
-
技术方案:OCR+目标检测:使用OCR识别设计稿中的文字(如按钮标签),结合目标检测定位元素坐标。
-
设计工具插件:Figma/Sketch插件自动导出元素属性(如按钮ID、位置、交互状态)。
二、人工评审关键环节处理流程
尽管AI可生成大部分用例,核心环节仍需人工介入:
1、高风险用例复核
- 金融资损类:如“大额转账、优惠券叠加”需人工确认逻辑正确性。
- 合规类:如“用户隐私数据访问”需法务/合规团队审核。
2、复杂业务逻辑修正
- 多系统交互场景:如“订单支付后库存扣减+积分增加”,需人工补充关联校验点。
- 状态机验证:如“订单状态:待支付→已支付→已发货”,需人工补充状态流转用例。
3. 测试数据优化
- 真实数据模拟:如金融测试需使用符合业务规则的测试账号(如“VIP用户 vs 普通用户”)。
- 环境依赖处理:如“依赖第三方支付的用例”需补充Mock服务配置说明。
三、自动化后的技术解决方案
1、规则引擎自动修正
-
格式修正规则
-
自动补全缺失字段(如未写“前置条件”时,默认填充“系统已登录”)。
-
标准化描述(将“点击按钮后应该成功”改为“点击‘提交’按钮,页面跳转至‘支付成功’页”)。
-
-
逻辑修正规则:冲突用例合并(如多个“密码错误”用例合并为一条,补充不同错误类型)。
2、历史用例库检索增强
-
相似用例召回:基于需求描述检索历史用例,复用已有测试点(如“登录失败”场景可直接复用)。
-
差异对比:新旧版本用例对比,自动标记新增/修改部分(如“V2.0新增指纹登录用例”)。
3、测试数据自动生成
-
基于用例语义生成数据
-
-
如“测试用户注册”用例,自动生成符合规则的手机号、邮箱。
-
-
-
边界值数据自动计算(如“金额字段:最大值+1、最小值-1”)。
-
落地实践案例及关键实施建议
1、金融支付
-
人工复核“跨境支付”用例,补充汇率计算校验点。
-
自动关联历史Bug库,标记曾引发问题的场景(如“重复支付”)。
2、电商行业
-
人工优化“秒杀库存扣减”用例,增加并发请求测试。
-
自动补充促销规则用例(如“满100减20不与折扣券叠加”)。
-
解析UI设计稿,生成分辨率适配用例(如“在375×812屏点击购物车图标”)。
3、医疗行业
-
术语标准化(如“PRN医嘱”统一替换为“按需执行”)。
-
人工补充设备异常场景(如“CT机断电时的数据保存机制”)。
-
自动关联HIPAA合规规则,过滤不合规用例(如“未授权访问患者数据”)。
4、关键实施建议
-
分阶段实施:优先处理高风险领域(支付、资损),再扩展至全业务。
-
建立质量门禁:设置自动化检查点(如“所有用例必须含预期结果”),不合格用例阻断流转。
-
持续迭代知识库:将人工修正的用例反馈AI模型,形成闭环优化。
AI生成用例的后期处理是“机器效率”与“人工经验”的结合。
通过规则引擎、历史用例复用、自动化数据生成等技术,可减少80%的人工操作,剩余20%的关键决策仍需人工介入。金融、医疗等行业需尤其注重合规性校验,而电商可侧重UI与促销规则优化。
最终目标是实现“AI生成→自动处理→人工微调”的高效流水线。
最后: 下方这份完整的软件测试视频教程已经整理上传完成,需要的朋友们可以自行领取【保证100%免费】



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献100条内容
已为社区贡献100条内容

所有评论(0)