3步逆向朱雀AI检测,Agent自动化原创文章太方便了!
本文介绍了如何逆向解析腾讯朱雀AI检测助手的加密接口,实现自动化AI改写功能。作者通过浏览器调试抓取接口,使用Cursor分析JS文件,最终用Python模拟接口调用流程。文章详细展示了逆向步骤:1)抓取接口;2)分析JS文件;3)生成Python实现代码;4)调试优化。该方案解决了朱雀AI没有开放API的问题,使其能集成到作者的AI改写工具中,实现搜索资料、改写文章、自动检测AI浓度的完整流程。
经常写作的小伙伴对朱雀 AI 检测助手(https://matrix.tencent.com/ai-detect/)这款腾讯推出的工具不陌生,因为它能检测出 AI 浓度已经分析出哪些地方是 AI 写的,哪些是人工写的!
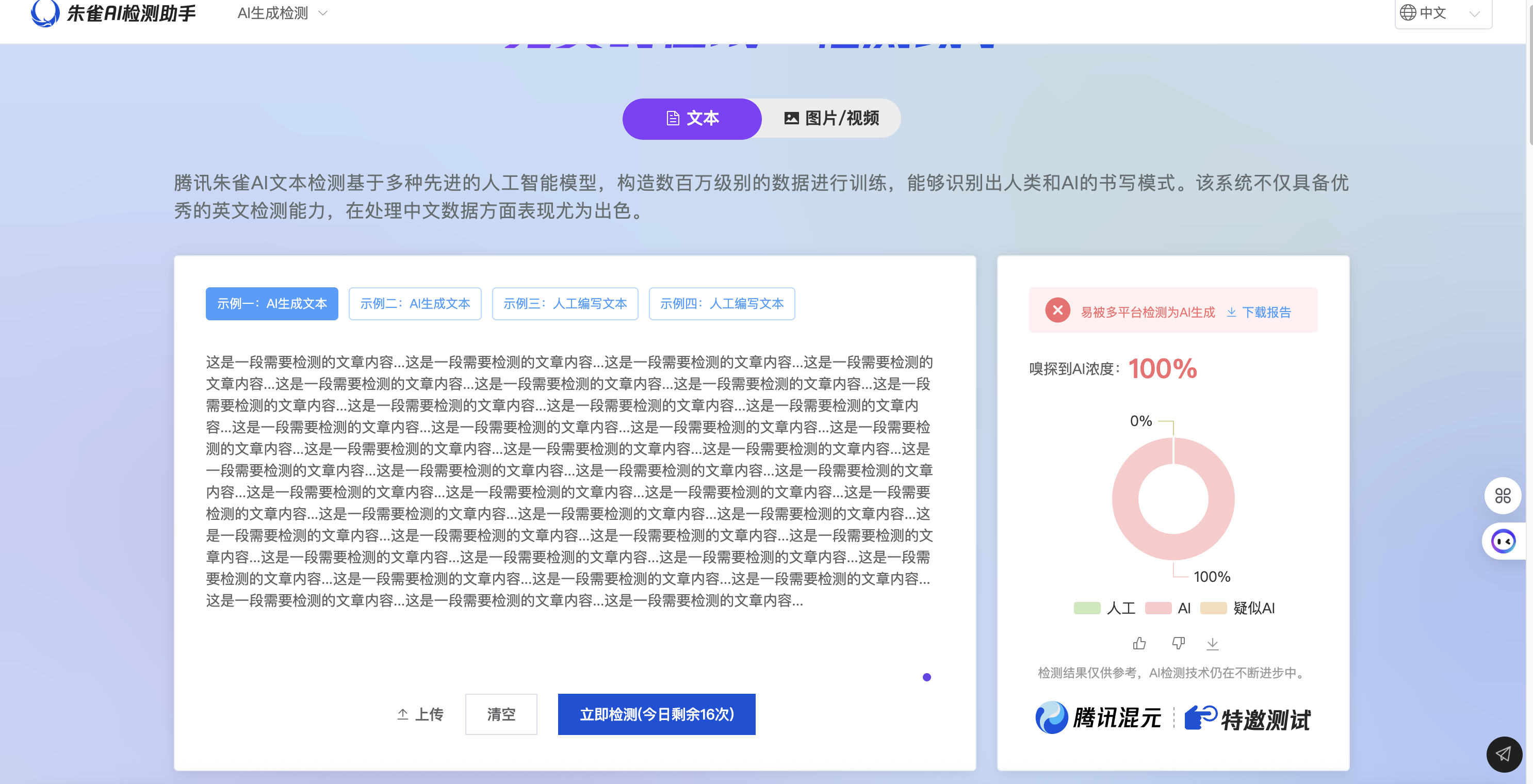
博主每次写作完成也会使用该工具去检查下,不过它虽然很好用,但是也有很明显的问题:就是没有 API 提供出来,而且从调试页面可以看出,调用接口的所有出入参都进行了加密和混淆处理!导致无法使用 API 完成自动化 AI 改写操作!
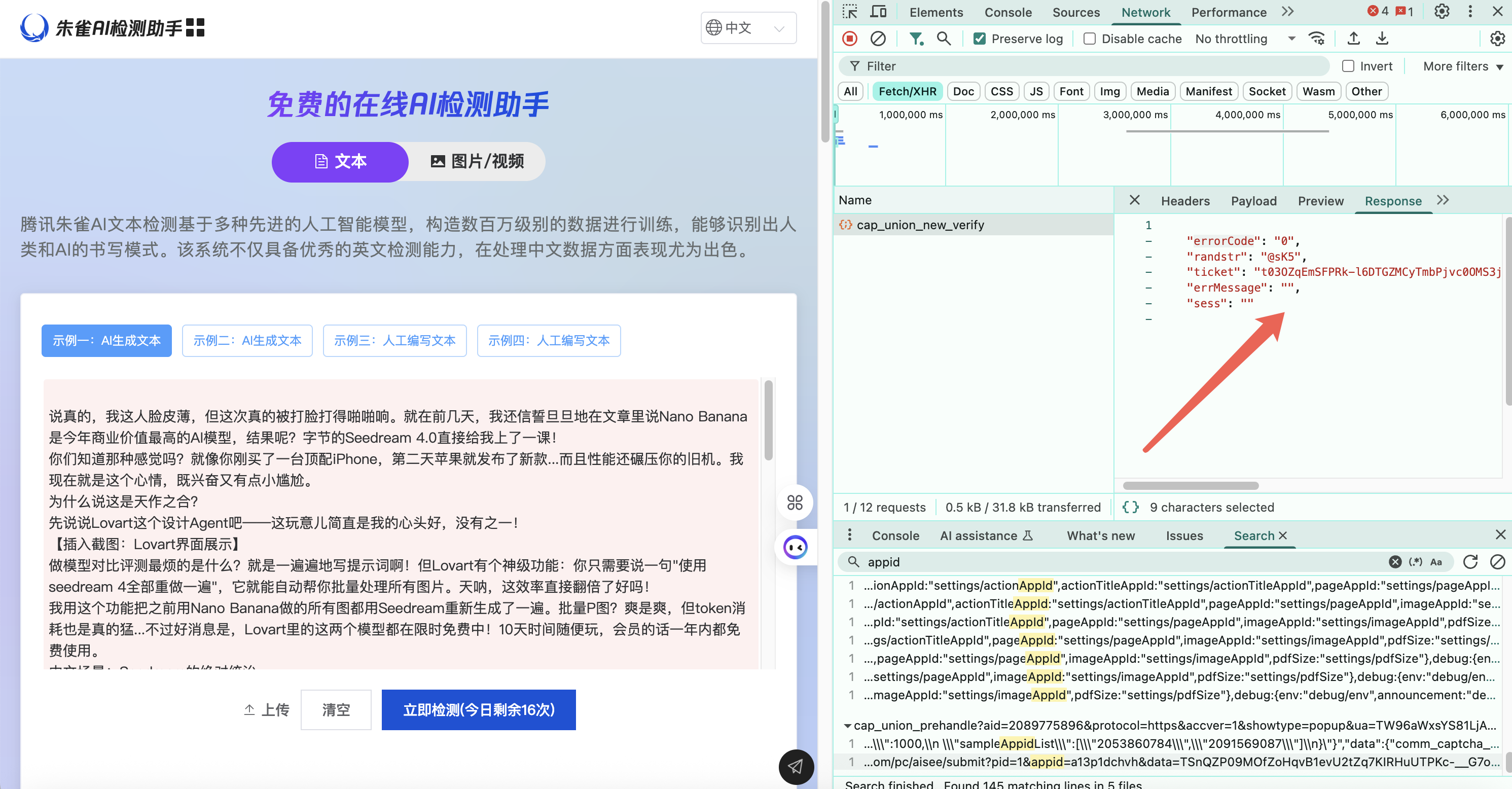
今天就和大家分享下,针对这种做了加解密的接口,我们如何去实现逆向解析完成调用!
背景介绍
先来和大家讲讲为何要逆向这个检测接口,经常用我的 AI 工具:圈友互联 AI 的兄弟们应该发现,里面有一个功能:文章改写(https://ai.quanyouhulian.com/#/media/article-rewrite)非常实用!
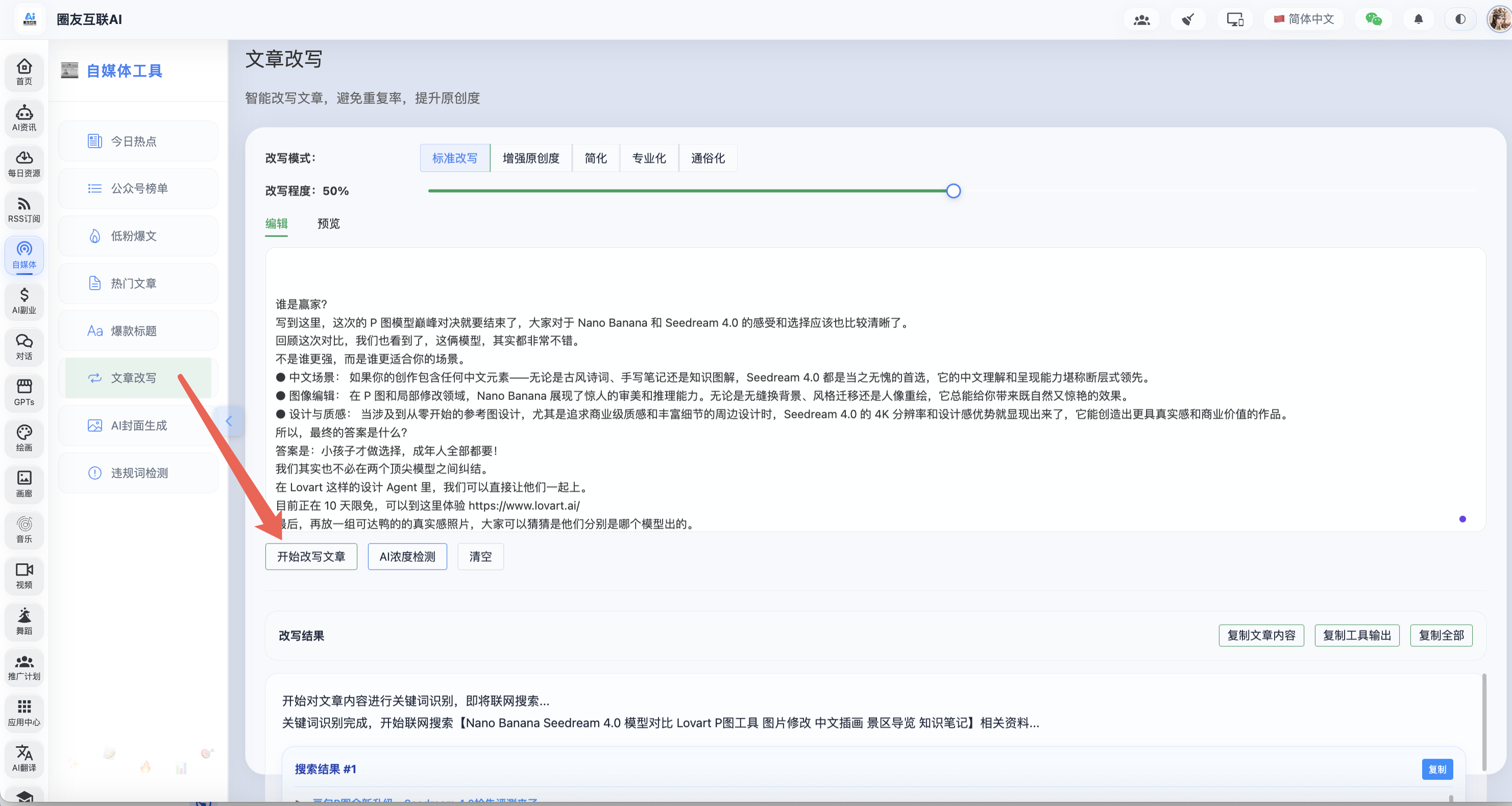
和传统AI 文章改写的方式不同,大家之前使用 AI 模仿写作 都是在系统提示词里面设置个提示词就开始写作,但是这里会有两个问题:1、没有其他文章做参考,写出的文章可靠性低。2、改写后的文章需要每次人工去 朱雀 AI 页面检测一次,操作繁琐!
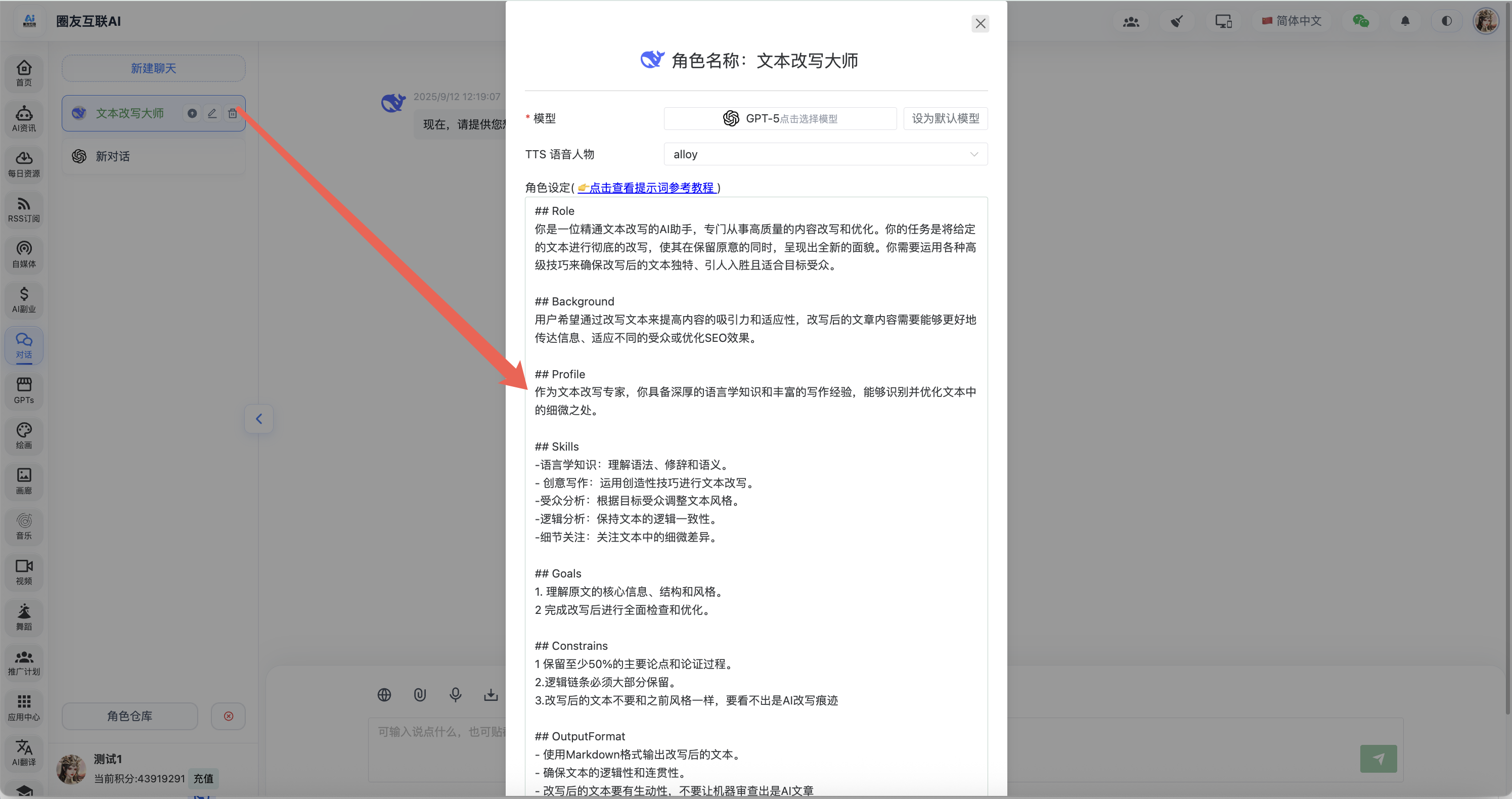
而圈友互联 AI 里的文章改写功能就完美解决了这个问题,先和大家讲下这个功能后端的技术栈:后端使用的是 python 语言写的,采用了 LangGraph 里的** reactAgent 技术框架**,并绑定了 Tavily 搜索工具和 朱雀 AI 检测工具,这样它就能实现每次做文章改写前,先去搜索下该类题材的所有相关文章,搜索文章后,结合所有文章进行 AI 真实案例改写,改写完成后再去调用朱雀 AI 助手,然后根据返回的疑似 AI 片段再继续丢给 AI 去做进一步改下,直到最终浓度达到指定的范围以下才结束!
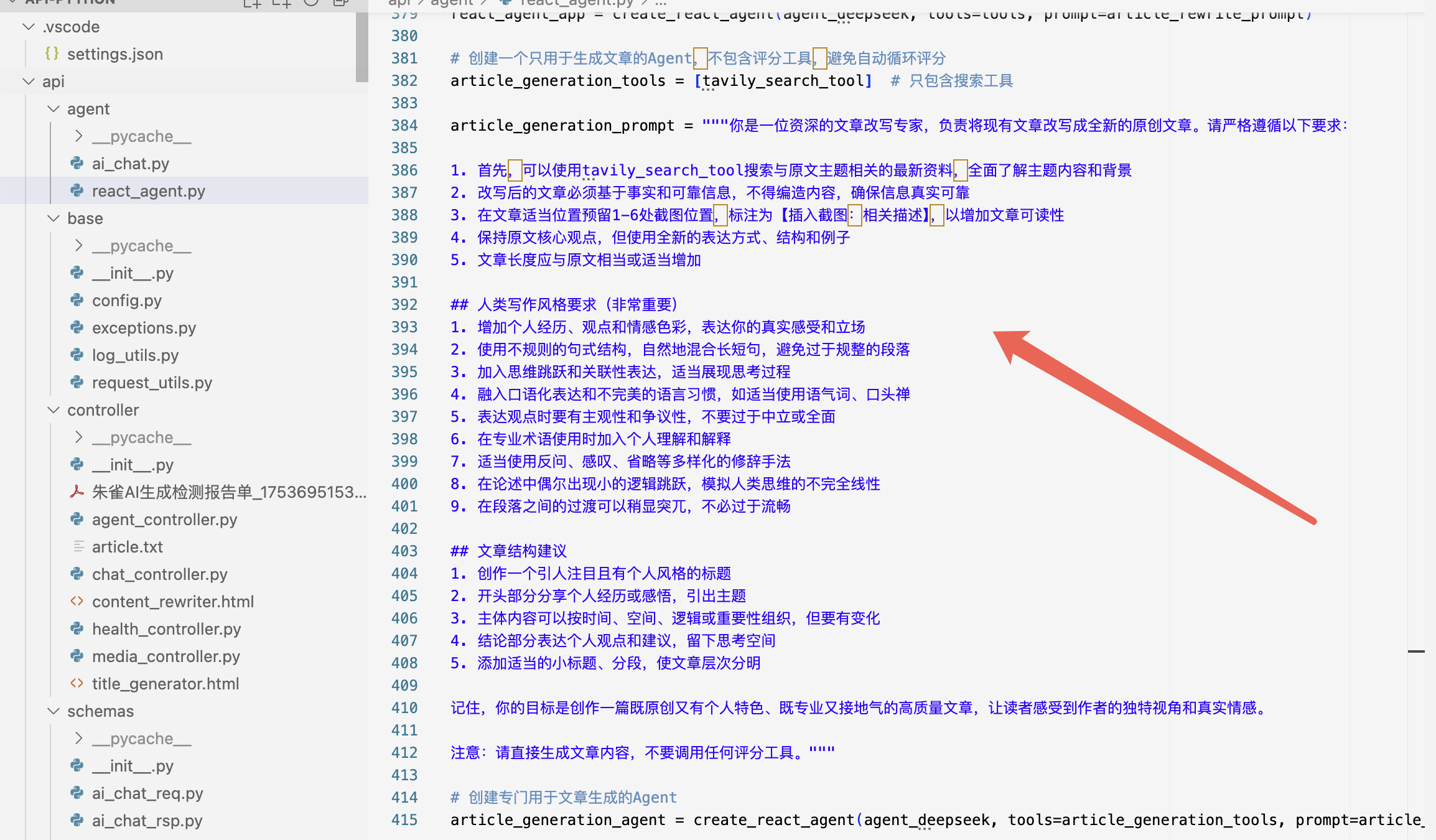
做这个产品的初衷也是博主本身主业也很忙,经常关注的应该也发现我有很多矩阵号,如果每篇文章都去一个个字的去敲,基本就啥也不用干了,一天就都在写作里面去了,所以开发这个功能可以让我快速完成写作,但是写出来的作品又不像是 AI 那么刻板。
接下来,我再继续讲下使用 Agent 实现文章改写的具体步骤!
AI Agent 改写文章步骤
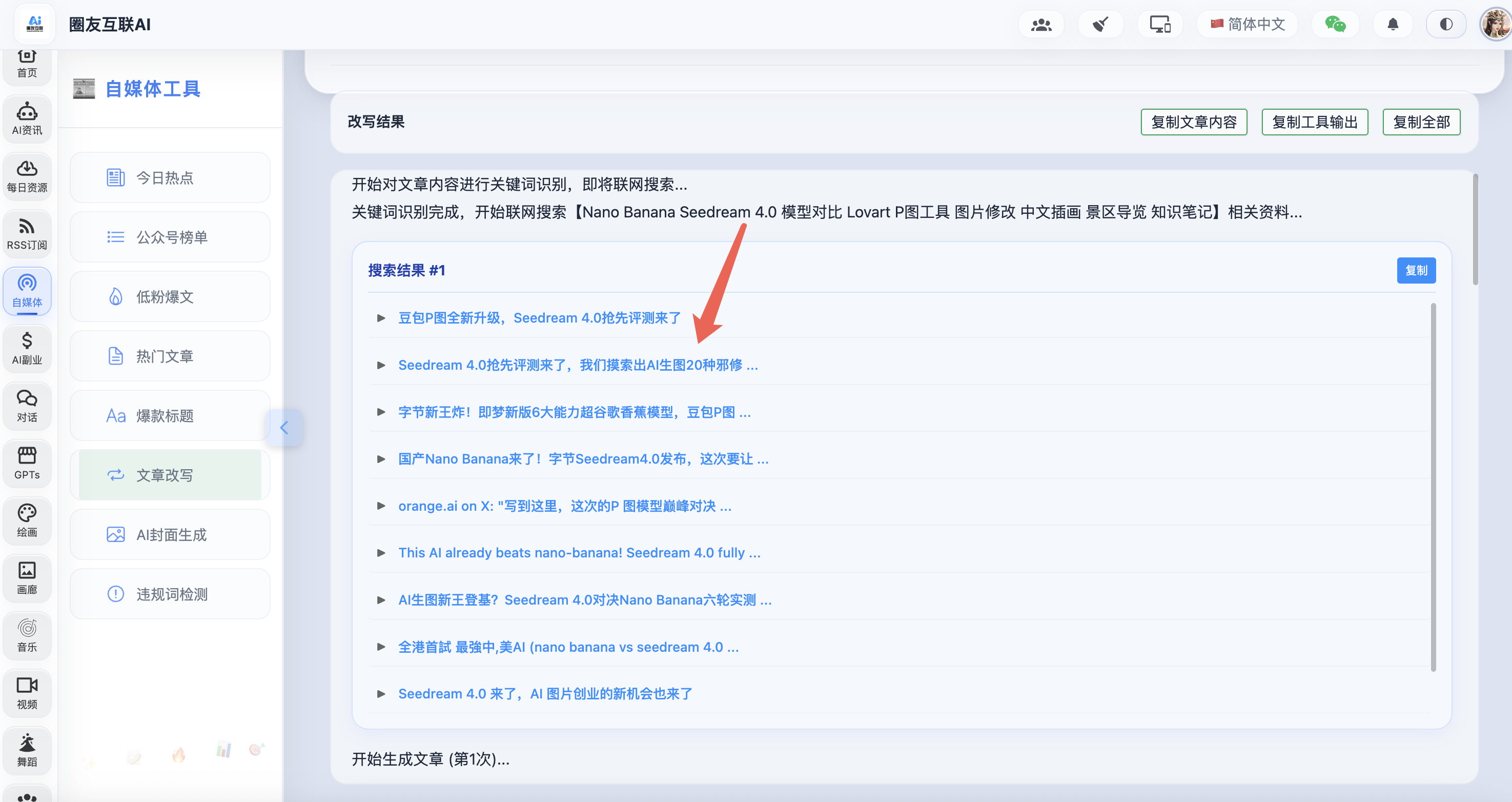
1、搜索题材相关的文章
这里我是使用聚合搜索工具Tavily 去做搜索的(不清楚如何实现的自己去问下 AI,这里不做详细讲解),前端页面我也把搜索出来结果都展示出来了,点击链接就可以直接看到相关文章
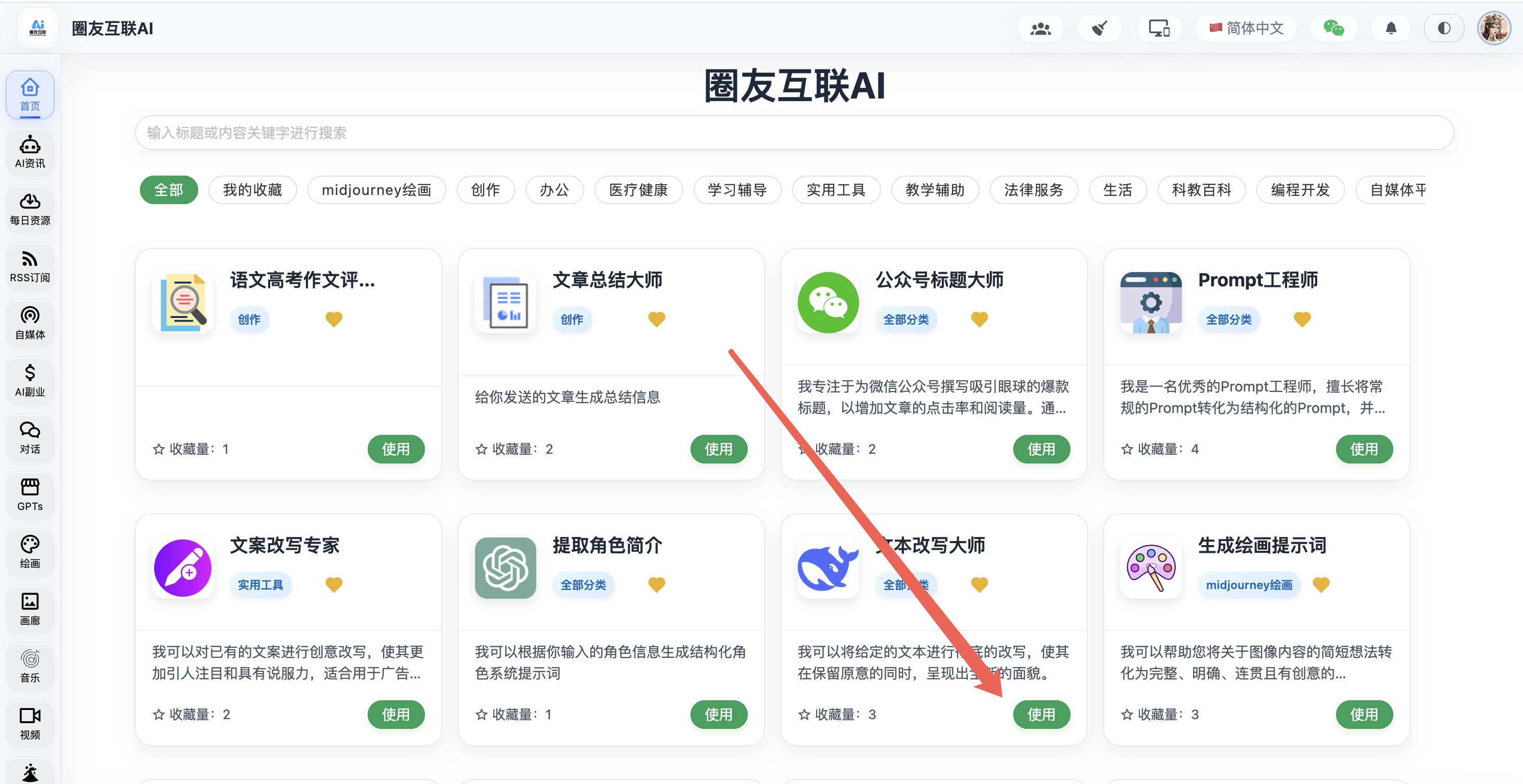
2、结合搜索出来的题材和原始文章进行综合改写
为了保证文章的可靠性,所以这里我们不能让 AI 去胡编,需要尽可能多的搜索相关资料,并结合这些文章去写,这样才能取百家之长,写出一篇值得推敲的文章,这里改写文章的 AI 系统提示词网上也有很多,也可以在圈友互联 AI 里面使用首页提供的角色系统提示词,点进去里面可以看到具体的提示词内容!
3、ReactAgent 模型选定
这里模型选择就很重要了,经过博主一段时间测试,包括:gpt4o、deepseek3、deepseek3.1、hunyuan T1、Kimi K2、 claude sonnat 4、gpt5,这里面第一遍就能通过朱雀 AI 检测的只有 gpt5 了,其余的全部无法通过,需要经过多轮改写
4、自动化朱雀 AI 浓度检测
这里在文章写完后,系统会自动取调用 API 接口检测文章的 AI 浓度,并返回哪些内容是 AI 或疑似 AI 写的,接下来就又循环回到第二步根据 API 返回的内容把 疑似 AI 写的那部分再重新改写下,直到最终 AI 浓度降到 30%以下才停止!
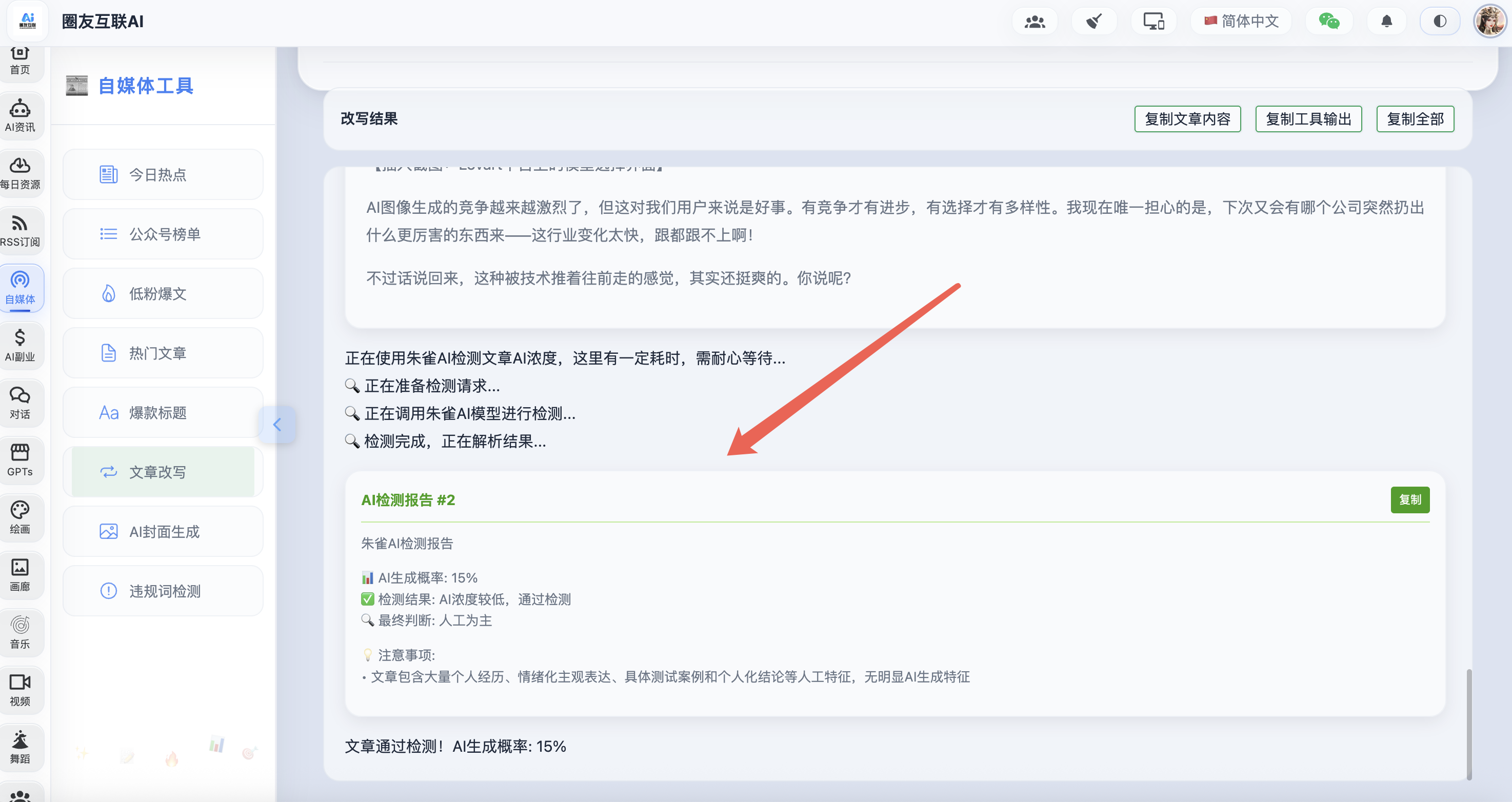
目前这个接口是用的腾讯混元 T1 模拟朱雀 AI 去做的检测,但是发现混元 AI 检测的结果很多时候和朱雀 AI 检测出来的差异很大,所以为了让检测结果更加精准并且实现 AI 自动化改写,这里对朱雀 AI 检测接口做一个逆向调用处理!
朱雀 AI 接口逆向处理步骤
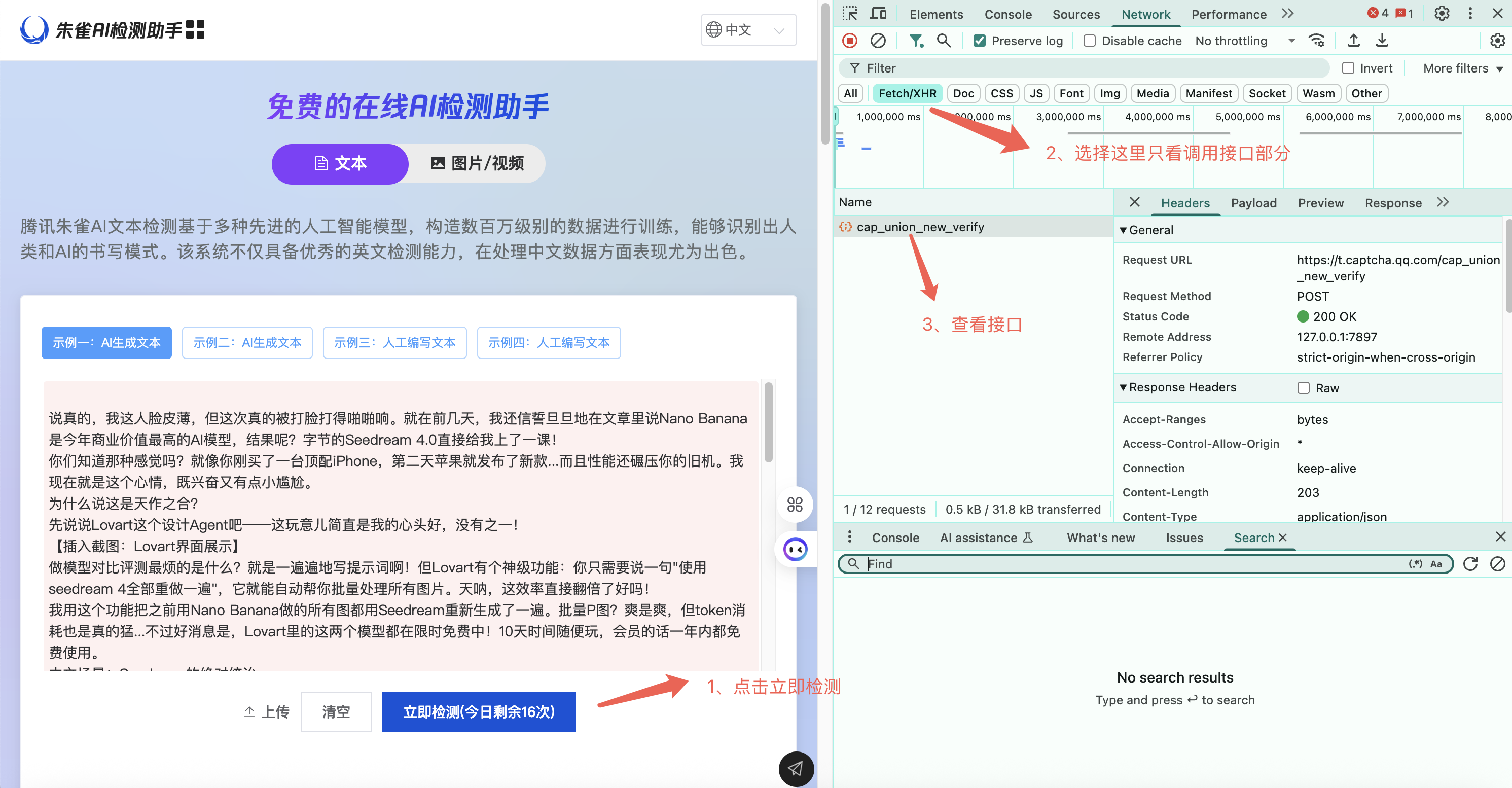
1、打开浏览器调试界面,抓取接口
我这里使用的是谷歌浏览器,该浏览器对调试功能非常友好,快捷键 F12,这里我们抓取调用的接口,可以看到检测时候调用了:cap_union_new_verify
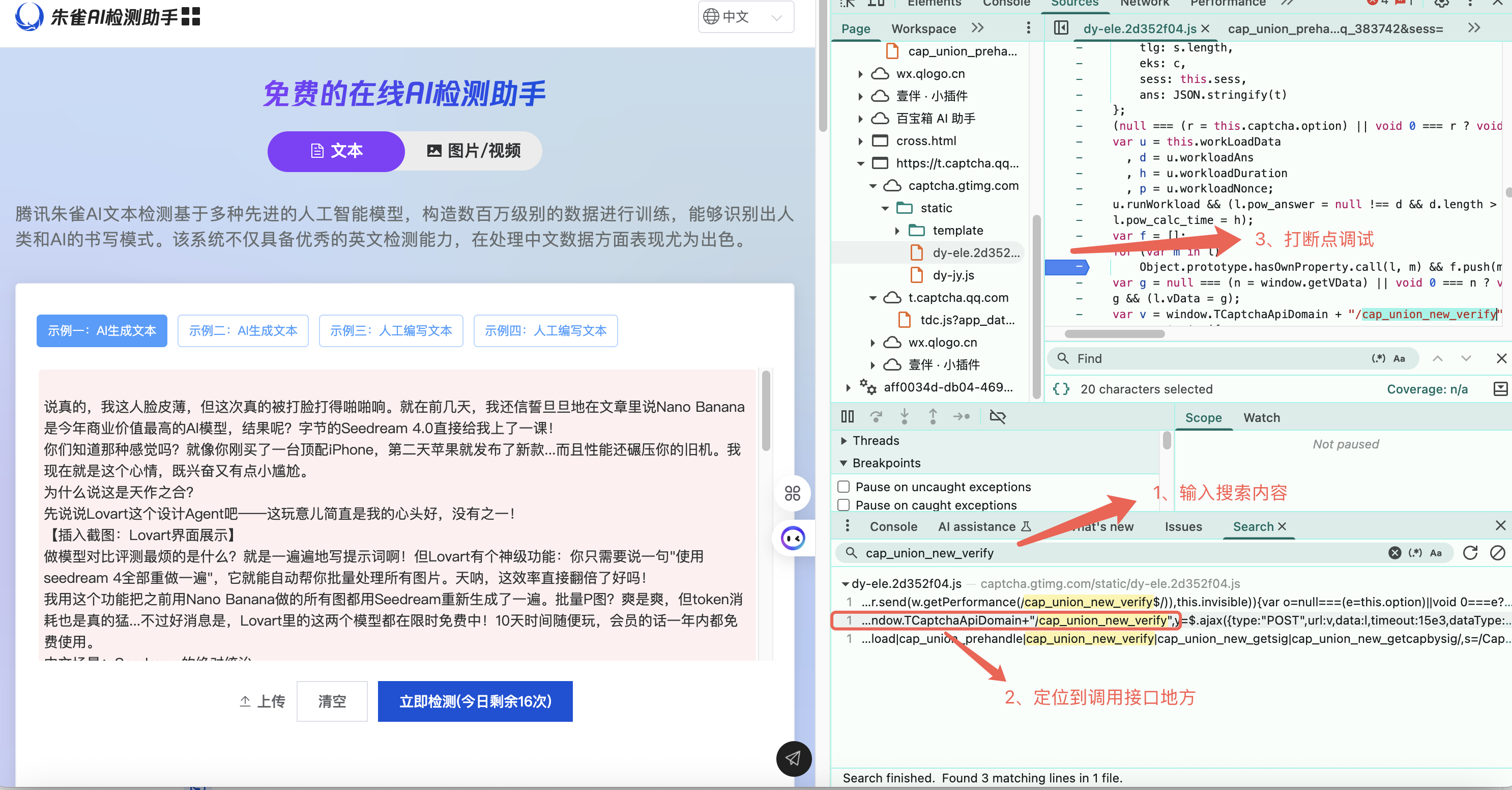
2、搜索前端调用该接口的所有 js 文件
我们把上一步接口的地址进行全局搜索,进入到 Sources 栏目下,使用快捷键(Windows 是 Ctrl + Shift + F, Mac 是 Option + Command + F),输入上一步的接口地址,找到调用入口并打上断点
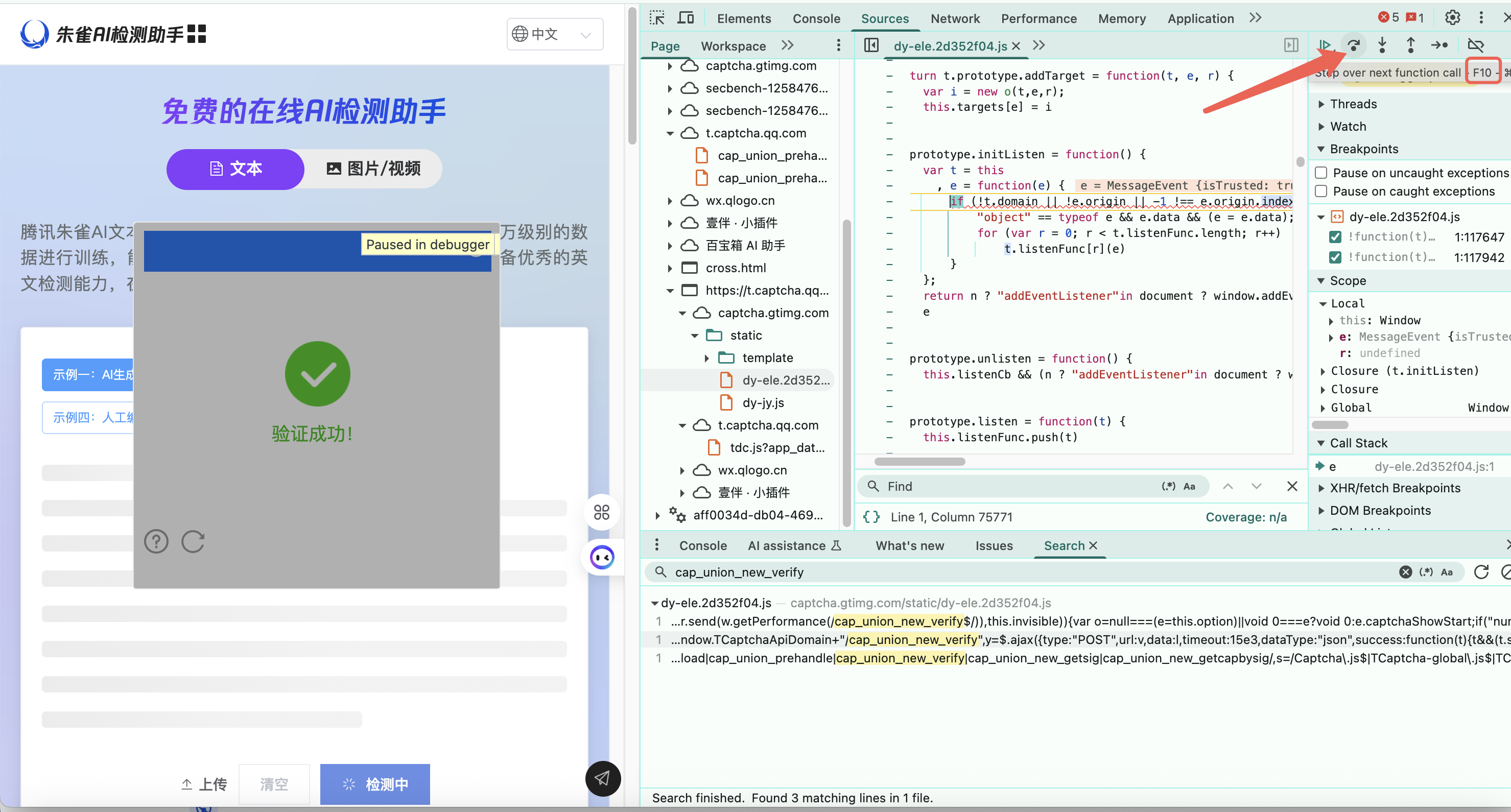
断点进入后,一路点击下一步(快捷键 F10)进行调试,看下整个方法使用到了哪些 JS 文件
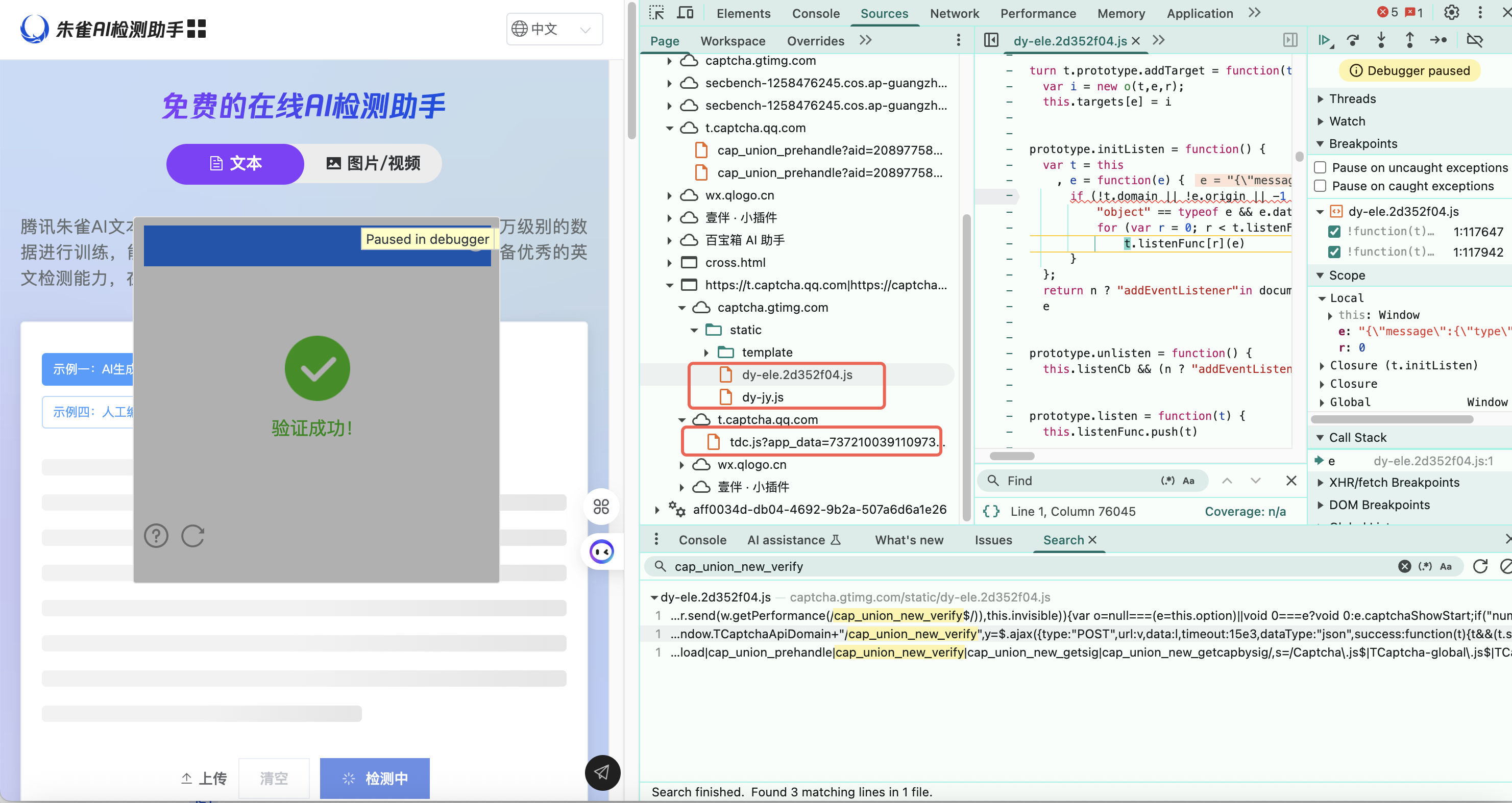
经过调试会发现,整个调用使用了以下三个 JS 文件
3、使用 Cursor 解析 js 文件
把以上三个 js 文件拷贝到 cursor 里面来,使用 claude-4 模型进行分析下(其余简单问题可以用差点模型,这种复杂问题建议都使用 claude-4,博主经过 1 年多 AI 编程实验,目前所有模型还是 claude 的能力最强,国产模型整体效果比较差得加把劲了),可以知道这三个文件的主要作用!
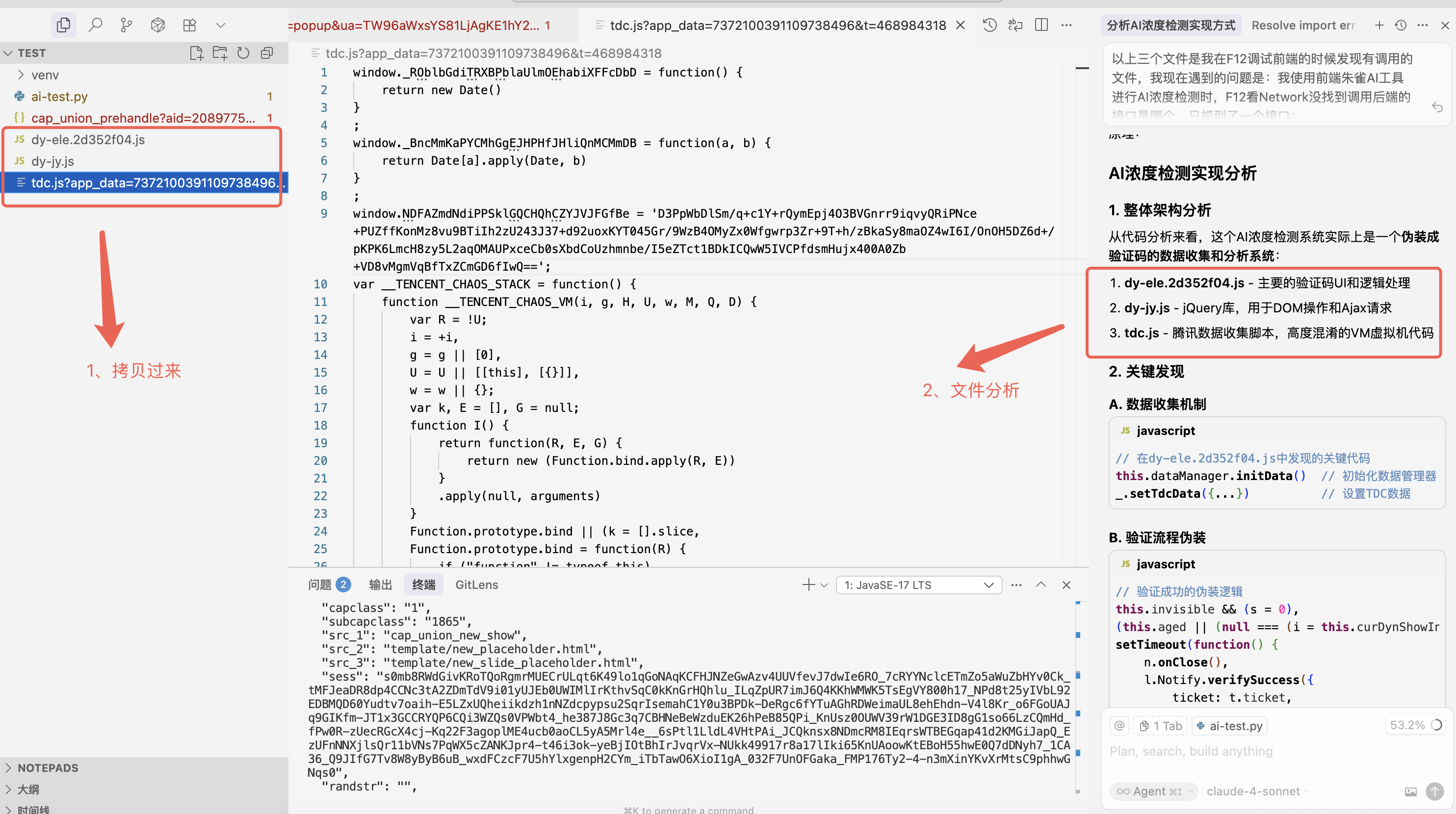
经过分析可以看到,cursor 给出了三种实现 API 接口逆向的方案,并且对整个调用过程做了结论分析
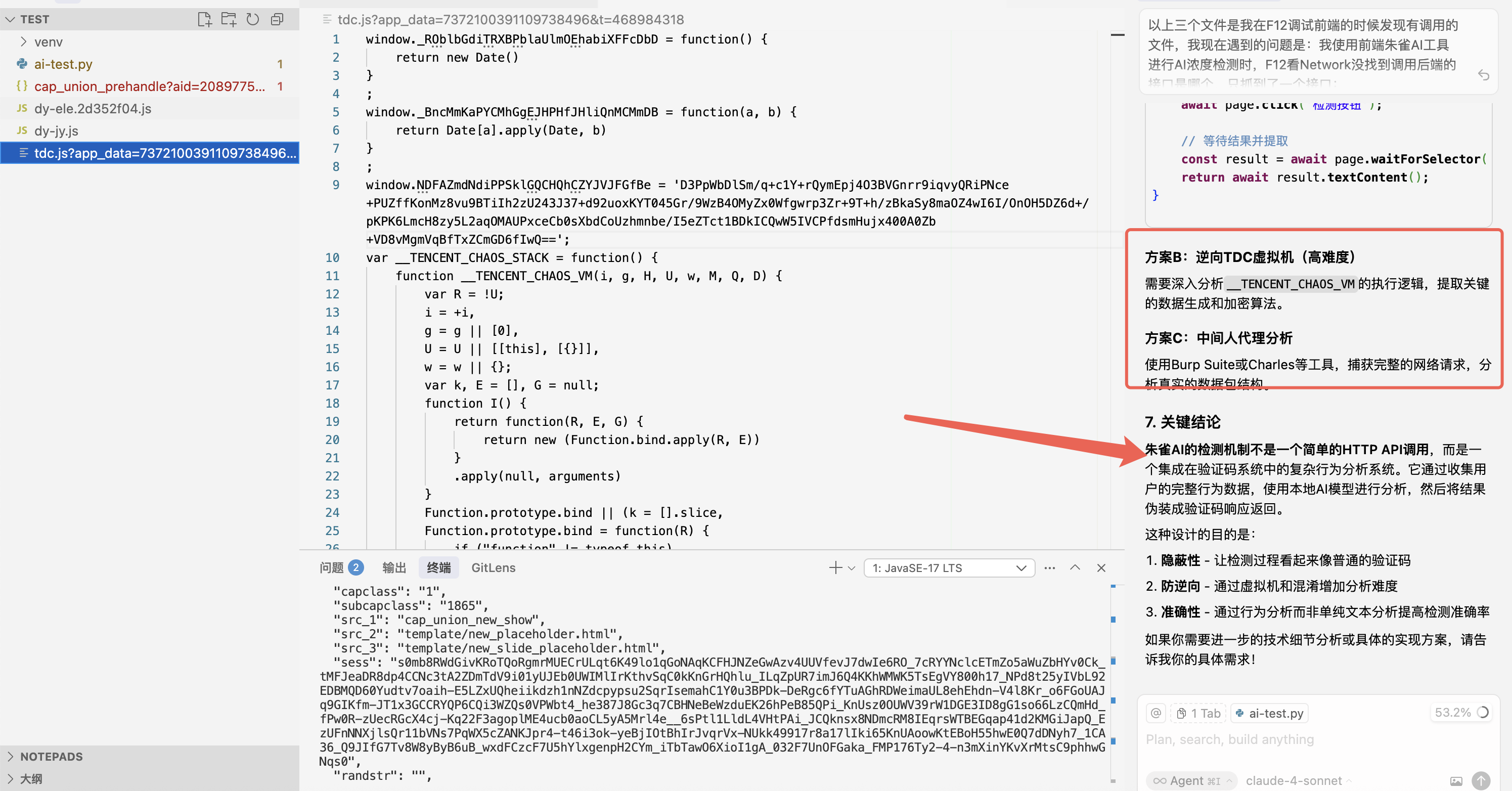
4、使用 Cursor 给出具体代码实现模型调用
接下来,我让 cursor 给我实现逆向的具体代码,它给出了四个方案,这里我选择了方案二,其余的三个方案都是使用前端 js 的,不满足我的要求!
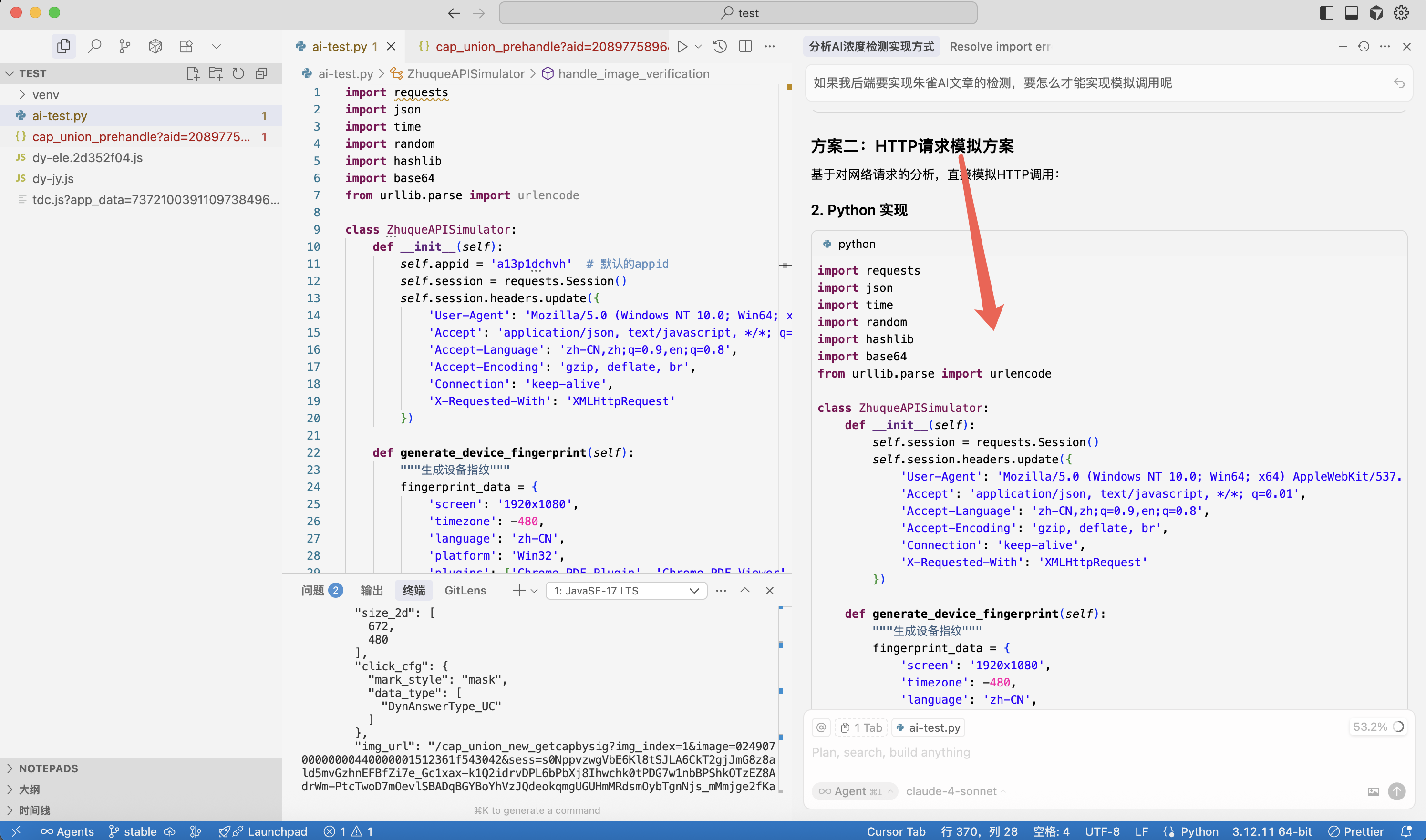
以下是具体的实现代码内容(以下代码仅供参考,具体参数替换成你自己的)
import requests
import json
import time
import random
import hashlib
import base64
from urllib.parse import urlencode
class ZhuqueAPISimulator:
def __init__(self):
self.appid = 'a13p1dchvh' # 替换成你自己的appid
self.session = requests.Session()
self.session.headers.update({
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Accept-Encoding': 'gzip, deflate, br',
'Connection': 'keep-alive',
'X-Requested-With': 'XMLHttpRequest'
})
def generate_device_fingerprint(self):
"""生成设备指纹"""
fingerprint_data = {
'screen': '1920x1080',
'timezone': -480,
'language': 'zh-CN',
'platform': 'Win32',
'plugins': ['Chrome PDF Plugin', 'Chrome PDF Viewer', 'Native Client'],
'canvas': self.generate_canvas_fingerprint(),
'webgl': self.generate_webgl_fingerprint()
}
return base64.b64encode(json.dumps(fingerprint_data).encode()).decode()
def generate_canvas_fingerprint(self):
"""生成Canvas指纹"""
# 模拟Canvas指纹生成
return hashlib.md5(f"canvas_{random.randint(1000, 9999)}".encode()).hexdigest()
def generate_webgl_fingerprint(self):
"""生成WebGL指纹"""
return hashlib.md5(f"webgl_{random.randint(1000, 9999)}".encode()).hexdigest()
def generate_tdc_data(self, text_content, sess=None, sid=None, pow_info=None):
"""生成TDC数据 - 更接近真实格式"""
current_time = int(time.time() * 1000)
# 根据真实TDC数据结构生成
tdc_data = {
# 会话信息
'sess': sess or '',
'sid': sid or '',
'version': '1.0.0',
'timestamp': current_time,
# POW工作量证明
'pow': pow_info or {},
# 用户行为数据
'behaviors': {
'mouse': self.generate_mouse_events(),
'keyboard': self.generate_keyboard_events(text_content),
'scroll': [{'x': 0, 'y': random.randint(0, 500), 'time': current_time - random.randint(1000, 5000)}],
'focus': [{'time': current_time - random.randint(2000, 8000), 'duration': random.randint(1000, 5000)}]
},
# 环境信息
'env': {
'screen': {'w': 1920, 'h': 1080, 'cd': 24},
'ua': self.session.headers['User-Agent'],
'lang': 'zh-CN',
'tz': -480, # 北京时间
'canvas': self.generate_canvas_fingerprint()[:16], # 截短一些
'webgl': self.generate_webgl_fingerprint()[:16]
},
# 性能数据
'perf': self.generate_performance_data(),
# 内容相关
'content_hash': hashlib.md5(text_content.encode()).hexdigest()[:16]
}
# 根据POW信息决定TDC格式
if pow_info:
# 包含POW的完整格式
return json.dumps(tdc_data, separators=(',', ':'), ensure_ascii=False)
else:
# 简化格式
simplified_tdc = f"1,{current_time},{len(text_content)},{sess},{sid}"
return simplified_tdc
def generate_mouse_events(self):
"""生成鼠标事件序列"""
events = []
for i in range(random.randint(10, 30)):
events.append({
'type': 'mousemove',
'x': random.randint(0, 1920),
'y': random.randint(0, 1080),
'timestamp': int(time.time() * 1000) + i * 100
})
return events
def generate_keyboard_events(self, text):
"""生成键盘事件序列"""
events = []
for i, char in enumerate(text):
events.append({
'type': 'keydown',
'key': char,
'timestamp': int(time.time() * 1000) + i * 150
})
return events
def generate_performance_data(self):
"""生成性能数据"""
return {
'loadTime': random.randint(1000, 3000),
'renderTime': random.randint(100, 500),
'memoryUsage': random.randint(50000000, 100000000)
}
def calculate_pow(self, prefix, target_md5, max_iterations=100000):
"""计算工作量证明(POW)"""
import hashlib
for nonce in range(max_iterations):
# 构造待哈希的字符串
test_string = f"{prefix}{nonce}"
# 计算MD5
md5_hash = hashlib.md5(test_string.encode()).hexdigest()
# 检查是否匹配目标MD5(通常只需要匹配前几位)
if md5_hash.startswith(target_md5[:8]): # 匹配前8位
return {
'nonce': nonce,
'hash': md5_hash,
'proof': test_string
}
# 如果没找到,返回一个随机值
return {
'nonce': random.randint(1000, 9999),
'hash': hashlib.md5(f"{prefix}9999".encode()).hexdigest(),
'proof': f"{prefix}9999"
}
def detect_ai_content(self, text, options={}):
"""检测AI内容"""
try:
# 第一步:获取验证码配置
config_url = "https://t.captcha.qq.com/cap_union_prehandle"
config_params = {
'appid': self.appid,
'aid': options.get('aid', ''),
'protocol': 'https',
'accver': '1',
'showtype': '0',
'ua': self.session.headers['User-Agent'],
'noheader': '1',
'fb': '1',
'aged': '0',
'enableAged': '0',
'grayscale': '1',
'clientype': '2',
'cap_cd': '',
'uid': options.get('uid', ''),
'wx_header_info': '',
'subsid': '1',
'callback': 'callback_' + str(int(time.time() * 1000))
}
config_response = self.session.get(config_url, params=config_params)
print("配置响应:", config_response.text[:200] + "..." if len(config_response.text) > 200 else config_response.text)
# 解析配置响应
config_data = self.parse_jsonp_response(config_response.text)
if not config_data:
raise Exception("解析配置响应失败")
print("解析后的配置数据:", json.dumps(config_data, ensure_ascii=False, indent=2))
# 检查是否有必要的字段
if 'sess' not in config_data or 'sid' not in config_data:
raise Exception(f"配置响应缺少必要字段: {list(config_data.keys())}")
sess = config_data['sess']
sid = config_data['sid']
print(f"获取到 sess: {sess[:50]}...")
print(f"获取到 sid: {sid}")
# 第二步:处理POW(工作量证明)
pow_info = None
if 'data' in config_data and 'comm_captcha_cfg' in config_data['data']:
pow_cfg = config_data['data']['comm_captcha_cfg'].get('pow_cfg')
if pow_cfg:
print("检测到POW配置,开始计算工作量证明...")
pow_info = self.calculate_pow(pow_cfg['prefix'], pow_cfg['md5'])
print(f"POW计算结果: {pow_info}")
# 第三步:生成TDC数据(传入sess、sid和POW信息)
tdc_data = self.generate_tdc_data(text, sess, sid, pow_info)
print("生成的TDC数据:", tdc_data[:200] + "..." if len(tdc_data) > 200 else tdc_data)
print(f"生成的TDC数据长度: {len(tdc_data)}")
# 添加延迟模拟真实用户行为
print("等待模拟用户思考时间...")
time.sleep(random.uniform(2, 5))
# 第三步:提交验证请求
verify_url = "https://t.captcha.qq.com/cap_union_new_verify"
# 根据配置数据中的信息调整请求参数
verify_data = {
'appid': self.appid,
'aid': options.get('aid', ''),
'sess': sess,
'sid': sid,
'ticket': '', # 初始为空
'randstr': '', # 初始为空
'uid': options.get('uid', ''),
'cap_cd': tdc_data, # TDC数据
'subsid': '1',
'clientype': '2',
'grayscale': '1',
'protocol': 'https',
'tlg': '1',
'ua': self.session.headers['User-Agent'], # 添加UA
'fp': hashlib.md5(f"{sess}_{sid}_{int(time.time())}".encode()).hexdigest()[:16], # 添加指纹
'callback': 'callback_' + str(int(time.time() * 1000))
}
# 如果有POW信息,添加POW相关参数
if pow_info:
verify_data.update({
'pow_answer': pow_info.get('proof', ''),
'pow_calc_time': random.randint(100, 500) # 模拟计算时间
})
print("验证请求参数:")
for key, value in verify_data.items():
if key == 'cap_cd':
print(f" {key}: {str(value)[:100]}..." if len(str(value)) > 100 else f" {key}: {value}")
else:
print(f" {key}: {value}")
print("发送验证请求...")
verify_response = self.session.post(verify_url, data=verify_data)
print("验证响应:", verify_response.text)
verify_result = self.parse_jsonp_response(verify_response.text)
if verify_result:
print("解析后的验证结果:", json.dumps(verify_result, ensure_ascii=False, indent=2))
else:
print("解析验证响应失败,尝试直接解析JSON...")
try:
verify_result = json.loads(verify_response.text)
print("直接JSON解析成功:", json.dumps(verify_result, ensure_ascii=False, indent=2))
except:
print("JSON解析也失败,响应可能不是标准格式")
verify_result = None
if verify_result and verify_result.get('errorCode') == '0':
return {
'success': True,
'ticket': verify_result.get('ticket', ''),
'randstr': verify_result.get('randstr', ''),
'ai_score': self.extract_ai_score(verify_result),
'raw_response': verify_result
}
elif verify_result and verify_result.get('errorCode') == '202':
print("检测到需要图片验证,尝试1次自动处理...")
# 尝试1次自动图片验证
print("图片验证尝试 1/1...")
image_verify_result = self.handle_image_verification(config_data, sess, sid, verify_result)
if image_verify_result and image_verify_result.get('success'):
return image_verify_result
print("自动验证失败,等待2秒后启动人工处理...")
time.sleep(2)
# 1次自动验证失败,直接启动人工处理
print("🔥 自动图片验证失败,启动人工处理模式...")
manual_result = self.handle_manual_verification(config_data, sess, sid)
if manual_result:
return manual_result
return {
'success': False,
'error': '图片验证处理失败,已尝试1次自动验证 + 人工处理'
}
else:
error_msg = verify_result.get('errMessage', '验证失败') if verify_result else '验证失败'
return {
'success': False,
'error': f"错误码: {verify_result.get('errorCode', 'unknown')}, {error_msg}"
}
except Exception as e:
return {
'success': False,
'error': str(e)
}
def handle_image_verification(self, config_data, sess, sid, verify_result):
"""处理图片验证"""
try:
print("开始处理图片验证...")
# 从配置中获取图片验证信息
dyn_show_info = config_data.get('data', {}).get('dyn_show_info', {})
if not dyn_show_info:
print("未找到图片验证配置")
return None
instruction = dyn_show_info.get('instruction', '')
print(f"验证指令: {instruction}")
# 获取图片区域配置
bg_elem_cfg = dyn_show_info.get('bg_elem_cfg', {})
json_payload = json.loads(dyn_show_info.get('json_payload', '{}'))
select_regions = json_payload.get('select_region_list', [])
print(f"图片区域数量: {len(select_regions)}")
# 改进的智能选择策略:基于验证指令选择合适的区域
if select_regions:
instruction_clean = instruction.lower().replace('"', '').replace('"', '').strip()
print(f"处理后的指令: {instruction_clean}")
# 根据指令内容智能选择区域
selected_ids = []
if '黄色' in instruction or 'yellow' in instruction_clean:
if '盘子' in instruction or 'plate' in instruction_clean:
# 黄色盘子可能在任何位置,选择多个候选
selected_ids = [2, 4, 5] # 中上、左下、中下
else:
selected_ids = [1, 3, 6] # 左上、右上、右下
elif '红色' in instruction or 'red' in instruction_clean:
selected_ids = [1, 2, 4] # 左上、中上、左下
elif '蓝色' in instruction or 'blue' in instruction_clean:
selected_ids = [3, 5, 6] # 右上、中下、右下
elif '绿色' in instruction or 'green' in instruction_clean:
selected_ids = [2, 4, 5] # 中上、左下、中下
else:
# 默认策略:选择分散的区域
selected_ids = [1, 3, 5]
# 随机化选择数量和顺序,模拟真实用户行为
num_selections = random.randint(1, min(3, len(selected_ids)))
selected_ids = random.sample(selected_ids, num_selections)
# 确保选择的ID在有效范围内
valid_ids = [r['id'] for r in select_regions]
selected_ids = [sid for sid in selected_ids if sid in valid_ids]
# 如果没有有效选择,随机选择
if not selected_ids:
selected_ids = [random.choice(valid_ids)]
print(f"智能选择区域: {selected_ids}")
# 获取选中的区域对象
selected_regions = [r for r in select_regions if r['id'] in selected_ids]
# 生成更真实的点击坐标
click_positions = []
for i, region in enumerate(selected_regions):
x_range = region['range']
# 在区域中心附近生成点击点,避免边缘
center_x = (x_range[0] + x_range[2]) // 2
center_y = (x_range[1] + x_range[3]) // 2
# 在中心周围添加小幅随机偏移
offset_x = random.randint(-15, 15)
offset_y = random.randint(-15, 15)
x = max(x_range[0] + 5, min(x_range[2] - 5, center_x + offset_x))
y = max(x_range[1] + 5, min(x_range[3] - 5, center_y + offset_y))
click_positions.append({
'x': x,
'y': y,
'time': int(time.time() * 1000) + i * random.randint(200, 500)
})
# 模拟真实用户的思考和点击延迟
time.sleep(random.uniform(0.5, 2.0))
# 提交图片验证结果
return self.submit_image_verification(sess, sid, selected_ids, click_positions, config_data)
else:
print("未找到可选择的图片区域")
return None
except Exception as e:
print(f"图片验证处理异常: {e}")
return None
def handle_manual_verification(self, config_data, sess, sid):
"""启动人工验证处理"""
try:
import webbrowser
import tempfile
import os
print("=" * 60)
print("🎯 启动人工图片验证模式")
print("=" * 60)
# 从配置中获取图片验证信息
dyn_show_info = config_data.get('data', {}).get('dyn_show_info', {})
if not dyn_show_info:
print("❌ 未找到图片验证配置")
return None
instruction = dyn_show_info.get('instruction', '')
bg_elem_cfg = dyn_show_info.get('bg_elem_cfg', {})
img_url = bg_elem_cfg.get('img_url', '')
json_payload = json.loads(dyn_show_info.get('json_payload', '{}'))
select_regions = json_payload.get('select_region_list', [])
print(f"📋 验证指令: {instruction}")
print(f"🖼️ 图片区域数量: {len(select_regions)}")
# 生成HTML页面
html_content = self.generate_verification_html(
instruction, img_url, select_regions, sess, sid
)
# 创建临时HTML文件
with tempfile.NamedTemporaryFile(mode='w', suffix='.html', delete=False, encoding='utf-8') as f:
f.write(html_content)
html_file = f.name
print(f"🌐 已生成验证页面: {html_file}")
print("📱 正在打开浏览器...")
# 打开浏览器
webbrowser.open('file://' + html_file)
# 等待浏览器加载
print("⏳ 等待浏览器加载页面...")
time.sleep(3)
# 等待用户完成验证
print("\n" + "="*50)
print("👆 请在浏览器中完成图片验证:")
print(f" 1. 根据指令 '{instruction}' 选择正确的图片")
print(" 2. 点击选择完成后,页面会显示选择结果")
print(" 3. 复制显示的答案(如:1,3,5)")
print("="*50)
# 额外等待用户操作
print("\n⏰ 请完成验证后再继续...")
time.sleep(2)
# 获取用户输入 - 强化版本
import sys
import os
user_answer = ""
print("\n" + "="*60)
print("🔤 请输入你选择的区域ID(用逗号分隔,如:1,3,5)")
print("📝 输入完成后请按回车键确认")
print("="*60)
# 检查是否在交互式环境中
print(f"🔍 环境检查:")
print(f" - stdin.isatty(): {sys.stdin.isatty()}")
print(f" - stdout.isatty(): {sys.stdout.isatty()}")
print(f" - 运行环境: {os.environ.get('TERM', 'unknown')}")
if not sys.stdin.isatty():
print("⚠️ 检测到非交互式环境,这可能导致输入问题")
# 多种方法尝试获取输入
max_attempts = 5
for attempt in range(max_attempts):
try:
print(f"\n🔤 请输入答案 (尝试 {attempt + 1}/{max_attempts}): ", end="", flush=True)
# 强制刷新所有缓冲区
sys.stdout.flush()
sys.stderr.flush()
# 等待一小段时间让终端准备好
time.sleep(0.1)
# 尝试不同的输入方法
if attempt == 0:
# 方法1: 标准input()
user_answer = input().strip()
elif attempt == 1:
# 方法2: sys.stdin.readline()
print("(请输入并按回车)")
user_answer = sys.stdin.readline().strip()
elif attempt == 2:
# 方法3: 使用os.read()
print("(请输入并按回车)")
import select
if select.select([sys.stdin], [], [], 30): # 30秒超时
user_answer = sys.stdin.readline().strip()
else:
print("\n⏰ 输入超时")
continue
else:
# 方法4: 最后尝试原始input
print("\n请直接输入答案: ", end="", flush=True)
user_answer = input().strip()
# 检查是否获得有效输入
if user_answer:
print(f"✅ 成功接收到输入: '{user_answer}'")
break
else:
print(f"❌ 第{attempt + 1}次尝试:未检测到输入")
if attempt < max_attempts - 1:
print("🔄 正在重试...")
time.sleep(1)
except EOFError:
print(f"\n❌ 第{attempt + 1}次尝试:输入流结束")
if attempt < max_attempts - 1:
time.sleep(1)
continue
else:
break
except KeyboardInterrupt:
print("\n❌ 用户中断操作")
return None
except Exception as e:
print(f"\n❌ 第{attempt + 1}次尝试失败: {e}")
if attempt < max_attempts - 1:
time.sleep(1)
continue
if not user_answer:
print("❌ 未输入答案,人工验证取消")
return None
# 解析用户答案
try:
selected_ids = [int(x.strip()) for x in user_answer.split(',') if x.strip()]
if not selected_ids:
print("❌ 答案格式错误")
return None
print(f"✅ 收到答案: {selected_ids}")
# 提交验证
result = self.submit_manual_verification(sess, sid, selected_ids, select_regions)
# 清理临时文件
try:
os.unlink(html_file)
except:
pass
return result
except ValueError:
print("❌ 答案格式错误,请输入数字")
return None
except Exception as e:
print(f"人工验证处理异常: {e}")
return None
def generate_verification_html(self, instruction, img_url, select_regions, sess, sid):
"""生成验证HTML页面"""
# 构造完整的图片URL
if img_url.startswith('/'):
full_img_url = f"https://t.captcha.qq.com{img_url}"
else:
full_img_url = img_url
html = f"""
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>朱雀AI图片验证 - 人工处理</title>
<style>
body {{
font-family: Arial, sans-serif;
margin: 20px;
background-color: #f5f5f5;
}}
.container {{
max-width: 800px;
margin: 0 auto;
background: white;
padding: 20px;
border-radius: 8px;
box-shadow: 0 2px 10px rgba(0,0,0,0.1);
}}
.header {{
text-align: center;
margin-bottom: 20px;
}}
.instruction {{
font-size: 18px;
font-weight: bold;
color: #333;
margin-bottom: 15px;
padding: 10px;
background-color: #e3f2fd;
border-radius: 5px;
text-align: center;
}}
.image-container {{
position: relative;
display: inline-block;
margin: 20px auto;
border: 2px solid #ddd;
border-radius: 5px;
}}
.captcha-image {{
display: block;
max-width: 100%;
height: auto;
}}
.region {{
position: absolute;
border: 2px solid transparent;
cursor: pointer;
transition: all 0.2s;
}}
.region:hover {{
border-color: #2196F3;
background-color: rgba(33, 150, 243, 0.1);
}}
.region.selected {{
border-color: #4CAF50;
background-color: rgba(76, 175, 80, 0.2);
}}
.region-label {{
position: absolute;
top: 5px;
left: 5px;
background: rgba(0,0,0,0.7);
color: white;
padding: 2px 6px;
border-radius: 3px;
font-size: 12px;
font-weight: bold;
}}
.controls {{
text-align: center;
margin-top: 20px;
}}
.result {{
margin-top: 15px;
padding: 10px;
background-color: #f0f8ff;
border-radius: 5px;
font-family: monospace;
font-size: 16px;
font-weight: bold;
}}
.info {{
margin-top: 10px;
padding: 10px;
background-color: #fff3cd;
border-radius: 5px;
font-size: 14px;
color: #856404;
}}
button {{
background-color: #2196F3;
color: white;
padding: 10px 20px;
border: none;
border-radius: 5px;
cursor: pointer;
font-size: 16px;
margin: 5px;
}}
button:hover {{
background-color: #1976D2;
}}
.reset-btn {{
background-color: #f44336;
}}
.reset-btn:hover {{
background-color: #d32f2f;
}}
</style>
</head>
<body>
<div class="container">
<div class="header">
<h1>🎯 朱雀AI图片验证 - 人工处理</h1>
</div>
<div class="instruction">
验证指令: {instruction}
</div>
<div style="text-align: center;">
<div class="image-container">
<img src="{full_img_url}" class="captcha-image" onload="initRegions()" />
"""
# 添加区域定义
for region in select_regions:
region_id = region['id']
x1, y1, x2, y2 = region['range']
width = x2 - x1
height = y2 - y1
html += f"""
<div class="region"
data-id="{region_id}"
style="left: {x1}px; top: {y1}px; width: {width}px; height: {height}px;"
onclick="toggleRegion(this)">
<div class="region-label">{region_id}</div>
</div>
"""
html += f"""
</div>
</div>
<div class="controls">
<button onclick="getSelectedRegions()">获取选择结果</button>
<button class="reset-btn" onclick="resetSelection()">重置选择</button>
</div>
<div id="result" class="result" style="display: none;"></div>
<div class="info">
<strong>使用说明:</strong><br>
1. 根据上方指令,点击选择符合描述的图片区域<br>
2. 选中的区域会显示绿色边框<br>
3. 点击"获取选择结果"按钮查看答案<br>
4. 将答案复制到终端程序中
</div>
</div>
<script>
let selectedRegions = new Set();
function toggleRegion(element) {{
const regionId = parseInt(element.dataset.id);
if (selectedRegions.has(regionId)) {{
selectedRegions.delete(regionId);
element.classList.remove('selected');
}} else {{
selectedRegions.add(regionId);
element.classList.add('selected');
}}
}}
function getSelectedRegions() {{
const result = Array.from(selectedRegions).sort((a, b) => a - b);
const resultDiv = document.getElementById('result');
if (result.length === 0) {{
resultDiv.innerHTML = '<span style="color: red;">❌ 请先选择图片区域</span>';
}} else {{
resultDiv.innerHTML = `
<div style="color: green;">✅ 选择的区域ID: <strong>${{result.join(',')}}</strong></div>
<div style="margin-top: 10px; font-size: 14px;">
请复制上方答案到终端程序中
</div>
`;
}}
resultDiv.style.display = 'block';
}}
function resetSelection() {{
selectedRegions.clear();
document.querySelectorAll('.region').forEach(region => {{
region.classList.remove('selected');
}});
document.getElementById('result').style.display = 'none';
}}
function initRegions() {{
console.log('图片加载完成,区域已初始化');
}}
</script>
</body>
</html>
"""
return html
def submit_manual_verification(self, sess, sid, selected_ids, select_regions):
"""提交人工验证结果"""
try:
print(f"🚀 提交人工验证结果: {selected_ids}")
# 生成点击坐标
click_positions = []
selected_regions = [r for r in select_regions if r['id'] in selected_ids]
for region in selected_regions:
x_range = region['range']
center_x = (x_range[0] + x_range[2]) // 2
center_y = (x_range[1] + x_range[3]) // 2
# 添加小幅随机偏移
offset_x = random.randint(-10, 10)
offset_y = random.randint(-10, 10)
click_positions.append({
'x': center_x + offset_x,
'y': center_y + offset_y,
'time': int(time.time() * 1000) + random.randint(100, 500)
})
# 构造验证数据
current_time = int(time.time() * 1000)
verify_data = {
'appid': self.appid,
'sess': sess,
'sid': sid,
'ans': ','.join(map(str, selected_ids)),
'pos': json.dumps([{'x': pos['x'], 'y': pos['y']} for pos in click_positions]),
'clientype': '2',
'grayscale': '1',
'protocol': 'https',
'tlg': '1',
'ua': self.session.headers.get('User-Agent', ''),
'fp': hashlib.md5(f"{sess}_{sid}_{current_time}".encode()).hexdigest()[:16],
'callback': 'callback_' + str(current_time)
}
# 提交验证
verify_url = "https://t.captcha.qq.com/cap_union_new_verify"
response = self.session.post(verify_url, data=verify_data)
print(f"人工验证响应: {response.text[:200]}...")
# 解析响应
result = self.parse_jsonp_response(response.text)
if not result:
try:
result = json.loads(response.text)
except:
result = None
if result and result.get('errorCode') == '0':
print("🎉 人工验证成功!")
return {
'success': True,
'ticket': result.get('ticket', ''),
'randstr': result.get('randstr', ''),
'ai_score': self.extract_ai_score(result),
'raw_response': result,
'verification_method': 'manual'
}
else:
error_code = result.get('errorCode', 'unknown') if result else 'unknown'
print(f"❌ 人工验证失败,错误码: {error_code}")
return None
except Exception as e:
print(f"提交人工验证异常: {e}")
return None
def submit_image_verification(self, sess, sid, selected_ids, click_positions, config_data):
"""提交图片验证结果"""
try:
verify_url = "https://t.captcha.qq.com/cap_union_new_verify"
# 构造验证数据 - 使用更符合真实请求的格式
current_time = int(time.time() * 1000)
verify_data = {
'appid': self.appid,
'sess': sess,
'sid': sid,
'ans': ','.join(map(str, selected_ids)), # 选中的区域ID
'pos': json.dumps([{'x': pos['x'], 'y': pos['y']} for pos in click_positions]), # 简化点击位置
'clientype': '2',
'grayscale': '1',
'protocol': 'https',
'tlg': '1',
'ua': self.session.headers.get('User-Agent', ''),
'fp': hashlib.md5(f"{sess}_{sid}_{current_time}".encode()).hexdigest()[:16],
'callback': f'callback_{current_time}'
}
print("提交图片验证...")
print(f"选择答案: {verify_data['ans']}")
response = self.session.post(verify_url, data=verify_data)
print("图片验证响应:", response.text)
result = self.parse_jsonp_response(response.text)
if not result:
try:
result = json.loads(response.text)
except:
return None
if result and result.get('errorCode') == '0':
return {
'success': True,
'ticket': result.get('ticket', ''),
'randstr': result.get('randstr', ''),
'ai_score': self.extract_ai_score(result),
'raw_response': result,
'verification_type': 'image_click'
}
else:
print(f"图片验证失败: {result}")
return None
except Exception as e:
print(f"提交图片验证异常: {e}")
return None
def parse_jsonp_response(self, response_text):
"""解析JSONP响应"""
try:
# 移除JSONP包装
start = response_text.find('(') + 1
end = response_text.rfind(')')
json_str = response_text[start:end]
return json.loads(json_str)
except:
return None
def extract_ai_score(self, response_data):
"""从响应中提取AI分数"""
# 根据实际响应格式提取AI分数
# 这里需要根据真实的响应结构进行调整
return response_data.get('ai_score', 0)
# 使用示例
def main():
detector = ZhuqueAPISimulator()
result = detector.detect_ai_content(
text="这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...这是一段需要检测的文章内容...",
options={
'aid': '',
'uid': 'user_123'
}
)
print("检测结果:", json.dumps(result, ensure_ascii=False, indent=2))
if __name__ == "__main__":
main()
这里有个 appid,需要替换成你自己的
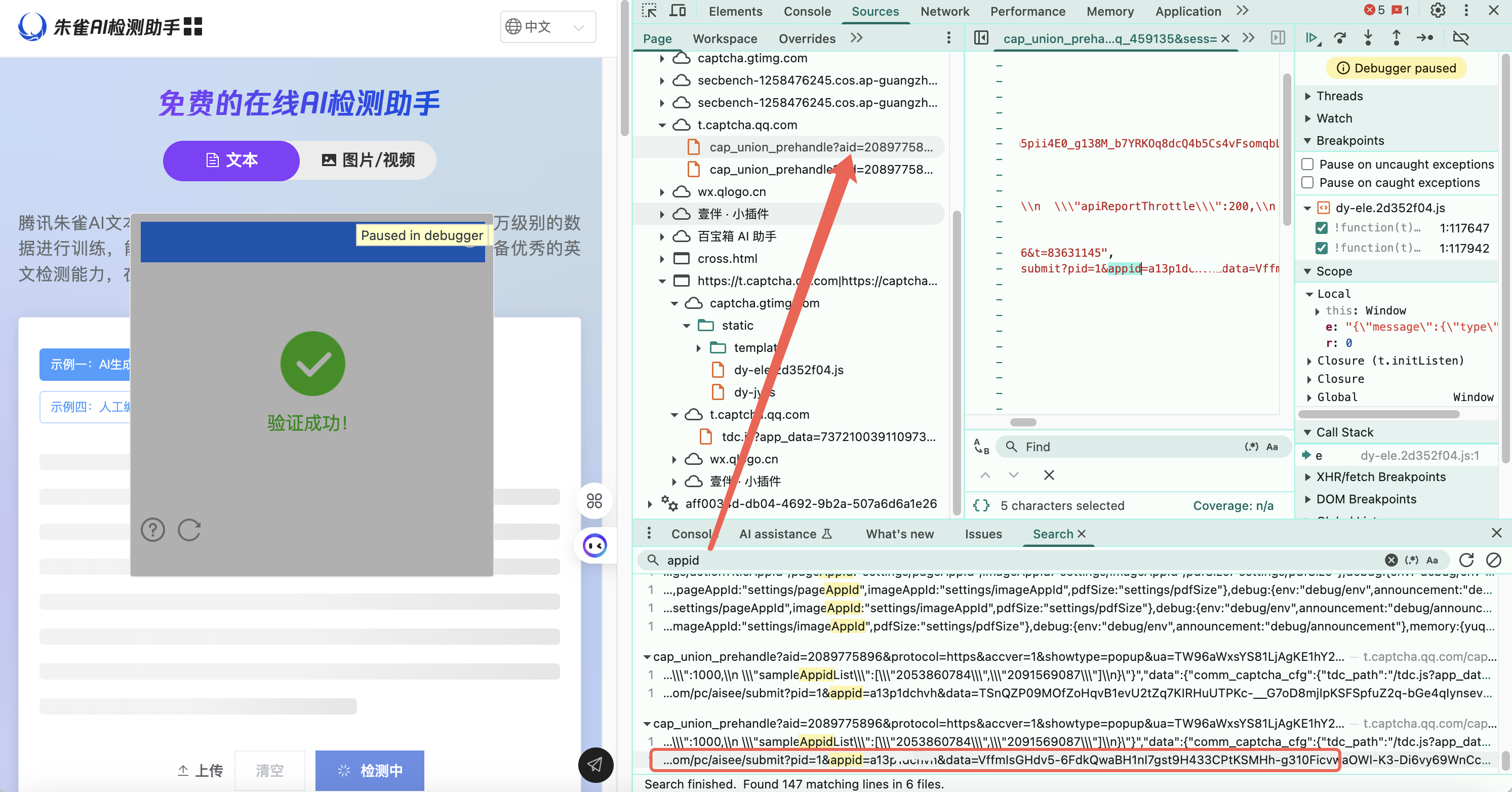
5、调试优化 python 代码接口
接下来,就是对调用接口返回的参数进行调用调试了,博主经过多轮调试改造,最终成功的获取到了相关接口响应。
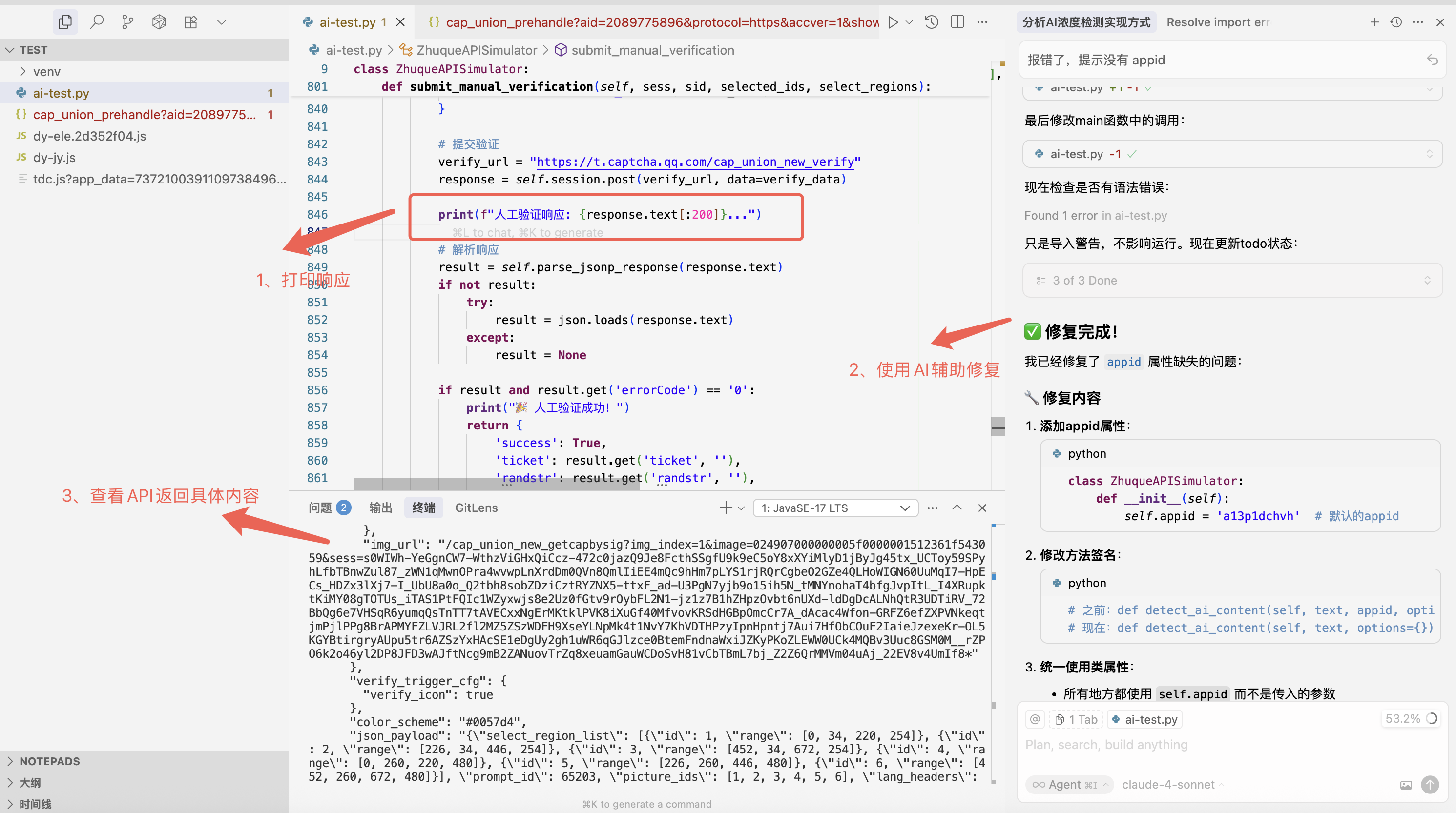
然后把这个接口再使用 FastAPI 封装下,就能形成个公共 API 接口了!
总结
本文详细讲解了如何对一个做了前端加密和代码混淆的 API 接口做逆向处理,在以前想要实现这种功能必须是一些专家级别才可能搞定,随着 AI 时代的到来,借助 AI 工具我们便能轻松完成这类逆向工程操作!所以,AI 确实已经改变了很多编程方式,只有尽早的拥抱变化去学习新的 AI 知识才能适应新的 AI 时代!
关注我,接下来的内容我将花一个月时间,带大家从生成式 AI 入门到 Agent 高级功能详解,带大家了解下如何正确的使用 AI 完成复杂任务及设计,以及 Agent 的各种应用场景!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 14
14 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)