主流 vGPU 技术方案
vGPU 技术方案各有千秋,你的选择很大程度上取决于应用场景:追求稳定、安全且预算充足的虚拟化环境,可考虑 NVIDIA vGPU 或 AMD MxGPU。主要在 Kubernetes 中部署 AI 应用,希望提升 GPU 利用率并实现细粒度共享,开源方案 HAMi 是一个值得尝试的选择。对于临时、简单的测试环境,NVIDIA MPS 可以快速上手,但要小心其稳定性问题。希望这些信息能帮助你做出更
·
主流 vGPU 技术方案的对比,方便你快速了解:
| 方案名称 | 核心原理 | 优势 | 局限 | 典型场景 |
|---|---|---|---|---|
| NVIDIA vGPU | 基于SR-IOV的硬件虚拟化,时间分片和显存隔离 | 性能隔离性较好,支持CUDA生态 | 需特定硬件和License,配置不灵活 | 虚拟桌面基础设施(VDI), AI计算 |
| NVIDIA MPS | 软件层面的算力共享(CUDA Stream) | 配置灵活,与Docker适配良好 | 缺乏隔离,MPS故障影响所有共享进程 | 容器化AI推理 |
| AMD MxGPU | 基于 SR-IOV 的硬件虚拟化(每个vGPU是一个VF) | 硬件级隔离,性能更稳定,安全性好 | 切分配置限制较多(如必须为偶数) | 图形工作站,虚拟化环境 |
| 开源软件方案 (如 HAMi) | CUDA API拦截与重写(如通过libvgpu.so),实现资源限制 |
细粒度切分(可精确控制显存和算力百分比),K8s原生集成 | 存在性能开销(~5-10%),软件隔离性非绝对可靠 | Kubernetes环境下的AI训练与推理 |
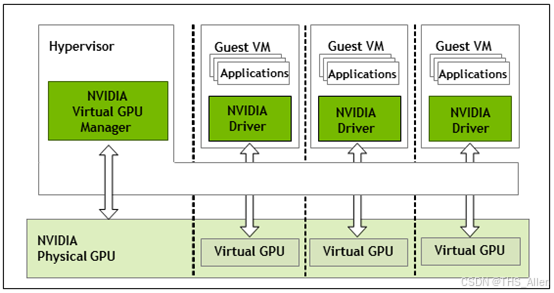
方案详解与选型考虑
1. NVIDIA vGPU (软件方案)
NVIDIA 的 vGPU 方案基于 SR-IOV 技术,在驱动层进行时间分片和显存隔离。
- 工作原理:vGPU Manager 在 Hypervisor 层进行调度,将物理 GPU 的计算核心通过时间分片共享给多个虚拟机,但显存、PCIe 带宽等资源是独占分配的。
- 授权(License):需要额外的许可证服务器(License Server)来激活和管理 vGPU 功能。
- 适用场景:更适合传统的虚拟桌面(VDI) 和需要强隔离性的虚拟化环境。
2. NVIDIA MPS (Multi-Process Service)
MPS 是一种算力共享的软件方案,允许多个 CUDA 进程共享 GPU 的计算引擎。
- 工作原理:基于 C/S 架构,所有共享 GPU 的进程将其 CUDA Kernel 发送给一个共同的 MPS Server,由该 Server 统一提交给 GPU 硬件执行,从而实现计算资源的复用。
- 主要问题:缺乏显存和错误隔离。一旦 MPS Server 出现问题,所有共享该 GPU 的进程都会受到影响,通常需要重置 GPU 才能恢复。
3. AMD MxGPU (硬件方案)
AMD 的 MxGPU 是基于 SR-IOV 标准的硬件虚拟化方案。
- 工作原理:物理 GPU(PF)被硬件切分为多个虚拟功能(VF),每个 VF 可以直接通过 IOMMU 分配给一个虚拟机,接近原生性能,且虚拟机间隔离性更好。
- 优势与限制:无需软件授权,但硬件切分策略相对固定(例如早期型号要求单卡切分的桌面数必须是偶数)。
4. 开源软件方案 (如 HAMi)
这类方案通过在容器层面拦截 CUDA API 调用,模拟出多个虚拟 GPU 设备。
- 工作原理:以 HAMi 为例,它通过一个自定义的
libvgpu.so库文件(通过LD_PRELOAD机制注入容器),拦截并重写如cuMemAlloc,cuLaunchKernel等 CUDA API 调用。- 显存限制:当容器内应用申请的显存超过其配额时,直接返回“OOM”错误。
- 算力限制:通常采用令牌桶等算法来限制 GPU SM 的算力使用百分比。
- K8s集成:提供专用的 Device Plugin 和调度器(Scheduler),能在 K8s 中上报虚拟 GPU 资源,并支持精细的调度策略(如 Binpack/Spread)。
- 性能损耗:API 拦截和资源管理的开销会引入一定的性能损耗,通常估计在 5%-10% 左右。
如何选择 vGPU 方案
选择哪种 vGPU 方案,取决于你的具体需求和环境:
-
虚拟化环境(VDI) vs. 容器化环境(AI/ML):
- 如果需要为虚拟机提供图形工作站或虚拟桌面,NVIDIA vGPU 或 AMD MxGPU 这类硬件虚拟化方案更合适。
- 如果主要在 Kubernetes 环境中运行 AI 训练或推理任务,开源的 HAMi 等方案与 K8s 生态集成更深,支持更细粒度的共享和调度。
-
隔离性要求:
- 对安全性和稳定性要求极高,需要避免邻居应用干扰,硬件虚拟化方案(如 AMD MxGPU)提供的隔离性更强。
- 如果是在可控的内部环境中运行同类负载,对轻微干扰不敏感,软件方案(如 MPS 或 HAMi)的灵活性更有优势。
-
成本考量:
- NVIDIA vGPU 需要购买额外的许可证,硬件也需要特定型号,总体拥有成本较高。
- 开源方案(如 HAMi)无软件许可费用,但需要自行部署和维护,并承担一定的性能损耗风险。
-
功能与粒度:
- 需要极其精细的算力和显存控制(如 1% 级别),开源软件方案是目前唯一的选择。
- 如果只需要简单的时分复用,NVIDIA MPS 或许能满足需求,但要承受其隔离性差的风险。
总结与建议
vGPU 技术方案各有千秋,你的选择很大程度上取决于应用场景:
- 追求稳定、安全且预算充足的虚拟化环境,可考虑 NVIDIA vGPU 或 AMD MxGPU。
- 主要在 Kubernetes 中部署 AI 应用,希望提升 GPU 利用率并实现细粒度共享,开源方案 HAMi 是一个值得尝试的选择。
- 对于临时、简单的测试环境,NVIDIA MPS 可以快速上手,但要小心其稳定性问题。
希望这些信息能帮助你做出更合适的技术选型。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 16
16 0
0- 0



 已为社区贡献51条内容
已为社区贡献51条内容

所有评论(0)