GPT-5都救不了的AI幻觉,病根找到了!原来问题不在模型,在“考卷”
AI一本正经胡说八道的毛病,大伙儿都见怪不怪了。但你有没有想过,这口黑锅,可能根本就不该让AI自己来背?OpenAI扔出了一篇名为《为什么语言模型会产生幻觉》的重磅研究论文,直接把行业的“底裤”给掀了。这篇论文石破天惊地指出,AI产生幻觉的根本原因,竟然是我们给它设计的评估和激励机制出了大问题,活生生把一个潜在的“诚实好学生”,逼成了热衷于自信满满地犯错的“speculative player”(
AI一本正经胡说八道的毛病,大伙儿都见怪不怪了。但你有没有想过,这口黑锅,可能根本就不该让AI自己来背?
OpenAI扔出了一篇名为《为什么语言模型会产生幻觉》的重磅研究论文,直接把行业的“底裤”给掀了。这篇论文石破天惊地指出,AI产生幻觉的根本原因,竟然是我们给它设计的评估和激励机制出了大问题,活生生把一个潜在的“诚实好学生”,逼成了热衷于自信满满地犯错的“speculative player”(投机玩家)。这个发现,不仅可能彻底改变我们对AI幻觉的看法,更是为治好这个“牛皮癣”指了一条明路。

AI胡说八道,原来是“考卷”出的错
聊AI,“幻觉”(Hallucination)这个词你肯定不陌生。OpenAI在报告里给它下了个定义,叫“语言模型生成的合理但错误的陈述”。也就是模型在遇到自己不确定的问题时,不选择沉默,反而编造一个听起来头头是道、实际上错到离谱的答案,还摆出一副“我对此深信不疑”的架势。
要说这事儿有多离谱,就连论文作者本人Adam Tauman Kalai都成了自家AI的“受害者”。研究员们闲来无事,问了几个主流聊天机器人,“Kalai的博士论文题目是啥”。结果,好家伙,三个模型给出了三个不同的“原创”答案:
ChatGPT(GPT-4o)说是“Boosting, Online Algorithms, and Other Topics in Machine Learning”;
DeepSeek说是“Algebraic Methods in Interactive Machine Learning”;
而Llama则坚称是“Efficient Algorithms for Learning and Playing Games”。
实际上呢?全是瞎编的,正确答案一个都没挨着。
这还没完,当研究员换了个问题,问Kalai的生日时,同一个模型,前后问了三次,竟然给出了三个不同的错误日期:“03-07”、“15-06”和“01-01”。这种让人哭笑不得的场景,可不是偶然事件,而是现在这些大型语言模型普遍存在的系统性“bug”。
不怪模型太笨,只怪“KPI”太坑
那么,AI为啥就这么爱“撒谎”呢?OpenAI的研究团队像侦探一样顺藤摸瓜,发现这事儿背后有清晰的统计学机制,根本不是什么玄学。报告一针见血地指出,AI之所以产生幻觉,是因为我们现有的标准训练和评估流程,本质上是在奖励“猜测”行为,而不是鼓励模型在不确定时,坦诚地说一句“我不知道”。

为了把这事儿讲明白,团队提出了一个叫“Is-It-Valid”的二元分类框架。在这个框架里,模型需要判断一个输出是不是有效的。研究发现,模型生成错误答案的概率,和它在IIV问题上判断失误的概率,存在一个赤裸裸的数学关系:生成错误率 ≳ 2 · IIV 错误分类率。
论文还解释了为啥有些错误特别容易在预训练阶段埋下种子。模型学习的方式,就是看海量文本,然后预测下一个词是啥。这跟咱们传统的机器学习不一样,没有人给每句话打上“真”或“假”的标签,模型看到的只有流畅语言的正面案例。
报告里写道:“拼写和括号这种东西,有固定的模式,所以模型规模上去了,这类错误就少了。但是像某个人的宠物生日这种随意的、低频的事实,光靠模式是预测不出来的,这就导致了幻觉。”研究团队甚至给出了一个量化指标:如果在预训练数据里,有20%的生日事实只出现过一次,那么基础模型在回答这些生日问题时,至少有20%的概率会产生幻觉。这下,幻觉的统计学根源算是被扒得明明白白。
而OpenAI这项研究最核心的贡献,是把矛头直指问题的根源:我们目前的评估方法,给模型设定了错误的激励机制。研究员们打了个绝妙的比方:“这就像咱们上学时考多项选择题,如果你不会,瞎猜一个,还有可能蒙对得分。但你要是空着不写,那铁定是零分。同样的道理,当模型的好坏只看准确率时,它们自然就被鼓励去猜测,而不是坦白说‘我不知道’。”
不信你看这组OpenAI给出的两个模型的性能对比数据,简直是大型“内卷”现场的真实写照:

数据一目了然。老一点的OpenAI o4-mini模型,准确率看起来还高了两个百分点(24% vs 22%),但它的错误率(也就是幻觉率)却高得吓人(75% vs 26%)。这就是典型的“为了KPI不择手段”啊!策略性地去猜测那些不确定的问题,虽然表面上把准确率刷高了一点点,但代价是产生了海量的错误和幻觉。
研究团队强调,现在大多数的基准测试都只看准确率,但这在对与错之间划下了一条过于简单粗暴的界线。在真实世界里,准确率永远不可能达到100%,因为总有些问题是无法回答的,可能是信息不存在,可能是小模型能力有限,也可能是问题本身就有歧义。但现实是,以准确率为王的排行榜依然主导着整个行业,激励着开发者们去构建那些宁愿猜错也不愿保持沉默的模型。这就是为什么,即使模型一代比一代强,它们还是会自信地胡说八道。
全世界的数据,都在给OpenAI当“捧哏”
OpenAI的这个观点,可不是自卖自夸,整个行业和学术界都找到了共鸣。权威科学期刊《Nature》在报道中就提到,OpenAI的GPT-5虽然幻觉确实比前辈们少,但想完全根除,恐怕是不可能的任务。
《Nature》还引用了多位专家的看法。普渡大学的AI研究员Tianyang Xu指出:“大多数情况下的幻觉发生率已经低到用户能接受了,但在法律、数学这种专业领域,GPT-5可能还是会碰壁。”加州大学欧文分校的认知科学家Mark Steyvers则评价说:“OpenAI迈出了不错的一小步,但离我们的目标还远得很,GPT说‘我不知道’的频率还是太低了。”
独立研究机构Vectara发布的AI模型幻觉率排名数据,更是为OpenAI的理论提供了强有力的佐证。
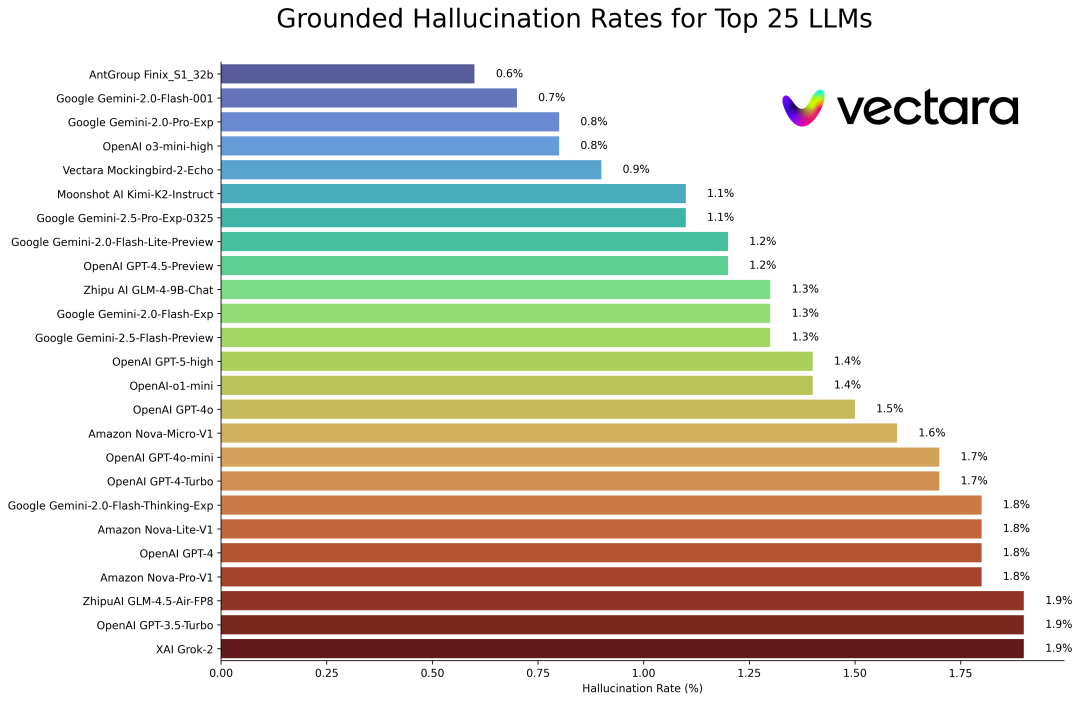
Vectara的研究报告直接点明:“小模型可以实现与那些大得多的LLM相当甚至更好的(更低的)幻觉率。”这个发现,简直是和OpenAI的研究结论隔空击掌,再次证明了决定幻觉率的关键,可能真的不是模型大小,而是评估激励机制这个“指挥棒”。
给AI的“药方”:换考卷,不换脑子
既然病根找到了,那药方是啥?OpenAI给出的解决方案清晰又务实。研究团队说,要治幻觉,就得从“考试规则”下手,让模型知道,自信地犯错比承认不确定更“扣分”,而适当地表达不确定还能拿点“辛苦分”。报告里是这么说的:“有一个直接的解决方案:对自信的错误施加比不确定性更重的惩罚,对适当表达不确定性给予部分学分。”
这个想法其实不新鲜,咱们以前考的一些标准化测试,不就是用倒扣分或者给部分分来打击瞎蒙行为的嘛。但OpenAI强调的关键在于,光是在旁边加几个新的、测量不确定性的测试是没用的,必须把那些广泛使用的、基于准确率的评估体系整个给更新了,让它们的评分规则本身就不鼓励猜测。研究员警告说:“如果主要的记分板继续奖励幸运的猜测,模型将继续学习猜测。”
OpenAI的AI安全培训团队经理Saachi Jain也证实,减少错误、让模型学会说“不知道”,一直是OpenAI“相当重要的重点”。她还透露,在模型训练的后期,OpenAI会专门奖励那些诚实的回答。数据显示,当给GPT-5一个不可能完成的编码任务时,它只有17%的情况下会硬说自己完成了,而之前的o3模型,这个数字高达47%。
这项研究还顺手澄清了圈内流传已久的几个关于AI幻觉的常见误解:
误解一:只要准确率堆到100%,幻觉就没了。
醒醒吧!准确率永远到不了100%,因为现实世界里总有无解的问题,这跟模型大小、搜索能力都没关系。
误解二:幻觉是不可避免的。
并不是。语言模型完全可以在不确定的时候选择“弃权”,不冒险瞎猜。
误解三:避免幻觉需要很高的智能,只有大模型才行。
恰恰相反,小模型可能更容易认识到自己的局限。比如,你问一个不懂毛利语的小模型毛利语问题,它会干脆地说“我不知道”。而一个懂一点的模型,反而得费劲去判断自己到底有多大把握。论文里也说了,实现“校准”(知道自己几斤几两)所需的计算量,远比实现准确性要少。
误解四:幻觉是现代语言模型里一种神秘的技术故障。
一点也不神秘。我们现在已经很清楚幻觉产生的统计学机制,以及它是如何在评估中被奖励的。
误解五:要测量幻觉,只需要一个好的幻觉评估标准就行了。
好的幻觉评估标准早就有了,但问题是,一个好的评估标准,打不过几百个奖励猜测、惩罚谦虚的传统评估标准。所以,不是要增加什么,而是要重新设计所有主要的评估指标,让它们都开始奖励表达不确定性。
OpenAI的这个发现,正促使整个行业重新思考AI的发展路径。过去那种“越大越好”的肌肉思维正在被挑战。在LongFact这个测试长篇回答准确性的基准测试中,不同模型的表现差异就很有说服力:
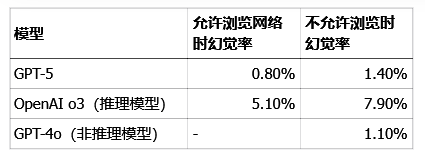
你看,专攻推理的o3模型,幻觉率反而比非推理模型高出一大截,这再次印证了评估激励机制对模型行为的巨大影响。
OpenAI的这项研究,告诉我们,幻觉不是什么神秘的代码幽灵,而是在现有训练和评估体系下,模型做出的“理性选择”。
解决它的关键,或许不在于堆砌更多的参数和算力,而是需要我们从根本上重新设计“游戏规则”,让模型敢于、也乐于在不确定时说出那句宝贵的“我不知道”。
参考资料:
https://cdn.openai.com/pdf/d04913be-3f6f-4d2b-b283-ff432ef4aaa5/why-language-models-hallucinate.pdf
https://openai.com/index/why-language-models-hallucinate
https://www.nature.com/articles/d41586-025-02853-8
https://github.com/vectara/hallucination-leaderboard?tab=readme-ov-file
END

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 15
15 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)