LangChain 源码 深度历险:基于GOF的设计模式,穿透 LangChain 源码
LangChain 源码 深度历险:基于GOF的设计模式,穿透 LangChain 源码
本文 的 原文 地址
原始的内容,请参考 本文 的 原文 地址
尼恩:LLM大模型学习圣经PDF的起源
在40岁老架构师 尼恩的读者交流群(50+)中,经常性的指导小伙伴们改造简历。
经过尼恩的改造之后,很多小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试机会,拿到了大厂机会。
2025年开始,尼恩一直在辅导小伙伴们做 AI 架构面试, 很多小伙伴 拿到了 Java + AI 架构offer ,比如下面的案例:
34岁无路可走,一个月翻盘,拿 3个架构offer,靠 Java+Al 逆天改命!!!
3年 程序媛 被裁, 25W-》40W 上岸, 逆涨60%。 Java+AI 太神了, 架构小白 2个月逆天改命
36岁/失业7个月/彻底绝望 。狠卷 3个月 Java+AI ,终于逆风翻盘,顺利 上岸
尼恩架构团队,通过 梳理一个《LLM大模型学习圣经》 帮助更多的人做LLM架构,拿到年薪100W, 这个内容体系包括下面的内容:
-
《LangChain学习圣经:从0到1精通LLM大模型应用开发的基础框架》
-
《LLM大模型学习圣经:从0到1精通RAG架构,基于LLM+RAG构建生产级企业知识库》
-
《SpringCloud + Python 混合微服务架构,打造AI分布式业务应用的技术底层》
-
《LLM大模型学习圣经:从0到1吃透大模型的顶级架构》
-
《LLM 智能体 学习圣经:从0到1吃透 LLM 智能体 的架构 与实操》
-
《LLM 智能体 学习圣经:从0到1吃透 LLM 智能体 的 中台 架构 与实操》
LangChain 源码 + 24 设计模式:通过设计模式,穿透 LangChain 源码
LangChain 源码 很复杂, 很多小伙伴和尼恩反馈: 看不懂。
接下来, 尼恩结合 GOF的 设计模式 , 帮助大家 穿透式、起底式 掌握 LangChain 源码 ,实现大家内力猛涨。
一、引言
1.1 为什么需要深入理解LangChain源码?
在当今人工智能领域,大型语言模型(LLMs)如GPT-4、Claude等展现出了强大的自然语言处理能力。然而,要将这些模型应用于实际场景,开发者往往面临诸多挑战,如上下文管理、工具调用、多模态交互等。LangChain作为一个开源框架,提供了一套灵活且强大的工具集,帮助开发者构建基于LLMs的复杂应用。
深入理解LangChain源码有以下几个重要原因:
- 定制化需求:不同的应用场景可能需要对LangChain的核心组件进行定制或扩展,例如自定义提示模板、记忆策略或代理决策逻辑。
- 性能优化:通过分析源码,可以识别性能瓶颈并进行针对性优化,例如缓存机制、异步处理或并行计算。
- 故障排查:当应用出现问题时,源码级别的理解能够帮助快速定位和解决问题。
- 技术创新:了解LangChain的实现原理可以启发开发者在其基础上进行技术创新,开发新的组件或应用模式。
二、LangChain架构概述
2.1 LangChain整体架构设计
LangChain的架构设计遵循模块化、可扩展的原则,主要由以下几个核心层组成:
(1) LLM接口层:负责与各种大型语言模型(如OpenAI、Hugging Face等)进行交互,提供统一的调用接口。
(2) 核心组件层:包含Chains、Memory、Prompt Templates、Agents和Tools等核心组件,实现了LLM应用的基本功能单元。
(3) 集成层:提供与外部数据源(如向量数据库、文件系统等)和工具(如搜索引擎、计算器等)的集成能力。
(4) 应用层:基于上述组件构建的具体应用,如聊天机器人、文档问答系统等。
这种分层设计使得LangChain具有良好的可扩展性和灵活性,开发者可以根据需要替换或扩展任意层的功能。
2.2 LangChain核心模块划分
LangChain的源码主要分为以下几个核心模块:
langchain/
├── chains/ # 链组件,用于定义和管理处理流程
├── memory/ # 记忆组件,用于管理对话和交互的上下文
├── prompts/ # 提示模板组件,用于生成向LLM提交的提示
├── agents/ # 代理组件,用于实现智能决策和工具调用
├── tools/ # 工具组件,封装各种外部功能
├── llms/ # LLM接口层,支持多种LLM提供商
├── embeddings/ # 嵌入模型接口,用于文本向量化
├── vectorstores/ # 向量数据库接口,用于语义搜索
├── document_loaders/ # 文档加载器,用于处理各种格式的文档
├── text_splitter/ # 文本分割器,用于将长文本分割为小块
├── callbacks/ # 回调系统,用于监控和记录执行过程
└── utils/ # 工具函数和辅助类
接下来,我们将深入分析每个模块的核心功能和实现原理。
三、LLM接口层实现
3.1 LLM抽象基类
LangChain通过定义抽象基类来统一不同LLM提供商的接口,使得开发者可以无缝切换不同的模型。核心抽象基类位于langchain/llms/base.py:
# langchain/llms/base.py
from abc import ABC, abstractmethod
from typing import Any, List, Mapping, Optional, Union
class LLM(ABC):
"""LLM抽象基类,定义了所有LLM实现必须遵循的接口"""
@property
@abstractmethod
def _llm_type(self) -> str:
"""返回LLM类型的字符串标识"""
pass
@abstractmethod
def _call(
self,
prompt: str,
stop: Optional[List[str]] = None
) -> str:
"""执行LLM调用的核心方法"""
pass
@property
def _identifying_params(self) -> Mapping[str, Any]:
"""返回标识LLM实例的参数"""
return {}
def __str__(self) -> str:
"""返回LLM的字符串表示"""
return f"{self._llm_type()}: {self._identifying_params}"
所有具体的LLM实现都必须继承这个抽象基类,并实现_llm_type和_call方法。_llm_type返回LLM的类型标识(如"openai"、"huggingface"等),而_call方法则实现了实际的模型调用逻辑。
3.1.1 通过 模板方法模式(Template Method Pattern) 剖析 LLM抽象基类
我们 结合一个经典的设计模式对这段代码进行介绍。
模板方法模式是一种行为型设计模式,它定义了一个算法的骨架,并允许子类在不改变算法结构的前提下重新定义算法的某些步骤。
在我们这段代码中,LLM 类是一个抽象基类(Abstract Base Class),它定义了所有语言模型(如 OpenAI、HuggingFace 等)必须遵循的接口。这个类中定义了抽象方法(_llm_type 和 _call)和一些默认实现的方法(如 __str__ 和 _identifying_params),这正是模板方法模式的典型应用。
3.1.2代码逐行注释
# langchain/llms/base.py
# 导入 Python 的抽象基类模块
from abc import ABC, abstractmethod
# 导入类型注解相关的模块
from typing import Any, List, Mapping, Optional, Union
# 定义 LLM 抽象基类,继承自 ABC,表示这是一个抽象类
class LLM(ABC):
"""LLM抽象基类,定义了所有LLM实现必须遵循的接口"""
# 抽象属性方法,子类必须实现,用于返回当前 LLM 的类型标识字符串
@property
@abstractmethod
def _llm_type(self) -> str:
"""返回LLM类型的字符串标识"""
pass
# 抽象方法,子类必须实现,用于执行模型调用的核心逻辑
@abstractmethod
def _call(
self,
prompt: str,
stop: Optional[List[str]] = None
) -> str:
"""执行LLM调用的核心方法"""
pass
# 可选实现的属性方法,返回标识当前 LLM 实例的参数字典
@property
def _identifying_params(self) -> Mapping[str, Any]:
"""返回标识LLM实例的参数"""
return {}
# 默认实现的字符串方法,用于打印 LLM 的类型和参数信息
def __str__(self) -> str:
"""返回LLM的字符串表示"""
return f"{self._llm_type()}: {self._identifying_params}"
3.1.3模板方法模式如何体现?
在这个类中:
_llm_type和_call是抽象方法,相当于模板中“必须实现”的步骤。_identifying_params和__str__是具体方法,相当于模板中“默认实现”的步骤。- 整个类定义了使用 LLM 的流程框架,比如调用模型、获取类型、生成字符串表示等。
- 子类只需要实现抽象方法,就能融入整个框架中,无需关心整体流程。
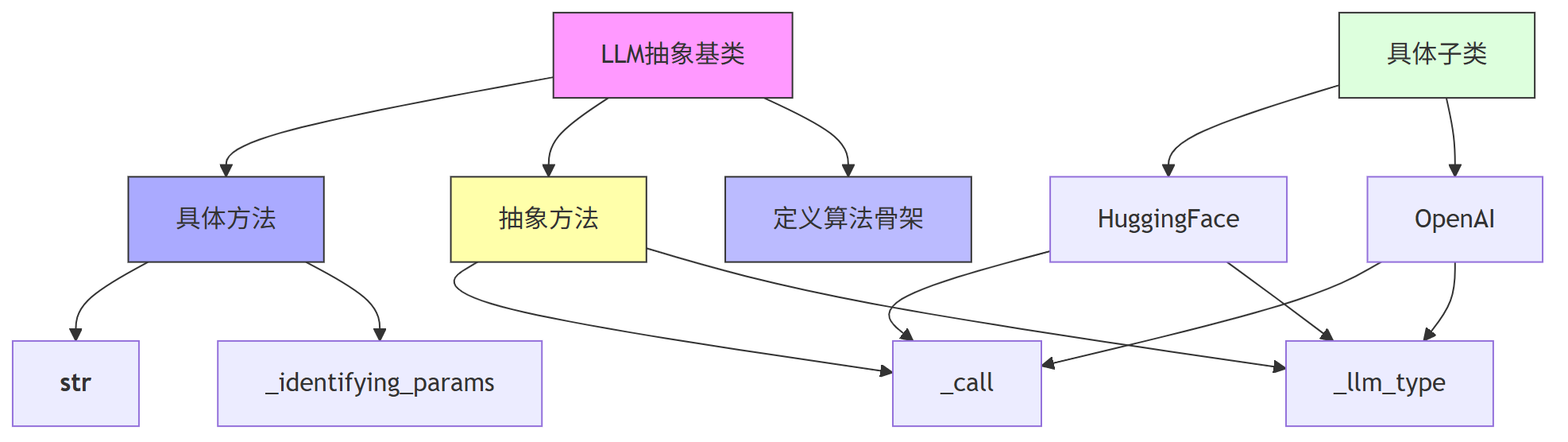
第一、这段代码使用了模板方法模式,通过定义一个抽象基类 LLM,统一了不同语言模型的调用接口。
第二、抽象方法 _llm_type 和 _call 定义了子类必须实现的逻辑,而其他方法提供了默认实现,构成了算法的骨架。
第三、这种设计让不同模型(如 OpenAI、HuggingFace)可以无缝接入 LangChain,同时保持调用方式的一致性。
第四、通过 图可以清晰看到类结构和继承关系,帮助理解模板方法模式是如何组织代码逻辑的。
3.2 OpenAI LLM实现
以OpenAI LLM实现为例,我们来看具体的实现细节:
# langchain/llms/openai.py
import openai
from typing import Any, Dict, List, Optional, Union
from langchain.llms.base import LLM
from langchain.utils import get_from_dict_or_env
class OpenAI(LLM):
"""OpenAI LLM实现"""
# 模型名称,默认为text-davinci-003
model_name: str = "text-davinci-003"
# 温度参数,控制输出的随机性
temperature: float = 0.7
# 最大生成token数
max_tokens: int = 2049
# 顶部概率采样参数
top_p: float = 1
# 频率惩罚参数
frequency_penalty: float = 0
# 存在惩罚参数
presence_penalty: float = 0
# API密钥
openai_api_key: Optional[str] = None
@property
def _llm_type(self) -> str:
"""返回LLM类型标识"""
return "openai"
def _call(
self,
prompt: str,
stop: Optional[List[str]] = None
) -> str:
"""执行OpenAI API调用"""
# 获取API密钥,优先从实例属性获取,否则从环境变量获取
openai_api_key = get_from_dict_or_env(
self.__dict__, "openai_api_key", "OPENAI_API_KEY"
)
# 构建API调用参数
params = {
"model": self.model_name,
"prompt": prompt,
"temperature": self.temperature,
"max_tokens": self.max_tokens,
"top_p": self.top_p,
"frequency_penalty": self.frequency_penalty,
"presence_penalty": self.presence_penalty,
}
# 如果提供了停止词,添加到参数中
if stop is not None:
params["stop"] = stop
# 执行API调用
response = openai.Completion.create(
api_key=openai_api_key,
**params
)
# 提取并返回生成的文本
return response.choices[0].text.strip()
@property
def _identifying_params(self) -> Dict[str, Any]:
"""返回标识LLM实例的参数"""
return {
"model_name": self.model_name,
"temperature": self.temperature,
"max_tokens": self.max_tokens,
"top_p": self.top_p,
"frequency_penalty": self.frequency_penalty,
"presence_penalty": self.presence_penalty,
}
从这个实现中可以看出,OpenAI类继承了LLM抽象基类,并实现了必要的方法。_call方法负责构建API请求参数并执行实际的API调用,处理响应并返回生成的文本。
3.3 LLM调用流程
当使用LangChain调用LLM时,整个流程大致如下:
(1) 用户通过LangChain API创建LLM实例(如OpenAI、HuggingFace等)
(2) 用户构建提示文本并调用LLM实例
(3) LLM实例将提示文本和其他参数传递给_call方法
(4) _call方法根据具体的LLM提供商实现,构建并发送API请求
(5) 接收API响应并处理结果
(6) 将处理后的结果返回给用户
这种设计使得LangChain能够支持多种LLM提供商,用户可以根据需要轻松切换不同的模型,而无需修改业务逻辑代码。
3.4 异步支持
LangChain还提供了对异步LLM调用的支持,通过定义异步方法:
# langchain/llms/base.py
import asyncio
from typing import AsyncGenerator
class LLM(ABC):
# ... 其他方法 ...
async def agenerate(
self,
prompts: List[str],
stop: Optional[List[str]] = None
) -> LLMResult:
"""异步生成多个提示的响应"""
tasks = [self._agenerate_one(prompt, stop=stop) for prompt in prompts]
results = await asyncio.gather(*tasks)
return LLMResult(generations=[[res] for res in results])
async def _agenerate_one(
self,
prompt: str,
stop: Optional[List[str]] = None
) -> Generation:
"""异步生成单个提示的响应"""
text = await self._acall(prompt, stop=stop)
return Generation(text=text)
@abstractmethod
async def _acall(
self,
prompt: str,
stop: Optional[List[str]] = None
) -> str:
"""异步调用LLM的核心方法,由子类实现"""
pass
具体的LLM实现需要实现_acall方法,提供异步调用能力。例如,OpenAI的异步实现:
# langchain/llms/openai.py
class OpenAI(LLM):
# ... 其他方法 ...
async def _acall(
self,
prompt: str,
stop: Optional[List[str]] = None
) -> str:
"""异步执行OpenAI API调用"""
openai_api_key = get_from_dict_or_env(
self.__dict__, "openai_api_key", "OPENAI_API_KEY"
)
params = {
"model": self.model_name,
"prompt": prompt,
"temperature": self.temperature,
"max_tokens": self.max_tokens,
"top_p": self.top_p,
"frequency_penalty": self.frequency_penalty,
"presence_penalty": self.presence_penalty,
}
if stop is not None:
params["stop"] = stop
# 异步执行API调用
response = await openai.Completion.acreate(
api_key=openai_api_key,
**params
)
return response.choices[0].text.strip()
这种异步支持使得LangChain能够高效处理多个并发的LLM请求,提高系统的吞吐量和响应性能。
四、Chain组件实现原理
4.1 Chain抽象基类
Chain是LangChain中最核心的组件之一,用于定义和管理一系列处理步骤。Chain的抽象基类定义在langchain/chains/base.py:
# langchain/chains/base.py
from abc import ABC, abstractmethod
from typing import Any, Dict, List, Optional, Tuple, Union
from langchain.callbacks.base import BaseCallbackManager
from langchain.callbacks.manager import (
AsyncCallbackManagerForChainRun,
CallbackManagerForChainRun,
Callbacks,
)
class Chain(ABC):
"""Chain抽象基类,定义了所有Chain实现必须遵循的接口"""
# 回调管理器,用于记录和监控Chain的执行过程
callback_manager: Optional[BaseCallbackManager] = None
@property
@abstractmethod
def input_keys(self) -> List[str]:
"""返回Chain期望的输入键列表"""
pass
@property
@abstractmethod
def output_keys(self) -> List[str]:
"""返回Chain产生的输出键列表"""
pass
@abstractmethod
def _call(
self,
inputs: Dict[str, Any],
run_manager: Optional[CallbackManagerForChainRun] = None
) -> Dict[str, Any]:
"""执行Chain的核心方法,由子类实现"""
pass
async def _acall(
self,
inputs: Dict[str, Any],
run_manager: Optional[AsyncCallbackManagerForChainRun] = None
) -> Dict[str, Any]:
"""异步执行Chain的方法,默认同步实现,可被子类重写"""
return self._call(inputs, run_manager=run_manager)
def run(
self,
callbacks: Callbacks = None,
**kwargs: Any
) -> Union[str, Dict[str, Any]]:
"""便捷方法,用于直接运行Chain并获取结果"""
# 检查输入键是否匹配
if set(kwargs.keys()) != set(self.input_keys):
raise ValueError(
f"输入键不匹配。期望: {self.input_keys}, 实际: {list(kwargs.keys())}"
)
# 执行Chain
output = self(kwargs, callbacks=callbacks)
# 如果只有一个输出键,直接返回该值
if len(self.output_keys) == 1:
return output[self.output_keys[0]]
else:
return output
async def arun(
self,
callbacks: Callbacks = None,
**kwargs: Any
) -> Union[str, Dict[str, Any]]:
"""异步便捷方法,用于直接运行Chain并获取结果"""
if set(kwargs.keys()) != set(self.input_keys):
raise ValueError(
f"输入键不匹配。期望: {self.input_keys}, 实际: {list(kwargs.keys())}"
)
output = await self.acall(kwargs, callbacks=callbacks)
if len(self.output_keys) == 1:
return output[self.output_keys[0]]
else:
return output
# 其他方法...
所有具体的Chain实现都必须继承这个抽象基类,并实现input_keys、output_keys和_call方法。input_keys和output_keys分别定义了Chain的输入和输出键,而_call方法则实现了Chain的核心处理逻辑。
4.1.1、使用的设计模式:模板方法模式(Template Method Pattern)
为什么选择这个模式?
模板方法模式是一种行为型设计模式,它定义了一个算法的骨架,并允许子类在不改变算法结构的前提下重新定义算法的某些步骤。
这正好契合了Chain抽象基类的作用:它定义了执行流程的框架(比如输入验证、执行、输出处理),而具体执行逻辑(_call方法)则由子类去实现。
4.1.2 结合模板方法模式 代码介绍
我们来看一下这段代码的核心作用:
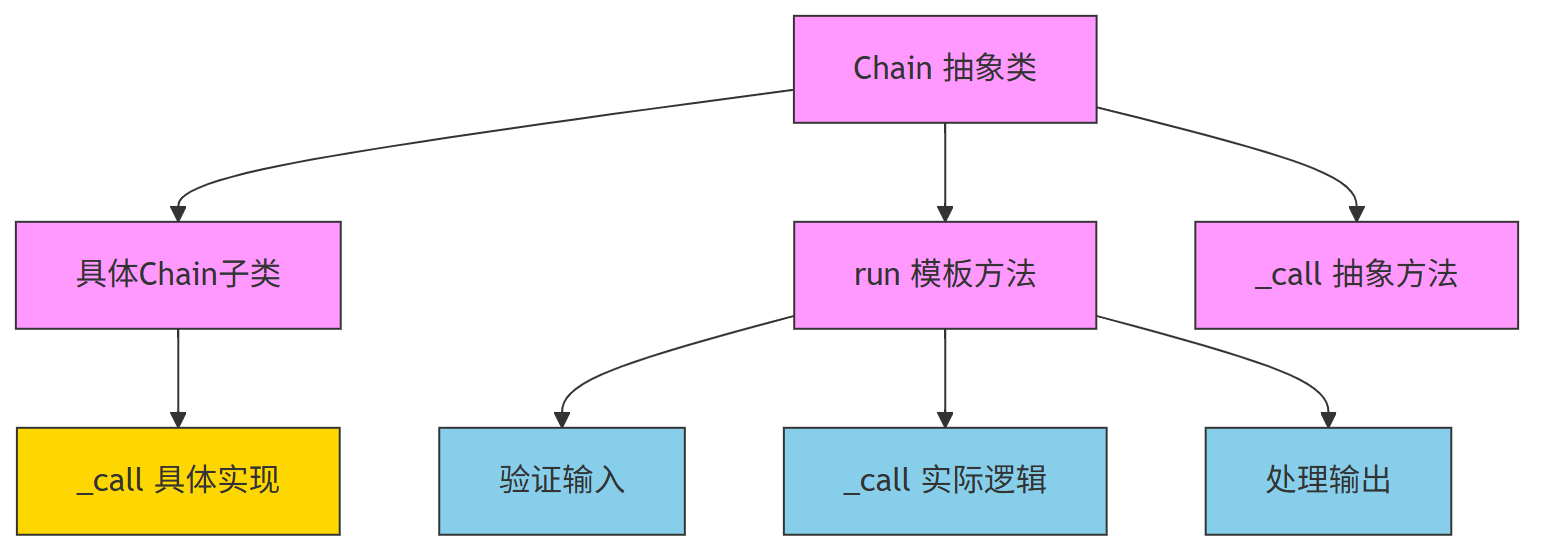
第一、这是一个抽象基类 Chain,用于定义“执行链”的统一结构
- 它定义了所有子类必须实现的接口:
input_keys、output_keys、_call - 它提供了通用的执行流程:
run、_call、_acall、arun等方法 - 子类只需要关注自己的核心逻辑(
_call),其他流程由基类统一管理
第二、run 方法是模板方法的体现
run 方法定义了执行链的标准流程:
(1) 检查输入是否符合要求(input_keys)
(2) 调用 _call 执行核心逻辑(子类实现)
(3) 根据输出键数量决定返回格式
这个流程是固定的,但 _call 是子类自己实现的。这就是模板方法模式的核心思想。
第三、_call 是一个抽象方法,留给子类实现
子类必须实现这个方法,完成自己的处理逻辑,比如调用大模型、数据库查询、数据转换等。
第四、run 和 arun 提供了同步和异步的统一入口
用户可以通过 run() 或 arun() 来调用,无需关心底层是同步还是异步执行。
4.1.3 图解(模板方法模式 + Chain 类结构)
下面 展示模板方法模式在 Chain 中的体现:
4.2 LLMChain实现分析
LLMChain是LangChain中最常用的Chain之一,它将提示模板和LLM结合起来,用于生成文本。下面是其核心实现:
# langchain/chains/llm.py
# 导入必要的模块和类
from typing import Any, Dict, List, Optional, Union
from langchain.base_language import BaseLanguageModel
from langchain.callbacks.manager import AsyncCallbackManagerForChainRun, CallbackManagerForChainRun
from langchain.chains.base import Chain
from langchain.prompts.base import BasePromptTemplate
# LLMChain 继承自 Chain,是 LangChain 中最常用的 Chain 之一
class LLMChain(Chain):
"""LLMChain将提示模板和LLM结合,用于生成文本"""
# 提示模板,类型为 BasePromptTemplate
prompt: BasePromptTemplate
# 语言模型,类型为 BaseLanguageModel
llm: BaseLanguageModel
# 输出键名称,默认为 "text"
output_key: str = "text"
@property
def input_keys(self) -> List[str]:
"""返回提示模板所需的输入键"""
return self.prompt.input_variables
@property
def output_keys(self) -> List[str]:
"""返回输出键"""
return [self.output_key]
def _call(
self,
inputs: Dict[str, Any],
run_manager: Optional[CallbackManagerForChainRun] = None
) -> Dict[str, str]:
"""执行LLMChain,生成文本"""
# 第一步:使用提示模板格式化输入,生成最终的提示文本
prompt_value = self.prompt.format_prompt(**inputs)
# 第二步:如果有回调管理器,记录提示内容(绿色)
if run_manager:
run_manager.on_text("Prompt after formatting:\n", end="\n", verbose=self.verbose)
run_manager.on_text(prompt_value.to_string(), color="green", end="\n", verbose=self.verbose)
# 第三步:调用语言模型生成响应
response = self.llm.generate_prompt(
[prompt_value],
callbacks=run_manager.get_child() if run_manager else None
)
# 第四步:提取生成的文本
text = response.generations[0][0].text
# 第五步:如果有回调管理器,记录生成结果(黄色)
if run_manager:
run_manager.on_text("Generated response:", end="\n", verbose=self.verbose)
run_manager.on_text(text, color="yellow", end="\n", verbose=self.verbose)
# 第六步:返回结果,格式为 {output_key: text}
return {self.output_key: text}
async def _acall(
self,
inputs: Dict[str, Any],
run_manager: Optional[AsyncCallbackManagerForChainRun] = None
) -> Dict[str, str]:
"""异步执行LLMChain,生成文本"""
# 异步版本的流程几乎一致,只是用了 await
prompt_value = self.prompt.format_prompt(**inputs)
if run_manager:
await run_manager.on_text("Prompt after formatting:\n", end="\n", verbose=self.verbose)
await run_manager.on_text(prompt_value.to_string(), color="green", end="\n", verbose=self.verbose)
response = await self.llm.agenerate_prompt(
[prompt_value],
callbacks=run_manager.get_child() if run_manager else None
)
text = response.generations[0][0].text
if run_manager:
await run_manager.on_text("Generated response:", end="\n", verbose=self.verbose)
await run_manager.on_text(text, color="yellow", end="\n", verbose=self.verbose)
return {self.output_key: text}
LLMChain的核心逻辑是将输入变量传递给提示模板,生成最终的提示文本,然后将该提示文本传递给LLM进行处理,最后将生成的结果作为输出返回。这种设计使得提示模板和LLM可以独立配置和替换,提高了代码的灵活性和可复用性。
4.2.1、LLMChain 是如何使用模板方法模式的?
模板方法模式是一种行为型设计模式,它定义了一个操作中的算法骨架,而将一些步骤延迟到子类中。这样可以不改变算法结构的前提下,让子类重新定义某些步骤。
在 LLMChain 中,_call 方法定义了整个调用流程(也就是算法骨架),包括:
(1) 使用提示模板生成提示文本
(2) 调用语言模型生成响应
(3) 返回结果
这些步骤中,有些是固定的(如流程顺序),有些是可变的(如具体的提示模板或语言模型)。通过模板方法模式,LLMChain 提供了统一的调用流程,而具体的实现细节(如 prompt.format_prompt() 和 llm.generate_prompt())则由不同的子类或实例决定。
4.3 链式组合机制
LangChain提供了多种方式来组合不同的Chain,形成复杂的处理流程:
(1) SequentialChain:允许定义多个Chain,并指定它们之间的输入输出关系
(2) SimpleSequentialChain:简化版的顺序链,前一个Chain的输出直接作为后一个Chain的输入
(3) RouterChain:根据输入内容动态选择合适的子Chain
(4) TransformChain:用于对数据进行转换和处理
这些组合机制使得开发者可以根据具体需求,灵活构建各种复杂的处理流程。例如,一个典型的文档问答系统可能包含以下Chain的组合:
(1) 文档加载Chain:负责加载和解析文档
(2) 文本分割Chain:将长文档分割为小块
(3) 嵌入生成Chain:将文本转换为向量表示
(4) 向量检索Chain:在向量数据库中检索相关内容
(5) 问答Chain:结合检索结果和用户问题生成答案
通过合理组合不同的Chain,开发者可以构建出功能强大、灵活可扩展的LLM应用。
4.4 SimpleSequentialChain实现分析
SimpleSequentialChain是一个简单的顺序链实现,它按顺序执行多个子Chain,前一个Chain的输出作为后一个Chain的输入。下面是其核心实现:
# langchain/chains/sequential.py
from typing import Any, Dict, List, Optional
from langchain.chains.base import Chain
class SimpleSequentialChain(Chain):
"""简单顺序链,按顺序执行多个Chain,前一个Chain的输出作为后一个Chain的输入"""
# 子Chain列表
chains: List[Chain]
# 是否只返回最后一个Chain的输出
return_only_final_output: bool = False
@property
def input_keys(self) -> List[str]:
"""返回第一个Chain的输入键"""
return self.chains[0].input_keys
@property
def output_keys(self) -> List[str]:
"""返回最后一个Chain的输出键"""
return self.chains[-1].output_keys
def _call(
self,
inputs: Dict[str, Any],
run_manager: Optional[CallbackManagerForChainRun] = None
) -> Dict[str, Any]:
"""执行顺序链"""
current_inputs = inputs
intermediate_outputs = {}
# 依次执行每个子Chain
for i, chain in enumerate(self.chains):
# 为当前Chain创建回调管理器
if run_manager:
new_run_manager = run_manager.get_child()
else:
new_run_manager = None
# 执行当前Chain
outputs = chain(current_inputs, callbacks=new_run_manager)
# 记录中间输出
if not self.return_only_final_output:
for k, v in outputs.items():
intermediate_outputs[f"{chain.__class__.__name__}_{k}"] = v
# 更新当前输入为当前Chain的输出
current_inputs = outputs
# 返回最终输出或所有中间输出
if self.return_only_final_output:
return current_inputs
else:
return intermediate_outputs
async def _acall(
self,
inputs: Dict[str, Any],
run_manager: Optional[AsyncCallbackManagerForChainRun] = None
) -> Dict[str, Any]:
"""异步执行顺序链"""
current_inputs = inputs
intermediate_outputs = {}
for i, chain in enumerate(self.chains):
if run_manager:
new_run_manager = run_manager.get_child()
else:
new_run_manager = None
outputs = await chain.acall(current_inputs, callbacks=new_run_manager)
if not self.return_only_final_output:
for k, v in outputs.items():
intermediate_outputs[f"{chain.__class__.__name__}_{k}"] = v
current_inputs = outputs
if self.return_only_final_output:
return current_inputs
else:
return intermediate_outputs
从这个实现可以看出,SimpleSequentialChain通过遍历子Chain列表,依次执行每个Chain,并将前一个Chain的输出作为后一个Chain的输入。这种设计使得多个Chain可以灵活组合,形成复杂的处理流程。
五、Memory组件实现原理
5.1 Memory抽象基类
Memory组件负责在Chain执行过程中存储和检索上下文信息,使得Chain能够"记住"之前的交互内容。Memory的抽象基类定义在langchain/memory/base.py:
# langchain/memory/base.py
from abc import ABC, abstractmethod
from typing import Any, Dict, List, Optional, Tuple
from langchain.schema import BaseMessage
class BaseMemory(ABC):
"""Memory抽象基类,定义了所有Memory实现必须遵循的接口"""
@property
@abstractmethod
def memory_variables(self) -> List[str]:
"""返回Memory中存储的变量名称列表"""
pass
@abstractmethod
def load_memory_variables(self, inputs: Dict[str, Any]) -> Dict[str, Any]:
"""根据输入加载Memory中的变量"""
pass
@abstractmethod
def save_context(self, inputs: Dict[str, Any], outputs: Dict[str, Any]) -> None:
"""保存上下文信息到Memory中"""
pass
def clear(self) -> None:
"""清除Memory中的所有信息,默认实现为空"""
pass
所有具体的Memory实现都必须继承这个抽象基类,并实现memory_variables、load_memory_variables和save_context方法。memory_variables返回Memory中存储的变量名称,load_memory_variables根据当前输入加载相应的上下文信息,save_context则将新的上下文信息保存到Memory中。
5.1.1、模板方法模式在 Memory 基类中的体现
抽象类 BaseMemory,它就像是一个模板,规定了所有子类必须实现的方法:
memory_variables:告诉别人我这个 Memory 里有哪些变量可以读。load_memory_variables:根据当前输入,从 Memory 中读取变量。save_context:把当前输入和输出保存到 Memory 中。clear:可选方法,清空 Memory,默认为空实现。
这些方法就构成了一个“记忆流程”的模板,不同的子类(比如 ConversationBufferMemory)会根据这个模板去实现自己的逻辑。
5.1.2、结合模板方法模式的流程图
下面,展示了 Memory 的核心流程和设计模式的结构关系:
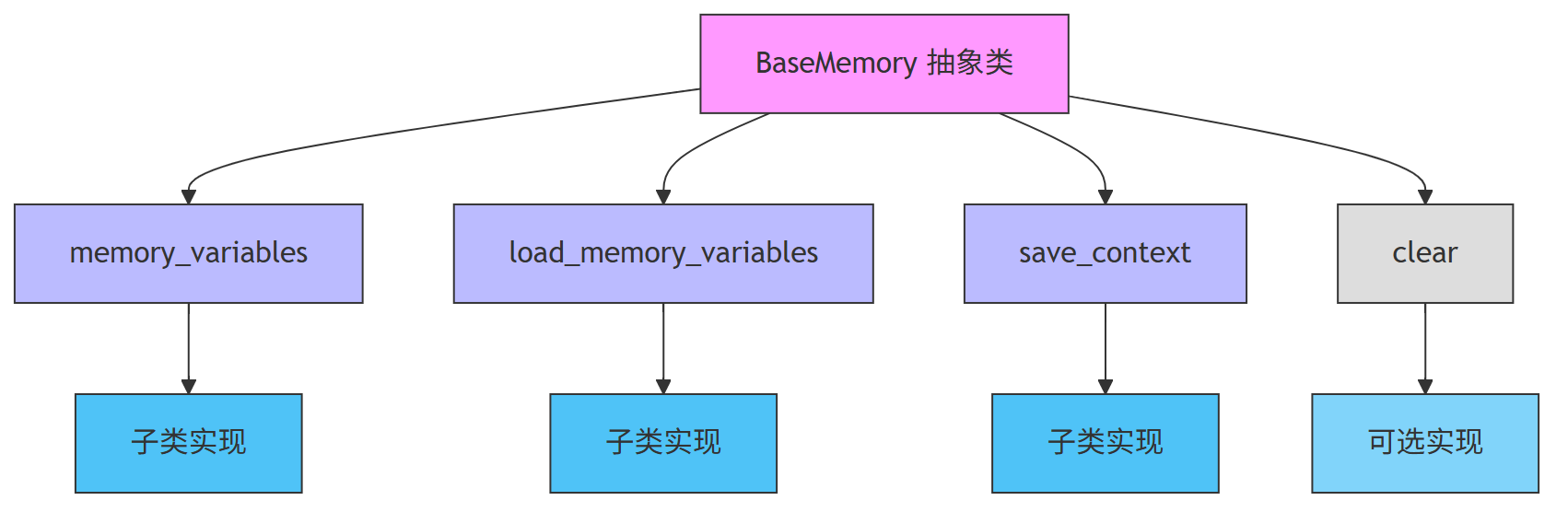
通过模板方法模式,BaseMemory 类定义了一个统一的“记忆”流程,让所有子类都按照这个流程来工作。这样做的好处是:
- 统一接口:所有 Memory 实现都有统一的使用方式。
- 扩展性强:新增一个 Memory 类型只需要继承 BaseMemory 并实现抽象方法。
- 结构清晰:模板方法模式让整个流程清晰易懂,便于维护和阅读
5.2 ConversationBufferMemory实现分析
ConversationBufferMemory是最简单也是最常用的Memory实现之一,它以文本形式存储整个对话历史。下面是其核心实现:
# langchain/memory/buffer.py
from typing import Any, Dict, List, Optional, Tuple
from langchain.memory.base import BaseMemory
from langchain.schema import BaseMessage, HumanMessage, AIMessage
class ConversationBufferMemory(BaseMemory):
"""对话缓冲区Memory,存储整个对话历史"""
# 对话历史
chat_memory: BaseChatMemory
# 是否返回聊天历史作为字符串
return_messages: bool = False
# 输入键名称
input_key: Optional[str] = None
# 输出键名称
output_key: Optional[str] = None
@property
def memory_variables(self) -> List[str]:
"""返回Memory中存储的变量名称"""
return ["history"]
def load_memory_variables(self, inputs: Dict[str, Any]) -> Dict[str, Any]:
"""加载对话历史"""
messages = self.chat_memory.messages
if self.return_messages:
# 直接返回消息列表
history = messages
else:
# 将消息转换为字符串
history = get_buffer_string(messages)
return {"history": history}
def save_context(self, inputs: Dict[str, Any], outputs: Dict[str, Any]) -> None:
"""保存上下文信息到对话历史"""
# 获取用户输入
input_str = inputs[self.input_key] if self.input_key else inputs[list(inputs.keys())[0]]
# 添加用户消息到对话历史
self.chat_memory.add_user_message(input_str)
# 获取模型输出
output_str = outputs[self.output_key] if self.output_key else outputs[list(outputs.keys())[0]]
# 添加模型回复到对话历史
self.chat_memory.add_ai_message(output_str)
def clear(self) -> None:
"""清除对话历史"""
self.chat_memory.clear()
ConversationBufferMemory使用chat_memory属性来存储对话历史,支持以消息列表或字符串形式返回历史记录。save_context方法将用户输入和模型输出添加到对话历史中,而load_memory_variables方法则负责加载这些历史记录。
5.3 ConversationSummaryMemory实现分析
ConversationSummaryMemory会维护对话的摘要,而不是存储完整的对话历史,这在处理长对话时非常有用。下面是其核心实现:
# langchain/memory/summary.py
from typing import Any, Dict, List, Optional, Tuple
from langchain.base_language import BaseLanguageModel
from langchain.chains import LLMChain
from langchain.memory.base import BaseMemory
from langchain.prompts import PromptTemplate
from langchain.schema import BaseMessage, HumanMessage, AIMessage
SUMMARY_PROMPT = """总结以下对话:
{history}
总结:"""
class ConversationSummaryMemory(BaseMemory):
"""对话摘要Memory,维护对话的摘要"""
# 语言模型,用于生成摘要
llm: BaseLanguageModel
# 对话历史
chat_memory: BaseChatMemory
# 摘要
summary: str = ""
# 摘要提示模板
prompt: PromptTemplate = PromptTemplate(
input_variables=["history"], template=SUMMARY_PROMPT
)
# 输入键名称
input_key: Optional[str] = None
# 输出键名称
output_key: Optional[str] = None
@property
def memory_variables(self) -> List[str]:
"""返回Memory中存储的变量名称"""
return ["history"]
def load_memory_variables(self, inputs: Dict[str, Any]) -> Dict[str, Any]:
"""加载对话摘要"""
return {"history": self.summary}
def save_context(self, inputs: Dict[str, Any], outputs: Dict[str, Any]) -> None:
"""保存上下文信息并更新摘要"""
# 保存用户输入和模型输出到对话历史
input_str = inputs[self.input_key] if self.input_key else inputs[list(inputs.keys())[0]]
self.chat_memory.add_user_message(input_str)
output_str = outputs[self.output_key] if self.output_key else outputs[list(outputs.keys())[0]]
self.chat_memory.add_ai_message(output_str)
# 获取最新的对话历史
messages = self.chat_memory.messages
message_text = get_buffer_string(messages)
# 创建LLMChain用于生成摘要
chain = LLMChain(llm=self.llm, prompt=self.prompt)
# 生成新的摘要
self.summary = chain.run(history=message_text)
def clear(self) -> None:
"""清除对话历史和摘要"""
self.chat_memory.clear()
self.summary = ""
ConversationSummaryMemory使用LLM来生成对话的摘要,每次有新的对话内容时,它会更新摘要。这种方法可以有效地减少内存占用,同时保留对话的关键信息。
5.3.1 ConversationBufferMemory实现分析
结合一个最经典的设计模式 —— 观察者模式(Observer Pattern),来对这段 ConversationBufferMemory 的代码进行介绍和图示说明。
第一、什么是观察者模式?
观察者模式是一种行为型设计模式,它的核心思想是:当一个对象的状态发生变化时,所有依赖它的对象都会收到通知并自动更新。
这就像你订阅了一个公众号,公众号一更新,你就收到推送。公众号是“被观察者”,你是“观察者”。
第二、为什么用观察者模式来理解这段代码?
虽然 ConversationBufferMemory 的代码中没有显式使用观察者模式的结构,但它在“保存上下文”和“加载上下文”这两个行为上,本质上是在观察用户的输入和模型的输出,并将这些变化记录到历史中。
我们可以把 ConversationBufferMemory 看作是一个“观察者”,它观察用户和AI的对话内容,然后把这些内容保存到 chat_memory 中。
第3、用观察者模式理解 ConversationBufferMemory 的工作流程
我们可以把整个流程看成是:
- 用户输入和模型输出是“被观察的对象”
ConversationBufferMemory是“观察者”,它监听这些输入输出的变化- 每次有新输入或输出,它就更新自己的
chat_memory
第4、 图展示流程
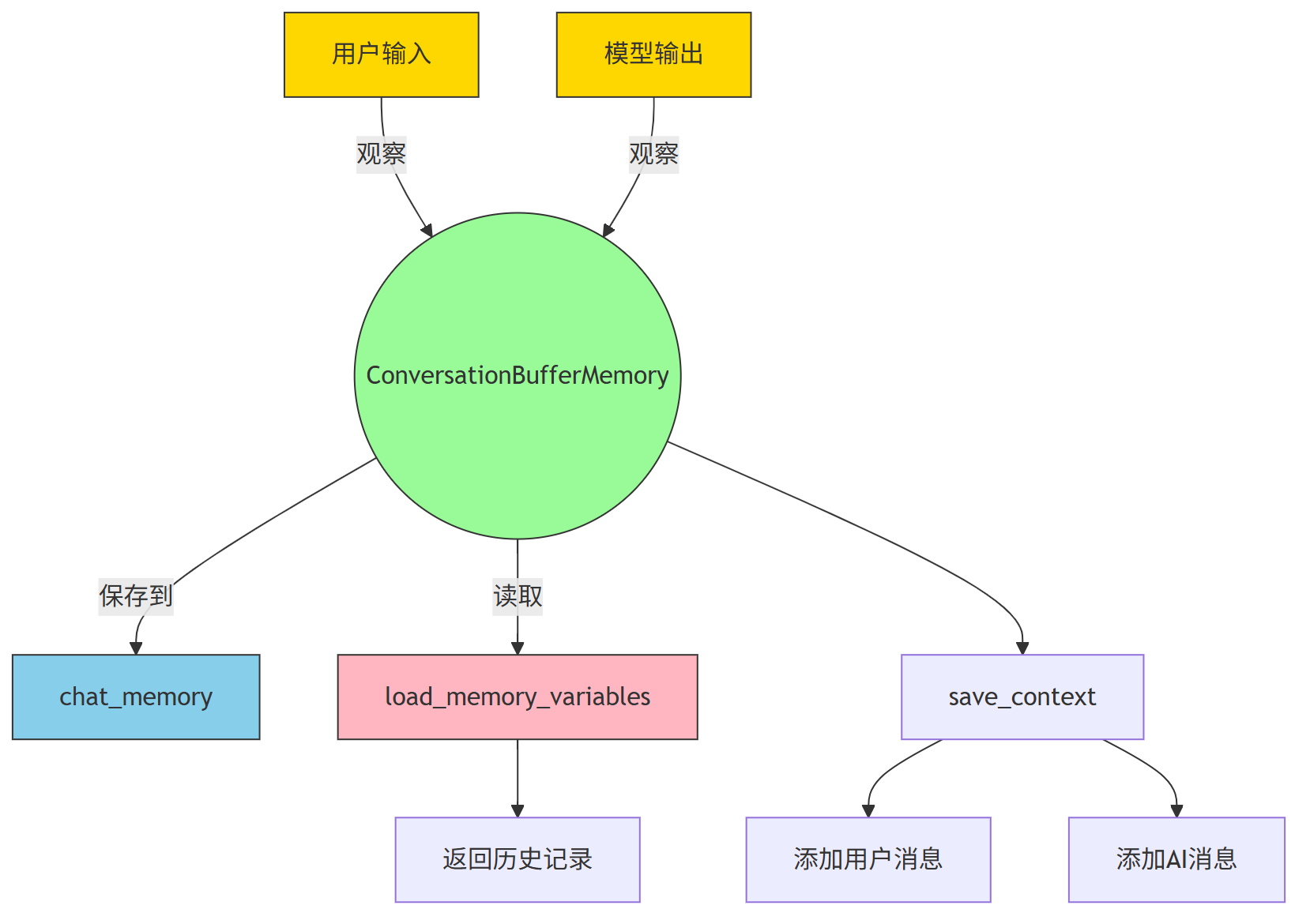
总结一句话:
ConversationBufferMemory 就像一个忠实的记录员,它观察用户和AI的对话,把每一句话都记下来,等需要的时候再拿出来用 —— 这正是观察者模式的核心思想。
5.4 其他Memory实现
除了上述两种Memory实现,LangChain还提供了多种其他Memory类型,包括:
(1) ConversationBufferWindowMemory:存储最近的N条对话消息,适用于限制对话历史长度的场景
(2) ConversationTokenBufferMemory:基于token数量限制对话历史长度,而不是消息数量
(3) EntityMemory:跟踪对话中提到的实体及其相关信息
(4) VectorStoreRetrieverMemory:使用向量数据库存储和检索对话历史,支持语义检索
这些Memory实现可以根据具体应用场景选择和组合使用,以满足不同的需求。
5.5 Memory在Chain中的集成
Memory组件通常与Chain一起使用,为Chain提供上下文信息。下面是一个简单的示例,展示如何在LLMChain中使用ConversationBufferMemory:
from langchain.llms import OpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
from langchain.memory import ConversationBufferMemory
# 创建提示模板
prompt = PromptTemplate(
input_variables=["input", "history"],
template="""你是一个智能助手,帮助用户解决问题。
以下是之前的对话历史:
{history}
用户提问: {input}
助手回答:"""
)
# 创建Memory
memory = ConversationBufferMemory(input_key="input", output_key="text")
# 创建LLMChain并集成Memory
chain = LLMChain(
llm=OpenAI(),
prompt=prompt,
memory=memory,
verbose=True
)
# 第一次调用
result = chain.run("你好,我是小明。")
print(result)
# 第二次调用,Memory会自动包含第一次的对话历史
result = chain.run("我今天感觉很累,有什么建议吗?")
print(result)
在这个示例中,Memory会自动保存每次对话的上下文,并在下次调用时提供给Chain,使得对话能够保持连贯性。
六、Prompt Templates组件实现原理
6.1 PromptTemplate基类
Prompt Templates负责生成向LLM提交的提示文本,它允许将动态变量插入到固定的提示模板中。核心基类定义在langchain/prompts/base.py:
# langchain/prompts/base.py
from abc import ABC, abstractmethod
from typing import Any, Dict, List, Optional, Union
from langchain.schema import BaseMessage
class BasePromptTemplate(ABC):
"""提示模板抽象基类,定义了所有提示模板必须遵循的接口"""
@property
@abstractmethod
def input_variables(self) -> List[str]:
"""返回提示模板期望的输入变量列表"""
pass
@abstractmethod
def format_prompt(self, **kwargs: Any) -> PromptValue:
"""格式化提示模板,返回PromptValue对象"""
pass
@abstractmethod
def format(self, **kwargs: Any) -> str:
"""格式化提示模板,返回字符串"""
pass
def _get_prompt_dict(self) -> Dict[str, Any]:
"""返回提示模板的字典表示"""
return {
"input_variables": self.input_variables,
"template": self.format(),
}
所有具体的提示模板实现都必须继承这个抽象基类,并实现input_variables、format_prompt和format方法。input_variables返回模板期望的输入变量列表,format_prompt和format方法用于将变量值填充到模板中,生成最终的提示文本。
第一、设计模式选择:模板方法模式(Template Method Pattern)
模板方法模式是行为型设计模式中最经典、最贴近代码结构的一种。
它定义了一个算法的骨架,但将一些步骤延迟到子类中实现。这样可以在不改变算法结构的前提下,允许子类重新定义某些步骤。
在 BasePromptTemplate 这个类中,就很好地体现了模板方法模式的思想。
第二、代码结合设计模式的介绍
BasePromptTemplate是一个“模板类”,它规定了所有提示模板必须具备的功能。- 它定义了三个必须实现的方法:
input_variables(输入变量)、format_prompt(生成 PromptValue)、format(生成字符串)。 - 它还提供了一个已经实现的方法
_get_prompt_dict,这个方法就是一个模板方法,它调用了抽象方法,但本身是固定的流程。 - 子类只需要实现抽象方法,就可以自动获得
_get_prompt_dict的功能。
第三、用 图展示模板方法模式的核心流程
下面展示了模板方法 _get_prompt_dict 是如何调用子类实现的抽象方法的。
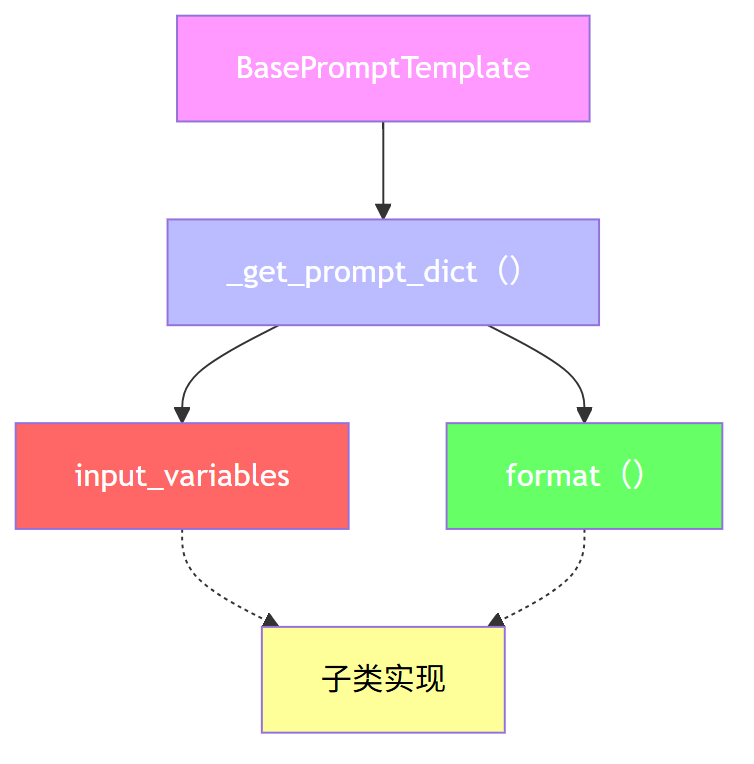
第四、总结
第一、BasePromptTemplate 是一个抽象基类,定义了提示模板的统一接口。
第二、它使用了模板方法设计模式,通过 _get_prompt_dict 方法定义了固定流程,调用子类实现的抽象方法。
第三、这种设计让子类专注于实现具体逻辑,而不需要关心整体结构,提高了代码的复用性和扩展性。
6.2 PromptTemplate实现分析
PromptTemplate是最常用的提示模板实现,它使用Python的字符串格式化语法:
# langchain/prompts/prompt.py
from typing import Any, Dict, List, Optional, Union
from langchain.prompts.base import BasePromptTemplate, PromptValue
from langchain.schema import BaseMessage, HumanMessage
class PromptTemplate(BasePromptTemplate):
"""基于字符串格式化的提示模板"""
# 模板字符串
template: str
# 输入变量列表
input_variables: List[str]
# 模板格式,默认为f-string
template_format: str = "f-string"
# 是否验证模板
validate_template: bool = True
def __init__(
self,
input_variables: List[str],
template: str,
template_format: str = "f-string",
validate_template: bool = True,
**kwargs: Any,
):
"""初始化PromptTemplate"""
super().__init__(**kwargs)
self.input_variables = input_variables
self.template = template
self.template_format = template_format
# 验证模板
if validate_template:
self._validate_template()
def _validate_template(self) -> None:
"""验证模板格式是否正确"""
if self.template_format == "f-string":
# 简单验证f-string格式
try:
# 使用空字典进行格式化,检查是否有未定义的变量
self.format(**{v: "" for v in self.input_variables})
except Exception as e:
raise ValueError(f"模板验证失败: {e}")
# 其他格式的验证...
def format_prompt(self, **kwargs: Any) -> PromptValue:
"""格式化提示模板"""
# 检查所有必需的输入变量都已提供
missing_vars = set(self.input_variables) - set(kwargs.keys())
if missing_vars:
raise ValueError(f"缺少必需的输入变量: {missing_vars}")
# 格式化模板
formatted = self.format(**kwargs)
# 返回PromptValue对象
return StringPromptValue(text=formatted)
def format(self, **kwargs: Any) -> str:
"""格式化模板字符串"""
if self.template_format == "f-string":
# 使用f-string格式化
return self.template.format(**kwargs)
elif self.template_format == "jinja2":
# 使用Jinja2格式化
from jinja2 import Template
return Template(self.template).render(**kwargs)
else:
raise ValueError(f"不支持的模板格式: {self.template_format}")
def _get_prompt_dict(self) -> Dict[str, Any]:
"""返回提示模板的字典表示"""
return {
"input_variables": self.input_variables,
"template": self.template,
"template_format": self.template_format,
}
PromptTemplate支持多种格式化语法,默认使用Python的f-string格式。它会验证输入变量是否齐全,并将变量值正确地填充到模板中。
6.3 FewShotPromptTemplate实现分析
FewShotPromptTemplate用于生成包含示例的提示,这在进行少样本学习时非常有用:
# langchain/prompts/few_shot.py
from typing import Any, Dict, List, Optional, Union
from langchain.prompts.base import BasePromptTemplate, PromptValue
from langchain.prompts.example_selector.base import BaseExampleSelector
from langchain.prompts.prompt import PromptTemplate
from langchain.schema import BaseMessage, HumanMessage
class FewShotPromptTemplate(BasePromptTemplate):
"""少样本提示模板,用于生成包含示例的提示"""
# 示例选择器或示例列表
examples: Union[List[Dict[str, Any]], BaseExampleSelector]
# 示例格式提示
example_prompt: PromptTemplate
# 连接示例的字符串
example_separator: str = "\n\n"
# 前缀文本
prefix: str = ""
# 后缀文本
suffix: str = ""
# 输入变量
input_variables: List[str]
# 模板格式
template_format: str = "f-string"
def format_prompt(self, **kwargs: Any) -> PromptValue:
"""格式化提示模板"""
# 获取示例
if isinstance(self.examples, BaseExampleSelector):
examples = self.examples.select_examples(kwargs)
else:
examples = self.examples
# 格式化每个示例
example_strings = [
self.example_prompt.format(**example) for example in examples
]
# 连接示例
example_string = self.example_separator.join(example_strings)
# 构建完整的提示
pieces = [self.prefix, example_string, self.suffix]
full_prompt = "\n\n".join([p for p in pieces if p])
# 格式化最终提示
formatted_prompt = full_prompt.format(**kwargs)
return StringPromptValue(text=formatted_prompt)
def format(self, **kwargs: Any) -> str:
"""格式化提示模板,返回字符串"""
return self.format_prompt(**kwargs).to_string()
def _get_prompt_dict(self) -> Dict[str, Any]:
"""返回提示模板的字典表示"""
return {
"examples": self.examples,
"example_prompt": self.example_prompt,
"example_separator": self.example_separator,
"prefix": self.prefix,
"suffix": self.suffix,
"input_variables": self.input_variables,
"template_format": self.template_format,
}
FewShotPromptTemplate允许在提示中包含多个示例,这些示例可以帮助LLM更好地理解任务要求。它可以通过BaseExampleSelector动态选择示例,也可以使用预定义的示例列表。
第一、FewShotPromptTemplate 模板方法模式简介
模板方法模式是一种行为型设计模式,它的核心思想是:定义一个操作中的算法骨架,而将一些步骤延迟到子类中实现。
这样可以在不改变算法结构的前提下,让子类重新定义某些步骤。
通俗点说,它就像一个“填空题”模板,主流程已经写好了,但具体细节可以由不同的子类来填。
第二、代码与模板方法模式的结合分析
在 FewShotPromptTemplate 这个类中,虽然没有显式使用抽象类定义模板方法,
但FewShotPromptTemplate 本质上是模板方法模式的实现,因为 :
- 定义了生成提示的固定流程(骨架)
- 将某些具体步骤(如示例格式化、连接方式)留给了子类或外部传入(如
example_prompt和example_separator)
主要流程如下:
(1) 获取示例:判断是使用示例选择器还是直接使用示例列表
(2) 格式化每个示例:使用 example_prompt 对每个示例进行格式化
(3) 拼接示例字符串:使用 example_separator 拼接成完整示例块
(4) 拼接完整提示:将 prefix + 示例块 + suffix 拼接成完整提示
(5) 最终格式化输出:使用 kwargs 替换变量,生成最终提示字符串
这些步骤构成了一个固定的流程结构,而具体实现细节(如示例格式、连接方式等)是可变的,这正是模板方法模式的核心思想。
第3、FewShotPromptTemplate 流程图
下面 的流程图,展示了 FewShotPromptTemplate 的核心流程:
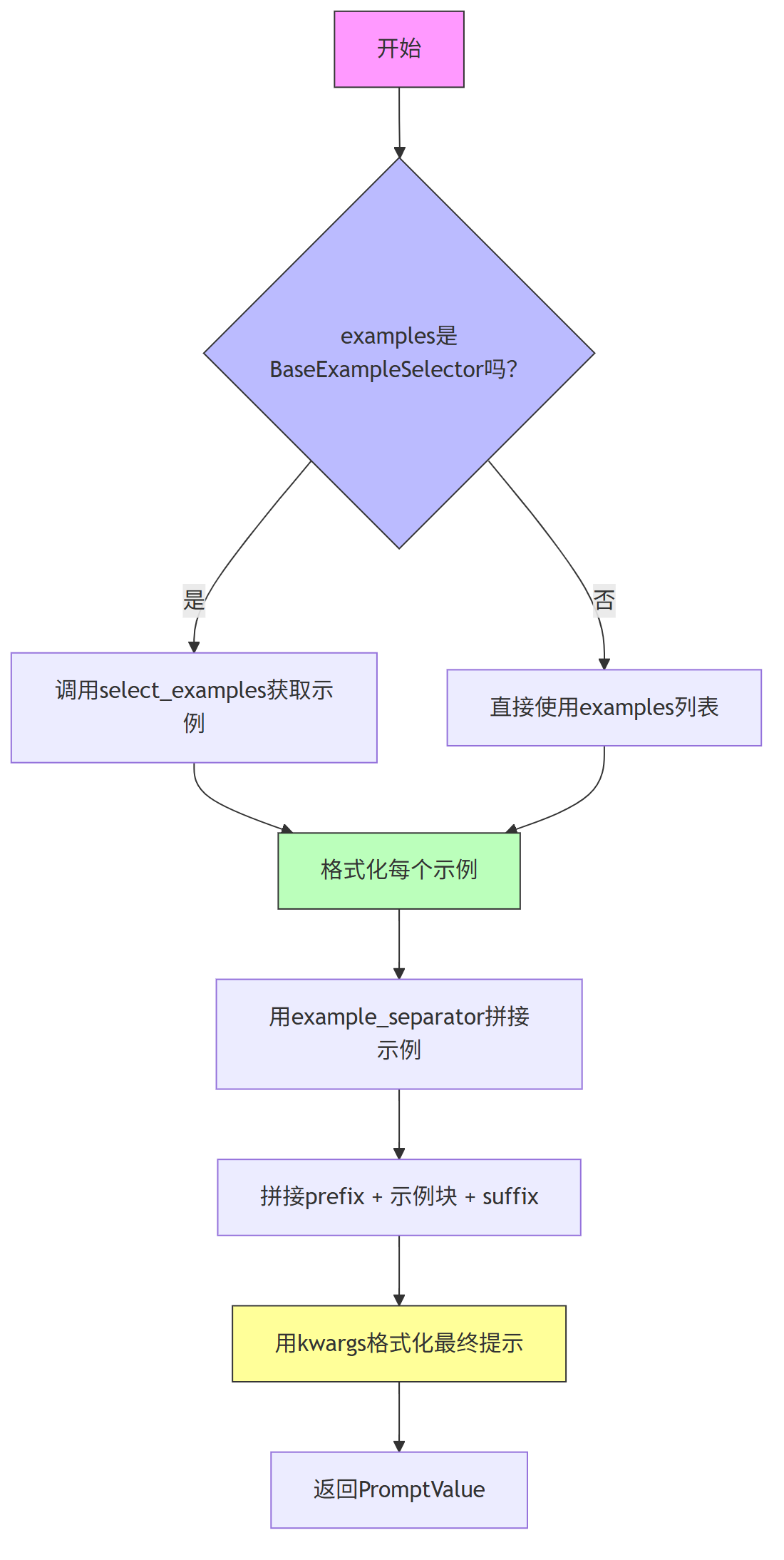
通过模板方法模式的思想,FewShotPromptTemplate 实现了一个可扩展、可配置的提示生成流程。
它定义了生成提示的骨架流程,而将示例格式、连接方式等细节交给外部配置,从而实现了高度灵活的提示生成机制。
这种设计非常适合像 LangChain 这样的框架,因为它允许用户在不修改核心逻辑的前提下,灵活地定制提示内容。
6.4 其他提示模板实现
LangChain还提供了多种其他提示模板实现,包括:
(1) ChatPromptTemplate:专为聊天模型设计的提示模板
(2) PipelinePromptTemplate:组合多个提示模板
(3) PromptTemplate.from_template:从字符串快速创建提示模板
(4) load_prompt:从文件加载提示模板
这些提示模板实现提供了丰富的功能,使得开发者可以根据具体需求灵活构建复杂的提示。
6.5 提示模板的高级特性
除了基本的变量替换功能,LangChain的提示模板还支持一些高级特性:
(1) 动态示例选择:通过BaseExampleSelector接口,可以根据当前输入动态选择最相关的示例
(2) 模板验证:可以验证模板格式是否正确,确保所有必需的变量都被提供
(3) 多语言支持:支持多种模板格式语法,如f-string、Jinja2等
(4) 序列化和反序列化:可以将提示模板保存到文件或从文件加载
这些高级特性使得提示模板更加灵活和强大,能够适应各种复杂的应用场景。
七、Agents组件实现原理
7.1 Agent抽象基类
Agents是LangChain中最复杂也是最强大的组件之一,它允许LLM根据任务需求自主选择和使用工具。Agent的抽象基类定义在langchain/agents/base.py:
# langchain/agents/base.py
from abc import ABC, abstractmethod
from typing import Any, Dict, List, Optional, Tuple, Union
from langchain.base_language import BaseLanguageModel
from langchain.callbacks.base import BaseCallbackManager
from langchain.chains.base import Chain
from langchain.prompts.base import BasePromptTemplate
from langchain.schema import AgentAction, AgentFinish, OutputParserException
class Agent(ABC):
"""Agent抽象基类,定义了所有Agent必须遵循的接口"""
# 语言模型
llm: BaseLanguageModel
# 工具列表
tools: List[BaseTool]
# 提示模板
prompt: BasePromptTemplate
# 回调管理器
callback_manager: Optional[BaseCallbackManager] = None
@classmethod
@abstractmethod
def create_prompt(cls, tools: List[BaseTool]) -> BasePromptTemplate:
"""创建Agent使用的提示模板"""
pass
@classmethod
@abstractmethod
def _get_default_output_parser(cls, **kwargs: Any) -> AgentOutputParser:
"""获取默认的输出解析器"""
pass
@property
@abstractmethod
def observation_prefix(self) -> str:
"""观察结果的前缀"""
pass
@property
@abstractmethod
def llm_prefix(self) -> str:
"""LLM思考的前缀"""
pass
@abstractmethod
def _construct_scratchpad(
self, intermediate_steps: List[Tuple[AgentAction, str]]
) -> str:
"""构建思考过程的草稿本"""
pass
@classmethod
@abstractmethod
def from_llm_and_tools(
cls,
llm: BaseLanguageModel,
tools: List[BaseTool],
callback_manager: Optional[BaseCallbackManager] = None,
**kwargs: Any,
) -> "Agent":
"""从LLM和工具列表创建Agent"""
pass
@abstractmethod
def plan(
self,
intermediate_steps: List[Tuple[AgentAction, str]],
callbacks: Optional[BaseCallbackManager] = None,
**kwargs: Any,
) -> Union[AgentAction, AgentFinish]:
"""根据中间步骤和输入计划下一步行动"""
pass
async def aplan(
self,
intermediate_steps: List[Tuple[AgentAction, str]],
callbacks: Optional[BaseCallbackManager] = None,
**kwargs: Any,
) -> Union[AgentAction, AgentFinish]:
"""异步根据中间步骤和输入计划下一步行动"""
return self.plan(intermediate_steps, callbacks=callbacks, **kwargs)
所有具体的Agent实现都必须继承这个抽象基类,并实现上述抽象方法。这些方法定义了Agent如何创建提示模板、解析LLM输出、规划下一步行动等核心功能。
现在 结合一个最经典、与代码关系最紧密的设计模式——模板方法模式(Template Method Pattern),来解读这段关于 Agent 抽象基类的代码。
第一、模板方法模式介绍
模板方法模式是一种行为型设计模式。
它的核心思想是:在一个抽象类中定义算法的骨架,而将一些步骤延迟到子类中实现。
这样可以在不改变算法结构的前提下,允许子类重新定义算法中的某些步骤。
这非常适合像 Agent 这样的抽象类,它定义了 Agent 的整体行为流程,但具体实现由子类完成。
第二、代码结合模板方法模式的解读
我们来看这段 Agent 类的代码:
class Agent(ABC):
...
这个类继承了 ABC,说明它是一个抽象基类。
它定义了一系列抽象方法,比如:
create_prompt_get_default_output_parserplanfrom_llm_and_tools_construct_scratchpadobservation_prefixllm_prefix
这些方法就像是模板方法模式中的“抽象步骤”。
它们定义了 Agent 的核心流程,但具体实现由子类完成。
而 plan() 方法是整个 Agent 的核心执行逻辑,它会被模板方法调用,子类可以重写它来实现不同的行为策略。
第三、模板方法模式在 Agent 中的体现
我们可以把 Agent 看作一个模板类,它定义了以下流程:
(1) 创建提示模板(create_prompt)
(2) 获取输出解析器(_get_default_output_parser)
(3) 构建草稿本(_construct_scratchpad)
(4) 规划下一步(plan)
(5) 返回结果(AgentAction 或 AgentFinish)
这些方法的调用顺序和逻辑由 Agent 类控制,但具体实现由子类完成。
第四、 Agent抽象基类流程 图解
下面 展示了 Agent 的核心流程 :

Agent 抽象类使用了模板方法模式,它定义了 Agent 的整体行为流程,但具体的实现(如提示模板、输出解析、规划逻辑)由子类完成,从而实现了算法结构统一、行为可扩展的设计目标。
7.2 AgentOutputParser抽象基类
AgentOutputParser负责解析LLM的输出,将其转换为AgentAction或AgentFinish对象:
# langchain/agents/agent.py
from abc import ABC, abstractmethod
from typing import Any, Dict, List, Optional, Tuple, Union
from langchain.schema import AgentAction, AgentFinish
class AgentOutputParser(ABC):
"""Agent输出解析器抽象基类"""
@abstractmethod
def parse(self, text: str) -> Union[AgentAction, AgentFinish]:
"""解析LLM输出"""
pass
def get_format_instructions(self) -> str:
"""获取格式说明"""
return ""
不同类型的Agent通常需要不同的输出解析器,以正确解析LLM的输出。
第二、代码结合模板方法模式进行AgentOutputParser 讲解
我们 结合一个最经典的设计模式——模板方法模式(Template Method Pattern),来讲解AgentOutputParser抽象基类 。
模板方法模式是一种行为型设计模式。 它的核心思想是:在一个抽象类中定义算法的骨架,而将一些步骤延迟到子类中实现。这样可以在不改变算法结构的前提下,允许子类重新定义某些步骤。
这个模式非常适合用来设计像 AgentOutputParser 这样的抽象基类。
结合模板方法模式来看:
AgentOutputParser是一个抽象类,它定义了所有子类必须实现的parse方法。parse方法就是模板方法模式中“算法”的核心步骤,但这个步骤是抽象的,由子类去实现。get_format_instructions是一个可选方法,它提供了一个默认实现,子类可以选择是否重写。
这样,所有具体的解析器(如 JSONAgentOutputParser 或 ReActOutputParser)都可以继承这个类,并实现自己的解析逻辑,但都遵循统一的接口。
第三、模板方法模式在AgentOutputParser 代码中的体现
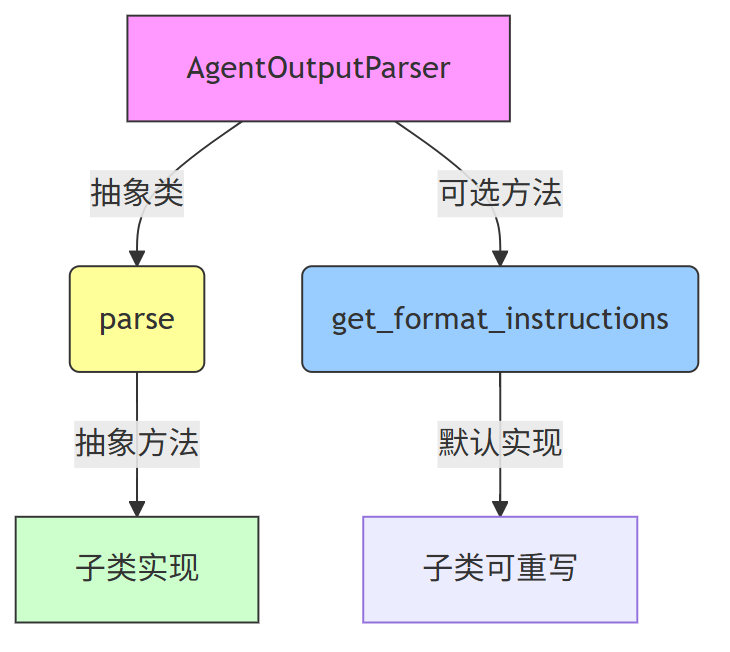
第四、总结
第一、AgentOutputParser 是一个抽象基类,使用了模板方法模式的核心思想:定义结构,延迟实现。
第二、它定义了 parse 这个抽象方法,强制子类必须实现解析逻辑。
第三、它提供了 get_format_instructions 的默认实现,子类可以选择是否重写。
第四、这种设计让不同类型的 Agent 可以拥有不同的输出解析方式,同时保持统一的接口,便于扩展和维护。
7.3 ZeroShotAgent实现分析
ZeroShotAgent是一种常用的Agent实现,它可以在没有预定义示例的情况下使用工具:
# langchain/agents/zero_shot.py
from typing import Any, Dict, List, Optional, Tuple, Union
from langchain.agents.agent import Agent, AgentOutputParser
from langchain.agents.agent_types import AgentType
from langchain.base_language import BaseLanguageModel
from langchain.callbacks.base import BaseCallbackManager
from langchain.chains import LLMChain
from langchain.prompts import BasePromptTemplate, PromptTemplate
from langchain.schema import AgentAction, AgentFinish, OutputParserException
class ZeroShotAgent(Agent):
"""零样本Agent,能够在没有预定义示例的情况下使用工具"""
@classmethod
def create_prompt(
cls,
tools: List[BaseTool],
prefix: str = DEFAULT_PREFIX,
suffix: str = DEFAULT_SUFFIX,
format_instructions: str = FORMAT_INSTRUCTIONS,
input_variables: Optional[List[str]] = None,
) -> BasePromptTemplate:
"""创建提示模板"""
tool_strings = "\n".join([f"{tool.name}: {tool.description}" for tool in tools])
tool_names = ", ".join([tool.name for tool in tools])
format_instructions = format_instructions.format(tool_names=tool_names)
template = "\n\n".join([prefix, tool_strings, format_instructions, suffix])
if input_variables is None:
input_variables = ["input", "agent_scratchpad"]
return PromptTemplate(template=template, input_variables=input_variables)
@classmethod
def _get_default_output_parser(cls, **kwargs: Any) -> AgentOutputParser:
"""获取默认的输出解析器"""
return ZeroShotAgentOutputParser()
@property
def observation_prefix(self) -> str:
"""观察结果的前缀"""
return "Observation: "
@property
def llm_prefix(self) -> str:
"""LLM思考的前缀"""
return "Thought: "
def _construct_scratchpad(
self, intermediate_steps: List[Tuple[AgentAction, str]]
) -> str:
"""构建思考过程的草稿本"""
thoughts = ""
for action, observation in intermediate_steps:
thoughts += f"{action.log}\n{self.observation_prefix}{observation}\n{self.llm_prefix}"
return thoughts
@classmethod
def from_llm_and_tools(
cls,
llm: BaseLanguageModel,
tools: List[BaseTool],
callback_manager: Optional[BaseCallbackManager] = None,
**kwargs: Any,
) -> "ZeroShotAgent":
"""从LLM和工具列表创建Agent"""
cls._validate_tools(tools)
prompt = cls.create_prompt(tools, **kwargs)
output_parser = kwargs.pop("output_parser", cls._get_default_output_parser())
return cls(
llm_chain=LLMChain(
llm=llm,
prompt=prompt,
callback_manager=callback_manager,
),
tools=tools,
output_parser=output_parser,
**kwargs,
)
def plan(
self,
intermediate_steps: List[Tuple[AgentAction, str]],
callbacks: Optional[BaseCallbackManager] = None,
**kwargs: Any,
) -> Union[AgentAction, AgentFinish]:
"""根据中间步骤和输入计划下一步行动"""
# 构建思考草稿本
thoughts = self._construct_scratchpad(intermediate_steps)
# 构建输入
inputs = {
"input": kwargs["input"],
"agent_scratchpad": thoughts,
**{k: v for k, v in kwargs.items() if k != "input"},
}
# 调用LLM生成下一步行动
output = self.llm_chain.predict(callbacks=callbacks, **inputs)
# 解析LLM输出
try:
return self.output_parser.parse(output)
except OutputParserException as e:
return AgentFinish(
return_values={"output": str(e)},
log=output,
)
ZeroShotAgent的核心是通过提示模板告诉LLM有哪些工具可用以及如何使用它们,然后LLM根据输入自主决定是否使用工具以及使用哪个工具。
第一、ZeroShotAgent 与 策略模式
策略模式是一种行为型设计模式,它允许你定义一系列算法或行为,并在运行时动态地选择其中一个。
它的核心思想是:将“行为”封装成独立的类,使得它们可以互相替换。
在 ZeroShotAgent 中,虽然没有显式地使用策略模式的类结构,但它的核心思想是类似的:
- LLM(语言模型)作为“策略”执行者,根据输入和提示模板决定下一步动作(调用哪个工具或直接输出结果)。
- 输出解析器(output_parser)也是一个策略,它决定了如何解析LLM输出的内容。
第二、ZeroShotAgent 的核心逻辑与策略模式的结合
我们可以把 ZeroShotAgent 看作一个“决策引擎”,它通过以下策略来决定下一步:
(1) 提示策略(Prompt Strategy):通过 create_prompt 构建提示模板,告诉LLM有哪些工具可用。
(2) 执行策略(LLM Strategy):调用LLM,让它根据提示决定下一步。
(3) 解析策略(Output Parsing Strategy):解析LLM的输出,判断是调用工具还是直接返回结果。
这些策略在运行时可以被替换,比如:
- 换不同的提示模板;
- 换不同的LLM;
- 换不同的输出解析器。
这正是策略模式的精髓所在。
第3、 图解ZeroShotAgent 核心流程
下面是一个简化版的 流程图,展示了 ZeroShotAgent 的核心流程 :
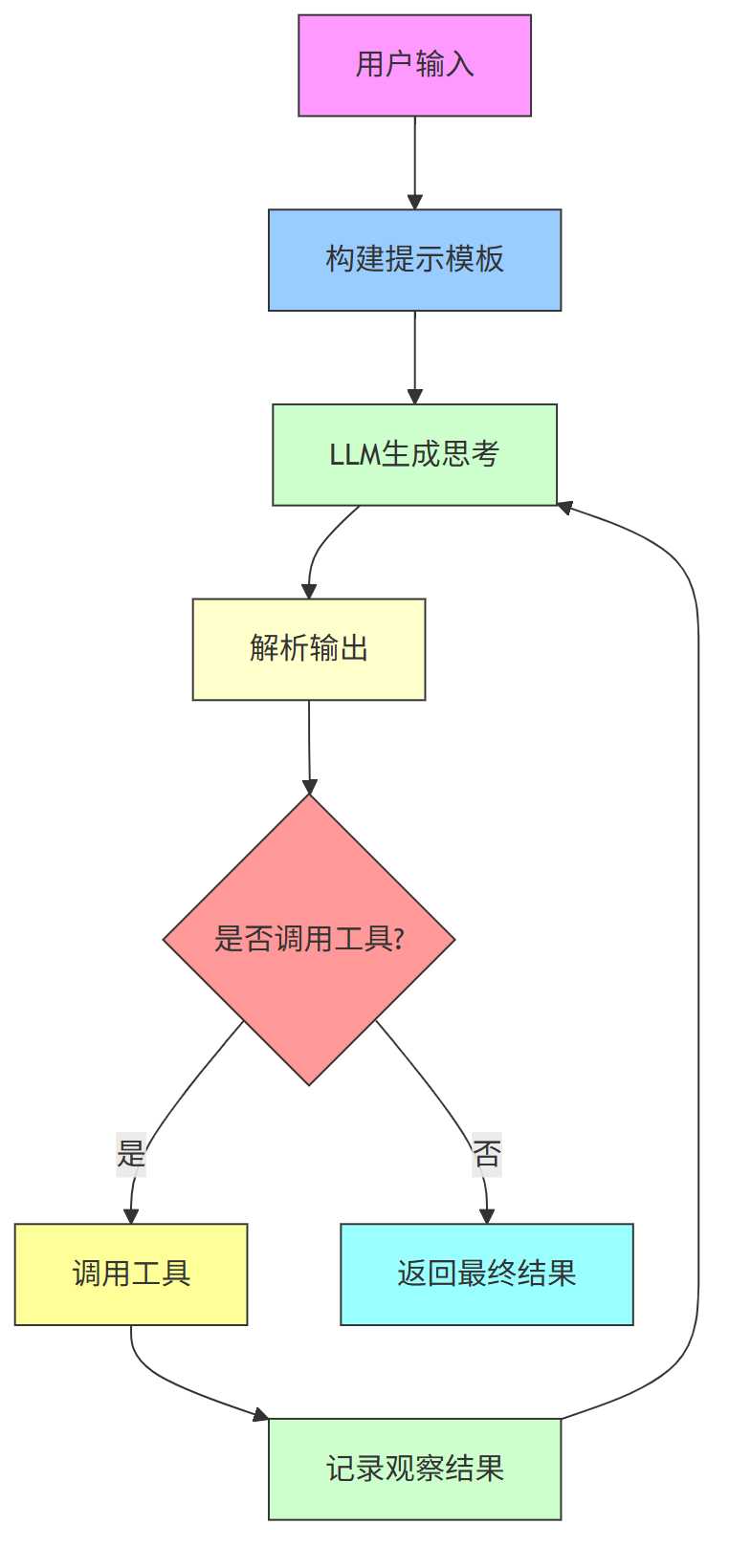
总结
通过策略模式的视角来看,ZeroShotAgent 是一个高度灵活的决策系统,它将不同的行为(提示生成、LLM调用、输出解析)抽象为可替换的策略,从而实现了在没有预定义示例的情况下,也能让LLM自主决定下一步操作。
这种设计使得系统具备良好的扩展性和可维护性,是AI Agent设计中非常典型的一种实现方式。
7.4 AgentExecutor实现分析
AgentExecutor负责执行Agent,管理工具调用和中间步骤:
# langchain/agents/agent_executor.py
from typing import Any, Dict, List, Optional, Tuple, Union
from langchain.agents.agent import Agent, AgentOutputParser
from langchain.agents.tools import BaseTool
from langchain.base_language import BaseLanguageModel
from langchain.callbacks.base import BaseCallbackManager
from langchain.chains.base import Chain
from langchain.schema import AgentAction, AgentFinish, OutputParserException
class AgentExecutor(Chain):
"""Agent执行器,负责执行Agent并管理工具调用"""
# Agent
agent: Agent
# 工具列表
tools: List[BaseTool]
# 最大迭代次数
max_iterations: Optional[int] = 15
# 是否返回中间步骤
return_intermediate_steps: bool = False
# 工具名称到工具的映射
tool_names: List[str]
# 工具名称到工具的映射
name_to_tool_map: Dict[str, BaseTool]
@property
def input_keys(self) -> List[str]:
"""返回期望的输入键"""
return self.agent.input_keys
@property
def output_keys(self) -> List[str]:
"""返回产生的输出键"""
return self.agent.output_keys
@classmethod
def from_agent_and_tools(
cls,
agent: Agent,
tools: List[BaseTool],
callback_manager: Optional[BaseCallbackManager] = None,
**kwargs: Any,
) -> "AgentExecutor":
"""从Agent和工具列表创建执行器"""
name_to_tool_map = {tool.name: tool for tool in tools}
tool_names = list(name_to_tool_map.keys())
return cls(
agent=agent,
tools=tools,
name_to_tool_map=name_to_tool_map,
tool_names=tool_names,
callback_manager=callback_manager,
**kwargs,
)
def _call(
self,
inputs: Dict[str, Any],
run_manager: Optional[CallbackManagerForChainRun] = None,
) -> Dict[str, Any]:
"""执行Agent"""
# 准备输入
intermediate_steps: List[Tuple[AgentAction, str]] = []
agent_inputs = inputs
# 获取终止消息
stop = agent_inputs.get("stop", None)
# 主循环
iterations = 0
while self._should_continue(iterations, intermediate_steps):
# 调用Agent规划下一步行动
next_step_output = self._take_next_step(
agent_inputs, intermediate_steps, run_manager=run_manager
)
# 如果Agent返回完成,直接返回结果
if isinstance(next_step_output, AgentFinish):
if self.return_intermediate_steps:
return {
**next_step_output.return_values,
"intermediate_steps": intermediate_steps,
}
else:
return next_step_output.return_values
# 否则,执行工具并记录结果
action = next_step_output
if run_manager:
run_manager.on_agent_action(action)
# 执行工具
observation = self._call_tool(action, run_manager=run_manager)
# 记录中间步骤
intermediate_steps.append((action, observation))
# 更新迭代次数
iterations += 1
# 如果达到最大迭代次数,返回错误
output = self.agent.return_stopped_response(
self.agent.llm_chain.llm, intermediate_steps, False
)
if self.return_intermediate_steps:
return {**output.return_values, "intermediate_steps": intermediate_steps}
else:
return output.return_values
def _take_next_step(
self,
inputs: Dict[str, Any],
intermediate_steps: List[Tuple[AgentAction, str]],
run_manager: Optional[CallbackManagerForChainRun] = None,
) -> Union[AgentAction, AgentFinish]:
"""获取下一步行动"""
# 调用Agent规划下一步
return self.agent.plan(
intermediate_steps,
callbacks=run_manager.get_child() if run_manager else None,
**inputs,
)
def _call_tool(
self,
action: AgentAction,
run_manager: Optional[CallbackManagerForChainRun] = None,
) -> str:
"""调用工具并返回观察结果"""
if action.tool not in self.name_to_tool_map:
return (
f"错误: 工具 '{action.tool}' 不存在。可用工具: {', '.join(self.tool_names)}"
)
# 获取工具
tool = self.name_to_tool_map[action.tool]
# 执行工具
observation = tool.run(
action.tool_input,
verbose=self.verbose,
callbacks=run_manager.get_child() if run_manager else None,
)
return observation
def _should_continue(
self, iterations: int, intermediate_steps: List[Tuple[AgentAction, str]]
) -> bool:
"""判断是否应该继续执行"""
if self.max_iterations is not None and iterations >= self.max_iterations:
return False
return True
AgentExecutor实现了Agent的执行逻辑,包括循环调用Agent规划下一步行动、执行工具、记录中间步骤等。它确保了整个执行过程的可控性和可观测性。
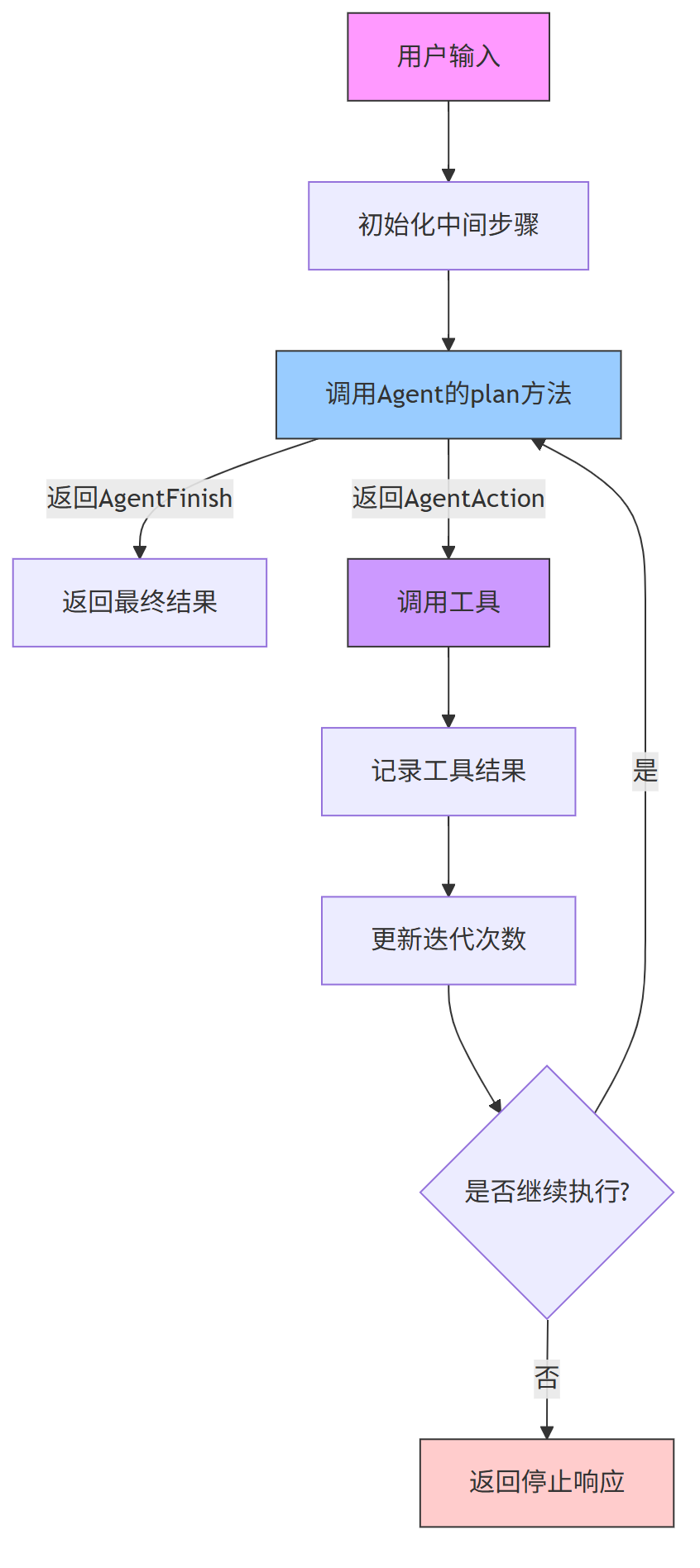
第一、AgentExecutor 策略模式介绍
我们 结合一个经典的设计模式——策略模式(Strategy Pattern),来分析 AgentExecutor 的代码,并配合一个简单 流程图 , 更好地理解它的执行逻辑。
策略模式是一种行为型设计模式,它允许你定义一系列算法(策略),将它们封装成独立的类,并使它们可以互相替换。这样可以在运行时根据不同的需求选择不同的“策略”来完成任务。
在 AgentExecutor 中,Agent 的行为(plan 方法)就是一种策略,它决定了下一步该做什么。而 AgentExecutor 本身就像是一个执行器,负责按照这个策略一步步执行下去。
第二、AgentExecutor 的核心流程
AgentExecutor 的主要职责是:
(1) 接收输入
(2) 循环调用 Agent 获取下一步动作
(3) 如果是完成动作(AgentFinish),就返回结果
(4) 如果是调用工具(AgentAction),就执行工具并记录结果
(5) 控制最大迭代次数,防止无限循环
第三、结合策略模式进行分析
在这个结构中:
- 策略接口:
Agent类中的plan()方法,定义了“下一步动作”的策略 - 具体策略:不同的
Agent实现类(如 ZeroShotAgent、StructuredAgent 等),提供不同的规划策略 - 上下文:
AgentExecutor本身,它持有 Agent 的引用,并根据其策略来执行流程
第四、AgentExecutor 流程图
下面是一个简化版的流程图,展示了 AgentExecutor 的核心逻辑流程 :
7.5 其他Agent实现
LangChain提供了多种Agent实现,包括:
(1) ReAct Agent:基于ReAct框架的Agent,能够在思考和行动之间进行循环
(2) SelfAskWithSearch Agent:专门用于知识检索的Agent,能够递归地提出问题
(3) Chat Agent:专为聊天模型设计的Agent,能够处理对话格式的输入和输出
(4) Structured Tools Agent:支持结构化工具输入的Agent,能够处理复杂的工具参数
这些Agent实现适用于不同的应用场景,开发者可以根据具体需求选择合适的Agent类型。
7.6 Agent的工作流程
当使用AgentExecutor执行一个任务时,整个工作流程大致如下:
(1) 用户提供输入,AgentExecutor将其传递给Agent
(2) Agent根据输入和当前状态,决定是直接返回结果还是调用工具
(3) 如果决定调用工具,Agent会生成一个AgentAction,描述要调用的工具和参数
(4) AgentExecutor执行该工具,并获取观察结果
(5) AgentExecutor将观察结果添加到中间步骤列表中,并将其反馈给Agent
(6) Agent根据新的中间步骤,再次决定下一步行动
(7) 重复步骤3-6,直到Agent返回AgentFinish,表示任务完成
(8) AgentExecutor返回最终结果
这种设计使得Agent能够根据任务需求,灵活地选择和使用工具,从而完成复杂的任务。
八、Tools组件实现原理
8.1 Tool抽象基类
Tools是LangChain中用于执行特定任务的组件,它封装了各种外部功能,使Agent能够扩展其能力。Tool的抽象基类定义在langchain/tools/base.py:
# langchain/tools/base.py
from abc import ABC, abstractmethod
from typing import Any, Callable, Dict, List, Optional, Sequence, Type, Union
from langchain.callbacks.base import BaseCallbackManager
from langchain.schema import BaseTool
class Tool(BaseTool, ABC):
"""Tool抽象基类,定义了所有工具必须遵循的接口"""
# 工具名称
name: str
# 工具描述
description: str
# 是否异步支持
is_async: bool = False
def __init__(
self,
name: str,
description: str,
func: Optional[Callable[..., str]] = None,
coroutine: Optional[Callable[..., str]] = None,
**kwargs: Any,
):
"""初始化工具"""
super().__init__(**kwargs)
self.name = name
self.description = description
self.func = func
self.coroutine = coroutine
@abstractmethod
def _run(self, *args: Any, **kwargs: Any) -> str:
"""同步运行工具的核心方法"""
pass
async def _arun(self, *args: Any, **kwargs: Any) -> str:
"""异步运行工具的核心方法,默认调用同步方法"""
return self._run(*args, **kwargs)
def run(
self,
tool_input: Union[str, Dict],
verbose: bool = False,
callbacks: Optional[BaseCallbackManager] = None,
) -> str:
"""运行工具"""
# 处理输入
if isinstance(tool_input, str):
parsed_input = (tool_input,)
kwargs = {}
else:
parsed_input =()
kwargs = tool_input
# 执行工具
if self.is_async:
# 如果是异步工具,使用asyncio运行
import asyncio
return asyncio.run(self._arun(*parsed_input, **kwargs))
else:
return self._run(*parsed_input, **kwargs)
async def arun(
self,
tool_input: Union[str, Dict],
verbose: bool = False,
callbacks: Optional[BaseCallbackManager] = None,
) -> str:
"""异步运行工具"""
if isinstance(tool_input, str):
parsed_input = (tool_input,)
kwargs = {}
else:
parsed_input =()
kwargs = tool_input
return await self._arun(*parsed_input, **kwargs)
所有具体的Tool实现都必须继承这个抽象基类,并实现_run方法(如果支持异步,还需实现_arun方法)。_run方法定义了工具的核心功能,接收输入参数并返回执行结果。
第一、Tool 的 模板方法模式简介
我们 结合一个最经典、与代码关系最紧密的设计模式 —— 模板方法模式(Template Method Pattern),来解读上面这段代码。
模板方法模式是一种行为型设计模式,它的核心思想是:在一个方法中定义算法的骨架,而将一些步骤延迟到子类中实现。这样可以在不改变算法结构的前提下,让不同的子类提供不同的实现。
第2、Tools 代码结构与模板方法模式的关系
我们来看这段代码的核心结构:
class Tool(BaseTool, ABC):
...
@abstractmethod
def _run(self, *args: Any, **kwargs: Any) -> str:
"""同步运行工具的核心方法"""
pass
async def _arun(self, *args: Any, **kwargs: Any) -> str:
"""异步运行工具的核心方法,默认调用同步方法"""
return self._run(*args, **kwargs)
def run(...):
# 处理输入、判断是否异步、执行工具
...
async def arun(...):
# 处理输入、调用_arun
...
这段代码中,run 和 arun 是模板方法,它们定义了执行工具的标准流程,而 _run 和 _arun 是留给子类去实现的具体行为。
模板方法模式体现在:
run方法定义了执行工具的流程(处理输入、判断是否异步、调用_run或_arun),但具体执行逻辑由_run实现。_run是一个抽象方法,强制子类必须实现。_arun有默认实现,调用_run,但子类可以重写它来支持异步逻辑。
第3、 Tool 的 模板方法模式总结
Tool类使用了 模板方法模式,定义了工具执行的统一流程。run和arun是模板方法,定义了执行流程。_run是抽象方法,必须由子类实现;_arun有默认实现,但也可以被重写。- 这种设计让所有工具在统一接口下,可以灵活实现自己的逻辑,同时保持调用方式一致。
8.2 内置工具示例
LangChain提供了多种内置工具,以下是一些常见的示例:
8.2.1 PythonREPLTool
# langchain/tools/python/tool.py
class PythonREPLTool(BaseTool):
"""Python REPL工具,允许执行Python代码"""
name = "python_repl"
description = (
"一个Python shell。适合执行Python代码。"
"输入应该是有效的Python代码。"
"如果您期望输出,应该打印它。"
)
def __init__(self):
super().__init__()
self.repl = PythonREPL()
def _run(self, code: str) -> str:
"""执行Python代码并返回结果"""
return self.repl.run(code)
async def _arun(self, code: str) -> str:
"""异步执行Python代码并返回结果"""
return await asyncio.to_thread(self._run, code)
8.2.2 SerpAPIWrapper
# langchain/tools/serpapi.py
class SerpAPIWrapper(BaseTool):
"""SerpAPI工具,用于搜索引擎查询"""
name = "serpapi"
description = (
"一个搜索引擎。适合回答关于当前事件的问题。"
"输入应该是一个搜索查询。"
)
def __init__(self, serpapi_api_key: Optional[str] = None):
super().__init__()
self.serpapi_api_key = serpapi_api_key or os.environ.get("SERPAPI_API_KEY")
if not self.serpapi_api_key:
raise ValueError("需要设置SERPAPI_API_KEY环境变量或提供serpapi_api_key参数")
def _run(self, query: str) -> str:
"""执行搜索查询并返回结果"""
params = {
"q": query,
"api_key": self.serpapi_api_key,
"engine": "google",
"gl": "us",
"hl": "en",
}
response = requests.get("https://serpapi.com/search", params=params)
response.raise_for_status()
return response.json()
async def _arun(self, query: str) -> str:
"""异步执行搜索查询并返回结果"""
return await asyncio.to_thread(self._run, query)
8.2.3 CalculatorTool
# langchain/tools/calculator.py
class CalculatorTool(BaseTool):
"""计算器工具,用于执行数学计算"""
name = "calculator"
description = (
"一个计算器。适合执行复杂的数学计算。"
"输入应该是一个数学表达式。"
)
def _run(self, query: str) -> str:
"""执行数学计算并返回结果"""
try:
# 使用ast来安全地评估数学表达式
return str(eval(query, {"__builtins__": None}, {}))
except Exception as e:
return f"错误: {str(e)}"
async def _arun(self, query: str) -> str:
"""异步执行数学计算并返回结果"""
return await asyncio.to_thread(self._run, query)
8.3 自定义工具
开发者可以根据需要创建自定义工具,只需继承BaseTool类并实现_run方法。以下是一个简单的示例:
from langchain.tools import BaseTool
class GetWeatherTool(BaseTool):
"""获取天气信息的工具"""
name = "get_weather"
description = (
"获取指定城市的当前天气信息。"
"输入应该是城市名称。"
)
def _run(self, city: str) -> str:
"""获取并返回城市的天气信息"""
# 实际实现中,这里会调用天气API
# 为简化示例,我们返回模拟数据
weather_data = {
"北京": "晴朗,25°C",
"上海": "多云,28°C",
"广州": "小雨,27°C",
"深圳": "多云,29°C",
}
if city in weather_data:
return f"{city}的当前天气是{weather_data[city]}"
else:
return f"抱歉,没有找到{city}的天气信息"
async def _arun(self, city: str) -> str:
"""异步获取并返回城市的天气信息"""
return await asyncio.to_thread(self._run, city)
8.4 工具的参数验证
LangChain支持对工具的输入参数进行验证,确保输入符合工具的要求。可以通过在工具类中定义args_schema属性来实现:
from langchain.tools import BaseTool
from pydantic import BaseModel, Field
class GetWeatherInput(BaseModel):
"""获取天气工具的输入参数"""
city: str = Field(..., description="城市名称")
class GetWeatherTool(BaseTool):
"""获取天气信息的工具"""
name = "get_weather"
description = (
"获取指定城市的当前天气信息。"
"输入应该是城市名称。"
)
args_schema: Type[BaseModel] = GetWeatherInput
def _run(self, city: str) -> str:
"""获取并返回城市的天气信息"""
# 实际实现中,这里会调用天气API
weather_data = {
"北京": "晴朗,25°C",
"上海": "多云,28°C",
"广州": "小雨,27°C",
"深圳": "多云,29°C",
}
if city in weather_data:
return f"{city}的当前天气是{weather_data[city]}"
else:
return f"抱歉,没有找到{city}的天气信息"
通过这种方式,工具会自动验证输入参数,并在输入不符合要求时抛出异常。
8.5 工具的异步支持
对于支持异步操作的工具,可以实现_arun方法,并将is_async属性设置为True:
from langchain.tools import BaseTool
class AsyncHTTPRequestTool(BaseTool):
"""异步HTTP请求工具"""
name = "http_request"
description = (
"发送HTTP请求并获取响应。"
"输入应该是一个包含URL和可选参数的字典。"
)
is_async: bool = True
async def _arun(self, params: dict) -> str:
"""异步发送HTTP请求并返回响应"""
url = params.get("url")
method = params.get("method", "GET")
headers = params.get("headers", {})
data = params.get("data", {})
if not url:
return "错误: 缺少URL参数"
async with aiohttp.ClientSession() as session:
async with session.request(method, url, headers=headers, json=data) as response:
return await response.text()
这样,当AgentExecutor调用这个工具时,会自动使用异步方式执行,提高系统的并发处理能力。
九、异步处理与并发
由于平台篇幅限制, 剩下的内容(5000字+),请参参见原文地址
原始的内容,请参考 本文 的 原文 地址

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)