白话GPU-03之围剿NVLink?CXL、UALink及产品一文详解
CXL的诞生源于一个关键的行业问题:传统PCIe接口在缓存一致性、内存共享和低延迟通信方面逐渐显露出不足。随着异构计算(CPU、GPU、FPGA及AI加速器)的迅猛发展,这些瓶颈日益突出。当谈及高速互联技术时,英伟达无疑占据了显著位置,其NVLink/NVSwitch及InfiniBand为全球互联技术的发展指明了方向,促使PCIe总线成为GPU互联的关键技术路径。天下苦英伟达久矣,全球的云服务、

一、CXL的起源与演进
CXL的诞生源于一个关键的行业问题:传统PCIe接口在缓存一致性、内存共享和低延迟通信方面逐渐显露出不足。随着异构计算(CPU、GPU、FPGA及AI加速器)的迅猛发展,这些瓶颈日益突出。当谈及高速互联技术时,英伟达无疑占据了显著位置,其NVLink/NVSwitch及InfiniBand为全球互联技术的发展指明了方向,促使PCIe总线成为GPU互联的关键技术路径。天下苦英伟达久矣,全球的云服务、芯片、网络设备厂商希望通过联合构建开放协议与标准来试图改变英伟达在GPU互联网技术与产品层面一家独大局面。
-
2019年:英特尔(Intel) 牵头,联合阿里巴巴、思科、戴尔EMC、Meta(Facebook)、谷歌、HPE(惠普企业)、华为和微软等科技巨头,共同成立了CXL联盟。同年,CXL 1.0/1.1规范发布,它基于PCIe 5.0物理层,引入了缓存一致性协议(CXL.cache)和内存扩展协议(CXL.mem)。 -
2020年:CXL 2.0发布,增加了对内存池化(Memory Pooling) 和交换机(Switch)架构的支持,允许多台主机共享内存资源,这是迈向资源灵活共享的关键一步。 -
2022年至2024年:CXL 3.0及相关版本(如3.1)发布,物理层更新至PCIe 6.0,带宽提升至64GT/s。更重要的是,CXL 3.0引入了真正的内存共享(Memory Sharing) 功能,允许多个设备同时访问同一内存地址空间,并支持更复杂的拓扑结构。
CXL在发展过程中,迅速赢得了业界的广泛支持。其竞争对手如Gen-Z和OpenCAPI联盟纷纷选择将其技术规范和资产转移给CXL联盟。这使得CXL事实上成为了行业统一的开放标准,避免了市场分裂(希望联合制衡英伟达)。
二、主导厂商与生态系统
CXL的成功离不开众多行业领导厂商的推动和支持。
1)核心发起与推动厂商CXL联盟的创始成员包括阿里巴巴、思科、戴尔EMC、Meta、谷歌、HPE、华为、英特尔和微软。这些巨头在数据中心、云计算和硬件设计领域的影响力为CXL的初期发展和推广提供了强大助力。
随后,AMD、Arm、三星、SK海力士、美光(Micron)、Marvell、Rambus等各大CPU、GPU、内存、存储和网络设备制造商也纷纷加入联盟。截至2024年底,CXL联盟已有超过250多个成员,几乎涵盖了数据中心基础设施所有关键领域的厂商。根据市场调研机构Yole的预测,到2025年,采用CXL协议的数据中心服务器占比达到60%左右,到2027年,这一比例将接近100%。
2)关键技术与产品提供商
在CXL技术和产品化方面,以下几类厂商尤为活跃:
-
IP供应商:这些公司提供CXL控制器IP,是芯片设计的基础。新思科技(Synopsys)、Cadence、Rambus是全球CXL控制器IP市场的主要服务商。 -
内存厂商:
CXL为内存扩展和池化带来了革命性的变化,内存大厂积极跟进。三星(Samsung)、SK海力士(SK Hynix)、美光(Micron) 等均已推出或宣布支持CXL的内存扩展产品。 -
中国厂商的参与:一些中国企业在
CXL生态中也开始布局。澜起科技发布了全球首款CXL内存扩展控制器芯片(MXC),并宣布其PCIe 5.0/CXL 2.0 Retimer芯片已成功量产。得润电子曾在互动平台表示具有CXL相关技术储备。三、CXL协议版本演进一览
三、CXL协议版本演进一览
CXL主要版本的演进及其核心特性:

四、CXL在GPU互联中的核心角色
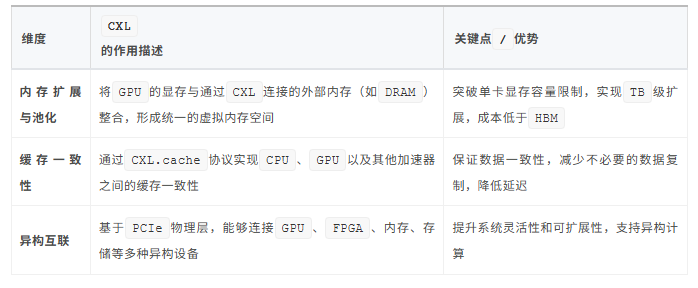
五、CXL、PCIe与NVLink技术对比
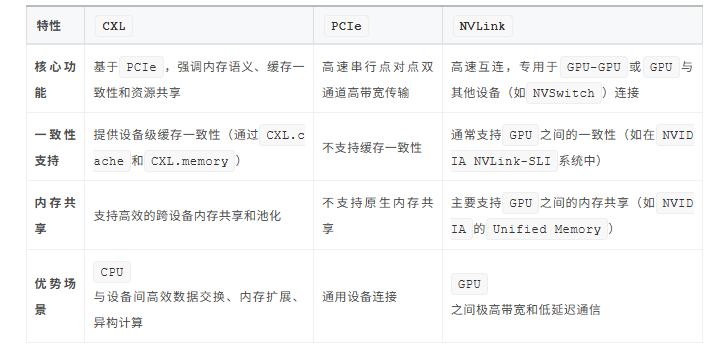
六、CXL在AI和高性能计算领域的应用前景
-
大规模
AI训练:对于训练千亿参数的大模型,CXL内存池可以存储优化器状态、梯度等大量数据,让GPU显存专注于存放当前计算所需的参数和激活值,从而显著提升训练效率。 -
AI推理与数据中心:在AI推理场景,CXL可以帮助GPU应对动态负载和更大的模型,避免因内存不足而性能下降。结合RDMA技术,CXL还能在更大范围内实现高效的数据搬运。 -
异构计算与资源池化:
CXL支持CPU、GPU、FPGA、内存、存储等设备的灵活组合和资源池化。通过CXL交换机(如国数集联的CMNS),可以实现跨机柜的资源共享和灵活调度,提高整个数据中心的资源利用率和灵活性。
七、CXL厂商与及市场产品

CXL技术生态正在快速发展,产品主要集中在内存扩展与池化方向,技术版本上CXL 2.0是当前产品的主流,而更先进的CXL 3.1产品也已开始亮相。
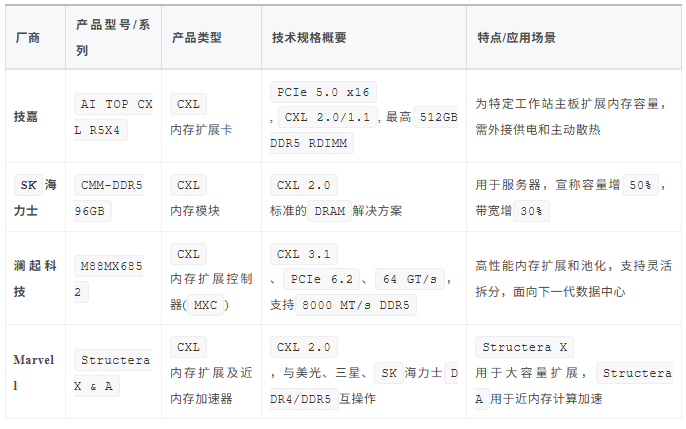
市场产品CXL技术版本要点:
-
CXL 2.0:这是当前众多已上市或送样产品采用的版本。它引入了内存池化(Memory Pooling)、同级连接(Peer-to-Peer)等关键特性,显著提升了内存的利用效率和灵活性。技嘉的扩展卡、SK海力士的CMM模块以及Marvell的Structera系列都支持CXL 2.0。 -
CXL 3.1:这是目前最新的版本之一(截至2025年9月)。它在CXL 3.0的基础上进一步完善,主要特性包括更高的带宽(通过PCIe 6.2物理层实现)、更低的延迟,并支持Fabric(交换网络)功能,允许更复杂的设备互联和更大规模的内存池化。澜起科技的M88MX6852芯片是此版本的典型代表。
从市场产品来看,所有产品均集中在内在扩展与池化方向,对于GPU互联涉足极为有限,似乎离NVLink尚远。
八、专注于AI加速器间互联的UALink
CXL从一开始就肩负的重大责任,参与的厂商涵盖GPU、CPU,到DDR内存,因此需要在技术层面同时兼顾对GPU、CPU、内存DDR等外设。因此,CXL功能最全,协议最多。但是有得必有失,协议越多开销就越大。因此,为进一步围剿英伟达,这些厂商计划针对AI加速器(GPU)间互联场景,开发拟定更专注的协议与标准。
2024年5月,AMD、Broadcom、Cisco、Google、HPE、Intel、Meta和Microsoft达成一致,将制定一项新的行业标准,专用于推动数据中心用纵向扩展人工智能(AI)系统连接的高速低延迟通信。该初始小组将定义并建立一个开放的行业标准,称为超加速器链路 (UALink),该标准将使AI加速器能够更有效地进行通信。
1、CXL与UALink技术对比
UALink专注于AI加速器(如GPU)之间的高速互连与规模化组网,而CXL则侧重于处理器(CPU)与加速器、内存之间高效、一致的互联与资源池化。两者都是为了解决现代计算,尤其是AI和高性能计算中的瓶颈,但关注点和技术路径不同。

UALink和CXL并非简单的竞争关系,它们更多是互补的,在未来数据中心中很可能协同工作:
-
CXL更关注的是“垂直”方向的整合,即在一个计算节点内部或之间,实现CPU、内存、加速器等资源的高效一致性与池化。 -
UALink则更关注“水平”方向的扩展,即如何将成千上万个加速器高效地连接起来形成一个庞大的计算池,专注于加速器之间的通信效率。
一个未来的异构计算系统,完全可以同时包含这两种技术:用CXL来实现CPU与加速器之间的紧密耦合和内存共享,同时用UALink来连接这些加速器,形成大规模计算集群。
2、CXL与UALink生态与现状
-
UALink:由UALink联盟(包括AMD、Intel、Google、Meta、微软、思科等众多行业巨头)推动,旨在打破英伟达NVLink在AI加速器互连领域的垄断,构建开放生态。其1.0规范已于2025年4月发布,首批支持UALink的商用硬件预计将在2026年问世。 -
CXL:由CXL联盟推动,也得到了业界广泛支持(Intel、AMD、ARM、三星、美光等)。目前CXL 2.0的产品(如内存扩展控制器)已经开始上市并完成互操作性测试,CXL 3.0/3.1规范也引入了更多高级特性(如多级交换、真正内存共享)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 27
27 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)