真得收藏!深度学习模型一网打尽!
本文系统介绍了深度学习领域的关键模型及其应用场景。从基础的感知机、多层感知机到CNN、RNN、Transformer等主流模型,再到GAN、VAE等生成模型,以及Q学习、DQN等强化学习方法,全面涵盖了计算机视觉、自然语言处理、序列分析等任务。文章还特别介绍了BERT、GPT、DALL·E等前沿模型,并提供了U-Net、YOLO等实用模型的工程应用场景。此外,文中还推广了一套AI科研入门学习方案,
前出了一期机器学习模型的文章受到不少同学的好评(没看过的可以点击图片查看)
所以今天给大家带来——深度学习模型篇,本文将为大家简洁而全面地解析关键深度学习模型,大家可以当成模型备忘录。
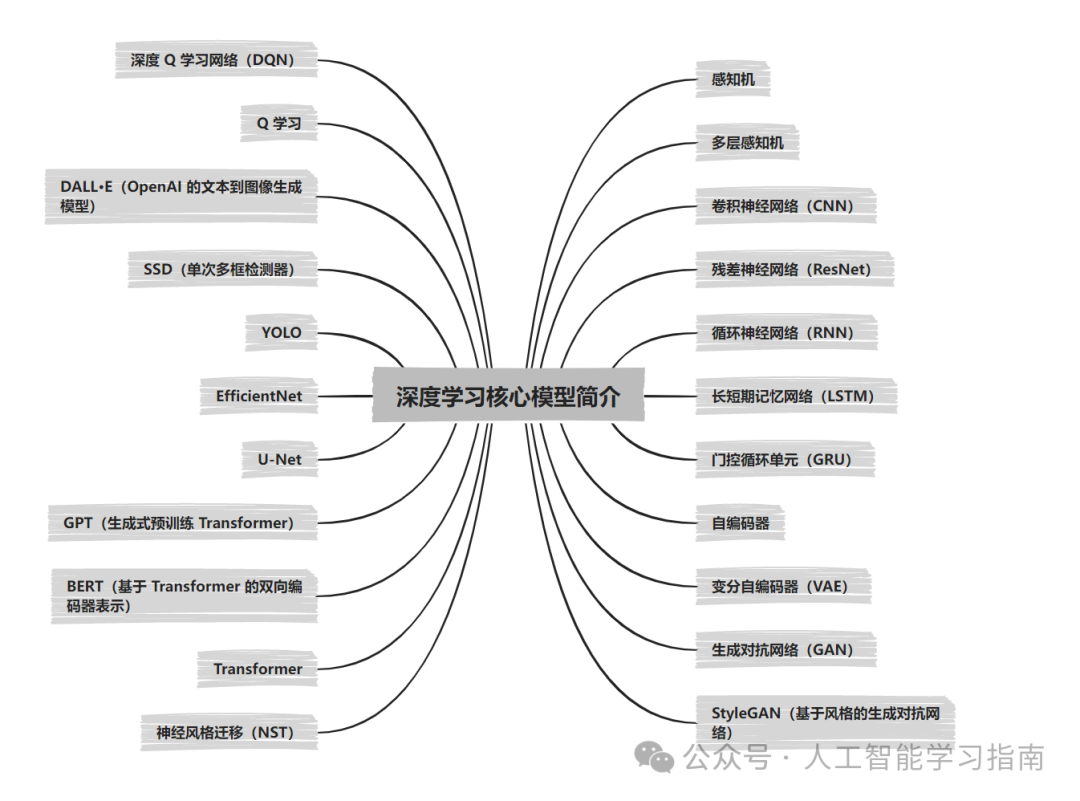
感知机
感知机是神经网络最基本的构建模块,常被称作人工神经元。
它由多个输入节点、一个加权求和函数以及一个决定输出的激活函数组成。
感知机旨在通过学习决策边界来解决二分类问题(例如区分猫和狗),该模型利用感知机学习算法更新权重,直至能够正确分类数据点。
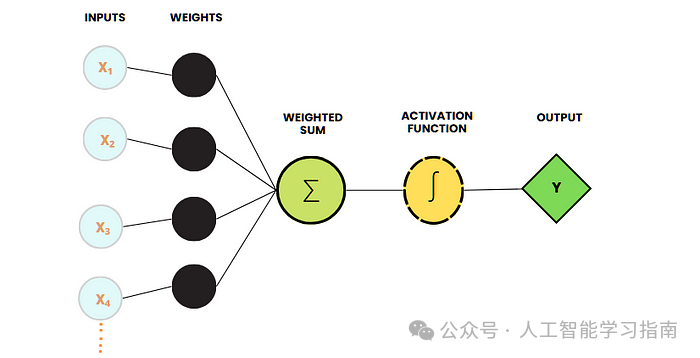
多层感知机
多层感知机(MLP)由三层或更多层构成,包括接收数据的输入层、学习复杂数据表示的一个或多个隐藏层,以及产生最终预测结果的输出层。
它使用 ReLU、Sigmoid 或 Tanh 之类的激活函数来引入非线性,从而能够捕捉复杂的数据模式。
多层感知机通过反向传播算法进行学习,在这个过程中,模型不断调整内部权重以最小化预测误差。
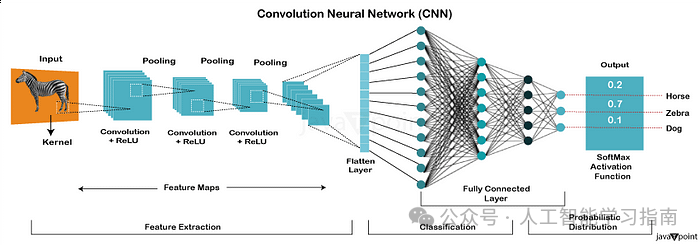
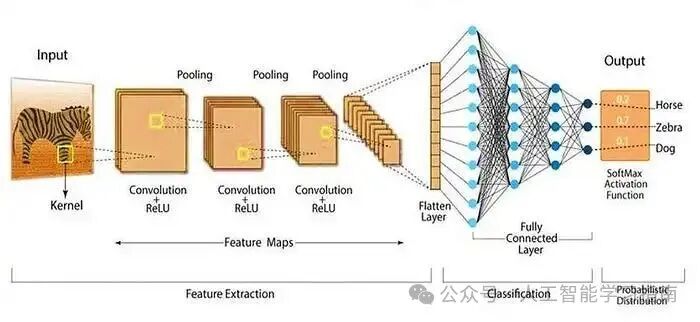
卷积神经网络(CNN)
卷积神经网络(CNN)是一种专门为处理网格状数据(如图像和视频)而设计的特殊神经网络。
受人类大脑视觉皮层的启发,CNN 能够自动从原始图像数据中提取边缘、形状和纹理等重要特征,无需人工进行特征工程。
CNN 的核心组件包括卷积层,它应用滤波器来检测模式。
池化层,它在保留重要信息的同时降低空间维度。
以及全连接层,它做出最终预测。
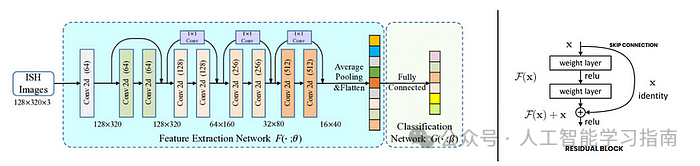
残差神经网络(ResNet)
残差神经网络(ResNet)是一种深度学习模型,旨在通过引入残差连接(或跳跃连接)来解决极深神经网络中的梯度消失问题。
在传统的深度网络中,梯度在经过多层传递后往往会逐渐减小,导致训练困难。
ResNet 通过允许梯度直接通过跳跃连接流动来解决这一问题,使模型能够在不降低性能的情况下训练极深的网络,核心思想是学习残差映射(输入与输出之间的差异),而非直接学习输出,从而使优化过程更加容易。
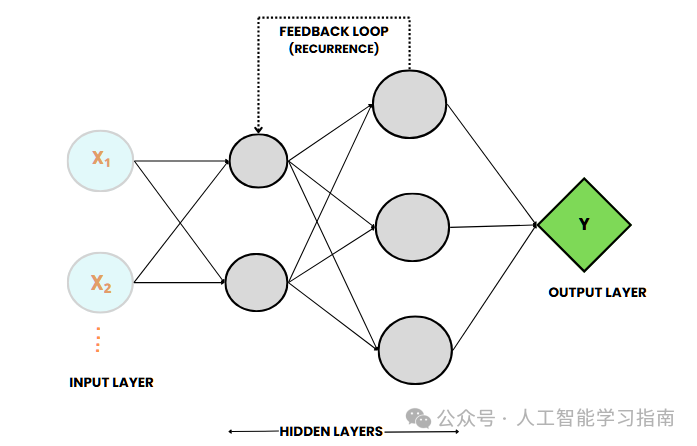
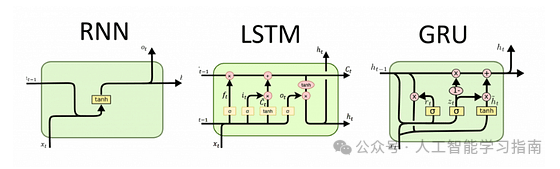
循环神经网络(RNN)
循环神经网络(RNN)是一种专门为处理序列数据(如时间序列、文本和音频)而设计的深度学习模型。
RNN 具有反馈回路,使其能够保留之前输入的信息,从而能够有效处理具有时间依赖性的任务。
这种类似记忆的行为使 RNN 能够理解数据的上下文,非常适合语言建模、语音识别和时间序列预测等应用。
标准的 RNN 往往难以处理长期依赖问题,这是由于梯度消失问题限制了其在长序列中捕捉信息的能力,为此引入了长短期记忆网络(LSTM)和门控循环单元(GRU)等变体,使 RNN 在序列任务中更加有效。
另外我们精心打磨了一套基于数据与模型方法的 AI科研入门学习方案(已经迭代过5次,即将迭代第6次),对于人工智能来说,任何专业,要处理的都只是实验数据,所以我们根据实验数据将课程分为了三种方向的针对性课程,包含时序、影像、AI+实验室,我们会根据你的数据类型来帮助你选择合适的实验室,根据规划好的路线学习 只需5个月左右(很多同学通过学习已经发表了 sci 一区及以下、和同等级别的会议论文)学习形式为直播+录播,多位老师为你的论文保驾护航。
文章中所有的数据和资料,可添加小助手无偿分享~
扫码添加小助手即可无偿获取~
也可以关注“AI技术星球”公众号,关注后回复“221C”获取。

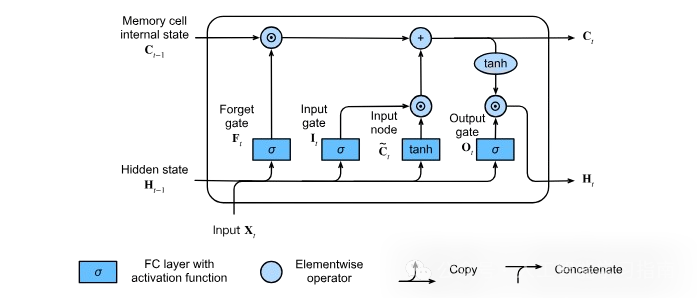
长短期记忆网络(LSTM)
长短期记忆网络(LSTM)是一种先进的循环神经网络(RNN),旨在克服标准 RNN 在捕捉长期依赖方面的局限性(梯度消失问题)。LSTM 采用了一种独特的架构,包含输入门、遗忘门和输出门,以及一个记忆细胞来控制信息的流动。
遗忘门决定丢弃哪些信息,输入门用新数据更新细胞状态,输出门确定下一个隐藏状态。
这种机制使 LSTM 能够捕捉序列数据中的长期依赖关系,对于需要长时间保留上下文的任务非常有效。
门控循环单元(GRU)
门控循环单元(GRU)是循环神经网络(RNN)的另一种先进变体,旨在解决梯度消失问题并提高训练效率。
与使用三个门的 LSTM 不同,GRU 只有两个门——更新门和重置门,更新门控制需要保留多少之前的信息,重置门决定应该遗忘多少过去的信息。
在训练速度至关重要且不影响性能的任务中,GRU 通常比 LSTM 更受青睐。
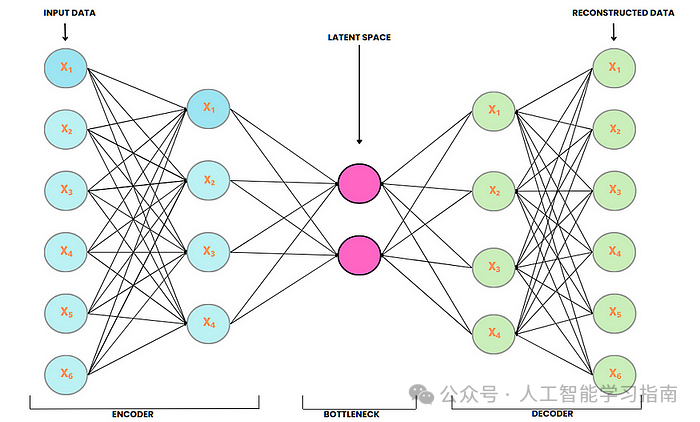
自编码器
自编码器是一种无监督的深度学习模型,旨在将输入数据压缩到低维潜在空间,然后再将其重构回原始形式。
它由两个主要部分组成——编码器,将输入压缩为紧凑的表示。
解码器,从该表示中重构原始输入。
自编码器常用于降维、异常检测、图像去噪以及生成新的数据样本。
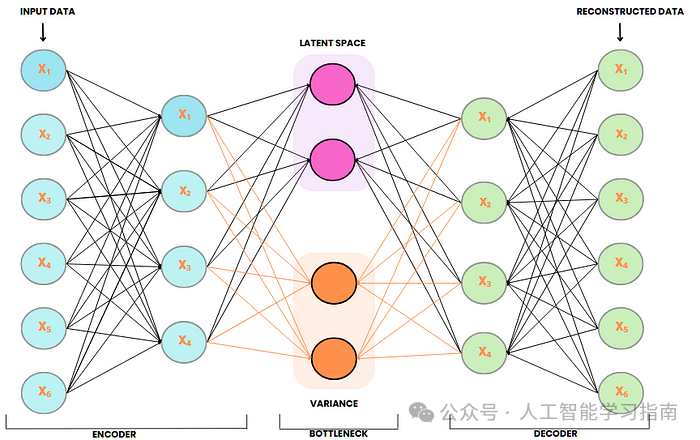
变分自编码器(VAE)
变分自编码器(VAE)是一种生成式深度学习模型,旨在学习输入数据的潜在表示,并生成与训练数据相似的新数据样本。
与标准自编码器不同,VAE 通过学习一个概率潜在空间引入随机性,编码器输出的是均值(μ)和方差(σ),而非固定的表示。
在训练过程中,从这些分布中随机采样潜在向量,通过解码器生成多样化的输出。
这使得 VAE 在图像生成、数据增强、异常检测和潜在空间探索等任务中非常有效。
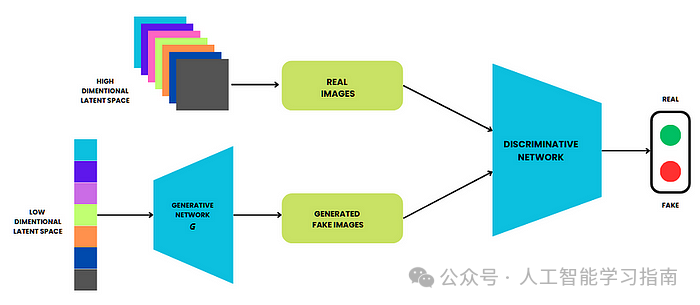
生成对抗网络(GAN)
生成对抗网络(GAN)由两个神经网络组成——生成器和判别器,它们在零和博弈中相互竞争。
生成器从随机噪声中创建逼真的合成数据,而判别器则试图区分真实数据和生成的数据,随着训练的进行,生成器不断改进,直到能够生成判别器无法与真实数据区分的高度逼真的数据。
GAN 广泛应用于图像生成、深度伪造创建、数据增强和风格迁移等领域,是生成式深度学习中最强大的模型之一。
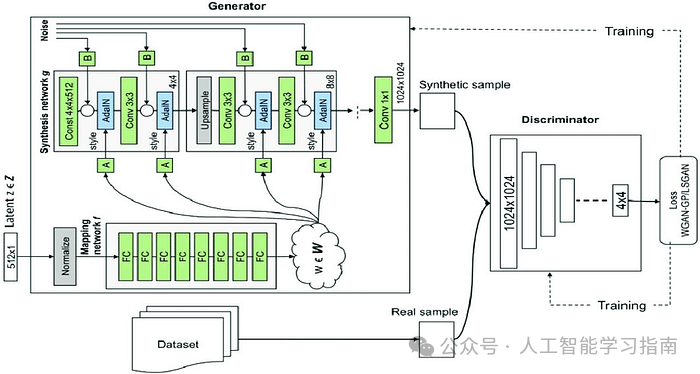
StyleGAN(基于风格的生成对抗网络)
StyleGAN 是一种先进的生成对抗网络(GAN),专门用于高质量图像生成,尤其是在人脸合成方面。
与传统 GAN 不同,StyleGAN 引入了一种基于风格的生成器架构,其中潜在向量(输入噪声)首先被转换为风格表示,使模型能够控制不同的视觉属性,如年龄、发型、面部表情和背景。
该架构还使用了一种称为自适应实例归一化(AdaIN)的技术来控制这些风格变化,从而生成超逼真且可定制的图像。
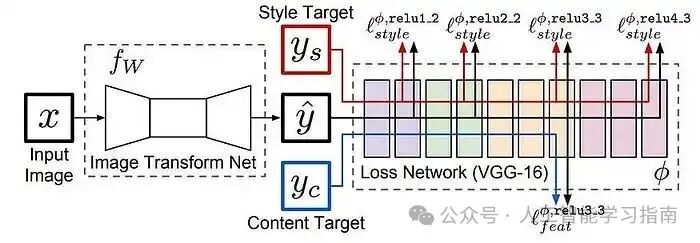
神经风格迁移(NST)
神经风格迁移(NST)是一种深度学习技术,它将一幅图像(风格图像)的艺术风格应用到另一幅图像(内容图像)的内容上,从而创建出视觉上吸引人的混合图像。
它使用通常在大规模图像数据集上预训练的卷积神经网络(CNN)来提取和操作图像的内容和风格表示。
该过程涉及最小化一个结合了内容损失(保留图像结构)和风格损失(捕捉艺术纹理)的损失函数,NST 广泛应用于艺术生成、照片风格化和创意图像处理等领域。
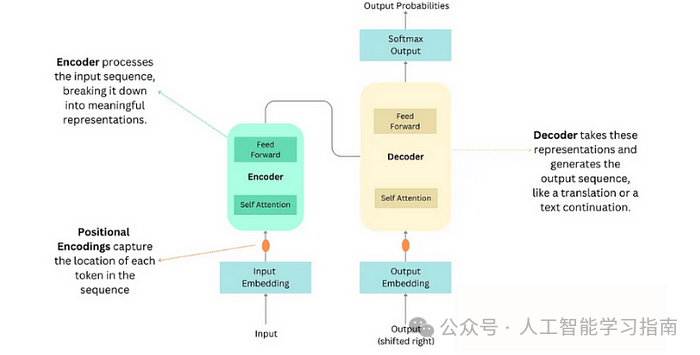
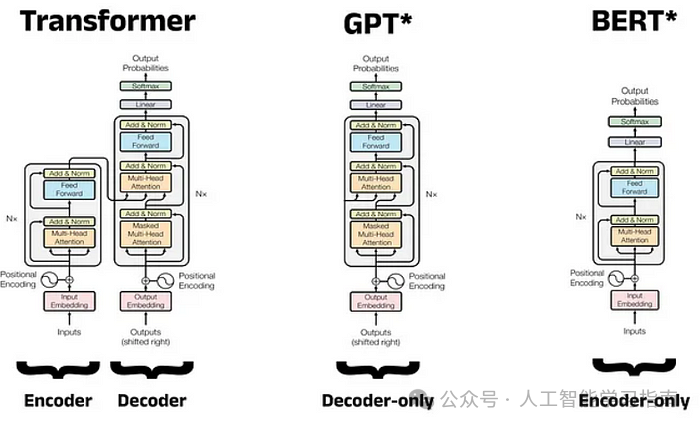
Transformer
Transformer 是一种用于处理序列数据(如文本或音频)的深度学习模型,无需使用循环或卷积。
相反,它采用了一种自注意力机制,使模型能够同时查看所有输入单词,并理解它们之间的相互关系,无论它们在序列中出现的位置如何。
该模型有两个主要部分——编码器,用于理解输入数据。
解码器,根据编码器的理解生成输出。
Transformer 广泛应用于 BERT、GPT 和 T5 等先进的自然语言处理模型中,因为它们速度快且效果显著。
BERT(基于 Transformer 的双向编码器表示)
BERT 是一种基于 Transformer 架构的预训练深度学习模型,旨在从左右两个方向理解句子中单词的上下文(双向)。
与传统的顺序处理文本的模型不同,BERT 使用自注意力机制,通过一次性考虑整个输入序列来捕捉上下文含义。
它在大规模文本语料库上进行预训练,任务包括掩码语言建模(MLM)和下一句预测(NSP),从而能够生成深度的上下文嵌入。
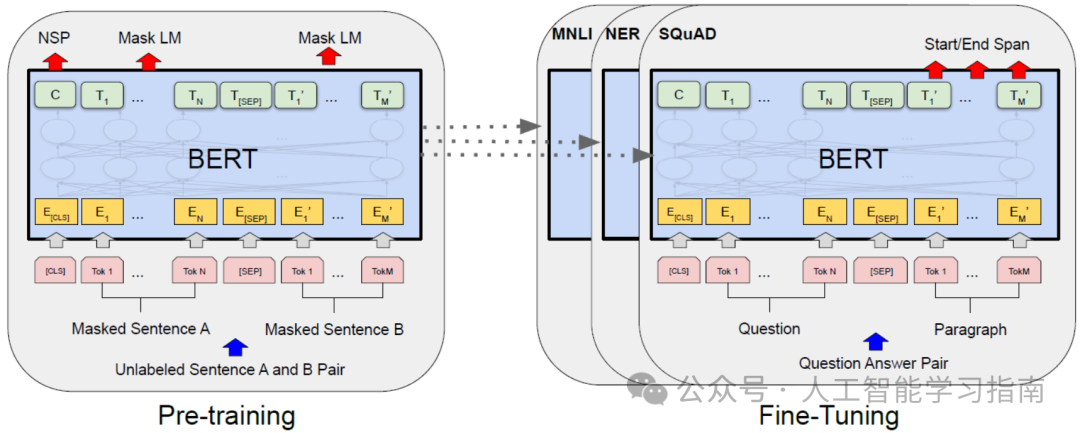
GPT(生成式预训练 Transformer)
GPT 是一种基于 Transformer 架构的深度学习模型,主要用于生成文本、完成内容以及理解语言。
与从两个方向查看文本的 BERT 不同,GPT 从左到右逐个单词处理文本,能够根据前面的单词生成清晰且有意义的文本。
它在大规模文本数据上进行训练,以预测句子中的下一个单词,使其在聊天机器人、文本摘要和代码生成等任务中非常有效,GPT 的一个著名示例是 OpenAI 的 ChatGPT。
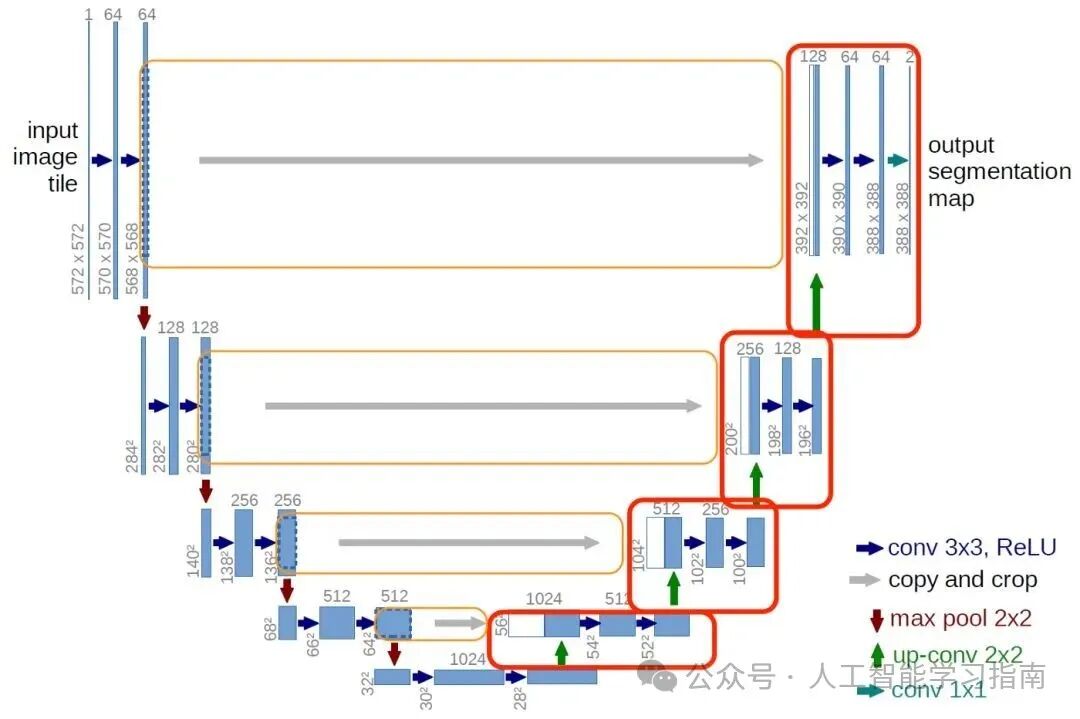
U-Net
U-Net 是一种主要用于图像分割的深度学习模型,在医学图像分析中尤为常用。
其 U 形架构由两部分组成——编码器,用于捕捉重要特征并减小图像尺寸;解码器,用于重建具有清晰分割细节的图像。
U-Net 还使用跳跃连接将编码器的低层特征传输到解码器,从而保留图像细节,这使得它在医学图像分割、目标检测和卫星图像分析等任务中非常有效。
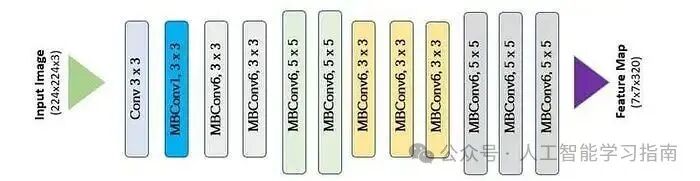
EfficientNet
EfficientNet 是一种用于图像分类的深度学习模型,在计算量较小的情况下也能实现高准确率。
与传统模型仅通过增加网络规模不同,EfficientNet 采用复合缩放方法——均匀缩放网络的深度、宽度和分辨率,以获得更好的性能。这使得它比 ResNet 或 VGG 等更大的模型更快、更高效,因此在图像分类、目标检测和医学图像分析等任务中备受欢迎。
YOLO
YOLO是一种用于图像和视频中实时目标检测的深度学习模型,与传统模型需要多步检测物体不同,YOLO 能够一次性完成检测,速度极快且效率极高。
它通过将图像划分为网格,并一次性预测物体及其位置,从而能够同时检测多个物体,这种速度使 YOLO 非常适合视频监控、自动驾驶和目标跟踪等实时应用。
SSD(单次多框检测器)
SSD(单次多框检测器)是一种用于图像和视频中实时目标检测的深度学习模型。
与传统模型需要两步检测物体不同,SSD 能够一次性完成检测,速度快且效率高,它使用多个特征图来检测不同大小的物体,从而能够准确处理小物体和大物体。
SSD 广泛应用于自动驾驶汽车、视频监控和需要速度和准确性的实时目标跟踪等领域。

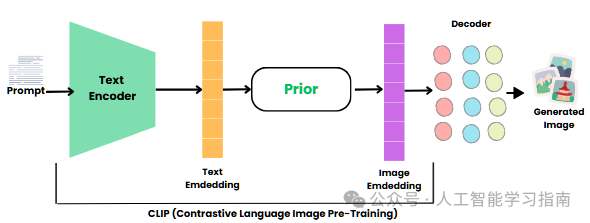
DALL·E(OpenAI 的文本到图像生成模型)
DALL·E 是 OpenAI 开发的一种生成式深度学习模型,能够根据文本描述生成逼真的图像(文本到图像生成)。
基于 GPT(生成式预训练 Transformer)架构构建,DALL·E 使用 Transformer 来理解文本提示并生成相应的视觉输出。
DALL·E 以仅根据文本输入就能生成高质量、多样化和创造性的视觉内容而广受认可。
Q 学习
Q 学习是一种强化学习技术,机器通过试错来学习。一个“智能体”(如机器人或游戏角色)与环境交互,尝试不同的动作,并根据其选择获得奖励或惩罚。
随着时间的推移,它通过将经验存储在 Q 表中来学习最佳动作,这种方法常用于游戏人工智能、自动驾驶汽车和交易机器人等领域,帮助它们自主做出明智的决策。
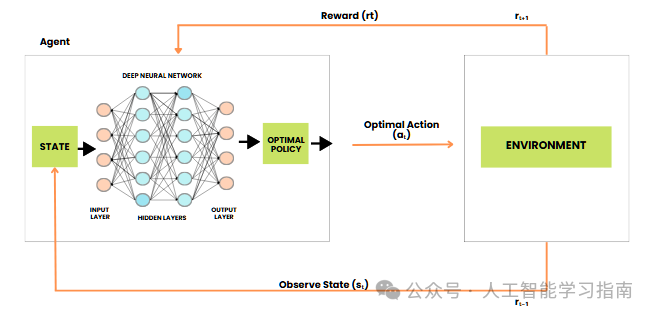
深度 Q 学习网络(DQN)
深度 Q 学习网络(DQN)是一种深度强化学习模型,它将 Q 学习(一种流行的强化学习算法)与深度神经网络(DNN)相结合,使智能体能够在复杂环境中学习最优动作。
与使用 Q 表存储状态 - 动作值的 Q 学习不同,DQN 使用神经网络来近似这些值,从而能够处理高维状态空间(如游戏中的图像),DQN 还结合了经验回放和目标网络等技术来稳定训练。
另外我们精心打磨了一套基于数据与模型方法的 AI科研入门学习方案(已经迭代过5次,即将迭代第6次),对于人工智能来说,任何专业,要处理的都只是实验数据,所以我们根据实验数据将课程分为了三种方向的针对性课程,包含时序、影像、AI+实验室,我们会根据你的数据类型来帮助你选择合适的实验室,根据规划好的路线学习 只需5个月左右(很多同学通过学习已经发表了 sci 一区及以下、和同等级别的会议论文)学习形式为直播+录播,多位老师为你的论文保驾护航。
文章中所有的数据和资料,可添加小助手无偿分享~
扫码添加小助手即可无偿获取~
也可以关注“AI技术星球”公众号,关注后回复“221C”获取。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)