【论文精读】OAgents: An Empirical Study of Building Effective Agents
【论文精读】OAgents: An Empirical Study of Building Effective Agents
·
【论文精读】OAgents: An Empirical Study of Building Effective Agents
一、论文基本信息
| 项目 | 内容 |
|---|---|
| 标题 | OAgents: 构建高效智能体的实证研究 |
| 作者 | OPPO AI Agent Team |
| 机构 | OPPO |
| 发表年份 | 2025年(根据日期推断) |
| 论文链接 | arXiv:2506.15741v2 |
| 代码仓库 | https://github.com/OPPO-PersonalAI/OAgents |
| 核心方法 | OAgents (一个模块化、开源的智能体框架) |
| 关键词 | 语言智能体 (Language Agents), 智能体框架 (Agent Framework), 实证研究 (Empirical Study), GAIA基准, 工具使用 (Tool Use), 规划 (Planning), 记忆 (Memory) |
二、研究背景与动机(Translation & Analysis)
翻译:
近年来,智能体(Agent)因其解决传统上需要人类干预的复杂任务的潜力而受到广泛关注。然而,尽管相关研究和开源框架激增,但当前的智能体AI研究实践缺乏严谨性和科学性。具体表现为:缺乏标准化的设计和实现细节(如规划、记忆、工具使用等关键组件在不同框架中差异巨大),报告的结果难以复现(由于评估设置不一致或框架配置未公开)。这种碎片化现状破坏了该领域的科学严谨性,研究结果无法被可靠地比较或继承。
分析:
- 问题定位:论文一针见血地指出了当前智能体研究领域的核心痛点——“炼丹”现象严重。大家热衷于提出新架构,但在实验的标准化、可复现性和公平比较方面做得很差。
- 研究动机:旨在通过系统的实证研究,厘清哪些组件和设计真正有效,并提供一种稳健的评估协议,从而推动智能体研究从“工程技巧”走向“科学实践”。
- 价值主张:这不仅关乎一个SOTA模型,更关乎为整个领域建立科学的研究范式。
三、研究目标与方法(Translation & Analysis)
核心目标
- 实证研究:在GAIA和BrowseComp基准上,系统性地研究智能体关键组件(规划、记忆、工具使用、测试时扩展等)不同设计选择的影响。
- 提出稳健评估协议:解决当前评估中因运行次数、错误处理、结果聚合方式不统一导致的巨大方差问题。
- 构建与开源框架:基于研究发现,构建并开源一个模块化的、高性能的智能体框架——OAgents,为未来研究提供基础和公平比较的平台。
方法论:双轴分析范式
论文提出了一个新颖的分析框架,从两个正交的维度评估智能体:
- 事实获取能力 (FAC - Factual Acquisition Capacity):衡量智能体从外部动态信息流中获取、验证和整合领域知识的能力。这主要由工具(Tools) 组件决定。
- 逻辑推理保真度 (LRF - Logical Reasoning Fidelity):衡量智能体在复杂问题解决过程中保持严格因果关系和推理链的能力。这由规划(Plan)、记忆(Memory)和测试时扩展(Test-Time Scaling) 组件协同决定。
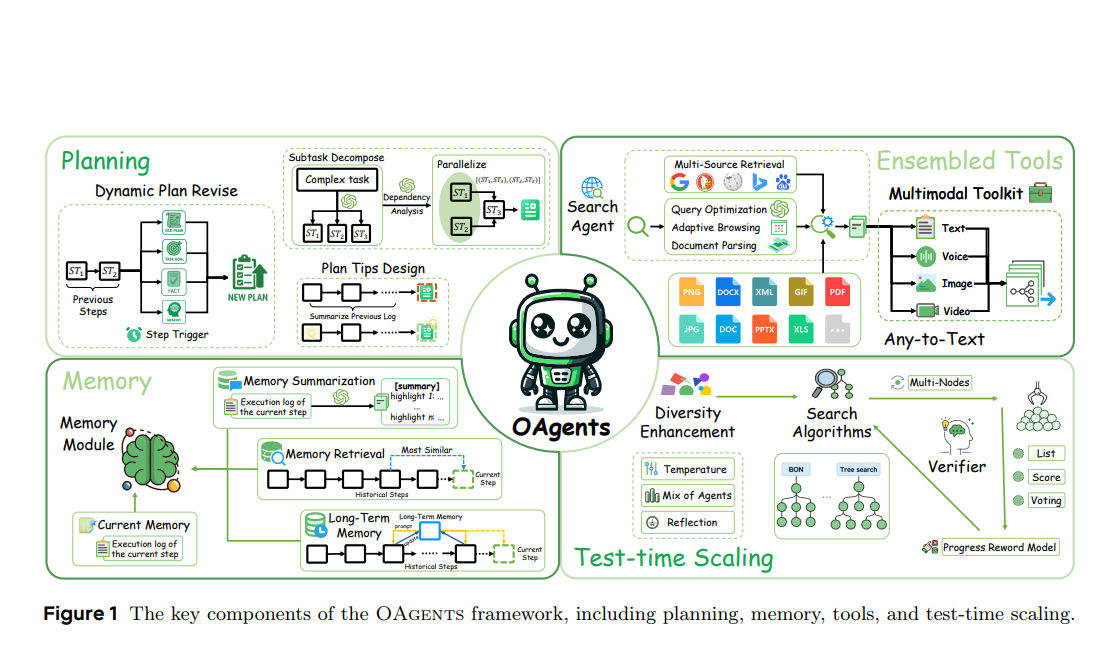
四、OAgents框架核心组件(Translation & Analysis)
OAgents是一个模块化的框架,其核心组件与上述双轴分析对应,如下图所示:
1. 事实获取能力 (FAC) 组件
- 多模态工具包:超越传统的单一模态转换,实现文本、语音、图像、视频的同步和跨模态语义解析。
- 搜索智能体:
- 多源检索:集成多个搜索引擎(Google, Bing)和档案系统(Wayback Machine),根据查询的时间约束和领域需求智能选择源。
- 查询优化:通过“反射(Reflect)”(解决语义模糊)和“扩展(Expand)”(生成词形/语义变体)组成闭环优化管道。
- 极简浏览:将复杂操作简化为三个原子功能:
Search(查询),Visit(访问),Read(阅读),降低认知负荷。
2. 逻辑推理保真度 (LRF) 组件
- 动态规划生成:
- 战略计划审查:不再执行静态计划,而是每N步根据最新观察结果动态修订计划。
- 子任务分解:将主目标分解为相互依赖的子任务,构建依赖图,动态调度无冲突的子任务集合并进行一致性验证。
- 计划提示 (Plan Tips):从历史执行轨迹中分析总结出启发式规则,作为软约束注入规划过程,避免已知陷阱。
- 记忆增强知识系统:包含一个分层记忆模块:
- 当前记忆:短期缓冲区,存储临时有序的任务特定信息。
- 记忆摘要:将原始经验序列转换为结构化的语义单元。
- 向量化检索:通过向量相似度从记忆中检索有益的历史信息。
- 长期记忆:整合历史推理过程中的关键见解,生成后续优化建议。
- 测试时扩展 (TTS):
- 多样性增强:采用混合智能体(Mixture-of-Agents)采样策略,结合多个LLM策略,生成更广泛的解决方案空间。
- 优化:引入基于过程的奖励函数,评估任务进展、错误处理和效率,提供细粒度反馈。
- 奖励建模:集成反射机制,评估中间步骤,实现实时自我纠正。
五、实验结果与讨论(Translation & Analysis)
1. 主实验结果(GAIA基准)
表:各智能体框架在GAIA基准上的性能对比
| 框架 | 类型 | Avg. | Level 1 | Level 2 | Level 3 |
|---|---|---|---|---|---|
| OAgents (Pass@3) | 开源 (本工作) | 73.93 | 83.02 | 74.42 | 53.85 |
| Langfun Agent | 闭源 | 71.52 | 83.02 | 68.60 | 57.69 |
| TraseAgent | 闭源 | 70.30 | 83.02 | 69.77 | 46.15 |
| OWL–Workforce | 开源 | 69.09 | 84.91 | 67.44 | 42.31 |
| OAgents (Pass@1) | 开源 (本工作) | 66.67 | 77.36 | 66.28 | 46.15 |
| … | … | … | … | … | … |
| Smolagents (复现) | 开源 | 49.70 | 54.72 | 53.49 | 26.92 |
分析:
- SOTA性能:OAgents (Pass@3) 取得了73.93%的平均准确率,超越了所有列出的开源和闭源框架,证明了其设计的有效性和鲁棒性。
- 复现性危机:论文中尝试复现已有的开源框架(Open Deep Research → Smolagents),发现性能出现显著下降。这强烈佐证了其核心论点:当前智能体研究的复现性极差,缺乏标准化评估使得报告结果水分很大。
- Level 3 性能:在最具挑战性的Level 3任务上,OAgents表现优异(53.85%),表明其在复杂多步推理任务上的强大能力。
2. 组件消融实验
- FAC组件:
- 多模态工具包将跨模态任务准确率从48.15% 提升至 74.07%(表2)。
- 多源搜索(5个引擎)和查询优化(Reflect-Expansion)策略均带来了显著的性能提升(表3,4,5)。
- LRF组件:
- 动态规划:战略审查、子任务分解和计划提示均带来提升,其中计划提示的贡献最大(+14.54%),证明了从历史错误中学习的重要性(表7)。
- 记忆系统:分层记忆的各个组件(摘要、检索、长期记忆)逐步带来性能提升,其中长期记忆的贡献最显著(图2)。
- 测试时扩展 (TTS):Best-of-N采样策略比反射(Reflection)更稳定有效。BO4取得了最佳整体性能(+5.19%),但复杂任务(Level 3)的提升仍是挑战(图3)。
3. BrowseComp基准上的评估
OAgents在更具挑战性的BrowseComp基准上也取得了显著提升,验证了其搜索智能体在复杂网页浏览任务上的有效性(表8)。
六、结论与贡献(Translation & Analysis)
主要结论
- 实证研究价值:通过系统的消融实验,明确了智能体各组件(尤其是计划提示和多源搜索)的有效性,并揭示了当前研究中存在的复现性危机。
- 评估标准化:提出了更稳健的评估协议(如明确Pass@K的标准),为领域的公平比较奠定了基础。
- 框架有效性:OAgents框架在GAIA和BrowseComp上实现了最先进的性能(尤其是 among开源项目),证明了其设计理念的成功。
核心贡献
- 提出了OAgents框架:一个高性能、模块化、开源的智能体框架,为社区提供了强大的基础和实验平台。
- 进行了系统的实证研究:揭示了构建高效智能体的关键因素和最佳实践,为未来研究提供了清晰的指导。
- 指出了复现性问题并提出了解决方案:强调了评估标准化的重要性,并提供了减少实验方差的实用技术(如优化推理参数和多数投票策略)。
- 开源了代码和提示词:论文附录提供了大量核心组件的详细提示词(Prompts),极大地促进了透明度和可复现性。
附:关键术语中英对照表
| 英文术语 | 中文术语 | 释义 |
|---|---|---|
| Agentic AI / Language Agents | 智能体 / 语言智能体 | 能够理解复杂指令、规划、使用工具并执行任务以达成目标的AI系统。 |
| OAgents | OAgents框架 | 本文提出的一个模块化、开源的智能体框架。 |
| GAIA Benchmark | GAIA基准 | 一个评估通用AI助手在需要推理、多模态处理和工具使用的真实世界问题中表现的基准。 |
| BrowseComp | BrowseComp基准 | 一个专注于评估网页浏览能力的更具挑战性的基准。 |
| Factual Acquisition Capacity (FAC) | 事实获取能力 (FAC) | 智能体从外部获取、验证和整合知识的能力,主要由工具组件决定。 |
| Logical Reasoning Fidelity (LRF) | 逻辑推理保真度 (LRF) | 智能体在推理过程中保持逻辑一致性和正确性的能力,由规划、记忆和测试时扩展组件决定。 |
| Planning | 规划 | 智能体为达成目标而制定行动方案的过程。 |
| Memory | 记忆 | 智能体存储、摘要和检索过去经验信息的能力。 |
| Tool Use | 工具使用 | 智能体调用外部工具(如搜索引擎、计算器、代码解释器)的能力。 |
| Test-Time Scaling (TTS) | 测试时扩展 (TTS) | 在推理(测试)阶段通过多次采样、反射等策略提升性能的技术。 |
| Pass@K | Pass@K指标 | 在K次独立尝试中至少有一次产生正确答案的概率,是评估智能体性能的常用指标。 |
| ReAct | ReAct框架 | “Reason + Act”的缩写,一种协同推理和行动的智能体交互范式。 |
| Reproducibility | 可复现性 | 其他研究者能够使用相同的代码和数据得到与原文报告相似结果的程度。 |
| Ablation Study | 消融实验 | 通过移除模型的某些组件来研究其贡献度的实验方法。 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)