PyBrain机器学习实战:PyBrain强化学习入门与实践
本文介绍了使用PyBrain库实现强化学习的基础知识。主要内容包括:1)强化学习核心概念(智能体、环境、奖励等);2)PyBrain库的安装与基本结构;3)通过迷宫寻路案例演示完整实现流程,包括环境定义、智能体构建、SARSA算法训练和结果评估。代码展示了如何训练智能体在9×9迷宫中找到目标位置,并可视化状态值函数。实验结果表明,经过1000次训练后,智能体能在15步内从随机起点导航至目标点。该教
PyBrain入门实践:强化学习入门
学习目标
本课程将引导学员了解强化学习的基本概念,包括环境、代理、奖励等核心要素,并通过PyBrain库实现一个简单的强化学习任务。通过本课程的学习,学员可以学习如何构建强化学习模型,并解决实际问题。
相关知识点
- PyBrain强化学习入门
学习内容
1 PyBrain强化学习入门
1.1 强化学习基础
强化学习是一种通过与环境的交互来学习最优行为策略的机器学习方法。在强化学习中,有一个智能体(Agent)通过与环境(Environment)的交互来学习如何采取行动以最大化某种累积奖励(Reward)。这种学习方式与监督学习和无监督学习不同,它不依赖于标记数据,而是通过试错来学习。
1.1.1 强化学习的基本元素
- 智能体(Agent):执行动作的主体,可以是一个软件程序或一个机器人。
- 环境(Environment):智能体所处的外部世界,可以是物理世界或虚拟世界。
- 状态(State):环境在某一时刻的状态,可以是连续的或离散的。
- 动作(Action):智能体在某一状态下可以采取的行为。
- 奖励(Reward):智能体执行动作后从环境中获得的即时反馈,用于评估动作的好坏。
- 策略(Policy):智能体根据当前状态选择动作的规则。
- 价值函数(Value Function):评估在给定状态下采取某个动作的长期收益。
- 模型(Model):对环境动态特性的预测,用于规划。
1.1.2强化学习的过程
强化学习的过程可以概括为以下几个步骤:
- 初始化:智能体处于初始状态。
- 选择动作:根据当前策略选择一个动作。
- 执行动作:智能体执行选定的动作,环境状态发生变化。
- 接收奖励:智能体从环境中接收奖励。
- 更新策略:根据奖励更新策略,以优化未来的决策。
- 重复:重复上述过程,直到达到某个终止条件。
1.1.3 PyBrain的基本结构
PyBrain库的主要组成部分包括:
- 数据结构:如
SupervisedDataSet用于监督学习,ReinforcementDataSet用于强化学习。 - 学习算法:如
BackpropTrainer用于神经网络的反向传播训练,Q用于Q学习。 - 环境:如
BlackBox用于模拟环境。 - 代理:如
Agent用于定义智能体的行为。 - 任务:如
EpisodicTask用于定义任务的执行方式。 - 实验:如
Experiment用于运行实验并收集数据。
1.1.4 PyBrain库安装
PyBrain(Python-Based Reinforcement Learning, Artificial Intelligence and Neural Network Library)是一个用于机器学习和神经网络的Python库,特别适合于强化学习任务。PyBrain提供了丰富的工具和算法,使得构建和训练强化学习模型变得简单。
首先,这里需要获取PyBrain的源码库,获取方式如下:
注意:pip安装的
PyBrain版本最新为0.3.0,与本课程不适配,需要编译0.3.3版本的包。PyBrain自2015年发布0.3.3版本以来就没再进行过版本更新,其源码中很多scipy引用的功能模块在当前已经全部移动到了numpy中,因此这里提供下载的PyBrain源码已经过改造,将所有原本涉及到的scipy引用替换为了numpy,直接编译即可。
!wget https://model-community-picture.obs.cn-north-4.myhuaweicloud.com/ascend-zone/notebook_codes/3e6601522ee211f09e19fa163edcddae/pybrain.zip --no-check-certificate
!unzip pybrain.zip
进入到源码包路径开始编译安装:
%cd pybrain/
import sys
%pip install wheel==0.44.0
%pip install ./
%cd ../
1.2 实现一个简单的强化学习任务
这里将使用PyBrain实现一个简单的强化学习任务,即让一个智能体学会在迷宫中找到出口。
1.2.1 定义环境
这里创建一个9×9的迷宫二维数组mazearray,其中1表示墙壁,0表示可通行路径。然后使用这个迷宫数组和目标位置坐标(7, 7)(即第8行第8列)初始化了一个Maze环境对象,用于后续的路径规划或强化学习等相关任务。
# 创建迷宫数组
mazearray = np.array(
[[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 0, 0, 1, 0, 0, 0, 0, 1],
[1, 0, 0, 1, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 0, 1, 0, 1],
[1, 0, 0, 1, 0, 1, 1, 0, 1],
[1, 0, 0, 0, 0, 0, 1, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 0, 1],
[1, 0, 0, 0, 0, 0, 0, 0, 1],
[1, 1, 1, 1, 1, 1, 1, 1, 1]]
)
env = Maze(mazearray, (7, 7))
1.2.2 定义智能体
然后使用PyBrain强化学习库实现了一个在迷宫环境中训练智能体的完整流程。通过定义MDPMazeTask任务,创建基于动作值表的控制器,使用SARSA强化学习算法,构建智能体并进行实验。经过1000次训练循环(每次循环包含100个交互步骤),智能体学习到从任意位置到目标位置(7,7)的最优策略。最后,代码可视化了智能体学习到的状态值函数,以灰度图形式展示迷宫中每个位置的价值估计,颜色越亮表示该位置的预期累积奖励越高。
# 创建任务
task = MDPMazeTask(env)
# 创建动作值表作为控制器
controller = ActionValueTable(81, 4)
controller.initialize(1.)
# 使用SARSA学习器
learner = SARSA()
# 创建智能体
agent = LearningAgent(controller, learner)
# 创建实验
experiment = Experiment(task, agent)
# 训练智能体
for i in range(1000):
experiment.doInteractions(100)
agent.learn()
agent.reset()
# 可视化智能体在迷宫环境中学习到的状态值函数
pylab.gray()
pylab.ion()
state_values = controller.params.reshape(81, 4).max(1).reshape(9, 9)
pylab.pcolor(state_values)
pylab.colorbar()
pylab.show()
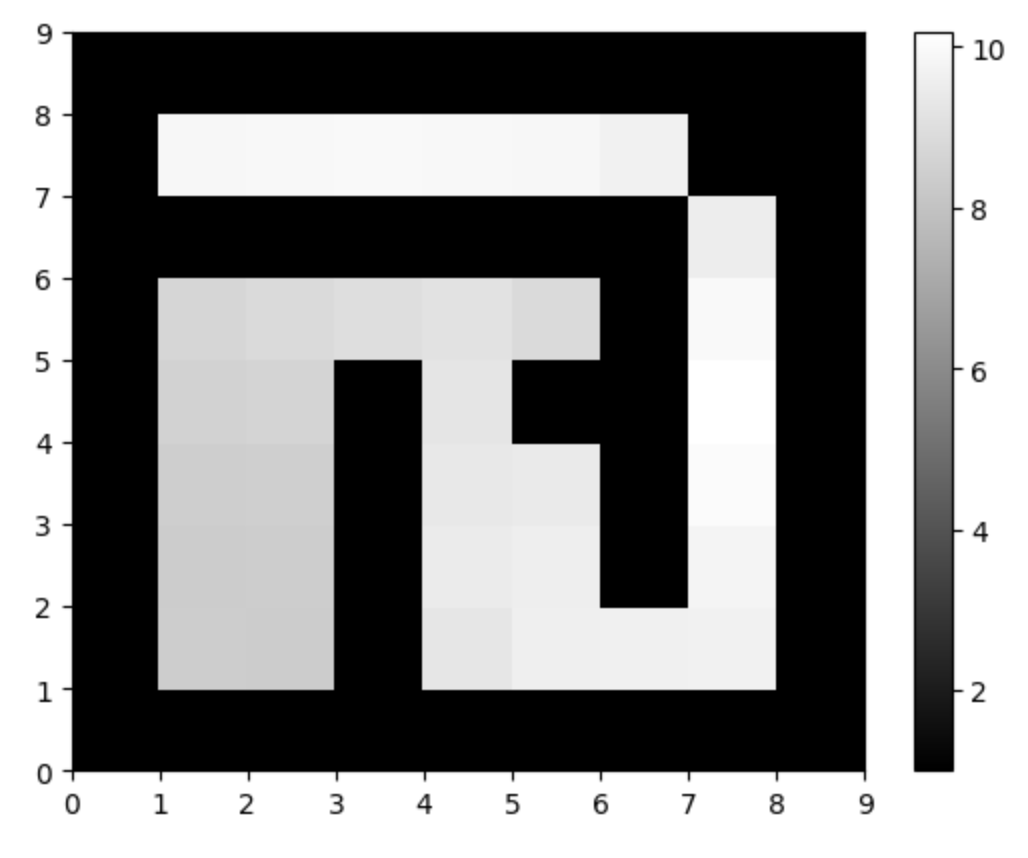
最后代码可视化的智能体学习到的状态值函数,以灰度图形式展示迷宫中每个位置的价值估计,颜色越亮表示该位置的预期累积奖励越高。
1.2.3 运行实验
最后创建一个实验并运行它,让智能体在迷宫中学习如何找到出口。这里对训练好的智能体进行评估,通过10次独立实验测试其从随机起始点导航至目标位置的能力。每次实验中,智能体在迷宫中最多尝试100步,代码记录并打印智能体的路径决策过程,包括到达目标的步数、路径长度以及前20个关键坐标点。若智能体成功到达目标位置(7,7),则提前结束当前轮次并输出成功信息。
# 评估智能体 - 随机起始点
for i in range(10):
print(f"\n评估轮次 {i+1}:")
# 重置环境和智能体
env.reset()
agent.reset()
# 获取初始状态并告知智能体
state = task.getObservation()
agent.integrateObservation(state)
# 获取目标位置的坐标
goal_x, goal_y = env.goal # 直接获取坐标元组
# 手动收集交互历史
episode = []
for step in range(100):
action = agent.getAction() # 获取动作
# 执行动作并获取下一个状态
task.performAction(action)
next_state = task.getObservation()
reward = task.getReward()
# 记录状态-动作对
episode.append((state, action, reward, next_state))
# 更新智能体的观察
agent.integrateObservation(next_state)
# 转换状态ID为坐标
state_id = int(state) # 确保状态是整数
x, y = state_id // env.mazeTable.shape[1], state_id % env.mazeTable.shape[1]
# 检查是否到达目标位置
if (x, y) == (goal_x, goal_y):
print(f"在步骤 {step+1} 到达目标位置 ({goal_x}, {goal_y})")
break
# 更新状态
state = next_state
# 打印路径
path = [step[0] for step in episode]
print(f"路径长度: {len(path)}")
# 打印路径的坐标表示
path_coordinates = [(s // 9, s % 9) for s in path]
new_path_coordinates = [(int(x[0]), int(y[0])) for x, y in path_coordinates] # 转换为 (x, y) 形式
print(f"路径坐标: {new_path_coordinates[:20]}")
评估轮次 1:
在步骤 15 到达目标位置 (7, 7)
路径长度: 15
路径坐标: [(5, 3), (5, 4), (4, 4), (3, 4), (2, 4), (2, 5), (1, 5), (1, 6), (1, 7), (2, 7), (3, 7), (4, 7), (5, 7), (6, 7), (7, 7)]
评估轮次 2:
在步骤 19 到达目标位置 (7, 7)
路径长度: 19
路径坐标: [(3, 1), (4, 1), (5, 1), (5, 2), (5, 3), (5, 4), (4, 4), (3, 4), (2, 4), (2, 5), (1, 5), (1, 6), (1, 7), (2, 7), (3, 7), (4, 7), (5, 7), (6, 7), (7, 7)]
评估轮次 3:
在步骤 11 到达目标位置 (7, 7)
路径长度: 11
路径坐标: [(2, 4), (2, 5), (1, 5), (1, 6), (1, 7), (2, 7), (3, 7), (4, 7), (5, 7), (6, 7), (7, 7)]
评估轮次 4:
在步骤 9 到达目标位置 (7, 7)
路径长度: 9
路径坐标: [(1, 5), (1, 6), (1, 7), (2, 7), (3, 7), (4, 7), (5, 7), (6, 7), (7, 7)]
评估轮次 5:
在步骤 20 到达目标位置 (7, 7)
路径长度: 20
路径坐标: [(2, 1), (3, 1), (4, 1), (5, 1), (5, 2), (5, 3), (5, 4), (4, 4), (3, 4), (2, 4), (2, 5), (1, 5), (1, 6), (1, 7), (2, 7), (3, 7), (4, 7), (5, 7), (6, 7), (7, 7)]
评估轮次 6:
在步骤 12 到达目标位置 (7, 7)
路径长度: 12
路径坐标: [(3, 4), (2, 4), (2, 5), (1, 5), (1, 6), (1, 7), (2, 7), (3, 7), (4, 7), (5, 7), (6, 7), (7, 7)]
评估轮次 7:
在步骤 18 到达目标位置 (7, 7)
路径长度: 18
路径坐标: [(4, 1), (5, 1), (5, 2), (5, 3), (5, 4), (4, 4), (3, 4), (2, 4), (2, 5), (1, 5), (1, 6), (1, 7), (2, 7), (3, 7), (4, 7), (5, 7), (6, 7), (7, 7)]
评估轮次 8:
在步骤 15 到达目标位置 (7, 7)
路径长度: 15
路径坐标: [(5, 5), (5, 4), (4, 4), (3, 4), (2, 4), (2, 5), (1, 5), (1, 6), (1, 7), (2, 7), (3, 7), (4, 7), (5, 7), (6, 7), (7, 7)]
评估轮次 9:
在步骤 14 到达目标位置 (7, 7)
路径长度: 14
路径坐标: [(5, 4), (4, 4), (3, 4), (2, 4), (2, 5), (1, 5), (1, 6), (1, 7), (2, 7), (3, 7), (4, 7), (5, 7), (6, 7), (7, 7)]
评估轮次 10:
在步骤 11 到达目标位置 (7, 7)
路径长度: 11
路径坐标: [(2, 4), (2, 5), (1, 5), (1, 6), (1, 7), (2, 7), (3, 7), (4, 7), (5, 7), (6, 7), (7, 7)]
从输出可以看到智能体在不同起始条件下的导航策略,均找到合理路径到达(7, 7)终点。通过本课程的学习,学员可以了解强化学习的基本概念,并使用PyBrain库实现了一个简单的强化学习任务。希望这些知识能够帮助学员在未来的项目中应用强化学习技术,解决更复杂的问题。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 6
6 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)