《Learning Langchain》阅读笔记13-Agent(1):Agent Architecture
摘要: Agent 的核心是“能行动”,涉及决策能力、可选方案和环境信息。基于 LLM 的 Agent 应用通过 Tool Calling(提供可选工具)和 Chain-of-Thought(分步推理)实现决策。LangGraph 是 LangChain 团队开发的框架,通过有向图(节点=执行单元,边=数据流/条件)结构化 Agent 流程,支持循环、分支等复杂逻辑。示例展示了搜索和计算工具的调用
Agent 可以最简单地定义为“能行动的东西”。实际上,行动这个词比表面上看起来要更丰富一些:
- 行动需要一定的能力来决定做什么。
- 决定做什么意味着有不止一种可能的行动方案。毕竟,没有选择的决定根本不是决定。
- 为了做出决定,agent 还需要访问有关外部环境(代理本身之外的一切)的信息。
一个 agentic LLM 应用程序必须使用 LLM 从一个或多个可能的行动方案中进行选择,给定一些关于当前世界状态的上下文或一些期望的下一个状态。这些属性通常通过混合两种提示技术来实现:
- **Tool calling:**在 prompt 中包含 LLM 可以使用的外部函数列表(即它可以决定采取的行动),并在它生成的输出中提供有关如何格式化其选择的说明。
- **Chain-of-thought:**当给LLMs下达通过将复杂问题分解成需要依次执行的细粒度步骤来进行推理的指令时,它们“会做出更好的决策”。这通常是通过添加类似于“一步一步地思考”的指令或包括问题和它们的分解成几个步骤/行动的示例来实现的。
LangGraph基础预备知识
LangGraph 是什么?
LangGraph 是 LangChain 团队开发的一个框架,用于把 LLM(大语言模型)、工具(Tools)、状态(State)组合成 有向图 (Graph)。
图里的节点(Node)代表执行单元(如模型推理、工具调用),边(Edge)代表数据流或条件跳转。
它的核心优势:
- 结构化:把复杂的 Agent 流程抽象成图,便于维护和扩展。
- 可控性:通过边和条件函数(Conditional Edges)精确控制调用顺序。
- 可组合:支持循环(model ↔ tools)、分支(条件边)、并行节点等。
基本组成部分
-
StateGraph
- 图的构造器,定义整个 Agent 的数据流。
-
State
- 共享状态,通常是一个字典(TypedDict),记录消息、工具结果等。
-
Node(节点)
-
执行单元,比如:
-
model_node→ 调用 LLM -
ToolNode→ 调用绑定的工具
-
-
-
Edge(边)
- 描述节点之间的连接关系。可以是普通边,也可以是条件边。
-
tools_condition
- 内置条件函数:检查 LLM 输出是否包含工具调用,如果是就去
tools节点,否则结束。
- 内置条件函数:检查 LLM 输出是否包含工具调用,如果是就去
运行流程示意
假设用户输入:
“帮我算一下 (13*7+5)/2 的结果是多少?”
执行过程:
-
START → model:模型读到用户消息,发现是数学计算。
-
tools_condition = True:模型请求调用
calculator工具。 -
model → tools:
ToolNode调用计算器,返回结果50.5。 -
tools → model:结果传回模型。
-
model 输出:模型生成自然语言回复 “结果是 50.5”。
-
tools_condition = False:没有新工具调用 → 图结束。
构建LangGraph agent
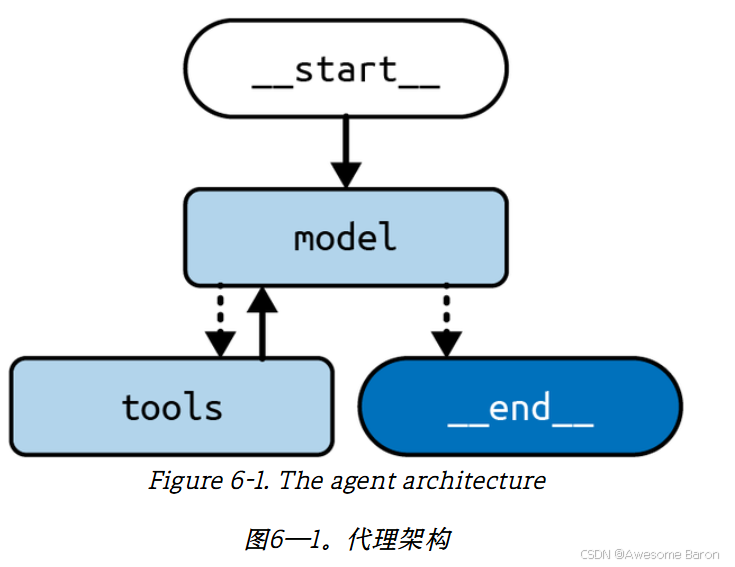
我们使用了 LangGraph 自带的两个便捷函数。ToolNode 在我们的图中作为一个节点;它会执行在最新 AI 消息中请求的工具调用,并返回一个包含每个结果的 ToolMessage。ToolNode 还会处理工具抛出的异常——利用错误消息构建一个 ToolMessage,然后传递给 LLM——由它决定如何处理错误。
tools_condition 作为一个条件边函数,它会查看状态中最新的 AI 消息,并在有工具需要执行时路由到工具节点。如果没有需要执行的工具,它就会结束这个图。
最后要注意,这个图会在模型节点和工具节点之间循环。也就是说,模型本身负责决定何时结束计算,这是 agent 架构的一个关键特性。每当我们在 LangGraph 中编写循环时,通常需要使用条件边,这样就能定义 stop condition,当图应该退出循环并停止执行时触发。
import ast from typing
import Annotated, TypedDict from langchain_community.tools import DuckDuckGoSearchRun
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI
from langgraph.graph import START, StateGraph
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode, tools_condition
# ---- 定义一个简单计算器工具 ----
@tool
def calculator(query: str) -> str:
"""A simple calculator tool. Input should be a mathematical expression."""
return ast.literal_eval(query)
# ---- 准备 LLM 与工具 ----
search = DuckDuckGoSearchRun()
tools = [search, calculator]
model = ChatOpenAI(temperature=0.1).bind_tools(tools)
# ---- 定义有状态的对话 State ----
class State(TypedDict):
messages: Annotated[list, add_messages]
# ---- 模型节点:让模型基于 state 产出下一条消息或工具调用 ----
def model_node(state: State) -> State:
res = model.invoke(state["messages"])
return {"messages": res}
# ---- 搭图:model <-> tools 循环,按需调用工具 ----
builder = StateGraph(State)
builder.add_node("model", model_node) # 模型节点
builder.add_node("tools", ToolNode(tools)) # 预制的工具节点
builder.add_edge(START, "model") # 起点 -> 模型
builder.add_conditional_edges("model", tools_condition) # 若需要工具 -> tools,否则结束
builder.add_edge("tools", "model") # 工具执行完 -> 回到模型
graph = builder.compile()
这个例子中使用了两个tool,search和 calculator。
接下来我们用一个例子讲讲整个过程:
我们的输入如下:
input = {
"messages": [
HumanMessage("""How old was the 30th president of the United States when he died?""")
]
}
for c in graph.stream(input):
print(c)
我们问的问题是美国第30任总统死的时候多少岁?
输出为:![![[Pasted image 20250911204622.png]]](https://i-blog.csdnimg.cn/direct/85f8ac99b5fe430f889a4e858807c0a0.png)
浏览这个输出过程:
- 首先,model node 被执行并决定调用 duckduckgo_search tool,这导致了 conditional edge 将我们路由到 tools node。
- 接着,ToolNode 执行了 search tool,并获得了上面打印出的搜索结果,其中实际上包含了答案 —— “Age and Year of Death. January 5, 1933 (aged 60)”。
- 然后,model tool 再次被调用,这一次它接收搜索结果作为最新的消息,并生成了最终答案(没有再进行其他的 tool 调用);因此,conditional edge 结束了整个 graph。
Always Calling a Tool First
在标准的 agent architecture 中,LLM 总是被调用来决定接下来要调用哪个 tool。这样的安排有一个明显的优势:它赋予了 LLM 最大的灵活性,使其能够根据每个用户的查询来调整应用程序的行为。
但是,这种灵活性也带来了代价:不可预测性。例如,如果你(作为应用程序的开发者)知道 search tool 应该始终被最先调用,那么强制这样做实际上可能对你的应用有好处:
-
它会减少整体延迟,因为它跳过了最初那个 LLM 调用(即生成调用 search tool 请求的那一步)。
-
它能防止 LLM 错误地认为在某些用户查询中不需要调用 search tool。
另一方面,如果你的应用程序没有明确的规则(比如“你应该始终先调用这个 tool”),那么引入这种约束反而可能会让应用变得更糟。![![[Pasted image 20250911205541.png]]](https://i-blog.csdnimg.cn/direct/6ce887d60df241bda6ea6ce5a27ec26d.png)
假如我们将上面的例子改成这样。我们开始所有调用时,都会先调用 first_model,它根本不会调用 LLM。它只是为 search tool 创建一个 tool call,直接把用户的消息原封不动地当作 search query。之前的架构则会让 LLM 来生成这个 tool call(或者生成它认为更合适的其他响应)。之后,我们进入 tools,这一步与前一个示例完全相同,然后再像之前一样进入 agent node。
其他代码保持不变,我们只修改这部分代码:
def first_model(state: State) -> State:
query = state["messages"][-1].content
search_tool_call = ToolCall( name="duckduckgo_search", args={"query": query}, id=uuid4().hex )
return {"messages": AIMessage(content="", tool_calls=[search_tool_call])}
builder = StateGraph(State)
builder.add_node("first_model", first_model)
builder.add_node("model", model_node)
builder.add_node("tools", ToolNode(tools))
builder.add_edge(START, "first_model")
builder.add_edge("first_model", "tools")
builder.add_conditional_edges("model", tools_condition)
builder.add_edge("tools", "model")
graph = builder.compile()
输出结果为:![![[Pasted image 20250911210128.png]]](https://i-blog.csdnimg.cn/direct/53bf777a8c724762a164e57b49bac44e.png)
和之前的区别总结:
之前
-
流程:
__start__ → model → tools → model → __end__ -
细节:
-
model 首先被调用,它决定要调用
duckduckgo_searchtool。 -
tools 执行搜索并返回结果(包含 Calvin Coolidge 的生卒年)。
-
model 再次处理这些结果,直接产出最终答案(Calvin Coolidge died on Jan 5, 1933, aged 60)。
-
-
特点:
-
LLM 负责决定是否调用工具,并总结最终回答。
-
整个回答比较直接,依赖搜索结果里的已有信息。
-
缺点:如果 LLM 判断错误,可能会跳过 tool 或提取不完整。
-
现在
-
流程:
__start__ → first_model → tools → model → __end__ -
细节:
-
first_model 直接把用户问题转化为 tool call(不会调用 LLM)。
-
tools 执行搜索并返回生卒年(Calvin Coolidge: 1872–1933)。
-
model 拿到这些结果,不只是复述,还进行推理计算:
-
1933 - 1872 = 61
-
输出“Calvin Coolidge was 61 years old when he died.”
-
-
-
特点:
-
工具调用是固定的(不会被 LLM 跳过)。
-
LLM 负责进一步推理和计算,而不是只依赖原文。
-
优势:能生成更完整、更可靠的推理型答案。
-
-
输出图1(标准 agent) → 答案是直接抽取的(aged 60)。
-
输出图2(带 first_model) → 答案是推理出来的(计算得 61 岁,并展示推理过程)。
使用多种工具
LLMs 并不完美,当在一个 prompt 中被给予过多选择或过量信息时,它们的表现会更加糟糕。这种局限性同样会影响下一步动作的规划。当工具数量过多(比如超过 10 个)时,规划性能(也就是 LLM 选择正确工具的能力)会开始下降。这个问题的解决方案是减少 LLM 可选择的工具数量。但如果你确实有很多工具,且希望它们能被用于不同的用户查询,该怎么办呢?
一个优雅的解决方案是:使用一个 RAG step 来为当前查询预先挑选出最相关的工具,然后只把这一小部分工具提供给 LLM,而不是把整个工具库都交给它。这还能帮助降低调用 LLM 的成本(商用 LLM 通常会根据 prompt 的长度和输出收费)。另一方面,这个 RAG step 会给应用增加额外的延迟,因此只有当你在添加更多工具后确实观察到性能下降时,才应该采用这种方法。
我们这样实现:
import ast
from typing import Annotated, TypedDict
from langchain_community.tools import DuckDuckGoSearchRun
from langchain_core.documents import Document
from langchain_core.messages import HumanMessage
from langchain_core.tools import tool
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
from langgraph.graph import START, StateGraph
from langgraph.graph.message import add_messages
from langgraph.prebuilt import ToolNode, tools_condition
@tool
def calculator(query: str) -> str:
"""A simple calculator tool. Input should be a mathematical express
ion."""
return ast.literal_eval(query)
search = DuckDuckGoSearchRun()
tools = [search, calculator]
embeddings = OpenAIEmbeddings()
model = ChatOpenAI(temperature=0.1)
tools_retriever = InMemoryVectorStore.from_documents(
[Document(tool.description, metadata={"name": tool.name}) for tool in tools],
embeddings,
).as_retriever()
class State(TypedDict):
messages: Annotated[list, add_messages]
selected_tools: list[str]
def model_node(state: State) -> State:
selected_tools = []
tool_for_tool in tools if tool.name in state["selected_tools"]
]
res = model.bind_tools(selected_tools).invoke(state["messages"])
return {"messages": res}
def select_tools(state: State) -> State:
query = state["messages"][-1].content
tool_docs = tools_retriever.invoke(query)
return {"selected_tools": [doc.metadata["name"] for doc in tool_doc
s]}
builder = StateGraph(State)
builder.add_node("select_tools", select_tools)
builder.add_node("model", model_node)
builder.add_node("tool", ToolNode(tools))
builder.add_edge(START, "select_tools")
builder.add_edge("select_tools", "model")
builder.add_conditional_edges("model", tools_condition,
{"tool": "tool", "end": "__end__"})
builder.add_edge("tool", "model")
graph = builder.compile()
![![[Pasted image 20250911211502.png]]](https://i-blog.csdnimg.cn/direct/c14604aa44a44ab1b51ca5c368151768.png)
我们来分析一下这个RAG步骤:
1) Retrieval:把“工具说明”当作语料建索引
embeddings = OpenAIEmbeddings() # 将文本映射到向量空间(需要 OPENAI_API_KEY)
tools_retriever = InMemoryVectorStore.from_documents(
[Document(tool.description, metadata={"name": tool.name}) for tool in tools],
embeddings,
).as_retriever()
-
给每个工具(
search,calculator)各生成一条 Document,内容是tool.description,并把tool.name存到 metadata。 -
用
OpenAIEmbeddings把这些说明文本向量化,塞进InMemoryVectorStore。 -
得到一个
retriever:输入一段自然语言,就能返回最相近的工具文档。
这里“语料库”= 工具说明;“索引”= 工具说明的向量表示。
2) Augment:根据用户问题检索相关工具,写回到 State
def select_tools(state: State) -> State:
query = state["messages"][-1].content # 最新一条用户意图
tool_docs = tools_retriever.invoke(query) # 向量检索,得到候选工具
return {"selected_tools": [doc.metadata["name"] for doc in tool_docs]}
-
把用户的最新消息当查询(query)。
-
retriever.invoke(query)返回最相似的工具文档列表。 -
把这些文档的
name提取出来,写入state["selected_tools"]。
这一步就是典型的 R(检索)+ A(把“检索结果”注入到系统状态),为下一步生成做约束与加持。
3) Generate:只绑定被检索出来的工具再生成
def model_node(state: State) -> State:
# 只选择被 RAG 选出的工具
selected_tools = [t for t in tools if t.name in state["selected_tools"]]
res = model.bind_tools(selected_tools).invoke(state["messages"])
return {"messages": res}
-
用检索结果过滤原始工具列表,只把这些“相关工具”绑定给模型(
bind_tools)。 -
这样模型在生成“下一条 AI 消息”时,只能调用这些工具,并据此给出更聚焦的答案。
这就是 G(生成):在“被检索出的上下文”(这里是“工具集合”)约束下进行推理/调用。
4) Graph 侧的编排:把 RAG 插在模型前面
builder.add_node("select_tools", select_tools) # RAG 选择工具
builder.add_node("model", model_node) # 绑定所选工具进行推理
builder.add_node("tool", ToolNode(tools)) # 执行具体工具
builder.add_edge(START, "select_tools") # 先做检索
builder.add_edge("select_tools", "model") # 再让模型生成
builder.add_conditional_edges("model", tools_condition, # 若模型请求工具 → tool
{"tool": "tool", "end": "__end__"})
builder.add_edge("tool", "model") # 工具执行结果回到模型
-
select_tools始终先跑,确保每轮对话都先“检索-挑工具”。 -
tools_condition控制是否跳到ToolNode真正去执行工具。 -
执行完再回到
model,直到模型不再请求工具,图结束。
我们来看看输出又有什么变化:![![[Pasted image 20250911212645.png]]](https://i-blog.csdnimg.cn/direct/5fbda87ee24346c695da066260ef5c68.png)
输出包含 3 段事件:
-
select_tools-
新增的节点输出:
selected_tools: ['duckduckgo_search', 'calculator'] -
说明本轮对话先做了检索,把允许绑定给模型的工具子集挑出来。
-
-
第一次
model-
messages里出现tool_calls=[{'name': 'duckduckgo_search', 'args': {'query': '30th president of the United States'}, ...}] -
这里的工具调用只会在被选中的集合里;与之前“直接绑定全部工具”不同,模型被约束在检索出的子集内做决定。
-
-
tools(ToolNode 执行)→ 再回到model-
tools返回ToolMessage(...),内容是检索到的 Calvin Coolidge 信息。 -
随后
model生成最终回答,并给出年龄的计算过程(这一步它没必然调用calculator,LLM 直接减法也能写出来,所以你看到的是只调用了 search 的路径)。
-
对比没有 RAG 的版本,输出的显著差异:
-
多了一帧
select_tools的结构化输出(这是 RAG 的“R/A”阶段的可见证据)。 -
model的tool_calls只会选自selected_tools,而不是所有工具——副作用更少、调用更稳定。 -
若检索未选中某个工具,该工具就不可能出现在后续调用里(以前有时会“误触发”无关工具)。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 30
30 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)