AI学习日记——线性回归实战
目录
线性回归实战
主要工具
我用的是平台是pycharm
-
也可以使用jupyter,
pip install jupyter命令安装,运行jupyter notebook后,终端会输出类似http://localhost:8888/?token=abc123...的URL。复制这个URL到浏览器打开即可
常用的库包括:
-
-
pandas:用于数据处理和分析。
-
numpy:用于科学计算和数值分析。
-
scikit-learn:提供了大量机器学习算法和工具,包括线性回归。
-
matplotlib / seaborn:用于数据可视化。
-
在 PyCharm 的终端中,可以使用
pip install pandas numpy scikit-learn matplotlib seaborn命令来一次性安装这些库
-
数据集
数据特点:
-
数据集名称:housing.csv
字段说明:
-
RM:住宅平均房间数(连续变量)
-
LSTAT:低收入人口比例(连续变量,百分比)
-
PTRATIO:城镇师生比例(连续变量)
-
MEDV:房屋价格中位数(目标变量,单位:美元)
-
包含34条样本数据
-
3个特征变量,1个目标变量
-
适合进行多元线性回归分析
代码分析
-
导入依赖
import numpy as np
import pandas as pd
import matplotlib as plt-
加载数据&查看数据信息
data=pd.read_csv('housing.csv');# 加载CSV数据文件
print(data.head());# 查看数据前5行,了解数据结构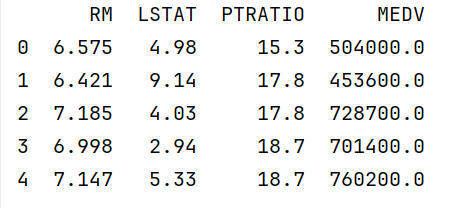
print(data.info());# 查看数据集基本信息,包括数据类型和非空值数量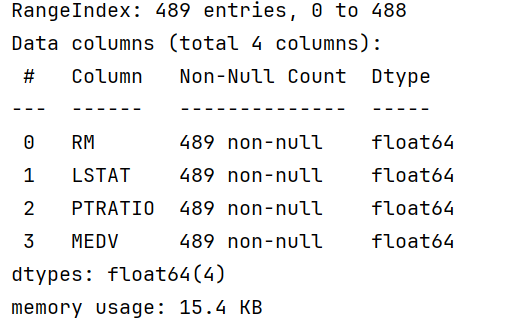
print(data.describe());# 查看数值型字段的描述性统计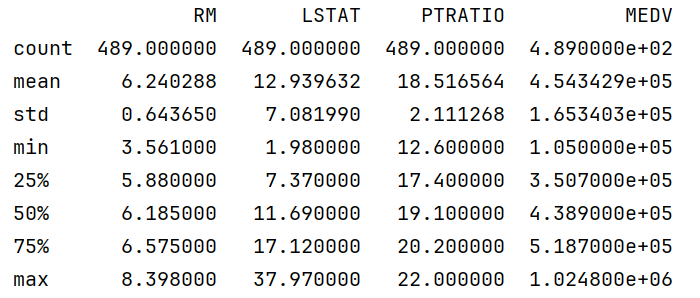
-
数据预处理
# 准备特征变量和目标变量
X = data[['RM', 'LSTAT', 'PTRATIO']] # 选择三个特征变量
y = data['MEDV'] # 目标变量为房价
# 划分训练集和测试集 (80%训练, 20%测试)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42 # random_state确保结果可重现
)
print(f"训练集样本数: {X_train.shape[0]}")
print(f"测试集样本数: {X_test.shape[0]}")-
模型训练与评估
# 创建线性回归模型实例
model = LinearRegression()
# 使用训练数据拟合模型
model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = model.predict(X_test)
# 计算模型评估指标
mse = mean_squared_error(y_test, y_pred) # 均方误差
rmse = np.sqrt(mse) # 均方根误差
r2 = r2_score(y_test, y_pred) # 决定系数
print(f"均方误差(MSE): {mse:.2f}")
print(f"均方根误差(RMSE): {rmse:.2f}")
print(f"决定系数(R²): {r2:.4f}")
# 查看模型参数
print("\n模型参数:")
print(f"截距(θ₀): {model.intercept_:.2f}")
for i, feature in enumerate(X.columns):
print(f"{feature}的系数(θ_{i+1}): {model.coef_[i]:.2f}")-
绘图
# 设置画布
plt.figure(figsize=(15, 10))
# 1. 特征与目标变量关系散点图
plt.subplot(2, 2, 1)
plt.scatter(data['RM'], data['MEDV'], alpha=0.6)
plt.xlabel('房间数量(RM)')
plt.ylabel('房价(MEDV)')
plt.title('房间数量与房价关系')
plt.subplot(2, 2, 2)
plt.scatter(data['LSTAT'], data['MEDV'], alpha=0.6)
plt.xlabel('低收入比例(LSTAT)')
plt.ylabel('房价(MEDV)')
plt.title('低收入比例与房价关系')
plt.subplot(2, 2, 3)
plt.scatter(data['PTRATIO'], data['MEDV'], alpha=0.6)
plt.xlabel('师生比例(PTRATIO)')
plt.ylabel('房价(MEDV)')
plt.title('师生比例与房价关系')
# 2. 预测值与真实值对比图
plt.subplot(2, 2, 4)
plt.scatter(y_test, y_pred, alpha=0.6)
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], 'r--')
plt.xlabel('真实价格')
plt.ylabel('预测价格')
plt.title('预测值 vs 真实值')
plt.tight_layout()
plt.show()
# 3. 残差图
residuals = y_test - y_pred
plt.figure(figsize=(8, 6))
plt.scatter(y_pred, residuals, alpha=0.6)
plt.axhline(y=0, color='r', linestyle='--')
plt.xlabel('预测价格')
plt.ylabel('残差')
plt.title('残差分析图')
plt.show()小结
流程总结:
-
数据加载与探索:使用pandas加载数据,查看基本信息和统计描述
-
数据预处理:选择相关特征,划分训练集和测试集
-
模型训练:使用训练数据拟合线性回归模型
-
模型评估:计算MSE、RMSE和R²等评估指标
-
结果可视化:绘制特征关系图、预测值对比图和残差分析图
-
模型应用:使用训练好的模型进行新数据预测
关键发现:
-
房间数量(RM)与房价呈正相关,是最重要的预测特征
-
低收入比例(LSTAT)与房价呈负相关
-
模型表现良好,R²值表明模型能够解释大部分价格变异
-
残差分析显示模型假设基本合理,预测误差随机分布

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)