【ComfyUI】SD3.5 简单版本提供快速上手的图像生成体验
本文介绍了一个基于Stable Diffusion 3.5的ComfyUI工作流,通过加载预训练模型、设置提示词、采样潜在图像和最终解码输出,实现从文本到图像的完整生成过程。工作流包含模型加载、条件编码、潜在初始化、迭代采样、图像解码和输出保存六个核心环节,支持高分辨率图像生成。该方案具有模块化设计特点,适用于创意设计、产品展示、影视场景构建等多种应用场景,既能提升创作效率,又能作为教学示例展示A
今天展示的案例是一个基于 Stable Diffusion 3.5 的 ComfyUI 工作流,通过加载预训练模型、设定正向与负向提示词、采样潜在图像并结合解码器完成生成,最终将图像输出保存。




整个过程以直观的方式体现了从文本到图像的完整链路,能够在具体场景中实现复杂的视觉生成与创意表达。
工作流介绍
该工作流以 sd3.5_large_fp8_scaled.safetensors 模型为核心,结合 CLIP 文本编码器对提示词进行处理,利用采样器对潜在空间进行迭代推理,并通过 VAE 解码器完成像素图像的还原。最终结果以高分辨率图像的形式保存,便于直接展示或进行后续编辑。整体设计逻辑清晰,涵盖了从文本条件到图像输出的主要环节,体现了 ComfyUI 的模块化和可视化优势。
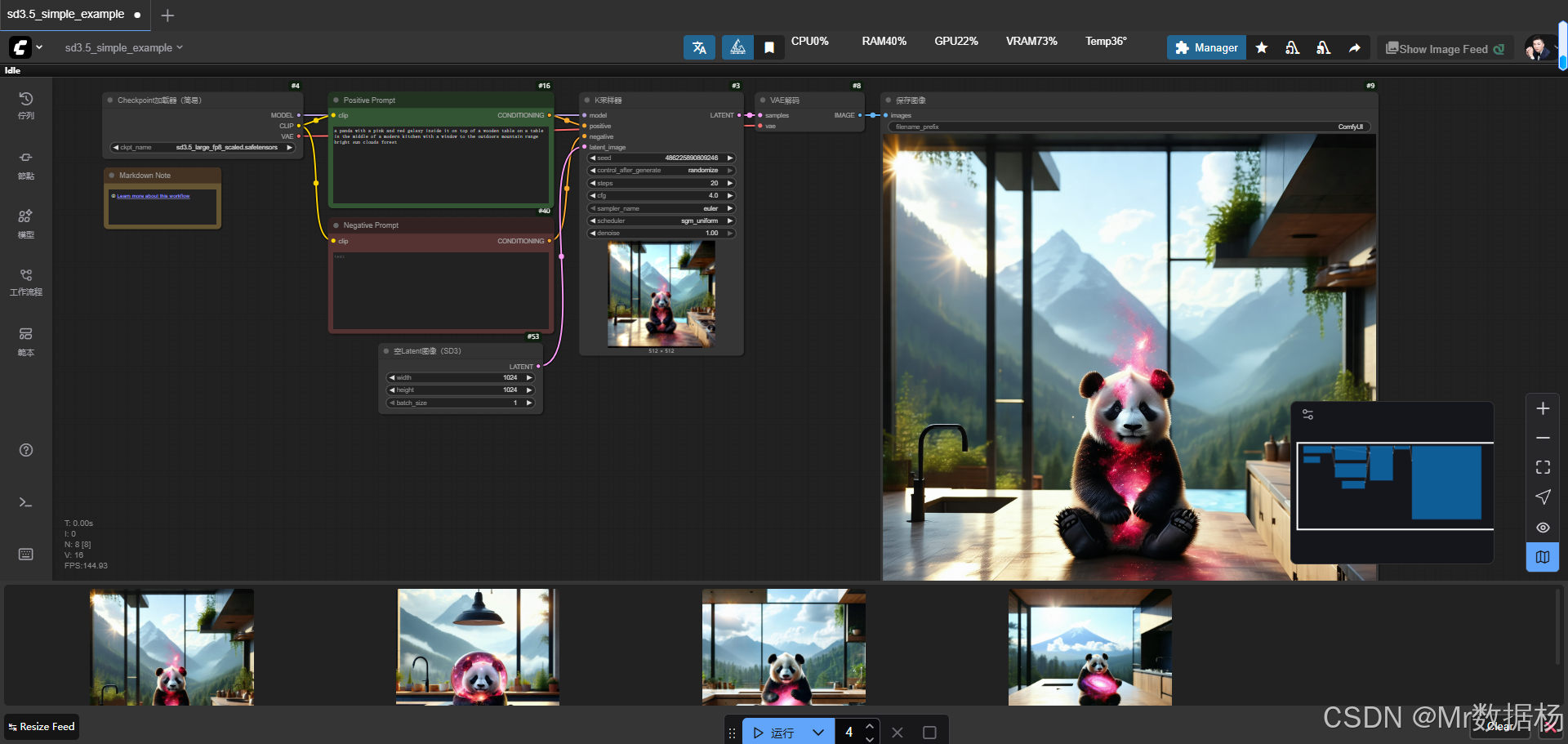
核心模型
在核心模型部分,工作流依赖 Stable Diffusion 3.5 的大规模权重文件,并通过 Checkpoint Loader 调用 CLIP 与 VAE 组件,为后续的提示词解析与图像生成奠定基础。模型的作用不仅体现在生成质量的提升,也保证了对高分辨率图像的兼容性,适合在创意绘制与设计场景中直接应用。
| 模型名称 | 说明 |
|---|---|
| sd3.5_large_fp8_scaled.safetensors | Stable Diffusion 3.5 大模型,支持 FP8 精度计算,兼容高分辨率生成 |
| CLIP | 用于将正向与负向提示词转换为条件向量,指导图像生成方向 |
| VAE | 将潜在空间的特征解码为最终的像素图像 |
Node节点
该工作流由多个节点协作完成,Checkpoint Loader 提供了模型、CLIP 与 VAE,CLIPTextEncode 节点分别用于正向与负向提示词的向量化,KSampler 节点在潜在空间内进行迭代采样,EmptySD3LatentImage 用于初始化潜在图像,最终通过 VAEDecode 还原成图像并交由 SaveImage 节点完成输出。各节点间的衔接逻辑紧凑,保证了提示词与模型推理之间的高效流转。
| 节点名称 | 说明 |
|---|---|
| CheckpointLoaderSimple | 加载 Stable Diffusion 3.5 模型及其 CLIP、VAE 组件 |
| CLIPTextEncode (Positive Prompt) | 编码正向提示词,指导图像的生成方向 |
| CLIPTextEncode (Negative Prompt) | 编码负向提示词,避免图像中出现不期望的元素 |
| EmptySD3LatentImage | 生成空的潜在图像作为初始输入 |
| KSampler | 基于模型与提示词对潜在空间进行迭代采样 |
| VAEDecode | 将潜在图像解码为最终的像素图像 |
| SaveImage | 保存生成的图像文件,便于展示与后续处理 |
工作流程
该工作流的整体运行逻辑从模型加载到最终图像输出,形成了一个完整的闭环。首先通过 Checkpoint Loader 加载 Stable Diffusion 3.5 的核心模型、CLIP 与 VAE 组件,随后由 CLIPTextEncode 节点对正向与负向提示词进行条件编码,并生成潜在空间输入。EmptySD3LatentImage 节点初始化了潜在图像,KSampler 节点在潜在空间中反复采样,依据提示词与模型权重不断优化生成结果。得到的潜在图像经 VAEDecode 解码还原为像素级的成品图像,最终由 SaveImage 节点保存输出。整个流程环环相扣,实现了从文本设定到图像呈现的全链路生成过程。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 模型加载 | 调用 Stable Diffusion 3.5 权重文件,并加载 CLIP 与 VAE 组件 | CheckpointLoaderSimple |
| 2 | 条件编码 | 将正向与负向提示词转化为可供模型使用的条件向量 | CLIPTextEncode (Positive/Negative) |
| 3 | 潜在初始化 | 构建基础潜在图像作为采样输入 | EmptySD3LatentImage |
| 4 | 迭代采样 | 基于条件向量和模型权重在潜在空间内迭代生成图像特征 | KSampler |
| 5 | 图像解码 | 将潜在图像转换为可视化的像素图像 | VAEDecode |
| 6 | 图像输出 | 将生成结果保存至指定目录,完成工作流闭环 | SaveImage |
应用场景
该工作流具备通用性与拓展性,可应用于创意设计、插画生成、视觉艺术探索、概念场景构建等多个方向。由于模型支持高分辨率与复杂提示词控制,适合在商业广告、影视分镜、产品原型可视化等场景中直接投入使用。同时也能作为教学示例,帮助学习者理解从文本到图像生成的完整原理与实践过程。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 创意插画 | 快速生成高质量艺术插画 | 插画师、设计师 | 带有复杂细节的画面 | 提升创作效率与风格多样性 |
| 产品展示 | 将概念文案转化为产品外观图 | 品牌方、设计团队 | 产品效果图或宣传素材 | 辅助视觉营销与宣传推广 |
| 影视场景 | 构建分镜头画面与氛围参考 | 编剧、导演、视觉团队 | 场景画面草稿 | 高效完成概念验证与氛围设计 |
| 学术教学 | 展示文本生成图像的完整流程 | 教学人员、研究者 | 模型生成流程演示 | 直观理解 AI 图像生成机制 |
| 个性化创作 | 满足兴趣与爱好的创意输出 | 爱好者、博主 | 独特风格的艺术作品 | 丰富个人表达与视觉呈现 |
开发与应用
更多 AIGC 与 ComfyUI工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)