又登CVPR,我悟了,Transformer+CNN+注意力机制组合才是论文收割机!
【AI混合架构研究新突破】三篇顶会论文揭示Transformer+Attention+CNN的创新应用:1)提出NeuralAttention机制,用神经网络替代点积注意力,提升模型表达能力;2)解析self-attention的几何结构,证明训练目标对矩阵特性的塑造规律;3)将线性注意力重构为动态VAR模型,在时间序列预测中实现SOTA性能。这些研究为复杂任务建模提供了新思路,涵盖NLP、CV和
近年来,“Transformer+Attention+CNN”的混合架构已成为人工智能领域的顶会顶刊宠儿,其爆发式增长源于它精准命中了单一模型在复杂任务中的根本性局限——CNN擅长捕捉局部特征但全局感知薄弱,Transformer长于建模长程依赖却计算开销巨大,而注意力机制则能动态聚焦关键信息并增强可解释性。
这种组合架构,无论CV/NLP/多模态领域都对它有强烈需求。为助力研究者快速切入,本文系统拆解了3篇最新顶会论文助你在学术与工程的双重赛道中抢占先机。
论文1:Neural Attention: A Novel Mechanism for Enhanced Expressive Power in Transformer Models
方法:这篇文章提出Neural Attention技术,用可学习的神经网络取代传统的点积注意力机制,大幅提升transformer模型的表达能力和性能。
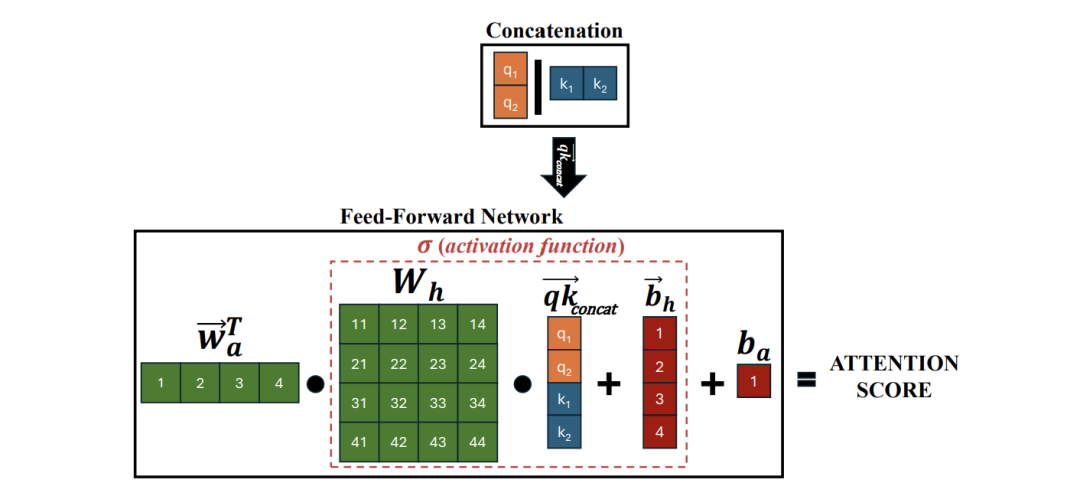
创新点:
-
引入非线性映射计算注意力分数,更好地捕捉嵌入向量间的复杂关系。
-
通过降维和分层应用策略有效降低计算开销,保持实用性。
-
在NLP和视觉任务上实验证明能显著降低困惑度并提高分类准确率。

想要发计算机顶会顶刊?
扫码添加发刊老师了解详情
论文2:The underlying structures of self-attention: symmetry, directionality,and emergent dynamics in Transformer training
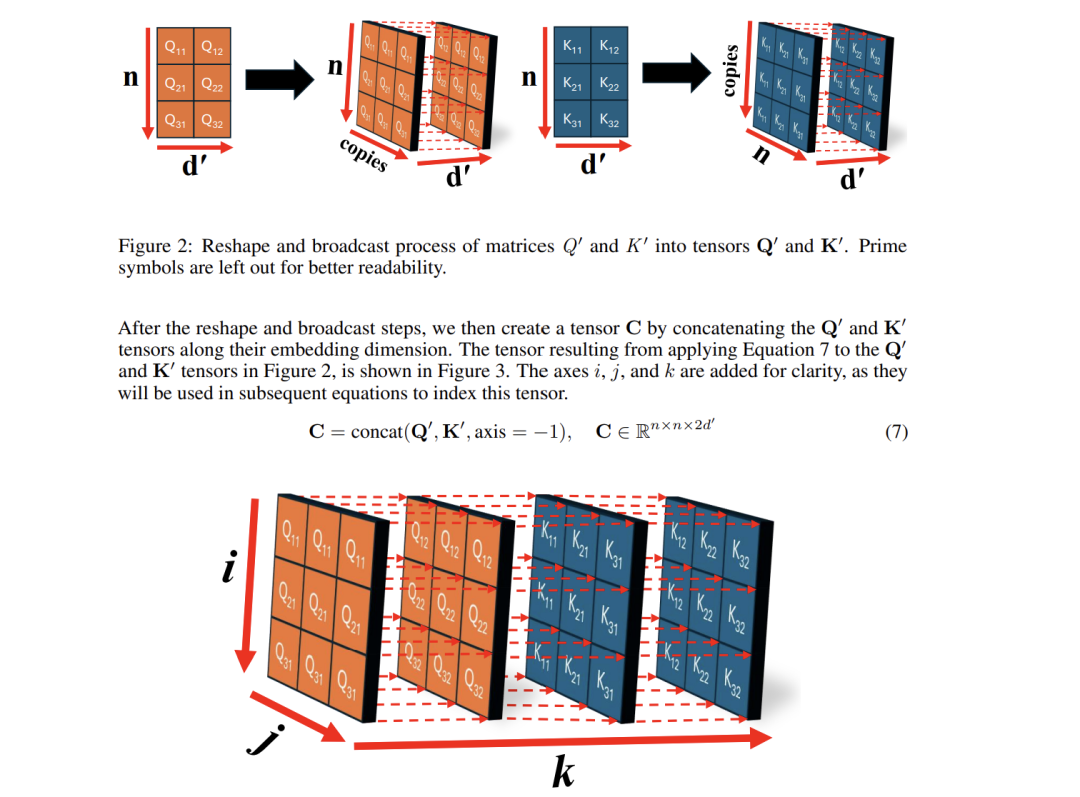
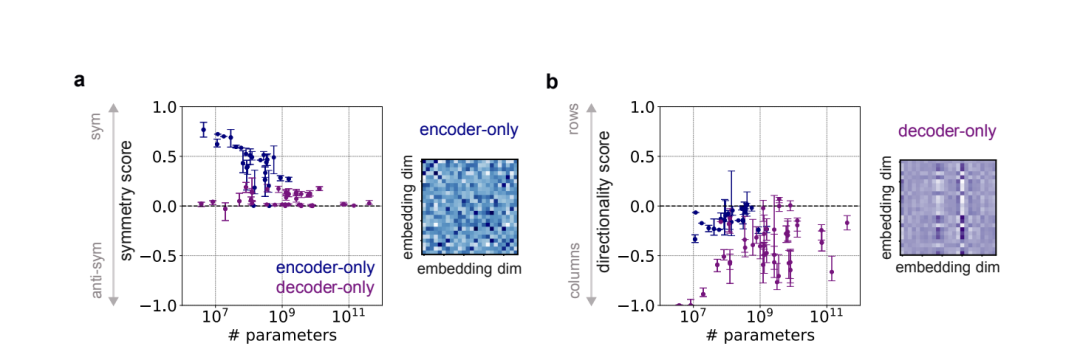
方法:这篇文章揭示self-attention矩阵的几何结构,证明双向训练诱导对称性而自回归训练导致方向性。
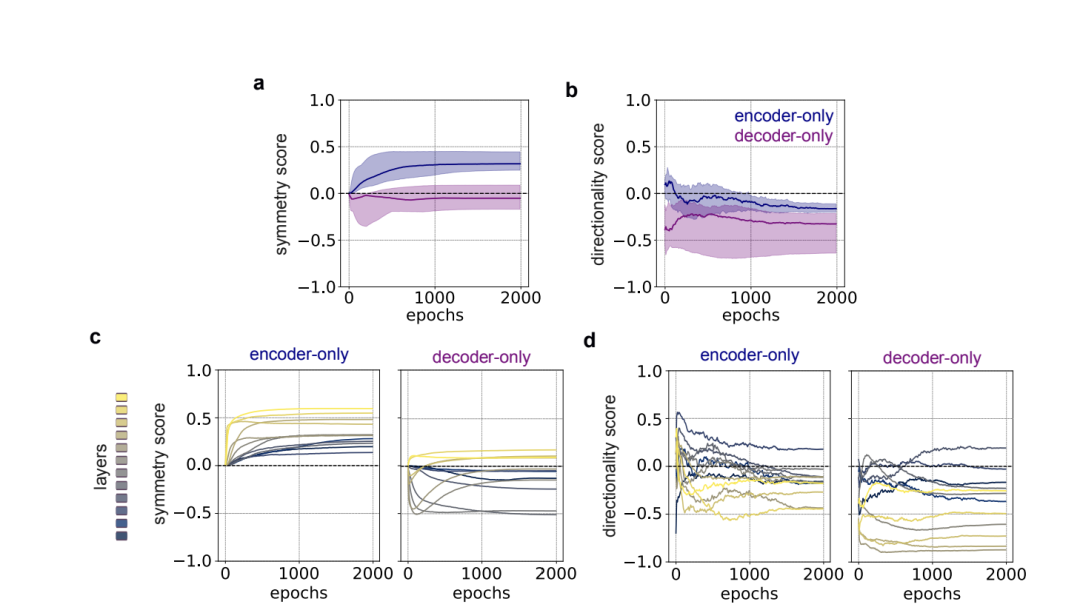
创新点:
-
建立数学框架证明目标函数如何塑造self-attention矩阵的结构特性。
-
提出对称性和方向性评分系统量化不同transformer模型的差异。
-
利用对称初始化策略提升编码器模型的训练效率和性能。
想要发计算机顶会顶刊?
扫码添加发刊老师了解详情
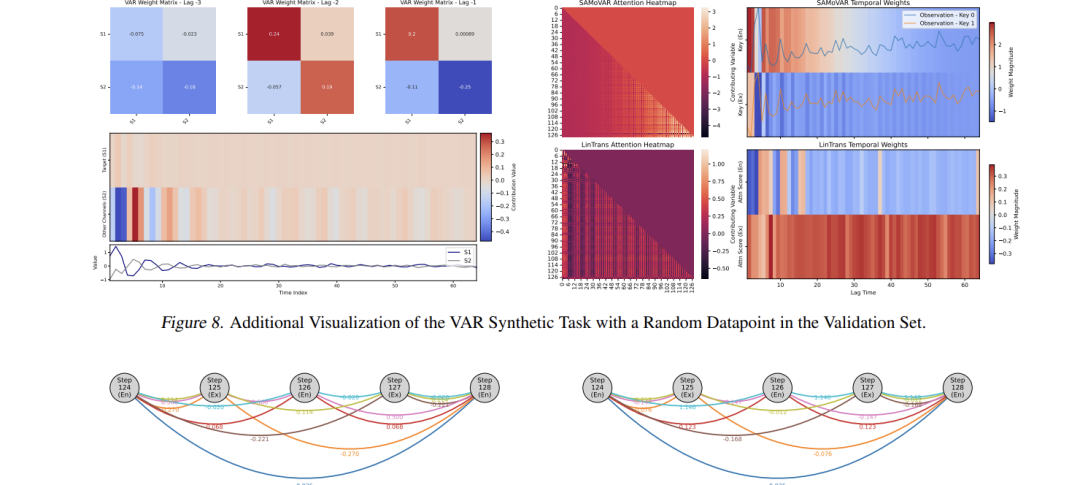
论文3:Linear Transformers as VAR Models: Aligning Autoregressive AttentionMechanisms with Autoregressive Forecasting
方法:这篇文章将线性注意力重新解释为动态向量自回归模型,提出结构对齐的SAMoVAR架构。
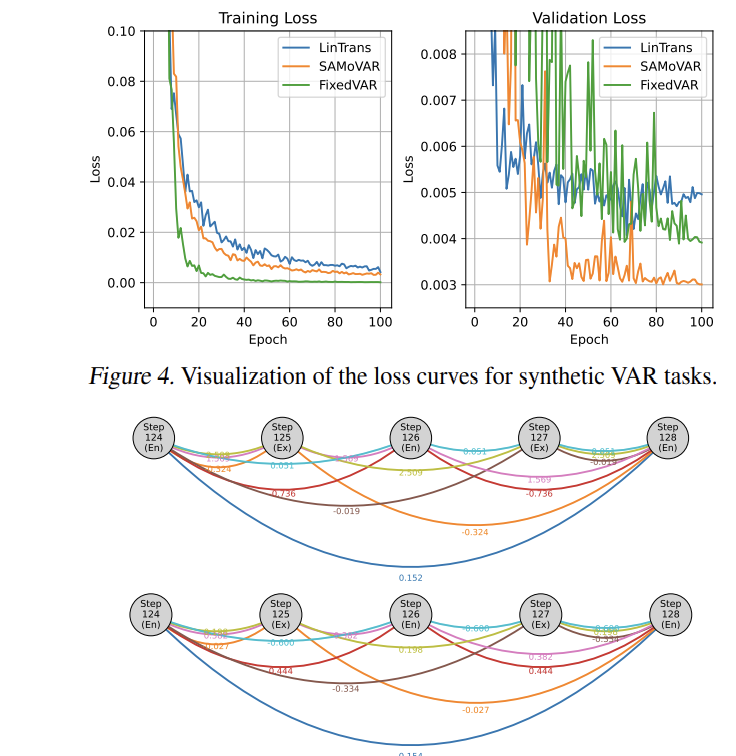
创新点:
-
证明单层线性注意力本质上是具有动态权重的VAR结构。
-
通过重组多层架构保留VAR特性,引入时间影响路径增强可解释性。
-
结合ARX标记化策略在多元时间序列预测中实现SOTA性能。
纠结选题?导师放养?投稿被拒?
快来找咕泡教育SCI/CCF论文辅导!
从选题—实验设计—论文撰写的一站式服务
扫码添加发刊老师!
论文发刊

论文服务流程
论文老师库

论文学员

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 5
5 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)