白话GPU-02之超高速公路NVLink、NVSwitch、SXM一文详解
NVLink是NVIDIA开发的一项高速互连技术,主要用于GPU之间以及GPU与CPU之间的高效数据通信。它旨在解决传统PCIe总线在带宽和延迟上的瓶颈,特别适合人工智能(AI)、高性能计算(HPC)和大型数据分析等需要大规模并行计算的工作负载。

一、NVLink在GPU服务器中的作用与价值

NVLink是NVIDIA开发的一项高速互连技术,主要用于GPU之间以及GPU与CPU之间的高效数据通信。它旨在解决传统PCIe总线在带宽和延迟上的瓶颈,特别适合人工智能(AI)、高性能计算(HPC)和大型数据分析等需要大规模并行计算的工作负载。
NVLink的核心价值在于它允许处理器之间直接高速通信,无需像传统PCIe那样经过CPU和主板芯片组中转。这不仅大幅提升了带宽,还显著降低了延迟。
更重要的是,NVLink支持GPU间直接内存访问(GPU Direct RDMA) 和内存一致性模型。这意味着多块GPU的显存可以被聚合为一个更大的统一内存池使用,这对于训练参数量远超单卡显存的大型AI模型至关重要。
为了连接更多设备,NVIDIA开发了NVSwitch交换芯片。它就像一个专门为NVLink网络设计的“交换机”,允许多个GPU实现全互联(All-to-All)通信,从而构建大规模、高效的计算集群。
二、NVLink各代版本的关键技术参数
下表格汇总了NVLink各代版本的关键技术参数,显示了其演进历程和性能提升。
|
特性维度 |
NVLink 1.0 |
NVLink 2.0 |
NVLink 3.0 |
NVLink 4.0 |
NVLink 5.0 (Blackwell) |
|---|---|---|---|---|---|
| 推出时间 | 2016
年 |
2017
年 |
2020
年 |
2022
年 |
2024
年 |
| 典型搭载硬件 | Tesla P100 |
Tesla V100 |
A100 |
H100 |
B200
、 |
| 单链路带宽(单向) | 20 GB/s |
25 GB/s |
25 GB/s |
25 GB/s |
50 GB/s |
单GPU总带宽 |
160 GB/s (双向) |
300 GB/s (双向) |
600 GB/s (双向) |
900 GB/s (双向) |
1800 GB/s (双向) |
与PCIe对比 |
约 |
约 |
约 |
约 |
约 |
| 关键特性 |
引入 |
支持 |
支持 |
支持 |
C2C
芯片互连、网络化 |
NVLink 5.0通过使能GPU共享内存和计算资源,大幅提升了更大规模多GPU系统的扩展能力,显著优化了训练 (Training)、推理 (Inference) 以及逻辑推理 (Reasoning) 工作流。单个NVIDIA Blackwell GPU支持多达18个NVLink 100 GB/s连接,总带宽为1.8 TB/s,是上一代的2倍,是PCIe 5.0带宽的14倍以上。NVIDIA Blackwell等服务器平台,利用这项技术为当今极为复杂的大型模型提供更高的可扩展性。
三、NVLink的扩展与生态系统——NVLink Fusion
2025年,NVIDIA宣布开放其互连技术,推出了NVLink Fusion计划。这允许其他合作伙伴(如CPU制造商、定制ASIC厂商)获得NVLink端口设计的许可,将其集成到自己的芯片中,从而与NVIDIA的GPU实现高速互联。
此举旨在将NVLink从内部的私有互联技术转变为更广泛的行业互联生态,巩固其在AI基础设施中的核心地位。首批合作伙伴包括联发科、Marvell、富士通和高通等。
四、NVLink的应用场景
-
大规模
AI模型训练与推理:这是NVLink的主战场。它极大地加速了多GPU之间梯度同步和参数交换的速度,缩短了大模型(如LLM)的训练周期。对于推理,它允许模型分布在多卡上,处理更大模型或更多并发请求。 -
高性能计算 (
HPC):在科学模拟、气候研究、流体动力学等领域,需要处理海量数据并进行密集计算,NVLink的高带宽和低延迟能显著提升整体计算效率。 -
专业图形与虚拟化:在高端工作站中,
NVLink可以连接多块专业GPU,共同完成复杂的3D渲染、视频编辑或虚拟化应用,提供更流畅的体验。
五、多GPU高速交换芯片——NVSwitch
NVSwitch是NVIDIA专为多GPU系统设计的一款高速交换芯片,它基于NVLink技术构建,旨在解决大规模GPU集群中高带宽、低延迟的通信需求。
1、NVSwitch的基本原理
NVSwitch是一种硬件交换机,允许多个GPU通过NVLink接口实现全互联(All-to-All)通信。它的核心作用是提升多GPU系统中的数据传输效率,避免传统PCIe总线带来的带宽瓶颈和延迟问题。
-
与
NVLink的关系:NVLink是点对点的高速互联技术,而NVSwitch则是在此基础上扩展的交换设备,支持更多GPU之间的高效通信。 -
解决通信瓶颈:在没有
NVSwitch的系统中,GPU间通信可能需要经过PCIe接口或中间GPU跳转,从而增加延迟和带宽限制。NVSwitch通过直接的全互联架构消除了这些瓶颈。
2、NVSwitch的技术特性
1)高带宽与低延迟:
-
第三代
NVSwitch支持3.2 TB/s的全双工带宽,采用50 Gbaud PAM4信号技术,每个差分对提供100 Gbps的带宽。 -
延迟显著低于传统网络(如
InfiniBand或以太网),因为它专为GPU间通信优化,减少了协议开销。
2)可扩展性与全互联:
-
NVSwitch支持多达16个GPU的全互联(第一代),第三代NVSwitch甚至可连接更多GPU,并支持跨节点扩展。 -
通过添加更多
NVSwitch,系统可以轻松扩展GPU数量,而不会牺牲性能。
3)高级功能集成:
-
SHARP技术:第三代NVSwitch集成了NVIDIA SHARP(可扩展分层聚合和缩减协议),支持网络内计算(如all_reduce、broadcast等操作),进一步加速集群通信。 -
安全与可靠性:支持安全处理器保护数据,分区功能隔离不同
NVLink网络,以及前向纠错(FEC)增强可靠性。
4)物理设计:
-
第三代
NVSwitch采用台积电4N工艺,包含251亿个晶体管,面积294 mm²,功耗控制良好。 -
封装为大型
BGA芯片,提供大量引脚支持NVLink端口及其他I/O接口。
NVSwitch部分版本技术参数对比如下:
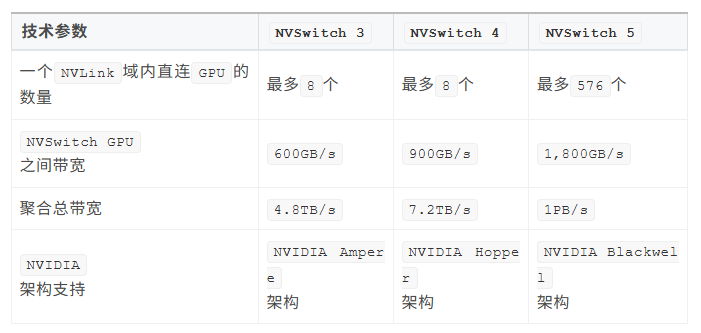
包含四块NVSwitch的HGX H200 8-GPU,见下图绿色标记:

3、NVSwitch对于快速的多GPU LLM推理至关重要
大型语言模型(LLM)越来越大,增加了处理推理请求所需的计算量。为了满足服务当今LLM的实时延迟要求,并为尽可能多的用户提供服务,多GPU计算是必不可少的。这不仅能够降低延迟,提高用户体验,还能够提高吞吐量,降低服务成本。两者同时重要。
即使大型模型可以装入单个state-of-the-art GPU的显存中,该GPU生成令牌的速率也取决于可用于处理请求的总计算量。通过结合多个state-of-the-art GPU的计算能力,可以实现最新模型的实时用户体验。
为了实现良好的多GPU扩展,AI服务器首先需要每个GPU具有出色的互连带宽。它还必须提供快速连接,以使所有GPU能够尽快与所有其他GPU交换数据。
借助NVSwitch,服务器中的每个GPU都可以与任何其他GPU同时超高速进行通信,提升LLM推理时令牌Tokens输出。
六、命令行查看NVLink与NVSwitch状态
可以使用NVIDIA提供的工具监控NVSwitch和NVLink:
1)nvidia-smi:
-
运行
nvidia-smi topo -m查看GPU互联拓扑。 -
运行
nvidia-smi nvlink --status检查NVLink带宽和状态。
2)dcgm工具:
-
运行
dcgmi diag -r 5进行NVLink诊断测试。
七、超越PCIe的封装形式——SXM
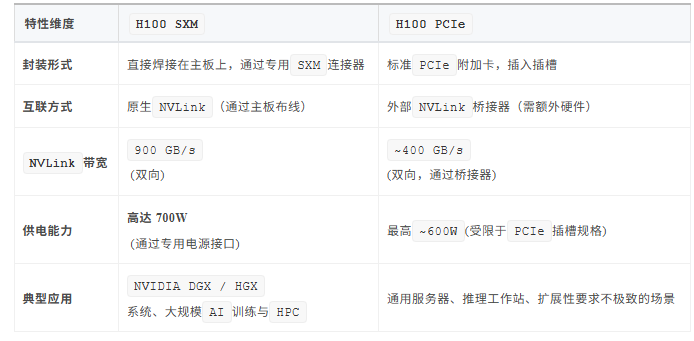
SXM的全称是Server PCIe Module,但它实际上完全避开了标准的PCIe插槽。它是一种专为高性能数据中心和AI工作负载设计的、直接焊接在服务器主板上的GPU封装形式。

1、SXM主要特点及与PCIe的对比
SXM的主要特点:
1)无PCIe插槽,直接板载:
-
SXM版本的GPU(如H100 SXM)没有常见的金手指,它通过一个专用的SXM连接器直接垂直安装在主板上。 -
这样做的好处是:信号路径更短,电气性能更优,供电能力远超
PCIe插槽,并且节省空间。
2)远超PCIe的供电能力:
-
一个标准的
PCIe 5.0 x16插槽最大供电能力约为600W。 -
而
H100 SXM版本的TDP(热设计功耗)高达700W。这额外的电力必须通过专用的、更粗的电源通道直接从服务器电源提供,以确保GPU在满负荷运行时稳定工作。
3)极致的互联带宽:原生NVLink支持
-
这是
SXM形式最核心的优势。SXM主板为GPU之间提供了原生、高速的NVLink互联通道。 -
H100 SXM每个GPU提供18 个 NVLink 4.0链路,总双向带宽高达900 GB/s。 -
相比之下,
PCIe版本的H100(例如H100 PCIe)通常只有7个NVLink 链路(用于卡间互联),带宽约为400 GB/s,并且需要通过外部桥接器连接。
以H100为例,SXM与PCIe两种形式对比:
2、SXM与NVSwitch的关系:天作之合
它们的关系是高度协同、相互依赖的,共同目标是释放多GPU系统的最大潜能。
1)SXM为NVSwitch提供物理基础:
-
SXM形式因子通过主板上的精密布线,将每个GPU,例如H100,18个NVLink端口直接引出来,连接到NVSwitch芯片上。 -
这种设计提供了最高质量的信号完整性,使得超高速(例如
H100,900 GB/s)的带宽能够稳定实现。这是使用外部桥接器的PCIe卡无法比拟的。
2)NVSwitch为SXM GPU提供极致互联:
-
SXM提供了“高速公路的入口”(高速NVLink端口),而NVSwitch则是整个城市的“立体交通枢纽系统”,它确保了任何两条“高速公路”之间都能无缝、高效地对接,没有拥堵和红灯。 -
没有
NVSwitch,SXM GPU之间的NVLink连接将是有限和局部的。有了NVSwitch,所有SXM GPU才真正构成了一个统一的计算巨兽。
3)共同应用于顶级平台:
-
这种
SXM + NVSwitch的组合是NVIDIA DGX和HGX系统的标配。 -
例如,
DGX H100服务器就是集成了8个H100 SXM GPU和4个第三代NVSwitch芯片的完美典范,形成了一个计算性能和通信性能都达到极致的AI超级计算机。
八、硬件总结
NVLink是NVIDIA攻克数据传输瓶颈、释放多芯片协同计算潜力的核心技术。它不仅通过极高的带宽和极低的延迟提升了性能,更通过统一内存访问和灵活的拓扑结构(借助NVSwitch)改变了我们构建计算系统的方式。
随着 NVLink Fusion 的开放,其影响力正从NVIDIA内部扩展到更广泛的异构计算生态,力图成为未来AI基础设施的互联标准。
NVSwitch基于NVLink技术构建,旨在解决大规模GPU集群中高带宽、低延迟的通信需求。随着Blackwell架构的推出,NVLink和NVSwitch的性能将进一步升级,支持更复杂和大规模的AI模型。
SXM是一种物理封装和互联标准,它让NVIDIA的数据中心级高性能GPU(例如H100),能够获得远超PCIe的供电和原生高速NVLink支持。
未来,随着AI模型规模的持续增长,NVSwitch及其后续技术将在构建高效GPU集群中发挥更加核心的作用。
九、写在最后
NVSwitch主要用于NVIDIA的高性能计算GPU,例如H100,并不涉及到RTX消费级GPU。早期消费级RTX GPU通常使用NVLink桥接器SLI实现多卡互联(现已不再支持)。这本质上是点对点的直接连接,并不能像NVSwitch那样实现真正的全互联拓扑。
因此,在多GPU并行计算时,尤其是需要所有GPU频繁交换数据的场景(如大规模AI训练),NVSwitch更能发挥多GPU性能与I/O。当然,优秀的硬件代价是更昂贵的价格,这也是什么H100 SXM比H100 PCIe贵的原因。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)