生成式AI助力金融合规可疑交易报告自动生成
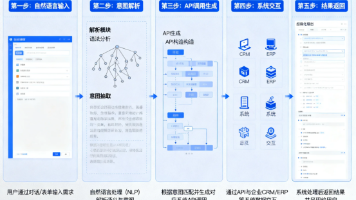
该解决方案使用某中心Bedrock知识库、某中心Bedrock代理、AWS Lambda、某中心简单存储服务(S3)和OpenSearch服务。用户通过业务应用程序请求创建STR报告草案。应用程序调用某中心Bedrock代理,该代理已预配置详细指令以与用户进行对话流。代理遵循这些指令从用户那里收集所需信息,通过调用行动组调用Lambda函数完成缺失信息,并以指定格式生成报告。根据其指令,代理调用某
金融法规和合规要求不断变化,合规报告的自动化已成为金融行业的变革性技术。某中心的生成式AI解决方案为自动化报告流程提供了无缝高效的方法。将生成式AI集成到合规框架中,不仅能提高效率,还能通过提升报告精确性和及时性,增强金融行业的信心和信任度。这些解决方案帮助金融机构避免因不合规带来的高昂成本和声誉损失,从而促进金融生态系统的整体稳定性和完整性。
某中心Bedrock是一项托管生成式AI服务,提供多种先进基础模型(FMs)。该服务包含高效创建生成式AI应用的功能,并高度重视隐私和安全。从基础模型获得良好响应很大程度上依赖于使用高效的提示技术。检索增强生成(RAG)是一种关键方法,通过从外部源获取上下文相关信息来增强基础模型提示。它使用向量数据库(如某中心OpenSearch服务)实现上下文信息的语义搜索。
某中心Bedrock知识库由某中心OpenSearch Serverless等向量数据库驱动,帮助实现RAG,用来自事实资源的相关信息补充模型输入,从而减少潜在幻觉并提高响应准确性。
某中心Bedrock代理使生成式AI应用能够使用行动组执行多步任务,并与API、知识库和基础模型交互。通过代理,可以设计直观且适应性强的生成式AI应用,能够理解自然语言查询并创建吸引人的对话以收集有效使用基础模型所需的细节。
可疑交易报告(STR)或可疑活动报告(SAR)是金融机构在活动中有合理理由怀疑已发生或试图进行的金融交易时必须向金融监管机构提交的一种报告。提交这些报告有规定的时间限制,通常需要数小时的人工努力才能为一个客户账户创建一份报告。
本文探讨了一种使用某中心Bedrock中的基础模型创建STR草案的解决方案。涵盖了如何利用生成式AI自动化草案生成的手动过程,使用账户信息、交易详情和通信摘要,以及创建涉及此类交易的欺诈实体信息知识库。
解决方案概述
该解决方案使用某中心Bedrock知识库、某中心Bedrock代理、AWS Lambda、某中心简单存储服务(S3)和OpenSearch服务。工作流程如下:
- 用户通过业务应用程序请求创建STR报告草案。
- 应用程序调用某中心Bedrock代理,该代理已预配置详细指令以与用户进行对话流。代理遵循这些指令从用户那里收集所需信息,通过调用行动组调用Lambda函数完成缺失信息,并以指定格式生成报告。
- 根据其指令,代理调用某中心Bedrock知识库以查找涉及可疑交易的欺诈实体详情。
- 某中心Bedrock知识库查询OpenSearch服务以执行报告所需实体的语义搜索。如果欺诈实体信息在某中心Bedrock知识库中可用,代理遵循其指令为用户生成报告。
- 如果知识库中未找到信息,代理使用聊天界面提示用户提供包含相关信息的网站URL。或者,用户可以在聊天界面中提供关于欺诈实体的描述。
- 如果用户提供可公开访问网站的URL,代理遵循其指令调用行动组以调用Lambda函数爬取网站URL。Lambda函数从网站抓取信息并将其返回给代理用于报告。
- Lambda函数还将抓取的内容存储在S3存储桶中,供搜索索引将来使用。
- 可以编程某中心Bedrock知识库定期扫描S3存储桶,以在OpenSearch服务中索引新内容。
以下图表说明了解决方案架构和工作流程。
可以使用GitHub上的完整代码通过某中心云开发工具包(CDK)部署解决方案。或者,可以按照逐步过程进行手动部署。本文中将介绍两种方法。
先决条件
要实现本文提供的解决方案,必须在某中心Bedrock中启用某中心Titan Text Embeddings V2和Anthropic Claude 3.5 Haiku的模型访问。
使用某中心CDK部署解决方案
要使用某中心CDK设置解决方案,请按照以下步骤操作:
- 验证某中心CDK是否已安装在环境中。有关安装说明,请参考某中心CDK沉浸日研讨会。
- 将某中心CDK更新到版本36.0.0或更高版本:
npm install -g aws-cdk - 在某中心账户中初始化某中心CDK环境:
cdk bootstrap - 克隆包含解决方案文件的GitHub仓库:
git clone https://github.com/aws-samples/suspicious-financial-transactions-reporting - 导航到解决方案目录:
cd financial-transaction-report-drafting-for-compliance - 创建并激活虚拟环境:
激活虚拟环境的方法因操作系统而异。请参考某中心CDK研讨会了解在其他环境中激活的信息。python3 -m venv .venv source .venv/bin/activate - 虚拟环境激活后,安装所需的依赖项:
pip install -r requirements.txt - 部署后端和前端堆栈:
cdk deploy -a ./app.py --all
部署完成后,通过访问某中心CloudFormation控制台检查这些已部署的堆栈。
手动部署
要手动实现解决方案而不使用某中心CDK,请完成以下步骤:
- 设置S3存储桶。
- 创建Lambda函数。
- 设置某中心Bedrock知识库。
- 设置某中心Bedrock代理。
本文中某些屏幕截图中的视觉布局可能与某中心管理控制台上的布局不同。
设置S3存储桶
为文档存储库创建一个具有唯一存储桶名称的S3存储桶。这将是某中心Bedrock知识库的数据源。
创建网站爬虫Lambda函数
使用Python 3.13运行时创建一个名为Url-Scraper的新Lambda函数,以爬取和抓取某中心Bedrock代理提供的网站URL。该函数将抓取内容,将信息发送给代理,并将内容存储在S3存储桶中以供将来参考。
为简洁起见,此代码片段中省略了错误处理。完整代码可在GitHub上获取。
创建一个名为search_suspicious_party.py的新文件,包含以下代码片段:
import boto3
from bs4 import BeautifulSoup
import os
import re
import urllib.request
BUCKET_NAME = os.getenv('S3_BUCKET')
s3 = boto3.client('s3')
def get_receiving_entity_from_url(start_url):
response = urllib.request.urlopen(
urllib.request.Request(url=start_url, method='GET'),
timeout=5)
soup = BeautifulSoup(response.read(), 'html.parser')
# Extract page title
title = soup.title.string if soup.title else 'Untitled'
# Extract page content for specific HTML elements
content = ' '.join(p.get_text() for p in soup.find_all(['p', 'h1', 'h2', 'h3', 'h4', 'h5', 'h6']))
content = re.sub(r'\s+', ' ', content).strip()
s3.put_object(Body=content, Bucket=BUCKET_NAME, Key=f"docs/{title}.txt")
return content
将lambda_function.py中的默认生成代码替换为以下代码:
import json
from search-suspicious-party import *
def lambda_handler(event, context):
# apiPath should match the path specified in action group schema
if event['apiPath'] == '/get-receiving-entity-details':
# Extract the property from request data
start_url = get_named_property(event, 'start_url')
scraped_text = get_receiving_entity_from_url(start_url)
action_response = {
'actionGroup': event['actionGroup'],
'apiPath': event['apiPath'],
'httpMethod': event['httpMethod'],
'httpStatusCode': 200,
'responseBody': {
'application/json': {
'body': json.dumps({'scraped_text': scraped_text})
}
}
}
return {'response': action_response}
# Return an error if apiPath is not recognized
return {
'statusCode': 400,
'body': json.dumps({'error': 'Invalid API path'})
}
def get_named_property(event, name):
return next(
item for item in
event['requestBody']['content']['application/json']['properties']
if item['name'] == name
)['value']
配置Lambda函数
设置一个Lambda环境变量S3_BUCKET。对于值,使用先前创建的S3存储桶。
将Lambda函数的超时持续时间增加到30秒。可以根据爬虫完成工作所需的时间调整此值。
设置某中心Bedrock知识库
完成以下步骤以在某中心Bedrock中创建新的知识库。该知识库将使用OpenSearch Serverless索引存储在Amazon S3中的欺诈实体数据。有关更多信息,请参考通过连接到某中心Bedrock知识库中的数据源创建知识库。
- 在某中心Bedrock控制台上,选择导航窗格中的知识库,然后选择创建知识库。
- 对于知识库名称,输入一个名称(例如,str-knowledge-base)。
- 对于服务角色名称,保留默认的系统生成值。
- 选择Amazon S3作为数据源。
- 配置Amazon S3数据源:
- 对于数据源名称,输入一个名称(例如,knowledge-base-data-source-s3)。
- 对于S3 URI,选择浏览S3并选择存储桶,其中包含网络爬虫抓取的关于欺诈实体的信息,供知识库使用。
- 保留所有其他默认值。
- 对于嵌入模型,选择Titan Text Embeddings V2。
- 对于向量数据库,选择快速创建新的向量存储以使用OpenSearch Serverless创建默认向量存储。
- 查看配置并选择创建知识库。
知识库成功创建后,可以看到知识库ID,在创建某中心Bedrock中的代理时将需要此ID。
从数据源列表中选择knowledge-base-data-source-s3,并选择同步以索引文档。
设置某中心Bedrock代理
要创建新的代理,请完成以下步骤。有关更多信息,请参考手动创建和配置代理。
-
在某中心Bedrock控制台上,选择导航窗格中的代理,然后选择创建代理。
-
对于名称,输入一个名称(例如,agent-str)。
-
选择创建。
-
对于代理资源角色,保留默认设置(创建并使用新的服务角色)。
-
对于选择模型,选择一个模型提供商和模型名称(例如,Anthropic的Claude 3.5 Haiku)。
-
对于代理的指令,提供允许代理调用大型语言模型(LLM)的指令。
可以从GitHub仓库中的agent-instructions.txt文件下载指令。参考下一节了解如何编写指令。
-
保留所有其他默认值。
-
选择保存。
-
在行动组下,选择添加以创建新的行动组。
行动是代理可以通过进行API调用来执行的任务。一组行动组成一个行动组。
-
提供一个定义行动组中所有API的API模式。
-
对于行动组详情,输入一个行动组名称(例如,agent-group-str-url-scraper)。
-
对于行动组类型,选择使用API模式定义。
-
对于行动组调用,选择选择现有的Lambda函数,即先前创建的Lambda函数。
-
对于行动组模式,选择通过内联模式编辑器定义。
-
将默认示例代码替换为以下示例,以定义模式来指定带有默认和强制值的输入参数:
openapi: 3.0.0 info: title: Gather suspicious receiving entity details from website version: 1.0.0 paths: /: post: description: Get details about suspicious receiving entity from the URL operationId: getReceivingEntityDetails requestBody: required: true content: application/json: schema: $ref: "#/components/schemas/ScrapeRequest" responses: "200": description: Receiving entity details gathered successfully components: schemas: ScrapeRequest: type: object properties: : type: string description: The URL to start scraping from required: - start_url -
选择创建。
-
在知识库下,选择添加。
-
对于选择知识库,选择先前创建的知识库-str,并添加以下指令:
使用知识库-str知识库中的信息选择交易报告。 -
选择保存以保存所有更改。
-
最后,选择准备以使此代理准备好进行测试。
还可以创建一个Streamlit应用程序为此应用程序创建UI。源代码可在GitHub上获取。
代理指令
某中心Bedrock代理的代理指令提供了一种多步用户交互机制,以收集代理调用LLM所需输入,使用丰富的提示以所需格式生成响应。以纯英语提供逻辑指令。这些指令没有预定义的格式。
-
提供任务概述,包括角色:
您是创建金融合规用例可疑交易报告(STR)草案的金融用户。 -
提供代理可用于启动用户交互的消息:
用消息“Hi <name>。欢迎来到STR报告起草。我能帮什么忙?”问候用户。 要求用户提供交易详情。从交易详情中,在<answer>标签中捕获响应,并包括<thinking>标签以理解响应背后的理由。 -
指定需要对从LLM接收的输出进行的处理:
对于用户提供的交易输入,为提供的银行账户和交易详情创建金融风险报告的叙述性描述。 1. 在叙述性描述中添加通信日志的摘要,包括标题、摘要、通信历史和分析。 2. 在叙述性描述中添加关于接收实体的详情。您可以从代理行动组获取关于接收实体的详情。 -
提供代理可用于多步交互以收集缺失输入的可选消息(如果需要):
如果您没有关于接收实体的知识,您应该向人类询问更多关于它的详情,消息为“不幸的是,我没有足够的上下文或关于接收实体<实体名称>的详情来提供准确的风险评估或摘要。您能提供一些关于<实体名称>的额外背景信息吗?<实体名称>的URL或描述是什么?” -
指定代理可以采取的行动,以使用行动组处理用户输入:
如果用户提供<实体名称>的URL,调用行动组<添加行动组名称>以获取详情。如果用户提供<实体名称>的描述,则总结并将其添加到叙述性描述中作为接收实体。 -
指定代理应如何提供响应,包括格式详情:
一旦您拥有所有必要的输入(金融交易详情和接收实体详情),创建一个详细且格式良好的草案报告,用于金融风险报告,包含提供的银行账户和交易详情,包括以下部分: 1. 标题 2. 交易摘要 3. 通信历史与分析 4. 接收实体摘要
测试解决方案
要测试解决方案,请按照以下步骤操作:
- 选择测试以开始测试代理。
- 启动聊天并观察代理如何使用配置步骤中提供的指令询问生成报告所需的详情。
- 尝试不同的提示,例如“为账户生成STR”。
屏幕截图显示了一个示例聊天。
另一个选项是同时提供所有详情,例如“为账户号12345-999-7654321生成STR,包含以下交易。”
从GitHub上的sample-transactions.txt文件复制并粘贴示例交易。
代理会不断询问缺失信息,如账户号、交易详情和通信历史。在拥有所有详情后,它将生成STR草案文档。
GitHub上的代码还包含一个示例StreamLit应用程序,可用于测试应用程序。
清理
为避免产生不必要的未来费用,请清理作为此解决方案一部分创建的资源。如果使用GitHub代码示例和某中心CDK创建了解决方案,请清空S3存储桶并删除CloudFormation堆栈。如果手动创建了解决方案,请完成以下步骤:
- 删除某中心Bedrock代理。
- 删除某中心Bedrock知识库。
- 清空并删除S3存储桶(如果专门为此解决方案创建了一个)。
- 删除Lambda函数。
结论
在本文中,我们展示了某中心Bedrock如何为构建生成式AI应用提供强大环境,具有一系列先进的基础模型。这项完全托管的服务优先考虑隐私和安全,同时帮助开发人员高效创建AI驱动的应用。一个突出特性RAG使用外部知识库用相关信息丰富AI生成的内容,并由OpenSearch服务作为其向量数据库支持。此外,可以在知识库和代理会话上下文中包含元数据字段,通过某中心验证权限传递细粒度访问上下文以进行授权。
通过仔细的提示工程,某中心Bedrock最大限度地减少了不准确性,并确保AI响应基于事实文档。这种先进技术和数据完整性的结合使某中心Bedrock成为任何寻求开发可靠生成式AI解决方案的人的理想选择。现在可以探索扩展此示例代码,使用某中心Bedrock和RAG可靠地生成合规报告的草案文档。
更多精彩内容 请关注我的个人公众号 公众号(办公AI智能小助手)或者 我的个人博客 https://blog.qife122.com/
公众号二维码

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献132条内容
已为社区贡献132条内容

所有评论(0)