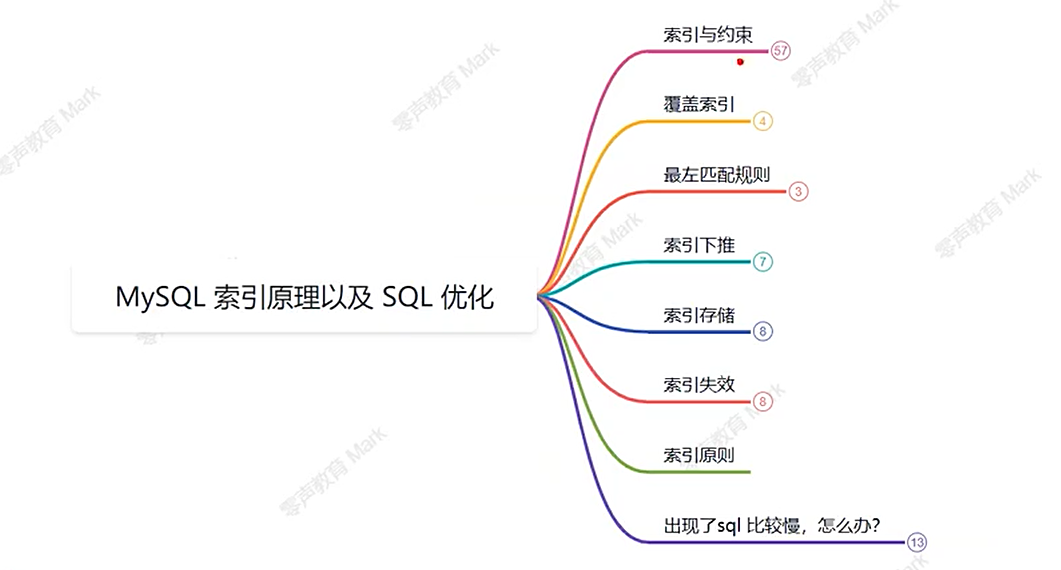
MySQL索引原理以及SQL优化
MySQL索引是加速查询的有序数据结构(如B+树),存储字段值和对应数据位置。索引依附于表,不能独立存在。常见索引类型包括主键、普通、组合索引等。组合索引需遵循最左匹配原则,否则可能失效。索引失效原因包括:使用函数/表达式、模糊查询以%开头、OR条件含未索引字段、隐式类型转换等。优化策略包括:使用覆盖索引、索引下推减少回表、合理设计组合索引等。EXPLAIN命令可分析索引使用情况,Buffer P
索引是什么?

PRIMARY KEY主键索引
KEY 普通索引
在 MySQL 中,索引不是一张 “单独的表”,但它会以独立的数据结构形式存储在磁盘上,与表的数据分开存放(可以理解为 “依附于表的特殊文件”)。
具体解释:
- 索引的本质:特殊数据结构
索引是为了加速查询而创建的有序数据结构(常见的有 B + 树、哈希表等,MySQL 中最常用的是 B + 树),它存储了表中某些字段的值以及这些值对应的 “数据行位置”(如物理磁盘地址或主键 ID)。
例如:为 user 表的 name 字段创建索引后,索引会以 “姓名→数据行位置” 的映射关系有序存储,查询 WHERE name='张三' 时,数据库可直接通过索引快速定位到对应的数据行,无需全表扫描。
- 索引与表的关系:依附于表,不能独立存在
- 索引必须基于某个表创建,与表 “绑定”(删除表时,其所有索引会被自动删除)。
- 索引不会像表一样存储完整的行数据,只存储 “索引字段值” 和 “数据位置指针”,因此体积通常远小于表本身。
- 一张表可以有多个索引(如
user表可同时为name、age字段创建索引),每个索引是独立的数据结构,但都依附于该表。
索引的目的
提升搜索效率
主键索引

唯一索引

普通索引

组合索引

全文索引

通过关键字反向索引对应的文章
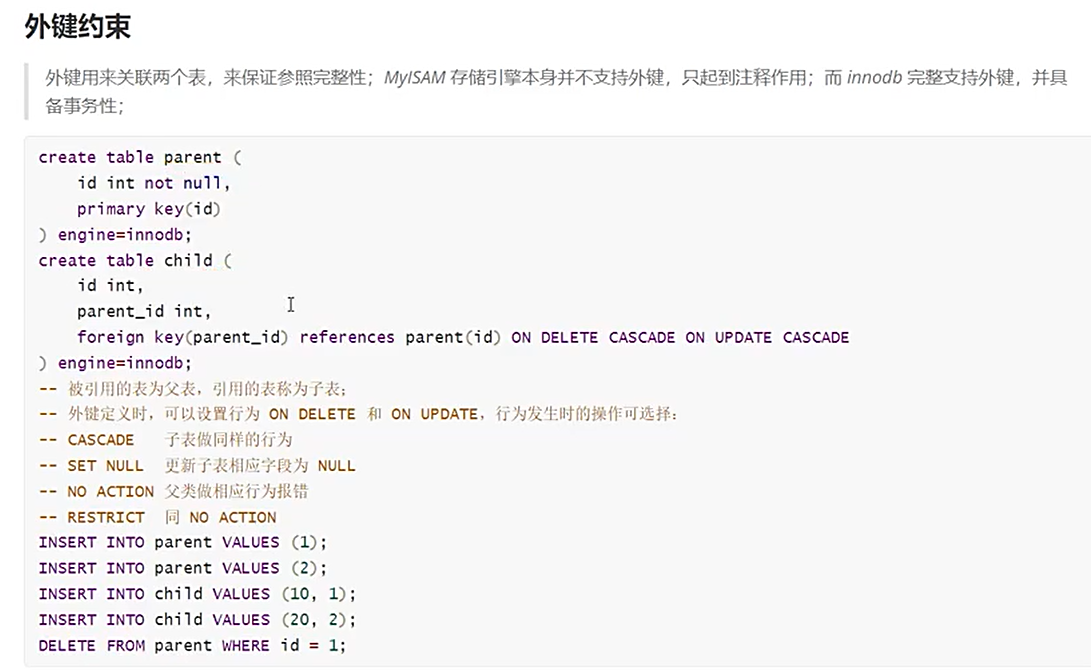
主键选择




约束

primary key:非空唯一
unique key:唯一
foreigh key:外键约束
约束与索引的区别

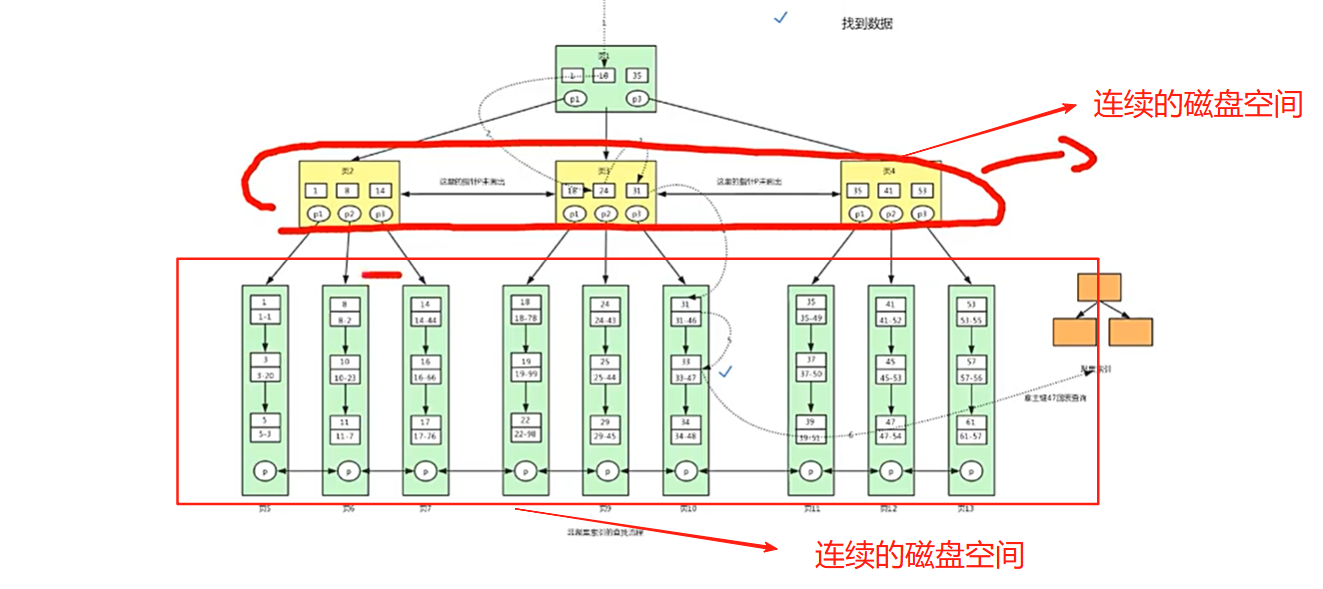
索引的存储形式
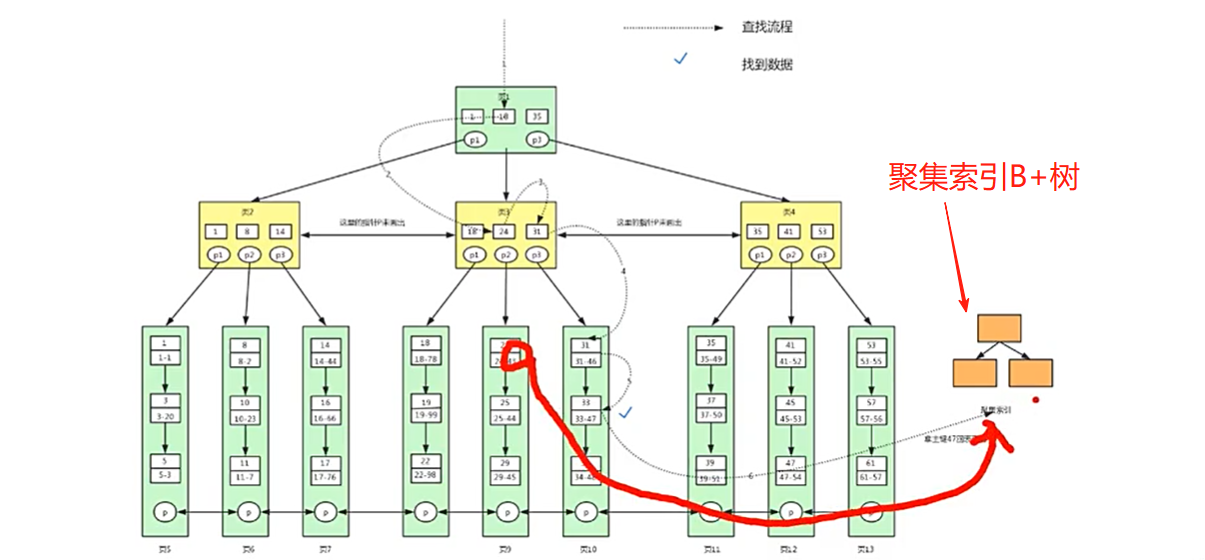
一个索引对应一个B+树
B+树
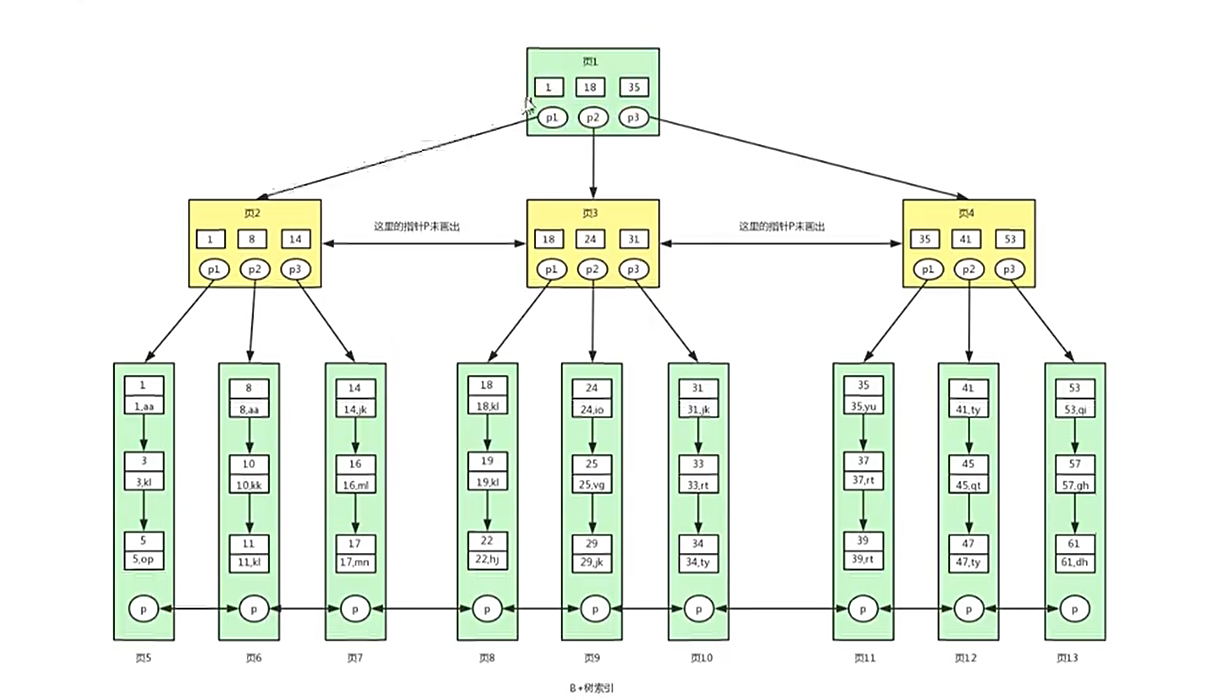

B+树组织的是磁盘的数据
Innodb默认访问4个或者2个连续的物理页,即16KB
对页的访问是一次磁盘IO
非叶子节点只存储索引信息
叶子节点存储具体的数据信息
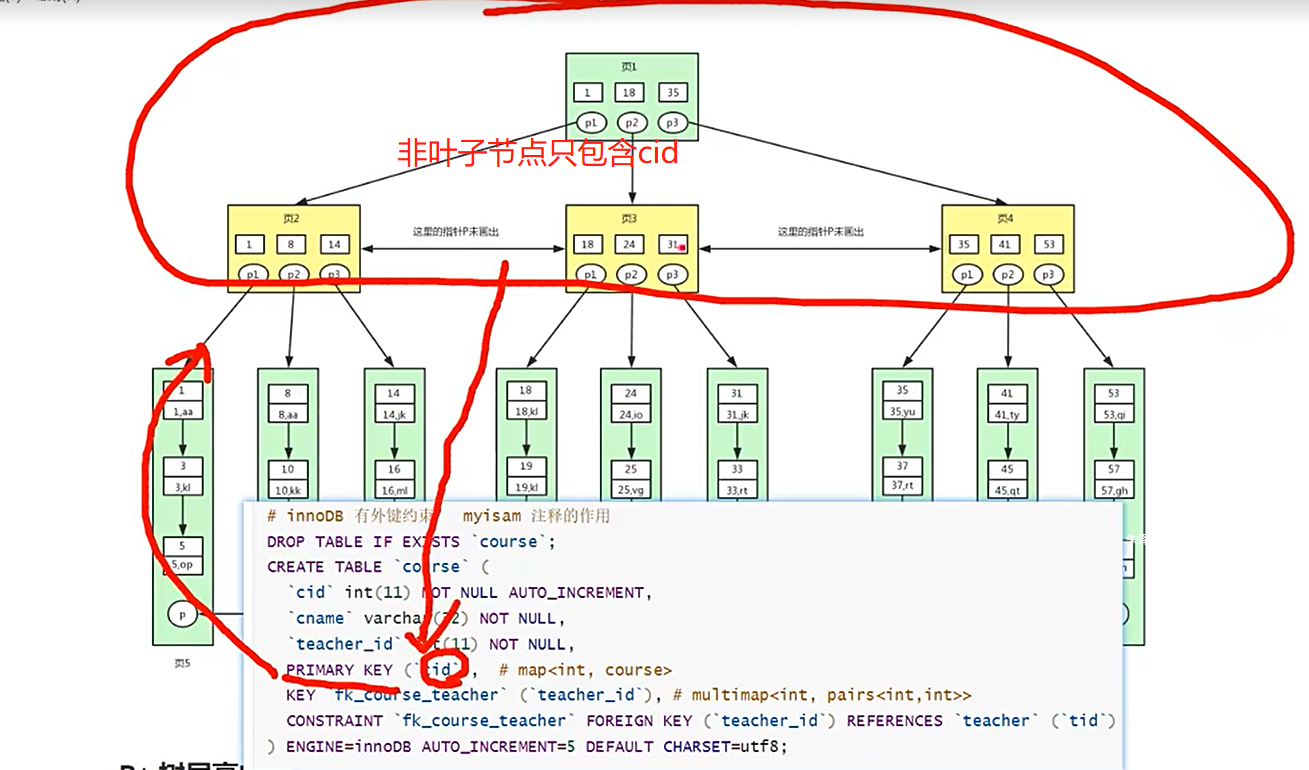


两种类型的B+树:
- 主键B+树(聚集索引B+树)
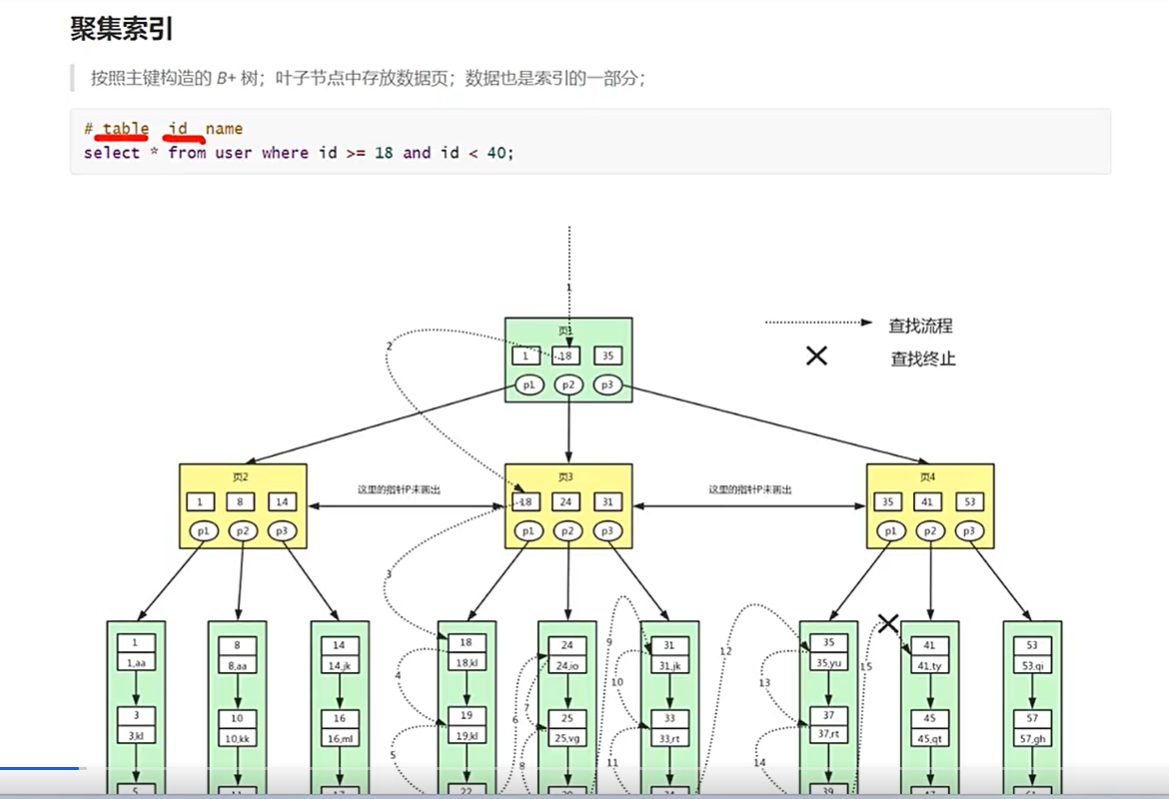
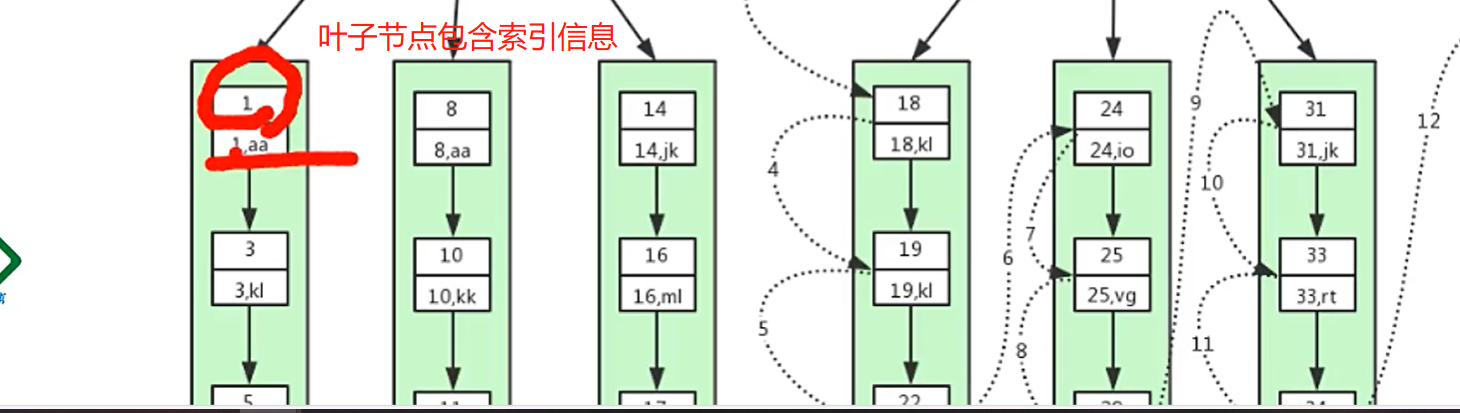
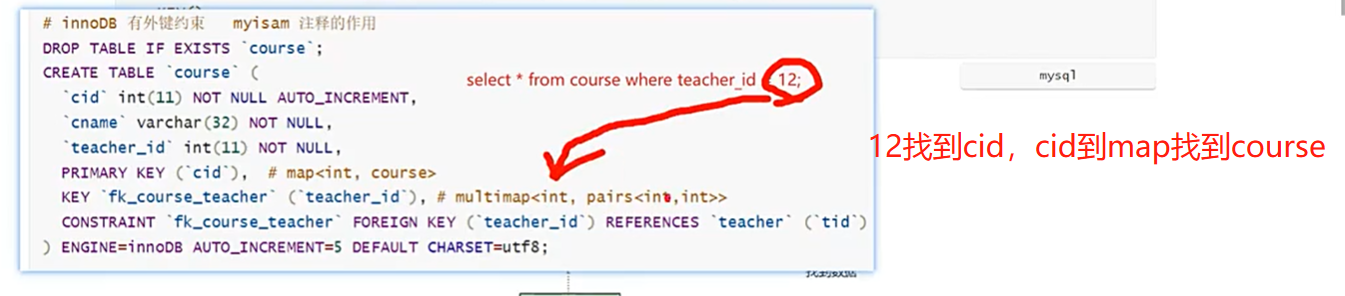
select * from user where id >= 18 and id < 40;
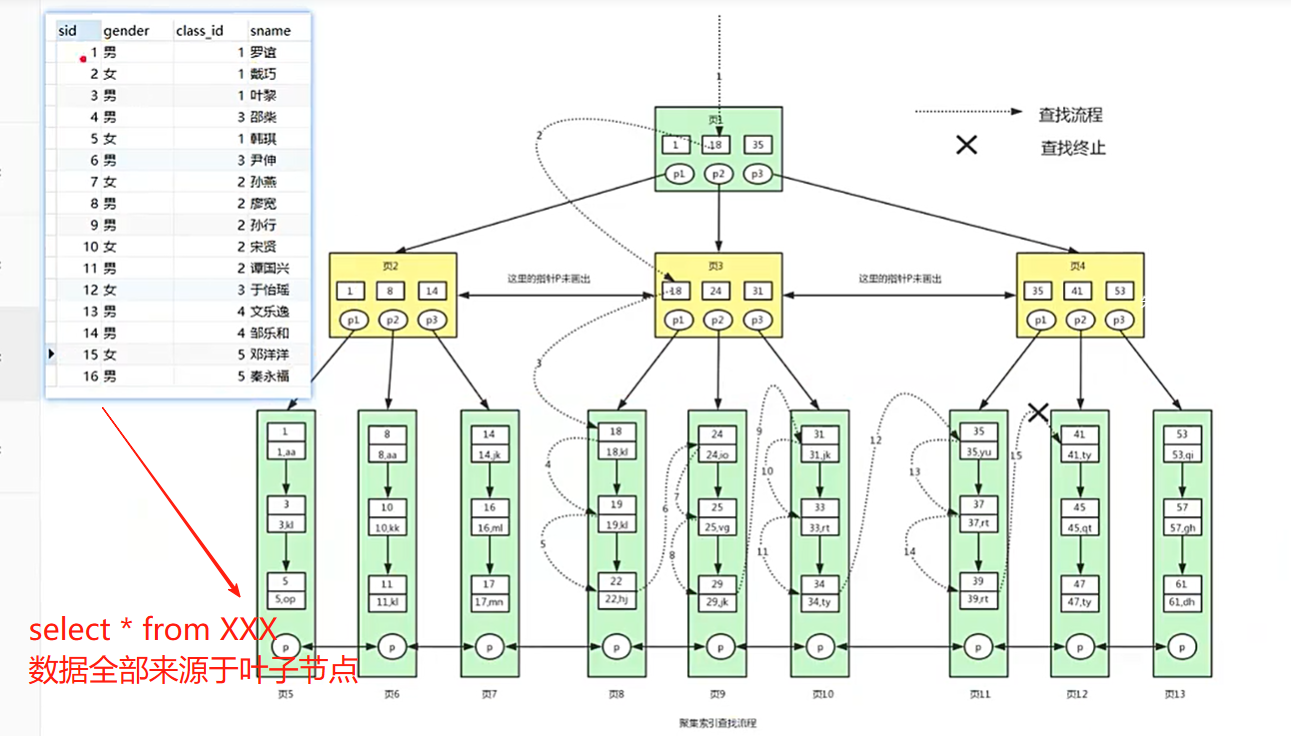
select * from user where id >= 18 and id < 40;共7次磁盘io。
- 二级索引B+树(辅助索引B+树)

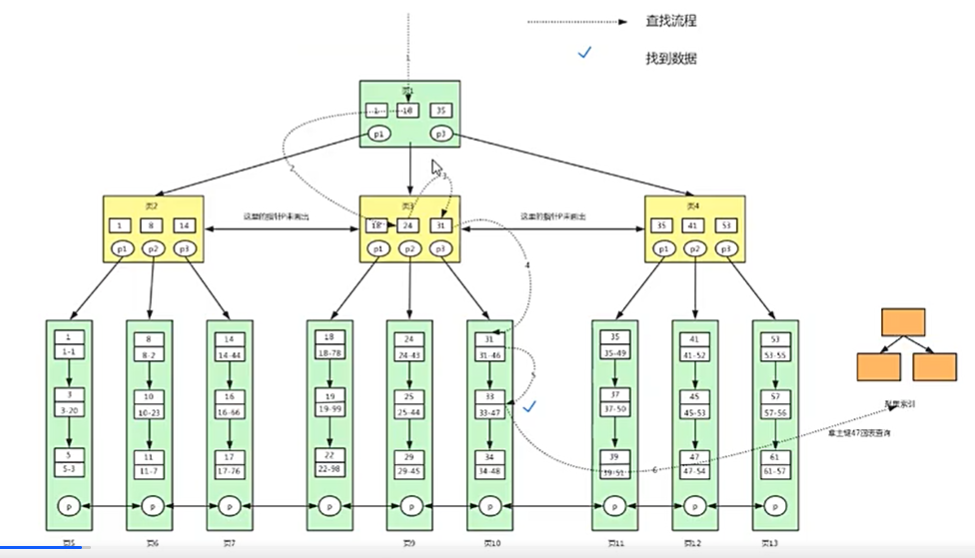
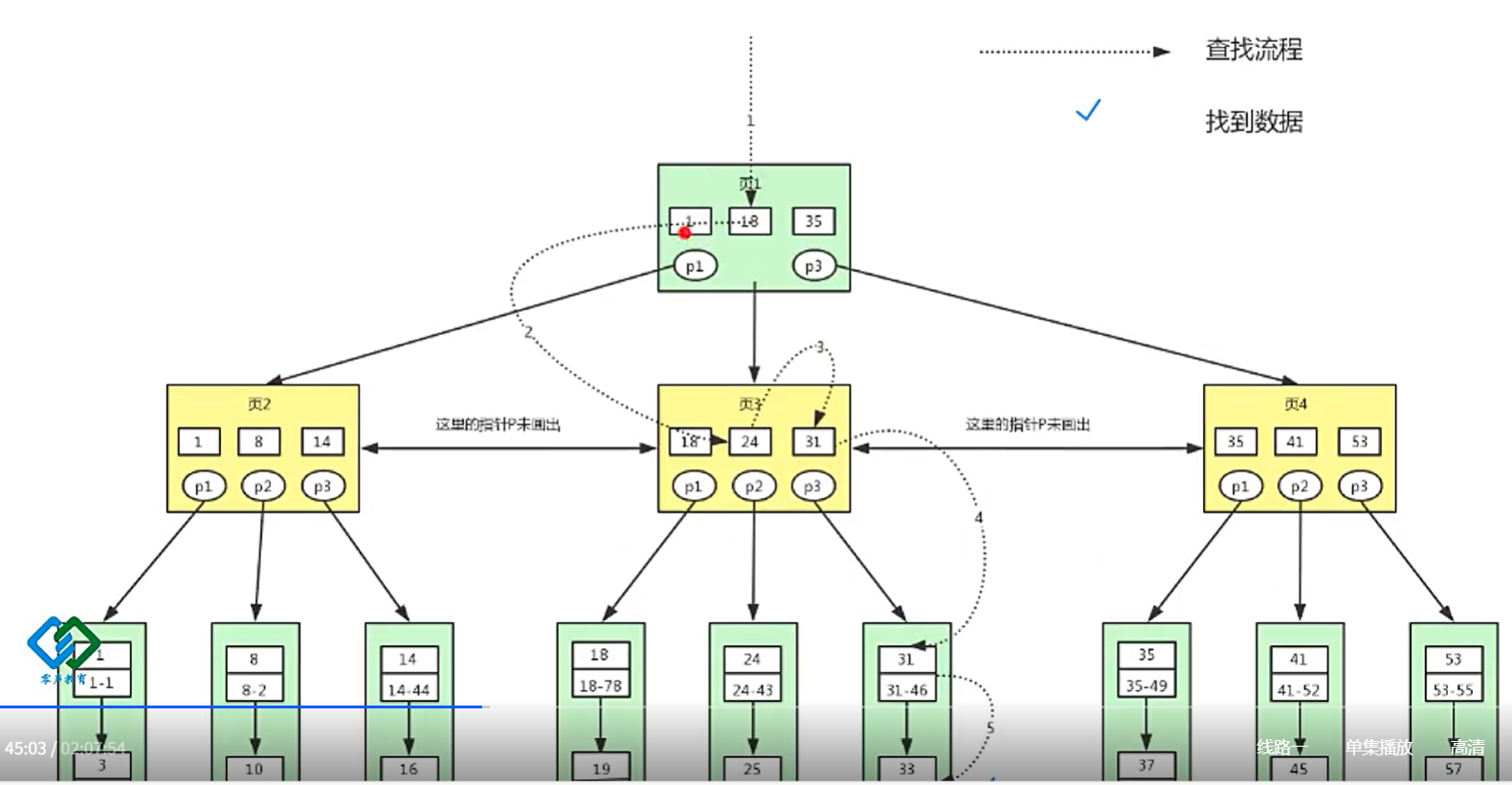
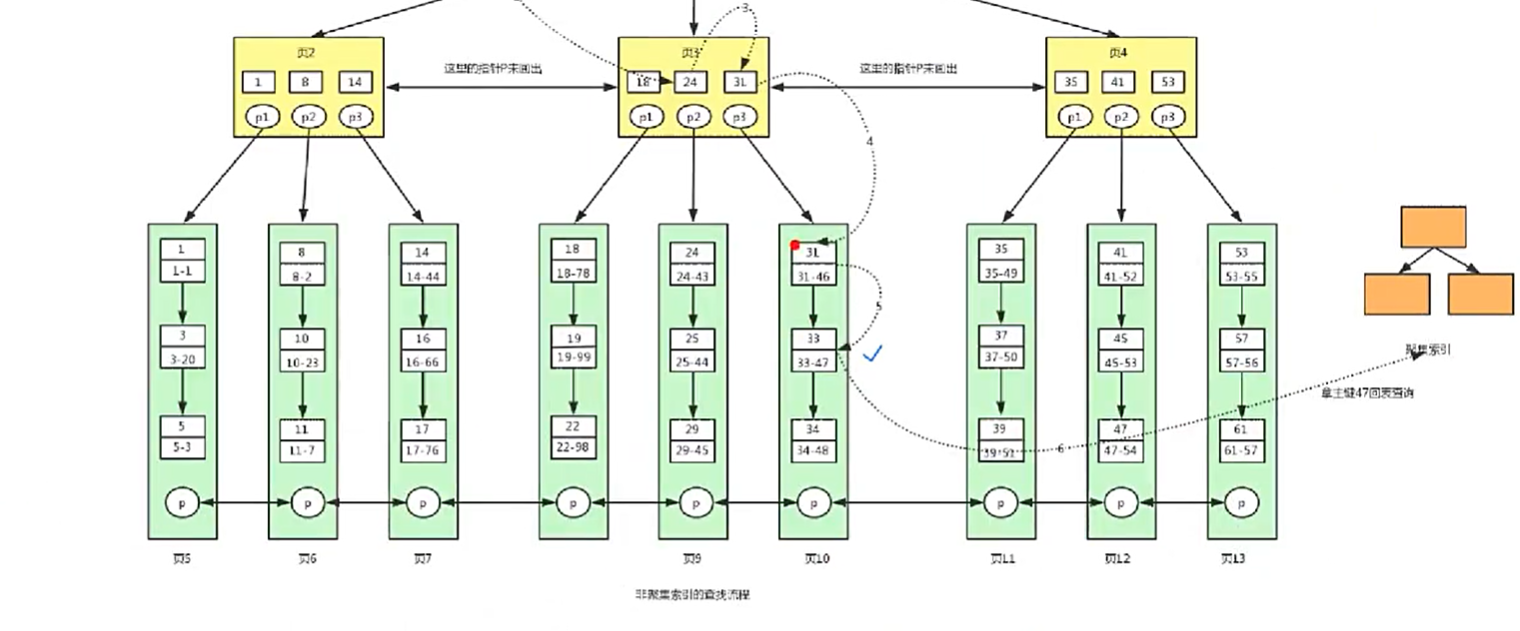
根据47主键回表查询,从聚集索引B+树找到id name lockynum
索引存储
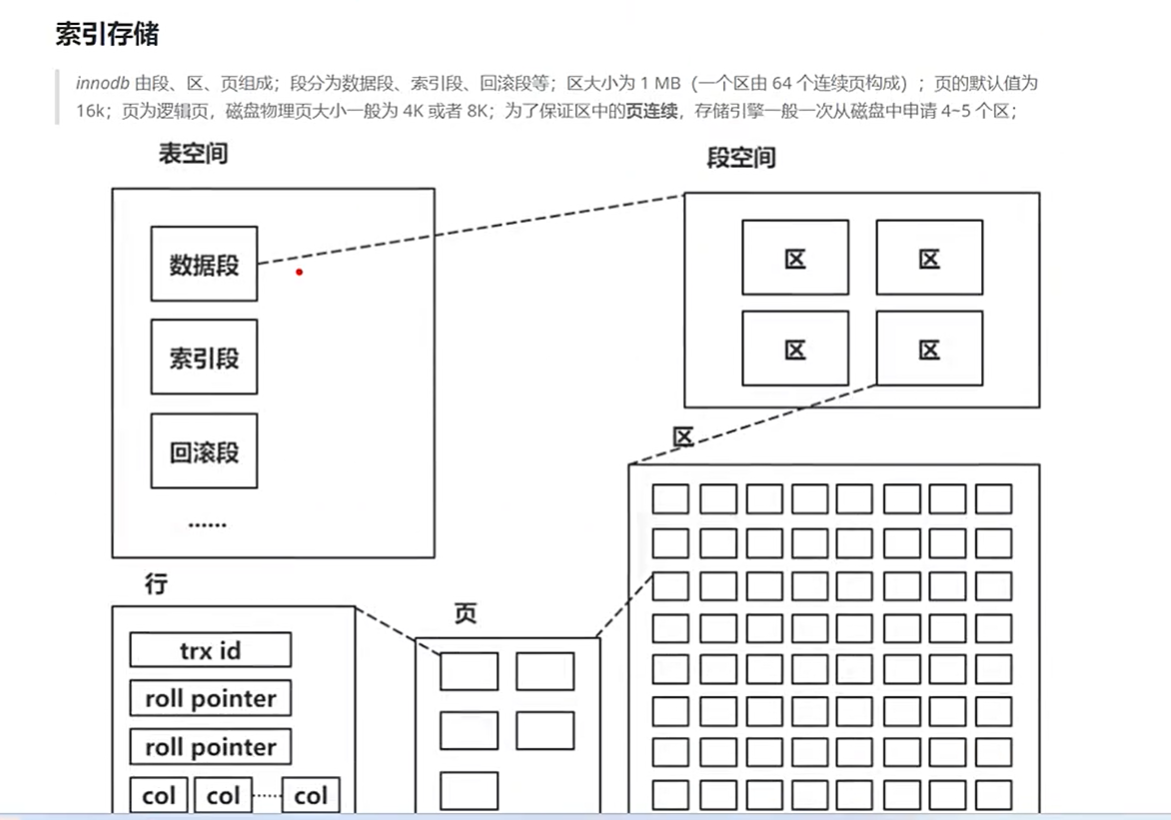
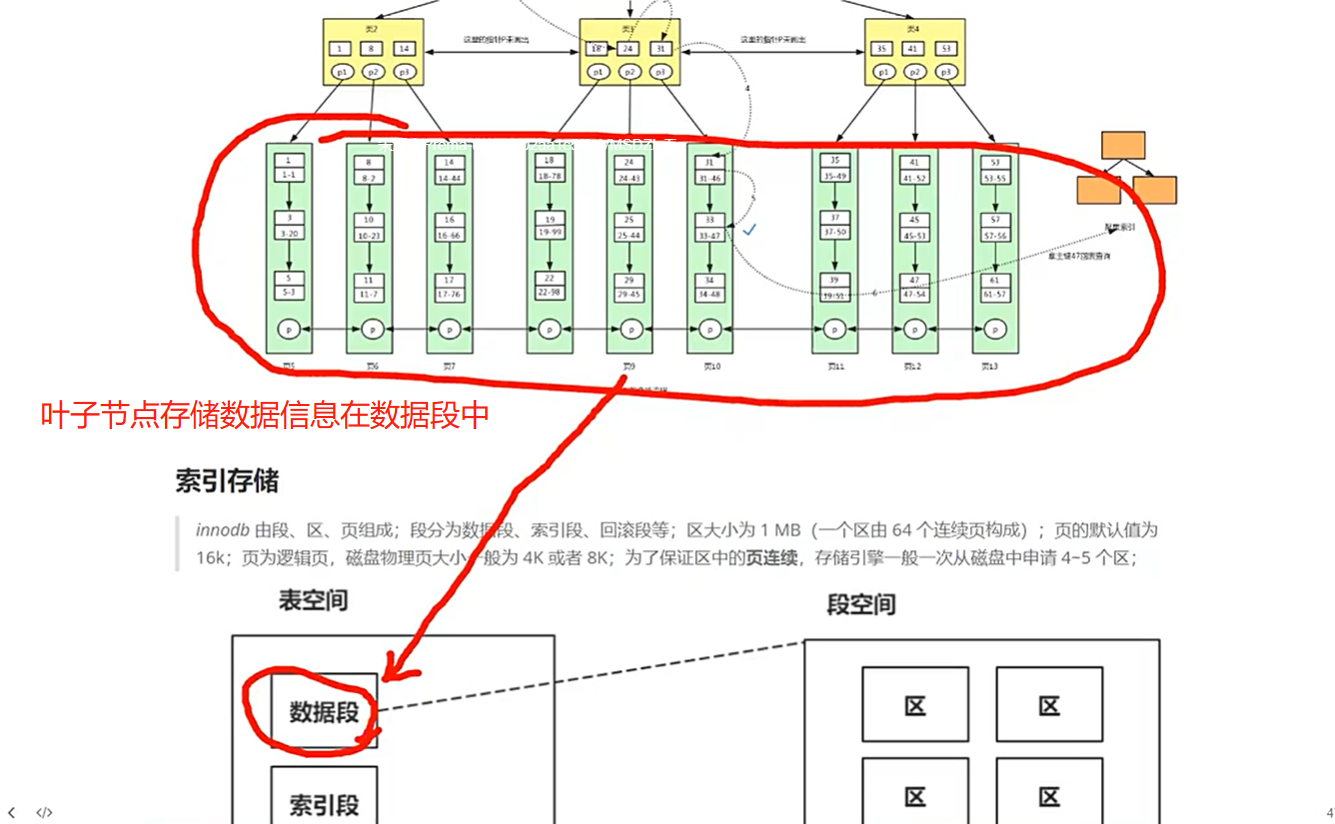
索引节点存储数据信息在索引段中

索引段和数据段分别是不同的连续磁盘页
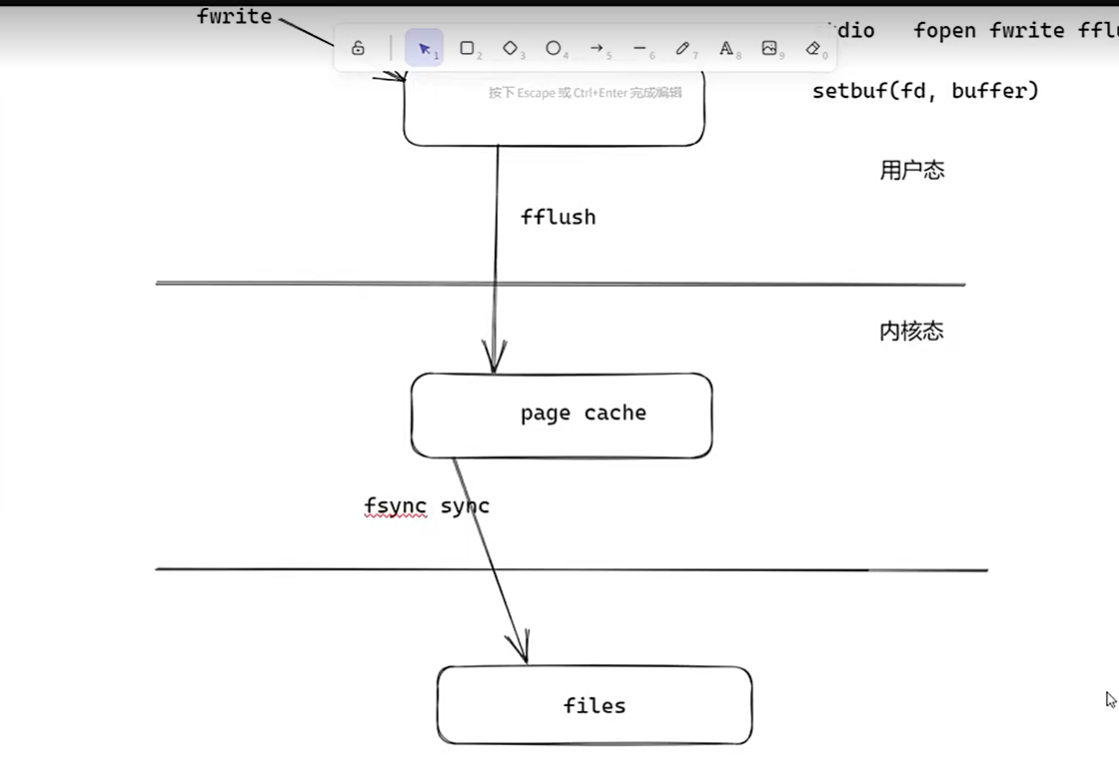
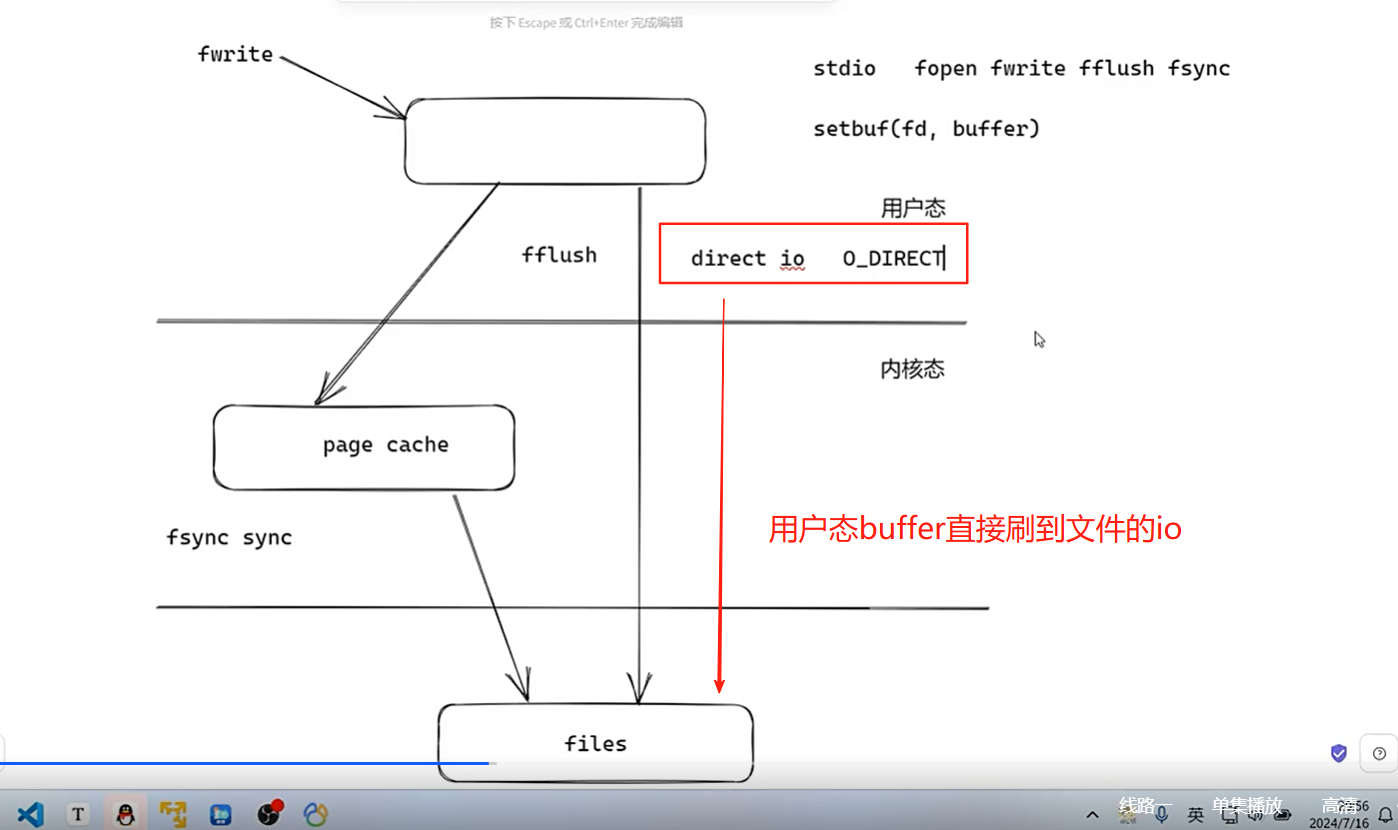
buffer pool缓存B+树经常使用的磁盘数据
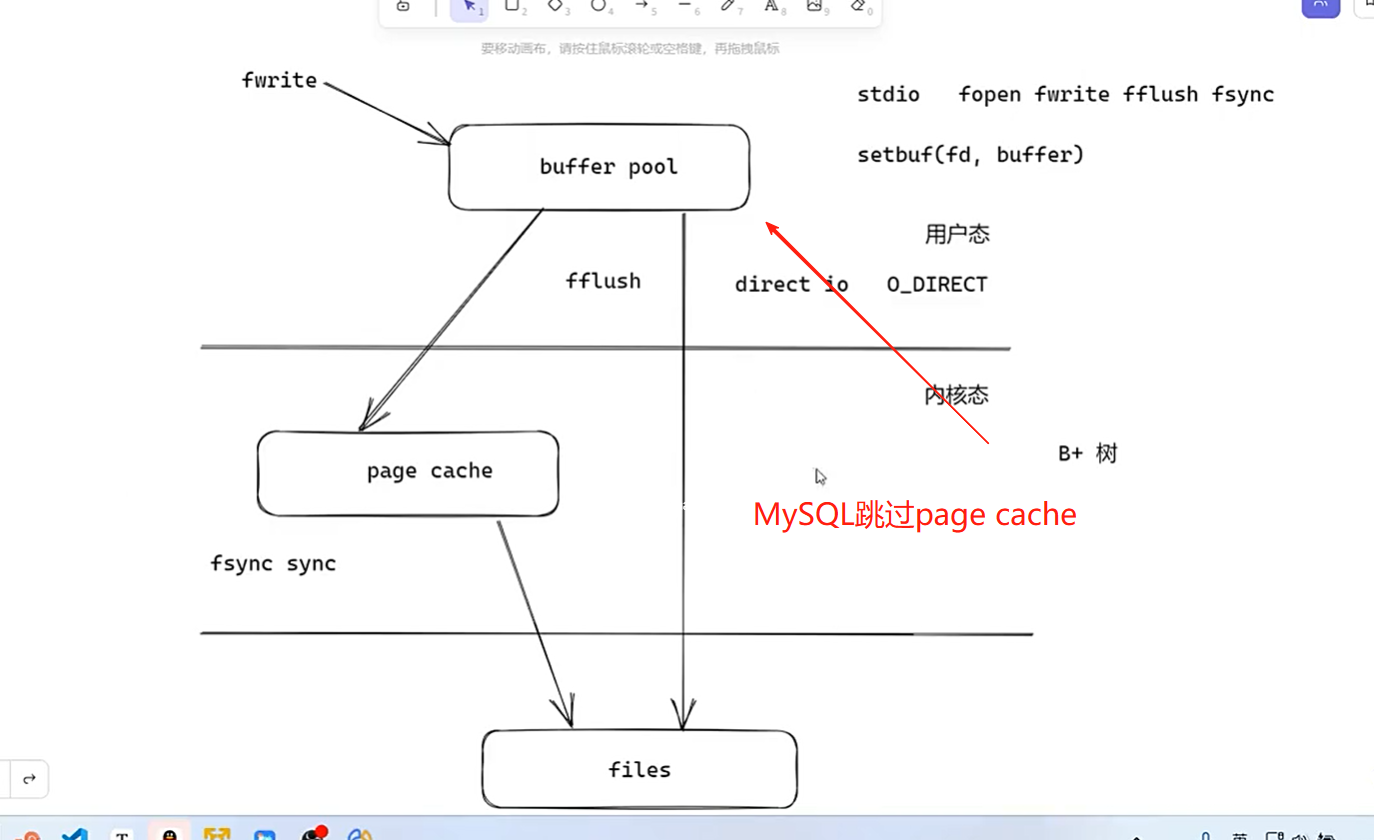
因为用户态无法订制page cache刷盘策略
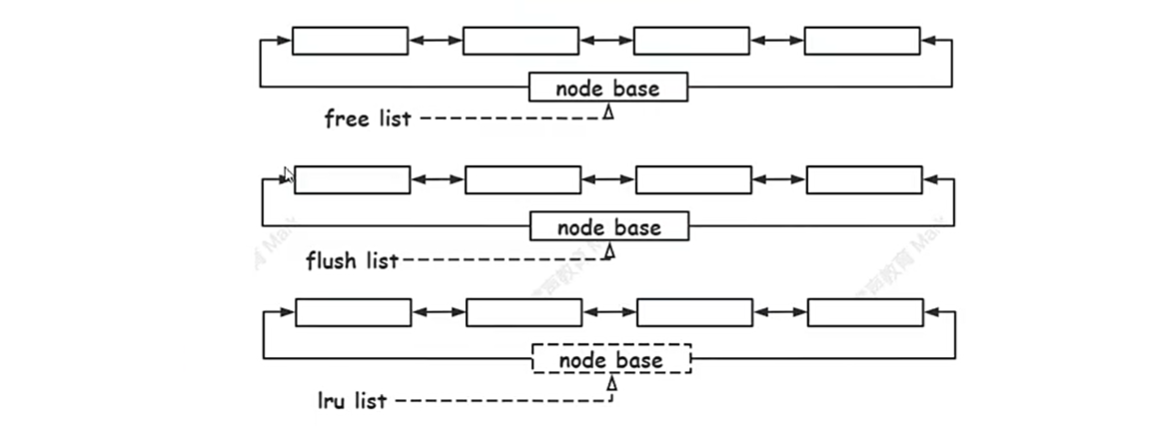
定制buffer_pool,制定LRU淘汰策略管理缓存的B+树的页的数据
Innodb体系结构
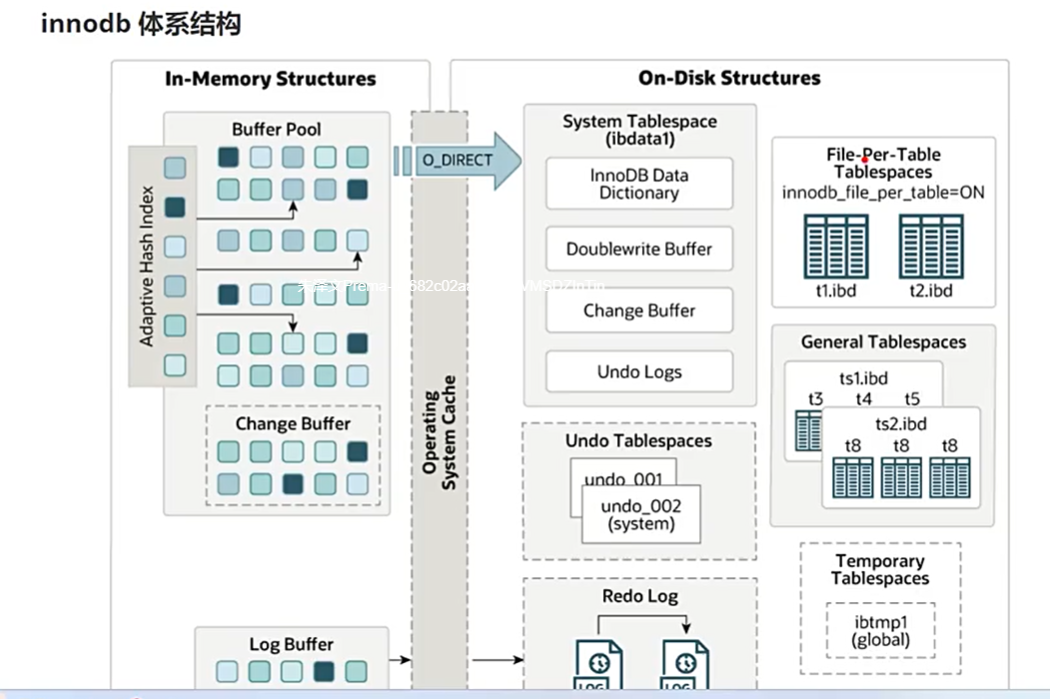
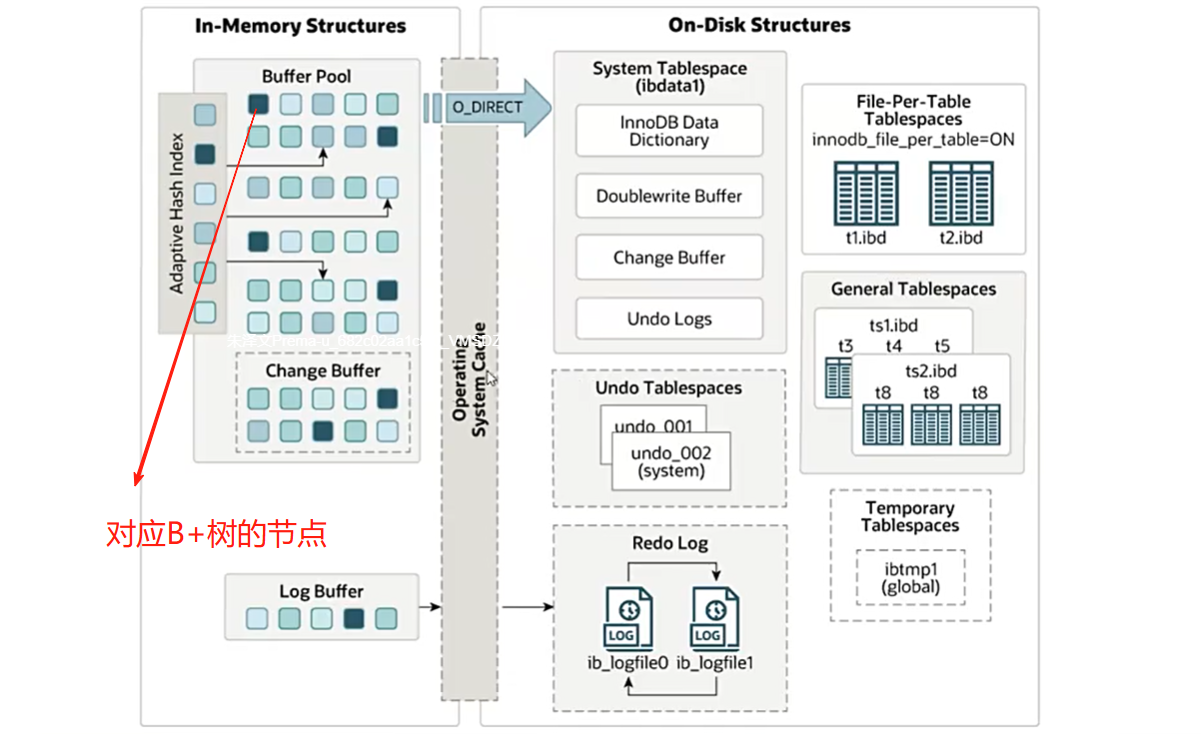
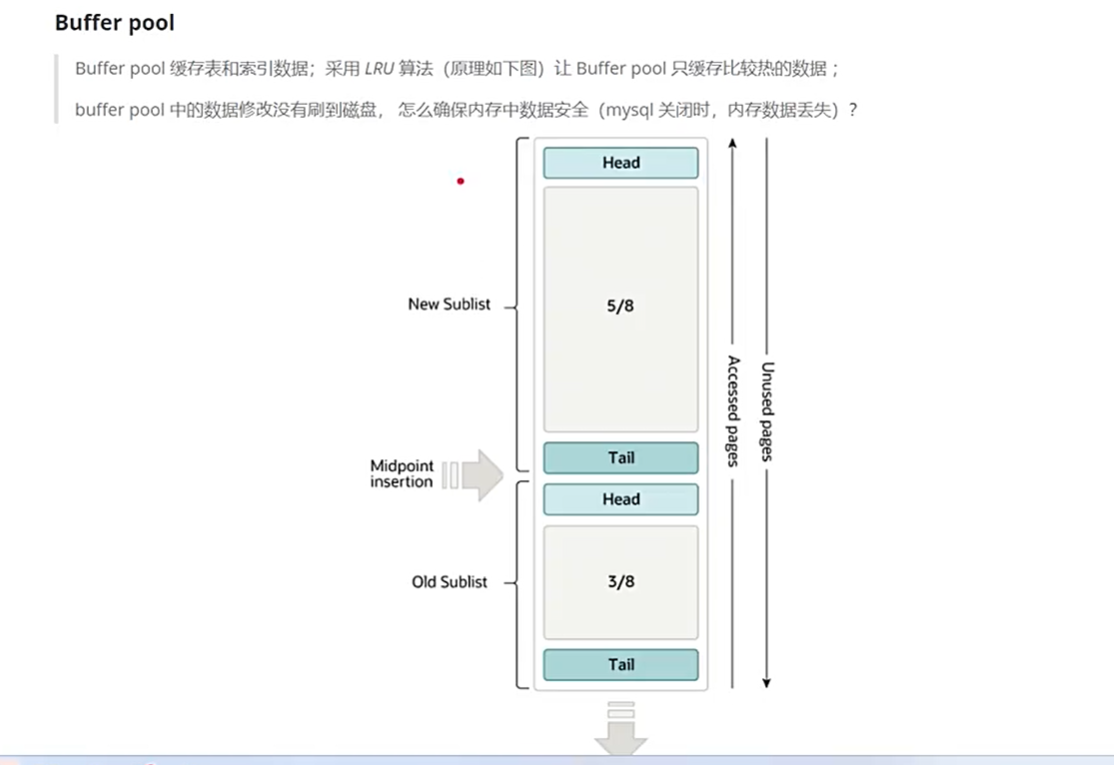
中间点插入最新数据,如果访问它,就往New Sublist这里挪动,如果长时间不访问它,就往Old Sublist移动。

MySQL 的 Change Buffer 是 InnoDB 存储引擎中的一个特殊数据结构,用于临时缓存对非唯一索引页的修改操作(如 INSERT、UPDATE、DELETE),待在修改时立即将这些操作写入磁盘,从而减少磁盘 I/O 并提升性能。
核心作用:优化非唯一索引的写操作
当执行修改操作(如插入一条新记录)时,若涉及的非唯一索引页不在内存中(即未被加载到 Buffer Pool),InnoDB 不会直接去磁盘加载该索引页并修改,而是将修改操作记录到 Change Buffer 中。
后续当需要访问这些索引页时(即索引页被加载到内存),InnoDB 会将 Change Buffer 中缓存的修改操作合并到实际的索引页中(这个过程称为 merge),最终再同步到磁盘。
为什么需要 Change Buffer?
- 减少磁盘 I/O:非唯一索引的修改频率高,且索引页可能频繁不在内存中。若每次修改都直接访问磁盘加载索引页,会产生大量随机 I/O(磁盘随机读写效率极低)。Change Buffer 相当于 “批量处理” 这些修改,降低 I/O 次数。
- 提升写入性能:将分散的小修改缓存起来,合并后一次性写入磁盘,减少了磁盘操作的开销。
适用场景与限制
- 只适用于非唯一索引:
唯一索引(如 PRIMARY KEY、UNIQUE)的修改需要立即校验唯一性(必须加载索引页到内存判断是否重复),因此不能使用 Change Buffer。
- 适合写多查少的场景:
若修改后的索引页短期内不会被访问,Change Buffer 能累积更多修改,合并时效率更高(如日志表、归档表)。反之,若修改后立即查询(索引页被快速加载到内存),Change Buffer 的优势会减弱。
- 存储在 buffer pool 中:
Change Buffer 是 buffer pool 的一部分,占用内存空间。若内存不足,会根据 LRU 策略淘汰部分内容(但会先确保已合并到磁盘)。
对于Buffer Pool和Change Buffer的修改,存放在Redo Log:顺序磁盘io,总是在文件后面附加,相当如redis的aof,用于突发断电后的数据重放恢复丢失的内存数据操作。
Redo Log和Undo Log用的是page cache,B+树的数据用Buffer Pool和Change Buffer。
MySQL 将 Buffer Pool(缓冲池)数据刷到磁盘(持久化)主要通过后台异步刷盘和前台触发刷盘两种机制,核心场景可分为以下几类:
1. 后台异步刷盘(Buffer Pool 自主维护)
这是最主要的刷盘方式,由 MySQL 后台线程(page cleaner线程)主动执行,不阻塞用户查询 / 更新,旨在平衡内存占用与磁盘 IO。
- 触发逻辑:基于 Buffer Pool 的 “脏页比例” 和 “redo log 空间” 两个核心阈值,由参数控制:
- 当脏页占比超过
innodb_max_dirty_pages_pct_lwm(低水位,默认 10%)时,线程开始低频率刷盘;超过innodb_max_dirty_pages_pct(高水位,默认 90%)时,会加速刷盘以避免脏页过多。 - 当redo log 文件(如 ib_logfile)使用空间超过
innodb_log_capacity的一定比例(隐含逻辑),为避免 redo log 写满导致数据库阻塞,会触发刷盘以释放 redo log 空间。
- 当脏页占比超过
2. 前台触发刷盘(阻塞用户操作)
当后台刷盘速度跟不上脏页产生速度,或满足特定条件时,会强制用户线程(执行 SQL 的线程)参与刷盘,此时会阻塞当前操作。
- 场景 1:Buffer Pool 无空闲页
当用户需要加载新数据页到 Buffer Pool,但无空闲页时,会触发 “LRU 淘汰”:若淘汰的是脏页,必须先将其刷到磁盘,才能释放内存。
- 场景 2:执行
FLUSH TABLES WITH READ LOCK
该命令会强制刷入所有脏页,并锁定表为只读,确保磁盘数据与内存一致(常用于全量备份)。
- 场景 3:数据库正常关闭(
SHUTDOWN)
正常关闭时,MySQL 会执行 “干净关闭” 流程,将 Buffer Pool 中所有脏页刷到磁盘,避免数据丢失,再停止服务。
3. 其他主动触发场景
- 执行
ALTER TABLE(DDL 操作)
部分 DDL 操作(如 InnoDB 表的结构修改)会触发脏页刷盘,确保修改前的旧数据已持久化。
- 设置
innodb_flush_log_at_trx_commit=1(事务日志刷盘联动)
虽然该参数主要控制 redo log 的刷盘,但当事务提交时,若对应的脏页未刷盘,会间接触发 “关联脏页” 的优先刷盘(确保事务持久性)。
手撕LRU策略
#include <iostream>
#include <unordered_map>
// 双向链表节点结构
struct Node {
int key;
int value;
Node* prev;
Node* next;
Node(int k, int v) : key(k), value(v), prev(nullptr), next(nullptr) {}
};
class LRUCache {
private:
int capacity; // 缓存容量
std::unordered_map<int, Node*> cache; // 哈希表,用于快速查找节点
Node* head; // 头节点(哨兵)
Node* tail; // 尾节点(哨兵)
// 将节点移动到头部(最近使用)
void moveToHead(Node* node) {
removeNode(node);
addToHead(node);
}
// 从链表中移除节点
void removeNode(Node* node) {
node->prev->next = node->next;
node->next->prev = node->prev;
}
// 将节点添加到头部
void addToHead(Node* node) {
node->prev = head;
node->next = head->next;
head->next->prev = node;
head->next = node;
}
// 移除尾部节点(最少使用)
Node* removeTail() {
Node* node = tail->prev;
removeNode(node);
return node;
}
public:
// 构造函数
LRUCache(int cap) : capacity(cap) {
// 初始化哨兵节点,避免边界判断
head = new Node(0, 0);
tail = new Node(0, 0);
head->next = tail;
tail->prev = head;
}
// 析构函数,释放所有节点
~LRUCache() {
Node* curr = head;
while (curr) {
Node* next = curr->next;
delete curr;
curr = next;
}
}
// 获取缓存值
int get(int key) {
// 如果key不存在,返回-1
if (cache.find(key) == cache.end()) {
return -1;
}
// 如果存在,将节点移到头部(标记为最近使用)
Node* node = cache[key];
moveToHead(node);
return node->value;
}
// 存入缓存
void put(int key, int value) {
// 如果key已存在,更新值并移到头部
if (cache.find(key) != cache.end()) {
Node* node = cache[key];
node->value = value;
moveToHead(node);
return;
}
// 如果key不存在,创建新节点
Node* newNode = new Node(key, value);
cache[key] = newNode;
addToHead(newNode);
// 如果超出容量,删除最少使用的节点(尾部节点)
if (cache.size() > capacity) {
Node* tailNode = removeTail();
cache.erase(tailNode->key);
delete tailNode; // 释放内存
}
}
// 打印缓存内容(用于调试)
void printCache() {
std::cout << "Cache content: ";
Node* curr = head->next;
while (curr != tail) {
std::cout << "(" << curr->key << ":" << curr->value << ") ";
curr = curr->next;
}
std::cout << std::endl;
}
};
// 测试代码
int main() {
LRUCache lru(2); // 创建容量为2的LRU缓存
lru.put(1, 1);
lru.printCache(); // 输出: (1:1)
lru.put(2, 2);
lru.printCache(); // 输出: (2:2) (1:1)
std::cout << lru.get(1) << std::endl; // 输出: 1,此时1变为最近使用
lru.printCache(); // 输出: (1:1) (2:2)
lru.put(3, 3); // 容量满,淘汰最少使用的2
lru.printCache(); // 输出: (3:3) (1:1)
std::cout << lru.get(2) << std::endl; // 输出: -1,2已被淘汰
lru.put(4, 4); // 容量满,淘汰最少使用的1
lru.printCache(); // 输出: (4:4) (3:3)
std::cout << lru.get(1) << std::endl; // 输出: -1,1已被淘汰
std::cout << lru.get(3) << std::endl; // 输出: 3
std::cout << lru.get(4) << std::endl; // 输出: 4
return 0;
}

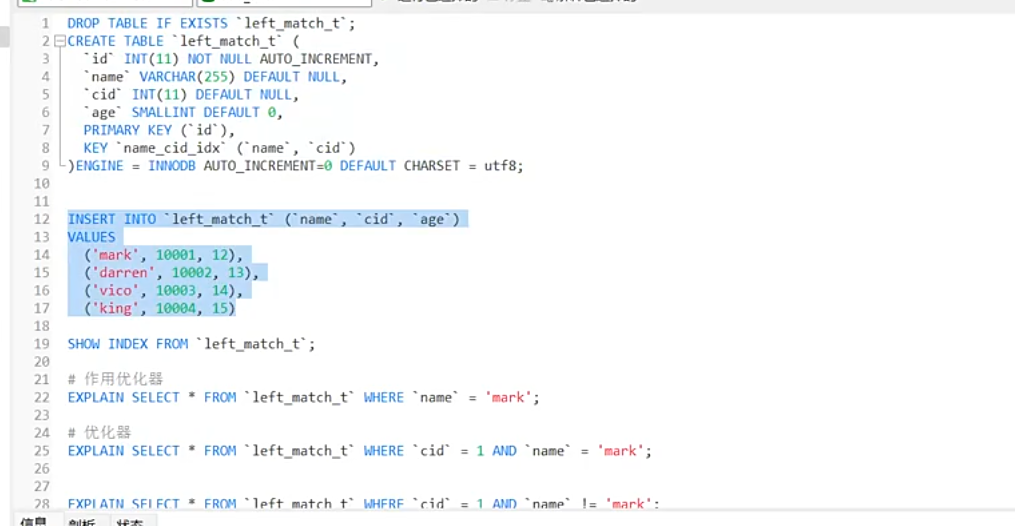
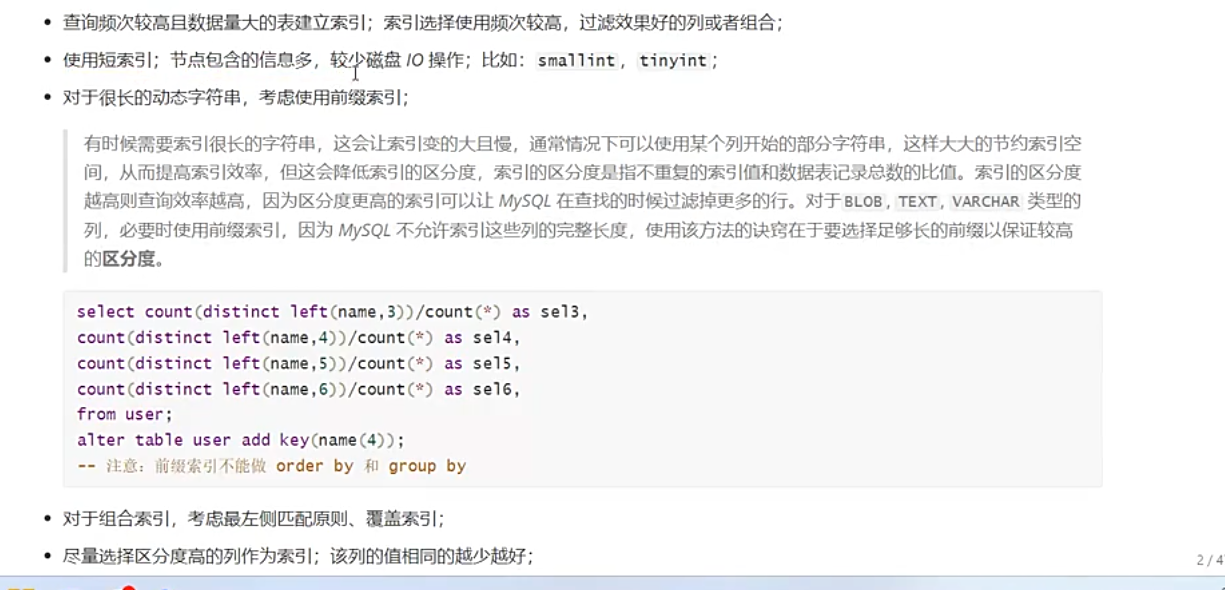
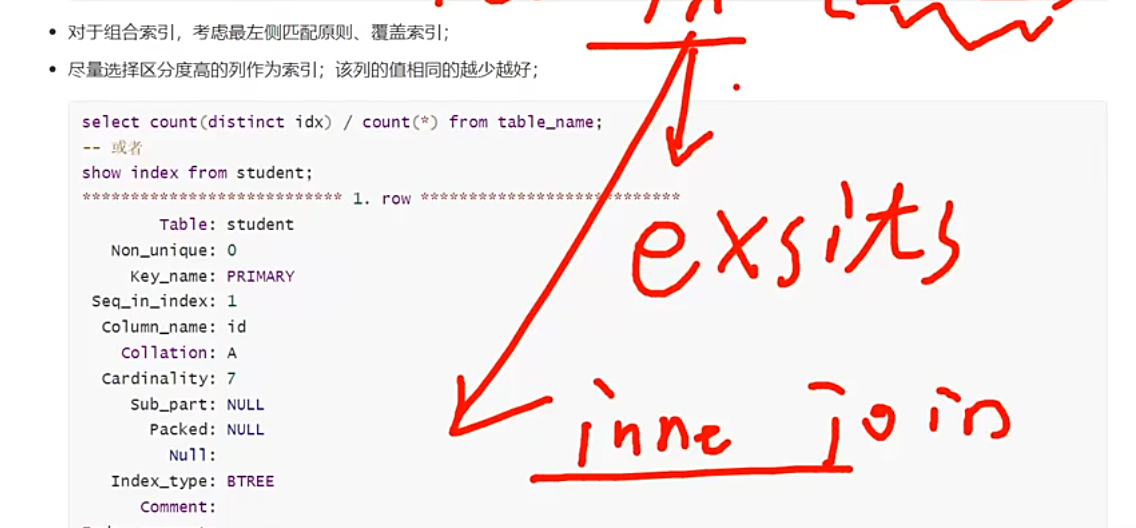
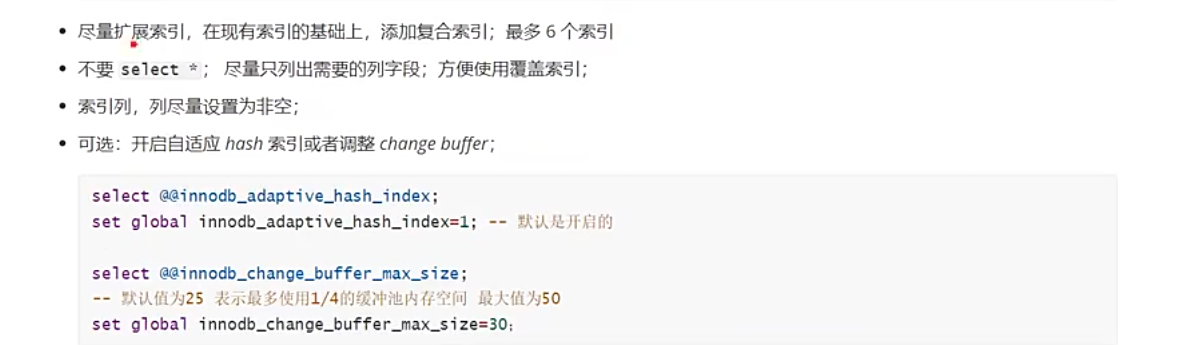
创建索引最好不超过6个。
为了缩减索引个数,采用合并的策略,将其合并为组合索引,常用的放左边,不常用的放右边
组合索引(Composite Index)
组合索引是指基于表中多个字段共同创建的索引,而非单一字段。它将多个字段的值按顺序组合成索引的 “键”,存放在 B + 树中,用于优化多字段联合查询的效率。
例如,对表user的age和name字段创建组合索引:
CREATE INDEX idx_age_name ON user(age, name);这棵 B + 树的索引键是(age, name)的组合,排序时先按age升序,age相同再按name升序。
可以把组合索引近似于看作是一个结构体或对象。
完全匹配左侧字段 → 索引生效
-- 条件包含age(最左字段),索引生效
SELECT * FROM user WHERE age = 18;
-- 条件包含age + name(按顺序匹配),索引生效
SELECT * FROM user WHERE age = 18 AND name = '张三';匹配部分左侧字段 → 索引部分生效
-- 条件包含age(左1)和部分name(左2),索引生效(仅用age+name前缀)
SELECT * FROM user WHERE age = 18 AND name LIKE '张%';跳过左侧字段 → 索引失效
-- 跳过age(最左字段),直接查name,索引完全失效
SELECT * FROM user WHERE name = '张三';-- 条件是name + age(顺序颠倒),仅age部分可能生效(数据库可能优化顺序),但name部分不生效
SELECT * FROM user WHERE name = '张三' AND age = 18;
-- 等效于 WHERE age = 18 AND name = '张三'(数据库会调整顺序),此时索引生效
-- 注意:这是数据库的查询优化,而非索引本身支持乱序匹配为什么需要最左匹配原则?
组合索引的 B + 树是按字段顺序逐层排序的(先排第一个字段,再排第二个,以此类推),类似字典的排序规则(先按首字母,再按第二个字母)。例如(age, name)的索引顺序是:
(18, '李四') → (18, '张三') → (20, '王五') → ...这种结构决定了只有从左侧第一个字段开始查询,才能利用索引的有序性快速定位。如果跳过第一个字段(如直接查name),就像在字典中跳过首字母查第二个字母,无法利用索引的排序规则,只能全表扫描。
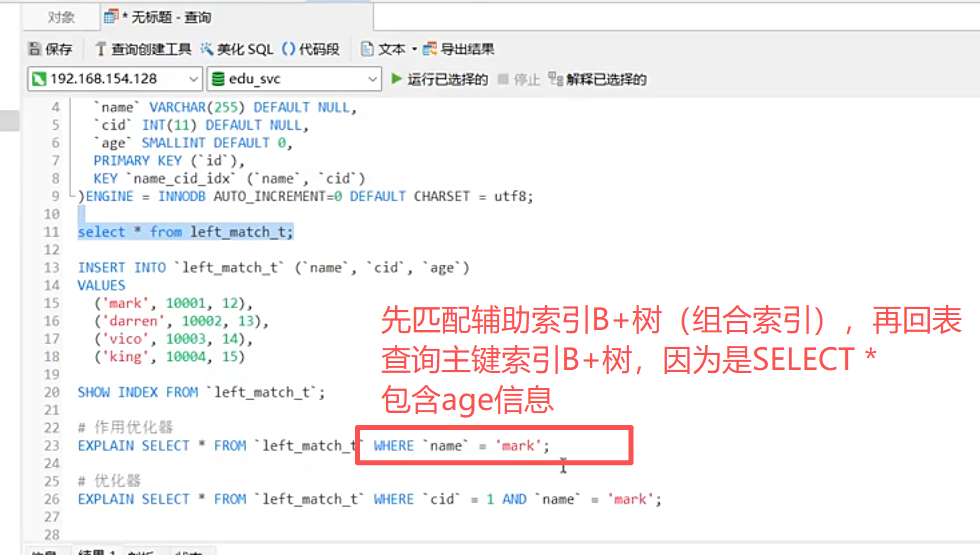
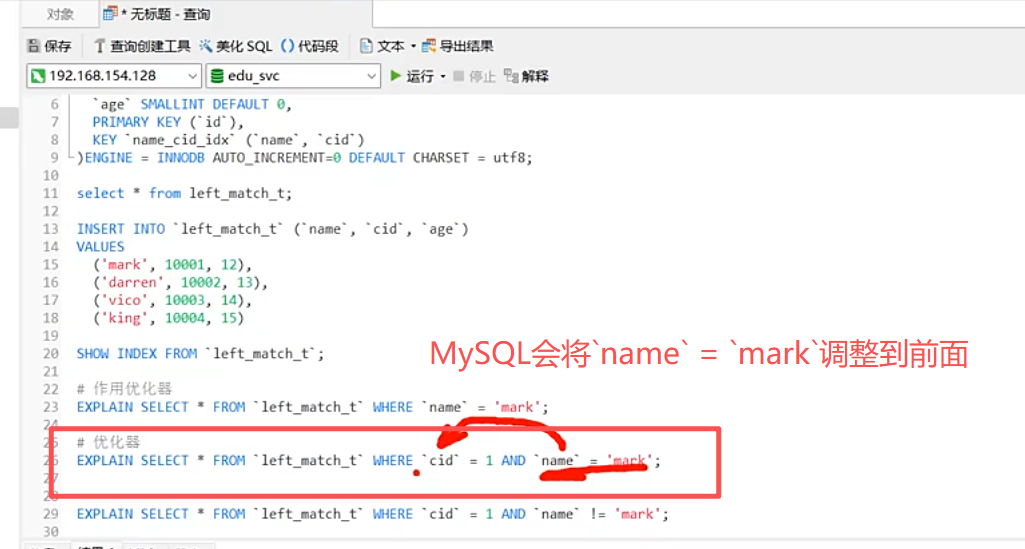
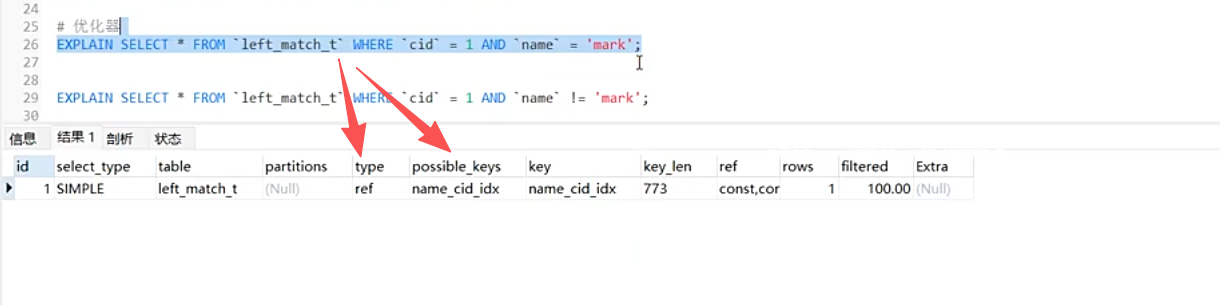
EXPLAIN作用优化器(制定执行计划)

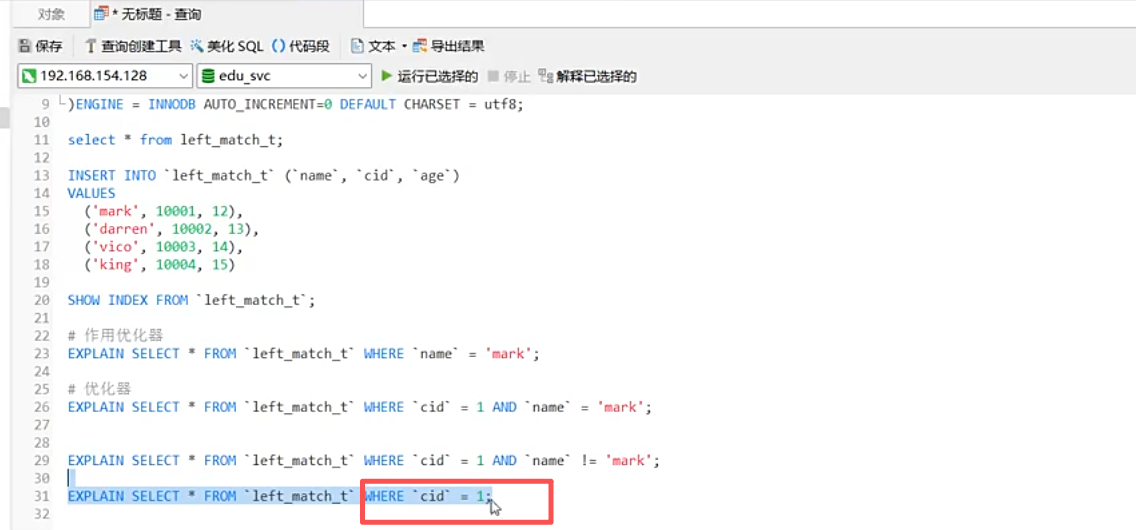
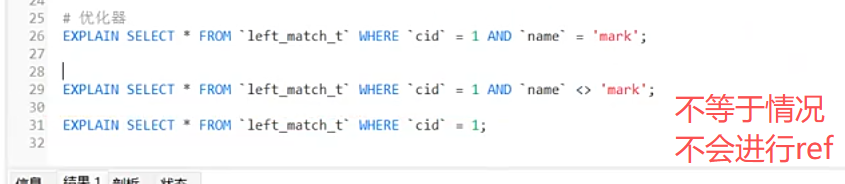
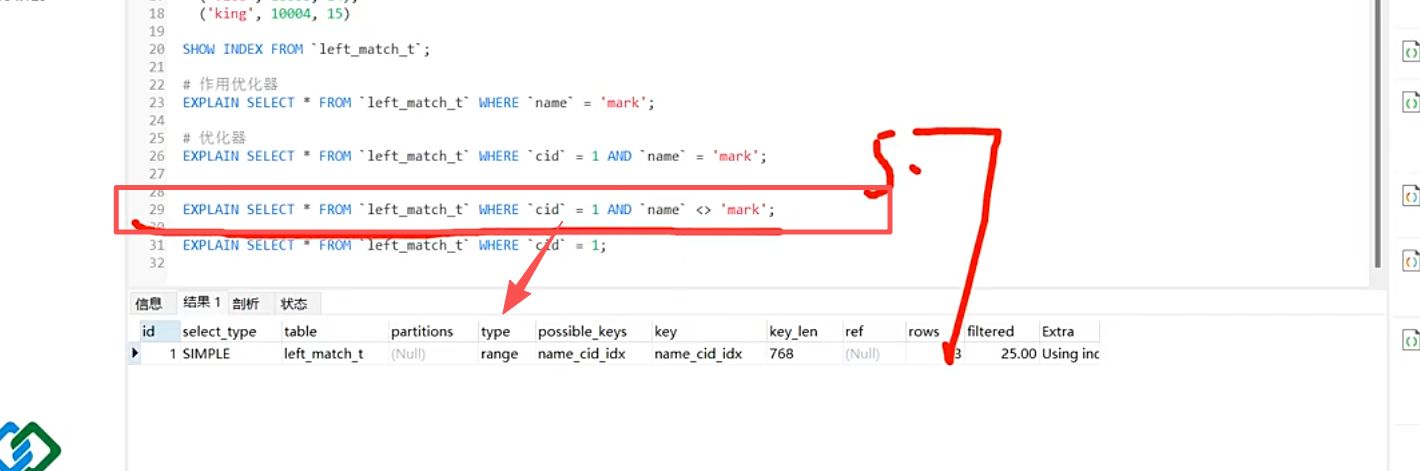
仅cid = 1,且并没有采用主键,采用的是全表扫描。


覆盖索引

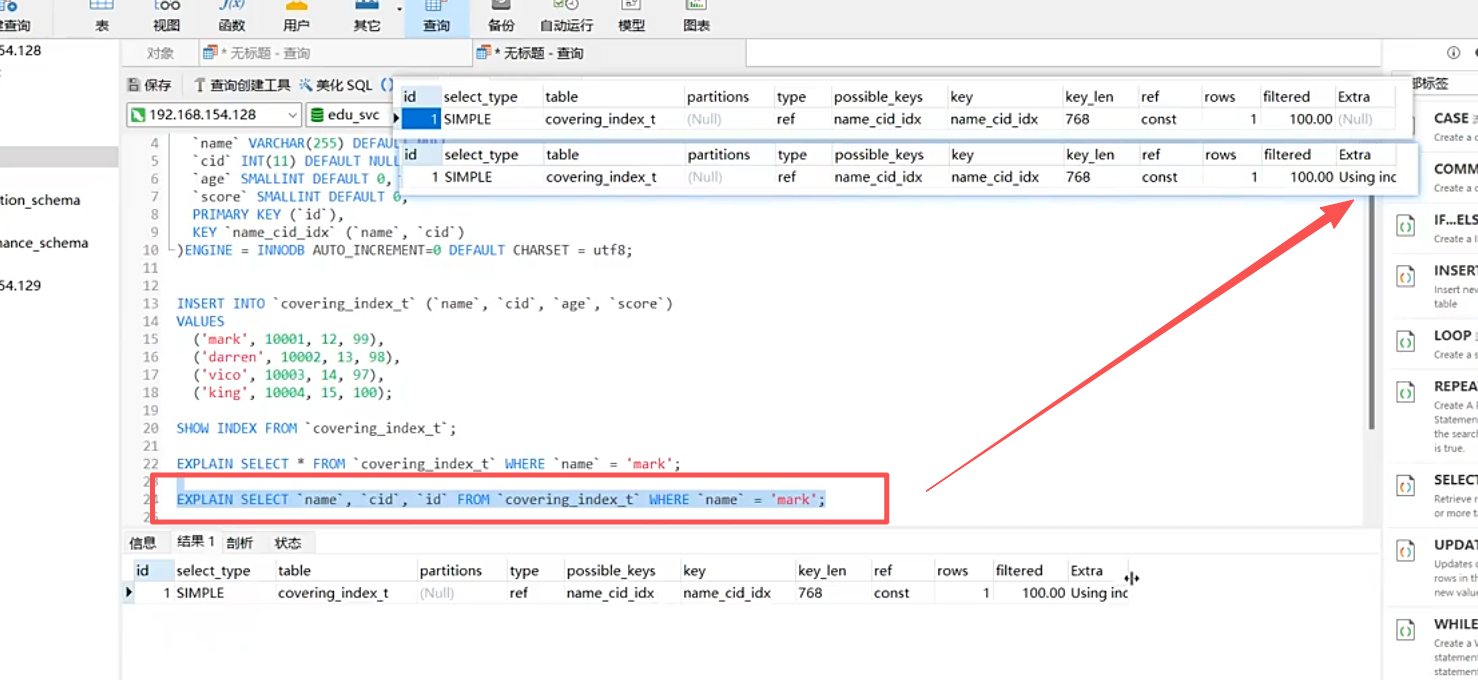
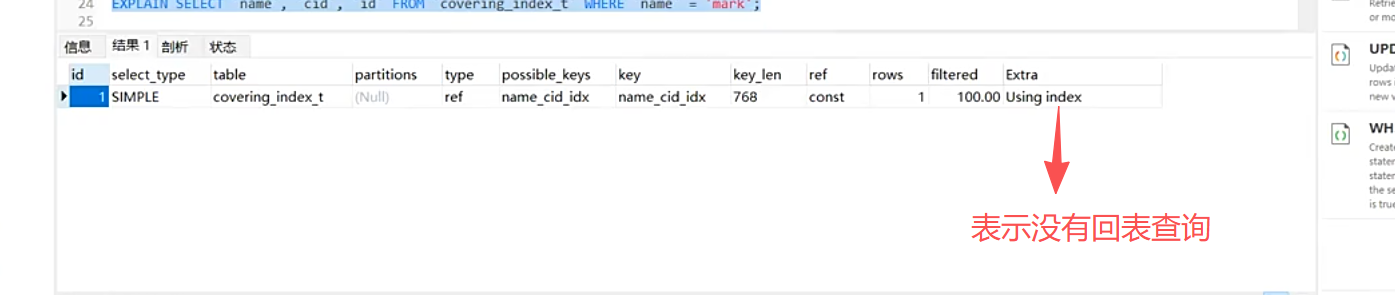
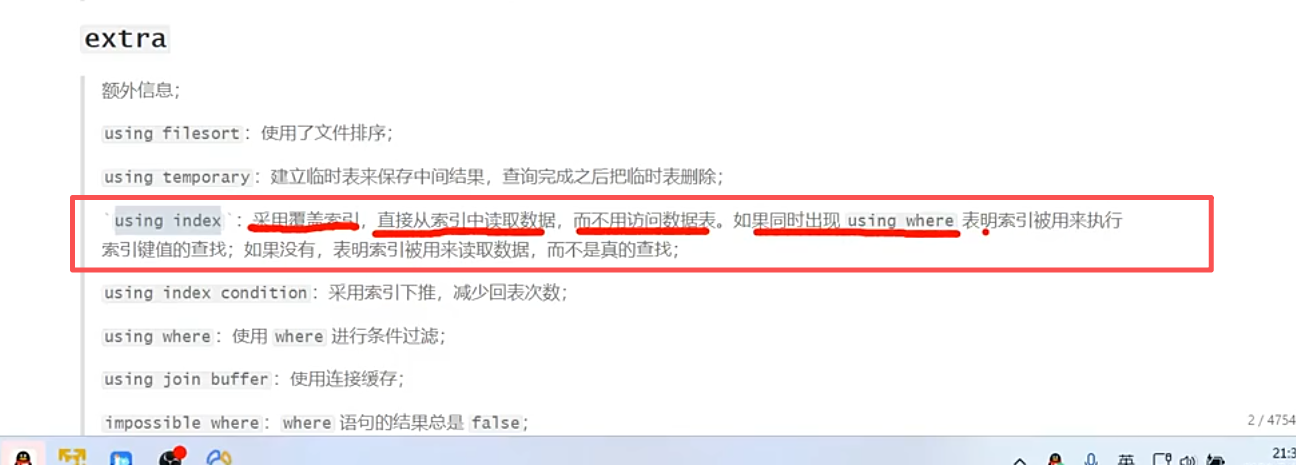
尽量列出所需要的字段,避免select * 从而避免全表扫描。
索引下推using index condition


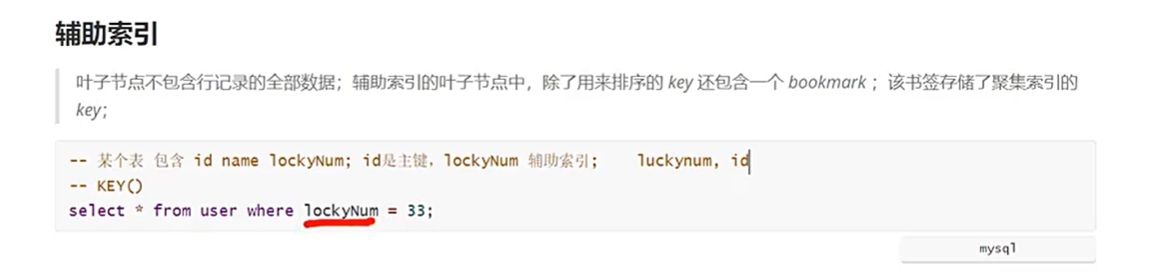
它能减少回表次数的核心原因是:在辅助索引(普通索引、联合索引等非聚簇索引)的查询中,存储引擎可以利用索引中已有的字段,提前过滤掉不符合条件的记录,避免这些记录被回表查询。
辅助索引(包括普通索引、联合索引)的 B + 树叶子节点只存储 “索引键 + 主键”(不存储完整行数据)。当查询需要获取索引键之外的字段时,必须通过主键到聚簇索引中查询完整数据,这个过程称为 “回表”。
回表的本质是 “二次查询”(先查辅助索引,再查聚簇索引),会产生额外的磁盘 I/O,是辅助索引查询的主要性能开销。回表次数越多,性能越差。
索引下推如何减少回表次数?
通过对比 “无 ICP” 和 “有 ICP” 的处理流程,能清晰看到差异:
场景举例:
表user有辅助索引idx_age_name(age, name)(联合索引),聚簇索引为id(主键),查询:
SELECT * FROM user WHERE age > 18 AND name LIKE '张%';(需要查询完整行数据,必须回表;过滤条件涉及索引键age和name)
1. 无 ICP 时的流程(MySQL 5.6 之前):
- 存储引擎层:仅利用
age > 18过滤辅助索引,找到所有符合条件的索引记录(包含age、name、id),但不检查name LIKE '张%',直接将这些记录的id返回给服务器层。 - 服务器层:接收
id后,逐一对每个id执行回表(查聚簇索引获取完整行数据),然后在服务器层用name LIKE '张%'过滤,最终返回符合条件的结果。
问题:即使某些记录的name不满足'张%',也会被回表(因为存储引擎没过滤),导致无效回表。
2. 有 ICP 时的流程(MySQL 5.6 及之后):
- 存储引擎层:利用辅助索引中的
age和name字段,同时检查age > 18和name LIKE '张%',直接过滤掉不符合name条件的记录,只将符合条件的记录的id返回给服务器层。 - 服务器层:仅对这些经过过滤的
id执行回表,获取完整数据后直接返回。
优化点:存储引擎利用索引中已有的name字段提前过滤,减少了需要回表的id数量,从而减少回表次数(本质是 “在回表前就扔掉无效数据”)。
索引失效
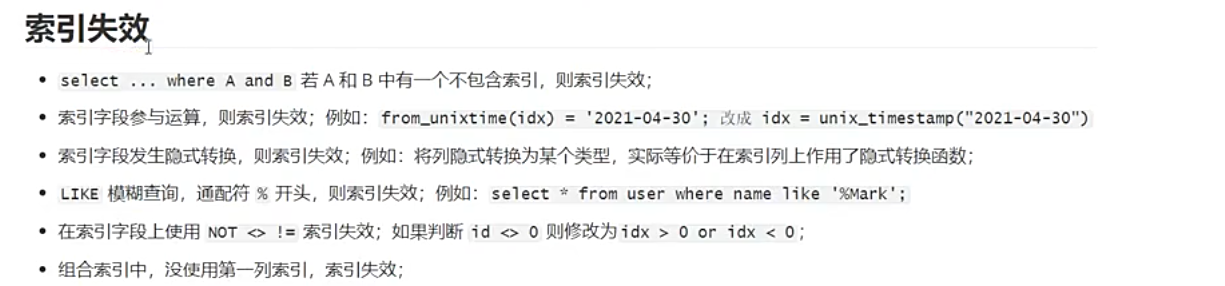
索引失效是指:表中虽然创建了索引,但查询执行时,数据库优化器判断使用索引的效率低于全表扫描(或全索引扫描),从而放弃使用索引,转而采用更慢的全表扫描方式。简单说,就是 “索引建了,但没被用上”。
索引失效的核心原因
索引的底层是有序的 B + 树结构,数据库使用索引的前提是 “能利用索引的有序性快速定位数据”。若查询条件破坏了这种有序性,或索引的过滤效果极差(如返回表中 90% 的数据),优化器会认为 “用索引不如直接扫全表快”,从而导致索引失效。
常见的索引失效场景(附例子)
假设表user有字段id(主键)、age(普通索引)、name(普通索引)、phone,并创建了联合索引idx_age_name(age, name)。
1. 对索引字段使用函数或表达式操作
索引的有序性是基于 “字段原始值” 的,若用函数 / 表达式修改字段值,会破坏索引的有序性,导致无法快速定位。
-- 对age索引字段使用函数,索引失效
SELECT * FROM user WHERE YEAR(birthday) = 1990; -- birthday有索引,但用了YEAR()函数
-- 对索引字段用表达式,索引失效
SELECT * FROM user WHERE age + 1 = 20; -- age有索引,但被表达式修改2. 模糊查询以%开头
LIKE '%xxx'会导致索引无法利用前缀有序性(索引是按字段值从左到右排序的,%在开头意味着无法匹配前缀)。
-- name有索引,但以%开头,索引失效
SELECT * FROM user WHERE name LIKE '%张三';
-- 注意:`LIKE '张三%'`(%在结尾)可以利用索引的前缀有序性,索引有效3. 索引字段使用不等于(!=/<>)、NOT IN、NOT EXISTS
这类操作会导致优化器认为 “过滤后的结果集很大”,使用索引的成本高于全表扫描(尤其当不符合条件的数据占比低时)。
-- age有索引,但用!=,索引可能失效
SELECT * FROM user WHERE age != 18;
-- NOT IN导致索引失效
SELECT * FROM user WHERE age NOT IN (18, 20);4. OR连接的条件中,存在未建索引的字段
OR要求两边的条件都能利用索引,否则整个查询无法使用索引(因为只要一边需要全表扫描,另一边用索引就失去意义)。
-- age有索引,但phone无索引,OR导致age索引失效
SELECT * FROM user WHERE age = 18 OR phone = '13800138000';5. 联合索引不满足最左匹配原则
联合索引(如(a, b, c))的有序性是 “先按 a 排,a 相同再按 b 排,以此类推”。若跳过左侧字段,或不按顺序查询,索引会部分 / 完全失效。
-- 联合索引idx_age_name(age, name)
SELECT * FROM user WHERE name = '张三'; -- 跳过age(最左字段),索引完全失效
SELECT * FROM user WHERE age > 18 AND name = '张三'; -- 部分有效(仅age部分被利用)6. 隐式类型转换
索引字段的类型与查询条件的类型不匹配时,MySQL 会自动进行类型转换(相当于对索引字段使用了函数),导致索引失效。
-- name是varchar类型(有索引),查询用数字,触发隐式转换(相当于CAST(name AS UNSIGNED))
SELECT * FROM user WHERE name = 123; -- 索引失效,应写成name = '123'
如何判断索引是否失效?
通过EXPLAIN命令查看执行计划,若type列显示为ALL(全表扫描),且key列显示为NULL(未使用任何索引),则说明索引失效。
EXPLAIN SELECT * FROM user WHERE name LIKE '%张三'; -- 查看该查询是否使用索引索引原则
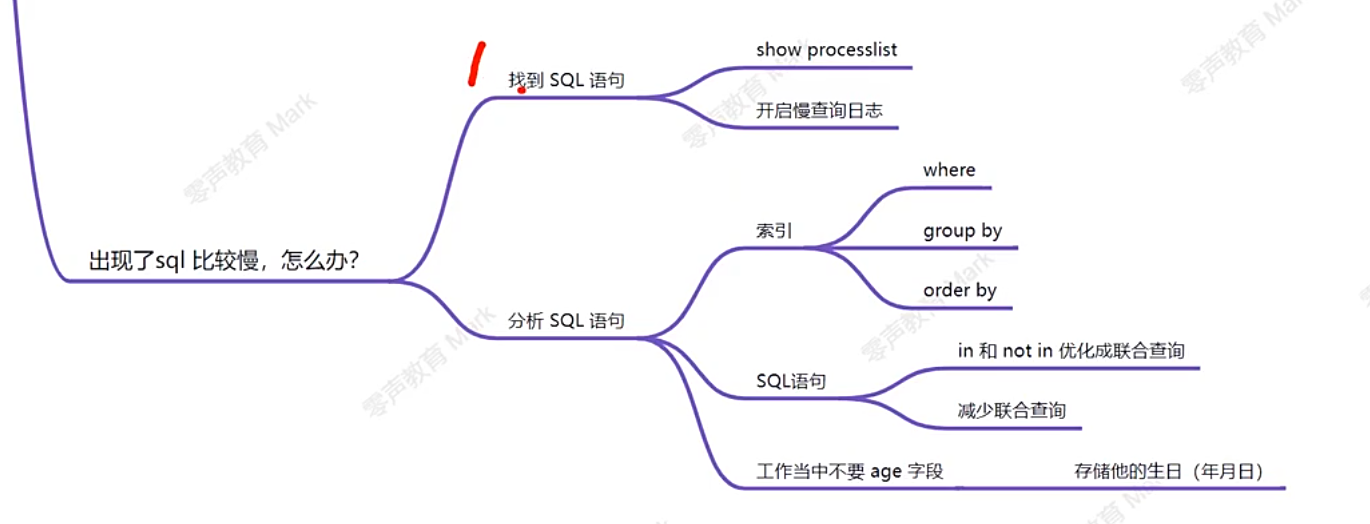
出现sql比较慢怎么办?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)