智能影音合成系统:基于通义万相Wan2.2-S2V的探索与实践
阿里巴巴升级通义万相模型至Wan2.2-S2V版本,实现基于静态图片和音频的电影级数字人视频生成。作者结合Fay数字人框架,搭建了集成文本转语音、语音克隆和视频合成的智能影音系统:1)采用ChatTTS-ui进行音频合成,支持语音克隆功能;2)通过阿里云接口实现视频生成,耗时比约为1:12。系统目前存在动作控制局限,未来计划通过ComfyUI接口优化生成效果,并遵循AI内容标识规范。
近日,阿里巴巴对其开源视频生成模型通义万相进行了重要升级,正式发布Wan2.2-S2V版本。该模型仅需一张静态图片和一段音频,即可生成口型精准、表情自然的电影级数字人视频,显著提升了视频的真实感与生成质量。
考虑到音频制作对普通用户来说仍有一定门槛,笔者基于之前研究的 Fay 数字人技术框架,并结合 Wan2.2-S2V 的能力,搭建了一个集文本转语音(TTS)、语音克隆与视频合成于一体的智能影音系统。以下是该系统的详细介绍:
1. 音频合成部分
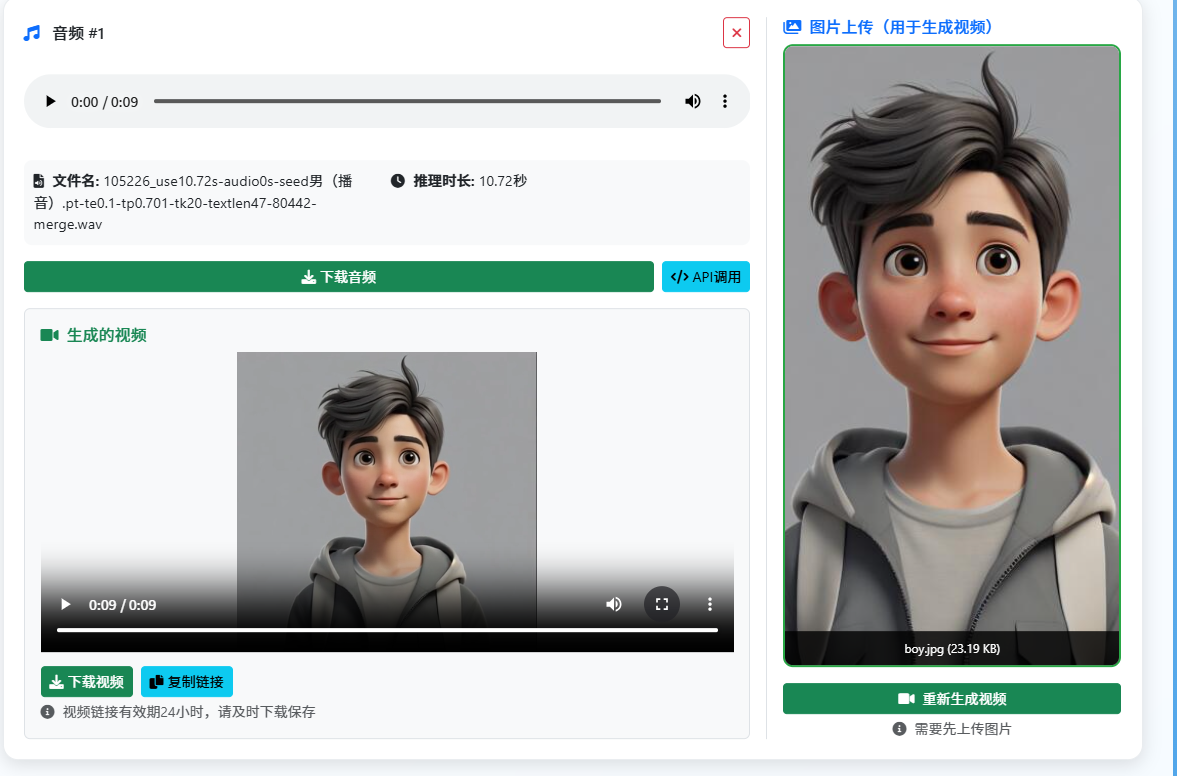
在对比多个开源 TTS 项目后,笔者选择了 jianchang512/ChatTTS-ui 作为系统的核心。用户只需输入文本或上传 TXT 文档,点击“声音合成”按钮,即可快速生成 Wan2.2-S2V 所需的音频输入。
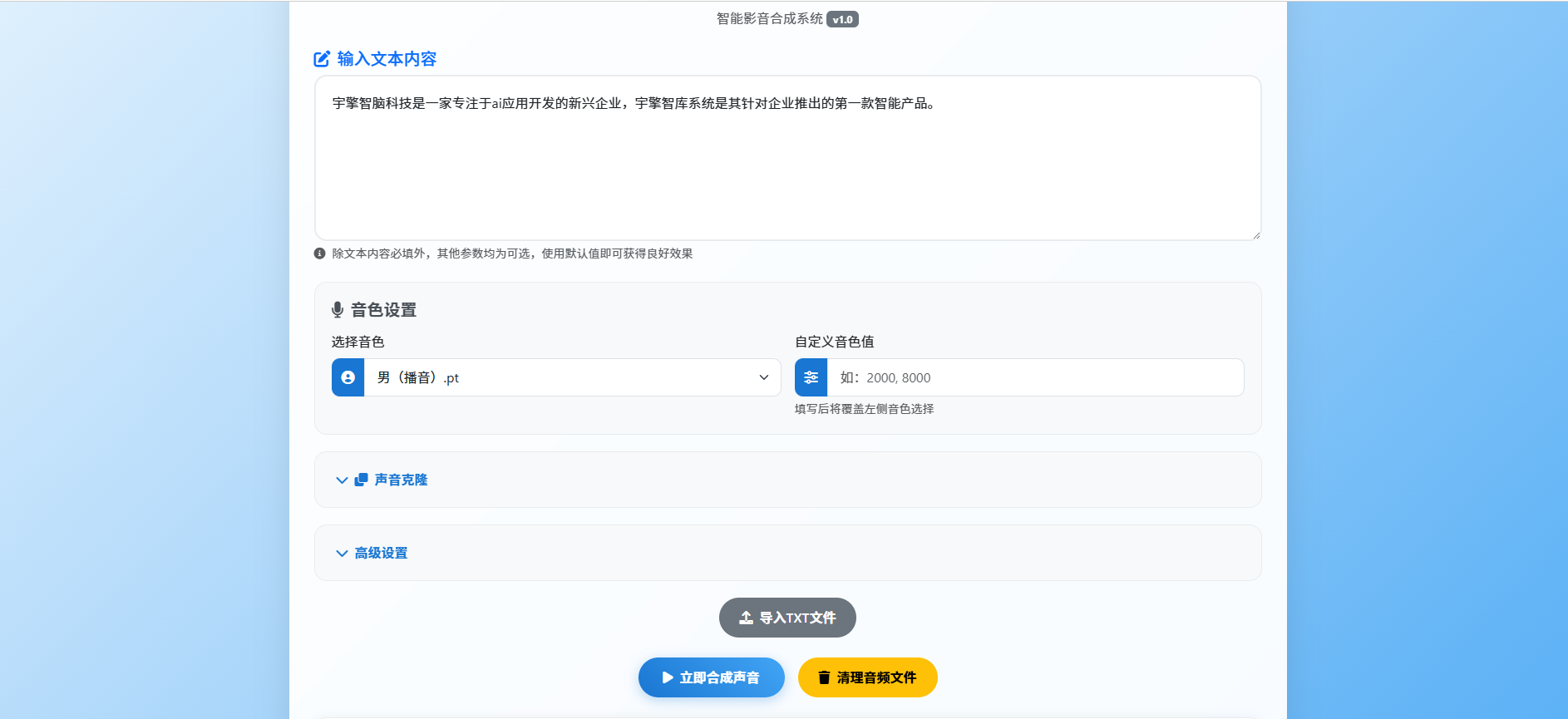
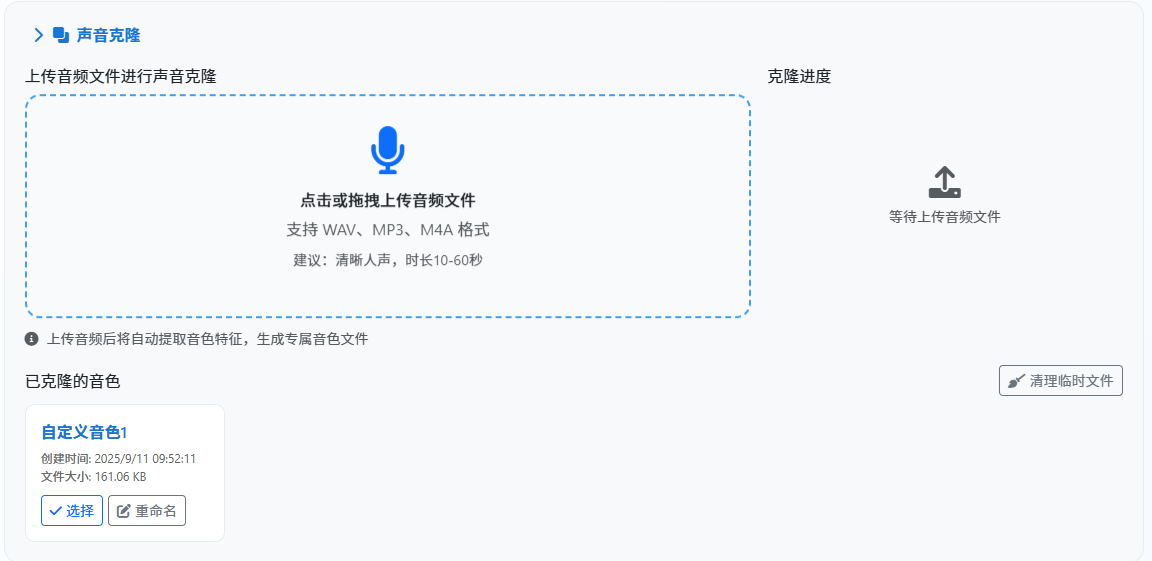
为了满足高级用户的个性化需求,系统在高级设置中保留了原始 ChatTTS 的自定义参数。同时,笔者还集成了 OpenVoice 项目,实现了强大的语音克隆功能。用户只需上传一段 10 秒以上的音频文件,系统便能自动提取并复用该音色,极大地扩展了音色的可玩性。
2. 视频生成部分
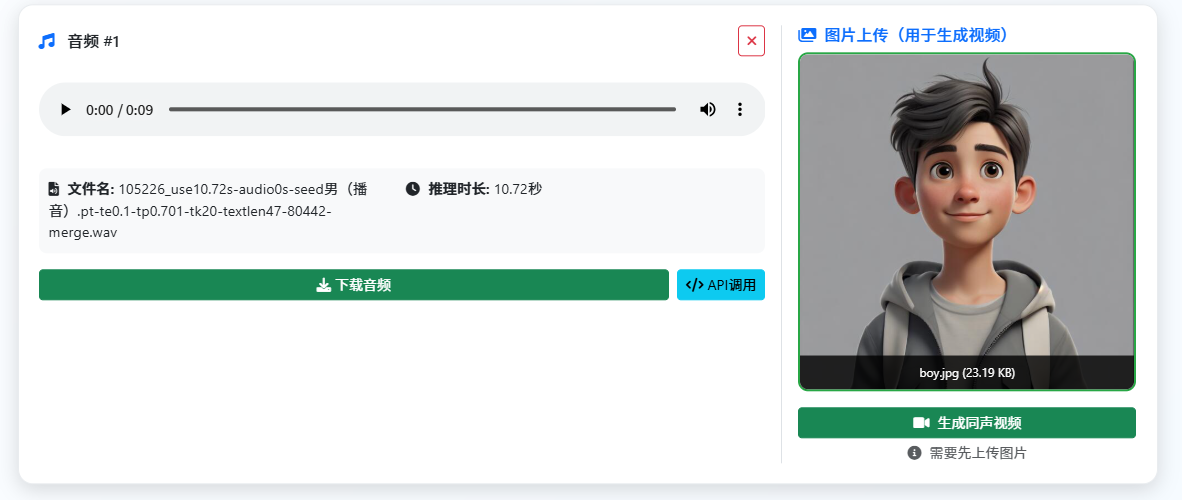
音频制作完成后,用户可以自行上传一张静态图片作为 Wan2.2-S2V 的另一项输入。点击生成同声视频后,系统将通过阿里云接口启动合成任务。根据笔者的测试,视频生成时长与视频长度大致呈 1:12 的关系,这意味着生成一个 10 秒的视频大约需要 2 分钟。
Wan2.2-S2V 任务生成接口请求示例:
curl 'https://dashscope.aliyuncs.com/api/v1/services/aigc/image2video/video-synthesis/' \
--header 'X-DashScope-Async: enable' \
--header "Authorization: Bearer $DASHSCOPE_API_KEY" \
--header 'Content-Type: application/json' \
--data '{
"model": "wan2.2-s2v",
"input": {
"image_url": "https://img.alicdn.com/imgextra/i3/O1CN011FObkp1T7Ttowoq4F_!!6000000002335-0-tps-1440-1797.jpg",
"audio_url": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20250825/iaqpio/input_audio.MP3"
},
"parameters": {
"resolution": "480P"
}
}'
注:image_url 和 audio_url 均需使用公网 IP,可通过自行部署 OSS 服务来解决。
未来展望
目前,通过 API 接口生成的视频无法像在 ComfyUI 中那样利用 ControlNet 等工具精确控制人物动作。未来的优化方向可以考虑通过 API 方式调用 ComfyUI,以实现更自由、更具创意的视频生成效果。
您可以参考这篇文章了解如何通过 API 调用 ComfyUI 的原生接口: https://blog.yuqingteck.com/archives/apifang-shi-diao-yong-comfyuiyuan-sheng-jie-kou。
依据国家网信办《人工智能生成合成内容标识办法》的要求,AI生成内容需要进行打标,您可以来参考这篇文章了解如何给音视频文件打标:https://blog.yuqingteck.com/archives/9yue-1ri-qi-aisheng-cheng-he-cheng-nei-rong-bi-xu-tian-jia-biao-shi。
文中最终视频生成效果见资源绑定。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)