MoE:如何用一万亿参数的模型跑出十亿参数的成本?
混合专家模型(MoE)通过稀疏激活机制突破了大模型计算瓶颈。该架构由多个专业子网络(专家)和智能路由系统(门控网络)组成,仅针对每个输入激活最相关的少量专家,使得万亿参数模型能以十亿级模型的计算量运行。门控网络通过TopK选择机制和持续学习优化专家分配策略,实现计算资源的动态高效利用。这种"专业分工+按需调用"的模式,为超大语言模型的实用化提供了创新解决方案,在保持模型容量的同
在过去几年,大模型竞赛的核心是参数规模的爆炸式增长。然而,每增加一个参数,训练和推理的计算成本都会随之增加,最终到达物理极限。当模型规模迈向万亿级别时,一种名为混合专家模型(Mixture of Experts, MoE)的架构,成为了解决这一难题的关键。
本文将深入浅出地解释 MoE 的核心思想、数学原理,以及它如何让一个万亿参数的模型,以十亿参数模型的计算量运行。
一、什么是混合专家模型?
传统的神经网络是“稠密”的,意味着每一个输入都会激活模型中的所有参数。这就像为了解决一个问题,你必须召集公司所有员工开会,无论他们是否相关。
MoE 则截然不同,它是一个“稀疏”的网络。MoE 架构由两部分组成:
-
专家网络(Expert Networks): 多个独立的、并行的前馈神经网络(FFN),每个专家都擅长处理特定类型的数据。比如,一个专家专门处理数学问题,另一个专门处理诗歌创作。
-
门控网络(Gating Network): 一个轻量级的“路由器”,它会根据输入内容,决定将该输入分配给哪个或哪几个专家来处理。
MoE 的核心优势在于,它允许模型的总参数量达到惊人的规模(如 Mixtral-8x7B),但对于任何一个输入,只激活其中一小部分参数,从而极大地节省了计算成本。这就像公司成立了多个专业小组,当有新任务时,只由最相关的小组来负责,而其他小组则保持待命。
二、核心:门控网络与稀疏激活
MoE 的核心在于其门控网络和激活专家的机制。这个过程可以用一个公式来完美概括:
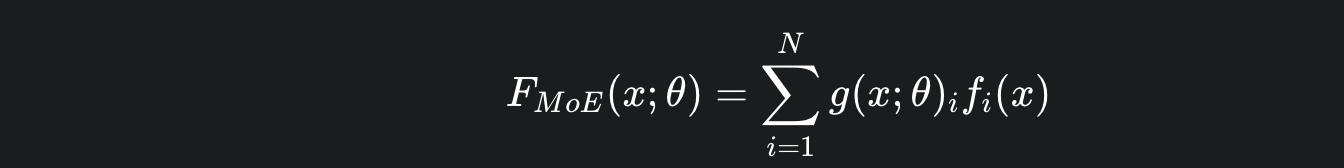
-
x:模型的输入。例如,一个问题:“如何使用 Python 编写一个排序算法?”
-
fi(x):第 i 个专家的输出。比如,数学专家会给出算法复杂度的结果,而代码专家则会给出具体的代码实现。
-
g(x;θ)i:门控网络为第 i 个专家分配的权重。这个权重决定了该专家对最终答案的贡献大小。
这个公式的核心是 “稀疏”,而稀疏是通过一个关键的 TopK 函数实现的。
TopK:只选最优
门控网络 s(x;θ) 会为所有专家计算一个原始得分。然后,一个 TopK 函数会从中选出得分最高的 K 个专家,将它们的得分保留,而将其他专家的得分设置为负无穷。
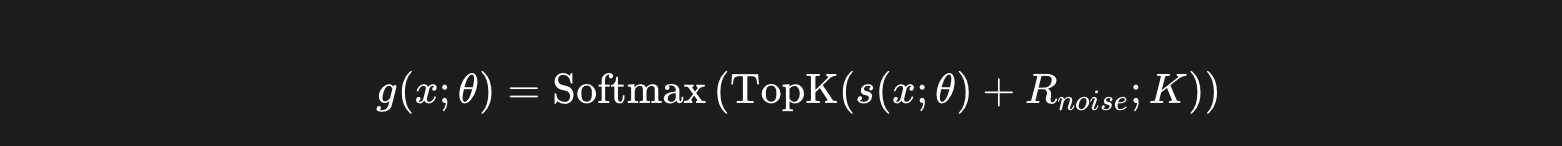
-
s(x;θ):门控网络计算的原始得分。
-
TopK(⋅;K):这个函数将所有专家的得分进行排序,只保留前 K 个。
-
Softmax:应用于筛选后的得分,确保只有这 K 个专家获得非零权重。
简单示例
假设一个 MoE 模型有 8 个专家,并设置 K=2。当输入“如何使用 Python 编写一个排序算法?”时:
-
门控网络为所有 8 个专家打分,例如:
[1.5, 3.2, 0.8, 4.1, 2.0, 0.5, 3.5, 1.1]。 -
TopK函数选出最高的 2 个得分:4.1 (来自第 4 个专家,可能是“代码实现专家”)和 3.5 (来自第 7 个专家,可能是“算法专家”)。 -
Softmax 函数将这两个得分转化为权重,比如 0.85 和 0.15。
-
最终,模型的输出将是:
0.85 × (代码实现专家的输出) + 0.15 × (算法专家的输出)。其他 6 个专家则完全不参与计算。
三、门控网络:一个学习的“侦察兵”
为什么门控网络能准确地为专家打分?
门控网络本身是一个小的神经网络,它的参数是可学习的。整个 MoE 模型通过反向传播进行训练。如果在某个输入上,门控网络选择了错误的专家,导致模型预测失败,那么反向传播会告诉门控网络:“你这次的决策是错误的,下次遇到这种输入时,你应该选择另一个专家。”
经过成千上万次这样的训练,门控网络学会了如何像一个“人才侦察兵”一样,根据输入的细微特征,高效地将任务分配给最擅长的专家。
四、总结
MoE 架构是扩展语言模型参数规模的一次革命性尝试。它允许模型拥有海量的参数,从而存储更丰富的知识,但又通过稀疏激活的方式,确保了高效的计算。这使得我们可以在有限的计算资源下,训练和部署前所未有的超大模型,为未来的 AI 应用开启了新的可能性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)