使用mslite+faiss在香橙派昇腾开发板上实现搜图功能
本文介绍了基于MindSpore Lite和CLIP模型的轻量级图像搜索系统实现方案。系统使用CLIP模型提取图像和文本特征,通过Faiss构建向量索引库,支持文本搜图和图像搜图功能。作者详细说明了在香橙派AI开发板上的部署过程,包括环境配置、模型转换、索引创建和搜索实现。测试使用ImageNet验证集,展示了搜索效果和性能数据,在8T、20T和AI Studio Pro等不同硬件配置下均能实现毫
代码和模型文件仓库链接:
https://xihe.mindspore.cn/models/zhouyifengCode/image_search_lite/tree
搜索测试用的数据集地址(imagenet1k的5万个验证集):
https://xihe.mindspore.cn/datasets/zhouyifengCode/image_search_data/tree
本案例中为了方便测试效果,直接使用了imagenet1k的5万个验证集图片,imagenet的图片都根据类别放在了不同的目录中,方便观察
参考思路:https://andy9999678.me/blog/?p=239
一:环境介绍
软件:mindspore 2.5.0, mslite 2.5.0,mindnlp 0.4.1, cann 8.0,faiss-cpu
硬件:香橙派 ai studio pro(310P), ai pro 20t和8t(310b1和b4)
使用的模型和实现:
clip模型,
mindnlp 0.4.1中clip模型实现:https://github.com/mindspore-lab/mindnlp/blob/0.4/mindnlp/transformers/models/clip/modeling_clip.py
原clip模型的权重仓库地址:
https://huggingface.co/openai/clip-vit-base-patch32
二:准备工作介绍
硬件环境以及模型推理引擎介绍:
开发板镜像和cann:
我这边ai pro20t使用的镜像:opiaipro_20t_ubuntu22.04_desktop_aarch64_20250211.img.xz,该镜像中已经安装cann 8.0
ai pro 8t使用的镜像:opiaipro_ubuntu22.04_desktop_aarch64_20241128.img.xz,内置cann 7.0,需要自己手动安装cann8.0
ai studio pro需要自己用U盘装系统的方式自己刷ubuntu镜像,然后根据香橙派手册安装cann 8.0
cann 8.0安装页面:
https://www.hiascend.com/developer/download/community/result?module=cann&cann=8.0.0.beta1
注意:需要安装的是cann-tooklit和kernels二进制包,kernels二进制包需要根据自己的芯片型号(310p还是310b)进行选择
mindnlp 0.4.1中的clip模型可以直接推理(即直接使用mindspore进行推理),但为了尽可能的提升推理性能和降低内存占用,这里将mindnlp的模型进行导出和lite convert(编译优化)转换操作,使用mslite(mindspore lite)进行推理,导出和转换的操作可以参考文档:
https://www.mindspore.cn/docs/zh-CN/r2.7.0/api_python/mindspore/mindspore.export.html?highlight=export#mindspore.export
https://www.mindspore.cn/lite/docs/zh-CN/r2.7.0/mindir/converter_tool_ascend.html
三:模型代码和数据集准备:
1.先将image_search_lite仓库拉去下来,里面有代码和模型文件,以及事先创建好的fasiss向量索引文件
2.将image_search_data仓库下的imagenet_val.zip下载存放在同级目录,然后unzip imagenet_val.zip解压
放大

四:mindspore相关和faiss依赖包安装:
1。安装mindspore 2.5.0:
pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.5.0/MindSpore/unified/aarch64/mindspore-2.5.0-cp39-cp39-linux_aarch64.whl -i https://repo.huaweicloud.com/repository/pypi/simple
2.安装mslite 2.5.0 python包:
pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/2.5.0/MindSpore/lite/release/linux/aarch64/cloud_fusion/python39/mindspore_lite-2.5.0-cp39-cp39-linux_aarch64.whl -i https://repo.huaweicloud.com/repository/pypi/simple
3.安装mindnlp 0.4.1:
pip install mindnlp==0.4.1 -i https://repo.huaweicloud.com/repository/pypi/simple
4.安装faiss包:
pip install faiss-cpu -i https://repo.huaweicloud.com/repository/pypi/simple
注意点:
在安装faiss-cpu后,可能把numpy也升级到了2.0以上版本,ai pro上测试下来会出错,重新安装numpy 1.26.4版本即可
pip install numpy==1.26.4 -i https://repo.huaweicloud.com/repository/pypi/simple
这边用到了faiss库,这是fackbook的一个向量数据引擎,用于存放特征向量和向量匹配搜索
五:运行代码:
首先cd image_search_lite,进入到代码目录下,有以下文件:
放大
4个mindir文件分别是通过mindnlp导出和lite转换得到的310p(ai studio)和310b(ai pro)上提取图片特征和文本特征的mslite模型文件
faiss_datavec 是我事先创建好的imagenet val图片的向量索引
clip-vit-base-patch32 目录是原clip模型目录,本案例中主要用来通过mindnlp套件加载里面的token等相关文件进行数据预处理操作
1.创建索引库:
python create_image_index.py --lite_mindir_path clip_get_image_feature_lite_310b.mindir --clip_path ./clip-vit-base-patch32/ --imagenet_path ../imagenet_val --output_path faiss_datavec/
在体验本案例时,这一步也可以不执行,直接使用我仓库里已经创建好的faiss_datavec目录
创建向量索引库时需要先获取图片特征,所以lite_mindir_path参数指定clip_get_image_feature_lite的模型文件
注意:
在创建向量索引库时和执行下面搜索代码时,相对于imanget_val图片目录的位置必须相同;faiss_datavec目录中有两个文件,img_vec.faiss是向量索引文件,还有一个img_info.json文件,因为faiss保存的是特征向量和对应的索引id,需要额外的文件来维护这个索引id和具体图片路径的对应关系
2.执行文本搜索图片:
python search_image_by_text.py --faiss_index_path ./faiss_datavec/ --lite_mindir_path clip_get_text_feature_lite_310b.mindir --clip_path ./clip-vit-base-patch32/ --search_text "apple"
文搜图功能需要获取文本特征向量,所以lite_mindir_path参数指定clip_get_text_feature_lite的模型文件
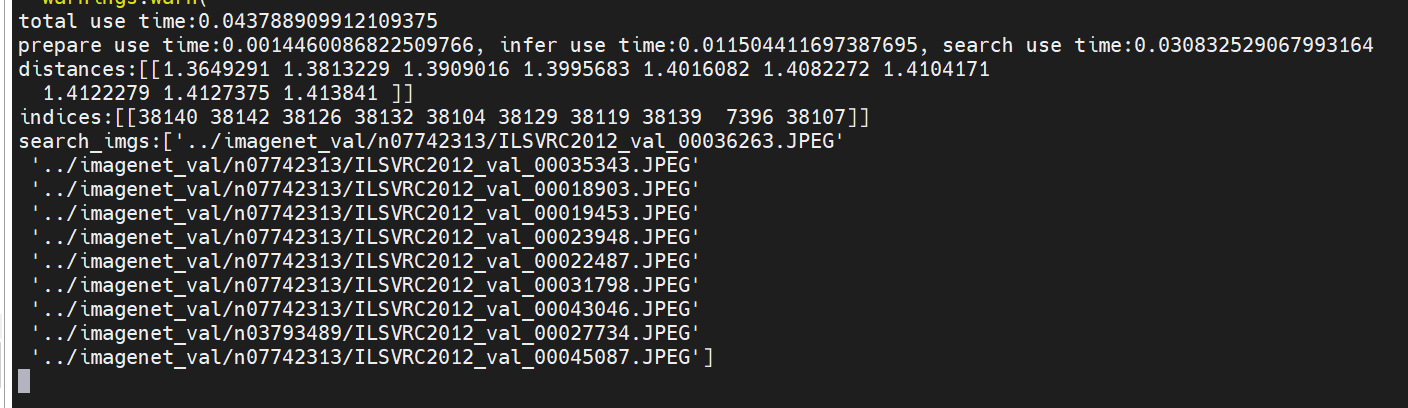
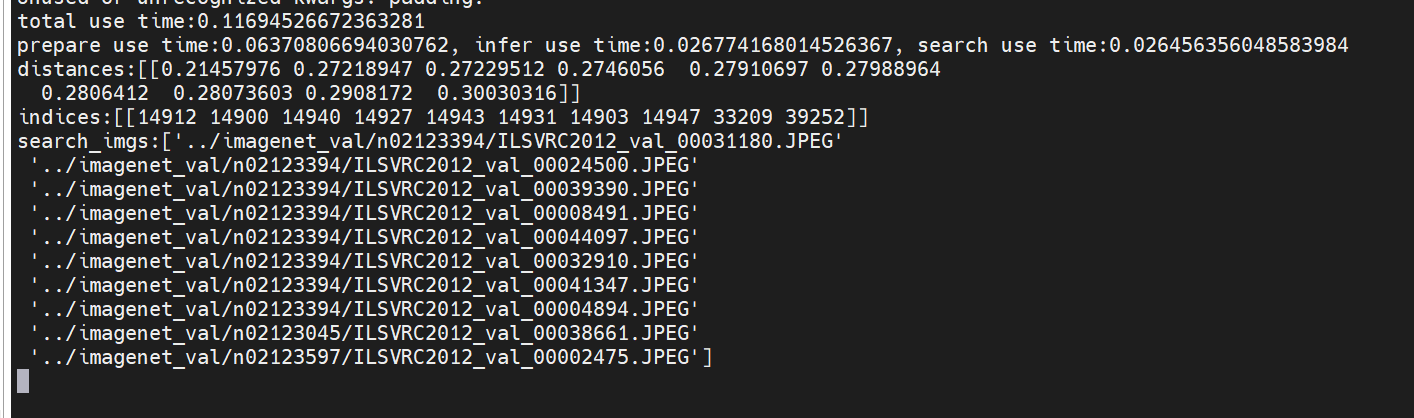
3.执行图片搜索图片:
python search_image_by_image.py --faiss_index_path ./faiss_datavec/ --lite_mindir_path clip_get_image_feature_lite_310b.mindir --clip_path ./clip-vit-base-patch32/ --search_img_path cat.jpg
图搜图功能需要获取图片特征向量,所以lite_mindir_path参数指定clip_get_image_feature_lite的模型文件
六:结果展示:
搜索代码中最后列出了搜索出来的最接近搜索要求的10张图片的路径,以及做了可视化弹窗,下面演示的都是在ai pro 8t板子上的截图;
上述文搜图“apple”的结果:
放大
放大

这边居然搜出了苹果鼠标的图片,有点感到意外
上述图搜图的结果:
首先用于搜索的cat.jpg这张图片是这只经典白猫(mindspore老玩家都懂的~):
放大

搜索结果:
放大
放大

通过一张猫的图片搜出了其它猫的图片
七:搜图能力优缺点总结:
在搜索能力方便,本案例中使用的是clip模型,对于特征的表达没有那些大参数量的LLM那么强大,所以在复杂的表达搜索中效果可能不好,且文本输入的长度clip文件限制了77个token;还有,这个模型openai在训练时,应该基本上使用的是英文文本,虽然中文也不是完全不能搜索,但效果很差,输入“猫咪”能搜索,但其它的我测试下来基本不对;
但总体而言,简单的英文表达搜索,以及简单含义的图搜图,效果还是不错的;在hf上也发现了中文版训练的clip模型,后续有空尝试使用中文版的clip做一下这个搜图功能;
还有搜索性能方面,clip模型参数量相对于其它LLM是比较少的,加上mslite的推理优化加速,总体而言性能也不错,配置最低的8t ai pro上也能毫秒级搜索,内存占用也不多:
8t板子内存占用截图,总体而言不超过5G:
放大
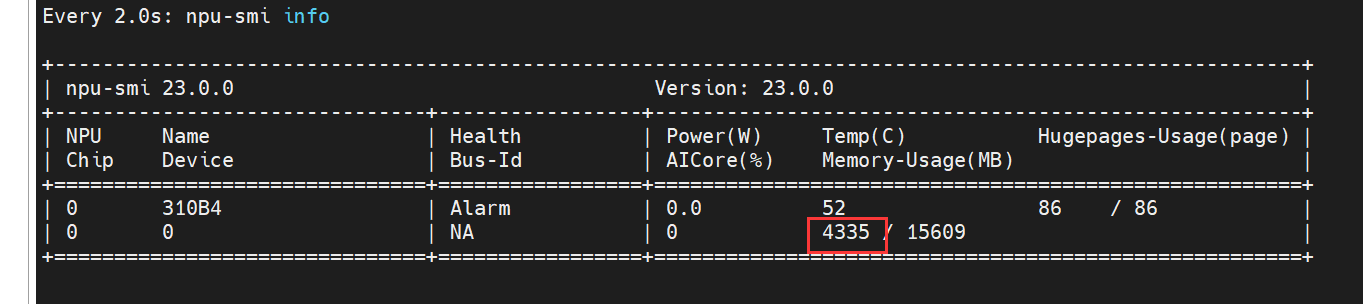
8t 板子性能:
文搜图:
total use time:0.03899216651916504
prepare use time:0.0012824535369873047, infer use time:0.011499643325805664, search use time:0.026203632354736328
放大
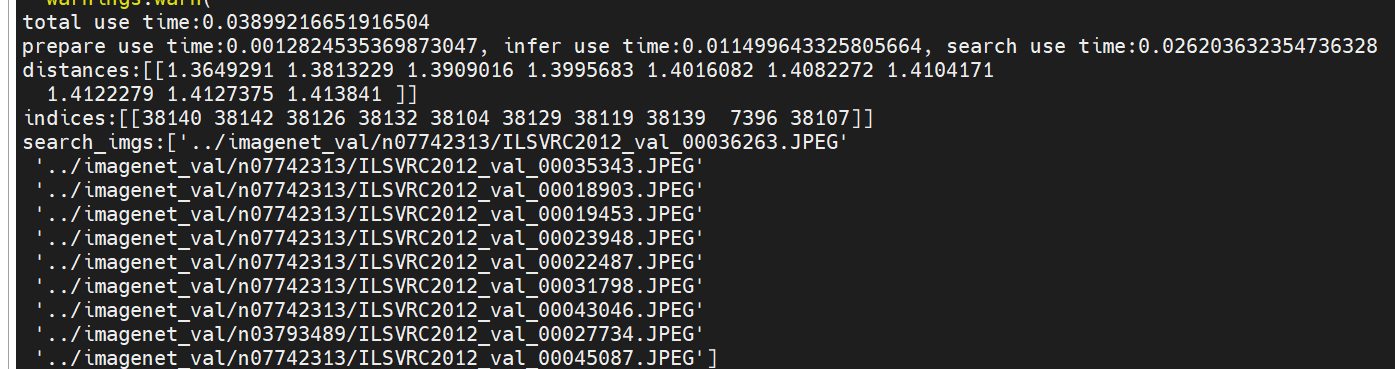
图搜图:
total use time:0.11694526672363281
prepare use time:0.06370806694030762, infer use time:0.026774168014526367, search use time:0.026456356048583984
放大
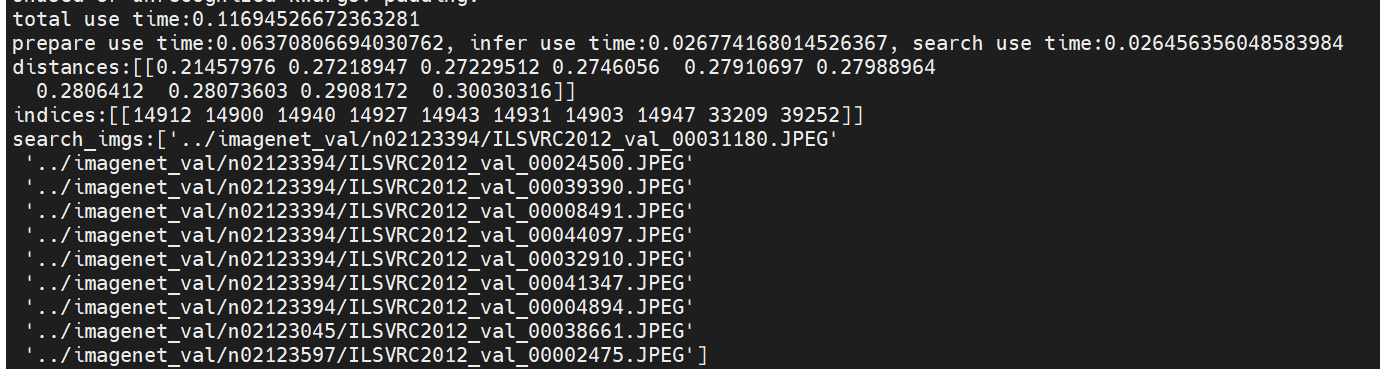
20t 板子性能:
文搜图:
total use time:0.02953171730041504
prepare use time:0.0009703636169433594, infer use time:0.006231069564819336, search use time:0.022325992584228516
放大
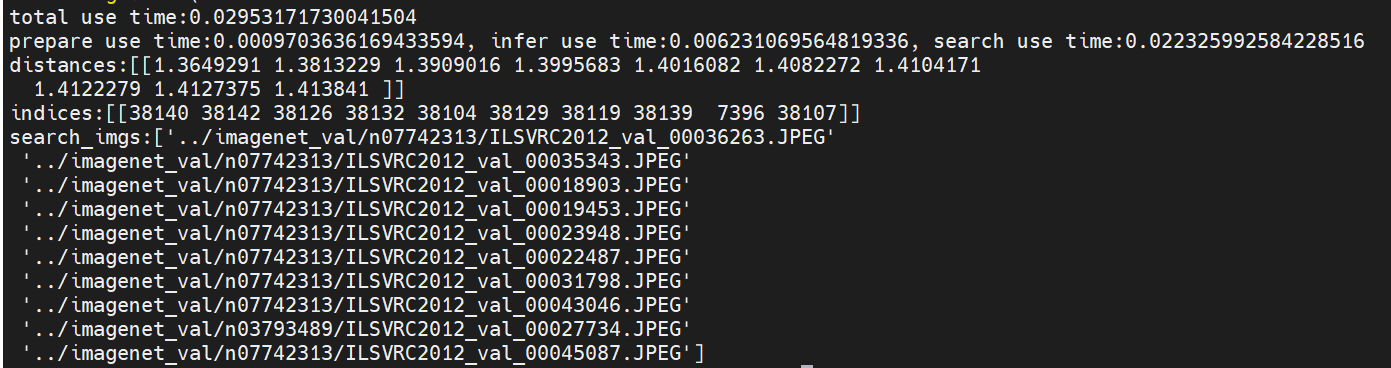
图搜图:
total use time:0.0781867504119873
prepare use time:0.0438840389251709, infer use time:0.01584339141845703, search use time:0.018454790115356445
放大
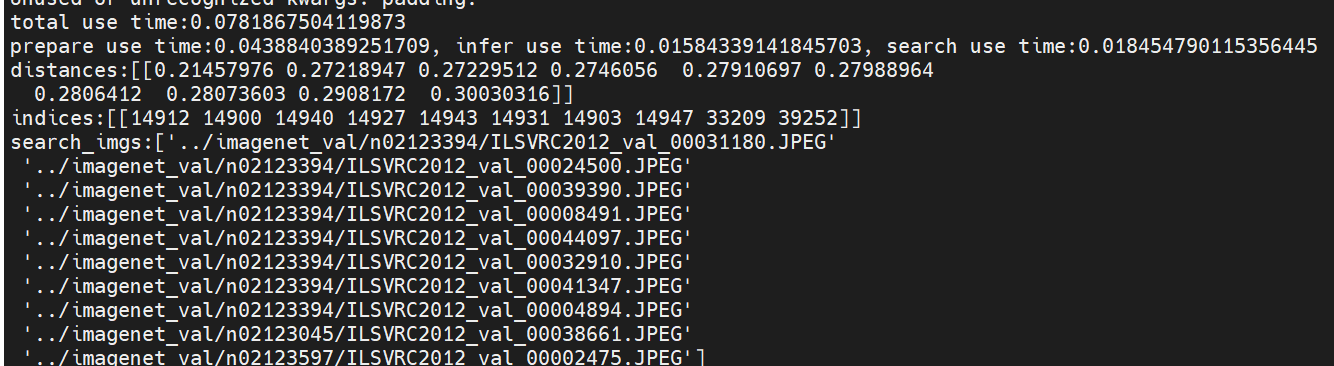
ai studio pro性能(有两个310p,总共352t,本案例中只使用了一个310p,也就是176t):
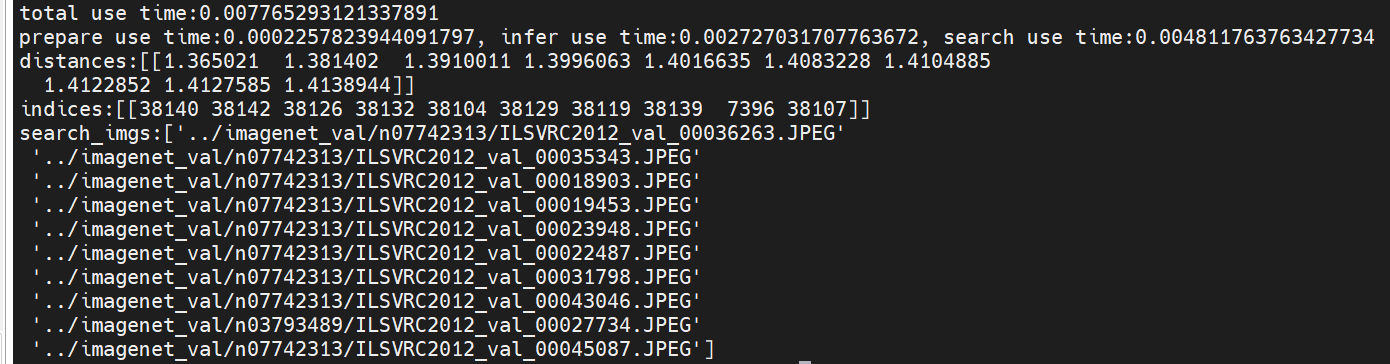
文搜图:
total use time:0.007765293121337891
prepare use time:0.0002257823944091797, infer use time:0.002727031707763672, search use time:0.004811763763427734
放大
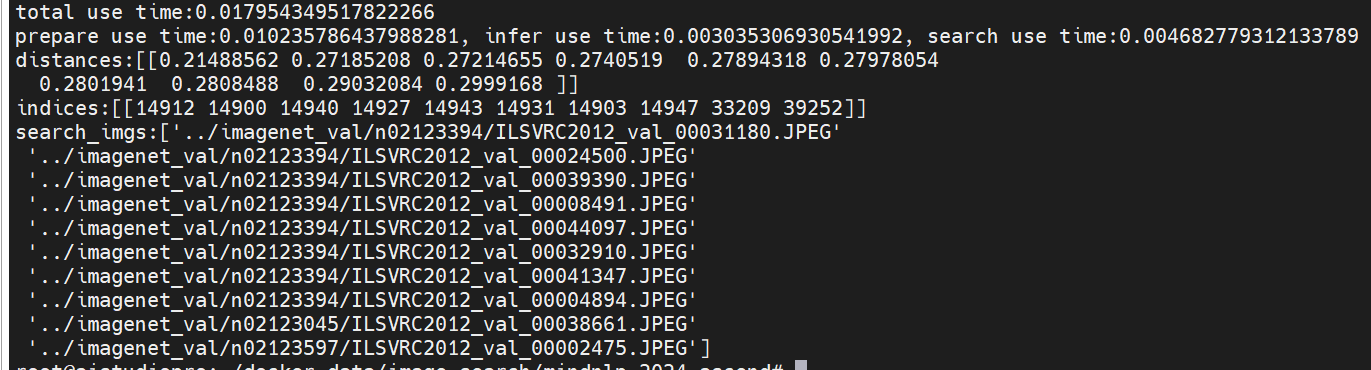
图搜图:
total use time:0.017954349517822266
prepare use time:0.010235786437988281, infer use time:0.003035306930541992, search use time:0.004682779312133789
放大
搜索过程总体可以分为三步,第一步预处理(图片或者文本的预处理),第二部模型推理,获取图片或者文本的特征,第三步,faiss向量索引库搜索
其中第一步和第三步看的是cpu性能,第一步的图片预处理对cpu性能要求比较搞,并且与图片大小也有关,所以cpu最弱的8t板子(arm 4核心1.0g主频,且实际只用了3核,有一个核作为ai cpu,不参与host cpu任务),在图搜图时第一步耗时最多;第二部获取特征才是走的ai芯片算力,且获取图片特征相比于获取文本特征需要的ai算力更高一些;
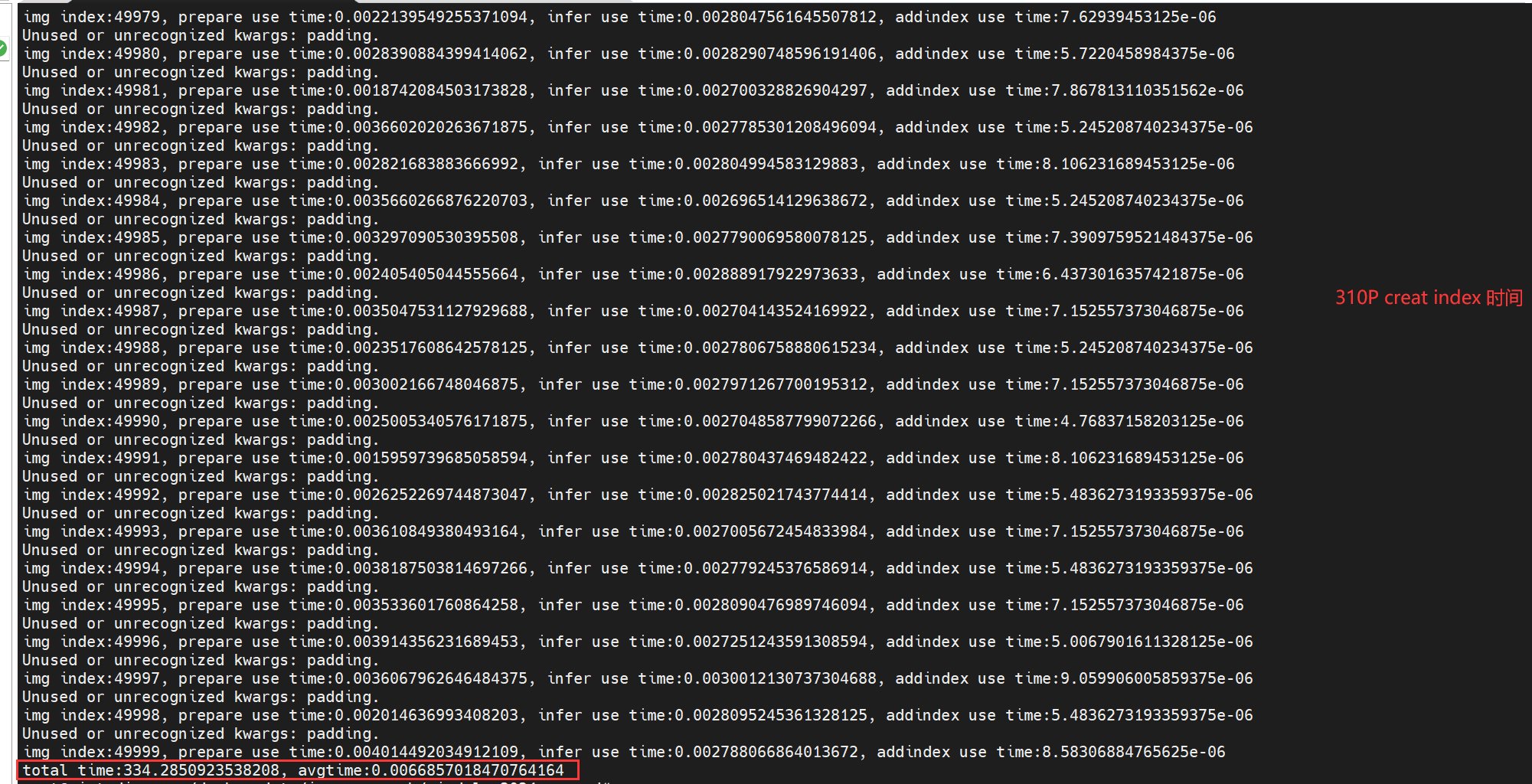
还有,一开始执行创建索引的代码,由于图片比较多(有5万个),建议在性能配置比较高的开发板上运行,否则会比较慢,我这边是在ai studio pro上执行的,截图如下:
放大
然后又在8t板子上稍微执行了一下:
放大
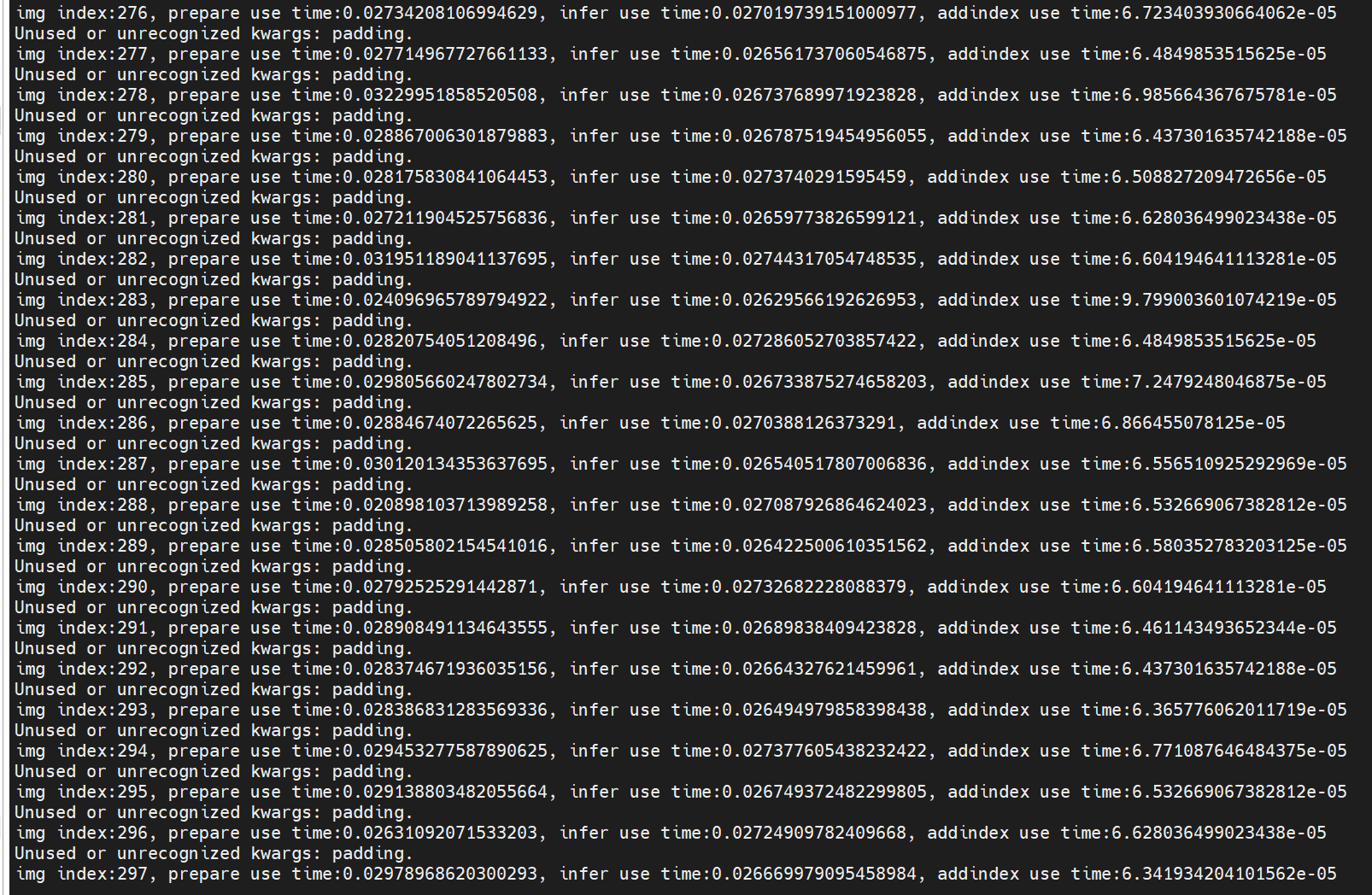
可以看出,8t板子的时间,几乎都是ai studio pro上的10倍
最后再提一下,在ai pro上有时候可能会发现什么都没正在执行的状态下,内存占用却很高,这可能是因为前面的一些操作,比如cann包的安装过程占用了内存,然后执行完毕后没有直接释放,而是放入缓存了,这种情况其实没有影响,当需要使用那部分内存时,系统会自动释放的,如果想要手动释放缓存,可以执行一下命令:
释放板子缓存
sudo sync && echo 3 | sudo tee /proc/sys/vm/drop_caches

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献53条内容
已为社区贡献53条内容

所有评论(0)