Oracle官方文档翻译《Database Concepts 23ai》第10章-SQL
Oracle官方文档翻译《Database Concepts 23ai》第10章-SQL
10 SQL
本章概述了结构化查询语言(SQL)以及Oracle数据库如何处理SQL语句。
-
Introduction to SQL(SQL简介)
SQL(发音为“sequel”)是一种基于集合的高级声明式计算机语言,所有程序和用户都通过它访问Oracle数据库中的数据。 -
Overview of SQL Statements(SQL语句概述)
对Oracle数据库中的信息执行的所有操作都通过SQL语句完成。SQL语句是一种计算机程序或指令,由标识符、参数、变量、名称、数据类型和SQL保留字组成。 -
Overview of the Optimizer(优化器概述)
要理解Oracle数据库如何处理SQL语句,必须先了解数据库中称为“优化器”(也称为查询优化器或基于成本的优化器)的组件。所有SQL语句都会借助优化器来确定访问指定数据的最高效方式。 -
Overview of SQL Processing(SQL处理概述)
本节介绍Oracle数据库如何处理SQL语句。具体而言,本节将说明数据库如何处理用于创建对象的DDL语句、用于修改数据的DML语句以及用于检索数据的查询语句。
Introduction to SQL(SQL简介)
SQL(发音为“sequel”)是一种基于集合的高级声明式计算机语言,所有程序和用户都通过它访问Oracle数据库中的数据。
尽管某些Oracle工具和应用程序会隐藏SQL的使用过程,但所有数据库任务的执行都依赖SQL。任何其他数据访问方式都会绕过Oracle数据库内置的安全性机制,可能损害数据安全性和完整性。
SQL为Oracle数据库这类关系型数据库提供了统一接口。通过这一种一致性语言,SQL可统一完成以下任务:
- 创建、替换、修改和删除对象
- 插入、更新和删除表行
- 查询数据
- 控制对数据库及其对象的访问
- 保证数据库的一致性和完整性
SQL支持交互式使用,即手动在程序中输入语句;也可嵌入到C、Java等其他编程语言编写的程序中使用。
-
SQL Data Access(SQL数据访问)
计算机语言主要分为两大类:一类是声明式语言(非过程化语言),用于描述“要做什么”;另一类是C++、Java等过程化语言,用于描述“要怎么做”。 -
SQL Standards(SQL标准)
Oracle致力于遵循行业认可的标准,并积极参与SQL标准委员会的工作。
另请参见:
- “Introduction to Server-Side Programming(服务器端编程简介)”
- 有关如何选择编程环境的内容,请参阅《Oracle Database Development Guide》(Oracle数据库开发指南)
- 有关SQL的简介,请参阅《Oracle Database SQL Language Reference》(Oracle数据库SQL语言参考)
SQL Data Access(SQL数据访问)
计算机语言主要分为两大类:一类是声明式语言(非过程化语言),用于描述“要做什么”;另一类是C++、Java等过程化语言,用于描述“要怎么做”。
SQL属于声明式语言,用户只需指定想要的结果,无需说明如何获取结果。例如,以下语句查询姓氏以“K”开头的员工记录:
SELECT last_name, first_name
FROM hr.employees
WHERE last_name LIKE 'K%'
ORDER BY last_name, first_name;
数据库会自动生成导航数据并检索所需结果的过程。SQL的声明式特性使您能够在逻辑层面操作数据,仅在需要处理数据时才需关注实现细节。
数据库会通过单个步骤检索所有满足WHERE条件(也称为谓词)的行,并可将这些行作为一个整体返回给用户、传递给另一条SQL语句或应用程序。应用程序无需逐行处理数据,开发人员也无需了解数据的物理存储或检索方式。
所有SQL语句都会使用“优化器”——数据库的一个组件,用于确定访问请求数据的最高效方式。Oracle数据库还支持多种技术,可帮助优化器更好地完成工作。
另请参见:
有关SQL语句及SQL其他组成部分(如运算符、函数和格式模型)的详细信息,请参阅《Oracle Database SQL Language Reference》(Oracle数据库SQL语言参考)
SQL Standards(SQL标准)
Oracle致力于遵循行业认可的标准,并积极参与SQL标准委员会的工作。
行业认可的委员会包括美国国家标准协会(ANSI)和国际标准化组织(ISO)。ANSI和ISO/IEC均已认可SQL作为关系型数据库的标准语言。
SQL标准包含十个部分。其中,SQL/RPR:2012是2012年新增的部分;2011年修订了另外五个部分;其余四个部分仍沿用2008年的版本。
Oracle SQL包含许多对ANSI/ISO标准SQL语言的扩展,Oracle数据库工具和应用程序还提供了额外的语句。SQL*Plus、SQL Developer和Oracle Enterprise Manager等工具支持您在Oracle数据库上运行任何ANSI/ISO标准SQL语句,以及这些工具支持的额外语句或函数。
另请参见:
- 《Oracle Database Get Started with Oracle Database Development》(Oracle数据库开发入门)
- 有关Oracle SQL与标准SQL差异的说明,请参阅《Oracle Database SQL Language Reference》(Oracle数据库SQL语言参考)
- 有关SQLPlus命令(包括其与SQL语句的区别)的内容,请参阅《SQLPlus User’s Guide and Reference》(SQL*Plus用户指南与参考)
Overview of SQL Statements(SQL语句概述)
对Oracle数据库中的信息执行的所有操作都通过SQL语句完成。SQL语句是一种计算机程序或指令,由标识符、参数、变量、名称、数据类型和SQL保留字组成。
注意:
SQL保留字在SQL中具有特殊含义,不应用于其他用途。例如,SELECT和UPDATE是保留字,不应作为表名使用。
一条SQL语句必须是一个完整的SQL句子,例如:
SELECT last_name, department_id FROM employees
Oracle数据库仅执行完整的SQL语句。以下这类片段会触发错误,提示“需要更多文本”:
SELECT last_name;
Oracle SQL语句分为以下类别:
-
数据定义语言(DDL)语句(Data Definition Language (DDL) Statements)
数据定义语言(DDL)语句用于定义、结构化修改和删除模式对象。 -
数据操作语言(DML)语句(Data Manipulation Language (DML) Statements)
数据操作语言(DML)语句用于查询或操作现有模式对象中的数据。 -
事务控制语句(Transaction Control Statements)
事务控制语句用于管理DML语句所做的修改,并将DML语句分组为事务。 -
会话控制语句(Session Control Statements)
会话控制语句用于动态管理用户会话的属性。 -
系统控制语句(System Control Statement)
系统控制语句用于修改数据库实例的属性。 -
嵌入式SQL语句(Embedded SQL Statements)
嵌入式SQL语句是将DDL、DML和事务控制语句嵌入到过程化语言程序中的语句。
数据定义语言(DDL)语句(Data Definition Language (DDL) Statements)
数据定义语言(DDL)语句用于定义、结构化修改和删除模式对象。
通过DDL,您可以修改对象的属性,而无需修改访问该对象的应用程序。例如,您可以向人力资源应用程序访问的表中添加一列,而无需重写该应用程序;也可以在数据库用户执行操作时,通过DDL修改对象的结构。
具体而言,DDL语句可实现以下功能:
- 创建、修改和删除模式对象及其他数据库结构(包括数据库本身和数据库用户)。大多数DDL语句以
CREATE、ALTER或DROP关键字开头。 - 清空模式对象中的所有数据,但保留对象结构(使用
TRUNCATE语句)。
注意:
与DELETE不同,TRUNCATE不会生成回滚数据,因此比DELETE更快;此外,TRUNCATE不会触发删除触发器。
- 授予和撤销权限与角色(使用
GRANT、REVOKE语句)。 - 启用和禁用审计选项(使用
AUDIT、NOAUDIT语句)。 - 向数据字典添加注释(使用
COMMENT语句)。
Example 10-1 DDL Statements(示例10-1 DDL语句)
以下示例使用DDL语句创建plants表,然后使用DML语句向该表中插入两行数据;接着通过DDL语句修改表结构、为用户授予和撤销该表的读取权限,最后删除该表:
CREATE TABLE plants
( plant_id NUMBER PRIMARY KEY,
common_name VARCHAR2(15)
);
INSERT INTO plants VALUES (1, 'African Violet'); -- DML语句
INSERT INTO plants VALUES (2, 'Amaryllis'); -- DML语句
ALTER TABLE plants ADD ( latin_name VARCHAR2(40) );
GRANT READ ON plants TO scott;
REVOKE READ ON plants FROM scott;
DROP TABLE plants;
在数据库执行DDL语句之前,会隐式执行一次COMMIT;DDL语句执行后,会立即执行一次COMMIT或ROLLBACK。在上述示例中,两条INSERT语句之后紧跟一条ALTER TABLE语句,因此数据库会提交这两条INSERT语句。如果ALTER TABLE语句执行成功,数据库会提交该语句;如果失败,则会回滚该语句。无论哪种情况,两条INSERT语句都已提前提交。
另请参见:
- 有关权限和角色的内容,请参阅《Oracle Database Security Guide》(Oracle数据库安全指南)
- 有关如何创建模式对象的内容,请参阅《Oracle Database Get Started with Oracle Database Development》(Oracle数据库开发入门)和《Oracle Database Administrator’s Guide》(Oracle数据库管理员指南)
- 有关阻塞式DDL与非阻塞式DDL差异的内容,请参阅《Oracle Database Development Guide》(Oracle数据库开发指南)
- 有关DDL语句列表,请参阅《Oracle Database SQL Language Reference》(Oracle数据库SQL语言参考)
数据操作语言(DML)语句(Data Manipulation Language (DML) Statements)
数据操作语言(DML)语句用于查询或操作现有模式对象中的数据。
DDL语句用于修改数据库结构,而DML语句用于查询或修改数据内容。例如,ALTER TABLE用于修改表结构,INSERT用于向表中添加一行或多行数据。
DML语句是最常用的SQL语句,可实现以下功能:
- 从一个或多个表或视图中检索数据(使用
SELECT语句)。 - 通过指定列值列表或使用子查询选择并处理现有数据,向表或视图中添加新行(使用
INSERT语句)。 - 修改表或视图中现有行的列值(使用
UPDATE语句)。 - 有条件地向表或视图中更新或插入行(使用
MERGE语句)。 - 从表或视图中删除行(使用
DELETE语句)。 - 查看SQL语句的执行计划(使用
EXPLAIN PLAN语句)。 - 锁定表或视图,暂时限制其他用户的访问(使用
LOCK TABLE语句)。
以下示例使用DML语句查询employees表,插入一行数据到该表,更新该行数据,最后删除该行:
SELECT * FROM employees;
INSERT INTO employees (employee_id, last_name, email, job_id, hire_date, salary)
VALUES (1234, 'Mascis', 'JMASCIS', 'IT_PROG', '14-FEB-2008', 9000);
UPDATE employees SET salary=9100 WHERE employee_id=1234;
DELETE FROM employees WHERE employee_id=1234;
构成一个逻辑工作单元的一组DML语句称为“事务”。例如,转账事务可能包含三个独立操作:减少储蓄账户余额、增加支票账户余额,以及在账户历史表中记录转账信息。与DDL语句不同,DML语句不会隐式提交当前事务。
-
SELECT语句(SELECT Statements)
查询(query)是从表或视图中检索数据的操作。 -
连接(Joins)
连接(join)是一种查询,用于合并来自两个或多个表、视图或物化视图的行。 -
子查询(Subqueries)
子查询(subquery)是嵌套在另一条SQL语句中的SELECT语句。当需要执行多个查询来解决单个问题时,子查询非常有用。
另请参见:
- “DML与DDL处理的差异(Differences Between DML and DDL Processing)”
- “事务简介(Introduction to Transactions)”
- 有关如何查询和操作数据的内容,请参阅《Oracle Database Get Started with Oracle Database Development》(Oracle数据库开发入门)
- 有关DML语句列表,请参阅《Oracle Database SQL Language Reference》(Oracle数据库SQL语言参考)
SELECT语句(SELECT Statements)
查询是从表或视图中检索数据的操作。
SELECT是唯一可用于查询数据的SQL语句。执行SELECT语句后检索到的数据集称为“结果集(result set)”。
下表列出了SELECT语句中两个必需的关键字和两个常用关键字,并关联了SELECT语句的功能与对应关键字:
Table 10-1 Keywords in a SQL Statement(表10-1 SQL语句中的关键字)
| 关键字(Keyword) | 是否必需(Required?) | 描述(Description) | 功能(Capability) |
|---|---|---|---|
SELECT |
是(Yes) | 指定结果中应显示的列。投影(Projection)会从表中筛选出列的子集。表达式(expression)是一个或多个值、运算符和SQL函数的组合,最终会解析为一个值。SELECT关键字之后、FROM子句之前的表达式列表称为“选择列表(select list)”。 |
投影(Projection) |
FROM |
否(No) | 指定应从中检索数据的表或视图。 | 连接(Joining) |
WHERE |
否(No) | 指定筛选行的条件,从表中筛选出行的子集。条件(condition)是一个或多个表达式与逻辑(布尔)运算符的组合,返回值为TRUE、FALSE或UNKNOWN。 |
选择(Selection) |
ORDER BY |
否(No) | 指定结果中行的显示顺序。 | - |
另请参见:
有关SELECT语句的语法和语义,请参阅《Oracle Database SQL Language Reference》(Oracle数据库SQL语言参考)
连接(Joins)
连接是一种查询,用于合并来自两个或多个表、视图或物化视图的行。
以下示例将employees表和departments表进行连接(FROM子句),仅选择满足指定条件的行(WHERE子句),并通过投影从两列中检索数据(SELECT语句)。SQL语句之后是示例输出:
SELECT email, department_name
FROM employees
JOIN departments ON employees.department_id = departments.department_id
WHERE employee_id IN (100,103)
ORDER BY email;
| DEPARTMENT_NAME | |
|---|---|
| AHUNOLD | IT |
| SKING | Executive |
下图展示了上述查询连接操作中的投影和选择过程:
Figure 10-1 Projection and Selection(图10-1 投影与选择)
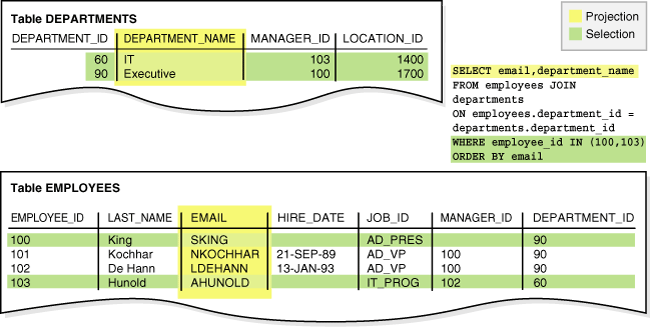
大多数连接至少包含一个连接条件(位于FROM子句或WHERE子句中),用于比较两个来自不同表的列。数据库会将两个表中的行两两组合(每个组合包含两个表各一行),仅保留连接条件结果为TRUE的组合。优化器会根据连接条件、索引以及表的可用统计信息,确定数据库连接表的顺序。
连接类型包括以下几种:
-
内连接(Inner joins)
内连接(inner join)是对两个或多个表的连接,仅返回满足连接条件的行。例如,如果连接条件为employees.department_id=departments.department_id,则不满足该条件的行不会被返回。 -
外连接(Outer joins)
外连接(outer join)会返回所有满足连接条件的行,同时还会返回来自其中一个表的、在另一个表中无匹配行的行。
表A和表B的左外连接(left outer join)结果始终包含左表A的所有记录,即使连接条件在右表B中无匹配记录。如果B中无匹配行,则B的列在无匹配的行中显示为空值(null)。例如,如果并非所有员工都属于某个部门,那么employees表(左表)与departments表(右表)的左外连接会检索employees表的所有行,即使departments表中无满足连接条件的行(即employees.department_id为空)。
表A和表B的右外连接(right outer join)结果包含右表B的所有记录,即使连接条件在左表A中无匹配行。如果A中无匹配行,则A的列在无匹配的行中显示为空值。例如,如果并非所有部门都有员工,那么employees表(左表)与departments表(右表)的右外连接会检索departments表的所有行,即使employees表中无满足连接条件的行。
全外连接(full outer join)是左外连接和右外连接的组合。 -
笛卡尔积(Cartesian products)
如果连接查询中的两个表没有连接条件,数据库会执行笛卡尔连接(Cartesian join)。此时,一个表的每一行都会与另一个表的每一行组合。例如,如果employees表有107行,departments表有27行,那么笛卡尔积将包含107×27行数据。笛卡尔积很少有实际用途。
另请参见:
- 有关连接的内容,请参阅《Oracle Database SQL Tuning Guide》(Oracle数据库SQL优化指南)
- 有关连接的详细描述和示例,请参阅《Oracle Database SQL Language Reference》(Oracle数据库SQL语言参考)
子查询(Subqueries)
子查询是嵌套在另一条SQL语句中的SELECT语句。当需要执行多个查询来解决单个问题时,子查询非常有用。
语句中的每个查询部分称为“查询块(query block)”。在以下查询中,括号内的子查询是“内部查询块(inner query block)”:
SELECT first_name, last_name
FROM employees
WHERE department_id IN (
SELECT department_id
FROM departments
WHERE location_id = 1800
);
内部SELECT语句检索位置ID为1800的部门的ID,这些部门ID供外部查询块使用,外部查询块则检索属于这些部门(由子查询提供部门ID)的员工姓名。
SQL语句的结构并不强制数据库先执行内部查询。例如,数据库可能会将整个查询重写为employees表和departments表的连接,使得子查询无需单独执行;又如,虚拟专用数据库(VPD)功能可能会通过WHERE子句限制对employees表的查询,导致数据库先查询employees表,再获取部门ID。优化器会确定检索请求行的最佳步骤顺序。
另请参见:
有关VPD的更多信息,请参阅《Oracle Database Security Guide》(Oracle数据库安全指南)
事务控制语句(Transaction Control Statements)
事务控制语句用于管理DML语句所做的修改,并将DML语句分组为事务。
这些语句可实现以下功能:
- 将事务中的修改永久化(使用
COMMIT语句)。 - 撤销事务中的修改(从事务开始时或从某个保存点开始,使用
ROLLBACK或ROLLBACK TO SAVEPOINT语句)。保存点(savepoint)是用户在事务上下文中声明的中间标记。
注意:ROLLBACK语句会结束事务,但ROLLBACK TO SAVEPOINT不会。
- 设置可回滚到的保存点(使用
SAVEPOINT语句)。 - 为事务设置属性(使用
SET TRANSACTION语句)。 - 指定可延迟完整性约束是在每条DML语句之后检查,还是在事务提交时检查(使用
SET CONSTRAINT语句)。
以下示例启动一个名为“Update salaries”的事务,创建保存点,更新员工薪资,然后将事务回滚到该保存点;接着将薪资更新为另一个值,并提交事务:
SET TRANSACTION NAME 'Update salaries';
SAVEPOINT before_salary_update;
UPDATE employees SET salary=9100 WHERE employee_id=1234; -- DML语句
ROLLBACK TO SAVEPOINT before_salary_update;
UPDATE employees SET salary=9200 WHERE employee_id=1234; -- DML语句
COMMIT COMMENT 'Updated salaries';
另请参见:
- “事务简介(Introduction to Transactions)”
- “数据库何时检查约束有效性(When the Database Checks Constraints for Validity)”
- 有关事务控制语句的内容,请参阅《Oracle Database SQL Language Reference》(Oracle数据库SQL语言参考)
会话控制语句(Session Control Statements)
会话控制语句用于动态管理用户会话的属性。
会话(session)是数据库实例内存中的逻辑实体,代表当前用户登录数据库的状态。会话从用户通过数据库身份验证开始,到用户断开连接或退出数据库应用程序结束。
会话控制语句可实现以下功能:
- 通过执行特定功能(如设置默认日期格式)修改当前会话(使用
ALTER SESSION语句)。 - 为当前会话启用和禁用角色(角色是权限的集合,使用
SET ROLE语句)。
以下语句将您的会话默认日期格式动态更改为'YYYY MM DD-HH24:MI:SS':
ALTER SESSION SET NLS_DATE_FORMAT = 'YYYY MM DD HH24:MI:SS';
会话控制语句不会隐式提交当前事务。
另请参见:
- “连接与会话(Connections and Sessions)”
- 有关
ALTER SESSION语句的语法和语义,请参阅《Oracle Database SQL Language Reference》(Oracle数据库SQL语言参考)
系统控制语句(System Control Statement)
系统控制语句用于修改数据库实例的属性。
唯一的系统控制语句是ALTER SYSTEM,可用于修改设置(如共享服务器的最小数量)、终止会话以及执行其他系统级任务。
系统控制语句示例如下:
ALTER SYSTEM SWITCH LOGFILE;
ALTER SYSTEM KILL SESSION '39, 23';
ALTER SYSTEM语句不会隐式提交当前事务。
另请参见:
有关ALTER SYSTEM语句的语法和语义,请参阅《Oracle Database SQL Language Reference》(Oracle数据库SQL语言参考)
嵌入式SQL语句(Embedded SQL Statements)
嵌入式SQL语句是将DDL、DML和事务控制语句嵌入到过程化语言程序中的语句。
嵌入式语句与Oracle预编译器配合使用。嵌入式SQL是在过程化语言应用程序中集成SQL的一种方式,另一种方式是使用Open Database Connectivity(ODBC,开放数据库连接)或Java Database Connectivity(JDBC,Java数据库连接)等过程化API。
嵌入式SQL语句可实现以下功能:
- 定义、分配和释放游标(使用
DECLARE CURSOR、OPEN、CLOSE语句)。 - 指定数据库并连接到该数据库(使用
DECLARE DATABASE、CONNECT语句)。 - 分配变量名(使用
DECLARE STATEMENT语句)。 - 初始化描述符(使用
DESCRIBE语句)。 - 指定错误和警告条件的处理方式(使用
WHENEVER语句)。 - 解析和执行SQL语句(使用
PREPARE、EXECUTE、EXECUTE IMMEDIATE语句)。 - 从数据库检索数据(使用
FETCH语句)。
另请参见:
- “服务器端编程简介(Introduction to Server-Side Programming)”
- 《Oracle Database Development Guide》(Oracle数据库开发指南)
Overview of the Optimizer(优化器概述)
要理解Oracle数据库如何处理SQL语句,必须先了解数据库中称为“优化器”(也称为查询优化器或基于成本的优化器)的组件。所有SQL语句都会借助优化器来确定访问指定数据的最高效方式。
-
优化器的使用(Use of the Optimizer)
优化器会生成描述可能执行方法的“执行计划(execution plans)”。 -
优化器组件(Optimizer Components)
优化器包含三个主要组件:转换器(transformer)、估计器(estimator)和计划生成器(plan generator)。 -
访问路径(Access Paths)
访问路径(access path)是查询用于检索行的技术。 -
优化器统计信息(Optimizer Statistics)
优化器统计信息(optimizer statistics)是一组描述数据库及其对象详细信息的数据。这些统计信息提供了数据存储和分布的统计准确视图,供优化器在评估访问路径时使用。 -
优化器提示(Optimizer Hints)
提示(hint)是SQL语句中的注释,用作对优化器的指令。
优化器的使用(Use of the Optimizer)
优化器会生成描述可能执行方法的执行计划。
优化器通过考虑多种信息来源来确定哪种执行计划最高效,例如查询条件、可用访问路径、为系统收集的统计信息以及提示。
要执行一条DML语句,Oracle数据库可能需要执行多个步骤。每个步骤要么从数据库物理检索行数据,要么为执行该语句的用户准备数据。数据库执行语句所采用的步骤会极大影响语句的运行速度,通常存在多种处理DML语句的方式(例如,访问表或索引的顺序可能不同)。
在为SQL语句确定最佳执行计划时,优化器会执行以下操作:
- 表达式和条件的评估
- 检查完整性约束以了解更多数据信息,并基于该元数据进行优化
- 语句转换
- 优化器目标的选择
- 访问路径的选择
- 连接顺序的选择
优化器会生成处理查询的大部分可能方式,并为生成的执行计划中的每个步骤分配一个“成本(cost)”。成本最低的计划将被选为要执行的“查询计划(query plan)”。
注意:
您可以在不执行执行计划的情况下获取SQL语句的执行计划。只有数据库实际用于执行查询的执行计划,才能正确称为“查询计划”。
您可以通过设置优化器目标和为优化器收集具有代表性的统计信息,来影响优化器的选择。例如,您可以将优化器目标设置为以下两者之一:
- 总吞吐量(Total throughput):
ALL_ROWS提示指示优化器以最快速度将结果的最后一行返回给客户端应用程序。 - 初始响应时间(Initial response time):
FIRST_ROWS提示指示优化器以最快速度将第一行返回给客户端。
典型的终端用户交互式应用程序会从初始响应时间优化中受益,而批处理模式的非交互式应用程序则会从总吞吐量优化中受益。
另请参见:
- 有关使用
DBMS_STATS的信息,请参阅《Oracle Database PL/SQL Packages and Types Reference》(Oracle数据库PL/SQL包和类型参考) - 有关优化器和提示使用的更多信息,请参阅《Oracle Database SQL Tuning Guide》(Oracle数据库SQL优化指南)
优化器组件(Optimizer Components)
优化器包含三个主要组件:转换器、估计器和计划生成器。
下图展示了这些组件:
Figure 10-2 Optimizer Components(图10-2 优化器组件)
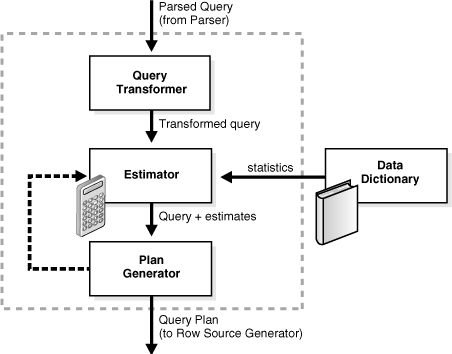
优化器的输入是解析后的查询。优化器会执行以下操作:
- 优化器接收解析后的查询,并基于可用访问路径和提示,为SQL语句生成一组潜在计划。
- 优化器根据数据字典中的统计信息估计每个计划的成本。成本是一个估计值,与使用特定计划执行语句所需的预期资源消耗成正比。
- 优化器比较各计划的成本,选择成本最低的计划(称为“查询计划”),并将其传递给行源生成器(row source generator)。
-
查询转换器(Query Transformer)
查询转换器(query transformer)会判断是否需要修改查询形式,以便优化器生成更好的执行计划。查询转换器的输入是解析后的查询,优化器将其表示为一组查询块。 -
估计器(Estimator)
估计器(estimator)用于确定给定执行计划的总成本。 -
计划生成器(Plan Generator)
计划生成器(plan generator)会为提交的查询尝试不同的计划,优化器选择成本最低的计划。
另请参见:
- “SQL解析(SQL Parsing)”
- “SQL行源生成(SQL Row Source Generation)”
查询转换器(Query Transformer)
查询转换器会判断是否需要修改查询形式,以便优化器生成更好的执行计划。查询转换器的输入是解析后的查询,优化器将其表示为一组查询块。
另请参见:
“查询重写(Query Rewrite)”
估计器(Estimator)
估计器用于确定给定执行计划的总成本。
为实现此目标,估计器会生成三种不同类型的度量:
- 选择性(Selectivity):表示行集中行的比例,与查询谓词(如
last_name='Smith')或谓词组合相关联。 - 基数(Cardinality):表示行集中行的数量。
- 成本(Cost):表示所使用的工作单元或资源,查询优化器以磁盘I/O、CPU使用率和内存使用率作为工作单元。
如果存在统计信息,估计器会使用这些统计信息计算度量值,从而提高度量的准确性。
计划生成器(Plan Generator)
计划生成器会为提交的查询尝试不同的计划,优化器选择成本最低的计划。
对于每个嵌套子查询和未合并视图,优化器都会生成一个子计划,并将每个子计划表示为单独的查询块。计划生成器通过尝试不同的访问路径、连接方法和连接顺序,为查询块探索各种计划。
自适应查询优化(adaptive query optimization)功能会根据语句执行期间收集的统计信息修改计划。所有自适应机制都能为语句执行最终计划,该计划可能与默认计划不同。自适应优化要么使用动态计划(在语句执行期间在子计划之间选择),要么使用重优化(在当前执行之后的执行中修改计划)。
另请参见:
- 有关SQL优化的简介,请参阅《Oracle Database Get Started with Performance Tuning》(Oracle数据库性能调优入门)
- 有关优化器组件和自适应优化的内容,请参阅《Oracle Database SQL Tuning Guide》(Oracle数据库SQL优化指南)
访问路径(Access Paths)
访问路径是查询用于检索行的技术。
例如,使用索引的查询与不使用索引的查询具有不同的访问路径。通常,索引访问路径最适合检索表中行子集的语句,而全表扫描(full scan)更适合访问表中大部分数据的场景。
数据库可以使用多种不同的访问路径从表中检索数据,以下是代表性列表:
- 全表扫描(Full table scans):这种扫描方式会读取表中的所有行,并筛选出不满足选择条件的行。数据库会顺序扫描段中的所有数据块,包括高水位线(HWM,用于区分已使用空间和未使用空间)以下的块(请参阅“段空间与高水位线(Segment Space and the High Water Mark)”)。
- Rowid扫描(Rowid scans):行的rowid指定了包含该行的数据文件、数据块以及该行在该块中的位置。数据库首先(通过语句
WHERE子句或索引扫描)获取所选行的rowid,然后根据rowid定位每个所选行。 - 索引扫描(Index scans):这种扫描方式会搜索索引,以查找SQL语句访问的索引列值(请参阅“索引扫描(Index Scans)”)。如果语句仅访问索引的列,则Oracle数据库会直接从索引中读取索引列值。
- 聚簇扫描(Cluster scans):聚簇扫描用于从存储在索引表聚簇(indexed table cluster)中的表中检索数据,其中具有相同聚簇键值的所有行都存储在同一个数据块中(请参阅“索引聚簇概述(Overview of Indexed Clusters)”)。数据库首先通过扫描聚簇索引获取所选行的rowid,然后根据该rowid定位行。
- 哈希扫描(Hash scans):哈希扫描用于在哈希聚簇(hash cluster)中定位行,其中具有相同哈希值的所有行都存储在同一个数据块中(请参阅“哈希聚簇概述(Overview of Hash Clusters)”)。数据库首先通过对语句指定的聚簇键值应用哈希函数获取哈希值,然后扫描包含具有该哈希值的行的数据块。
优化器会根据语句的可用访问路径以及使用每种访问路径(或路径组合)的估计成本,选择合适的访问路径。
另请参见:
有关访问路径的内容,请参阅《Oracle Database Get Started with Performance Tuning》(Oracle数据库性能调优入门)和《Oracle Database SQL Tuning Guide》(Oracle数据库SQL优化指南)
优化器统计信息(Optimizer Statistics)
优化器统计信息是一组描述数据库及其对象详细信息的数据。这些统计信息提供了数据存储和分布的统计准确视图,供优化器在评估访问路径时使用。
优化器统计信息包括以下类型:
- 表统计信息(Table statistics):包括行数、块数和平均行长度。
- 列统计信息(Column statistics):包括列中的不同值数量、空值数量以及数据分布。
- 索引统计信息(Index statistics):包括叶块数量和索引层级。
- 系统统计信息(System statistics):包括CPU和I/O性能及使用率。
Oracle数据库会自动收集所有数据库对象的优化器统计信息,并将这些统计信息作为自动维护任务进行维护。您也可以使用DBMS_STATS包手动收集统计信息。这个PL/SQL包可以修改、查看、导出、导入和删除统计信息。
注意:
优化器统计信息是为查询优化而创建的,存储在数据字典中。请勿将其与通过动态性能视图查看的性能统计信息混淆。
优化器统计信息顾问(Optimizer Statistics Advisor)是内置诊断软件,用于分析您当前收集统计信息的方式、现有统计信息收集作业的有效性以及收集到的统计信息的质量。该顾问会维护规则,这些规则体现了基于当前功能集的Oracle最佳实践,因此始终能提供最新的统计信息收集建议。
另请参见:
- 有关如何收集和管理统计信息的内容,请参阅《Oracle Database Get Started with Performance Tuning》(Oracle数据库性能调优入门)和《Oracle Database SQL Tuning Guide》(Oracle数据库SQL优化指南)
- 有关
DBMS_STATS的内容,请参阅《Oracle Database PL/SQL Packages and Types Reference》(Oracle数据库PL/SQL包和类型参考)
优化器提示(Optimizer Hints)
提示是SQL语句中的注释,用作对优化器的指令。
有时,应用程序设计人员比优化器更了解特定应用程序数据的情况,能够选择更高效的SQL语句执行方式。设计人员可以在SQL语句中使用提示,指定语句的执行方式。以下示例说明了提示的使用。
Example 10-2 Execution Plan for SELECT with FIRST_ROWS Hint(示例10-2 带有FIRST_ROWS提示的SELECT语句的执行计划)
假设您的交互式应用程序运行一个返回50行数据的查询,该应用程序最初仅获取查询结果的前25行展示给终端用户。您希望优化器生成一个能尽快获取前25条记录的计划,避免用户等待。如以下SELECT语句和AUTOTRACE输出所示,您可以使用提示向优化器传递此指令:
SELECT /*+ FIRST_ROWS(25) */ employee_id, department_id
FROM hr.employees
WHERE department_id > 50;
在此示例中,执行计划显示优化器选择employees.department_id列上的索引,以查找部门ID大于50的前25名员工。优化器使用从索引中检索到的rowid,从employees表中获取记录并返回给客户端。通常,第一条记录的检索几乎是即时的。
Example 10-3 Execution Plan for SELECT with No Hint(示例10-3 不带提示的SELECT语句的执行计划)
假设您执行相同的语句,但不使用优化器提示:
SELECT employee_id, department_id
FROM hr.employees
WHERE department_id > 50;
|* 3 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX | 50 | 350 |
| 3 | INDEX RANGE SCAN | EMP_DEPARTMENT_IX | 50 | 350 |
| 4 | INDEX FAST FULL SCAN| EMP_EMP_ID_PK | 50 | 350 |
在这种情况下,执行计划会连接两个索引,以尽快返回请求的记录。与示例10-2中反复从索引访问表不同,优化器选择对EMP_DEPARTMENT_IX进行范围扫描,查找所有部门ID大于50的行,并将这些行放入哈希表;然后选择读取EMP_EMP_ID_PK索引,对于该索引中的每一行,探查哈希表以查找部门ID。
在这种情况下,数据库必须完成EMP_DEPARTMENT_IX的索引范围扫描后,才能向客户端返回第一行数据。因此,生成的此计划返回第一条记录的时间会更长。与示例10-2中通过索引rowid访问表的计划不同,此计划使用多块I/O,可实现更大规模的读取,从而更快地返回整个结果集的最后一行。
另请参见:
有关如何使用优化器提示的内容,请参阅《Oracle Database SQL Tuning Guide》(Oracle数据库SQL优化指南)
Overview of SQL Processing(SQL处理概述)
本节介绍Oracle数据库如何处理SQL语句。具体而言,本节将说明数据库如何处理用于创建对象的DDL语句、用于修改数据的DML语句以及用于检索数据的查询语句。
-
SQL处理的阶段(Stages of SQL Processing)
SQL处理的一般阶段包括解析(parsing)、优化(optimization)、行源生成(row source generation)和执行(execution)。根据语句类型的不同,数据库可能会省略其中某些步骤。 -
DML与DDL处理的差异(Differences Between DML and DDL Processing)
Oracle数据库对DDL和DML的处理方式不同。
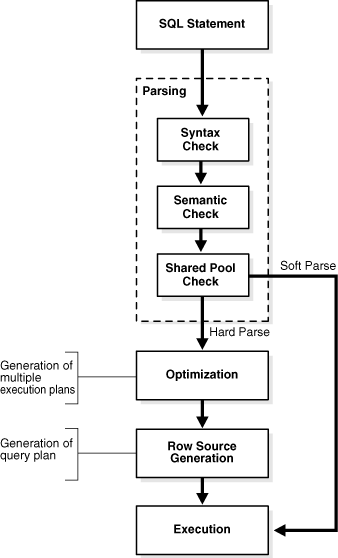
SQL处理的阶段(Stages of SQL Processing)
SQL处理的一般阶段包括解析、优化、行源生成和执行。根据语句类型的不同,数据库可能会省略其中某些步骤。
下图展示了一般阶段:
Figure 10-3 Stages of SQL Processing(图10-3 SQL处理的阶段)
-
SQL解析(SQL Parsing)
SQL处理的第一个阶段是SQL解析(SQL parsing)。在此阶段,会将SQL语句的各个部分拆分为数据结构,以便其他例程处理。 -
SQL优化(SQL Optimization)
查询优化(query optimization)是选择执行SQL语句最高效方式的过程。 -
SQL行源生成(SQL Row Source Generation)
行源生成器(row source generator)是一种软件,它从优化器接收最佳执行计划,并生成可被数据库其他部分使用的迭代计划(称为“查询计划”)。 -
SQL执行(SQL Execution)
在执行阶段,SQL引擎会执行行源生成器生成的树中的每个行源。这是DML处理中唯一必需的步骤。
SQL解析(SQL Parsing)
SQL处理的第一个阶段是SQL解析。在此阶段,会将SQL语句的各个部分拆分为数据结构,以便其他例程处理。
当应用程序发出SQL语句时,会向数据库发出解析调用(parse call),为执行语句做准备。解析调用会打开或创建一个游标(cursor)——游标是会话专用私有SQL区域的句柄,该区域存储解析后的SQL语句和其他处理信息。游标和私有SQL区域位于PGA(程序全局区)中。
在解析调用期间,数据库会执行以下检查:
- 语法检查(Syntax check)
- 语义检查(Semantic check)
- 共享池检查(Shared pool check)
上述检查会识别在语句执行前可发现的错误。有些错误无法在解析阶段捕获,例如数据库可能仅在语句执行期间遇到死锁或数据转换错误。
对于在解析阶段因ORA-00600错误而失败的SQL语句,数据库会尝试自动错误缓解。ORA-00600是严重错误,表示进程遇到了低级意外情况。当SQL语句在解析阶段因此错误失败时,自动错误缓解会捕获该错误并尝试解决问题。如果找到解决方案,数据库会生成SQL补丁以调整SQL执行计划;如果该补丁能使解析成功完成,则不会触发ORA-00600错误,应用程序也不会感知到异常。
另请参见:
- “锁与死锁(Locks and Deadlocks)”
- “自动SQL错误缓解简介(About Automatic SQL Error Mitigation)”
SQL优化(SQL Optimization)
查询优化是选择执行SQL语句最高效方式的过程。
数据库会根据收集到的、与实际访问数据相关的统计信息优化查询。优化器会使用行数、数据集大小和其他因素生成可能的执行计划,并为每个计划分配一个数值成本,最终选择成本最低的计划。
数据库必须至少对每个唯一的DML语句执行一次硬解析(hard parse),并在解析期间进行优化。DDL语句除非包含需要优化的DML组件(如子查询),否则不会被优化。
另请参见:
- “优化器概述(Overview of the Optimizer)”
- 有关查询优化器的详细信息,请参阅《Oracle Database SQL Tuning Guide》(Oracle数据库SQL优化指南)
SQL行源生成(SQL Row Source Generation)
行源生成器是一种软件,它从优化器接收最佳执行计划,并生成可被数据库其他部分使用的迭代计划(称为“查询计划”)。
查询计划采用多个步骤组合的形式,每个步骤返回一个行集(row set)。该行集中的行要么被下一步使用,要么在最后一步返回给发出SQL语句的应用程序。
行源(row source)是执行计划中某个步骤返回的行集,以及可迭代处理这些行的控制结构。行源可以是表、视图,也可以是连接或分组操作的结果。
SQL执行(SQL Execution)
在执行阶段,SQL引擎会执行行源生成器生成的树中的每个行源。这是DML处理中唯一必需的步骤。
执行期间,如果数据不在内存中,数据库会将数据从磁盘读取到内存;同时,数据库会获取确保数据完整性所需的所有锁和闩锁,并记录SQL执行期间所做的所有修改。SQL语句处理的最后一个阶段是关闭游标。
如果数据库配置为使用内存列存储(IM column store),则数据库会在可能的情况下将查询透明地路由到IM列存储,否则路由到磁盘和数据库缓冲区高速缓存。单个查询也可以同时使用IM列存储、磁盘和缓冲区高速缓存。例如,某个查询可能会连接两个表,其中只有一个表缓存在IM列存储中。
另请参见:
- “内存区域(In-Memory Area)”
- 有关执行计划和
EXPLAIN PLAN语句的详细信息,请参阅《Oracle Database SQL Tuning Guide》(Oracle数据库SQL优化指南)
DML与DDL处理的差异(Differences Between DML and DDL Processing)
Oracle数据库对DDL和DML的处理方式不同。
例如,创建表时,数据库不会优化CREATE TABLE语句,而是解析该DDL语句并执行命令。
与DDL不同,大多数DML语句包含查询组件。在查询中,执行游标会将查询生成的行放入结果集。
数据库可以逐行或以组的形式获取结果集行。在获取过程中,数据库会选择行,并在查询要求时对行进行排序。每次后续获取都会检索结果集中的下一行,直到获取完最后一行。
另请参见:
有关处理DDL、事务控制和其他类型语句的内容,请参阅《Oracle Database Development Guide》(Oracle数据库开发指南)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)