大模型的head都有哪些
Head 要轻量:大模型已学到丰富表示,Head 只做任务映射即可输出空间匹配任务:分类 → softmax,回归 → 实数向量,动作生成 → 连续动作训练方式:大模型可冻结或微调,Head 必须可训练共享与可扩展:不同任务可共享底层大模型,只换 Head 即可。
1️⃣ 大模型 + 任务头的基本概念
-
大模型:已经训练好的通用模型(例如 LLaMA、GPT、CLIP、Prismatic VLM)
-
任务头(Head):在大模型输出后增加的轻量网络,用于把通用表示映射成 具体任务所需输出
-
原理:大模型负责抽象表示(理解/生成),任务头把表示转换成 可监督或可执行信号
公式上:
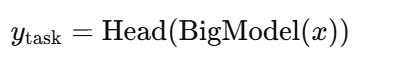
2️⃣ 不同任务的 Head 设计举例
(1) 分类任务
-
输入:文本 / 图像 / 多模态表示
-
设计:
-
取大模型最后层 [CLS] token 或 pooled representation
-
接一个 线性层 + softmax → 得到类别概率
-
-
公式:
![]()
-
示例:
-
文本分类:情感分析、意图识别
-
图像分类:猫/狗/鸟
-
多模态分类:视觉问答(VQA)选择答案
-
(2) 回归 / 连续值预测
-
输入:大模型表示
-
设计:
-
MLP 或线性层直接输出连续向量
-
-
公式:
![]()
-
示例:
-
房价预测
-
机器人关节角度(连续动作控制)
-
图像深度估计
-
(3) 动作生成 / 控制
-
输入:多模态融合特征(视觉 + 指令)
-
设计:
-
MLP 或小 Transformer,将融合向量映射成动作向量序列
-
可输出连续值(关节角度)或离散动作类别
-
-
示例:
-
OpenVLA 机器人动作头
-
自动驾驶车辆转向/加速输出
-
(4) 序列生成 / 文本生成
-
输入:大模型隐藏状态
-
设计:
-
通常 解码器 + softmax 输出词表概率
-
可以直接用大模型本身作为生成头(如 GPT)
-
-
示例:
-
机器翻译
-
对话生成
-
图像描述生成
-
(5) 多模态任务 / 跨模态检索
-
输入:视觉 token + 文本 token 表示
-
设计:
-
MLP 映射到统一 embedding 空间 → 相似度计算(cosine similarity)
-
可以加 contrastive loss 或 InfoNCE loss
-
-
示例:
-
图文检索(CLIP、OpenVLA 检索)
-
多模态对齐任务
-
3️⃣ 设计原则总结
-
Head 要轻量:大模型已学到丰富表示,Head 只做任务映射即可
-
输出空间匹配任务:分类 → softmax,回归 → 实数向量,动作生成 → 连续动作
-
训练方式:大模型可冻结或微调,Head 必须可训练
-
共享与可扩展:不同任务可共享底层大模型,只换 Head 即可

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)