面向智能感知的AI Agent多模态数据清洗与特征优化方法(附代码)
AI Agent在智能感知系统的数据预处理与优化中,既是“清洁工”,也是“优化师”。它不仅能提升数据质量和模型性能,还能通过自适应机制与模块化设计,满足未来多模态、分布式和高可解释性需求。随着技术的发展,AI Agent将逐步从“预处理助手”演变为“全链路优化决策者”,成为智能感知系统中不可或缺的核心组成部分。
面向智能感知的AI Agent多模态数据清洗与特征优化方法
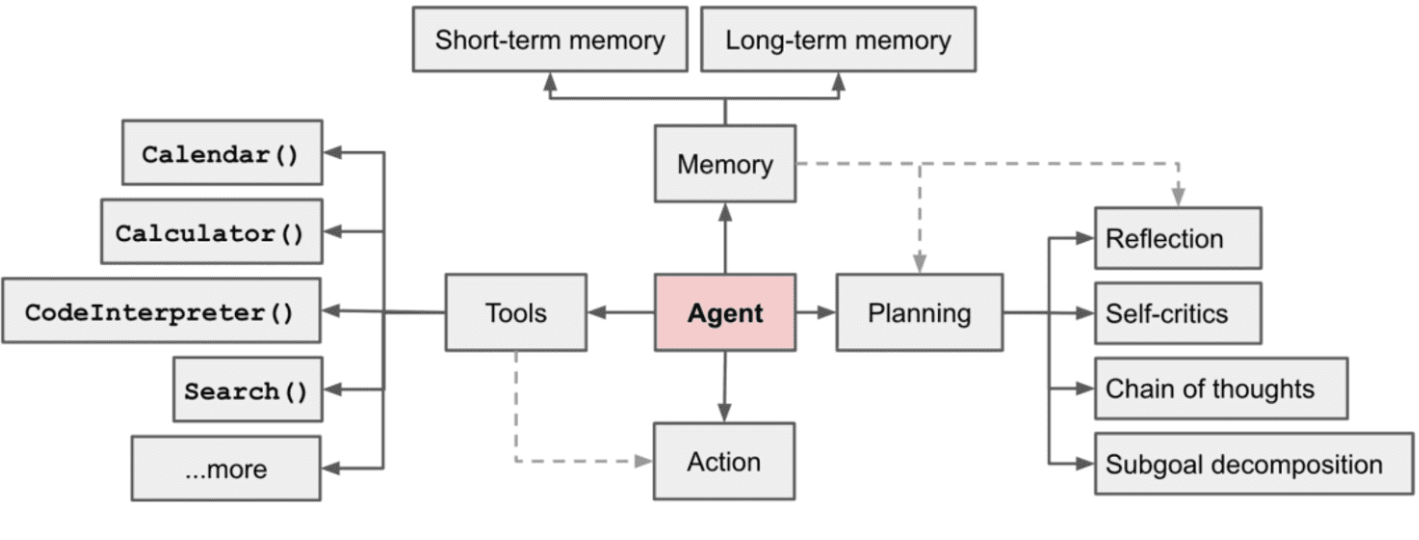
引言
在智能感知系统(Smart Perception Systems)中,传感器会不断采集多模态数据(图像、语音、传感器信号等)。然而,这些原始数据往往包含噪声、缺失值、冗余特征以及维度过高等问题。若直接输入AI模型,可能导致 训练效率下降、预测性能不足。
因此,如何利用 AI Agent 进行自动化的数据预处理与优化,成为构建高效智能感知系统的重要环节。本文将探讨AI Agent在数据清洗、特征提取、降维与增强方面的策略,并通过Python代码示例展示其实践过程。
一、AI Agent在智能感知系统中的角色
1.1 数据驱动的任务特性
在智能感知场景(如自动驾驶、智慧医疗、智能监控)中,AI Agent不仅是感知和决策的执行者,更是数据管道中的“智能处理单元”。它能根据任务需求动态选择预处理与优化策略,从而提升数据质量。
1.2 AI Agent的核心功能
- 数据清洗:自动检测缺失值、异常点并修复。
- 特征选择与降维:根据模型需求选择最优特征。
- 数据增强:对图像、语音等非结构化数据进行增强。
- 优化反馈:基于模型训练结果,动态调整预处理流程。
二、数据预处理策略
2.1 数据清洗
AI Agent通过异常检测算法(如IQR、孤立森林)剔除异常数据点,并采用插值或生成模型填补缺失值。
2.2 特征选择
- 过滤式:基于相关系数、卡方检验。
- 嵌入式:基于模型权重(如Lasso、决策树特征重要性)。
- 代理学习:AI Agent根据历史实验结果自动选择合适的特征。
2.3 降维与特征提取
常用方法:
- PCA:主成分分析。
- t-SNE/Umap:非线性降维,保持局部相似性。
- 自动编码器:利用深度学习提取低维表示。
2.4 数据增强
- 图像增强:旋转、翻转、颜色扰动。
- 时间序列增强:滑动窗口、加噪声。
- 语音增强:时域/频域扰动。
三、优化策略
3.1 动态调整机制
AI Agent结合强化学习或元学习,能够在不同任务和数据集上 动态选择最优预处理流程,而非固定管道。
3.2 反馈循环
训练完成后,AI Agent收集模型性能指标(如准确率、F1分数),并迭代优化数据处理策略。
四、代码实战:AI Agent自动化数据预处理
下面以一个传感器数据(带噪声与缺失值)为例,展示AI Agent如何进行自动预处理与优化。
import numpy as np
import pandas as pd
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
from sklearn.ensemble import IsolationForest
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score
class DataPreprocessingAgent:
def __init__(self):
self.imputer = SimpleImputer(strategy="mean")
self.scaler = StandardScaler()
self.pca = PCA(n_components=5)
self.outlier_detector = IsolationForest(contamination=0.05)
def clean_data(self, X):
# 填补缺失值
X_imputed = self.imputer.fit_transform(X)
# 去除异常值
mask = self.outlier_detector.fit_predict(X_imputed) == 1
return X_imputed[mask]
def optimize_features(self, X):
# 标准化
X_scaled = self.scaler.fit_transform(X)
# PCA降维
return self.pca.fit_transform(X_scaled)
def preprocess(self, X):
X_clean = self.clean_data(X)
X_opt = self.optimize_features(X_clean)
return X_opt
# ===== 模拟数据集 =====
np.random.seed(42)
X = np.random.randn(500, 10) * 5
y = np.random.randint(0, 2, 500)
# 注入缺失值
X.ravel()[np.random.choice(X.size, 50, replace=False)] = np.nan
# 使用AI Agent预处理
agent = DataPreprocessingAgent()
X_processed = agent.preprocess(X)
# 划分数据集并训练模型
X_train, X_test, y_train, y_test = train_test_split(X_processed, y, test_size=0.3, random_state=42)
clf = RandomForestClassifier()
clf.fit(X_train, y_train)
# 评估
y_pred = clf.predict(X_test)
print("Accuracy:", accuracy_score(y_test, y_pred))
print("F1 Score:", f1_score(y_test, y_pred))
代码说明
- DataPreprocessingAgent 封装了预处理管道(缺失值填充、异常值剔除、标准化、PCA降维)。
- 输入传感器数据后,AI Agent能自动输出优化后的数据。
- 最后利用RandomForest进行分类,并评估准确率与F1分数。
五、未来展望
5.1 自适应Agent
当前的数据预处理往往是“固定流程”,但不同场景对数据的处理需求并不一致。未来,AI Agent可以借助 强化学习(Reinforcement Learning) 和 元学习(Meta-Learning) 技术,在不同数据集与任务中实现动态策略选择。例如:
- 在噪声较多的环境中自动强化清洗流程;
- 在高维小样本任务中更偏向降维与特征选择;
- 在数据不足的情况下,自动启用数据增强策略。
这种自适应能力将使Agent在各种智能感知系统中更加高效,减少人工干预。
5.2 多模态数据融合
智能感知系统往往涉及 图像、语音、文本、传感器信号 等多模态数据。传统方法常常需要针对不同模态设计独立的预处理流程,但未来的AI Agent可以实现:
- 自动模态识别:根据数据特征判断其来源与类型;
- 跨模态特征对齐:统一时间戳、空间特征或语义表示;
- 多模态融合优化:利用深度网络(如多模态Transformer)生成统一特征表示。
这种自动化融合将提升系统整体的感知能力,为自动驾驶、智慧医疗等领域提供更强大的支撑。
5.3 边缘计算与联邦学习
随着物联网与边缘计算的兴起,数据处理不再仅依赖中心服务器。AI Agent可以部署在边缘节点,实现 就地预处理,减少数据传输开销。
- 边缘AI预处理:在传感器设备本地完成数据清洗与压缩,降低带宽消耗。
- 联邦学习结合预处理:多个设备的Agent可在不共享原始数据的前提下,共享预处理策略与模型参数,从而保护用户隐私。
5.4 可解释性与可控性
未来的AI Agent需要具备 可解释性,能够输出自身的决策逻辑,例如:为什么选择PCA而非AutoEncoder进行降维?为什么剔除了某些样本?这对医疗、金融等高风险领域尤为重要。
此外,Agent还应支持人机交互,让人工专家能够调整和约束其策略,形成“人机协同”的智能感知系统。
六、模块化AI Agent设计思路
为了适应复杂多样的应用场景,AI Agent的数据预处理模块需要具备 可插拔式设计,即不同策略可以自由组合。下面给出一个简化的模块化设计示例:
class BaseModule:
def process(self, X):
raise NotImplementedError
# ===== 各类模块实现 =====
class MissingValueHandler(BaseModule):
def __init__(self, strategy="mean"):
from sklearn.impute import SimpleImputer
self.imputer = SimpleImputer(strategy=strategy)
def process(self, X):
return self.imputer.fit_transform(X)
class OutlierRemover(BaseModule):
def __init__(self, contamination=0.05):
from sklearn.ensemble import IsolationForest
self.detector = IsolationForest(contamination=contamination)
def process(self, X):
mask = self.detector.fit_predict(X) == 1
return X[mask]
class FeatureScaler(BaseModule):
def __init__(self):
from sklearn.preprocessing import StandardScaler
self.scaler = StandardScaler()
def process(self, X):
return self.scaler.fit_transform(X)
class DimensionalityReducer(BaseModule):
def __init__(self, method="pca", n_components=5):
from sklearn.decomposition import PCA
self.reducer = PCA(n_components=n_components) if method == "pca" else None
def process(self, X):
return self.reducer.fit_transform(X)
# ===== Agent组装器 =====
class ModularDataAgent:
def __init__(self, modules):
self.modules = modules
def preprocess(self, X):
for module in self.modules:
X = module.process(X)
return X
# 使用示例
modules = [
MissingValueHandler(strategy="mean"),
OutlierRemover(contamination=0.05),
FeatureScaler(),
DimensionalityReducer(method="pca", n_components=5)
]
agent = ModularDataAgent(modules)
X_processed = agent.preprocess(X)
特点
- 模块化:每个功能(清洗、标准化、降维)作为独立模块实现。
- 可扩展:未来可轻松加入新的增强模块(如图像增强、特征选择)。
- 动态组合:根据任务需求,自由调整模块顺序或启用/禁用某些功能。
这种设计与实际AI Agent研发趋势一致,为后续的 自适应预处理 奠定了基础。
七、结论
AI Agent在智能感知系统的数据预处理与优化中,既是“清洁工”,也是“优化师”。它不仅能提升数据质量和模型性能,还能通过自适应机制与模块化设计,满足未来多模态、分布式和高可解释性需求。
随着技术的发展,AI Agent将逐步从“预处理助手”演变为“全链路优化决策者”,成为智能感知系统中不可或缺的核心组成部分。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)