LangChain教程——Tavily搜索引擎
在上篇我们学习了,这篇我们学习LangChain教程——Tavily搜索引擎。
在上篇我们学习了LangChain教程——历史消息管理(Memory类),这篇我们学习LangChain教程——Tavily搜索引擎。
Tavily
Tavily是一个专门为大语言模型设计的网络搜索引擎,可以将搜索结果输出为结构化、可解析的形式。
在使用Tavily前,需要在Tavily官网创建账号,创建完成后就会自动获取到每月1000次的搜索额度,如下图所示:
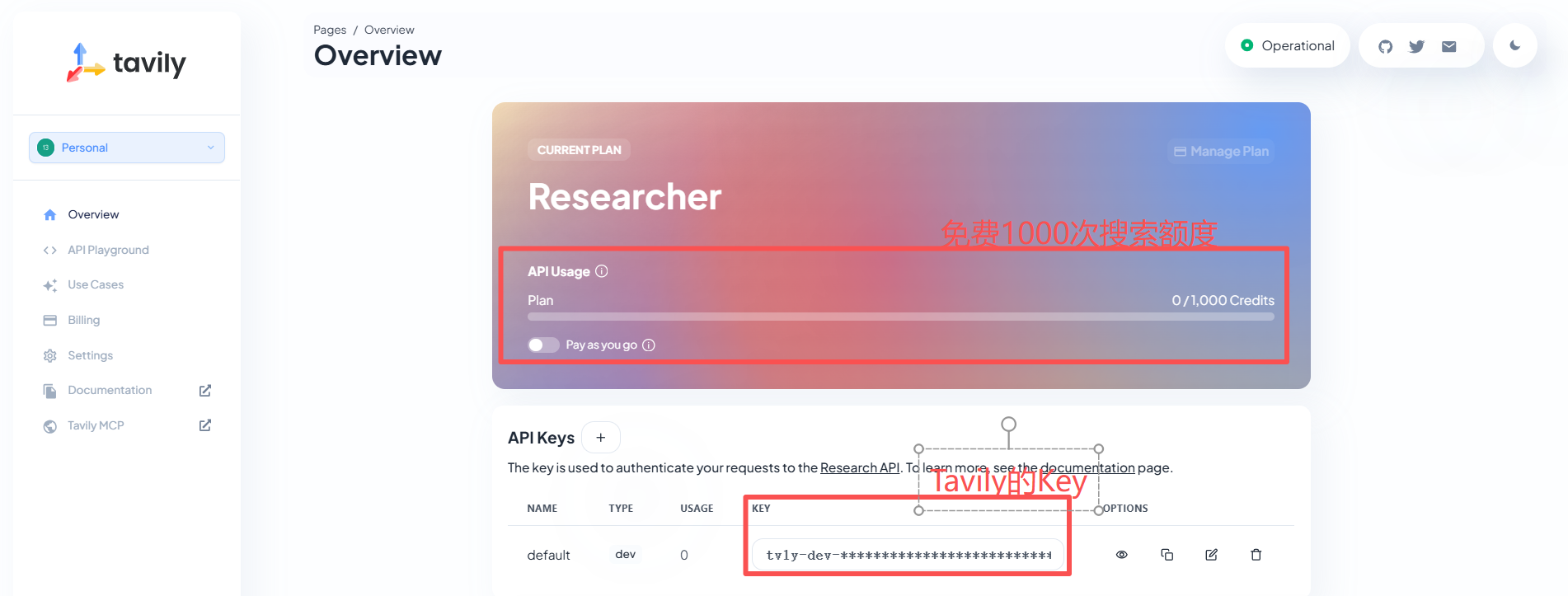
使用
首先执行如下代码安装tavily-python,
pip install tavily-python
tavily常用的方法有:
-
search:从网络中搜索问题内容;
-
extract:从指定url列表中提取和分析网页内容;
search方法
search方法可以从网络中搜索问题相关的内容,示例代码如下:
from tavily import TavilyClient
tavily_client = TavilyClient(api_key="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")
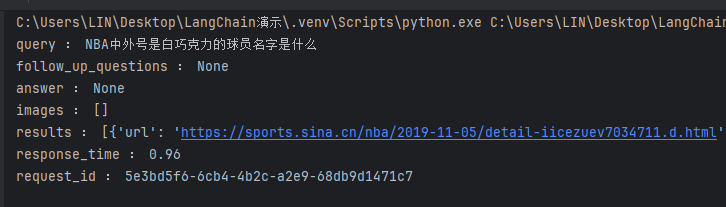
response = tavily_client.search("NBA中外号是白巧克力的球员名字是什么")
for result in response:
print(result, ":", response[result])
运行结果如下:

返回数据字段如下表所示:
| 字段 | 类型 | 描述 |
|---|---|---|
| query | str | 搜索的问题 |
| follow_up_questions | str | 后续的问题 |
| answer | str | LLM生成的对用户查询的简短回答 |
| images | list | 返回的图像列表 |
| results | list | 搜索返回结果,需开启include_sense |
| response_time | float | 完成请求所用时间 |
| request_id | str | 搜索请求ID |
在results中:
| 字段 | 描述 |
|---|---|
| url | 文章链接 |
| title | 文章标题 |
| content | 最相关的内容摘要 |
| score | 相关性得分 |
| raw_content | 原始HTML内容 |
在search方法中,可以添加如下表参数:
| 参数 | 类型 | 描述 | 默认值 | 可选值 |
|---|---|---|---|---|
| query | str | 搜索的内容,必填 | ||
| auto_parameters | bool | 根据查询内容自动配置搜索参数,当 | false | false、true |
| topic | str | 搜索主题 | general | general、news |
| search_depth | str | 搜索深度,basic需要消耗1个api,简单返回通用内容片段,advanced需要消耗2个api,返回最相关的源和内容片段 | basic | basic、advanced |
| chunks_per_source | int | 每个数据源返回相关块的长度,仅当search_depth处于advanced时可用 | 3 | |
| max_results | int | 最大搜索结果数 | 5 | |
| time_range | str | 时间范围,支持 “day”, “week”, “month”, “year”(“d”, “w”, “m”, “y”) | ||
| days | int | 从当前日期(发布日期)算起的天数,当topic=news时使用 | 7 | |
| start_date | str | 将返回指定开始日期(发布日期)后的所有结果。格式:YYYY-MM-DD | ||
| end_date | str | 将返回指定结束日期(发布日期)前的所有结果。格式:YYYY-MM-DD | ||
| include_answer | bool或str | 搜索结果生成的回答,basic或true为简要回答,advanced为详细回答 | false | basic、true、false、advanced |
| include_raw_content | bool或str | 解析的原始HTML内容,markdown或true为Markdown格式,text为纯文本 | false | true、false、markdown、text |
| include_images | bool | 返回与查询相关的图片列表 | false | true、false |
| include_image_descriptions | bool | 返回图片及其自动生成的描述 | false | true、false |
| include_favicon | boolean | 返回每个结果包含favicon的url | false | true、false |
| include_domains | list[str] | 指定包含的域名 | [] | |
| exclude_domains | list[str] | 指定不包含的域名 | [] | |
| country | str | 优先搜索所选国家的内容,当topic=general时使用 |
extract方法
extract从指定url列表中提取和分析网页内容,示例代码如下:
from tavily import TavilyClient
# 初始化客户端
tavily_client = TavilyClient("tvily的key")
# 执行提取请求
result = tavily_client.extract(
urls=["https://sports.sina.cn/nba/2019-11-05/detail-iicezuev7034711.d.html"],
include_images=False
)
for i in result:
print(i, ":", result[i])
运行结果如下:

langchain_tavily
langchain_tavily库封装Tavily为LangChain工具,让LangChain获得强大的网络搜索能力和内容提取能力。
注意:上面的tavily请求参数同样适用langchain_tavily。
langchain_tavily主要提供两大工具:
-
TavilySearch:实时网络搜索;
-
TavilyExtract:从指定一个或多个URL中提取和分析网页内容;
在使用前执行如下代码安装langchain_tavily:
pip install langchain_tavily
TavilySearch
TavilySearch在网络中搜索并返回结构化结果,其语法格式如下:
TavilySearch(
tavily_api_key # tavily的key
)
示例代码如下:
from langchain_tavily import TavilySearch
# 初始化搜索工具,可配置参数
tool = TavilySearch(
max_results=1, # 最大结果数,默认5
topic="general", # 搜索主题:general, news, finance
search_depth="basic", # 搜索深度:basic 或 advanced
tavily_api_key='tavily的key'
)
# 执行搜索
result = tool.invoke("NBA中外号是白巧克力的球员名字是什么")
for i in result:
print(i, ":", result[i])
运行结果如下:
TavilyExtract
TavilyExtract可以从指定一个或多个URL中提取和分析网页内容,其语法格式如下:
extract_tool = TavilyExtract(
tavily_api_key
)
extract_tool.invoke(
{
"urls":[ url列表 ]
}
)
示例代码如下:
from langchain_tavily import TavilyExtract
# 初始化提取工具
extract_tool = TavilyExtract(
extract_depth="basic", # 提取深度:basic 或 advanced
include_images=False, # 是否包含图片
tavily_api_key='tavily的key'
)
# 提取网页内容
result = extract_tool.invoke({"urls": ["https://sports.sina.cn/nba/2019-11-05/detail-iicezuev7034711.d.html"]})
for i in result:
print(i, ":", result[i])
运行结果如下:

好了,LangChain教程——Tavily搜索引擎就讲到这里了。
公众号:白巧克力LIN
该公众号发布Java、Python、数据库、Linux、Flask、Django、自动化测试、Git、算法、前端、服务器、AI等相关文章!
-
END -

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 4
4 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)