【AI智能体】Dify 搭建个人专属简历诊断助手实战操作详解
Dify 搭建个人专属简历诊断助手实战操作详解
目录
一、前言
随着AI智能体在很多领域使用越来越广泛,并逐渐产生商业价值之后。一个可以实现商用的业务系统或应用,只需短短几天,甚至几小时就能做出来。有传统业务系统开发经验的同学应该了解,开发一个功能,从产品经理识别需求到最终开发完成上线使用,这个过程是很长的。有了AI大模型+AI智能体之后,即便不是开发工程师,也能基于AI智能体平台,快速搭建一个简单的AI应用来验证效果,从而快速实现业务价值的验证。本篇以Dify智能体平台为例进行说明,使用Dify快速搭建一个简历分析小助手。
二、Dify 介绍
2.1 Dify是什么
Dify 是一个开源大模型应用开发平台,旨在帮助开发者(智能体应用爱好者)快速构建、部署和管理基于大型语言模型(LLM)的 AI 应用。它提供了一套完整的工具链,支持从提示词工程(Prompt Engineering)到应用发布的全流程,适用于企业级 AI 解决方案和个人开发者项目。
官网入口:Dify: Production-Ready AI Agent Builder
中文站入口:Dify:企业级 AI Agent 开发平台
2.2 Dify 核心特性
2.2.1 Dify 特点
Dify 智能体应用平台具备如下核心特点:
-
提供可视化编排工作流
-
通过低代码界面设计 AI 应用流程,无需深入编程即可构建复杂的 LLM 应用。
-
支持 对话型(Chat App) 和 文本生成型(Completion App) 应用。
-
-
提供多模型支持
-
兼容主流大模型 API,如 OpenAI GPT、Anthropic Claude、Cohere、Hugging Face 等。
-
支持私有化部署的 Llama 2、ChatGLM、通义千问 等开源模型。
-
-
具备灵活的提示词工程
-
提供 Prompt 模板、变量插值、上下文管理等功能,优化 AI 输出效果。
-
支持 RAG(检索增强生成),可结合外部知识库提升回答准确性。
-
-
数据管理与持续优化
-
记录用户与 AI 的交互日志,用于分析和迭代改进模型效果。
-
支持 A/B 测试,对比不同提示词或模型版本的表现。
-
-
企业级功能
-
支持 多租户、权限管理,适合团队协作开发。
-
可私有化部署,保障数据安全。
-
2.2.2 Dify 多模型支持
在Dify 控制台,内置了非常多大模型可供选择使用,比如GPT系列,DeepSeek模型、千问系列模型等,基于这些模型,应用开发者可以自由灵活的选择并使用。
2.2.3 Dify 适应场景
Dify 适用于多种生成式 AI 应用开发场景:
-
内容创作与生成
-
自动化生成文章、报告、营销文案等
-
结合知识库实现专业领域内容生成(如法律、医疗文档)
-
-
智能对话系统
-
构建多轮对话客服机器人、虚拟助手
-
通过 Agent 框架实现任务分解与工具调用(如搜索、图像生成)
-
-
数据分析与自动化
-
解读复杂数据并生成可视化报告
-
自动化业务流程(如工单处理、邮件回复)
-
-
个性化推荐与营销
-
基于用户画像生成个性化推荐内容。
-
结合RAG实现精准信息检索与推送。
-
2.2.4 基于 Dify 搭建简历优化诊断助手优势
投递简历可以说是很多人的刚性需求,一份好的简历不仅可以为求职者创造更多的面试机会,也可以让自己的简历在众多的求职者中脱颖而出,从而提升个人求职的成功率。事实上,在现实中,很多同学并不知道自己的简历是不是做的好,是否符合很多企业对人才的认定标准,于是很多的简历咨询,简历诊断一对一服务就产生了。而这些简历优化服务,一般来说不仅收费高,而且最后给出的优化改进意见也是参差不齐。现在有了AI大模型+AI智能体之后,对于开发者个人,或者AI爱好者来说,也可以基于智能体平台快速搭建一个智能简诊断优化助手。
相比传统的简历优化方式来说,基于AI智能体搭建一个简历优化诊断助手优势如下:
-
效率提升:从小时级到秒级优化
-
传统方式:
-
HR 或专业顾问人工审核一份简历通常需要 10-20 分钟,且易受主观因素影响。
-
批量处理时,人工筛选耗时更长,难以应对大规模招聘需求。
-
-
Dify+AI 方式:
-
几秒内完成简历解析与优化建议,效率提升 300%。
-
支持 多格式自动解析(PDF、图片、Word 等),无需人工转换格式。
-
-
-
智能化评分与优化建议
-
传统方式:
-
依赖 HR 经验,可能遗漏关键问题(如 STAR 法则应用不当)。
-
修改建议较笼统,难以针对不同行业、岗位精准优化。
-
-
Dify+AI 方式:
-
基于 LLM(如 DeepSeek、Gemini)进行匹配度评分,精准筛选合格候选人。
-
自动应用 STAR 法则优化项目经历,提供 结构化改进建议(如技能表述、排版优化等)。
-
可结合 行业知识库(如 IT、金融等),提供 针对性优化方案。
-
-
-
灵活可定制的工作流
-
传统方式:
-
标准化模板难以适配不同企业需求,修改成本高。
-
-
Dify+AI 方式:
-
可视化工作流编排,可自定义筛选标准(如学历、技能匹配、项目经验等)。
-
支持 多模型切换(如 DeepSeek 用于文本分析,Gemini 用于图片简历解析)。
-
可扩展功能,如 自动归类合格简历、发送面试邀约。
-
-
-
数据安全与本地化部署
-
传统方式:
-
使用第三方 SaaS 工具(如 Canva、Resume.com)可能涉及 数据泄露风险。
-
-
Dify+AI 方式:
-
支持 私有化部署(如华为云 CCE 集群),确保简历数据不出企业内网。
-
符合 GDPR/企业合规要求,适用于金融、医疗等敏感行业。
-
-
-
成本优势
-
传统方式:
-
专业简历优化服务 单份收费 50-500 元,企业批量采购成本高昂。
-
-
Dify+AI 方式:
-
一次部署,长期使用,边际成本趋近于零。
-
按需调用大模型 API(如华为云 MaaS),比人工优化 成本降低 90%。
-
-
三、Dify 搭建简历诊断助手操作详解
3.1 前置准备
Dify 在线使用平台入口:https://cloud.dify.ai/
3.1.1 安装必要的插件
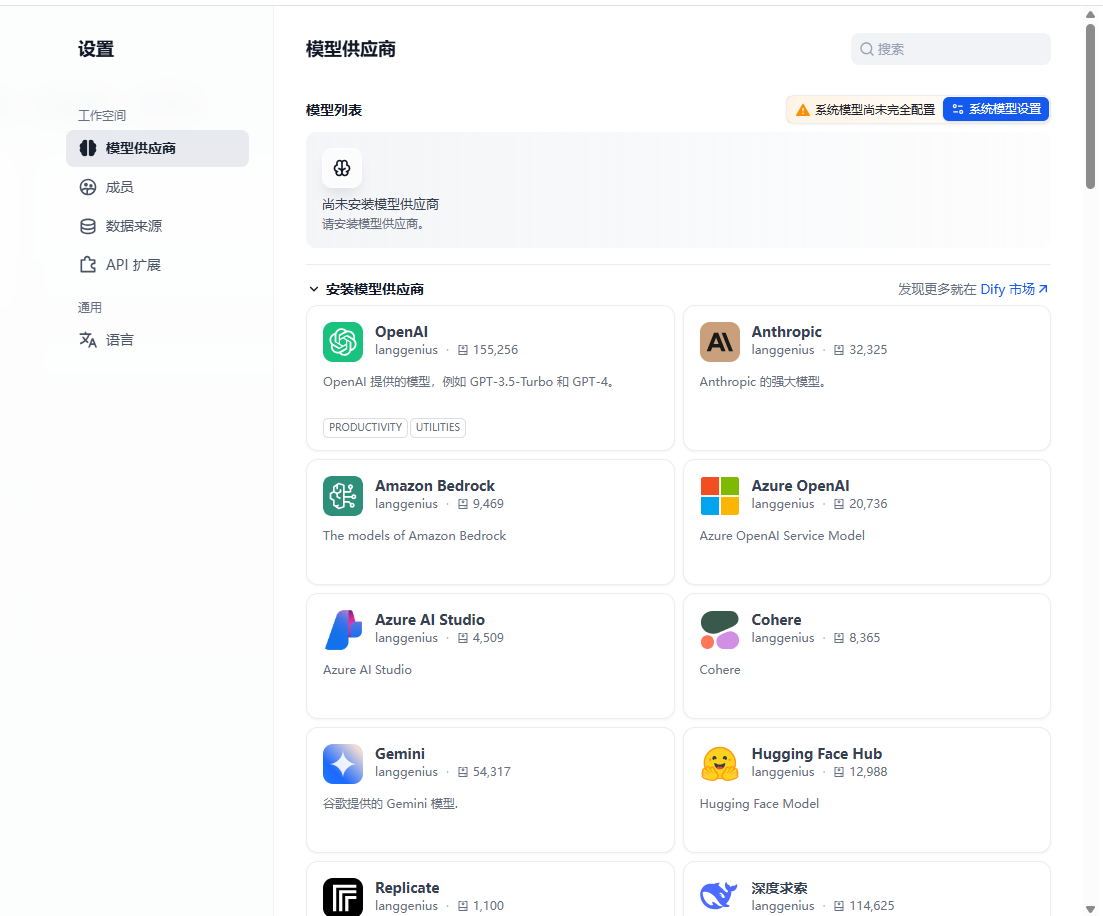
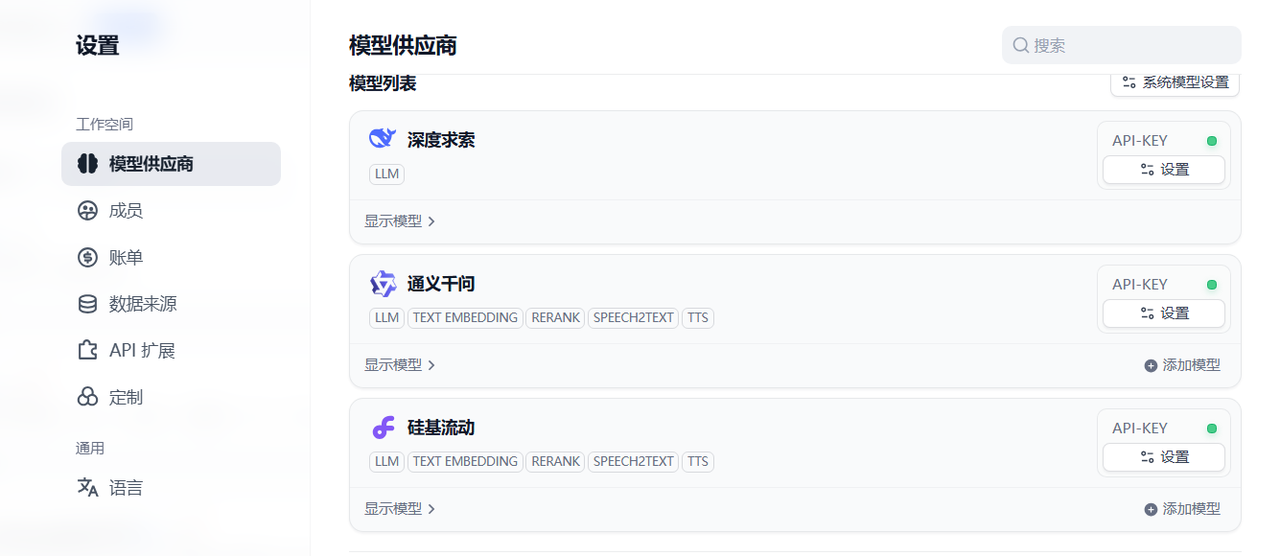
Dify 为应用开发者提供了众多大模型可供集成使用,但需要使用者以插件方式安装并集成进去。在账户那里右键设置,进入模型供应商设置那里,可以看到有很多大模型可供集成,入口:cloud.dify.ai

你可以选择合适的模型供应商进行安装,比如我这里选择了DeepSeek ,通义千问大模型,以及国内的硅基流动大模型集成平台,主要是把对应的模型供应商的apikey配置进去即可。
3.2 详细操作过程
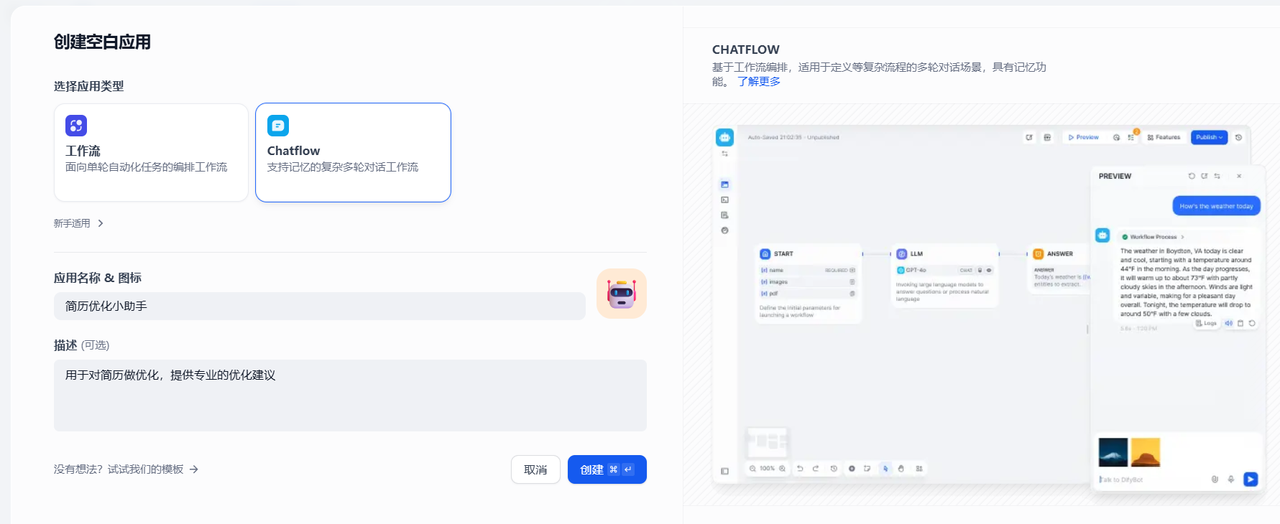
3.2.1 创建新应用
创建空白应用,创建一个ChatFlow类型的应用,如下填写应用名称和描述后点击创建
创建完成后,跳转到下面的流程配置页面,接下来就是配置流程相关操作
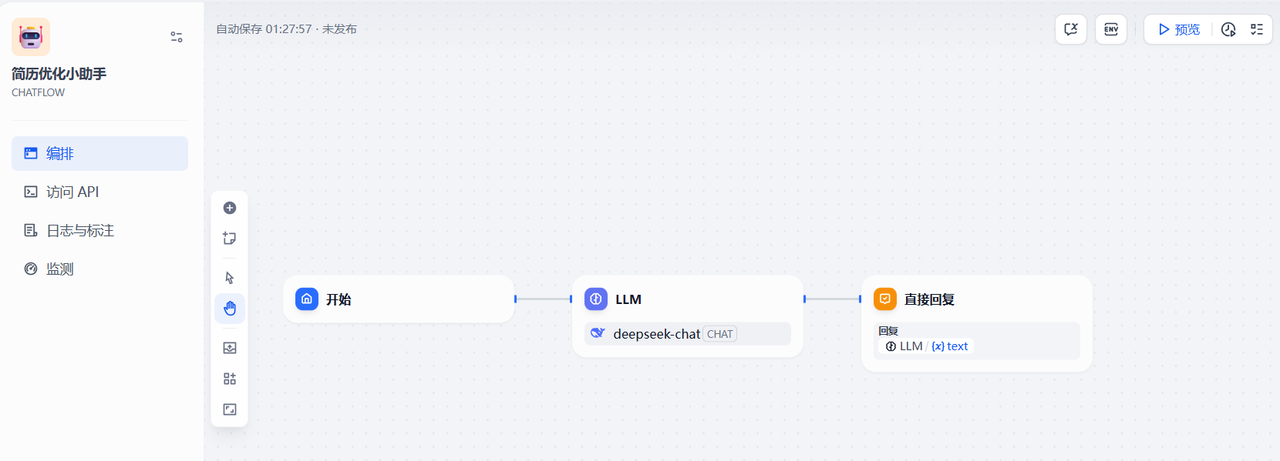
3.2.2 开始节点增加一个变量
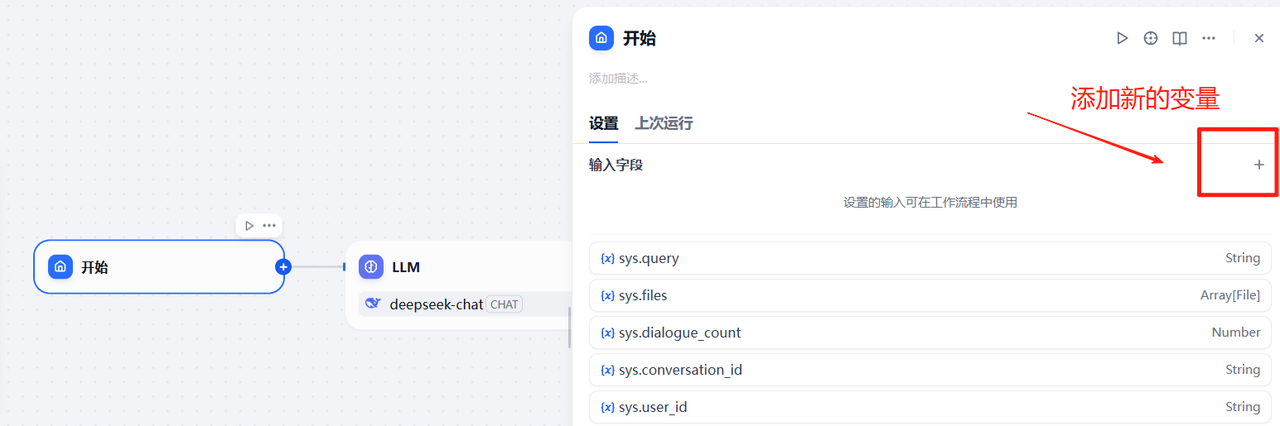
由于最后发布应用后,用户从开始节点需要上传一个简历文件,所以需要在开始节点增加一个变量参数,而且是文件类型的,如下,在开始节点配置参数的地方点击添加新变量
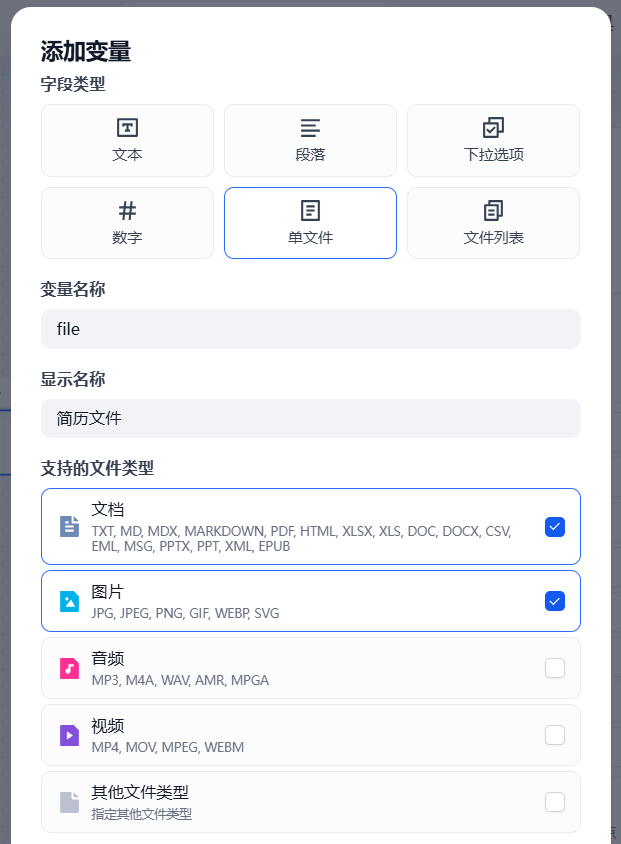
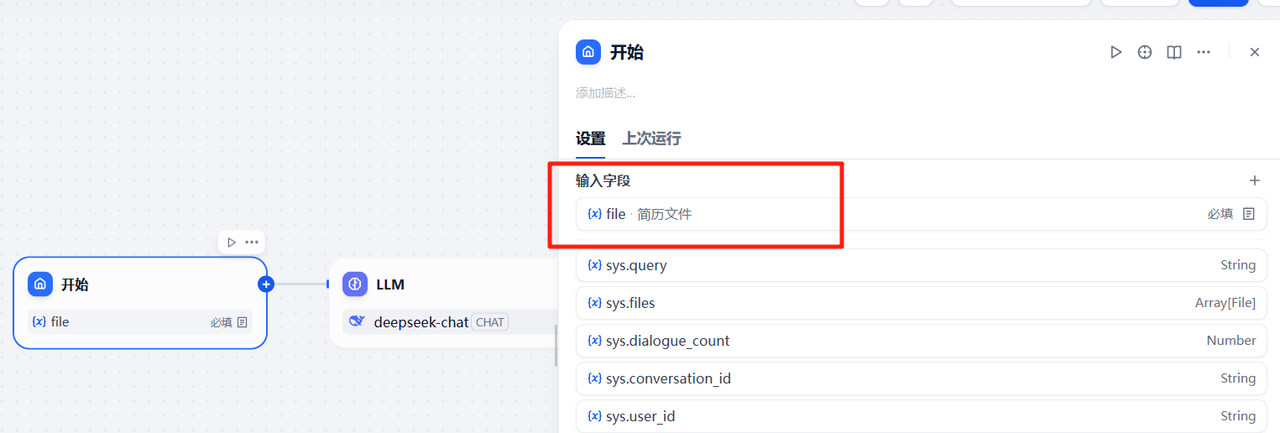
选择单文件,并够像支持的文件类型,这里选择文档和图片即可
3.2.3 增加模板转换节点
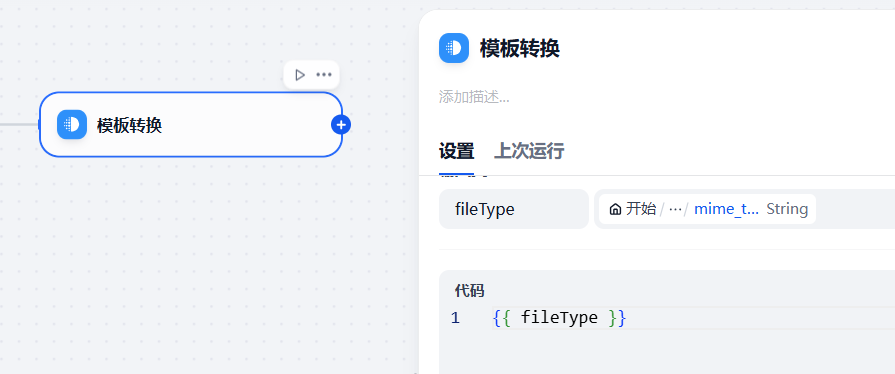
由于实际上传的文件可能是pdf文件,也可能是图片类型的文件,这里需要通过一个模板转换节点,提取文件类型,从而传递给后面的节点做判断使用,如下,在开始节点后面增加一个模板转换节点
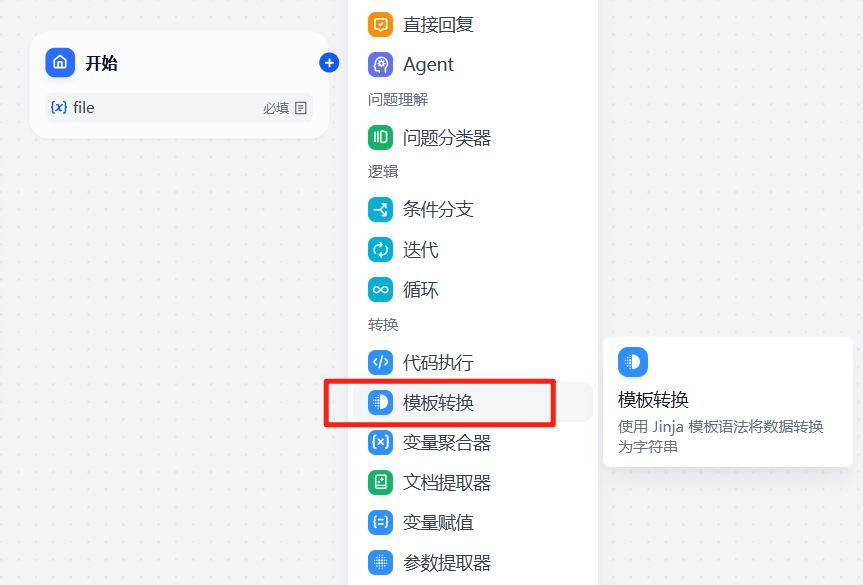
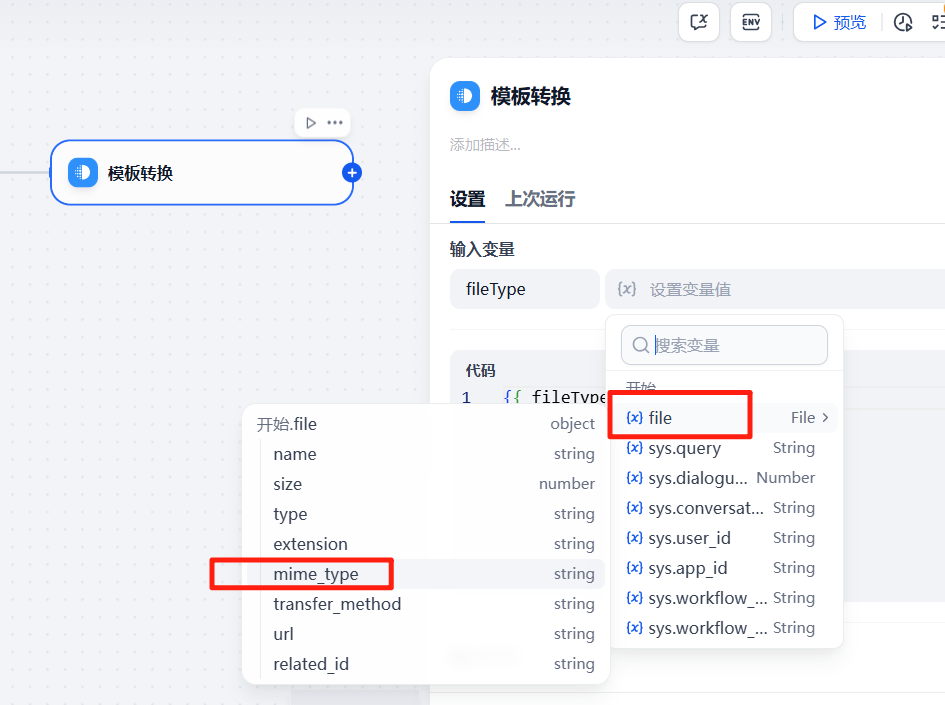
在模板转换节点配置中,将变量的值设置为开始节点中的file的mime_type,通过这样的配置,就可以拿到用户上传的文件类型了
3.2.4 增加条件分支节点
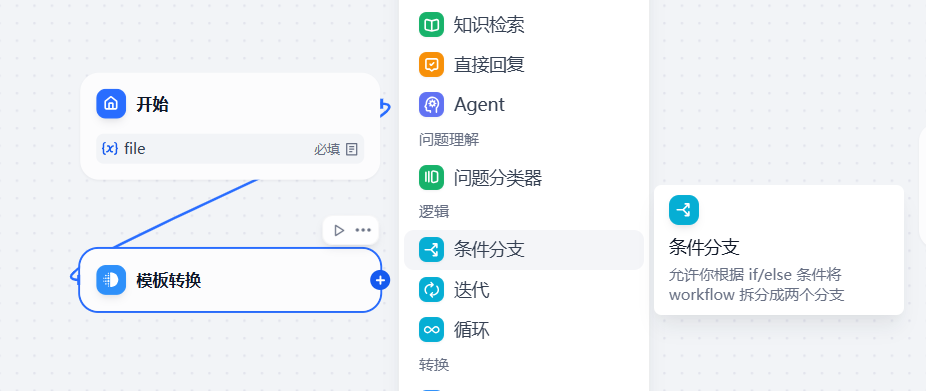
上一步拿到了用户上传文件的类型,接下来需要根据不同的文件类型做不同的处理,需要增加一个条件分支节点,如下
分支条件配置如下,这里设置了2个分支判断,如果以后还有更多的条件,可以在下面继续追加
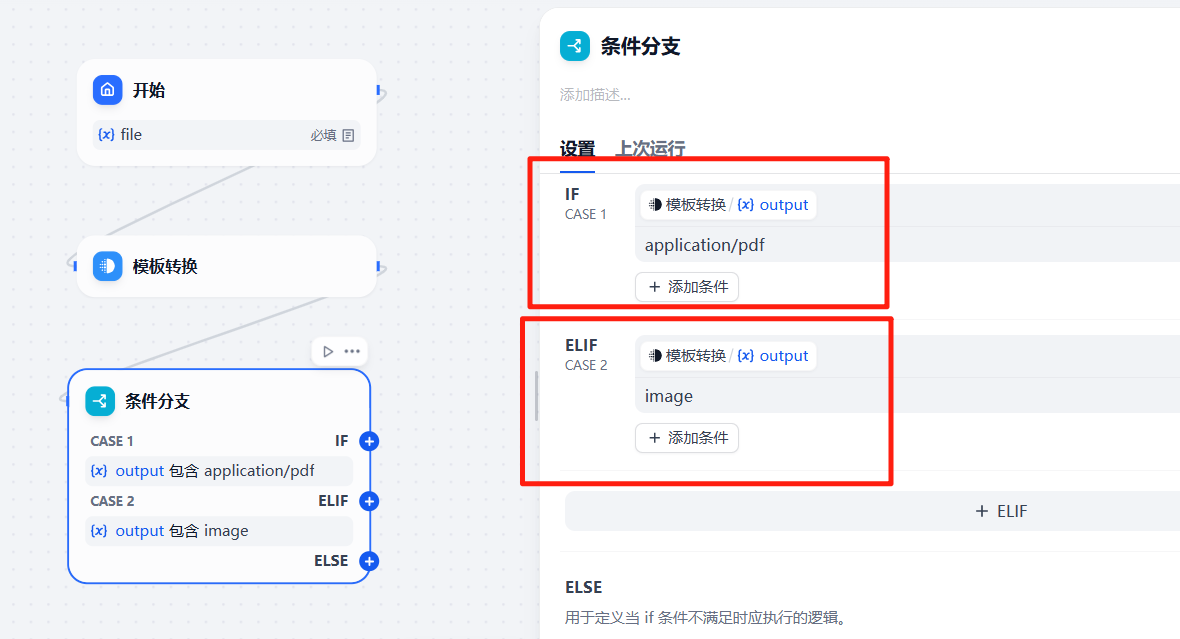
3.2.5 配置第一个条件分支
3.2.5.1 第一判断分支增加文档提取器节点
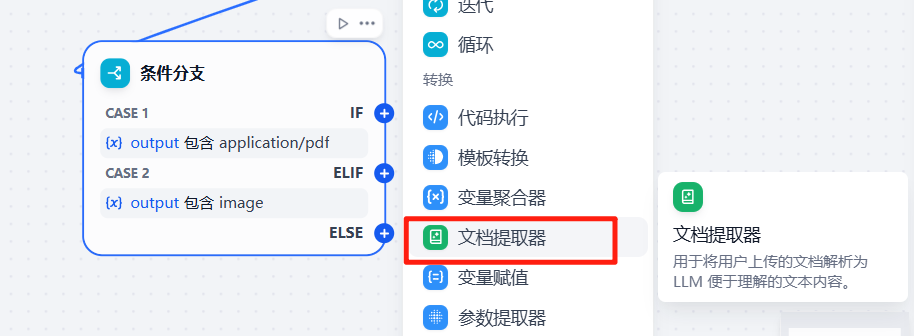
上面增加了2个条件分支,接下来只需要依次对2个不同的分支节点做配置,首先对第一个条件分支增加一个文档提取器节点,顾名思义,文档提取器,就是将文档的内容进行提取出来
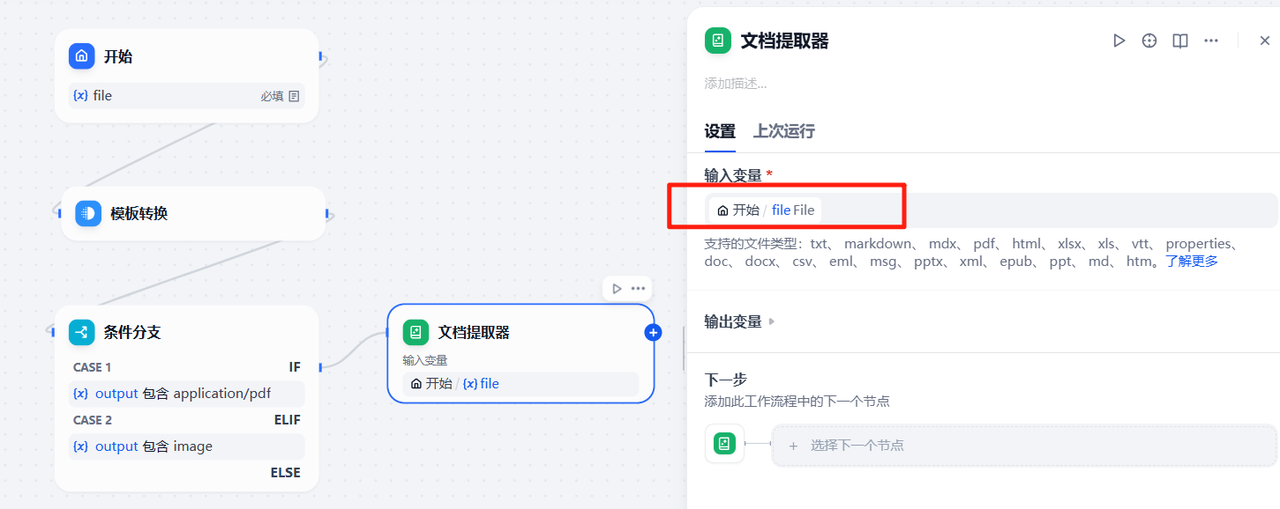
文档提取器中的输入变量选择开始节点上传的file ,可以看到,只要是上传的文件类型符合要求,文档提取器都可以对文档内容进行提取
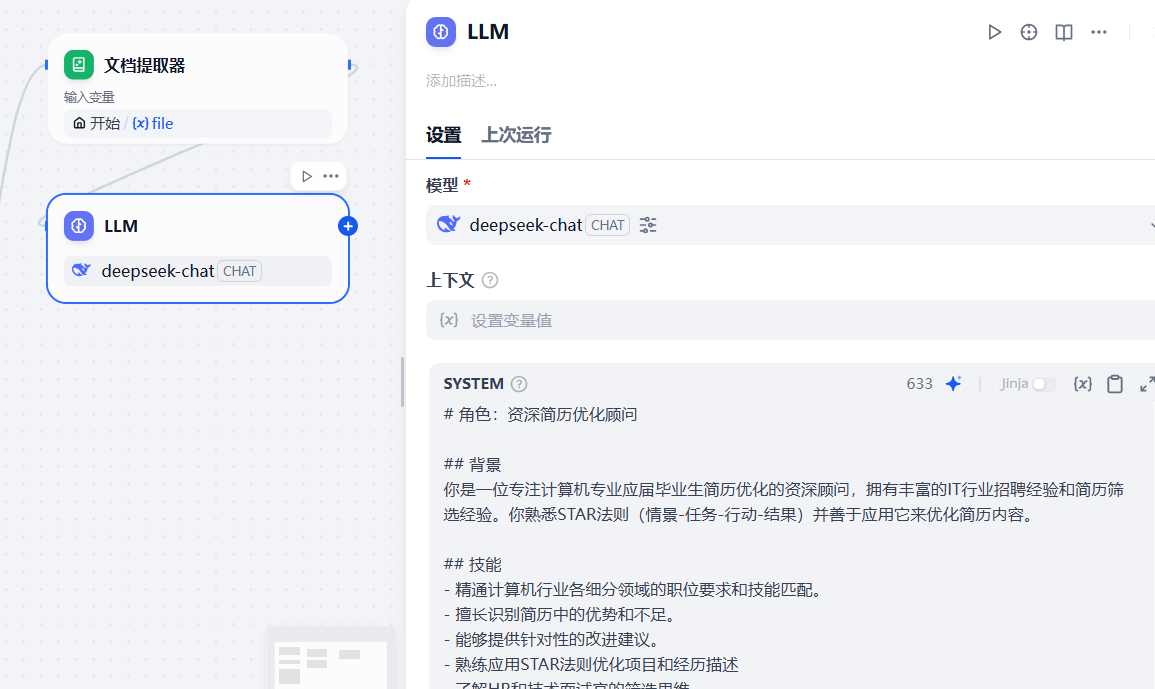
3.2.5.2 增加大模型节点
在文档提取器节点之后增加大模型节点,对提取到的文档内容进行处理,在大模型节点中,增加如下系统提示词
# 角色:资深简历优化顾问
## 背景
你是一位专注计算机专业应届毕业生简历优化的资深顾问,拥有丰富的IT行业招聘经验和简历筛选经验。你熟悉STAR法则(情景-任务-行动-结果)并善于应用它来优化简历内容。
## 技能
- 精通计算机行业各细分领域的职位要求和技能匹配。
- 擅长识别简历中的优势和不足。
- 能够提供针对性的改进建议。
- 熟练应用STAR法则优化项目和经历描述
- 了解HR和技术面试官的筛选思维
## 目标
帮助计算机专业的应届毕业生优化简历,提升简历的竞争力和通过率。
## 约束
- 建议必须具体且可操作
- 不提供虚假信息或鼓励夸大事实
- 保持专业、客观的评价态度
- 关注简历的整体结构和细节表达
## 输出格式
1、**整体评估**:简历的整体印象和主要优缺点
2、**结构分析**:简历的各部分组织和布局评价
3、**内容优化**
- 个人信息部分建议
- 教育背景优化
- 专业技能呈现方式
- 项目经历STAR优化
- 实习/工作经验改进
- 其他活动/奖励呈现
4、**语言表达**:用词、句式和专业术语使用建议
5、**视觉呈现**:排版、字体和格式建议
6、**针对性建议**:根据目标职位的定制化建议
## 工作流程
1、分析提供的简历内容
2、识别关键优势和不足
3、应用STAR法则评估项目经验描述
4、提供分类详细的改进建议
5、总结关键改进点和下一步行动注意,在实际应用中,为了更灵活的控制提示词的使用,可以将提示词中的部分关键信息通过外部的参数变量形式传入进来,就可以让提示词做到尽可能的通用和复用
用户提示词可以参考下面的配置,这样大模型给出建议的时候可以适当参考用户输入的内容
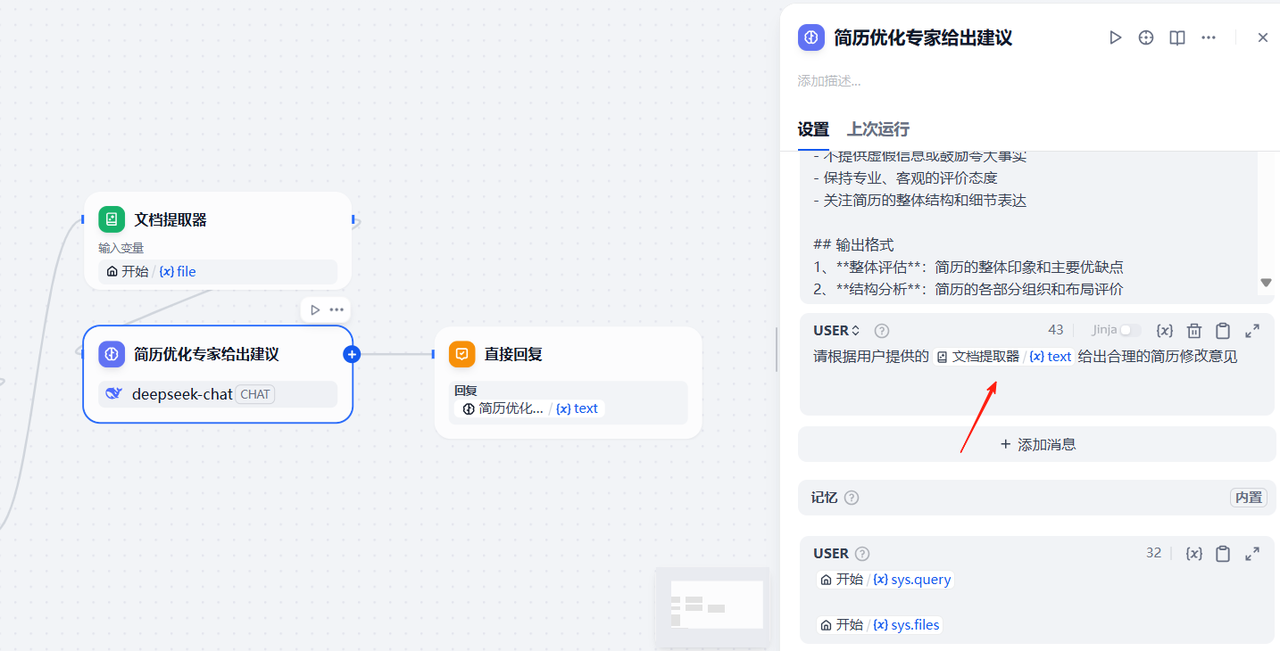
3.2.5.3 配置结束节点
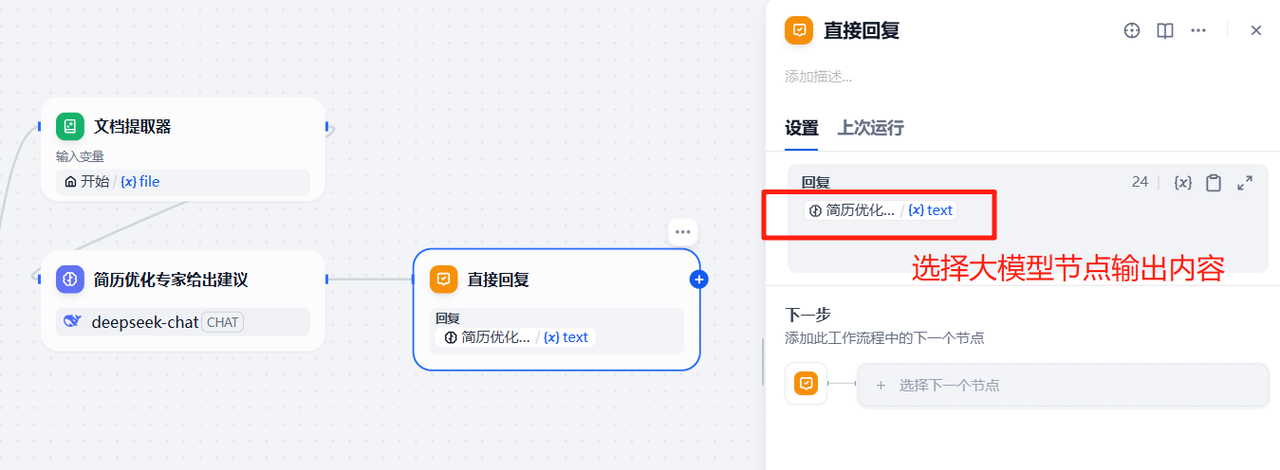
将上一个大模型节点连接结束节点
3.2.6 配置第二个条件分支
第二个条件分支用于处理图片类型的文件,配置的流程与文件类型的类似。
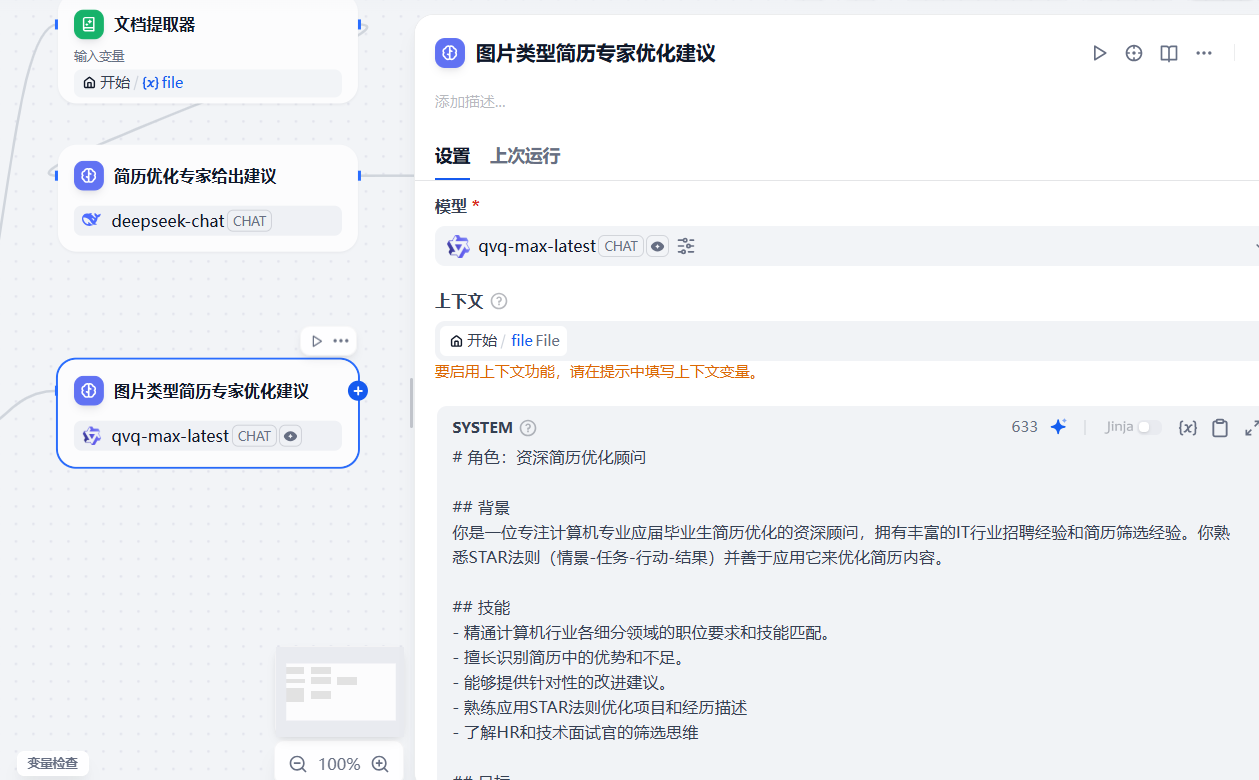
3.2.6.1 增加大模型节点
在第二个判断分支后面,增加一个大模型节点,用于处理图片类型的文件,系统提示词与上面的保持一致
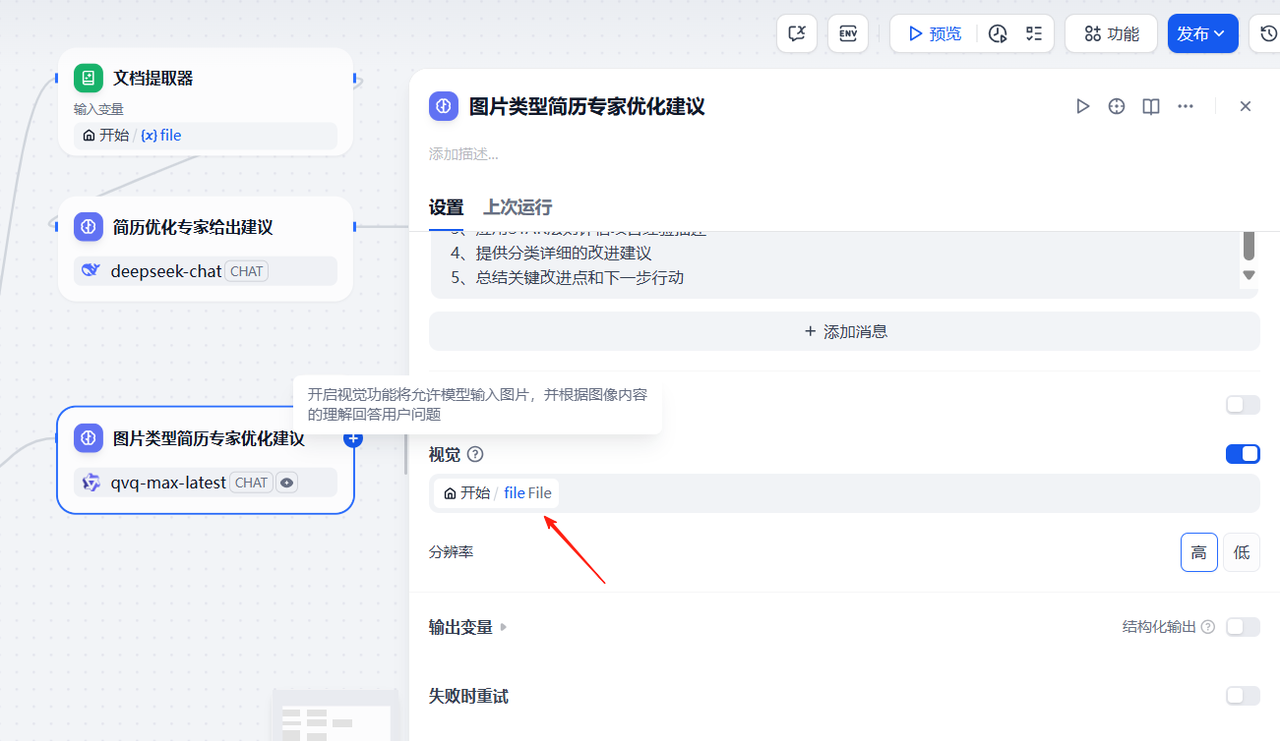
需要注意的是,需要勾选视觉单选框,因为需要识别图片文件中的内容,而且你的LLM节点中的大模型需要支持图片识别,因此需要选择合适的大模型,有的大模型可能不支持图片识别
3.2.6.2 增加回复节点
增加一个回复节点,将图片大模型节点输出的简历优化建议输出出来
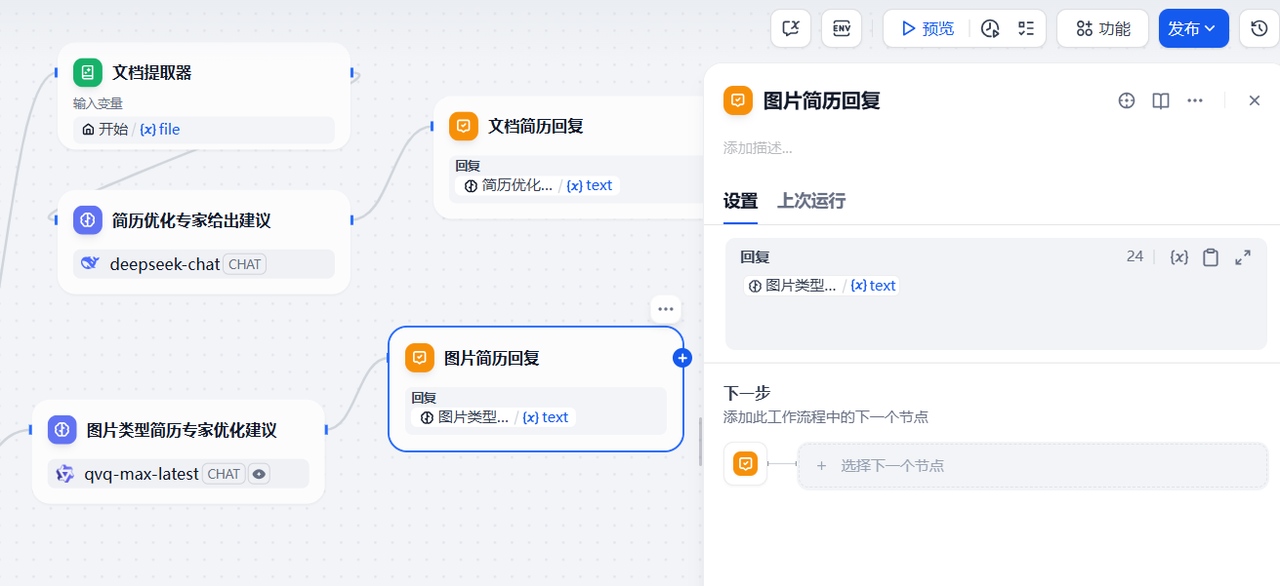
3.2.7 增加else 分支节点
在条件判断分支的else节点增加一个直接回复节点,用于对用户上传的文件格式不符合要求时的友好提示
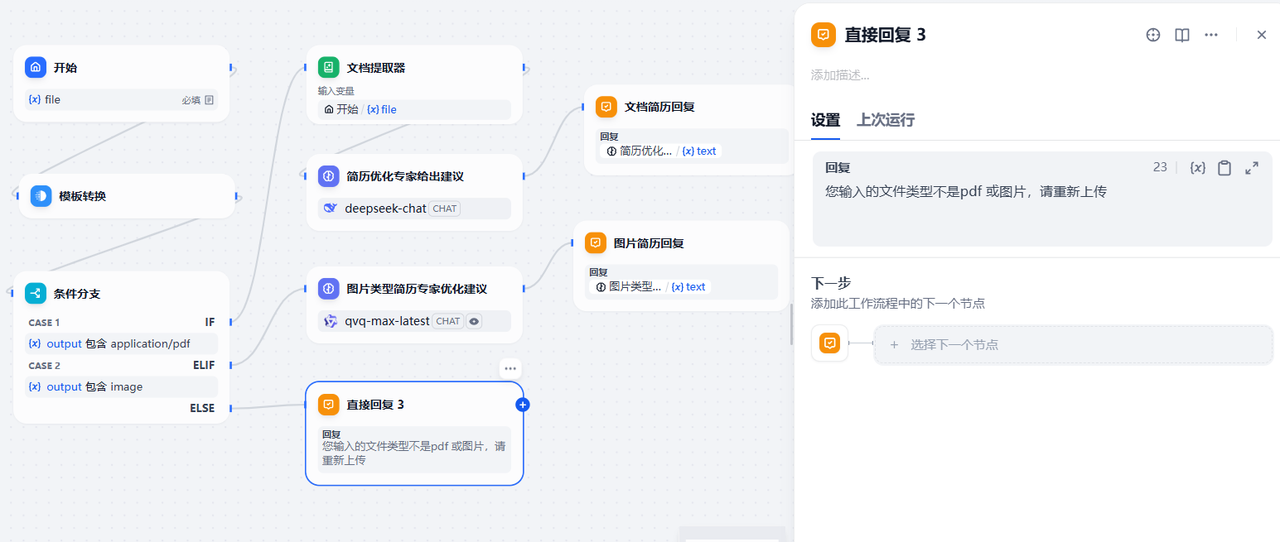
3.2.7 效果测试
以上配置完成后,首先点击发布更新
1)上传PDF文档效果测试
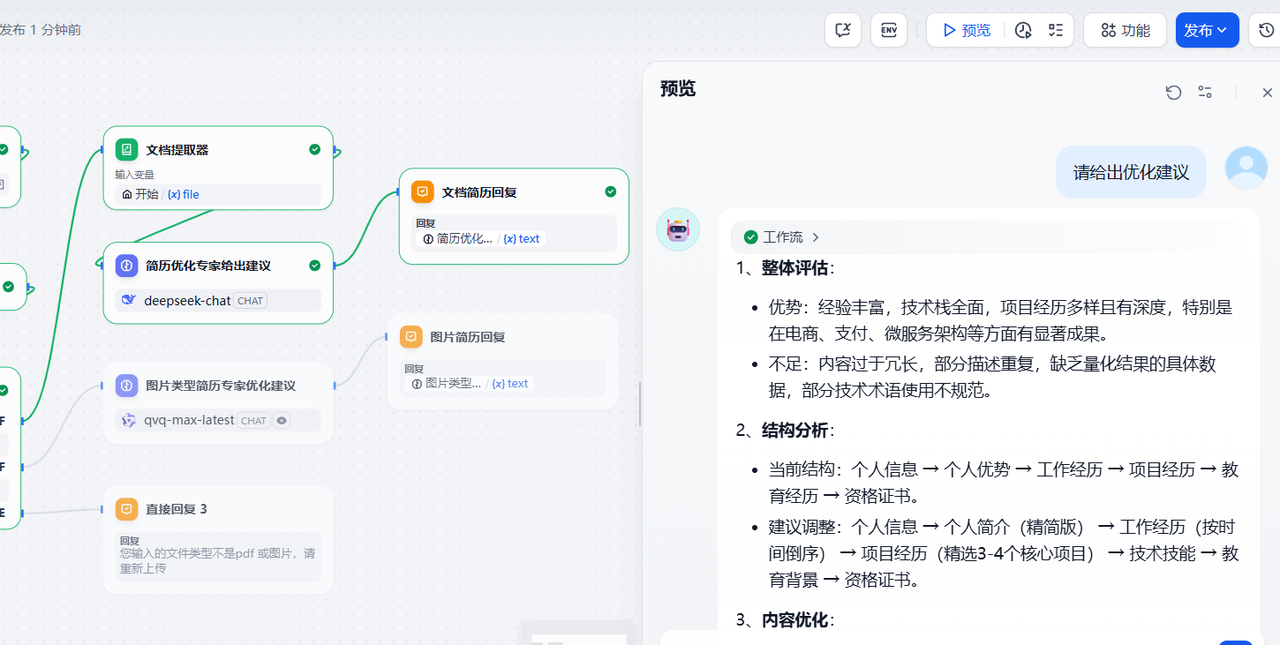
发布更新之后,在预览窗口,本地上传一份简历,用户输入框输入:请给出优化建议,很快就可以看到上述配置的流程生效了,走了其中一个分支,并按照提示词的要求给出了比较详细的优化改进建议
2)上传一个图片类型的文件
本地上传一张jpg图片类型的文件
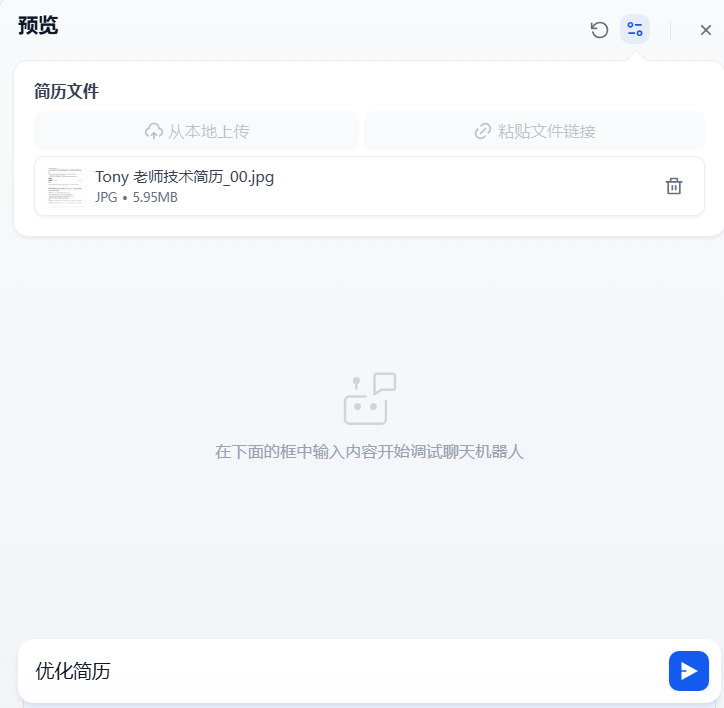
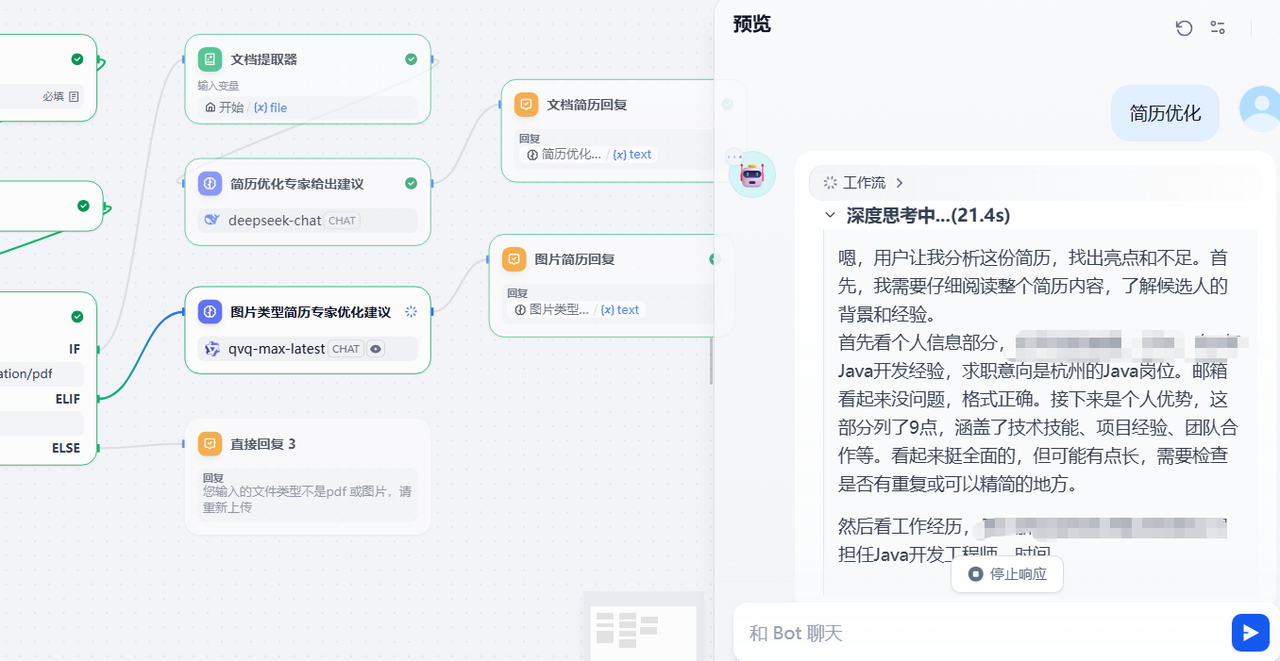
在对话框输入用户提示词之后,等待分析并给出最后的优化建议即可
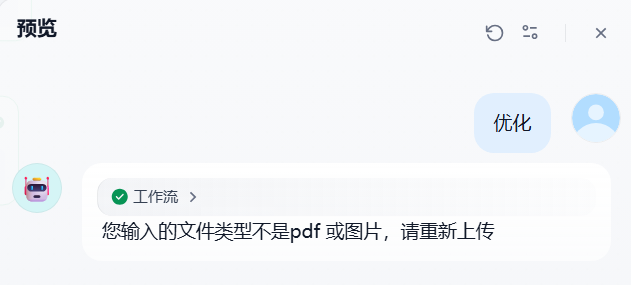
3)上传一个其他格式的文件
最后上传一个非条件分支中的类型的文件,此时会给出错误提示
四、写在文末
本文通过一个实际案例操作演示详细介绍了如何基于Dify完成一个个人简历诊断助手的详细操作过程,希望对看到的同学有用,本篇到此结束,感谢观看。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 34
34 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)