请求localhost不是请求127.0.0.1地址,真相竟是这样
问题背景某平台的组件,在创建流水线时,一直报错,日志显示请求一个地址连接失败。在平台流水线创建有关的组件日志里面,发现相同的错误。E1125 09:43:30.8616811 reflector.go:125] pkg/mod/k8s.io/client-go@v0.0.0-20200228043304-076fbc5c36a7/tools/cache/reflector.go:98: Fail
问题背景
某平台的组件,在创建流水线时,一直报错,日志显示请求一个地址连接失败。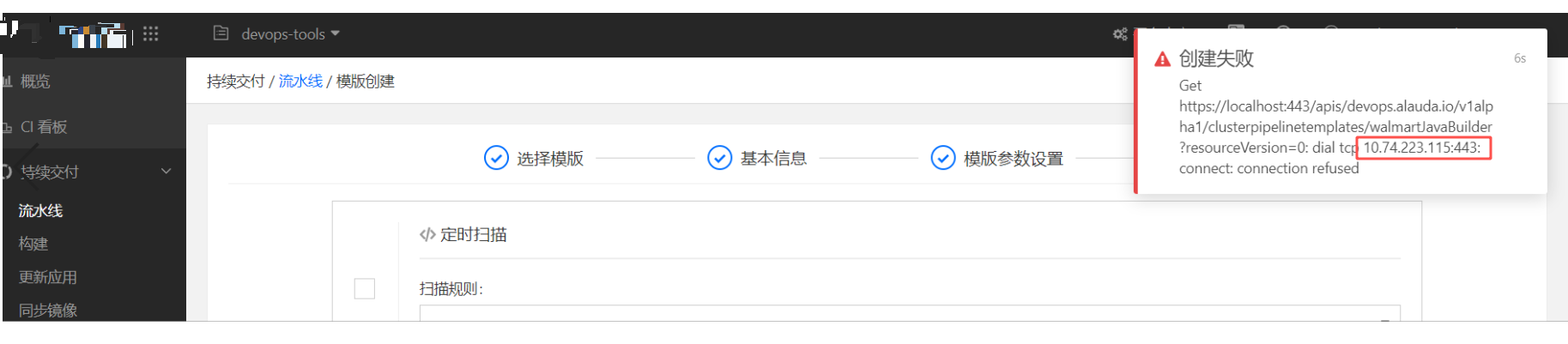
在平台流水线创建有关的组件日志里面,发现相同的错误。
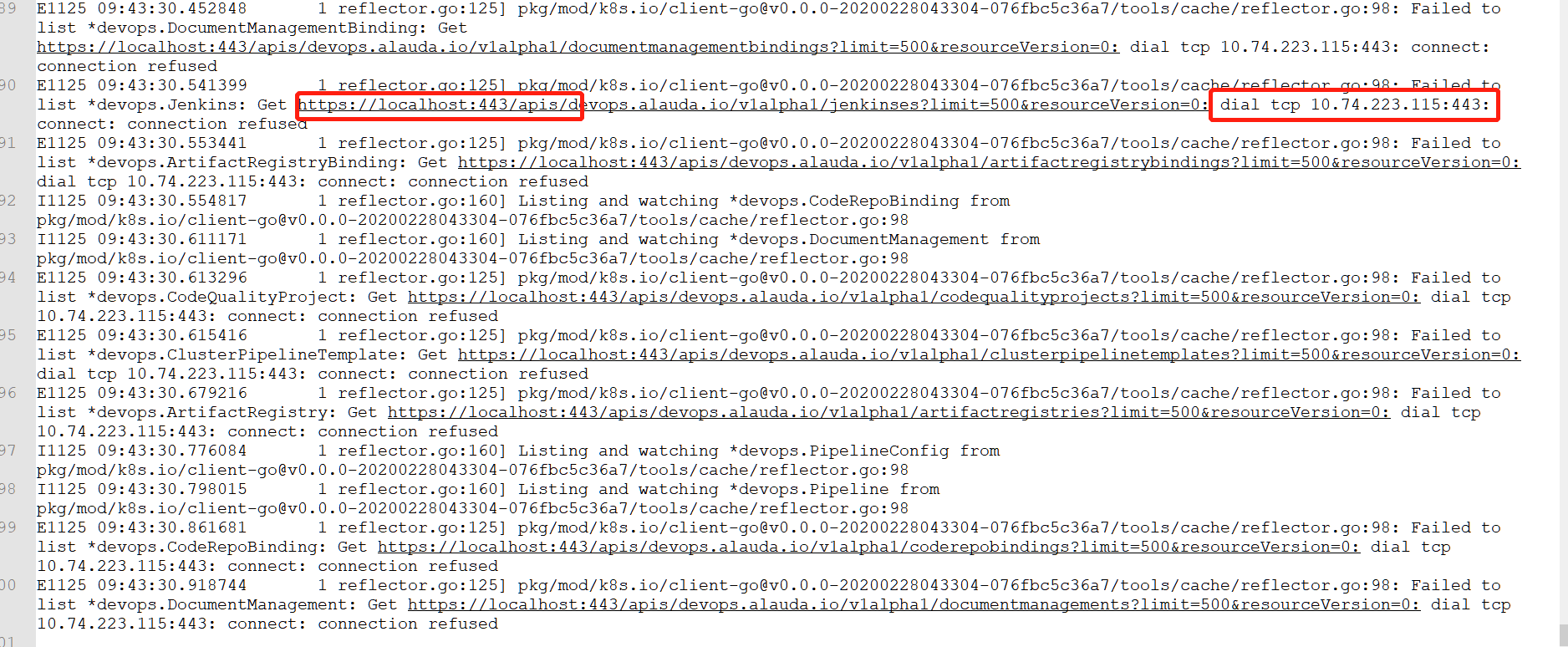
E1125 09:43:30.861681 1 reflector.go:125] pkg/mod/k8s.io/client-go@v0.0.0-20200228043304-076fbc5c36a7/tools/cache/reflector.go:98: Failed to list *devops.CodeRepoBinding: Get https://localhost:443/apis/devops.alauda.io/v1alpha1/coderepobindings?limit=500&resourceVersion=0: dial tcp 10.74.223.115:443: connect: connection refused
E1125 09:43:30.918744 1 reflector.go:125] pkg/mod/k8s.io/client-go@v0.0.0-20200228043304-076fbc5c36a7/tools/cache/reflector.go:98: Failed to list *devops.DocumentManagement: Get https://localhost:443/apis/devops.alauda.io/v1alpha1/documentmanagements?limit=500&resourceVersion=0: dial tcp 10.74.223.115:443: connect: connection refused
排查
-
从上面日志输出,很明显是程序去请求了10.74.223.115这个地址的443端口,但是连接失败。初始判断是程序本身配置错误引起,于是检查该组件的configmap信息,grep过滤这个IP地址,一无所获。在检查组件所在的k8s集群的service的IP信息,endpoint信息,secret信息等,都没有发现任何信息和这个IP地址关联。
-
根据日志记录,exec到此组件的pod里面,curl https://localhost:443/apis/,也是正常有返回结果。产研反馈创建流水线的代码逻辑,就是请求localhost的443地址。让该组件的研发,在源代码层面查找这个IP信息,也是没有结果,排查一时没有头绪了。
-
没有思路情况下,因为是个内网地址,k8s集群层面没有地址记录,于是反查这个IP是不是客户环境的。通过在本地
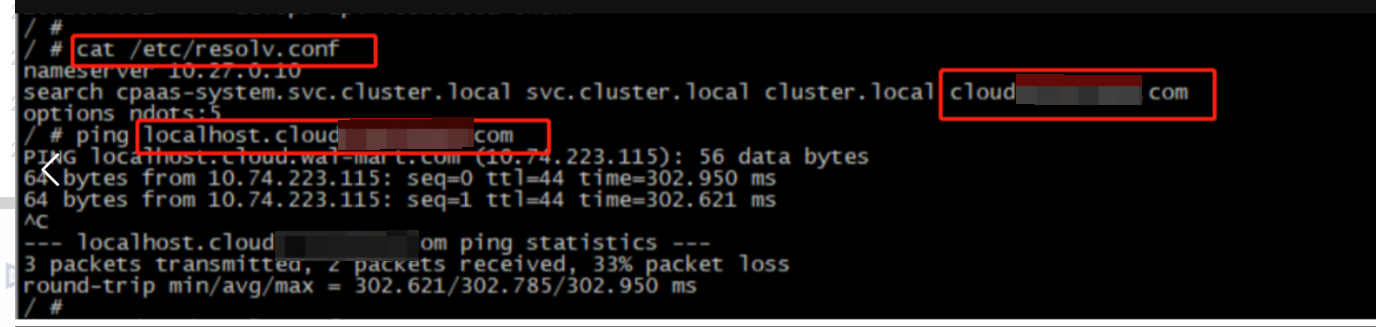
ping -a 10.74.223.115,发现了一些端倪。如下图,10.74.223.115,是有域名解析的,解析地址为localhost.cloud.xxx.com的地址,域名也有个localhost,貌似有点关联性。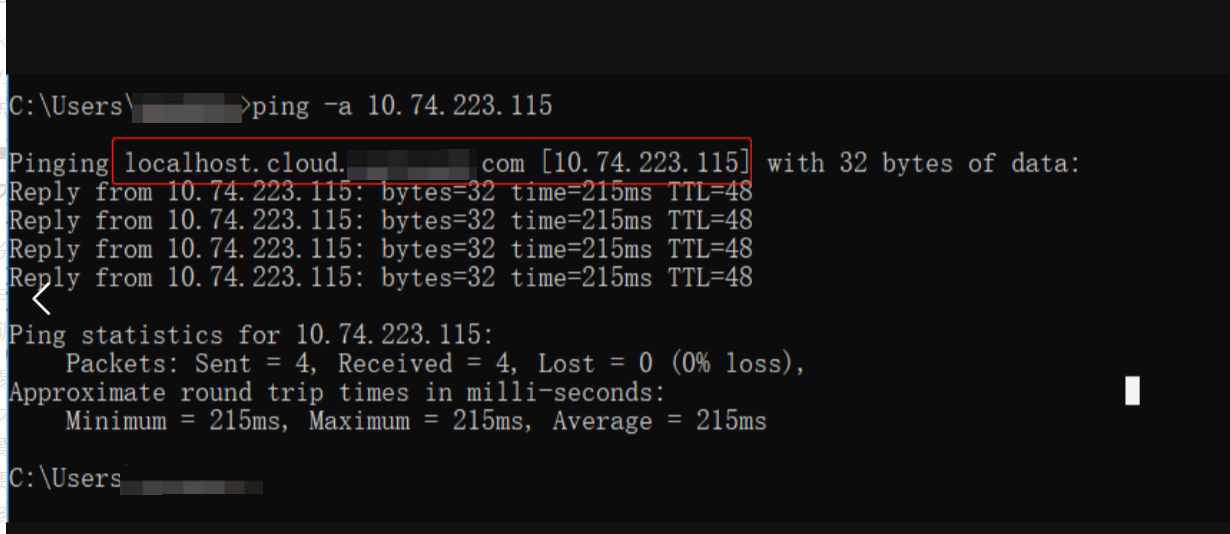
-
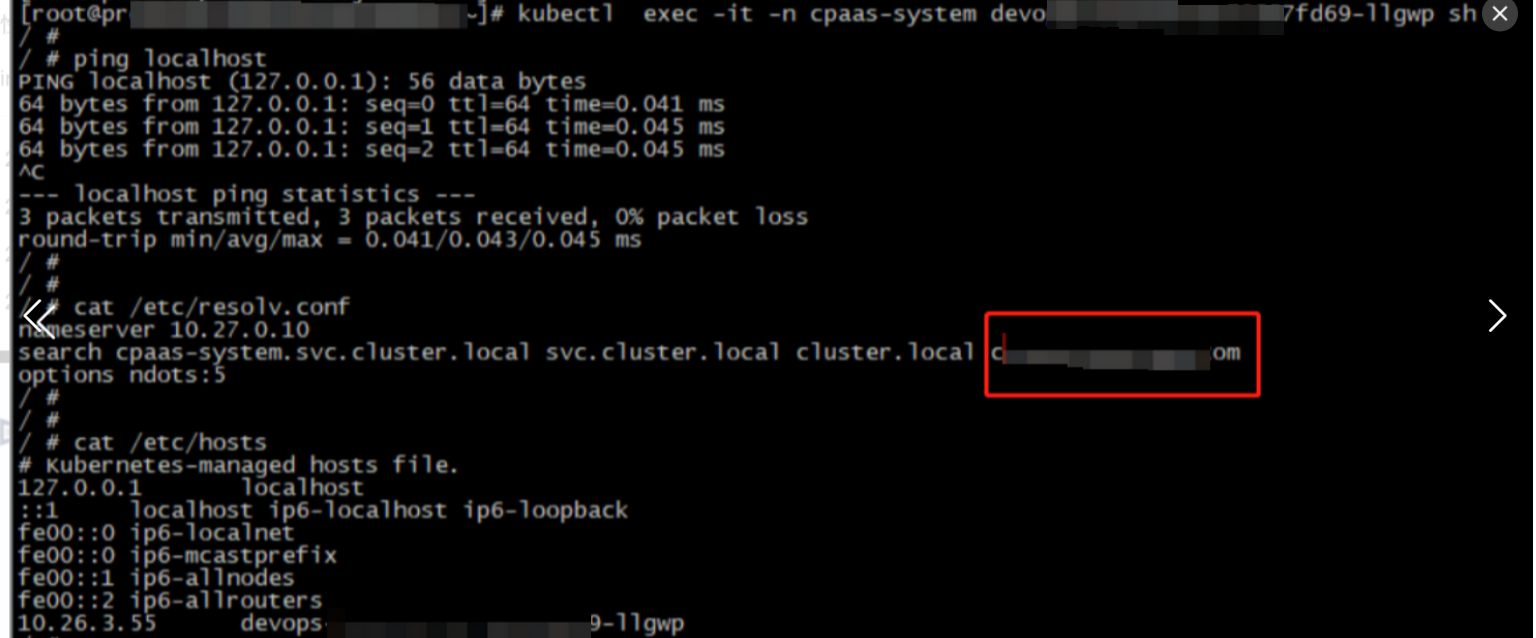
于是到组件pod检查 /etc/resolv.conf文件和/etc/hosts文件。在容器里面,ping localhost是有正常响应的,在/etc/hosts文件里面,也有localhost的记录。在/etc/resolv.conf里面的search域里面,确实有cloud.xxx.com的地址。同时pod里面ping localhost.cloud.xxx.com,是能ping通的,地址解析IP正是10.74.223.115这个地址。
-
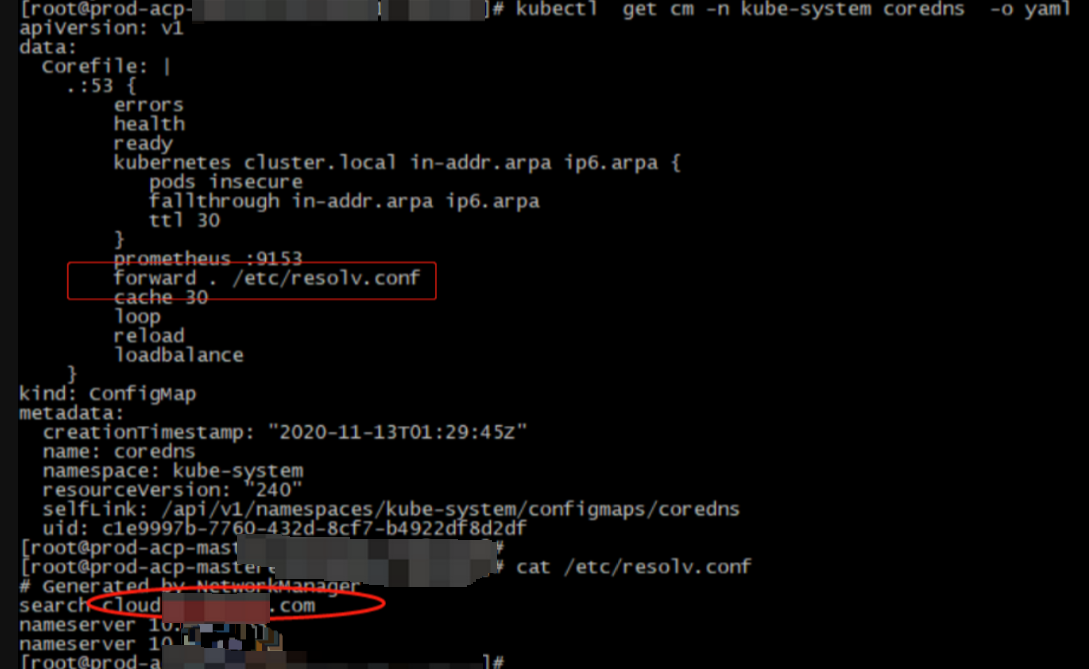
排查pod里面的search域有cloud.xxx.com地址,排查为集群的coredns开启了foward选项,宿主机的 /etc/resolv.conf是有这个search域的,因此属于正常现象。结合组件日志报错,问题变成为何组件请求localhost地址时,没有请求127.0.0.1,而是请求localhost.cloud.xxx.com地址,/etc/hosts文件配置了localhost解析,组件为何不优先使用此记录,这是常见linux系统默认行为。
-
linux系统,/etc/nsswitch.conf 可以控制dns和hosts文件解析顺序。然后观察到有问题的 Pod 用的 alpine 镜像,试试其它镜像后发现只有基于 alpine 的镜像才会有这个问题。
再一搜发现:musl libc 并不会使用 /etc/nsswitch.conf ,也就是说 alpine 镜像并没有实现用这个文件控制域名查找优先顺序,瞥了一眼 musl libc 的 gethostbyname 和 getaddrinfo 的实现,看起来也没有读这个文件来控制查找顺序,写死了先查 hosts,没找到再查 DNS。
这么说,那还是该先查 hosts 再查 DNS 呀,为什么这里抓包看到是先查的 DNS?(如果是先查 hosts 就能命中查询,不会再发起 DNS 请求)
另外这个异常的组件用 Go 写的,会不会是 Go 程序解析域名时压根没调底层 c 库的 gethostbyname 或 getaddrinfo?
搜一下发现果然是这样:go runtime 用 Go 实现了 Glibc 的 getaddrinfo 的行为来解析域名,减少了 c 库调用(应该是考虑到减少 cgo 调用带来的的性能损耗)。issue:net: replicate DNS resolution behaviour of getaddrinfo(glibc) in the go dns resolver
所以虽然 alpine 用的 musl libc 不是 Glibc,但 Go 程序解析域名还是一样走的 Glibc 的逻辑,而 alpine 没有 /etc/nsswitch.conf 文件,所以DNS解析请求高于hosts文件。
搜索到翻源码验证下:
Unix 系的 OS 下,除了 openbsd, go runtime 会读取 /etc/nsswitch.conf (net/conf.go):
hostLookupOrder 函数决定域名解析顺序的策略,Linux 下,如果没有 nsswitch.conf 文件就 DNS 比 hosts 文件优先(net/conf.go):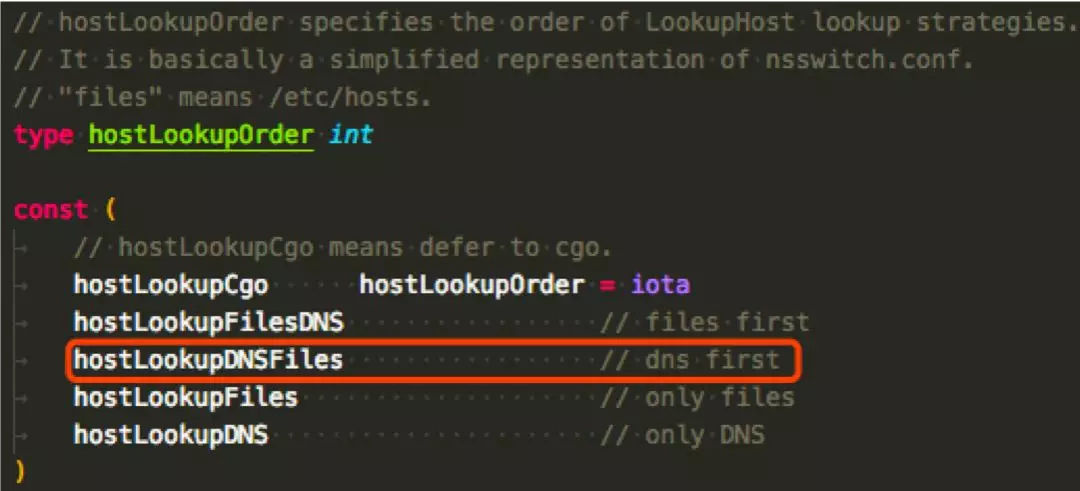
可以看到 hostLookupDNSFiles 的意思是 dns first(net/dnsclient_unix.go):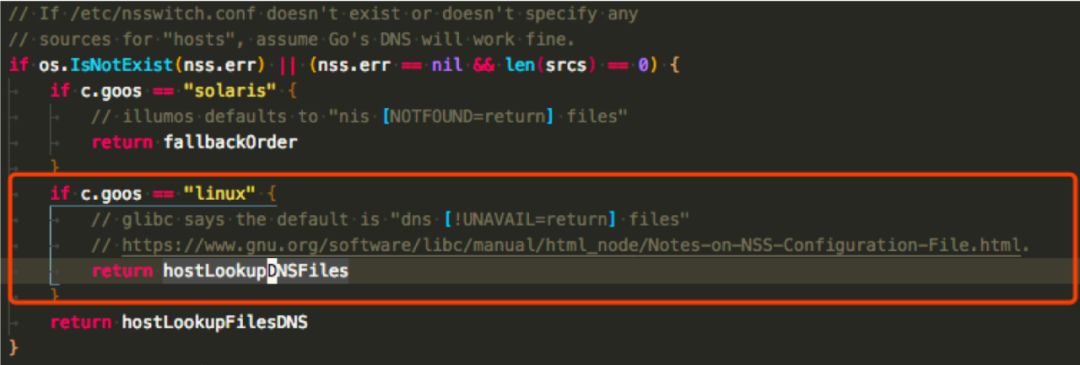
解决
重新做镜像,在Dockerfile中增加如下命令
RUN echo "hosts: files dns" > /etc/nsswitch.conf
参考
- https://github.com/golang/go/issues/22846
- https://www.jianshu.com/p/c47a08b3f22e

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)