从DeepSeek技术交底看大模型未来:MoE架构与Agentic AI必学指南(值得收藏)
本文深入解析DeepSeek技术交底,揭示MoE架构如何实现万亿参数大模型的高效训练,以及Agentic AI如何推动大模型从被动响应向主动协作转变。文章详解了下一代训练方法、对抗幻觉技术及未来AGI发展路径,为开发者和研究人员提供了大模型技术演进的全景视角和实践指导。
本文深入解析DeepSeek技术交底,揭示MoE架构如何实现万亿参数大模型的高效训练,以及Agentic AI如何推动大模型从被动响应向主动协作转变。文章详解了下一代训练方法、对抗幻觉技术及未来AGI发展路径,为开发者和研究人员提供了大模型技术演进的全景视角和实践指导。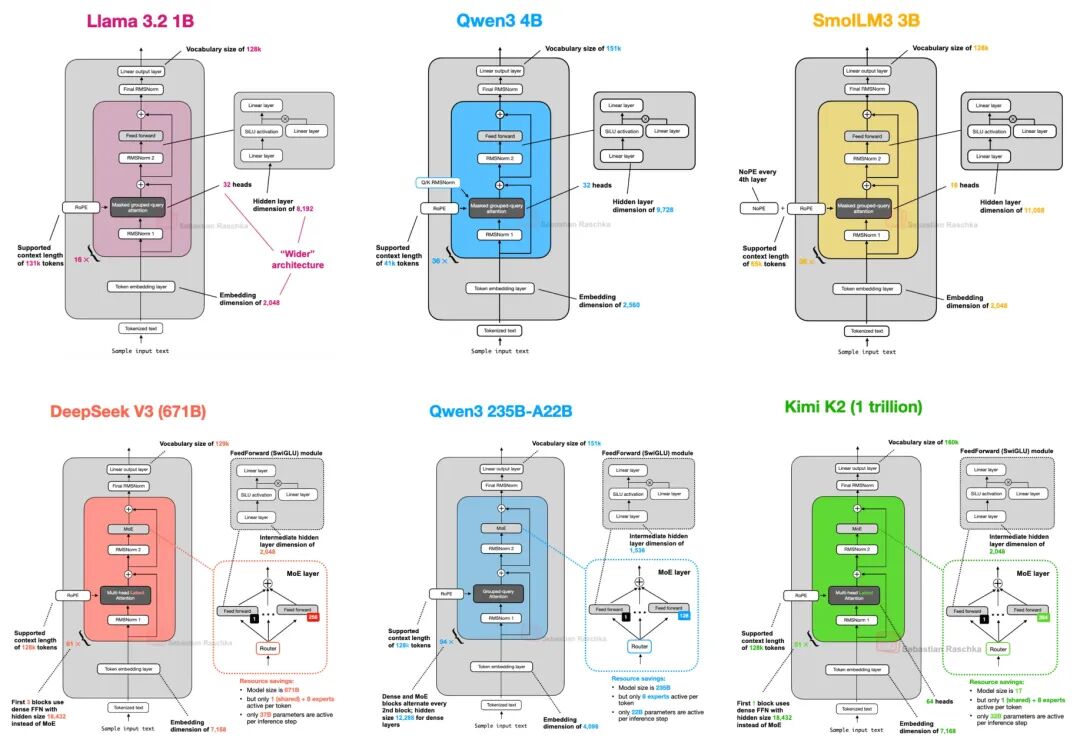
🔍 一、MoE架构:万亿参数的效率革命
Mixture of Experts(MoE) 是当前突破千亿级参数瓶颈的核心架构。与传统Transformer不同,MoE将模型拆分为多个“专家子网络”,每个输入仅激活部分专家(如DeepSeek-V3采用稀疏激活),实现计算效率与模型容量的双重突破。
下图对比稠密模型和Moe模型差异,MoE将传统的前馈模块替换为多个专家层,每个专家层也是一个前馈模块。在推理时,一个路由器会选择一小部分专家进行激活。例如,DeepSeek V3有256个专家,但每次推理仅激活9个专家(1个共享专家和8个由路由器选择的专家)。
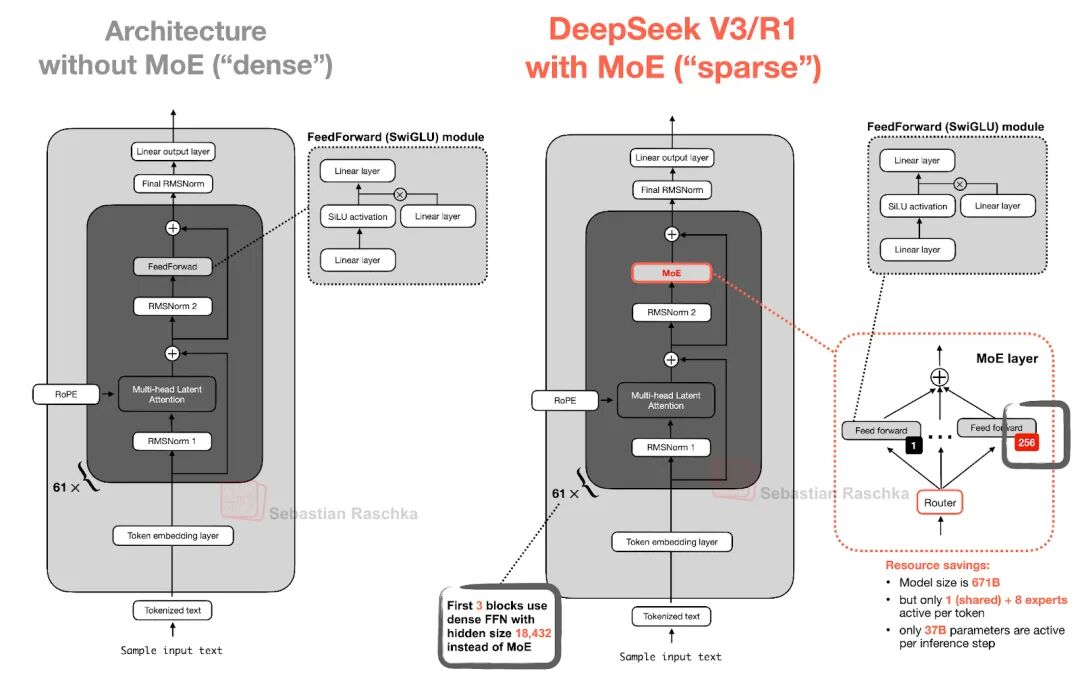
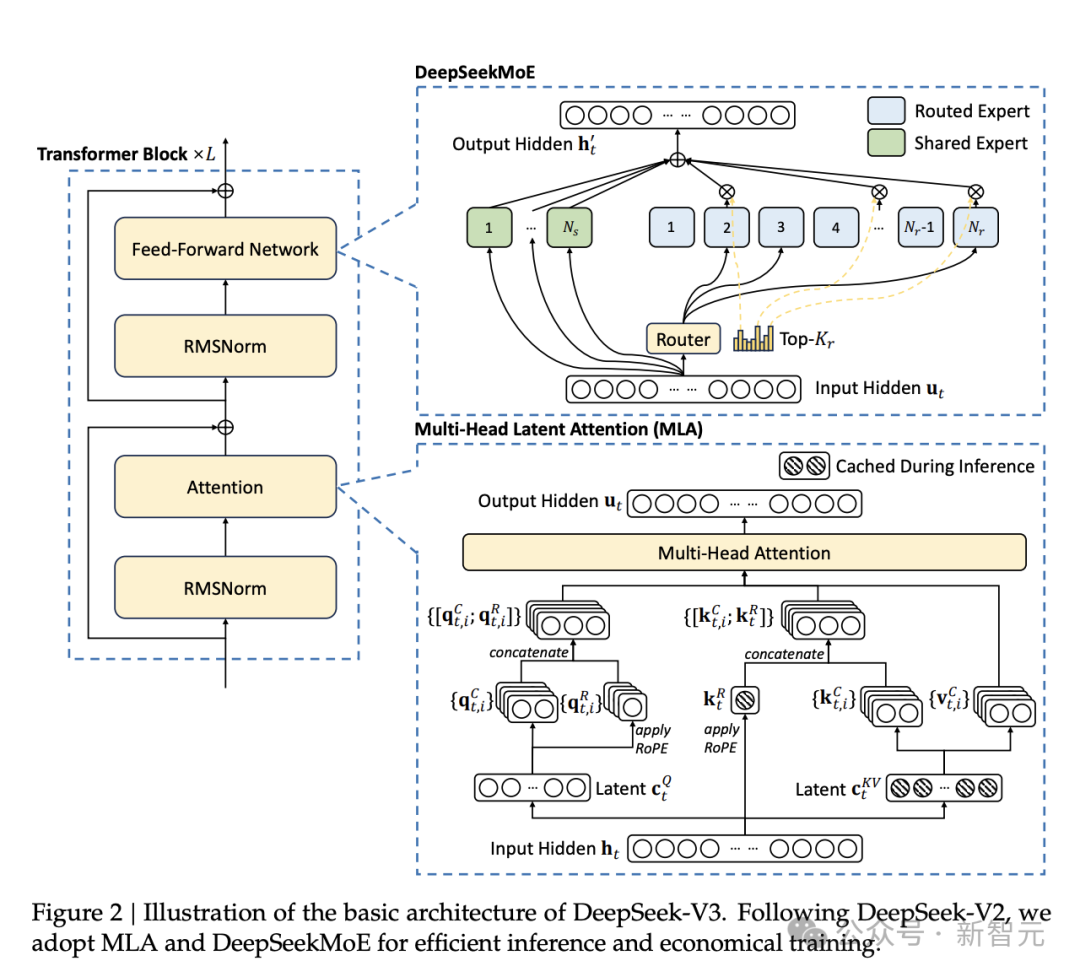
DeepSeek-V3-0324(6850亿参数)的规模背后,MoE架构功不可没:
MoE通过动态路由(如Top-k门控)选择专家,使模型在推理时仅消耗20%-30%的计算资源,却获得接近万亿参数的性能。
Llama 4采用了与DeepSeek V3类似的架构,但在某些细节上进行了优化,以提高模型的性能和效率。Llama 4使用了分组查询注意力(GQA)而非多头潜在注意力(MLA),并且在MoE模块中使用了更少但更大的专家。此外,Llama 4在每个Transformer块中交替使用MoE模块和密集模块。 Qwen3的MoE模型采用了与DeepSeek V3类似的架构,但在某些细节上有所不同,例如不使用共享专家。这种设计使得模型在训练时能够学习更多知识,而在推理时保持高效。 Kimi K2采用了DeepSeek V3的架构,并进行了扩展。它使用了Muon优化器而非AdamW,这可能是其训练损失曲线表现优异的原因之一。此外,Kimi K2在MoE模块中使用了更多的专家,在MLA模块中使用了更少的头。这些设计使得Kimi 2在训练过程中表现优异,训练损失曲线平滑且下降迅速。这可能有助于该模型跃居上述基准测试的榜首。 🤖 二、Agentic AI:从被动响应到主动协作
Agentic AI(智能体导向的AI)是下一代大模型的核心范式。它让模型具备目标分解、自我反思、工具调用能力,而不仅是“问答机器”。DeepSeek-R1的训练方法已初现Agentic雏形:
在优化训练阶段,研究人员引导模型生成带反思的详细答案(Self-Instruct),再通过人工修正提升逻辑严谨性:这种“自我验证+人工对齐”正是Agentic AI的早期实践——让模型像人类一样拆解任务、验证假设、修正错误。
先回顾一下人工反馈强化学习(Reinforcement Learning from Human Feedback,简称 RLHF),顾名思义,就是先训练基础模型,在训练奖励模型,然后用奖励模型给基础模型打分做强化学习,通过强化学习算法微调LLM,保证输出内容的对齐和调优。缺点也显而易见,一个是奖励模型训练复杂,决定了模型好坏;一个是这里注重结果,没有注重过程对齐训练。
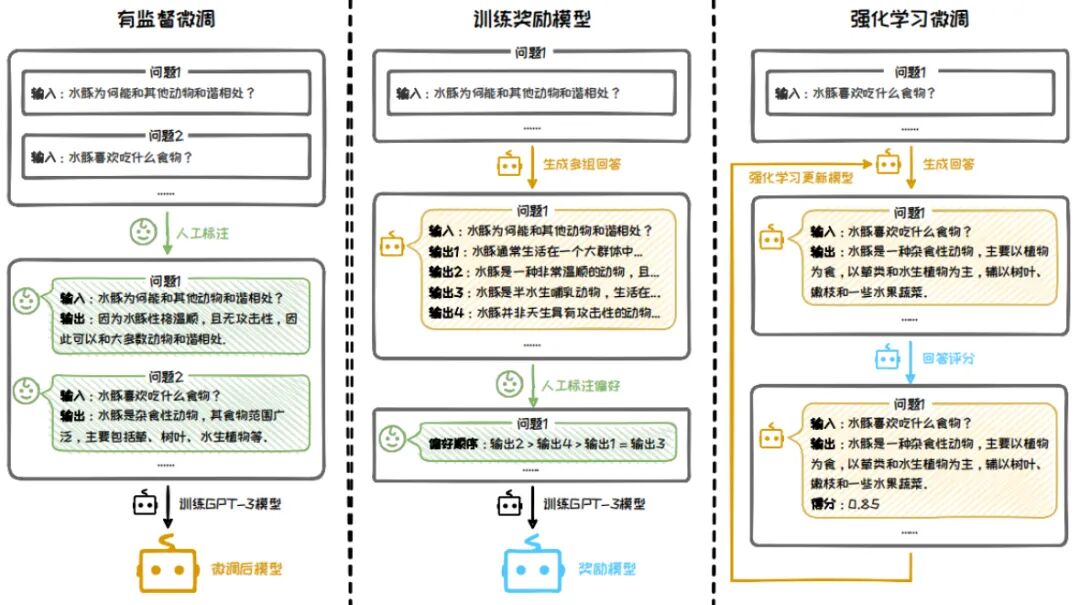
关于强化学习对齐的方法,这里主要有三种:PPO、DPO、GRPO。
近端策略优化[PPO](Schulman et al., 2017)是一种广泛应用于大语言模型强化学习精调阶段的演员-评论家强化学习算法。OpenAI 在大多数任务中使用的强化学习算法都是近端策略优化算法(Proximal Policy Optimization, PPO)。近端策略优化可以根据奖励模型获得的反馈优化模型,通过不断的迭代,让模型探索和发现更符合人类偏好的回复策略。
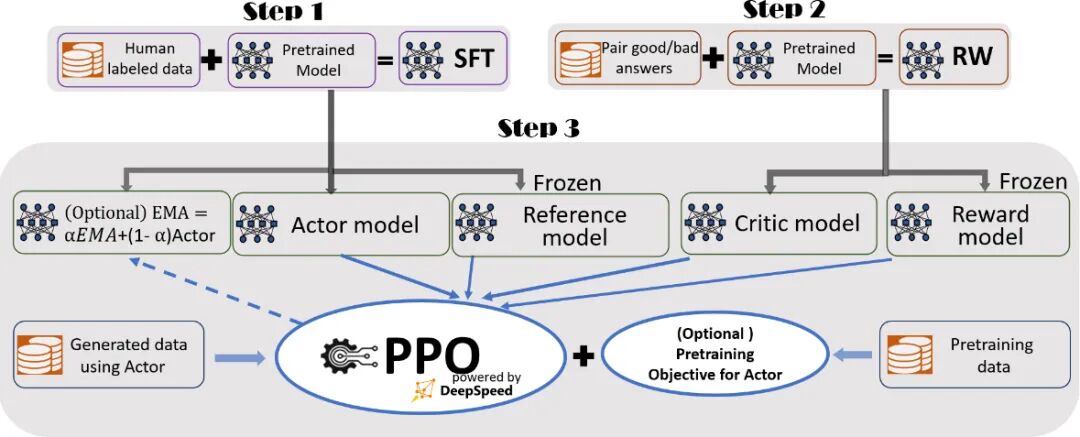
然后为了克服 RLHF 在计算效率上的缺陷,斯坦福大学在 2023 年在其基础上,提出了一种新的算法直接偏好优化(DPO)算法,成为中小模型的优选对齐方案。PPO需同时训练策略、奖励、评论、参考4个模型,且需在线采样数据,计算资源消耗大。DPO核心改进:跳过“奖励模型训练”步骤,直接用“人类偏好数据”优化LLM策略,仅需2个模型(策略模型+参考模型),无需在线采样。
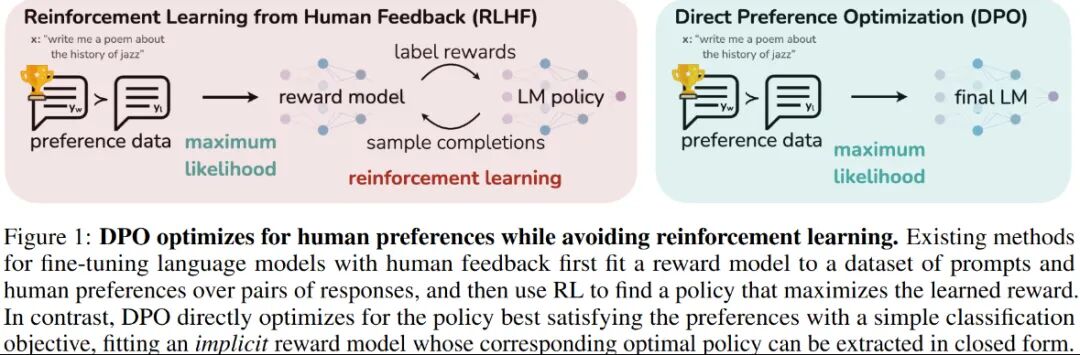
当然DPO也有一些缺点:样本利用率低:依赖离线标注数据,训练效率低,且易出现策略与数据不匹配问题。
组相对策略优化(Group Relative Policy Optimization, GRPO):是一种节省训练成本的RL框架,它避免了通常与policy model相同大小的critic model(value model),而是基于组得分估计基线。GRPO 的改进
- • 组内奖励标准化:对每个问题生成多个输出(组),用组内奖励的均值和标准差进行归一化。
- • 优势计算简化:直接使用归一化后的奖励作为优势值,无需评论家模型。
- • KL 散度正则化:通过无偏估计直接约束策略与参考模型的差异,避免奖励计算复杂化。
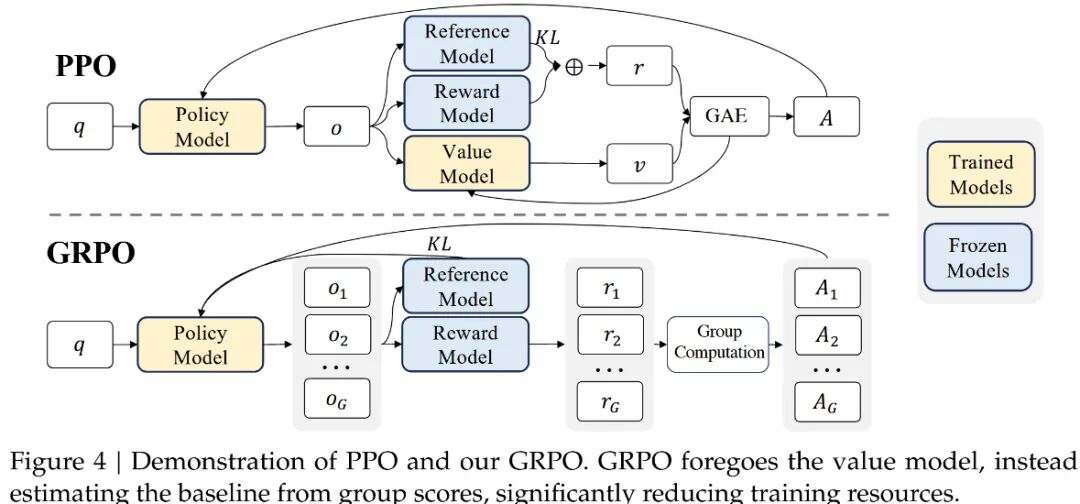
GRPO的核心是通过组内相对奖励优化策略(通过采样一组输出,计算这些输出的奖励,并根据奖励的相对值来更新模型参数。对每个输入状态,采样一组动作(如多个回答),通过奖励函数评估后,计算组内相对优势。这已经有过程对齐的那味儿了。
前面介绍了这么多还都是局部优化,之前的文章介绍了,未来的Agentic AI是强调自主规划、反馈迭代的能力,这块怎么训练呢。
🚀 三、下一代训练方法:解决三大核心挑战
1. 预训练革新:质量 > 规模
DeepSeek强调数据治理的核心地位:
- 过滤仇恨、暴力、侵权内容
- 算法+人工降低统计偏见
- 主动清除个人信息(即使偶然混入)
2. 优化训练:从SFT到Agentic微调
下一代训练将融合:
- Self-Improvement:模型生成高质量指令数据(如R1-Zero)
- 工具学习:调用API、搜索、代码解释器完成复杂任务
- 多智能体辩论:多个Agent协作验证答案可靠性
3. 推理架构:Agentic化部署
模型服务不再仅是“文本生成器”,而是具备记忆、规划、工具使用能力的智能体:
Agentic AI将动态整合外部知识(RAG)、程序执行(Code Interpreter)和长期记忆(Vector DB),实现“思考-行动”闭环。
蚂蚁团队给出的答案不是一个新算法,而是一个基础设施级别的解决方案——AWORLD框架。 你可以将 AWORLD 理解为一个为AgentAI量身打造的、高度优化的分布式计算与训练编排系统。它的核心贡献可以概括为以下三点: 1. 大规模并行执行:AWORLD 的核心设计思想是“分而治之”。它不再让一个Agent孤军奋战,而是利用Kubernetes(K8s)集群,同时启动成百上千个独立的、并行的环境。每个环境里都有一个Agent的“克隆”在尝试解决任务。这样一来,原来需要线性累加的尝试时间,现在被压缩到了接近单次尝试的时间。 2. 解耦的系统架构:AWORLD 将Agent训练的整个流程巧妙地解耦为两个主要部分: * • 推理/执行端:负责Agent与环境的高并发交互,即大规模的“实践”(Rollout)。 * • 训练端:负责收集所有“实践”数据,进行分析和学习,即更新模型参数。 这种设计允许为不同的任务匹配最合适的硬件资源,例如,用GPU集群进行高效的模型推理和训练,用CPU集群来承载大量的环境实例,从而最大化资源利用率。 3. 一套完整的“训练配方”:论文不仅提供了工具(AWORLD),更提供了一套可复现的、端到端的 Agentic AI 训练“配方”。这个配方结合了监督微调(SFT)和强化学习(RL),让模型能够平滑地从“模仿专家”过渡到“自我进化”。 🛡️ 四、对抗幻觉:Agentic AI的全新解法
DeepSeek指出当前大模型存在幻觉、偏见、滥用三大风险。下一代训练将通过:
-
红队测试(Red Teaming):模拟攻击训练模型抗干扰能力
-
可信验证链(Chain-of-Verification):强制模型分步验证输出
-
安全对齐(Safety Alignment):构造安全数据注入价值观
Agentic框架中,模型需展示推理过程,人类可实时干预修正(如“暂停生成,这一步证据不足”)
🔮 未来展望:开源生态与AGI路径
DeepSeek的全模型开源(MIT协议) 为Agentic AI社区化奠定基础。MoE+Agentic架构将推动模型向:
- 超级专家系统:医疗/法律等垂直领域MoE专家协作
- 社会智能体(Social Agent):理解人类意图并主动服务
- 可解释AI(XAI):全程可视化推理路径
“真正的AGI不是更大的参数,而是更自主的思考。”
读者福利大放送:如果你对大模型感兴趣,想更加深入的学习大模型**,那么这份精心整理的大模型学习资料,绝对能帮你少走弯路、快速入门**
如果你是零基础小白,别担心——大模型入门真的没那么难,你完全可以学得会!
👉 不用你懂任何算法和数学知识,公式推导、复杂原理这些都不用操心;
👉 也不挑电脑配置,普通家用电脑完全能 hold 住,不用额外花钱升级设备;
👉 更不用你提前学 Python 之类的编程语言,零基础照样能上手。
你要做的特别简单:跟着我的讲解走,照着教程里的步骤一步步操作就行。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
现在这份资料免费分享给大家,有需要的小伙伴,直接VX扫描下方二维码就能领取啦😝↓↓↓
为什么要学习大模型?
数据显示,2023 年我国大模型相关人才缺口已突破百万,这一数字直接暴露了人才培养体系的严重滞后与供给不足。而随着人工智能技术的飞速迭代,产业对专业人才的需求将呈爆发式增长,据预测,到 2025 年这一缺口将急剧扩大至 400 万!!
大模型学习路线汇总
整体的学习路线分成L1到L4四个阶段,一步步带你从入门到进阶,从理论到实战,跟着学习路线一步步打卡,小白也能轻松学会!
大模型实战项目&配套源码
光学理论可不够,这套学习资料还包含了丰富的实战案例,让你在实战中检验成果巩固所学知识
大模型学习必看书籍PDF
我精选了一系列大模型技术的书籍和学习文档(电子版),它们由领域内的顶尖专家撰写,内容全面、深入、详尽,为你学习大模型提供坚实的理论基础。
大模型超全面试题汇总
在面试过程中可能遇到的问题,我都给大家汇总好了,能让你们在面试中游刃有余
这些资料真的有用吗?
这份资料由我和鲁为民博士(北京清华大学学士和美国加州理工学院博士)共同整理,现任上海殷泊信息科技CEO,其创立的MoPaaS云平台获Forrester全球’强劲表现者’认证,服务航天科工、国家电网等1000+企业,以第一作者在IEEE Transactions发表论文50+篇,获NASA JPL火星探测系统强化学习专利等35项中美专利。本套AI大模型课程由清华大学-加州理工双料博士、吴文俊人工智能奖得主鲁为民教授领衔研发。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的技术人员,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。
👉获取方式:
😝有需要的小伙伴,可以保存图片到VX扫描下方二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最适合零基础的!!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献148条内容
已为社区贡献148条内容

所有评论(0)