9.10作业
哈希表(Hash Table)是一种高效的数据结构,它通过键值对(key-value pairs)的形式存储数据,能够在平均O(1)的时间复杂度内完成插入、删除和查找操作。哈希冲突是指不同的键经过哈希函数计算后得到相同的哈希值,从而映射到哈希表的同一个位置的现象。由于哈希函数的输出范围有限(通常是固定大小的数组),而输入范围可能无限,因此冲突是不可避免的。时间复杂度: O(n),其中n是字符串的长
什么是哈希表?
哈希表(Hash Table)是一种高效的数据结构,它通过键值对(key-value pairs)的形式存储数据,能够在平均O(1)的时间复杂度内完成插入、删除和查找操作。哈希表的核心思想是将键(key)通过哈希函数映射到数组的特定位置,从而实现快速的数据访问。
哈希表的基本结构
python
# 哈希表的简单实现示例
class HashTable:
def __init__(self, size=10):
self.size = size
self.table = [[] for _ in range(size)] # 使用链表法解决冲突
def hash_function(self, key):
return hash(key) % self.size
def insert(self, key, value):
index = self.hash_function(key)
# 在对应位置的链表中查找是否已存在该key
for item in self.table[index]:
if item[0] == key:
item[1] = value # 更新值
return
self.table[index].append([key, value]) # 添加新键值对
哈希冲突(Hash Collision)
什么是哈希冲突?
哈希冲突是指不同的键经过哈希函数计算后得到相同的哈希值,从而映射到哈希表的同一个位置的现象。由于哈希函数的输出范围有限(通常是固定大小的数组),而输入范围可能无限,因此冲突是不可避免的。
哈希冲突产生的原因
1. pigeonhole principle(鸽巢原理):当要存储的元素数量超过哈希表的大小时,必然会发生冲突
2. 哈希函数的局限性:任何哈希函数都无法保证完全均匀分布
3. 数据分布特性:某些数据集可能具有特定的模式,导致哈希值聚集
解决哈希冲突的主要方法
1. 链地址法(Separate Chaining)
原理:在每个哈希表位置维护一个链表(或其他数据结构),所有映射到同一位置的元素都存储在这个链表中。
python
链地址法示例
class SeparateChainingHashTable:
def __init__(self, size=10):
self.size = size
self.table = [[] for _ in range(size)]
def insert(self, key, value):
index = hash(key) % self.size
bucket = self.table[index]
检查是否已存在该key
for i, (k, v) in enumerate(bucket):
if k == key:
bucket[i] = (key, value) # 更新
return
bucket.append((key, value)) # 添加新元素
优点:
· 实现简单
· 可以处理任意数量的冲突
· 删除操作容易实现
缺点:
· 需要额外的指针空间
· 缓存不友好(链表节点可能分散在内存中)
2. 开放地址法(Open Addressing)
原理:当发生冲突时,按照某种探测序列寻找下一个空闲位置。
a) 线性探测(Linear Probing)
python
# 线性探测示例
class LinearProbingHashTable:
def __init__(self, size=10):
self.size = size
self.table = [None] * size
self.count = 0
def probe(self, key, start_index):
index = start_index
while self.table[index] is not None and self.table[index][0] != key:
index = (index + 1) % self.size
return index
b) 二次探测(Quadratic Probing)
python
# 二次探测示例
def quadratic_probe(start_index, i, size):
return (start_index + i**2) % size
c) 双重哈希(Double Hashing)python
双重哈希示例
def double_hash(key, i, size):
h1 = hash1(key)
h2 = hash2(key)
return (h1 + i * h2) % size
优点:
· 不需要额外的指针空间
· 更好的缓存性能
· 内存使用更紧凑
缺点:
· 删除操作复杂(需要特殊标记)
· 容易产生聚集现象(特别是线性探测)
哈希碰撞(Hash Collision)攻击
什么是哈希碰撞攻击?
哈希碰撞攻击是指故意构造大量具有相同哈希值的不同输入,使哈希表退化为链表,从而导致性能急剧下降的攻击方式。
经典案例:HashDoS攻击
在2011年,研究人员发现许多编程语言的哈希表实现容易受到HashDoS攻击。攻击者可以构造大量具有相同哈希值的字符串,使得Web服务器处理单个请求的时间从微秒级增加到秒级。
防御措施
1. 使用加密安全的哈希函数:如SHA-256
2. 随机化哈希函数:为每个哈希表实例使用不同的随机种子
3. 限制输入大小:对输入数据进行长度限制
4. 使用替代数据结构:在检测到异常时切换到平衡树python
使用随机化哈希函数的示例
import random
class SecureHashTable:
def __init__(self, size=10):
self.size = size
self.table = [[] for _ in range(size)]
self.salt = random.randint(0, 1000000) # 随机盐值
def secure_hash(self, key):
# 使用盐值增加哈希函数的随机性
return hash((key, self.salt)) % self.size
哈希函数的设计原则
1. 确定性:相同的输入必须产生相同的输出
2. 均匀性:哈希值应该均匀分布在值域中
3. 高效性:计算速度要快
4. 抗碰撞性:难以找到两个不同的输入产生相同的输出
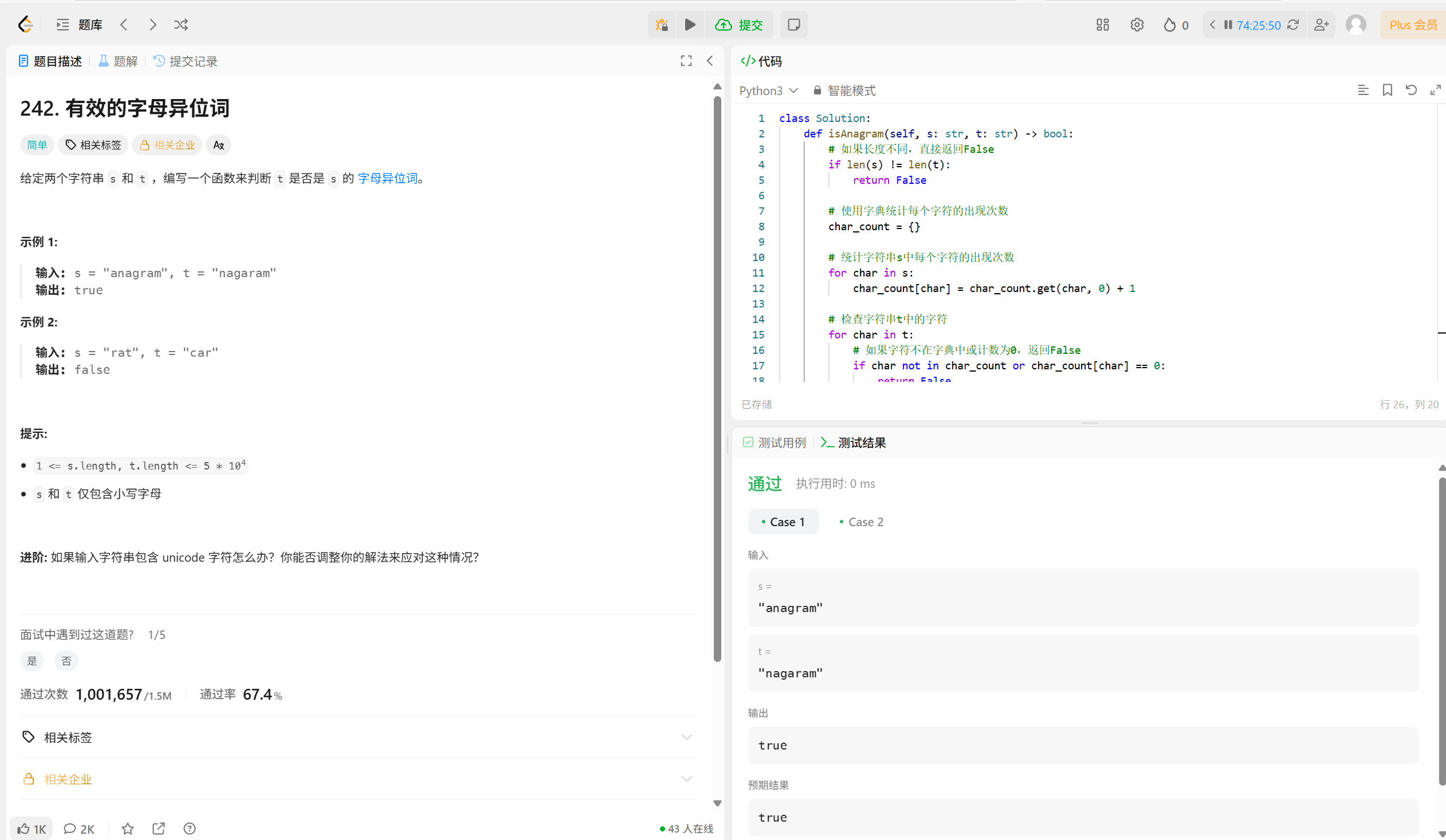
主要思路:
1. 长度检查:如果两个字符串长度不同,肯定不是异位词
2. 字符计数:使用字典统计每个字符的出现频率
3. 验证匹配:检查第二个字符串中的字符是否与第一个字符串的字符计数匹配
时间复杂度: O(n),其中n是字符串的长度 空间复杂度:O(1),因为最多只有26个小写字母(或者Unicode字符集,但空间需求是常数级别的)
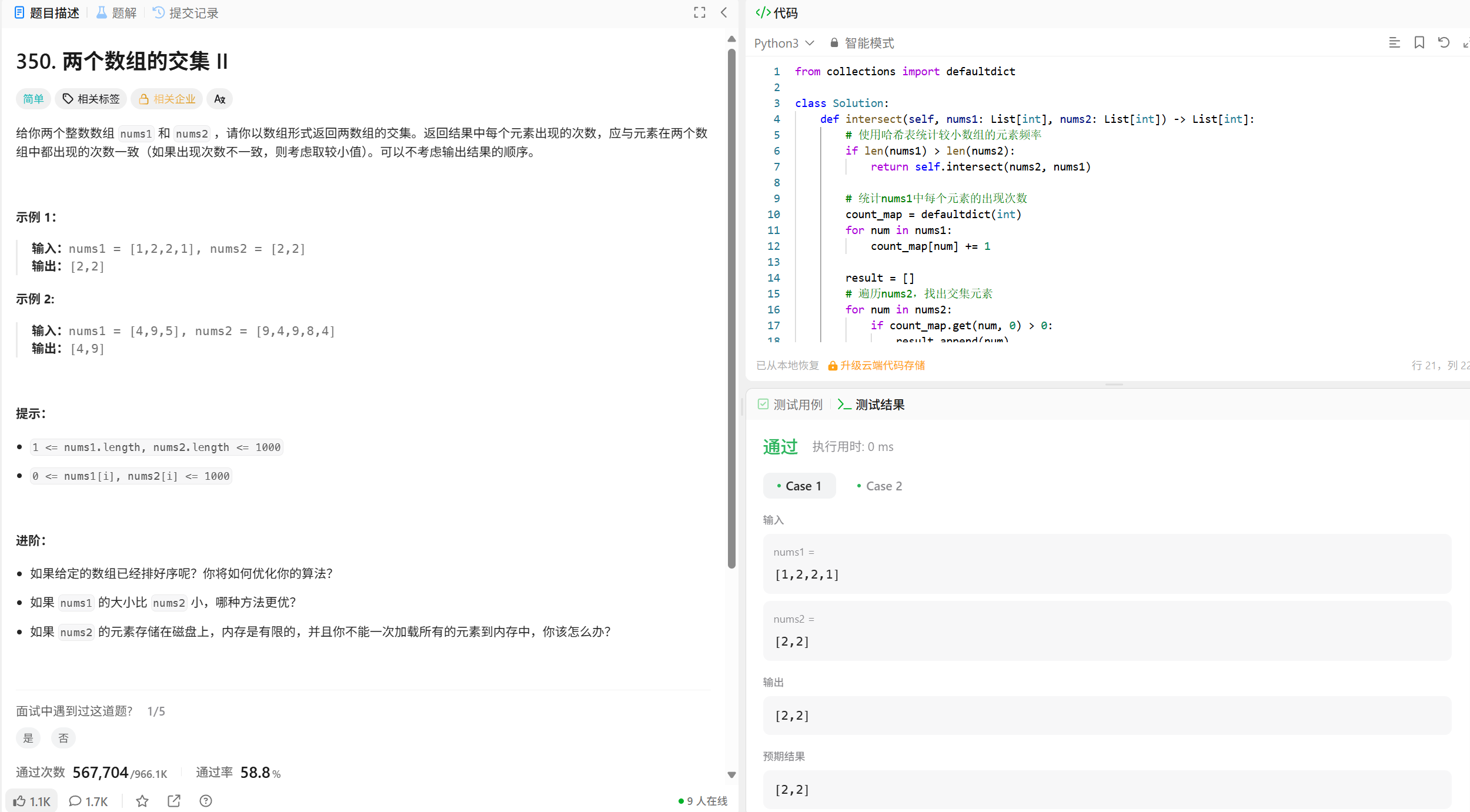
算法分析:
· 时间复杂度:O(m + n),其中m和n分别是两个数组的长度
· 空间复杂度:O(min(m, n)),用于存储较小数组的频率统计
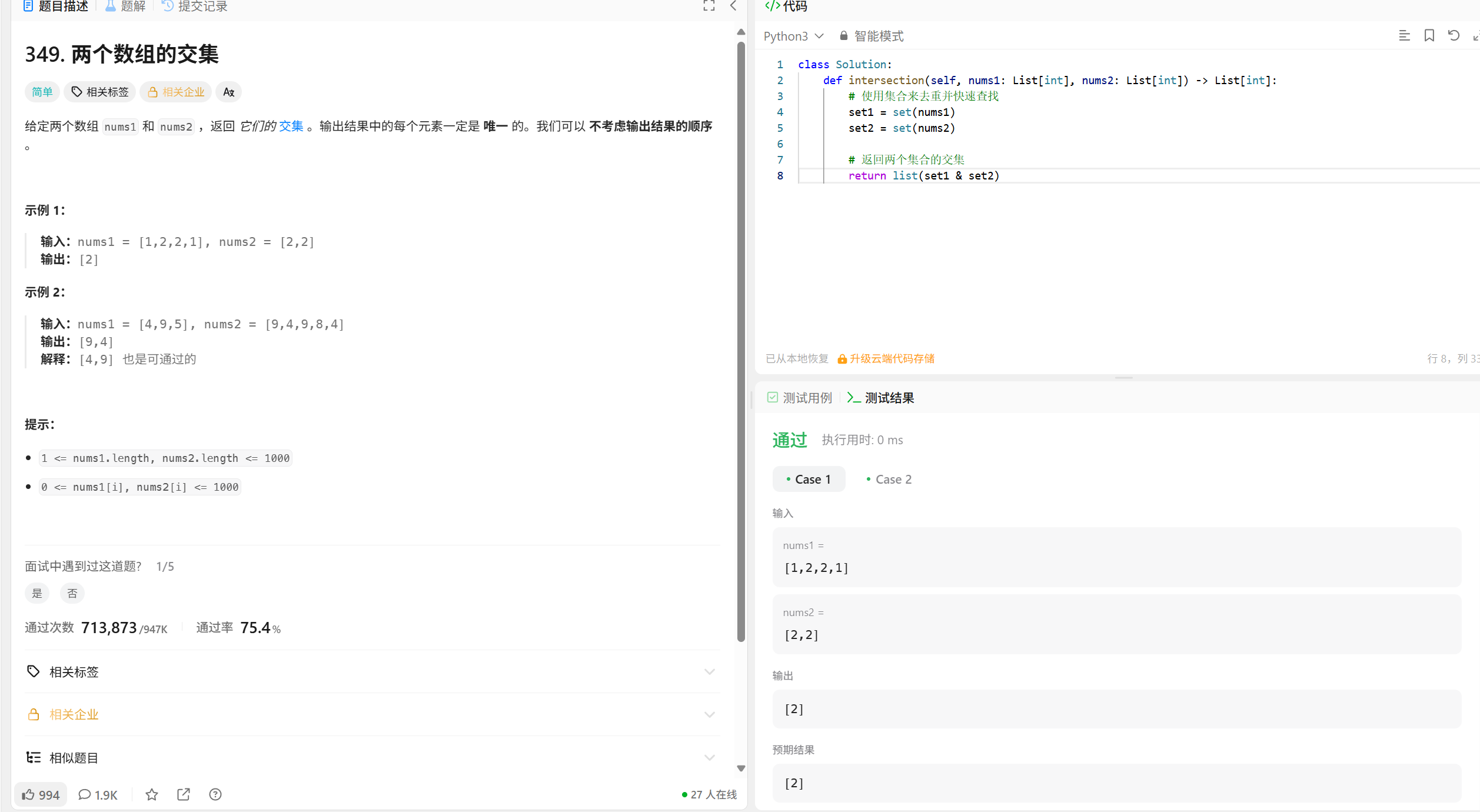
关键点:
1. 使用集合(set)来去重,因为集合自动去除重复元素
2. 使用集合的交集操作 & 或 intersection() 方法
3. 结果需要转换为列表返回
4. 题目不要求保持顺序,所以直接使用集合操作是最简洁高效的
这种方法利用了Python集合的高效查找特性(O(1)时间复杂度),使得整个算法非常高效。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)