AI大模型在自动驾驶决策与规划应用
本文探讨大模型在自动驾驶决策与规划中的应用。传统模块化架构存在泛化能力不足等问题,端到端学习虽能提升性能,但面临可解释性、泛化性和稀疏奖励等挑战。大语言模型(LLM)和视觉语言模型(VLM)为解决这些问题提供新思路:LLM通过自然语言增强可解释性,VLM融合多模态信息提升场景理解能力。研究分析三种大模型应用范式:直接生成决策指令(如LimSim++的解耦框架)、生成辅助特征(如AsyncDrive
1 绪论
自动驾驶研究范式正从传统模块化架构转向端到端学习。模块化架构拆分感知、决策等子任务,依赖人工规则,难覆盖长尾场景,且适应复杂交通能力弱;端到端方法直接从原始传感器数据学驾驶策略,更贴近人类感知 - 决策过程,有望提升系统性能。
但端到端范式应用存关键挑战:
-
一是可解释性不足,模型无透明推理链条,难因果分析,限制安全可控与人机协同应用;
-
二是泛化性能有限,训练数据难涵盖所有交通场景,模型在分布外环境易性能崩溃,鲁棒性差;
-
三是稀疏奖励困境,强化学习(RL)下仅稀疏事件后有反馈,影响学习效率,模仿学习(IL)虽绕开奖励设计,却易累积偏差且难处理复杂长期规划任务。
大语言模型(LLM)为缓解这些挑战提供新思路 ,其以自然语言外显决策过程,提升可解释性与推理透明度,整合跨模态及常识知识增强泛化性与鲁棒性,还能以自然语言提供细粒度策略引导,辅助策略学习稳定收敛。不过单一语言模态难满足端到端自动驾驶对时序密度和动态反馈的需求,研究范式正转向视觉语言模型(VLM),VLM 可直接编码多模态感知数据,保留空间动态特征,降低语义抽象信息损失,增强场景语义理解能力与长尾鲁棒性。
2 关键概念介绍
决策与规划技术可分为三类:
-
模块化架构,典型如基于规则的有限状态机、基于优化的模型预测控制方法等。这类方法的优势在于可解释性和稳定性较好,但短板明显,面对复杂或从未接触过的场景时,泛化能力有限。
-
基于强化学习的方法,将决策或规划看作智能体与环境交互的试错过程。通过设计合适的奖励函数 r (s,a) 评估策略质量,进而学习策略 π,以实现期望累计回报的最大化。
-
基于模仿学习的方法,核心是找到一个策略 π,使其在演示数据集的状态 - 动作分布上,与专家策略 π_E 保持贴近。
值得注意的是,基于强化学习和基于模仿学习的方法,均以学习策略为核心,相较模块化架构,二者具备更强的自适应性与泛化能力。
大模型介绍
LLM(大语言模型)基于 Transformer 架构,以大规模文本语料预训练,核心处理纯语言任务。它输入输出均为文本,能学习语言语法、语义与常识,具备强文本理解(如摘要、情感分析)和生成(如创作、翻译)能力,依赖 “预训练 - 微调” 适配场景,典型应用有智能客服、文案生成、会议纪要整理。
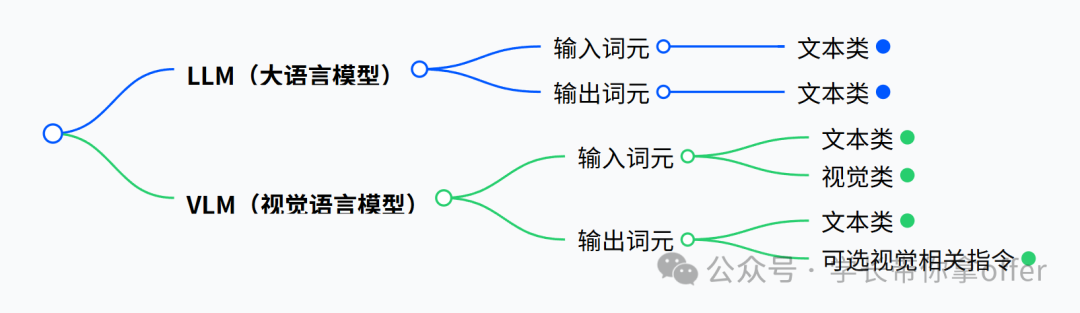
VLM(视觉语言模型)在 LLM 基础上融合视觉模态,通过 “语言 + 图像” 双模态数据预训练,核心是建立视觉特征与语言语义的映射。它可接收 “图像 + 文本” 输入,保留 LLM 语言能力的同时新增图像理解功能,能完成图像描述、跨模态交互(如图文结合回答问题)、视觉推理任务,典型应用包括自动驾驶(处理视觉数据辅助决策)、图像交互工具(按文本指令编辑图像)。
二者呈 “单模态到多模态” 演进,VLM 弥补了 LLM 仅处理文本的局限。
3 面向自动驾驶决策与规划的大模型介绍
基于大模型的决策与规划的典型范式分类方法介绍
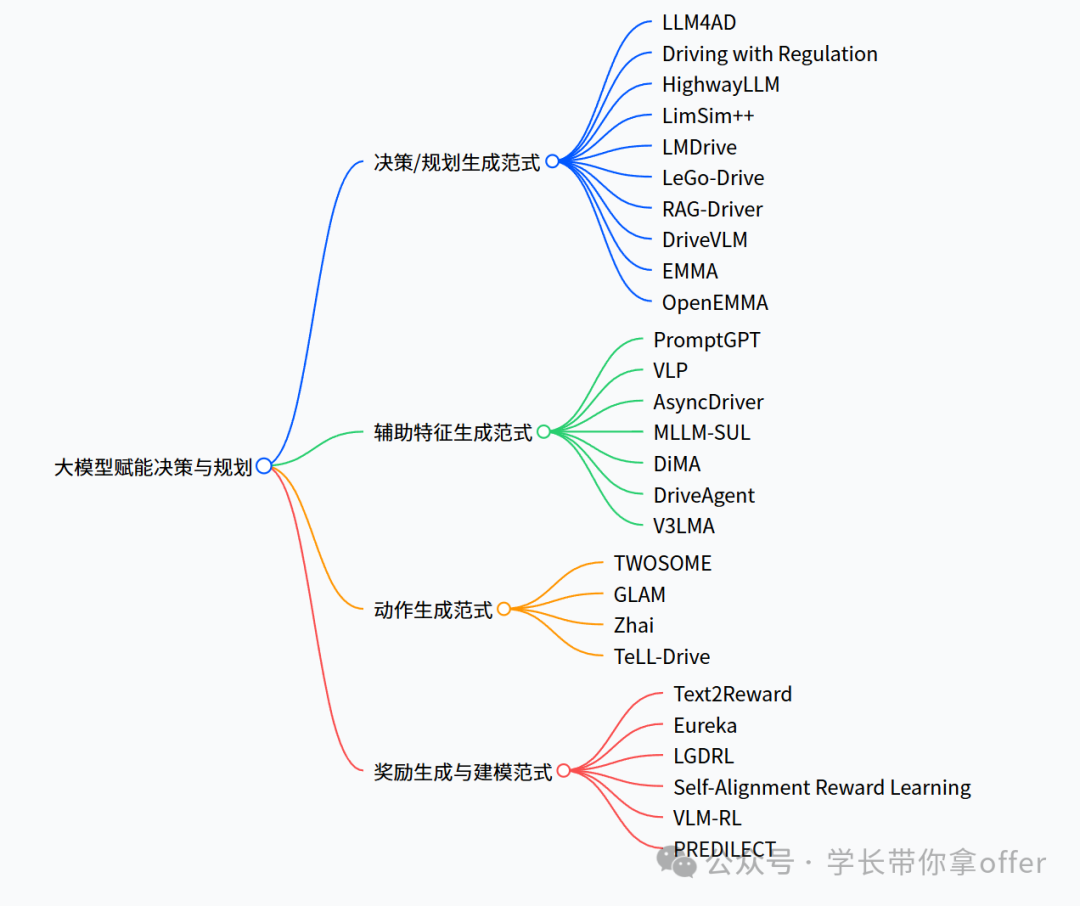
大模型直接生成决策或规划范式
在直接生成决策或规划范式中,大模型通常生成高 阶决策指令(如行为意图、动作类别)或规划的轨迹(如一系列参考轨迹点),其与端到端模型结合的典型架构 分别为并行模式和串行模式
并行模式
在并行模式架构中,不同模块同时对输入数据进行处理。以自动驾驶场景为例,视觉感知模块和语义理解模块可并行工作 。视觉感知模块快速提取图像中的目标物体、车道线等视觉特征,语义理解模块对交通规则、行驶意图等语义信息进行分析。
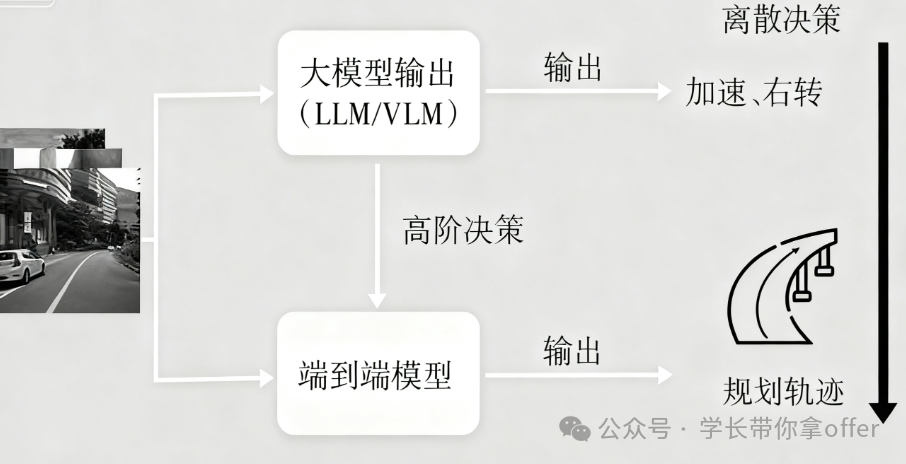
二者将处理结果同时输入到决策模块,由决策模块综合多源信息进行决策规划。这种模式优势在于能充分利用计算资源,加速处理速度,但对模块间的同步和协调要求较高。
串行模式
串行模式下,模型按照特定顺序依次处理数据。比如在语音识别转文本再到文本理解的任务中,先由语音识别模块将语音信号转换为文本,然后文本理解模块对生成的文本进行语义解析、意图识别等操作。
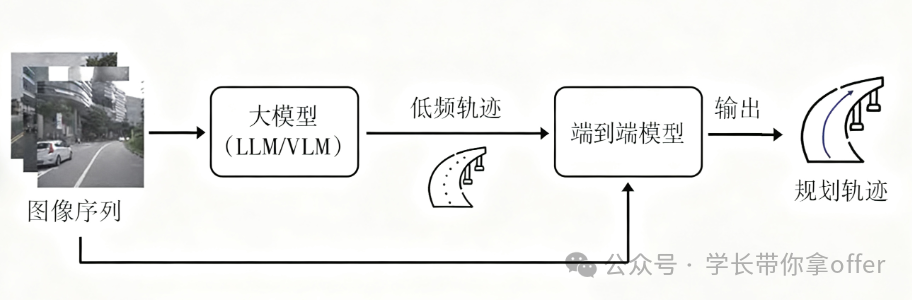
串行模式的流程清晰,便于设计和优化单个模块,但整体处理速度受限于最慢的模块,且前序模块的误差可能会累积影响后续模块的处理结果。
对其核心思路、技术实现路径、典型应用场景及主干模型架构 等关键要素进行全面总结如下:
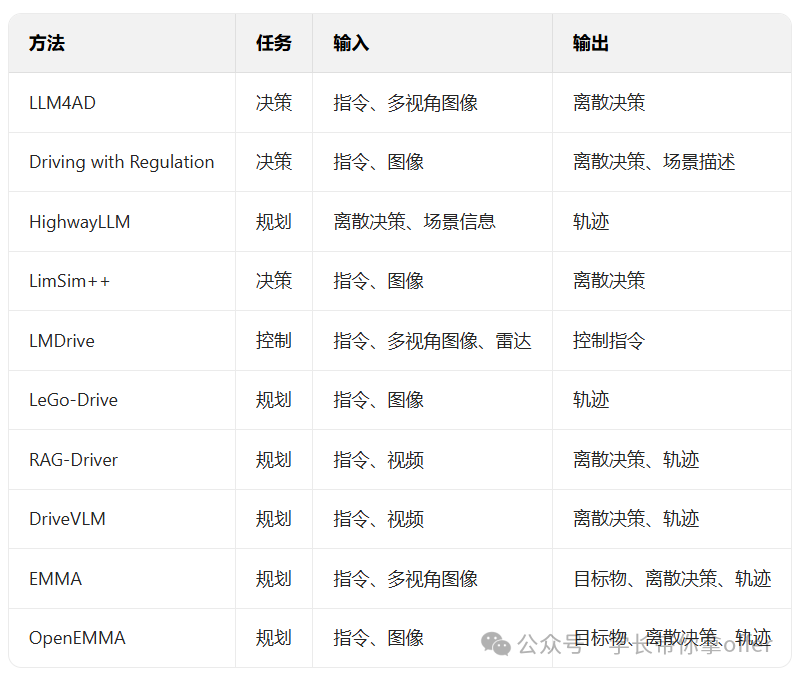
取LimSim++介绍:
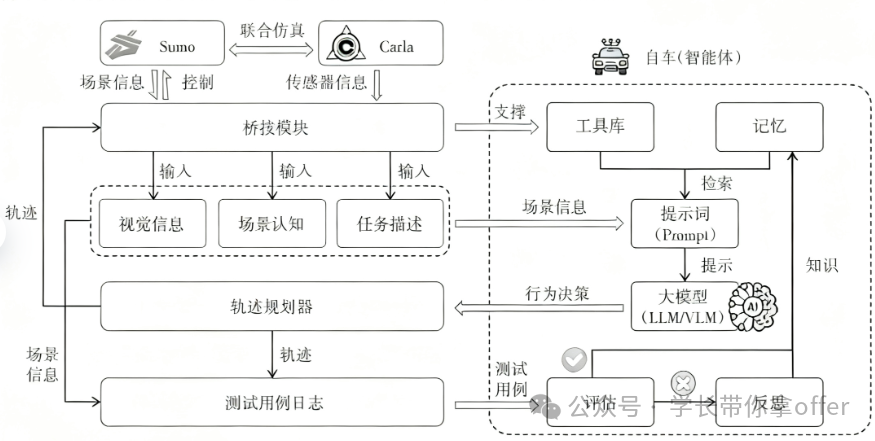
LimSim++基于HighwayLLM提出决策与规划解耦 的闭环验证框架,由LLM生成高层决策,使用独立的规 划器细化执行,并在SUMO和CARLA仿真环境中完 成完整闭环测试。该模型引入了反思机制与记忆机制, 在每段驾驶任务完成后,系统通过评估决策优劣,存储 高质量决策样本、反思并改进低质量决策,实现决策质量的持续优化。
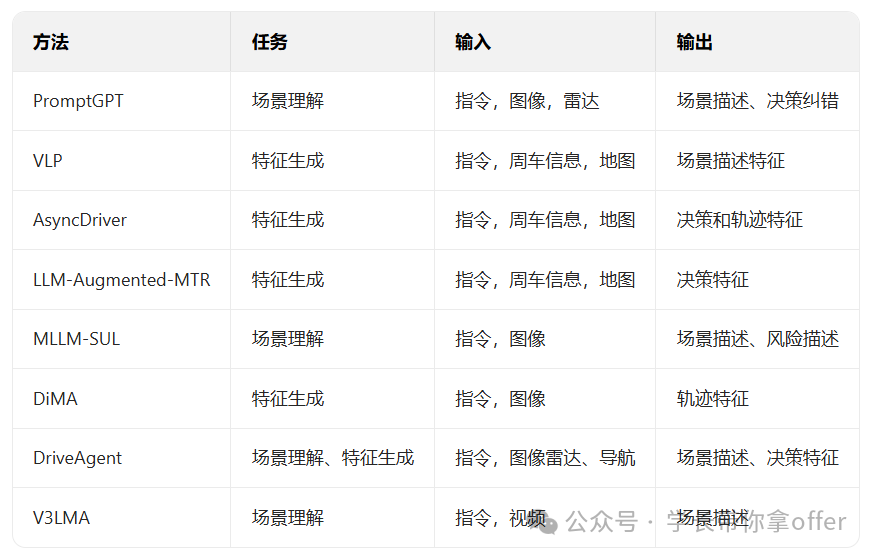
大模型生成辅助特征范式
在生成辅助特征范式中,大模型作为辅助特征生成器,增强端到端方法在复杂环境感知、异常检测与决策 容错性方面表现,该范式下具有代表性的研究工作
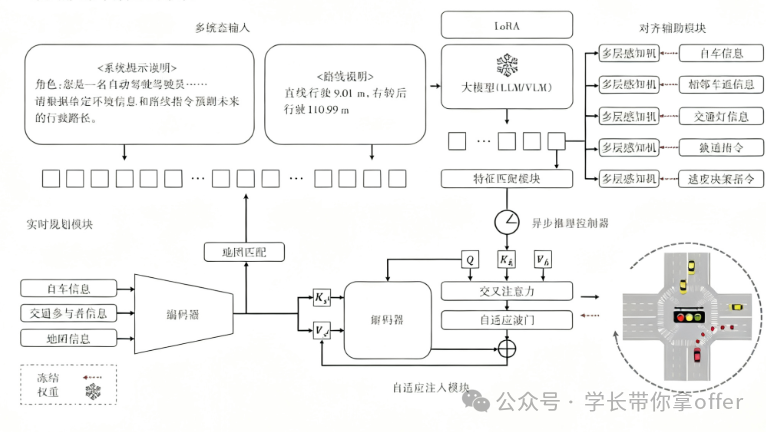
这里取AsyncDriver技术介绍:
AsyncDriver面 向实际部署的实时性需求,提出了异步LLM增强的闭 环框架,在推理阶段,LLM以低频率运行, 周期性产出场景辅助特征,高频轨迹规划器融合场景辅 助特征与基础感知结果共同生成实时轨迹。具体而言, LLM以较低频率运行,基于感知信息与路由指令,提取 场景关联特征(如当前环境复杂度、障碍物威胁等级、道 路优先级等);高频实时规划器融合LLM注入的辅助特 征,在基础感知输入上,生成细粒度、实时更新的轨迹输 出。AsyncDriver的异步特征增强设计在保持推理深度 的同时,有效平衡了实时性与推理精度。
大模型生成奖励范式
在模型生成奖励范式中,大模型参与奖励设计或评 价,即帮助RL方法定义或学习奖励信号,奖励设计在 RL中更具挑战性。
基于大模型生成奖励范式的代表性方法表
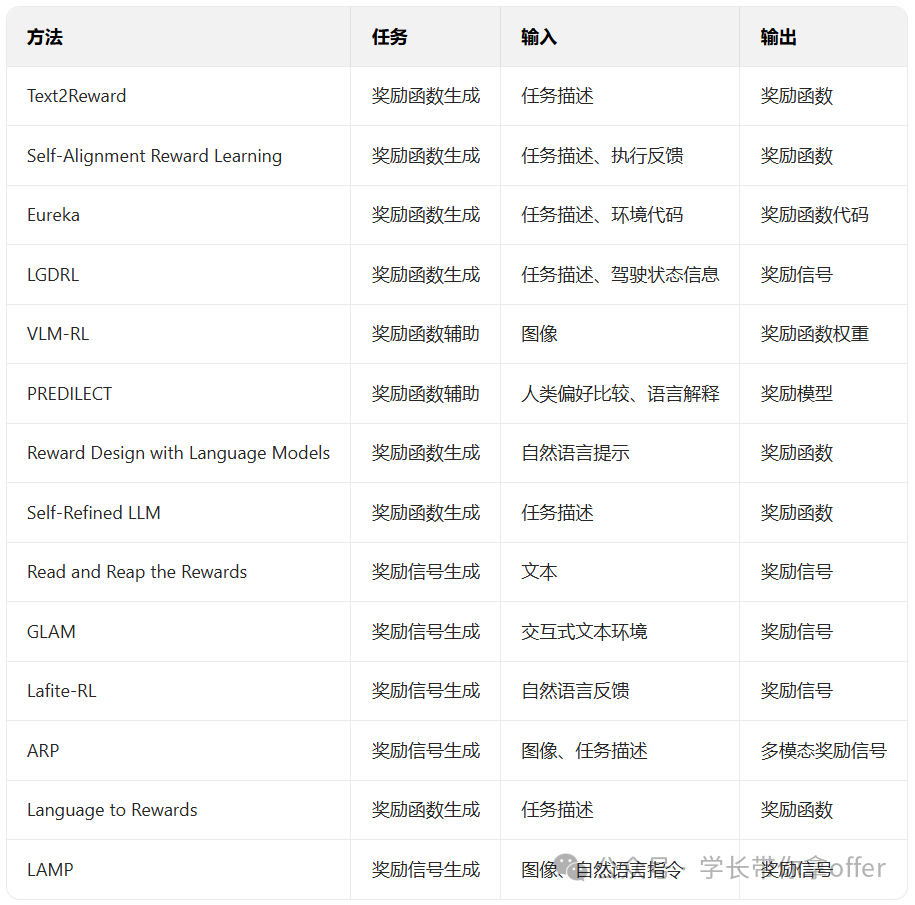
除了生成奖励函数外,一些研究探索通过直接生成奖励信号来指导强化学习训练。
现有研究表明,大模型能够将自然语言中的任务目 标、约束与优先级解析并转译为可用于策略学习的奖励 信号/函数。在若干基准与模拟任务上,其基于LLM的 奖励在成功率、累计回报等指标上可达到或超过人工设 计奖励的水平,表明自然语言可作为复杂任务奖励规范 的可行接口。但此类方法对提示模板、措辞、示例顺序 与解码参数比较敏感,容易造成奖励项或权重的不稳定,从而出现幻觉或遗漏关键安全约束。为了提升模型 的可实现性与效率,奖励更局限于环境的简化表示,而 在高保真环境下的稳定性较差。
因此,后续研究应在高保真仿真-封闭场-道路测 试的多级评测框架下,系统验证此类的可扩展性与可靠 性。通过结合人类监督与显式安全约束,纠正并约束大 模型可能产生的偏差。
结束语
融合大模型的自动驾驶决策与规划已成为当的研究热点之一,本文梳理了大模型在决策与规划输出、端到端赋能和奖励构建3类环节的作用:决策与规划输出作为高层决策器生成离散策略,或直接产出轨迹(轨迹集),用于下游控制;端到端赋能通过参数高效微调将通用模型适配到驾驶域,或在推理时注入场景先验(关键特征)以增强策略质量;奖励构建可由大模型合成可执行的奖励函数代码,并经校验后用于 策略优化;也可利用大模型解析人类偏好以训练奖励模型,部署时由轻量策略闭环执行。
尽管当前方法仍面临推理延迟、模型稳定性、表示 鸿沟以及训练与验证体系等核心瓶颈,随着模型压缩与 蒸馏、确定性输出与安全约束、多模态接口设计以及分 级验证框架的逐步完善,大模型有望在更复杂、动态的 道路环境中展现更强的泛化能力与工程价值

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)