多模态对齐与多模态融合
多模态对齐与融合是人工智能处理跨模态数据的关键技术。多模态对齐通过构建统一语义空间(如CLIP模型),让不同模态数据在向量空间中建立关联。多模态融合则通过注意力机制实现信息整合,包含早期、中期和晚期三种融合方式,应用于视频理解、医疗诊断等领域。两者结合使AI能更全面地理解和处理图像、文本、音频等多模态信息。
一句话解释
多模态对齐:如何让不同的模态的信息建立联系
多模态融合:让这些联系产生更强大的理解能力
多模态对齐是什么?
它是一个跨模态的语义桥梁。
(1)表示学习:构建统一的语义空间
设计共享表示空间,想象一个高维的数学空间,在这个空间中
- 一张猫的照片会映射到某个位置(视觉模态)
- “一只可爱的猫”这句话被映射到附近的位置(文本模态)
- 猫叫的音频也会聚集在同一区域(音频模态)
这种空间设计让AI能够理解,尽管这些数据表现的形式不一样,但是他们全部都指向一个概念“猫”。
每个模态都需要有一个专门的模态编码器,通过映射函数的学习将原始数据转换为向量表示。
关键在于训练这些编码器,使得语义相关的内容在向量空间中的距离更近
(2)对比学习:让相似的更近,不同的更远
这个主要是通过对比建立联系,对比学习就是给定一对相关的多模态数据(图片和文字的对应描述),让他们在向量空间中距离更近,同时让不相关的数据对距离更远。
CLIP模型对比学习的典型代表。
CLIP模型主要是通过大量的图文对比学习来实现的强大的跨模态理解能力。
训练过程:
- 正样本对构建:从互联网收集大量图像及其对应的文字描述
- 负样本对构建:随机匹配不对应的图文和文字
- 对比损失优化:让匹配的图文在向量空间中更近,不匹配的更远离
实际效果:
- 给定任意图片,CLIP模型能找到最匹配的文字描述
- 给定任意文字:CLIP能找到最符合的图像
- 支持零样本分类:无需额外训练就能识别新类别
(3)跨模态检索:验证对齐效果的直接方式
给定一张图片,系统能否找到最匹配的文字描述?
给定一段文字,系统能否找到最相关的图像?
图文检索是检验多模态对齐效果最直接的方式。
多模态融合是什么?
注意力机制是多模态融合的核心技术,它既能在单一模态内部建立语义管理(自注意力),又能让不同模态相互“对话”(交叉注意力)。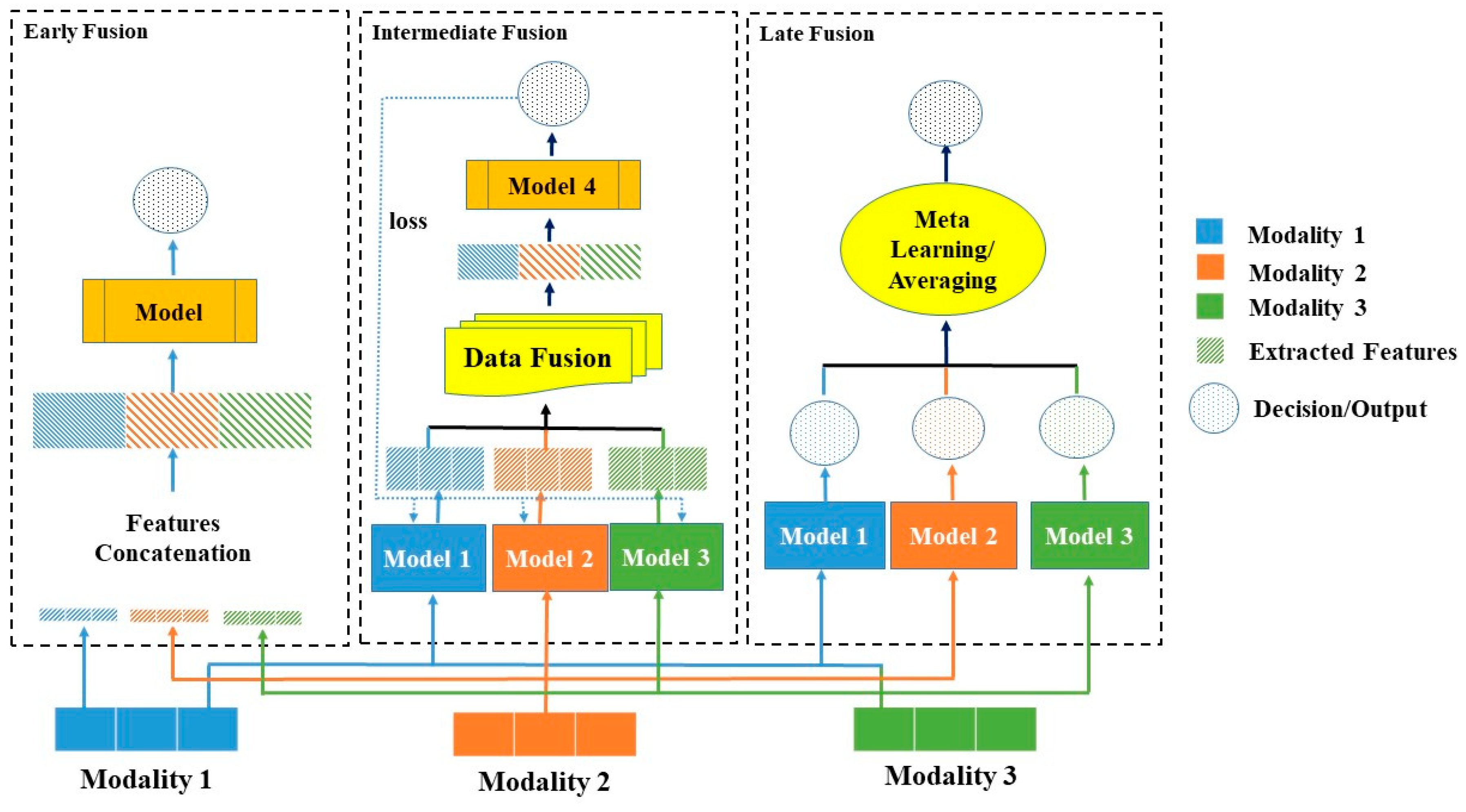
早期融合:(输入层直接融合)
在数据输入阶段就将不同模态的信息合并处理,让模型从底层开始学习跨模态的特征组合。
案例:视频理解系统
- 输入:视频帧序列 + 对应音频片段
- 处理:将每帧图像和对应时间窗口的音频特征直接拼接
- 目标:学习视听觉信息的同步关系和组合模式
- 应用:视频分类、事件检测、情感分析
中期融合:(特征层融合)
在特征提取过程中多次进行模态间的信息交换,让不同模态能够在处理过程中相互指导。
通过多层次交互和注意力机制,在保持各模态特色的同时实现整合。
实现机制:交叉注意力机制网络
- 文本处理流程:文本输入 -> BERT编码 -> 交叉注意力层 -> 文本特征
- 图像处理流程:图像输入 -> CNN/ViT编码 -> 交叉注意力层 -> 图像特征
- 交互过程:文本特征指导图像特征提取,图像特征增强文本理解。
晚期融合:(决策层集成)
让各模态独立处理较高层次,在最终决策时进行信息的整合。
应用场景:
- 医疗诊断:影响AI和文本AI分别分析,最后综合得出诊断
- 金融风控:图像识别和文本分析独立进行,决策层综合评估风险

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)