打破AI的“标签牢笼”:深入浅出彻底看懂多模态里程碑模型CLIP
CLIP 的出现是多模态领域的里程碑,催生了一系列后续工作和应用:CLIP 最重要的应用之一是作为引导信号。著名的 DALL-E 2 和 Stable Diffusion 等文生图模型,都使用 CLIP 的文本编码器来理解用户输入的文字提示,并指导扩散模型生成与之匹配的图像。
CLIP 的出现是多模态领域的里程碑,催生了一系列后续工作和应用:CLIP 最重要的应用之一是作为引导信号。著名的 DALL-E 2 和 Stable Diffusion 等文生图模型,都使用 CLIP 的文本编码器来理解用户输入的文字提示,并指导扩散模型生成与之匹配的图像。
1. 核心思想与要解决的问题
在 CLIP 出现之前,主流的计算机视觉模型(如 ImageNet 上训练的模型)存在几个固有缺陷:
封闭类别集: 模型只能识别训练时见过的、固定数量的类别。如果要新增一个类别(比如一开始训练识别动物的,要添加水果类别识别),就必须重新收集数据、重新训练模型,成本极高。
泛化能力弱: 在 ImageNet 上训练的分类模型,在处理风格、构图、任务与 ImageNet 照片差异较大的图像(如漫画、素描、医疗影像)时,性能会急剧下降。
CLIP 的核心思想是: 与其试图直接预测一个固定的标签(如“猫”),不如学习视觉概念和语言概念之间的广泛关联。
它通过一个非常简单的预训练任务来实现这一目标:判断一张图片和一段文本描述是否匹配。
这个任务不需要传统的“图像-标签”对(如 [image, "cat"]),而是需要图像-文本描述对(如 [image, "A cute cat sitting on a couch."])。互联网上有海量的这样的数据(例如图片的 alt-text 描述),这使得模型能够在大规模、多样化的数据上进行训练。
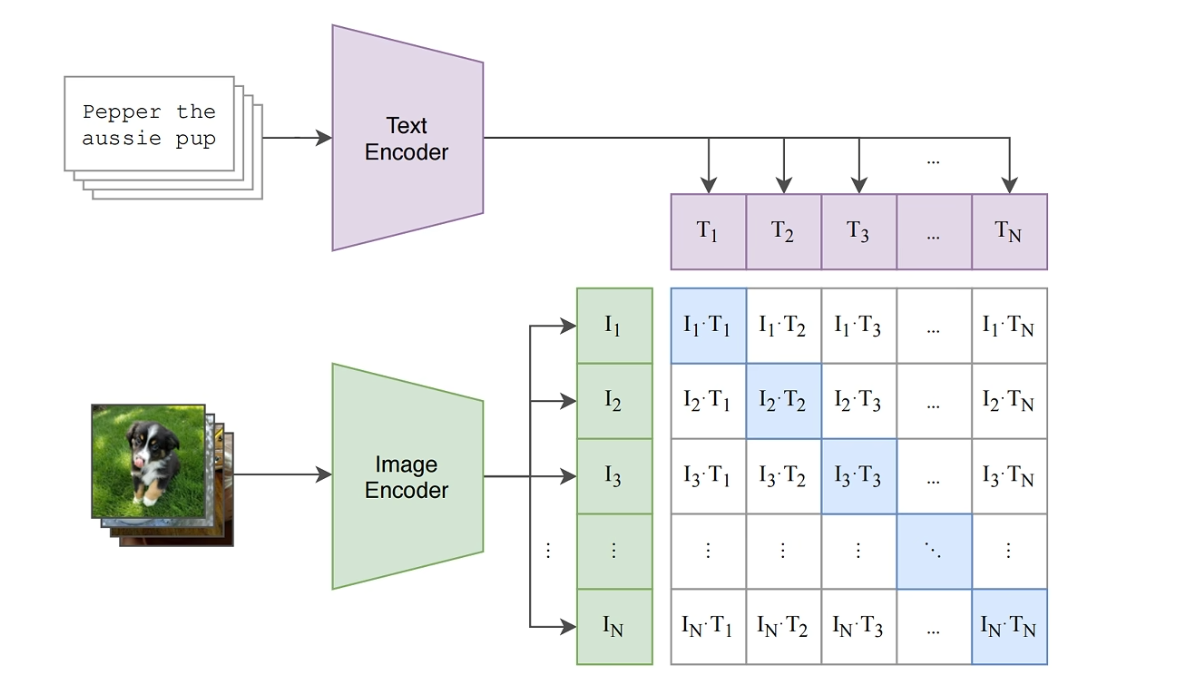
2. 模型架构:双塔编码器
CLIP核心目标是学习图像和文本之间的关联,从而将两者映射到一个共享的、有意义的特征空间中。这个强大的能力主要归功于其双塔编码器架构。
一、 什么是双塔编码器架构?
双塔编码器是一种常用于处理两种不同模态(或类型)输入的神经网络结构。想象一下两座并排矗立的塔,每一座塔都是一个独立的编码器(Encoder),负责处理一种特定的输入。
塔 A (例如,图像塔): 接收一种输入(如图片),并将其“编码”成一个固定长度的数学向量(称为 embedding)。这个向量是图片内容的浓缩表示。
塔 B (例如,文本塔): 接收另一种输入(如文字描述),并将其也“编码”成一个相同维度的向量。这个向量是文本语义的浓縮表示。
双塔架构的关键思想是:在训练过程中,两个编码器是独立工作的,它们之间没有直接的交叉连接。 只有在最后计算损失函数或进行相似度比较时,它们各自生成的向量才会被放在一起进行计算。
二、 CLIP 中的双塔架构详解
在 CLIP 模型中,这两座塔分别是 图像编码器 (Image Encoder) 和 文本编码器 (Text Encoder)。
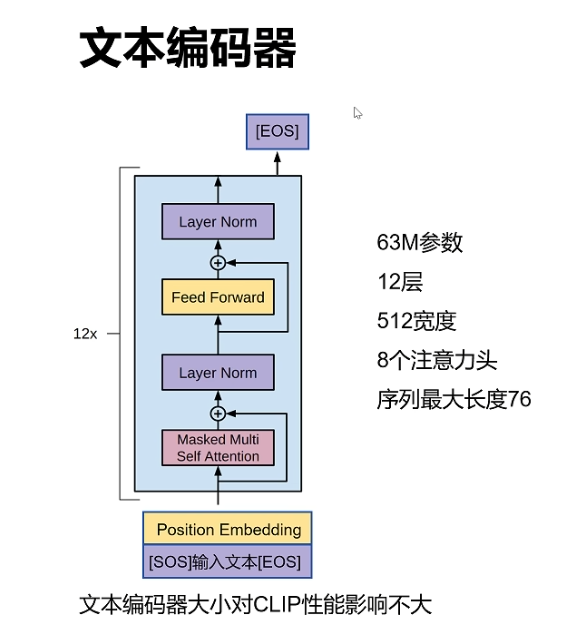
1. 图像编码器
作用: 接收一张图片作为输入,输出一个代表该图片内容的特征向量 I_f。
具体实现: OpenAI 在原论文中实验了两种主流的视觉模型作为图像编码器:
ResNet: 使用了经过修改的 ResNet-50,例如用注意力池化层(Attentional Pooling)取代全局平均池化层,以更好地聚合特征。
Vision Transformer (ViT): 这是更好的一个版本。ViT 将图片分割成一个个小块(Patches),将这些小块线性投影后,像处理单词一样送入一个标准的 Transformer 编码器中,最终提取出代表整张图片的特征向量。
无论使用哪种模型,最终目标都是将任意大小的输入图片,转换成一个固定维度(例如 512 维)的向量 I_f。
2. 文本编码器
作用: 接收一段文本作为输入,输出一个代表该文本语义的特征向量 T_f。
具体实现: CLIP 使用了一个标准的 Transformer 模型。
1.输入处理: 文本首先被分词(Tokenization),转换成数字 ID 序列。
2.编码过程: 这些 ID 序列被送入 Transformer 模型中。通过自注意力机制(Self-Attention),模型能够捕捉单词之间的依赖关系和上下文信息。
3.输出: 通常会取特定 token(如 [EOS] 或 [CLS] token)在最高层的输出,经过处理后,得到代表整个文本的特征向量 T_f。这个向量的维度与图像特征向量 I_f 相同。
3. 投影头
这是一个常被忽略但非常关键的细节。从图像编码器和文本编码器直接输出的特征向量,并不会直接用来计算相似度。它们会各自再经过一个线性投影层(Projection Head),将它们映射到最终的多模态共享空间。这个步骤可以帮助模型更好地学习两种模态之间的对齐关系。
三、 训练过程:对比学习
双塔架构的威力是在其独特的训练方式中体现出来的。CLIP 使用了对比学习的策略。
1.数据: 训练数据是海量的(图像,文本)配对。OpenAI 从互联网上收集了 4 亿个这样的配对。
2.核心思想:
对于一个正确的(图像,文本)对,模型的目标是让它们的特征向量 I_f 和 T_f 在共享空间中的距离尽可能近(即相似度尽可能高)。
对于一个错误的(图像,文本)对(例如,一张狗的图片和“一只猫的描述”这段文字),模型的目标是让它们的特征向量距离尽可能远(即相似度尽可能低)。
3.批处理训练
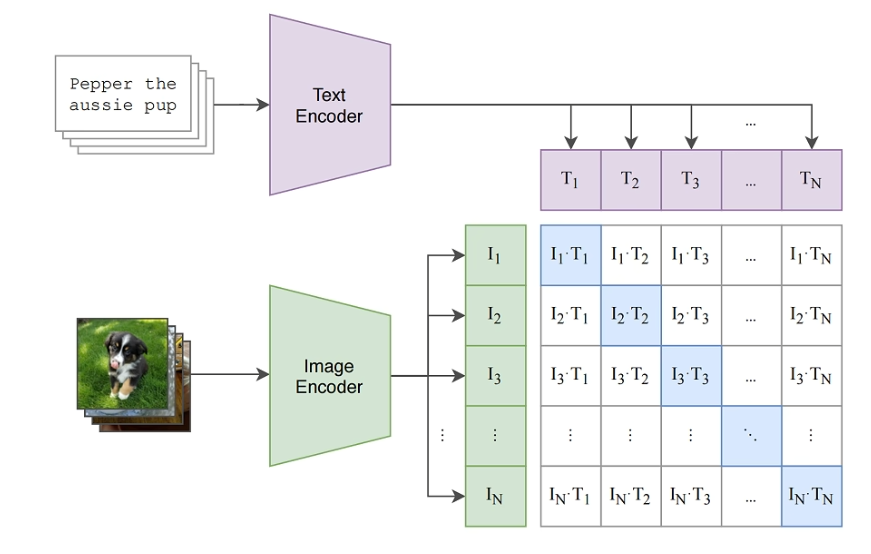
假设我们有一个大小为 N 的批次(Batch),里面包含 N 个正确的(图像,文本)对。
图像编码器会生成 N 个图像向量 I_1,I_2,...,I_N。
文本编码器会生成 N 个文本向量 T_1,T_2,...,T_N。
现在,我们可以计算一个 N×N 的相似度矩阵,其中矩阵中的每个元素 S_ij 是图像向量 I_i 和文本向量 T_j 的余弦相似度。
在这个矩阵中,对角线上的元素 S_11,S_22,...,S_NN 代表了 N 个正确的配对,它们的相似度应该被拉高。
所有非对角线上的元素(共 N2−N 个)都代表了不匹配的“负样本”对,它们的相似度应该被压低。
模型的损失函数(一种对称的交叉熵损失)就是围绕这个目标设计的,它同时在行和列两个方向上进行优化,鼓励模型准确地将每个图像与其对应的文本匹配起来。
四、 双塔架构的优势
-
推理效率极高: 这是双塔架构最显著的优点。在推理阶段(例如进行图像搜索),你可以预先将数据库里所有图片的特征向量全部计算并存储好。当用户输入一段文本进行搜索时,你只需要用文本编码器计算一次文本向量,然后用这个向量去和海量的、已算好的图像向量库进行高速的向量相似度检索。这个过程非常快,避免了每次都要将文本和图片一起输入到一个庞大模型中的巨大开销。
-
强大的可扩展性: 正是因为其推理效率,双塔模型非常适合大规模的检索系统。无论是图搜文,还是文搜图,都能轻松扩展到亿级别的数据量。
-
灵活的零样本学习 (Zero-Shot Learning) 能力: CLIP 的训练方式使其天然具备了强大的零样本分类能力。例如,要对一张图片进行分类,你不需要重新训练模型。你只需要将类别名称(如 "猫", "狗", "飞机")构造成文本描述(如 "a photo of a cat", "a photo of a dog"),然后将这些描述通过文本编码器得到各自的特征向量。最后,比较待分类图片的图像向量与哪个文本向量最相似,即可完成分类。这是单塔或融合模型难以直接做到的。
3.零样本预测:如何工作?
我们来详细拆解一下 CLIP 是如何实现其最令人惊艳的能力之一:零样本预测 。
这个过程非常巧妙,它利用了前文提到的双塔编码器架构所学习到的图文对齐能力。其核心思想是:将一个传统的分类问题,转化为一个图文匹配问题。
下面是其工作的详细步骤:
第一步:准备“候选描述”
假设你的任务是识别一张图片,并判断它属于以下哪个类别:猫 (cat)、狗 (dog)、汽车 (car)、飞机 (plane)。
在传统的监督学习中,模型输出的会是这几个类别的概率。但在 CLIP 的零样本设置中,我们不直接使用这些简单的类别名。相反,我们会将它们转换成更具描述性的文本句子,也就是“提示”或“模板”(Prompts/Templates)。
例如,我们可以使用一个模板,如 a photo of a {},然后将类别名填入:
"a photo of a cat"
"a photo of a dog"
"a photo of a car"
"a photo of a plane"
为什么需要这一步? 因为 CLIP 的训练数据是(图片,自然语言描述)对,它的文本编码器更擅长理解完整的句子,而不是孤立的单词。将类别名嵌入到一个句子中,可以更好地激活模型在预训练中学到的知识,从而得到更准确的语义向量。这个过程有时被称为“提示工程”。
第二步:分别进行图像和文本编码
现在我们有了:
-
一张待分类的输入图片。
-
一组代表所有可能类别的文本描述。
接下来,我们将它们分别送入 CLIP 的双塔编码器:
图像路径: 将输入图片送入 图像编码器 (Image Encoder)。经过处理后,输出一个代表该图片内容的特征向量,我们称之为 I_f。这个向量捕捉了图片中的视觉信息。
文本路径: 将我们准备好的每一个文本描述(例如 "a photo of a cat", "a photo of a dog" 等)逐一送入 文本编码器 (Text Encoder)。每个文本描述都会生成一个对应的特征向量。
"a photo of a cat" → T_cat
"a photo of a dog" → T_dog
"a photo of a car" → T_car
"a photo of a plane" → T_plane
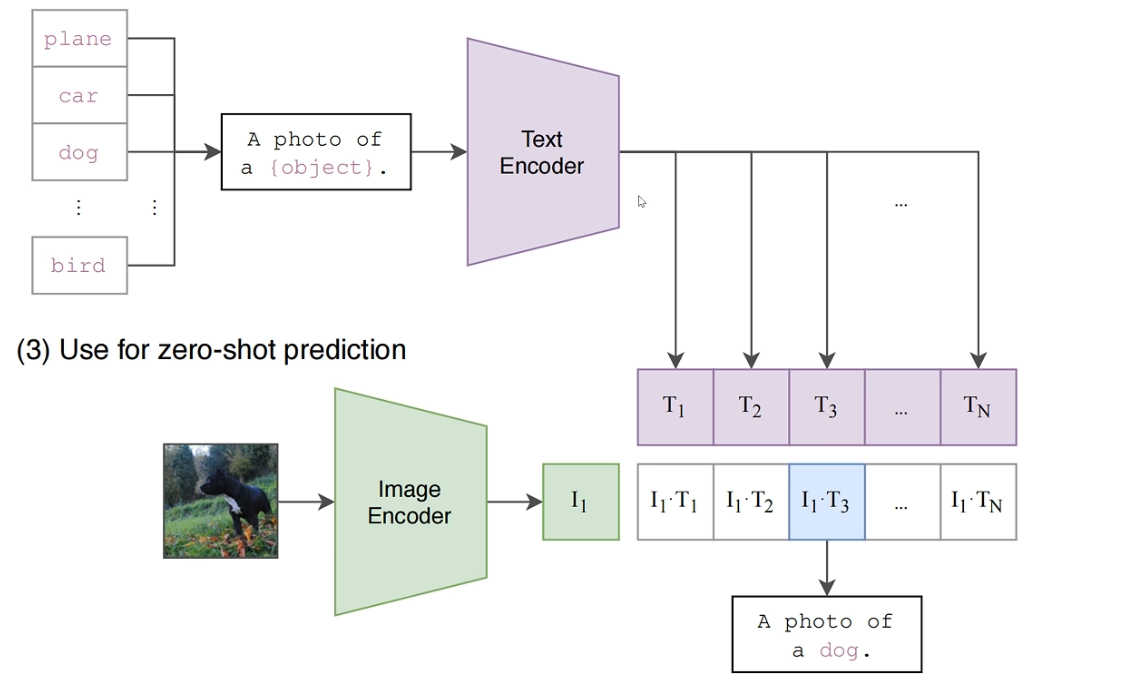
至此,我们已经成功地将一张图片和所有候选类别都映射到了同一个多模态共享空间中。
第三步:计算相似度并做出预测
既然所有的特征向量(I_f 和所有的 T_f)都在同一个语义空间里,那么它们的距离就代表了语义上的相关性。距离越近,相关性越高。
1.计算相似度: 我们计算图像特征向量 I_f 与每一个文本特征向量之间的余弦相似度 (Cosine Similarity)。
-
Similarity_cat= cosine(I_f,T_cat) -
Similarity_dog= cosine(I_f,T_dog) -
Similarity_car= cosine(I_f,T_car) -
...等等
2.选择最佳匹配: 哪个文本描述产生的相似度分数最高,就意味着它在语义上与图片最匹配。
-
例如,如果输入的图片是一只狗,那么理论上
Similarity_dog的值会是最高的。
输出预测结果: 模型最终的预测结果就是那个获得最高相似度分数的类别。
为了让输出更像一个传统的分类器,通常会将所有相似度分数通过一个 Softmax 函数。这样做可以将分数归一化,转换成一组总和为 1 的概率值。例如,对于一张狗的图片,输出可能如下:
-
猫: 0.05 (5%)
-
狗: 0.90 (90%)
-
汽车: 0.03 (3%)
-
飞机: 0.02 (2%)
显然,模型会预测这张图片是“狗”。
总结:为什么这被称为“零样本”?
这个过程被称为“零样本”是因为,模型在进行上述分类任务时,完全没有使用任何针对“猫、狗、汽车、飞机”这几个特定类别进行标注的图片进行过训练或微调。
它的分类能力完全来自于其在海量互联网图文数据上学到的通用知识。它不是在学习“识别猫”,而是在学习“将猫的视觉特征”与“‘猫’这个词的文本语义”关联起来。正是这种强大的泛化能力,使得 CLIP 可以直接应用于任何(只要是它在预训练中见过的概念)新的、未见过的分类任务,而无需任何额外的训练样本。这就是 CLIP 零样本预测的核心工作原理。
4.优势与局限性
优点:
强大的零样本性能: 在许多现有的计算机视觉数据集上,CLIP 的零样本性能可以媲美甚至超过经过全监督训练的模型。
极高的通用性与灵活性: 模型不再被固定的类别所束缚。任务可以通过自然语言指令来定义,实现了“任务无关性”。
强大的泛化与鲁棒性: 由于在极其多样化的网络数据上训练,CLIP 对分布偏移(如艺术创作、漫画、对抗性图像)的鲁棒性远高于传统的 ImageNet 模型。
可解释性: 通过观察图像与不同文本提示的相似度,我们可以窥探模型是如何“思考”的,理解它为什么做出某个决策。
局限性:
计算成本极高: 训练需要海量(4亿对)数据和巨大的算力。
细粒度分类能力较弱: 在需要精细区分的任务上(如区分汽车型号、鸟类品种),CLIP 的表现不如专门训练的模型。
对抽象概念理解不佳: 对于数字、文字等需要精确理解的任务(如“图像中有多少个苹果?”,“图片中的单词是什么?”),CLIP 表现很差。
提示工程敏感: 性能很大程度上依赖于文本提示的措辞,需要精心设计提示模板。
仍有偏见和不安全内容: 由于训练数据来自互联网,模型会继承数据中的社会偏见和可能的有害内容。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 31
31 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)