大语言模型预训练蒸馏会损害上下文学习能力?——Distilled Pretraining: A modern lens of Data, In-Context Learning and
本周速读的文章是:Distilled Pretraining: A modern lens of Data,In-Context Learning and Test-Time Scaling这篇文章介绍了预训练中使用蒸馏技术带来的负面影响——上下文学习能力的下降,及其响应的解决方案。
本周速读的论文是:Distilled Pretraining: A modern lens of Data,In-Context Learning and Test-Time Scaling
一句话总结
这篇文章展示了一种现象:即便Teacher LLM和Student LLM使用完全相同的数据集进行训练,通过Teacher LLM的Logits进行蒸馏预训练(Distilled Pretraining DPT)的Student LLM,与没有蒸馏训练的同Size模型相比,整体性能仍然更好,但也会出现pass@k效果更好,In-context Learning能力更弱的现象。
这两种现象都源于Teacher LLM的Logits分布引导带来的影响——学习Teacher模型更好但更复杂的Distribution,能让和逻辑能力相关的高熵Token的分布更合理,但也同时影响了简单任务,如纯记忆任务或token复制任务的拟合优度。毕竟2+3=这种题的答案只有一种,学一个复杂分布,不如学个简单的token 5。
澄清一下术语
这篇文章里作者提到的Test-Time Scaling仅指多次重试这一操作——甚至没有提到投票,而不包括我们通常理解的增加推理长度等其他方案。
文章中提到的Induction Task/Head,是指ICL方向的经典文章《In-context learning and induction heads》中提到的概念,即Transformer中有若干个Head负责在看到前文中出现的token1时,复制前文token1后面那个token的工作。
关键细节
1. Teacher和Student用一份数据训练,DPT训练还有优势吗?
之前一直有一种声音↓
DPT之所以成立,就是因为Teacher LLM见到了更大的数据集,间接等于Student LLM学到了更多数据带来的经验。
本文作者排除了这个因素,他在同一个数据集上:
1)先用常规 pretraining 方法训练一个 8B LLaMA 作为 Teacher;
2)再用该 Teacher 指导训练一个 Student 模型(1B);
3)用常规pretraining 训一个1B的模型
然后比较2)和3)产出的模型效果是否还有明显差异。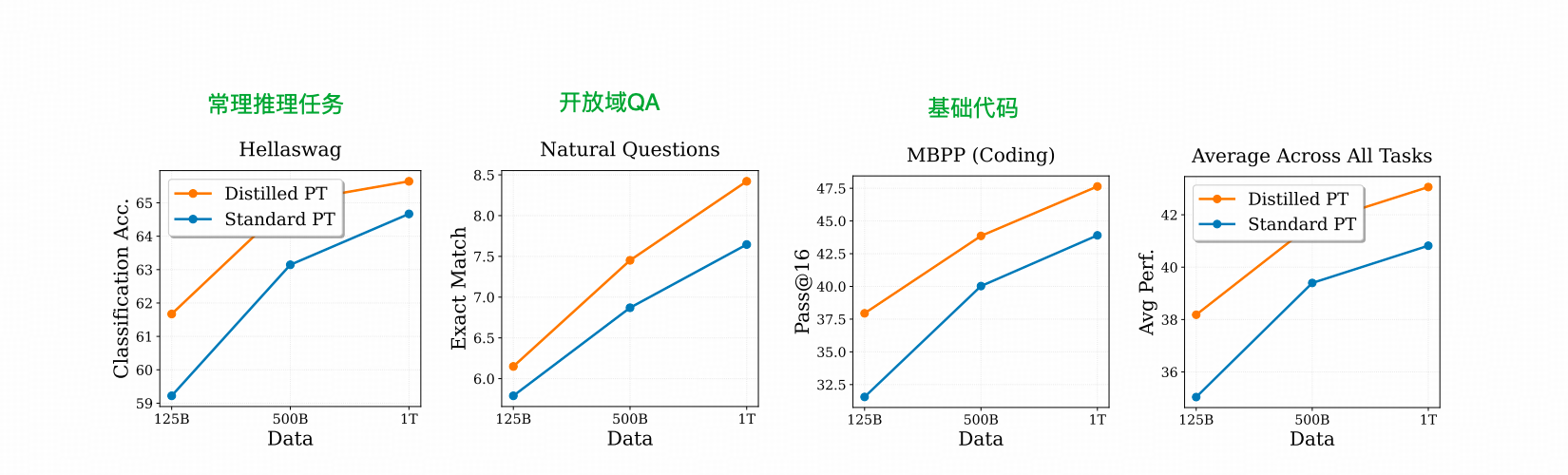
上图能够看出,在几种任务上,DPT的表现都比常规PT要好一点。
这点也体现了一个我们在Scaling Law里知道的点,参数规模越大,学习能力越强。而这种更好的结果也通过蒸馏流到了Student LLM里面。
2. Pass@K较强,ICL更弱
下图比较了两个从头开始Pretrain的LLama架构的1B模型在三个不同场景下的效果差异,一个由LLama3.1-8B模型蒸馏训练DPT(NTP 任务+蒸馏任务),一个纯NTP任务训练。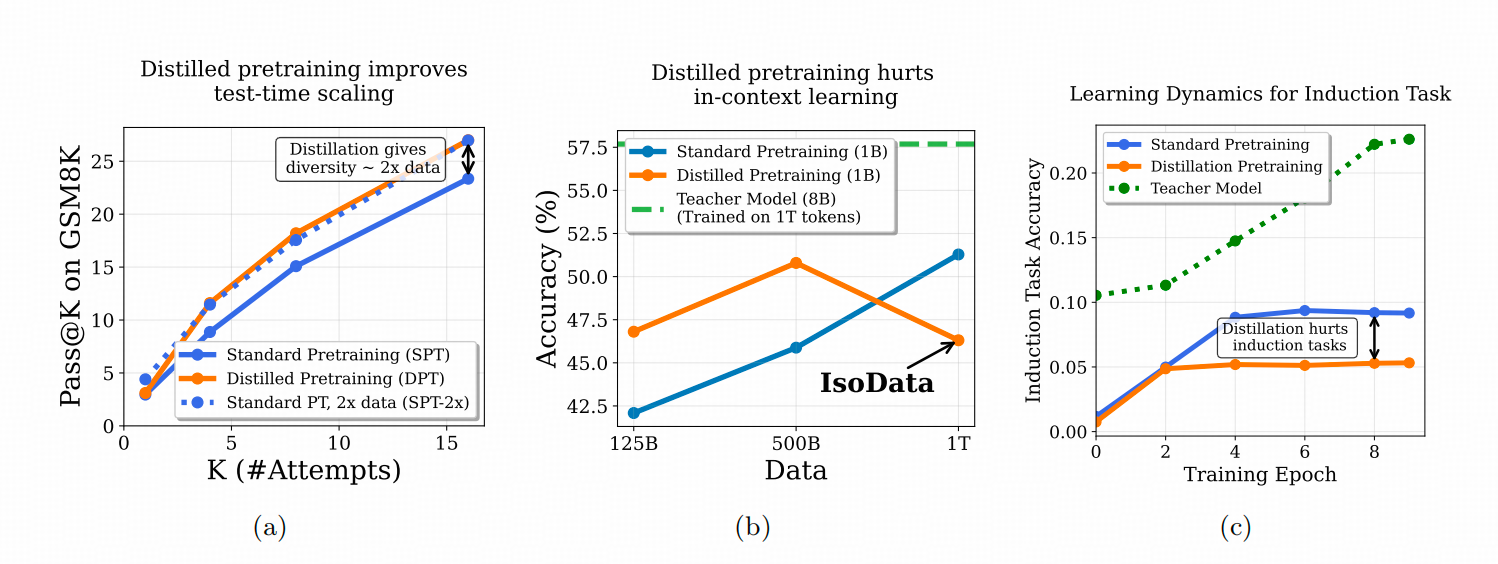
上图左1 是从pass@1扩展到pass@16的过程当中,DPT的模型的优势,左2则展示了DPT模型在几个侧重模型ICL能力的数据集上随着DPT的token增加,反而会变差。左3则展示了DPT训练的模型随着训练步数的增加,token copy这个与ICL能力高度相关的能力出现了不该有的瓶颈(如果我们认为蓝线对应的普通PT模型的能力平台是真正的瓶颈的话,两个线的GAP就是DPT单独带来的)。
其实,分析蒸馏的基本逻辑,确实存在这样的可能性,即相比于标准PT而言,DPT能在词表标签这个01标签之上,给出更多的已知分布信息。
但常规蒸馏方法的缺陷也在于,Student 模型只能通过结果分布来学习Teacher,学生本身的参数容量限制带来的局限,很可能会带来一些额外的问题。
作者用更多实验确认了DPT模型,在ICL任务上能力确实存在下降,而且随着预训练数据量的增加,常规预训练的模型的ICL能力会超过DPT。观察下图可以发现,在强依赖模型 ICL能力的反事实数据集上,DPT训练出的模型效果非常不好。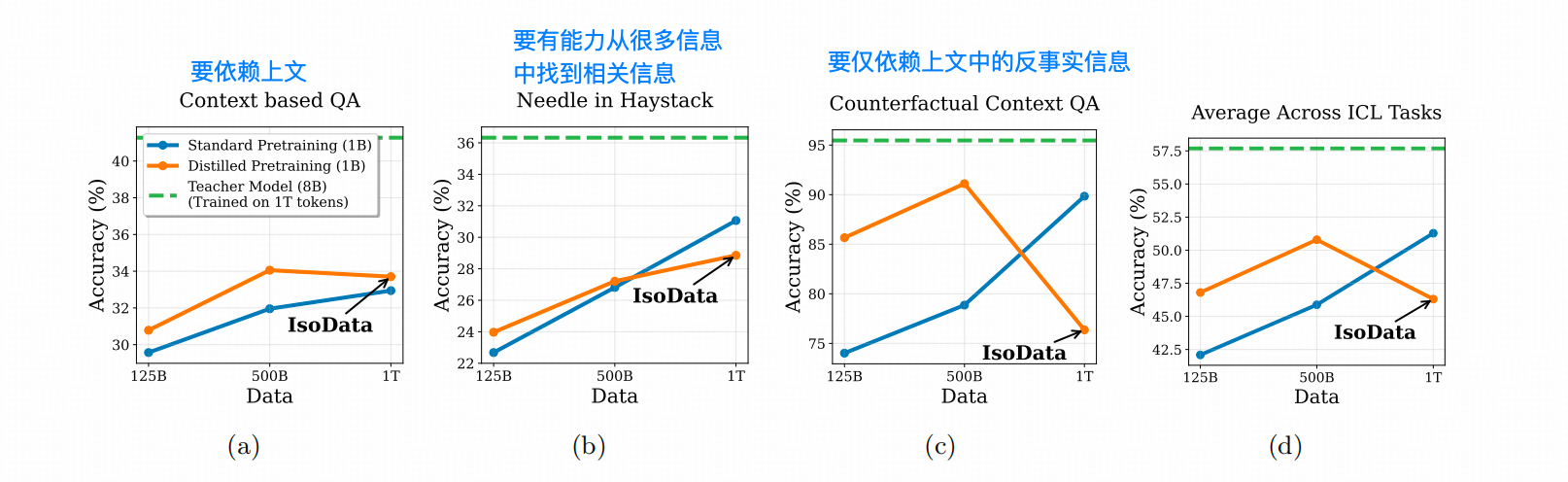
3. ICL能力减弱的原因是什么?
作者这里的控制实验的设计比较有意思,他设计了一个只有64个token的词表:
※ 1 将其中30%token设计为高熵Token,这个token之后跟着其他token的可能性很多,即多个token瓜分一个词表分布;
※ 2 将其中30% token设计为低熵token,即这个token之后跟着其他token的可能性只有一两种,即词表分布中只有一两种token的概率较高,其他的token对应的概率接近于0;
※ 3 剩下40%token,基于这两者之间。
这个词表用于一个2-gram的语言模型,并生成了序列长度全部为64的数据集。
然后,作者使用这个数据集进行常规预训练和DPT,并观察KL散度。
同时,作者构建了4000条,包含token复制任务的验证序列,例如“badkoisjadpliead”这种包含重复序列[ad]的数据,以比较常规预训练和DPT的能力差异(下图右1)。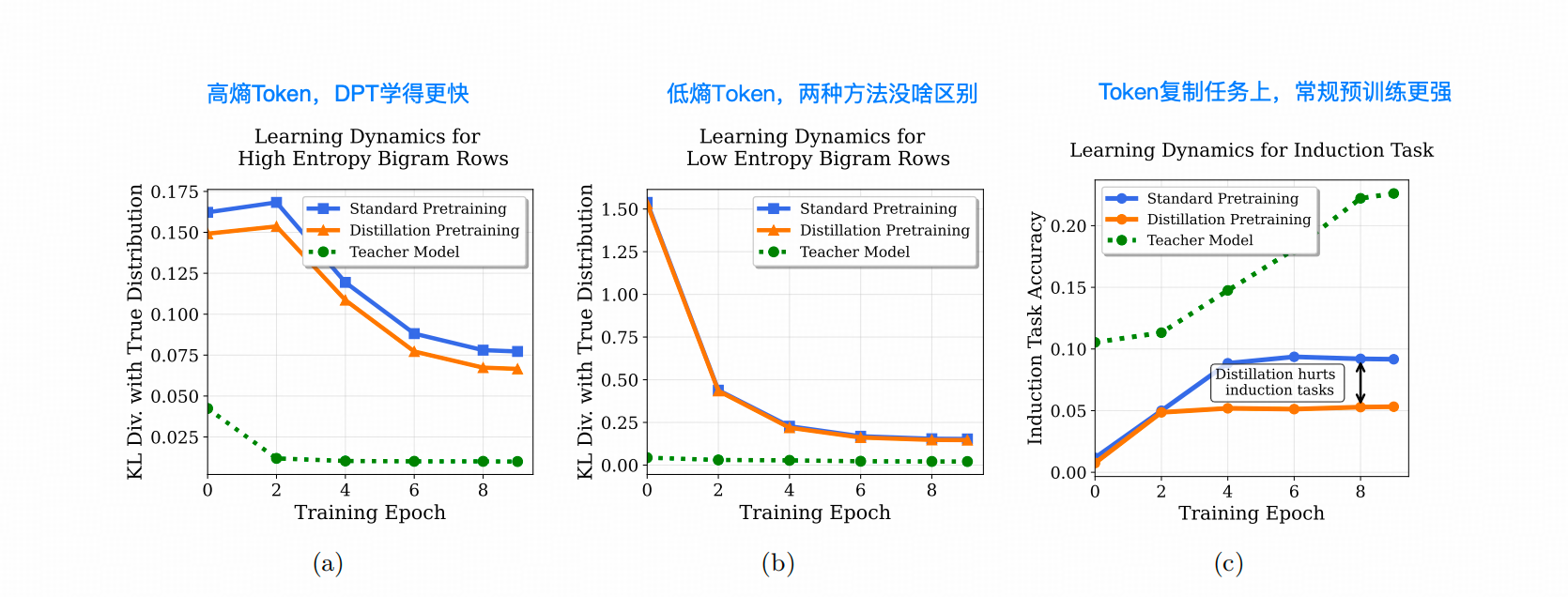
在token复制任务中,当模型看到一个重复序列的第一个token时,它需要生成重复序列的剩余token,这是ICL能力的源头之一。
DPT和常规PT在这种能力上的差异,主要是因为Teacher LLM在处理token复制任务时产生的Logits信号带来了噪声,影响了Student LLM的学习速度和方向。
而在前期的其他研究中,也提到高熵token在推理任务中对提升pass@k 非常的重要,他是优化模型推理过程中路径选择的重要支点,而DPT的蒸馏过程中,高熵Token的学习速度和最终效果(和原分布的KL divergence更小)都说明了DPT在这方面的效果。
4. 作者推荐的几种训练方案
方案1:跟80/20的方法反着来,熵最低的15%的distillation loss不要了。
这个方法一定程度上修复了DPT带来的ICL劣势。前面DPT做不过常规PT的任务上,用这种修复方法能打个平手。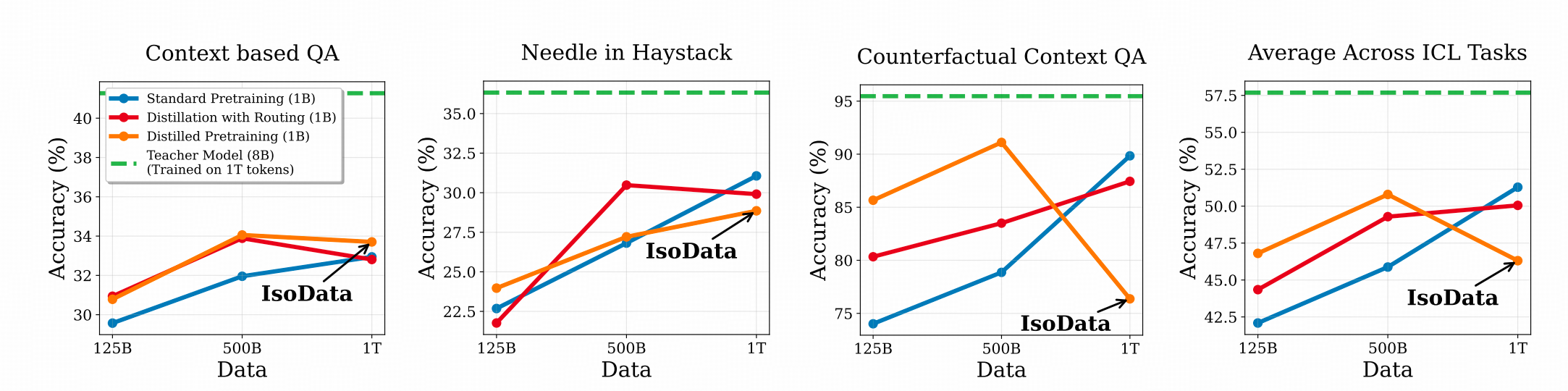
作者也试过砍掉熵最低的30%的Token的Distillation loss,但是效果变差了。
顺便说一句,基于熵选择Token学习这条路,前提确实是高熵Token对任务有关键作用——这点在推理以外的任务上,真不一定。
然后我猜作者还想再在原来的分析路径上继续突进,但没主意了,后面的就比较散了
方案2:对Teacher Logits做Topk截断
基于【Teacher Logits对在概率较高的部分可能更准,在概率较低的部分可能也不太准】这个判断,把一个Token 的Logits分布中取前TopK作为学习目标,后面的全部当做0来考虑,可能是一个有效的方案,于是作者选了K从小到大的几种可能性:[1,128,256,1024,all]。然后观察DPT的效果差异:整体看选Top-256的Logits学习,效果更好。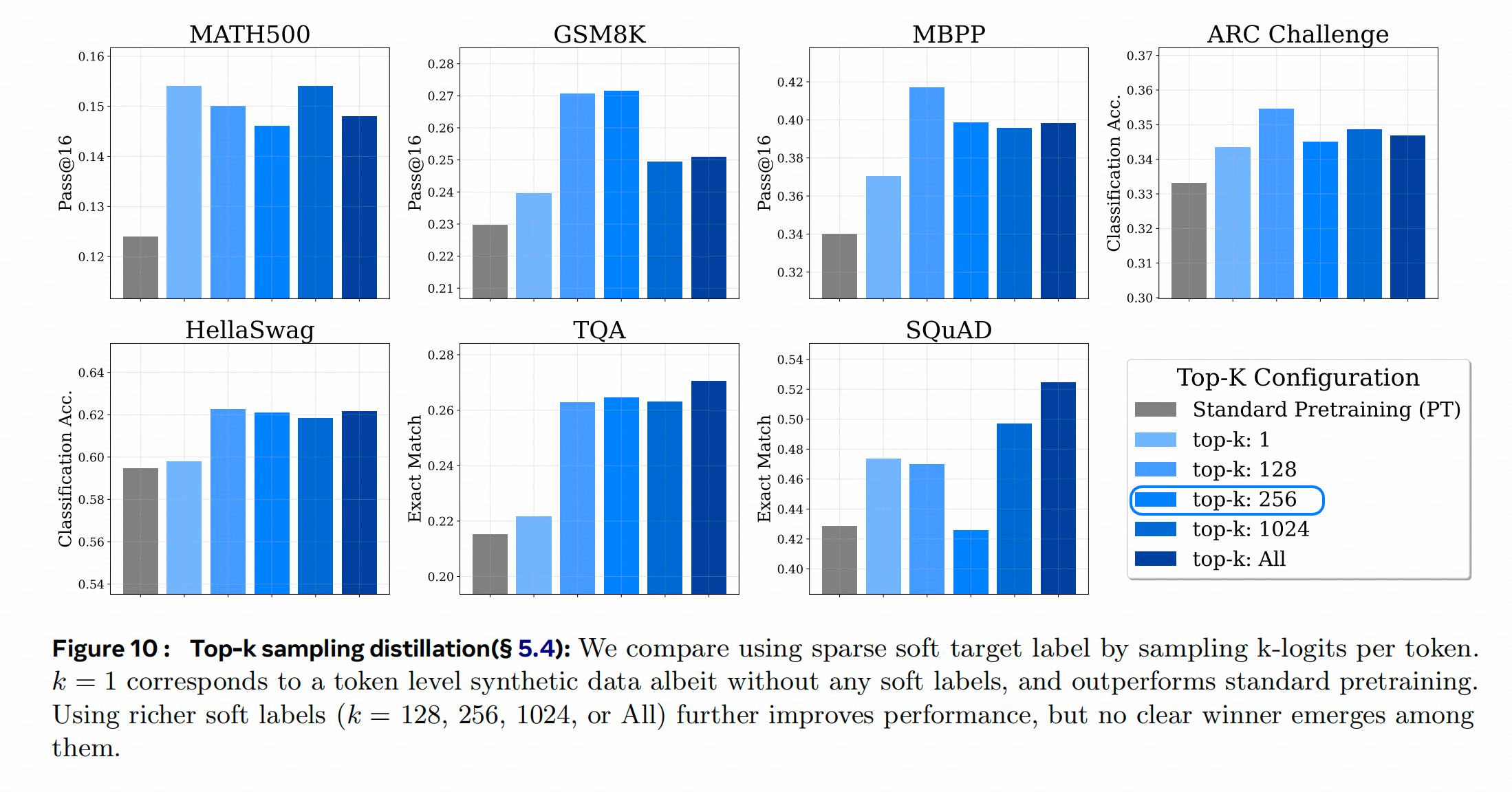
方案3:RL后的模型做Teacher更好
这个结果其实是比较符合预期的。作者用Base模型,Instruct 模型(SFT),和RL后的模型分别作为Teacher,用DPT训练1B的LLM,得到结果如下图。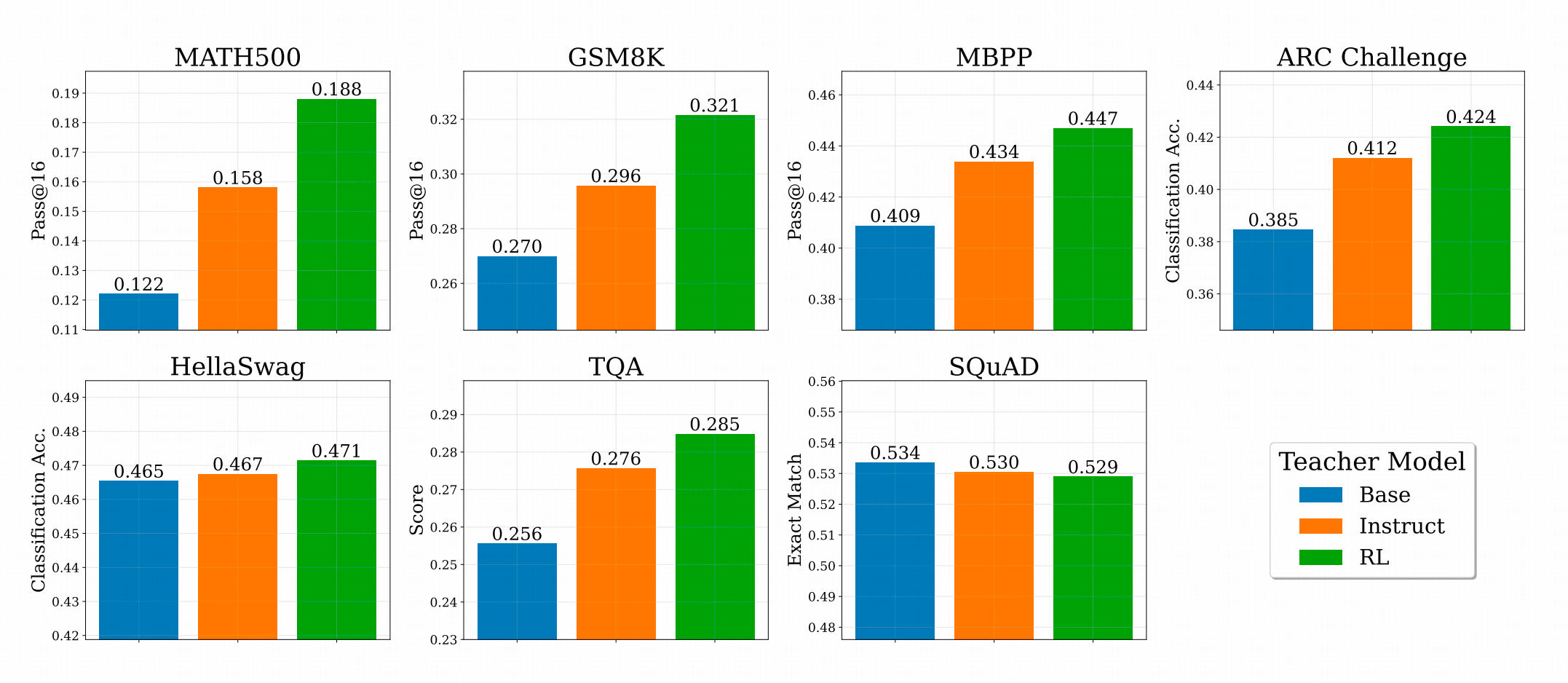
大部分任务上,都是RL的模型带来的结果更好,除了SQuAD(但作者没有拆Case进行分析,我只能盲猜因为SQuAD上文用的Wiki,SFT和RL都对他有点点遗忘?)
评价和感想
- 这篇文章着重探讨的现象很有意思——蒸馏Pretrain后,ICL的能力相对不足。
- 通过Teacher 和Student用一样的数据训练,说明了更大规模参数的模型学习的分布确实更有优势,这种优势也确实可以通过Distillation传递给小一点的模型。
- 作者在Pass@K的地方的说明好像有点问题,(这部分我没有收录)毕竟Pass@k是长序列采样后的一种准确率评估,而作者在正文里分析的是一个Token级别的分布拟合期望(也不是Pass@K准确率)
- 其实前面的文章思路相当规整,但到中后段就有点跳。其实作者在DPT的使用建议部分还比较了跟MTP之间的效果差异,不过从实验图上来看,差异真的不是很显著。而且这也跟作者的主线没什么关系,所以我也没写。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 28
28 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)