一文读懂大模型、RAG 与智能体:AI 应用的三大核心支柱
基于深度学习技术,拥有数十亿甚至数千亿参数,通过大规模数据训练,能处理复杂任务并生成高质量结果的模型。简单说,大模型就像一个 “超级大脑”,通过海量数据(比如互联网文本、图像、音频)学会了理解语言、识别图像,甚至生成内容。以大模型为 “大脑”,具备自主感知、规划、调用工具并执行多步决策,以完成目标的智能系统。简单说,智能体不是 “被动回答问题”,而是 “主动解决问题”。
在生成式 AI 爆发的今天,我们日常接触的智能聊天机器人、企业客服助手、自动旅行规划工具背后,其实离不开三大核心技术的支撑 ——大模型(Large Model)、检索增强生成(RAG)与智能体(Agent)。它们并非孤立存在,而是层层递进、相互协作,共同推动 AI 从 “能说话” 走向 “会做事”。今天我们就来系统拆解这三大技术,尤其聚焦 RAG 如何解决大模型的痛点,以及智能体如何让 AI 真正落地于复杂任务。
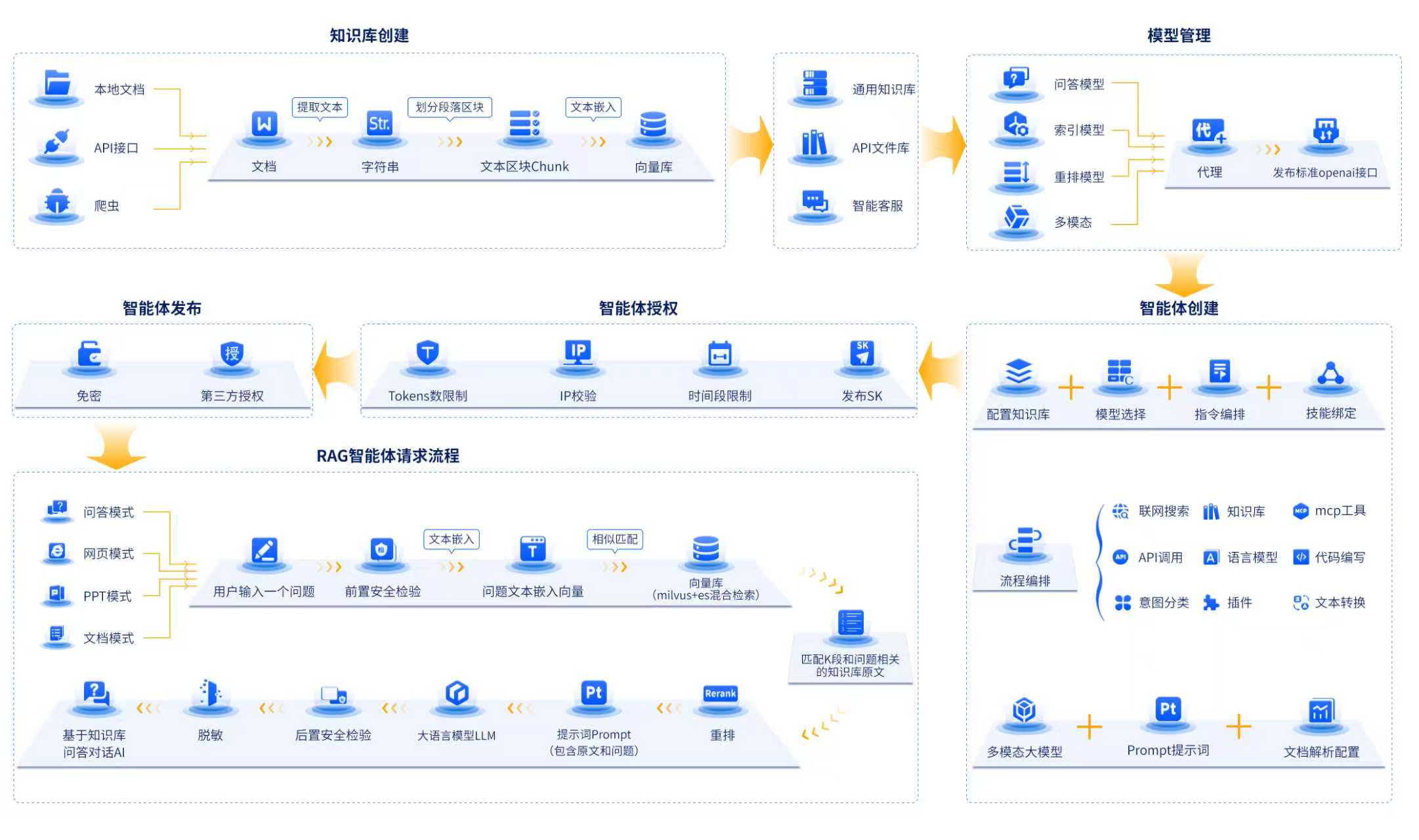
一、大模型:AI 的 “语言与推理基础”
要理解后两者,首先得从 “地基”—— 大模型说起。我们常听到的 CHAT GPT、Grok、Vision Transformer,本质上都是大模型的代表。
1. 什么是大模型?
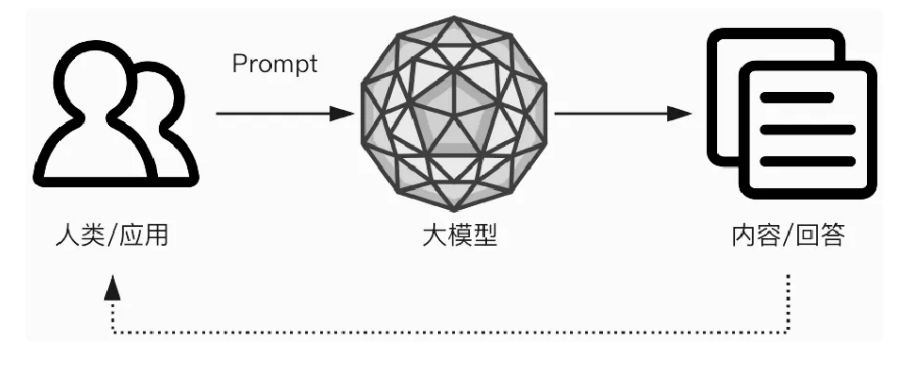
课件中对大模型的定义很明确:基于深度学习技术,拥有数十亿甚至数千亿参数,通过大规模数据训练,能处理复杂任务并生成高质量结果的模型。简单说,大模型就像一个 “超级大脑”,通过海量数据(比如互联网文本、图像、音频)学会了理解语言、识别图像,甚至生成内容。
2. 大模型的核心特点
- “大” 在规模:参数量从数十亿到数千亿,能捕捉数据中的细微规律(比如一句话里的隐含语义);
- 泛化能力强:训练后无需针对每个任务重新开发,就能处理翻译、摘要、问答等多种任务(比如用同一个大模型既能写文案,又能答问题);
- 生成能力突出:能输出连贯、高质量的文本(比如写邮件、编故事)或图像(比如 DALL-E 生成插画);
- 但并非完美:存在明显短板 —— 比如会产生 “幻觉”(编造不存在的信息)、知识过时(训练数据截止后无法更新)、可解释性差(不知道答案是怎么来的),而且训练需要巨额计算资源(GPU 集群跑几周甚至几个月)。
3. 大模型的 “痛点”:为何需要后续技术补充?
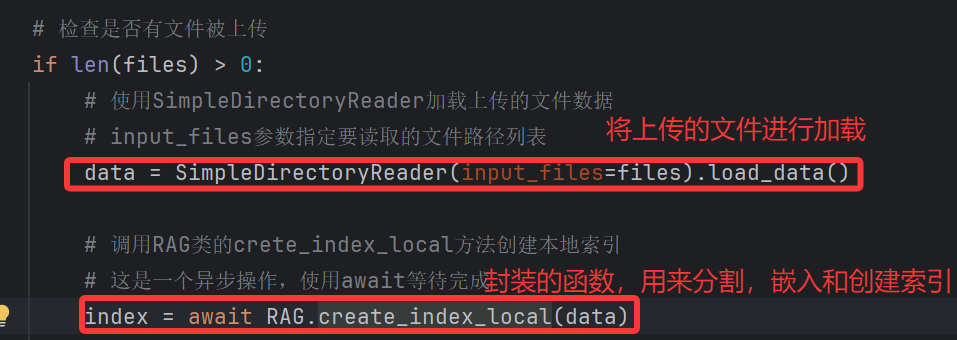
正是因为大模型存在 “幻觉”、“知识过时” 等问题,直接用它做企业级应用(比如金融咨询、医疗问答)风险很高 —— 想象一下,客服机器人告诉用户 “你的订单明天到”,结果实际要等一周,这就是大模型 “失忆”(没实时物流数据)导致的错误。而解决这些痛点的关键,就是 RAG。那什么是RAG呢,接下来就要我为大家来介绍一下RAG的基本知识点。
以下是添加了RAG后的图示:
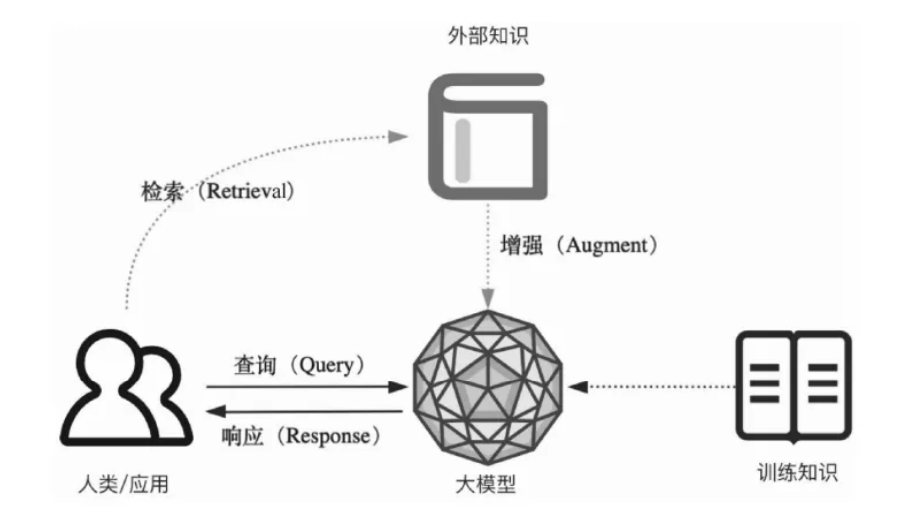
二、RAG:给大模型 “装一个实时知识库”
RAG(Retrieval-Augmented Generation,检索增强生成)是近几年 AI 应用的 “明星技术”,核心思路特别简单:让大模型在生成回答前,先 “查资料”—— 从外部知识库中检索最新、最准确的信息,再结合这些信息生成结果。相当于给大模型配了一个 “实时字典”,彻底解决了它 “凭记忆答题” 的毛病。
1. 为什么需要 RAG?—— 精准解决大模型 3 大核心痛点
- 消除 “幻觉”:大模型不再靠 “脑补”,而是基于检索到的真实资料(比如企业文档、物流数据)生成回答,事实一致性大幅提升;
- 解决 “知识过时”:外部知识库可以实时更新(比如每天同步最新的产品信息、政策文件),无需重新训练大模型,成本极低;
- 适配 “专业领域”:对医疗、法律等需要专业知识的场景,只需把行业手册、法规文档存入知识库,大模型就能快速 “上手” 专业问答,无需复杂微调。
例子:
电商客服场景就是一个典型例子:当用户问 “我上周买的商品什么时候到?”,RAG 会先检索订单数据库里的物流信息(比如 “2024 年 12 月 25 日发货,12 月 30 日送达”),再让大模型基于这个信息生成自然语言回答 —— 既准确又实时,完全避免了大模型 “瞎猜” 的问题。
2. RAG 的技术架构:从 “数据准备” 到 “生成回答” 的全流程
RAG 的工作分为两大阶段:数据索引阶段(提前准备可检索的知识)和数据查询阶段(实时响应用户问题),每个阶段都有明确的步骤,缺一不可。这个过程非常重要,需要理解和记忆,后续代码的基本过程和逻辑也是按照这个基本流程来进行一个实现。
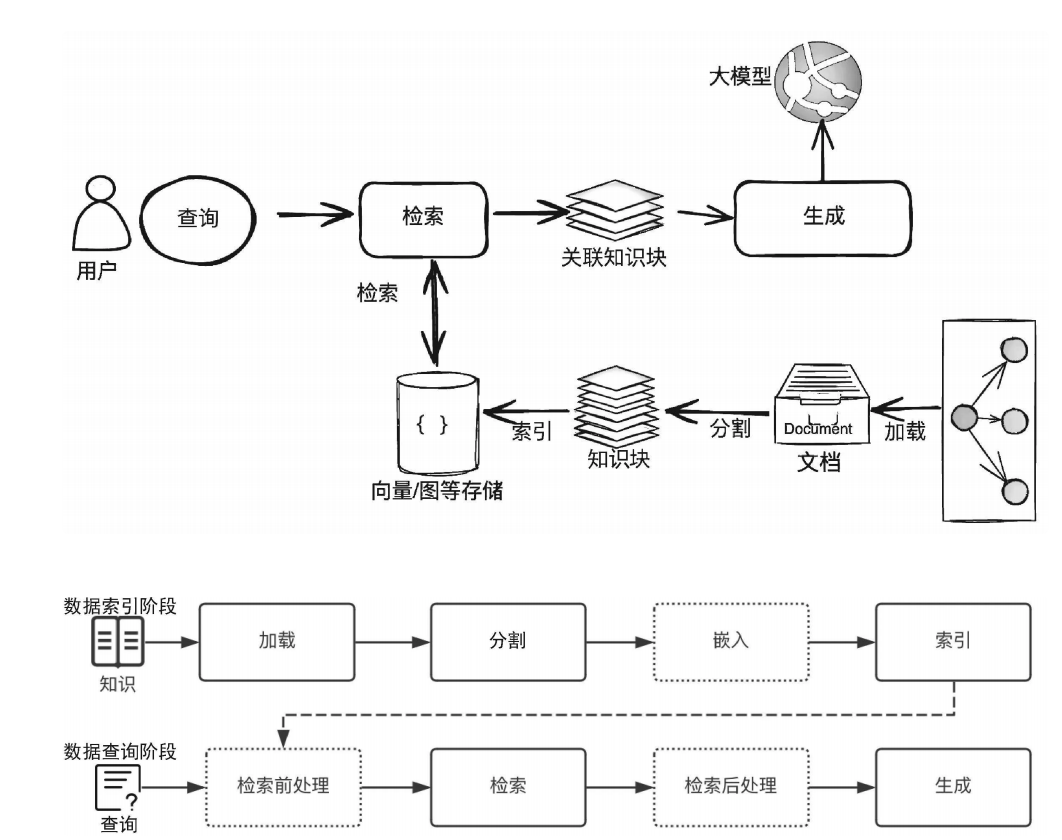
(1)数据索引阶段:把 “知识” 整理成大模型能查的格式
这一步是 RAG 的 “地基”—— 如果知识没整理好,后续检索就会 “查不到” 或 “查不准”。核心步骤有 4 个:
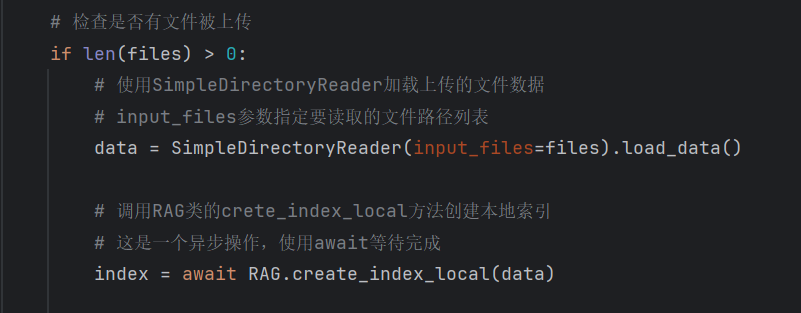
- ① 加载(Loading):收集所有需要的知识来源,比如企业内部的 PDF 手册、Excel 订单表、网页信息,甚至 API 接口返回的数据(比如物流系统 API);
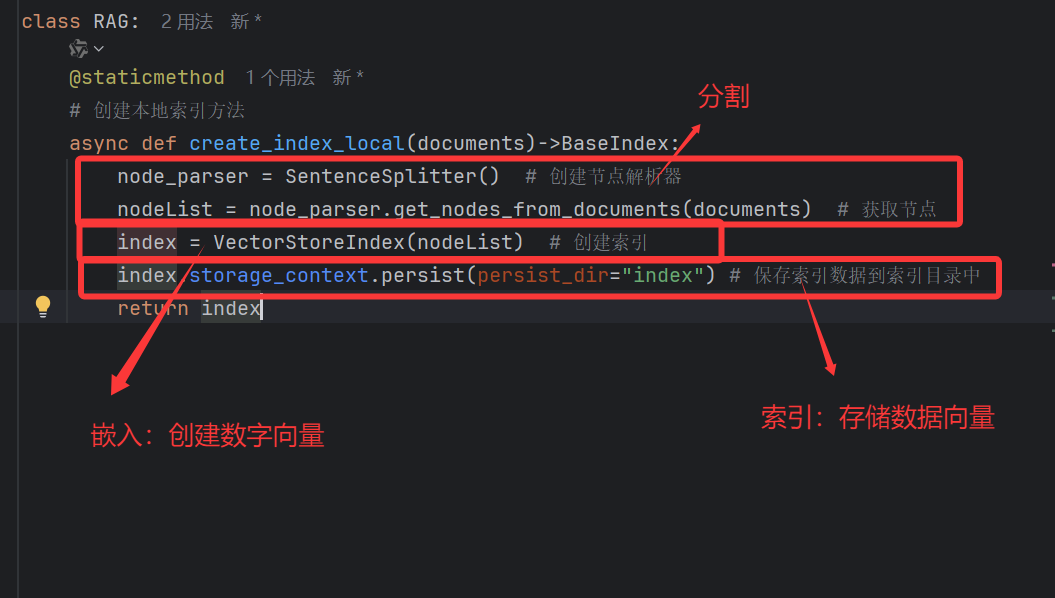
- ② 分割(Splitting):把大文档拆成小 “知识块”(Chunk)。比如一本 100 页的产品手册,拆成每 300 字左右的段落 —— 为什么要拆?因为大模型一次能处理的文本长度有限(上下文窗口限制),小知识块更易检索和使用;
- ③ 嵌入(Embedding):把文字 “翻译” 成电脑能懂的 “数字向量”。这里需要用到 “嵌入模型”(比如 OpenAI 的 text-embedding-3-small),它会把每个知识块变成一串数字(比如 1024 维的向量),而且语义相似的文字,向量距离会更近(比如 “发货” 和 “物流” 的向量很接近);
- ④ 索引(Indexing):把生成的向量存入 “向量数据库”(比如 Milvus、Pinecone)。向量数据库能快速计算 “用户问题向量” 和 “知识块向量” 的相似度,从而找到最相关的知识 —— 这比传统的 “关键词检索”(比如搜 “发货” 只找含这两个字的内容)更智能,能理解语义(比如搜 “我的快递到哪了” 也能找到物流信息)。
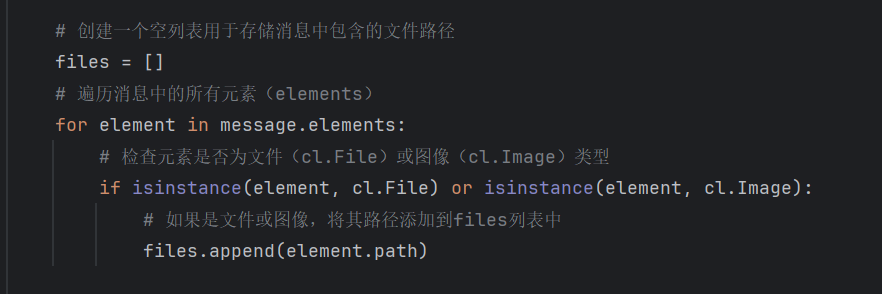
(2)数据查询阶段:实时响应用户,“查资料 + 写回答”
当用户提出问题后,RAG 会按以下步骤生成回答:
- ① 检索前处理:优化用户问题,比如把模糊的 “我的订单进度” 补充成 “查询用户 XXX 在 2024 年 12 月 20 日下单的订单物流进度”,提升检索准确性;
- ② 检索(Retrieval):把用户问题也转成向量,在向量数据库中找相似度最高的前 K 个知识块(比如前 5 个最相关的物流信息片段);
- ③ 检索后处理:过滤无用信息(比如过时的物流数据),给知识块排序(最相关的放前面),避免干扰大模型;
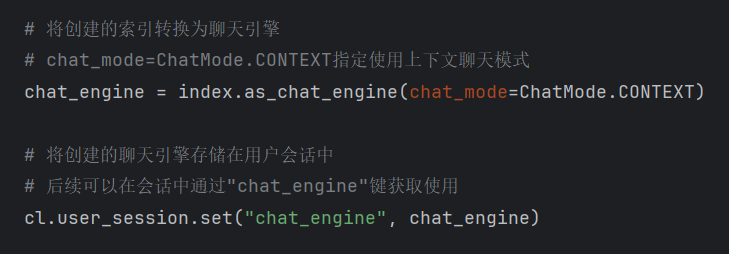
- ④ 生成(Generation):把 “用户问题 + 排序后的知识块” 一起传给大模型,再用精心设计的 Prompt(比如 “基于以下物流信息,用口语化的方式回答用户:XXX”)引导大模型生成准确回答。
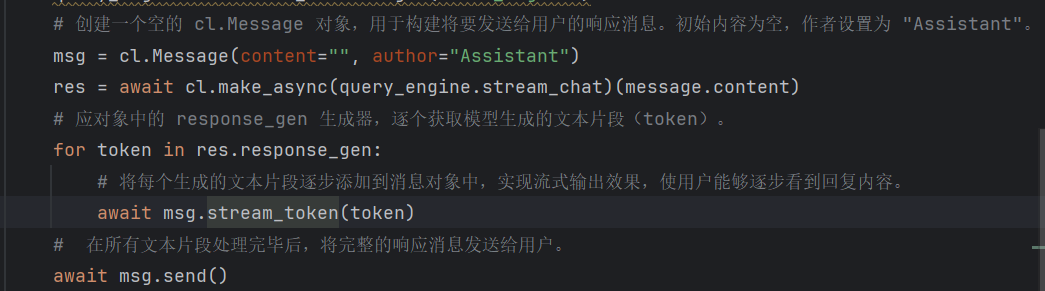
3. RAG 面临的挑战:看似简单,落地不易
虽然 RAG 思路清晰,但实际应用中仍有不少坑需要踩:
- 检索召回的精确度:如果检索到的知识块是无关的(比如用户问物流,却拿到了产品售后政策),大模型再厉害也会生成错误回答;
- 大模型的抗干扰能力:如果知识块里有矛盾信息(比如同一订单有两个不同的物流时间),大模型需要能识别并判断哪个是对的;
- 上下文窗口限制:大模型一次能处理的 token 有限,如果检索到的知识块太多,可能塞不进输入,需要权衡 “知识数量” 和 “窗口大小”;
- RAG 与微调的选择:什么时候用 RAG(比如知识更新快的场景),什么时候用模型微调(比如需要深度理解行业逻辑的场景),需要根据业务需求判断;
- 响应性能:RAG 比大模型直接回答多了 “检索” 步骤,如果向量数据库查询慢,会导致用户等待时间变长,需要优化性能。
三、智能体(Agent):让 AI 从 “会回答” 到 “会做事”
如果说大模型是 “大脑”,RAG 是 “知识库”,那智能体就是 “行动派”—— 它能把大模型的推理能力和 RAG 的知识检索能力结合起来,自主规划步骤、调用工具、执行复杂任务,真正落地于实际业务。
1. 什么是智能体?
中给出了核心定义:以大模型为 “大脑”,具备自主感知、规划、调用工具并执行多步决策,以完成目标的智能系统。简单说,智能体不是 “被动回答问题”,而是 “主动解决问题”。
例子:
比如我们常用的 “旅行规划助手” 就是一个智能体:当你说 “帮我规划 3 天上海游”,它会先调用大模型分析你的需求(比如是否偏好景点 / 美食),再用 RAG 检索上海最新的景点开放时间、酒店价格,接着调用机票预订 API 查航班,最后整合所有信息生成详细行程 —— 这一系列步骤,都是智能体自主完成的,无需你手动操作。
2. 智能体的核心特点
- 知识来源更广泛:不仅用大模型的预训练知识和 RAG 的外部知识库,还能接入实时传感器数据(比如天气 API)、第三方工具(比如支付接口);
- 自主决策能力:能拆解复杂任务,比如把 “旅行规划” 拆成 “确定行程天数→选景点→订酒店→查交通” 等步骤,再一步步执行;
- 可追溯与可控:会记录完整的 “思维链 + 工具调用日志”,比如为什么选 A 酒店而不是 B 酒店,方便后续审计和调整;
- 适用复杂任务:擅长处理多步、需要交互的任务,比如智能运维(检测服务器故障→调用日志工具查原因→自动生成修复方案)、数据分析(导入数据→调用统计工具分析→生成可视化报告)。
3. 智能体的技术组件:缺一不可的 “行动模块”
要实现自主决策,智能体需要多个组件协同工作:
- 规划器(Planner):负责拆解任务、制定步骤,比如把 “数据分析” 拆成 “数据导入→清洗→建模→可视化”;
- 工具箱(Toolset):包含智能体能调用的所有工具,比如 API 接口(机票预订、天气查询)、软件工具(Excel、Python 脚本);
- 记忆(Memory):存储任务过程中的信息,比如用户之前说过 “不喜欢人多的景点”,记忆模块会记住这个偏好,后续规划时避开;
- 执行器(Executor):负责执行规划好的步骤,比如调用机票 API 查询航班,或运行 Python 脚本分析数据;
- 反馈回路(Feedback Loop):根据执行结果调整方案,比如预订酒店时发现满房,会自动换其他酒店并重新规划。
4. 智能体的挑战:想 “完美做事” 没那么容易
- 任务分解准确性:如果把 “旅行规划” 拆错步骤(比如先订酒店再选景点),可能导致行程不合理;
- 工具可靠性:如果调用的 API 故障(比如天气 API 返回错误数据),智能体需要能识别并切换备用工具;
- 安全权限管理:智能体可能调用支付、日志等敏感工具,如何防止越权操作(比如擅自转账)是关键;
- 复杂流程调试:多步任务的流程复杂,一旦某个环节出错,排查问题的难度很大。
四、三者的关系:层层递进,缺一不可
看到这里,你可能已经发现:大模型、RAG、智能体不是相互替代的关系,而是 **“基础→增强→落地”** 的层层递进关系,具体可以总结为三句话:
- 大模型是 “地基”:提供最核心的语言理解和生成能力 —— 没有大模型,RAG 无法生成自然语言回答,智能体也无法做推理规划;
- RAG 是 “知识增强器”:解决大模型 “幻觉” 和 “知识过时” 的痛点,让大模型的回答更准确、更实时 —— 相当于给 “地基” 加了 “知识库支柱”;
- 智能体是 “应用落地载体”:把大模型的推理能力和 RAG 的知识检索能力结合起来,通过调用工具、多步决策,让 AI 从 “能说话” 变成 “会做事”—— 相当于在 “支柱” 上搭建了 “实际应用的房子”。
举个具体例子:企业智能客服机器人(智能体)的工作流程是这样的:
- 用户问 “你们最新款手机的电池容量是多少?”;
- 智能体的规划器判断 “需要先查产品信息”,让执行器调用 RAG 模块;
- RAG 模块检索产品知识库(提前索引好的 PDF 手册),找到 “最新款手机电池容量 5000mAh” 的知识块;
- 大模型基于这个知识块,生成口语化回答(“我们最新款手机的电池容量是 5000mAh,续航能满足一天使用哦~”);
- 智能体把回答返回给用户,同时记忆模块记录 “用户关注电池容量”,后续推荐时可优先提续航优势。
五、总结:AI 应用的未来,在于三者的协同进化
大模型让 AI 有了 “理解与生成” 的基础,RAG 让 AI 有了 “准确与实时” 的知识,智能体让 AI 有了 “自主与落地” 的能力。这三大技术的协同,正在推动 AI 从 “实验室” 走向 “产业界”—— 从简单的聊天机器人,到复杂的企业运维、医疗诊断、教育辅导,未来我们会看到更多基于 “大模型 + RAG + 智能体” 的 AI 应用,真正融入日常生活和工作。
如果你想入门 AI 应用开发,可以学习 “基于 llama-index 搭建 RAG 聊天功能”(比如用 DeepSeek 大模型、向量数据库做检索)是很好的实践起点 —— 从简单的 RAG 应用入手,再逐步探索智能体的开发,你会更直观地感受到这三大技术的魅力~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 30
30 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)