【论文阅读笔记】Exploring Hierarchical Molecular Graph Representation in Multimodal LLMs
本文提出M³LLM框架,首次系统研究分子图层级表示(原子/官能团/分子级)在多模态大模型中的作用。通过设计层级图编码器和两阶段训练策略(特征对齐预训练+LoRA微调),探究了不同特征融合策略对下游任务的影响。实验发现:1)不同任务需要不同层级特征(如反应预测需图级全局信息,分子描述需官能团语义);2)当前静态特征融合方式存在局限;3)LLM更依赖SELFIES文本模态而非图结构特征。研究为开发动态
原文:https://arxiv.org/abs/2411.04708
摘要
- 首次系统性研究了分子图的层级表示(节点、基序、图级)在多模态 LLMs 中的作用。
- 提出了 M³LLM 架构,该架构设计了层级图编码器以提取多级分子特征,并通过投射器实现特征与 LLMs 的对齐,同时采用两阶段(对齐预训练、LoRA 微调)训练策略。
- 通过不同特征融合策略的实验,揭示了不同下游任务对分子图层级特征的差异化需求,指出当前静态特征融合的局限,并为未来设计动态投影仪提供了关键 insights。
背景
- 当前与分子相关的多模态大型语言模型缺乏对图特征的全面理解。
- 静态处理不足以用于分层图特征。
现有方法
SELFLES/SMILES——>文本
微调多模态LLMs
微调多模态LLMs
GIT-MOL
InstructMol
指令微调/LORA微调
问题:
- 忽略了分子图的多层级特征
- InstructMol,仅仅使用节点信息,忽略复杂结构信息和语义信息
- 仅考虑单一层面(原子层面),无法充分理解整个分子
本文的贡献
思考:
- 不同层次的特征如何影响各种任务?
- 哪个级别的层次是最关键的?
- 结合多个层次的特征是否能提高多模态分子模型的性能?
方案:
-
设计多层级图编码器,参考MoleculeSTM
-
产生三个层次的特征——原子级、功能团级和分子级
-
分别提取3层次特征喂给LLM训练
最优的特征级别,因任务而异
主要工作:
- 综合研究了用于训练多模态LLMs的多层级图表达
- 提出结构,图模态特征提取+投影以对齐LLMs
- 通过多种特征融合策略,评估了每个特征层级在五个关键下游任务中的影响
方法
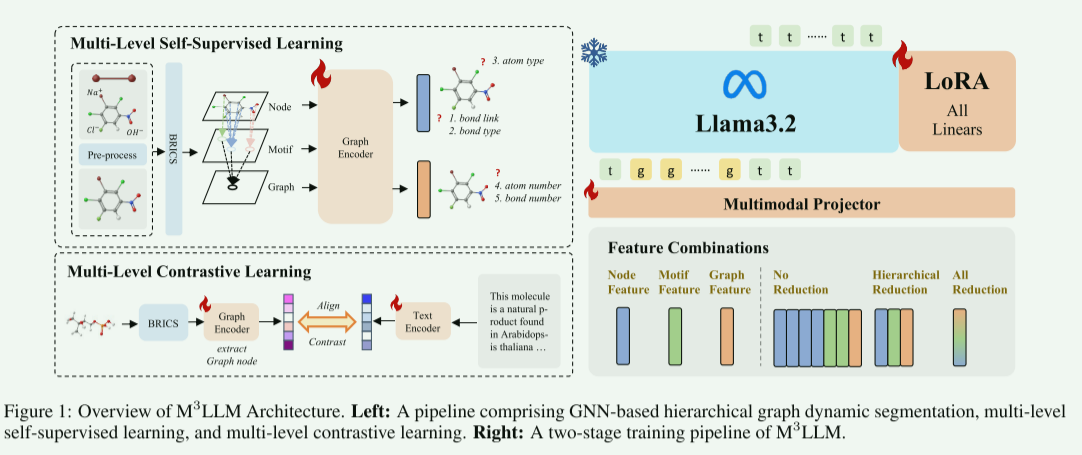
stage1:对齐预训练
-
遵循框架LLaVA框架
- 冻结除了projector以外的参数
- 让projector学习如何对齐图特征空间和LLM的嵌入空间
- 构建完成分子描述任务的模型
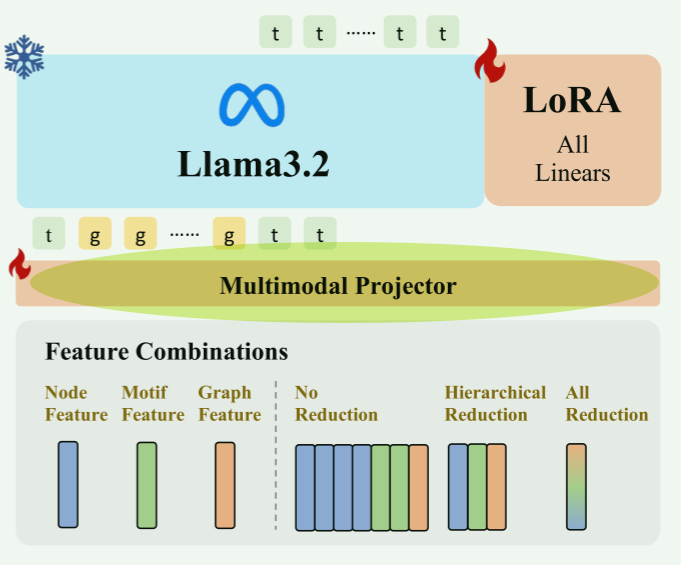
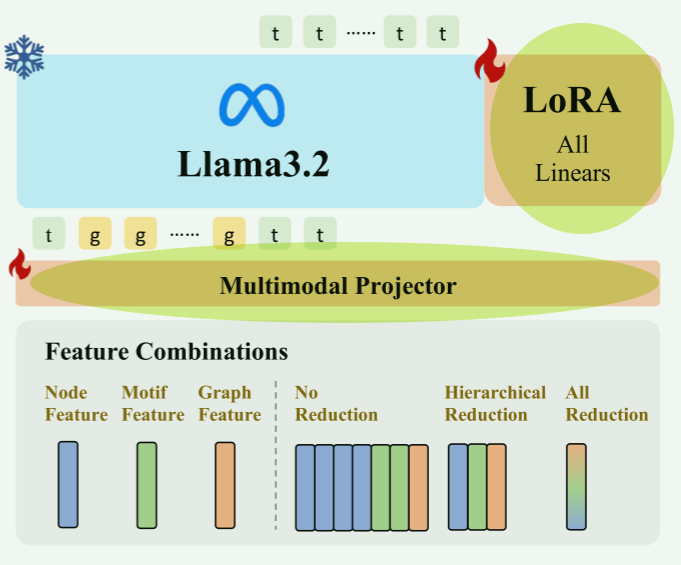
stage2:LORA微调
- 冻结图encoder和LLM
- 激活projector和LoRA权重
- 微调得到5种(下游)任务的LoRA adapter
stage3:设计分层图编码器
stage按文章顺序列的,我觉得这才应该是第一步QvQ
问题:
- 现有高维特征提取方法仍然缺乏精细的分子语义和结构信息。
- 现有数据集缺乏缺乏对分子低维结构及语义信息的精炼总结。
方法:动态分子图精细化分割算法
实现:
-
自动将分子图分割成不同层次的算法
-
重新设计训练流程
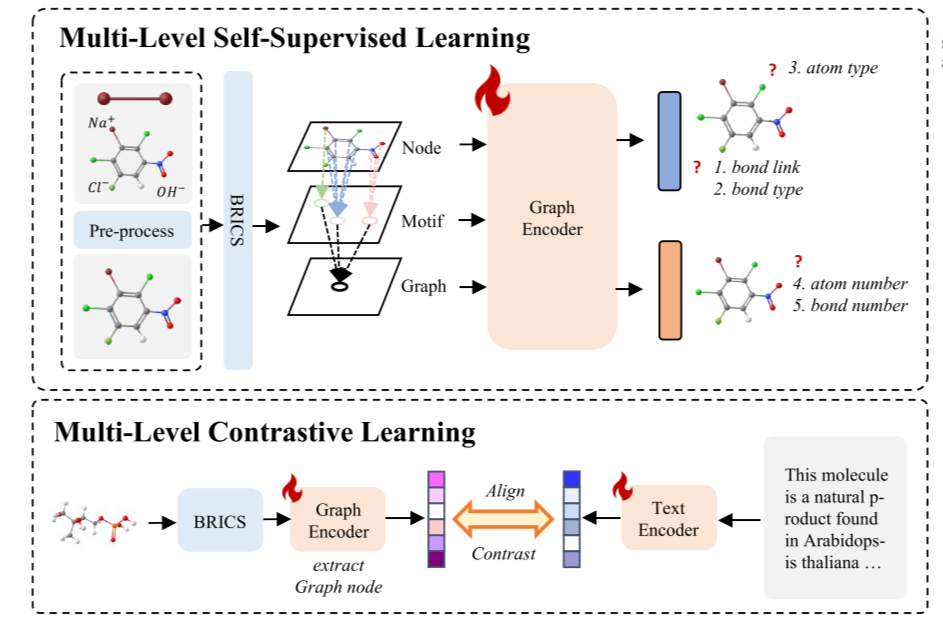
分级图动态分割
-
1获取节点编码V
-
2使用BRICS算法提取官能团信息M
rdkit.Chem.BRICS module — The RDKit 2025.03.3 documentation
rdkit_summary/recap_brics_decompose_build.ipynb at master · dreadlesss/rdkit_summary
-
3将官能团作为(虚拟)节点Vm,并加到分子图,在各自覆盖范围内创建节点-官能团边 Em。
-
4引入虚拟图节点Vg,创建图节点Vg和官能团节点的连接边Eg
-
得到
,其中
,
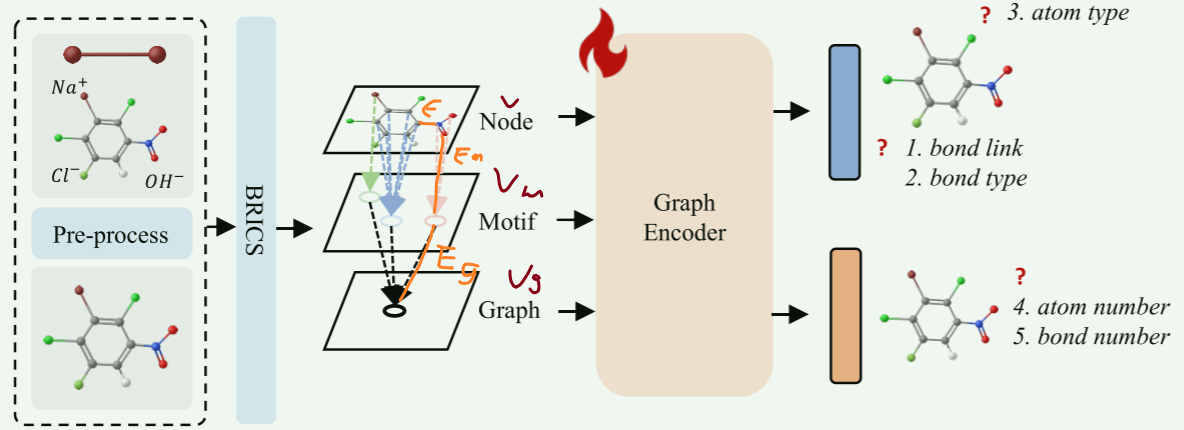
多级自监督学习
目的:使图神经网络能够高效地学习分子图的复杂内部信息(训练Graph Encoder)
1准备数据
- 1标准化+净化SMILES
- 2淘汰自由离子
- 3忽略少于5原子的分子
2使用分级图动态分割算法提取原子,官能团,图级信息
3分配任务:
-
原子级:引入三种(利用原子和键特性的)生成式预训练任务,每个任务有专用的预测头,分别使用三种不同的交叉熵损失进行优化
- 目标1:键连接预测
- 目标2:原子类型预测
- 目标3:键类型预测

-
图级:两类预测任务,分段损失函数(结合 MSE 和 L1 损失)
- 目标1:原子数量预测
- 目标2:键数量预测

多级对比学习
目的:对齐图特征和文本特征(使Graph Encoder能具备语义信息)
数据集:分子-文本对
方法:沿用MoleculeSTM
- 文本—>特征:SciBERT+平均池化
- 分子图—>特征:使用图节点(Vg)特征表示分子的多级特性
- 通过 “正样本匹配、负样本区分” 的方式,让 GNN 学到的图形特征与文本特征在同一空间内 “靠近”,同时让无关的图形 - 文本对 “远离”,实现跨模态语义对齐
stage4:探索多级特征
这一块儿和后面的实验部分基本一致
前置
-
1B LLaMA-3.2
-
重新评估5任务在InstructMol上的表现,建立基准
- 实验1:前向预测
- 实验2:试剂预测
- 实验3:逆合成预测
- 实验4:分子描述(molcap)
- 实验5:属性预测
-
选择1,2,4作为展开
探索1:Token Reduction
:节点级特征(
:节点级特征token数量),
:官能团级特征(
:官能团级特征token数量),
:GNN最终产生的特征
- projector:
将特征维度映射到LLM的维度
- 无压缩(No Reduction):直接拼接所有节点、基序、图特征(如某分子含 10 原子 + 3 基序 + 1 图,共 14 个token)。
- 分层压缩(Hierarchical Reduction):每级独立池化(节点 / 官能团级平均池化,图级保留),最终拼接 3 个token。
- 全压缩(All Reduction):全局平均池化所有特征,压缩为 1 个token(忽略粒度差异)。

| 任务 | 最优策略 | 原因分析 |
|---|---|---|
| 正向反应预测 | 无压缩 | 需要原子与官能团之间高精度的相互作用 |
| 试剂预测 | 全压缩 | 试剂依赖分子整体属性,并不需要底层的原子信息 |
| 分子描述(Molcap) | 无压缩 | 在分子描述任务中保留所有细节至关重要 |
Remark:
不同reduction方法的表现差异很小,说明完整的、高精度的图特征并不一定能让大语言模型获得更全面的分子理解。
相反,大型语言模型可能会更依赖SELFIES进行推理,这表明图结构模态的影响可能不如文本模态显著。
探索2:不同层级的影响
对每个层级进行全压缩(探索1的全压缩是指平均池化所有特征,这里应该是指分层压缩),分别作为分子图的表征,在3类任务上测试。
| 任务类型 | 最优层级 | 关键语义匹配 |
|---|---|---|
| 正向反应预测 | 图级 | 全局结构变化(环数、原子增减) |
| 试剂预测 | 图级( Exact Match) 官能团级(RDK 相似性) |
全局属性(极性)+ 功能团(亲电基团) |
| 分子描述(Molcap) | 官能团级 | 功能团语义(-OH、苯环) |
Exact Match(精确匹配):衡量模型预测的试剂 SMILES 字符串与真实试剂 SMILES 字符串经归一化后是否完全一致(得分 1 表示完全匹配,0 表示不匹配),直接反映试剂预测的 “精确性”。
RDK 相似性(RDK Similarity):基于 RDKit 工具生成的分子指纹,评估预测试剂与真实试剂的结构相似性(得分越高,结构越接近),反映预测试剂的 “合理性”(即使未完全匹配,结构相似的试剂也可能具有相似功能)。
Remark:
通过构建一个专门的虚拟节点,这种多层图神经网络能够更有效地汇总全局信息,甚至在某些任务中,其表现还能超越那些注重细节的方法。
例如,在正向反应预测任务中,图级方法(仅使用图级节点表征分子图)的表现优于采用无约简(no reduction)方法(concat所有特征)。
这表明,全局信息在帮助大模型理解分子结构方面发挥着关键作用,同时也验证了虚拟节点方法的有效性。
实验
分析
1:大型语言模型缺乏对图结构特征的全面理解,且无法充分有效地利用这些特征
-
节点级特征捕捉原子级信息
-
官能团级特征代表官能团间相互作用
-
平均池化成一个token影响不大,实际影响的可能是SELFLES
-
提出:构建新的对齐训练方法
- 1使LLM理解分子多层级间的关系
- 2促进对图特征与SELFIES表示之间联系的理解
- 现有:图文(LLM生成的分子描述)匹配效果不好
- 目标:对齐多层级信息、图特征与SELFIES表示方法
2:不同的任务可能需要来自不同层次的特征,这表明亟需一种能够跨多个层次处理信息的动态投射器(projector)
- 问题:当前使用的线性投射器,只起到对齐GNN embedding和LLM embedding的作用,无法考虑到不同特征层级间的语义区别;缺乏对各层级信息的全面应用
- 提出:使用动态投射器,根据不同任务选择性融合调整
实施细节
对话模板:

是 M³LLM 实现 “多模态分子任务交互” 的 “语言规范”—— 它一边告诉模型 “该如何行为(系统提示)”,一边告诉用户 “该如何输入(图形 + 指令)”,同时为模型输出划定 “格式边界”

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)