【Agent】WebWatcher: Breaking New Frontiers of Vision-Language Deep Research Agent
BrowseComp-VL是为在现实网络环境中运行的高级多模态推理代理而设计的。BrowseComp-VL被组织成5个主要领域,包括17个细粒度的子领域。(1.自然科学与形式科学(化学、物理、生物与医学、数学),2.工程与计算机科学(工程、计算机科学与人工智能),3.社会科学与人文科学(社会科学、历史、政治、地理),4.艺术、娱乐与体育(艺术、音乐、电视、游戏、体育),5.其他)Level 1:问
论文:https://arxiv.org/abs/2508.05748
代码:https://github.com/Alibaba-NLP/WebAgent
简介:Deep Research等网络Agent已经展示了卓越的认知能力,能够解决极具挑战性的信息搜索问题。然而,大多数研究仍然主要以文本为中心,忽视了现实世界中的视觉信息。这使得多模态深度研究非常具有挑战性,因为与基于文本的智能体相比,这种智能体在感知、逻辑、知识和使用更复杂的工具方面需要更强的推理能力。为了解决这一限制,我们引入了WebWatcher,这是一个用于深度研究的多模态智能体,具有增强的视觉语言推理能力。它利用高质量的合成多模态轨迹进行有效的冷启动训练,利用各种工具进行深度推理,并通过强化学习进一步增强泛化。为了更好地评估多模式Agent的能力,我们提出了BrowseComp-VL,这是一个具有browsecomp风格的基准测试,需要涉及视觉和文本信息的复杂信息检索。实验结果表明,WebWatcher在四个具有挑战性的VQA基准测试中显著优于专有基线、RAG工作流和开源代理,为解决复杂的多模态信息搜索任务铺平了道路。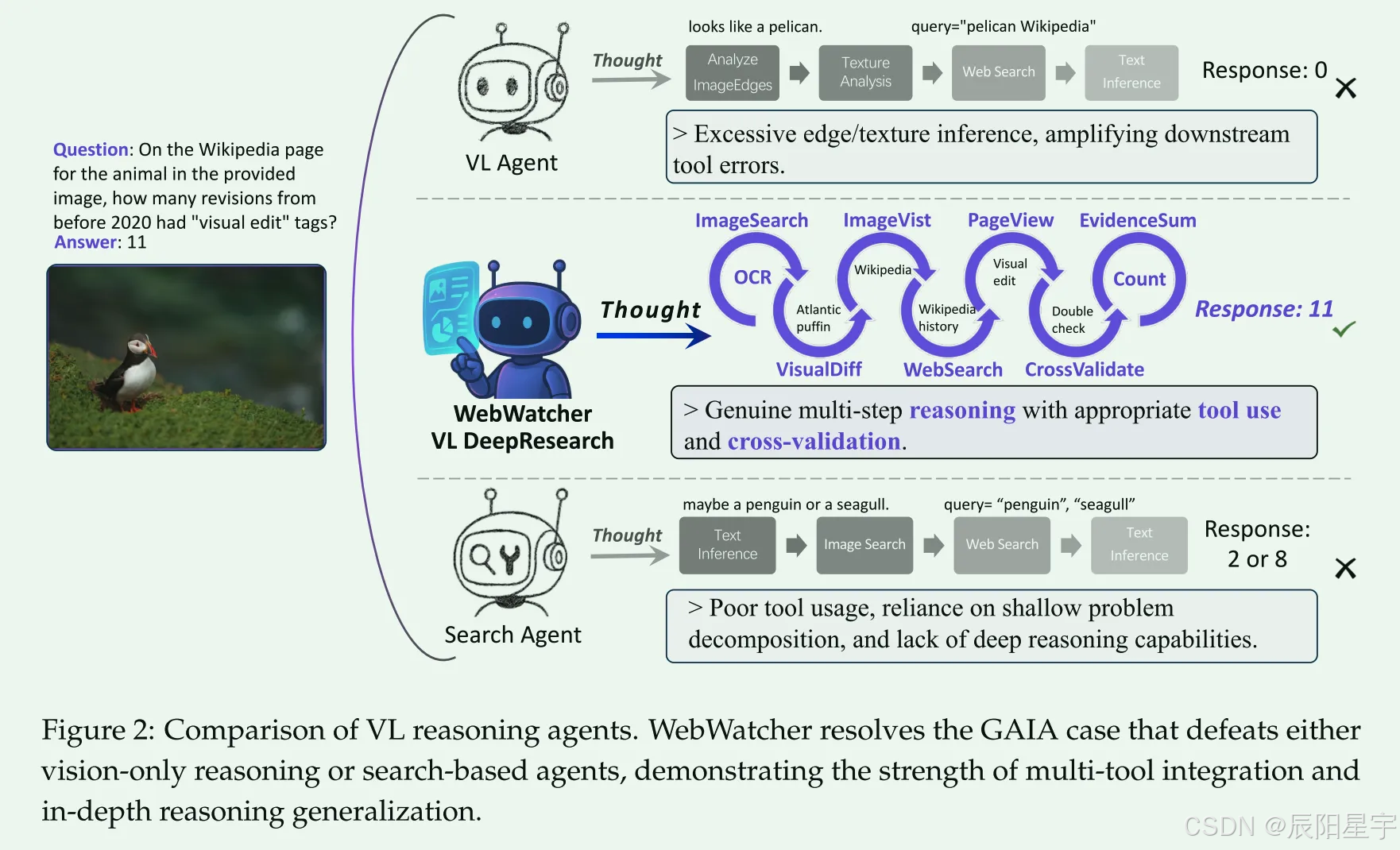
数据集构建
数据集介绍
BrowseComp-VL是为在现实网络环境中运行的高级多模态推理代理而设计的。BrowseComp-VL被组织成5个主要领域,包括17个细粒度的子领域。(1.自然科学与形式科学(化学、物理、生物与医学、数学),2.工程与计算机科学(工程、计算机科学与人工智能),3.社会科学与人文科学(社会科学、历史、政治、地理),4.艺术、娱乐与体育(艺术、音乐、电视、游戏、体育),5.其他)
- Level 1:问题需要多跳推理,但仍然引用显式实体。虽然可以通过迭代检索步骤获得答案,但由于需要跨多个来源集成信息,推理过程仍然很重要。这个级别总共包含199个VQA对。
- Level 2:问题是故意用模糊或模糊的实体和属性构造的。例如,具体的日期被模糊的句号取代,名字被掩盖,数量属性被模糊。这种设计引入了大量的不确定性,要求代理计划、比较和综合信息,而不是执行直接检索。我们总共提供了200对这个级别的VQA对。
数据集构建
生成QA
- Level 1:受WebDancer的CRAWL-QA的启发,我们通过从权威和知识丰富的来源(如arXiv, GitHub和Wikipedia)收集根url来增加推理的深度和广度。为了模拟类似人类的浏览行为,我们递归地遍历每个根域中的可访问超链接。然后使用gpt-4o从聚合的内容中合成问答对。
- Level 2:在WebSailor之后,我们通过用部分的、模糊的描述代替精确的引用来构造带有模糊实体的查询。我们的方法强调不能通过直接查找获取答案的情况,而是需要跨模式的上下文推理和综合。
两阶段生成框架
节点选择
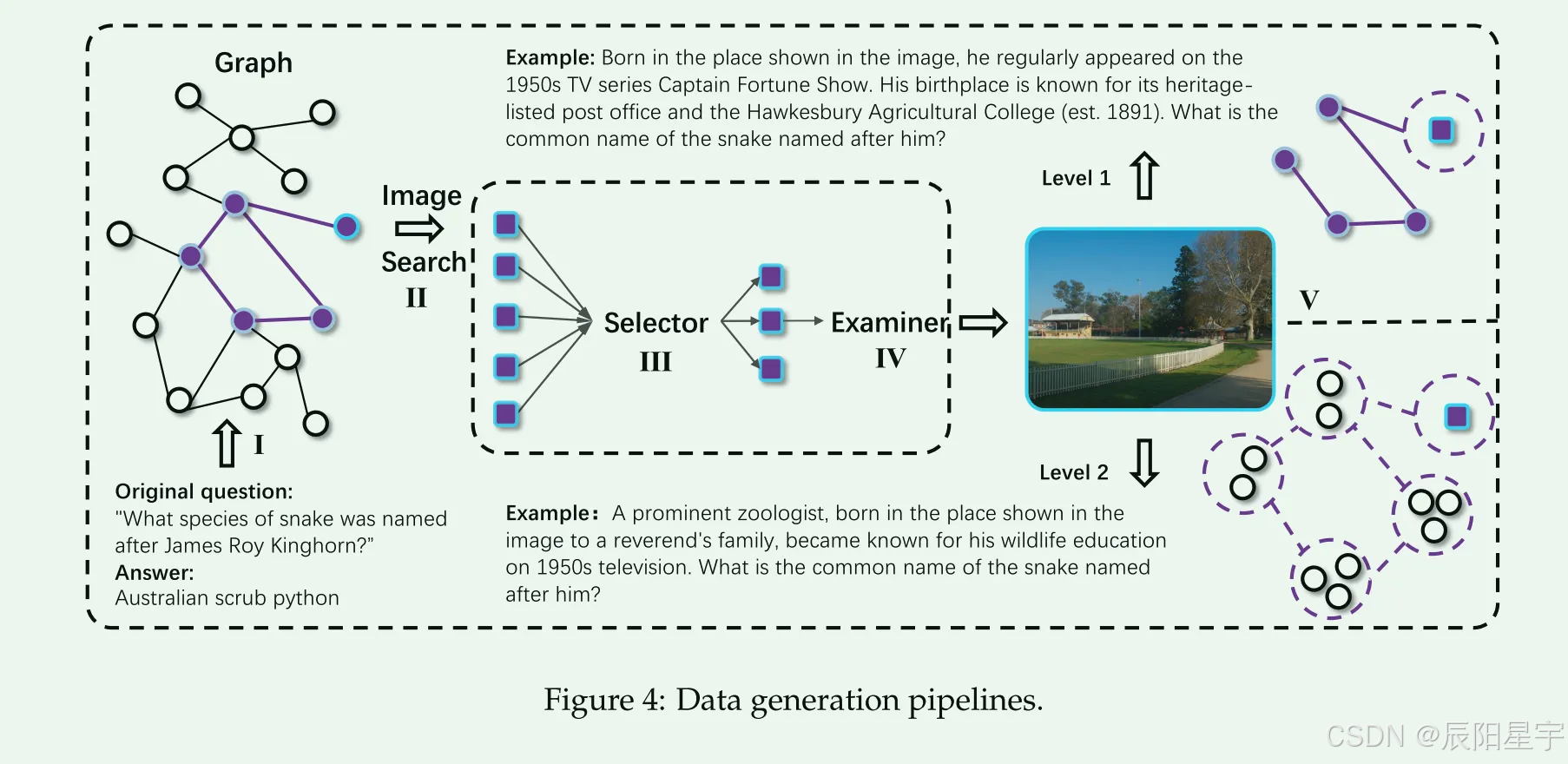
给定一个初始维基百科页面,我们首先提示gpt - 4o生成基于页面内容的基本QA对。页面标题作为根实体节点Broot。从Broot开始,我们递归地展开一个超链接图,通过遍历外向链接来构建一个深度为d、分支因子为k的树,从而在整个遍历中得到(kd+1−1)/(k−1)个节点。在我们的实现中,我们设置d = 3和k = 3以确保足够的语义覆盖。为了生成不同的推理路径,我们从整个树中采样多个子图。我们随机选择一个节点子集并继续展开,直到形成一个包含N个实体的子图。每个子图定义了从Broot到新选择的目标实体B的唯一推理路径,形成一个编码多跳关系的知识图谱。这些子图是生成不同QA对的基础。
查询生成
基于所选择的子图和真实值,我们首先提示gpt-4o生成一个标准形式,该形式在推理路径上显式地引用实体和关系。然后,它被转换成一个模糊的版本,其中关键引用被部分的、模糊的或定性的描述所取代。这种设计鼓励多种推理模式,推动模型通过综合而不是表面匹配来推断答案。
QA到VQA构建
VQA的视觉上下文构建
为了确保有效的视觉基础,我们首先过滤掉琐碎或过于模糊的目标实体B,例如那些表示时间参考或领域外部概念的实体B,它们缺乏足够的视觉基础。对于每个保留的实体B,我们检索一组web图像I(B) = I B 1, I B 2,…, I I B K via谷歌SerpApi,其中在我们的实现中K = 2。得到的图像I(B)作为构建多模态推理示例的视觉基础。与现有VQA基准测试中普遍存在的合成或合成图像不同,我们的图像是严格真实的,因此最小化了噪声并最大化了与现实世界任务的相关性。
实体掩码和问题转化
为了从每个文本QA实例(qt, a)中构建基于图像的VQA对,我们使用gpt-4o应用基于提示的重写。设qt表示包含明确提到目标实体的原始文本问题。我们用一个视觉参考标记rvis来掩盖这个提及,例如指示词(“这个实体”)或描述性短语(“图像中的对象”),以产生一个转换后的VQA查询q。同时,我们生成一个图像查询字符串simg(B)来指导I(B)的过滤。然后将每个图像I + B k∈I(+ B)与(q, a)配对以形成一个不同的VQA实例。因此,每个文本QA对产生K个多模态示例,从n个原始问题中产生总共Kn个VQA项目。
质量控制
采用三级过滤管道,确保高质量的VQA样本。
- 选择器:首先,我们消除了转换后的VQA查询q与原始问题qt相同的数据,并丢弃了实体名称m_b或其别名显式出现在qt中的情况,这表明实体屏蔽或问题重写失败。其次,提示gpt-4o根据原始QA对(qt, a)和转换后的VQA查询(q, a)评估每个图像I, B, k∈I(B)。gpt - 40评估上下文对齐,语义匹配和视觉推理的合理性。获得低相关性分数的实例将被过滤掉。
- 评审者:对于每个保留的图像查询对(simg(B), I(B)),提示gpt-4o仅使用视觉内容和I(B)的相关标题回答合成查询simg(B)。如果不能准确回答,则表示检索能力弱或图像查询格式不佳,因此会过滤掉此类查询q。
Agent轨迹构建
多模态工具
- (1)基于谷歌SerpAp的Web图像搜索,检索相关图像、相应的标题及其网页url,更好地理解输入图像I; (2) Web Text Search,用于开放域信息搜索,检索查询的标题和网页url; (3)访问Jian,使导航到特定的url的网页摘要,量身定制的“目标”在大型语言模型的行动中指定; (4)代码解释器,支持符号计算和数值推理; (5) OCR,通过提示符和SFT数据调用从输入图像中提取文本的内部工具。
构建轨迹
给定一个来自BrowseComp-VL的VQA实例(I, q, a),我们使用gpt-4o来自动构建工具使用轨迹,模拟人类如何通过一步一步地尝试不同的工具来探索和推理问题。根据ReAct的想法,每个轨迹τ由多个思考-行动-观察周期组成。具体来说,在每次迭代t时,语言模型将累积的上下文历史作为输入,生成:
- 思考:<think></think>
- 活动:<tool_call></tool_call>或<answer></answer>
- 观察:<tool_response></tool_response>
轨迹过滤和质量评估
为了确保鲁棒的和指导性监督,我们采用了三阶段轨迹选择:
- 最终答案匹配:我们保留轨迹τ,其中最终答案与真实值a匹配,确保工具使用步骤的整个序列导致正确和完整的解决方案。
- 步骤级检查:我们使用gpt-4o来验证轨迹τ中每个中间步骤的逻辑一致性。对每一对(tl, ol)进行审查,以确保工具调用和观察与上下文和推理目标保持一致。带有幻觉内容、矛盾或不合理的工具调用的轨迹将被丢弃。这避免了常见的失败模式,即通过幸运的猜测而不是有意义的工具使用来获得正确答案。
- 过滤少步骤:为了鼓励多步骤推理而不是走捷径,我们使用少于三个工具调用来删除τ。这确保了训练数据反映了实质性的、过程驱动的交互,而不是琐碎的或一步完成。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 11
11 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)